鸢尾花分类的6种机器学习方法综合分析与实现
鸢尾花分类的6种机器学习方法综合分析与实现
首先我们来看一下对应的实验结果。

数据准备与环境配置
在开始机器学习项目前,首先需要准备编程环境和加载数据。以下代码导入必要的库并加载鸢尾花数据集:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris# 加载数据集
iris = load_iris()
X = iris.data # 特征矩阵(150x4)
y = iris.target # 目标变量
feature_names = iris.feature_names # 特征名称列表
target_names = iris.target_names # 类别名称列表
该部分代码完成了基础环境设置,其中numpy和pandas用于数据处理,matplotlib和seaborn负责可视化展示。通过load_iris()函数获取经典数据集,该数据集包含三种鸢尾花的四个形态特征测量值。特征矩阵X存储150个样本的花萼长度、花萼宽度、花瓣长度和花瓣宽度数据,目标变量y对应三个类别标签。打印特征和类别名称有助于确认数据正确加载,例如输出显示特征为"sepal length (cm)"等四个测量维度,类别对应setosa、versicolor和virginica三个品种。
数据预处理与特征工程
数据预处理是机器学习流程中的关键步骤,以下代码完成数据划分与标准化:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42,stratify=y
)# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
数据划分采用分层抽样策略,保留30%样本作为测试集,stratify=y参数确保各类别比例一致,避免因随机划分导致样本偏差。random_state=42固定随机种子保证结果可复现。标准化处理通过StandardScaler将特征缩放至均值为0、方差为1的分布,这对基于距离计算的算法(如SVM、KNN)尤为重要。训练集的fit_transform同时计算参数并转换数据,而测试集仅使用训练集的参数进行转换,防止数据泄露。实际应用中可根据特征分布尝试其他预处理方法,例如对偏态分布特征使用对数变换,或对存在类别型特征时采用独热编码。
多模型实现与训练
本实验选取六种典型机器学习算法进行对比:
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNBmodels = {"逻辑回归": LogisticRegression(max_iter=1000),"决策树": DecisionTreeClassifier(max_depth=3),"支持向量机": SVC(kernel='rbf', probability=True),"随机森林": RandomForestClassifier(n_estimators=100),"K近邻": KNeighborsClassifier(n_neighbors=5),"朴素贝叶斯": GaussianNB()
}
模型选择涵盖不同学习范式:逻辑回归作为基础线性分类器,适合处理线性可分问题;决策树通过设置最大深度3控制模型复杂度;支持向量机采用RBF核处理非线性边界;随机森林集成多棵决策树提升泛化能力;K近邻基于局部相似性进行预测;朴素贝叶斯依赖特征条件独立假设。扩展时可以考虑添加梯度提升树(如XGBoost)或神经网络(MLPClassifier),例如:
from xgboost import XGBClassifier
from sklearn.neural_network import MLPClassifiermodels.update({"XGBoost": XGBClassifier(n_estimators=100),"神经网络": MLPClassifier(hidden_layer_sizes=(64,32), max_iter=1000)
})
模型评估与验证
采用交叉验证与测试集评估相结合的方式:
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score, confusion_matrix, classification_reportresults = {}
for name, model in models.items():# 交叉验证cv_scores = cross_val_score(model, X_train_scaled, y_train, cv=5)# 完整训练model.fit(X_train_scaled, y_train)y_pred = model.predict(X_test_scaled)# 结果存储results[name] = {'cv_mean': cv_scores.mean(),'cv_std': cv_scores.std(),'test_accuracy': accuracy_score(y_test, y_pred),'confusion_matrix': confusion_matrix(y_test, y_pred),'classification_report': classification_report(y_test, y_pred, target_names=target_names)}
五折交叉验证通过五次数据划分评估模型稳定性,交叉验证准确率的均值和标准差反映模型泛化能力。测试集评估使用准确率、混淆矩阵和包含精确率、召回率、F1值的分类报告进行全方位评价。对于类别不平衡问题,建议补充ROC曲线和AUC值评估,例如:
from sklearn.metrics import roc_curve, auc
from sklearn.preprocessing import label_binarize# 对目标变量进行二值化处理
y_test_bin = label_binarize(y_test, classes=[0,1,2])# 计算每个类别的ROC曲线
plt.figure(figsize=(10,8))
for name, model in results.items():if hasattr(model, "predict_proba"):y_score = model.predict_proba(X_test_scaled)for i in range(3):fpr, tpr, _ = roc_curve(y_test_bin[:,i], y_score[:,i])roc_auc = auc(fpr, tpr)plt.plot(fpr, tpr, label=f'{name} (Class {i}, AUC={roc_auc:.2f})')plt.plot([0,1], [0,1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('多类别ROC曲线')
plt.legend(loc="lower right")
plt.show()
模型对比如下所示。

