Python深度学习基础——卷积神经网络(CNN)(PyTorch)
CNN原理
从DNN到CNN
- 卷积层与汇聚
- 深度神经网络DNN中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(Pooling)。
- DNN 的全连接层对应 CNN 的卷积层,汇聚是与激活函数类似的附件;单个卷积层的结构是:卷积层-激活函数-(汇聚),其中汇聚可省略。
2.CNN:专攻多维数据
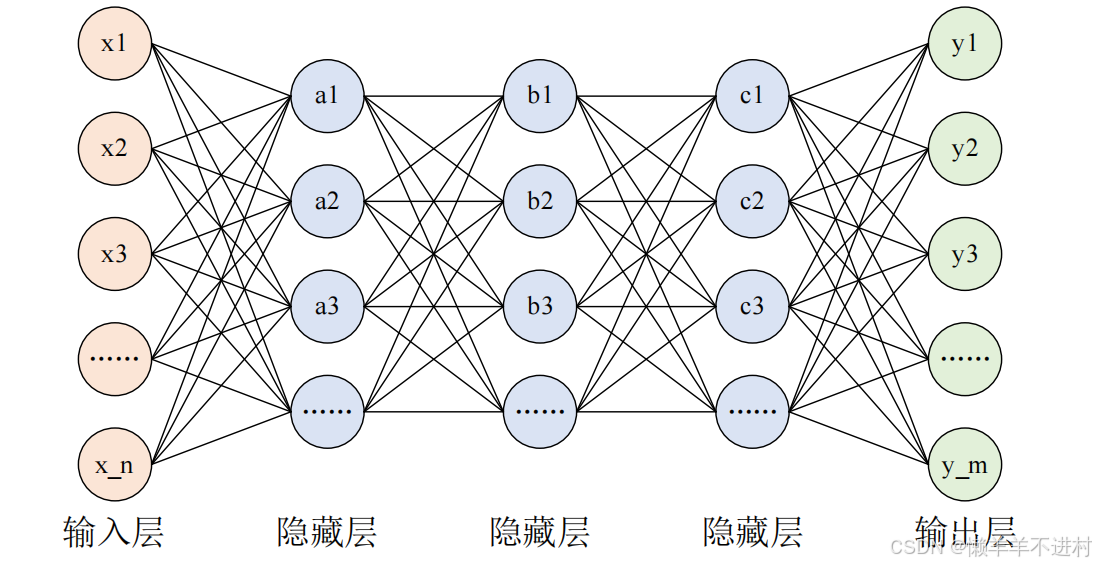
在深度神经网络 DNN 课程的最后一章,使用 DNN 进行了手写数字的识别。但是,图像至少就有二维,向全连接层输入时,需要多维数据拉平为 1 维数据,这样一来,图像的形状就被忽视了,很多特征是隐藏在空间属性里的,如