结果可视化与解释
通过可视化直观对比模型表现:
# 准确率对比
plt.figure(figsize=(12,6))
models_list = list(models.keys())
x = np.arange(len(models_list))
plt.barh(x, [results[name]['test_accuracy'] for name in models_list], color='steelblue')
plt.yticks(x, models_list)
plt.xlabel('测试集准确率')
plt.xlim(0.8, 1.0)
plt.title('分类模型性能对比')
plt.show()# 最佳模型混淆矩阵
best_model = max(results, key=lambda k: results[k]['test_accuracy'])
cm = results[best_model]['confusion_matrix']
plt.figure(figsize=(8,6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=target_names, yticklabels=target_names)
plt.title(f'{best_model}混淆矩阵\n准确率:{results[best_model]["test_accuracy"]:.3f}')
plt.xlabel('预测类别')
plt.ylabel('真实类别')
plt.show()
准确率对比图横向排列各模型表现,深蓝色柱体长度反映测试集准确率高低,x轴范围限定在0.8-1.0区间以突出差异。混淆矩阵采用颜色渐变的热力图形式,对角线深色方块表示正确分类数量,非对角线元素显示类别间误分情况。
from sklearn.model_selection import learning_curvedef plot_learning_curve(estimator, title, X, y, cv=5):train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=-1,train_sizes=np.linspace(0.1, 1.0, 5))plt.figure(figsize=(10,6))plt.plot(train_sizes, np.mean(train_scores, axis=1), 'o-', label="训练得分")plt.plot(train_sizes, np.mean(test_scores, axis=1), 'o-', label="验证得分")plt.xlabel("训练样本数")plt.ylabel("准确率")plt.title(title)plt.legend()plt.grid(True)plt.show()# 示例:绘制随机森林学习曲线
plot_learning_curve(RandomForestClassifier(n_estimators=100), "随机森林学习曲线", X_train_scaled, y_train)
热力图对比如下所示。

特征重要性分析
基于树模型的特征重要性评估:
# 随机森林特征重要性
rf_model = models["随机森林"].fit(X_train_scaled, y_train)
importances = rf_model.feature_importances_plt.figure(figsize=(10,6))
indices = np.argsort(importances)[::-1]
plt.barh(range(X.shape[1]), importances[indices], align='center')
plt.yticks(range(X.shape[1]), [feature_names[i] for i in indices])
plt.gca().invert_yaxis()
plt.xlabel('特征重要性')
plt.title('随机森林特征重要性排序')
plt.show()
该分析显示花瓣相关特征(特别是花瓣长度)对分类贡献最大,这与生物学事实一致——不同鸢尾花品种的花瓣形态差异显著。对于线性模型,可通过系数大小分析特征重要性:
# 逻辑回归系数分析
lr_model = models["逻辑回归"].fit(X_train_scaled, y_train)
coefficients = lr_model.coef_plt.figure(figsize=(10,6))
for i in range(3):plt.barh(feature_names, coefficients[i], label=f'Class {target_names[i]}')
plt.xlabel('系数大小')
plt.title('逻辑回归特征系数')
plt.legend()
plt.tight_layout()
plt.show()
特征重要性可视化如下所示。

模型部署与应用建议
在完成模型评估后,可将最佳模型序列化保存:
import joblib# 保存最佳模型
best_model = max(results, key=lambda k: results[k]['test_accuracy'])
joblib.dump(models[best_model], 'best_iris_classifier.pkl')# 加载模型进行预测示例
loaded_model = joblib.load('best_iris_classifier.pkl')
sample = X_test_scaled[0].reshape(1,-1)
prediction = loaded_model.predict(sample)
print(f"预测类别: {target_names[prediction[0]]}")
总结与展望
本实验系统实现了鸢尾花分类任务的机器学习流程,通过对比不同算法揭示了模型性能差异的原因——数据分布特性与算法假设的匹配程度。实验表明,基于核方法的SVM和集成学习随机森林在该数据集上表现优异,测试准确率接近100%。
相关文章:
鸢尾花分类的6种机器学习方法综合分析与实现
鸢尾花分类的6种机器学习方法综合分析与实现 首先我们来看一下对应的实验结果。 数据准备与环境配置 在开始机器学习项目前,首先需要准备编程环境和加载数据。以下代码导入必要的库并加载鸢尾花数据集: import numpy as np import pandas as pd impo…...
vite,Vue3,ts项目关于axios配置
一、安装依赖包 npm install axios -S npm install qs -S npm install js-cookie 文件目录 二、配置线上、本地环境 与src文件同级,分别创建本地环境文件 .env.development 和线上环境文件 .env.production # 本地环境 ENV = development # 本地环境接口地址 VITE_API_URL =…...

mysql:重置表自增字段序号
情况一:清空表数据后重置自增 ID 如果你希望清空表中的所有数据,并将自增 ID 重置为初始值(通常为 1) 1、truncate truncate table tb_dict; 2、delete 配合 alter 语句 delete from tb_dict; alter table tb_dict AUTO_INCR…...

STM32 模块化开发指南 · 第 4 篇 用状态机管理 BLE 应用逻辑:分层解耦的实践方式
本文是《STM32 模块化开发实战指南》第 4 篇,聚焦于 BLE 模块中的状态管理问题。我们将介绍如何通过有限状态机(Finite State Machine, FSM)架构,实现 BLE 广播、扫描、连接等行为的解耦与可控,并配合事件队列驱动完成主从共存、低功耗友好、状态清晰的 BLE 应用。 一、为…...

HTML — 浮动
浮动 HTML浮动(Float)是一种CSS布局技术,通过float: left或float: right使元素脱离常规文档流并向左/右对齐,常用于图文混排或横向排列内容。浮动元素会紧贴父容器或相邻浮动元素的边缘,但脱离文档流后可能导致父容器高…...

IP节点详解及国内IP节点获取指南
获取国内IP节点通常涉及网络技术或数据资源的使用,IP地址作为网络设备的唯一标识,对于网络连接和通信至关重要。详细介绍几种修改网络IP地址的常用方法,无论是对于家庭用户还是企业用户,希望能找到适合自己的解决方案。以下是方法…...
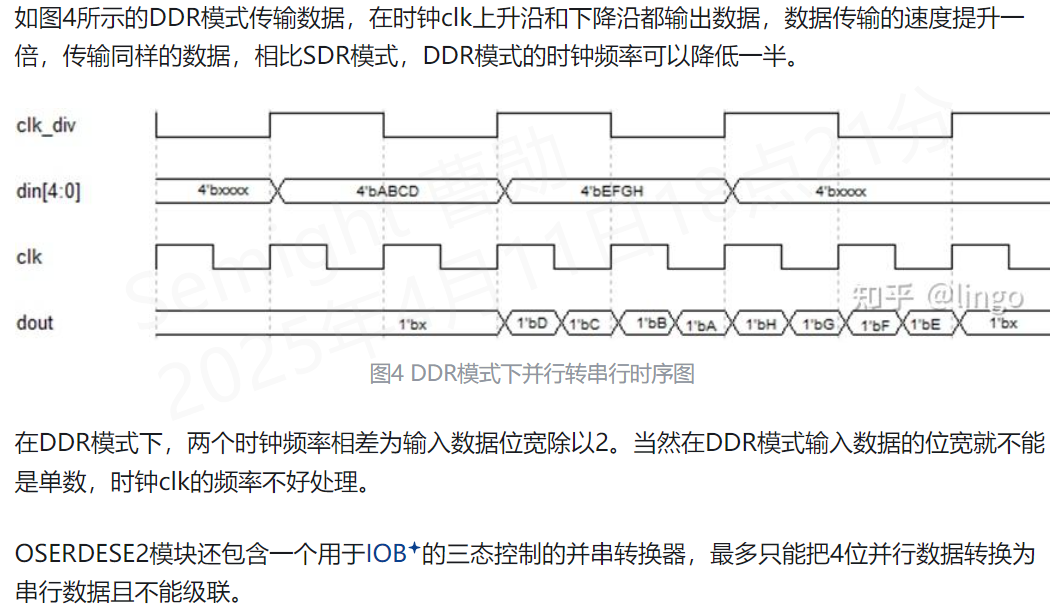
AD9253 LVDS 高速ADC驱动开发
1、查阅AD9253器件手册 2、查阅Xilinx xapp524手册 3、该款ADC工作在125Msps下,14bit - 2Lane - 1frame 模式。 对应:data clock时钟为500M DDR mode。data line rate:1Gbps。frame clock:1/4 data clock 具体内容:…...
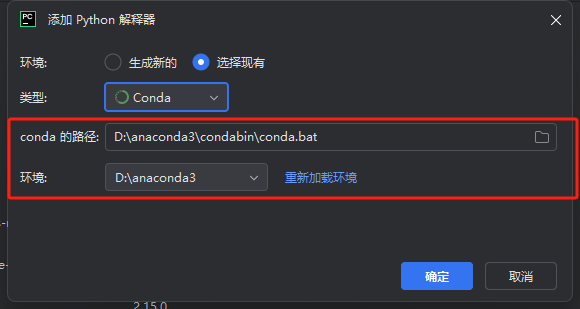
pycharm2024.3.5版本配置conda踩坑
配置解释器是conda时,死活选不到自己的环境 看了很多,都是说要选scripts下的conda.exe 都没用 主要坑在于这是新版的pycharm 是配置condabin 下的 conda.bat 参考:PyCharm配置PyTorch环境(完美解决找不到Conda可执行文件python.exe问题) …...

【异常处理】Clion IDE中cmake时头文件找不到 头文件飘红
如图所示是我的clion项目目录 我自定义的data_structure.h和func_declaration.h在unit_test.c中无法检索到 cmakelists.txt配置文件如下所示: cmake_minimum_required(VERSION 3.30) project(noc C) #设置头文件的目录 include_directories(${CMAKE_SOURCE_DIR}/…...
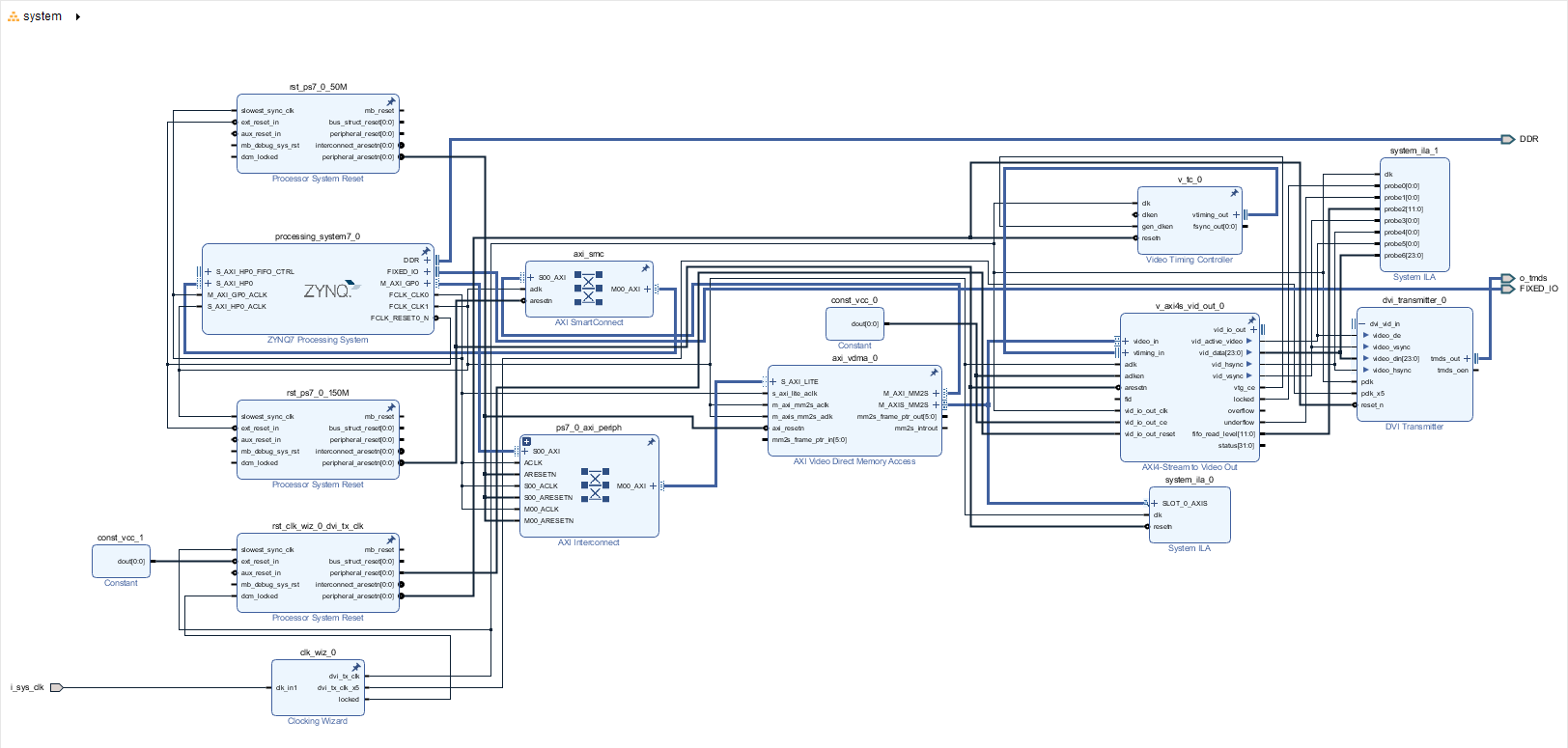
14 - VDMA彩条显示实验
文章目录 1 实验任务2 系统框图3 硬件设计4 软件设计 1 实验任务 本实验任务是PS端写彩条数据至DDR3内存中,然后通过PL端的VDMA IP核将彩条数据通过HDMI接口输出显示。 2 系统框图 本实验是用HDMI接口固定输出1080P的彩条图,所以: rgb2lc…...
:touch)
每天学一个 Linux 命令(13):touch
Linux 文件管理命令:touch touch 是 Linux 中一个简单但高频使用的命令,主要用于创建空文件或修改文件的时间戳(访问时间、修改时间)。它是文件管理和脚本操作的实用工具。 1. 命令作用 创建空文件:快速生成一个或多个空白文件。更新时间戳:修改文件的访问时间(Access …...
PromptUp 网站介绍:AI助力,轻松创作
1. 网站定位与核心功能 promptup.net 可能是一个面向 创作者、设计师、营销人员及艺术爱好者 的AI辅助创作平台,主打 零门槛、智能化的内容生成与优化。其核心功能可能包括: AI艺术创作:通过输入关键词、选择主题或拖放模板,快速生成风格多样的数字艺术作品(如插画、海报…...

高级java每日一道面试题-2025年3月26日-微服务篇[Nacos篇]-在Spring Cloud项目中如何集成Nacos?
如果有遗漏,评论区告诉我进行补充 面试官: 在Spring Cloud项目中如何集成Nacos? 我回答: 在Spring Cloud项目中集成Nacos,可以充分利用Nacos作为服务注册与发现中心以及配置管理中心的功能。以下是详细的步骤和说明,帮助你完成这一集成过程…...
 平台的整体概览与未来发展)
AI 大语言模型 (LLM) 平台的整体概览与未来发展
📋 分析报告:AI 大语言模型 (LLM) 平台的整体概览与未来发展 自动生成的结构化分析报告 💻 整体概述:AI LLM 平台的市场现状与发展动力 随着人工智能技术的飞速发展,大语言模型(Large Language Models, L…...

Java中的Map vs Python字典:核心对比与使用指南
一、核心概念 1. 基本定义 Python字典(dict) :动态类型键值对集合,语法简洁,支持快速查找。Java Map:接口,常用实现类如 HashMap、LinkedHashMap,需声明键值类型(泛型&…...

人工智能100问☞第3问:深度学习的核心原理是什么?
目录 一、通俗解释 二、专业解析 三、权威参考 深度学习的核心原理是通过构建多层神经网络结构,逐层自动提取并组合数据特征,利用反向传播算法优化参数,从而实现对复杂数据的高层次抽象和精准预测。 一、通俗解释 深度学习的核心原理,就像是教计算机像婴儿…...

金能电力:配电房为什么离不开绝缘胶板
在当今电力系统日益复杂、对供电稳定性与安全性要求极高的时代,每一个细节都关乎着电力供应的顺畅以及工作人员的生命安全。而配电房里常常被大家忽视的绝缘垫,实则起着至关重要的 “守护” 作用。今天,金能电力就来给大家详细讲讲配电房为什…...

Python 深度学习实战 第1章 什么是深度学习代码示例
第1章:什么是深度学习 内容概要 第1章介绍了深度学习的背景、发展历史及其在人工智能(AI)和机器学习(ML)中的地位。本章探讨了深度学习的定义、其与其他机器学习方法的关系,以及深度学习在近年来取得的成…...

【模块化拆解与多视角信息1】基础信息:隐藏的筛选规则——那些简历上没说出口的暗号
写在最前 作为一个中古程序猿,我有很多自己想做的事情,比如埋头苦干手搓一个低代码数据库设计平台(目前只针对写java的朋友),比如很喜欢帮身边的朋友看看简历,讲讲面试技巧,毕竟工作这么多年,也做到过高管,有很多面人经历,意见还算有用,大家基本都能拿到想要的offe…...
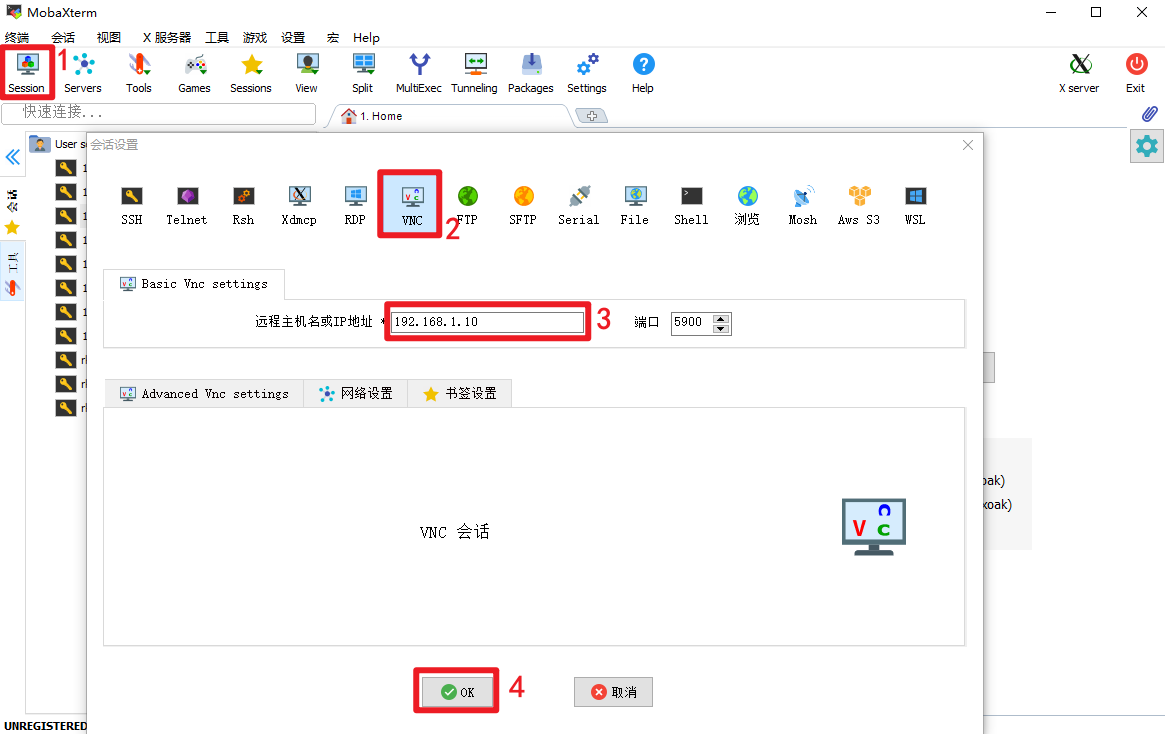
【HD-RK3576-PI】VNC 远程桌面连接
在当今数字化时代,高效便捷的操作方式是技术爱好者与专业人士的共同追求。对于使用 HD-RK3576-PI微型单板计算机的用户而言,当面临没有显示屏的场景时,如何实现远程操作桌面系统呢?别担心,VNC 远程桌面连接将为你解决这…...

Vue.js 中 v-if 的使用及其原理
在 Vue.js 的开发过程中,条件渲染是一项极为常见的需求。v-if指令作为 Vue.js 实现条件渲染的关键手段,能够根据表达式的真假来决定是否渲染某一块 DOM 元素。它在优化页面展示逻辑、提升用户体验等方面发挥着重要作用。接下来,我们就深入探讨…...

电梯广告江湖的终局:分众 “吃掉” 新潮,是救赎还是迷途?
文 / 大力财经 作者 / 魏力 导言:商业世界的底层运行法则,从来都是能量流动的自然映射。宇宙第一性原理和运行法则是,能量大的吸引能量小的。电梯里的战争与和平,从对抗到合并,成为中国商业竞争史中关于博弈与进化的…...

第十六届蓝桥杯大赛软件赛省赛 C/C++ 大学B组
由于官方没有公布题目的数据, 所以代码仅供参考 1. 移动距离 题目链接:P12130 [蓝桥杯 2025 省 B] 移动距离 - 洛谷 【问题描述】 小明初始在二维平面的原点,他想前往坐标 (233, 666)。在移动过程中,他 只能采用以下两种移动方式…...
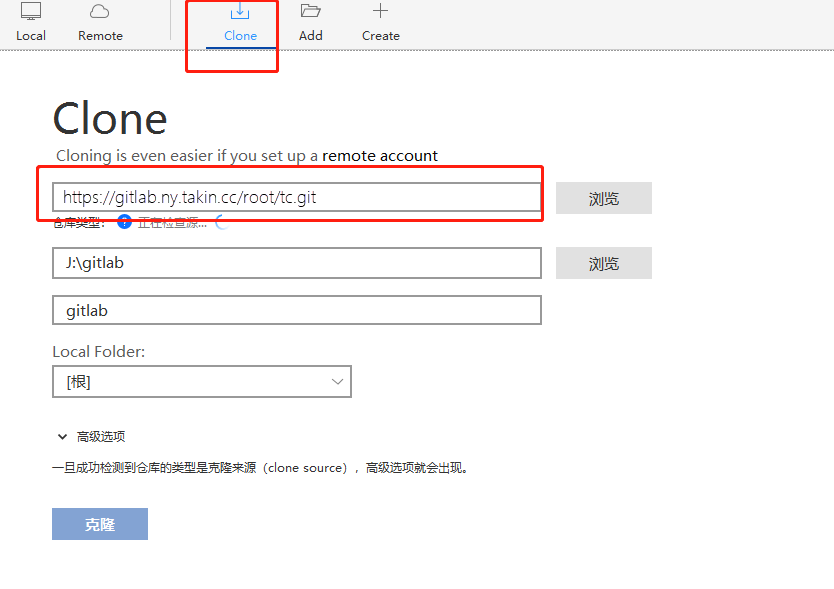
如何在 CentOS 7 系统上以容器方式部署 GitLab,使用 ZeroNews 通过互联网访问 GitLab 私有仓库,进行代码版本发布与更新
第 1 步: 部署 GitLab 容器 在开始部署 GitLab 容器之前,您需要创建本地目录来存储 GitLab 数据、配置和日志: #创建本地目录 mkdir -p /opt/docker/gitlab/data mkdir -p /opt/docker/gitlab/config mkdir -p /opt/docker/gitlab/log#gi…...
第1章 对大型语言模型的介绍
人类正处在一个关键转折点。自2012年起,基于深度神经网络的人工智能系统研发进入快速通道,将这一技术推向了新高度:至2019年底,首个能够撰写与人类文章真假难辨的软件系统问世,这个名为GPT-2(生成型预训练变…...

Quartus II的IP核调用及仿真测试
目录 第一章 什么是IP核?第二章 什么是LPM?第一节 设置LPM_COUNTER模块参数第二节 仿真 第三章 什么是PLL?第一节 设置ALTPLL(嵌入式锁相环)模块参数第二节 仿真 第四章 什么是RAM?第一节 RAM_1PORT的调用第…...

JDK(Java Development Kit)从发布至今所有主要版本 的详细差异、新增特性及关键更新的总结,按时间顺序排列
以下是 JDK(Java Development Kit)从发布至今所有主要版本 的详细差异、新增特性及关键更新的总结,按时间顺序排列: 1. JDK 1.0 (1996) 发布年份:1996年1月23日关键特性: Java首次正式发布。核心语言特性…...

Vue 3 和 Vue 2 的区别及优点
Vue.js 是一个流行的 JavaScript 框架,广泛用于构建用户界面和单页应用。自 Vue 3 发布以来,很多开发者开始探索 Vue 3 相较于 Vue 2 的新特性和优势。Vue 3 引入了许多改进,优化了性能、增强了功能、提升了开发体验。本文将详细介绍 Vue 2 和…...

Linux 入门五:Makefile—— 从手动编译到工程自动化的蜕变
一、概述:Makefile—— 工程编译的 “智能指挥官” 1. 为什么需要 Makefile? 手动编译的痛点:当工程包含数十个源文件时,每次修改都需重复输入冗长的编译命令(如gcc file1.c file2.c -o app),…...

通过websocket给服务端发送订单催单提醒消息
controller层 GetMapping("/reminder/{id}")public Result Remainder(PathVariable("id") Long id){orderService.remainder(id);return Result.success();} 实现类 Overridepublic void remainder(Long id) {Orders ordersDB orderMapper.getById(id);…...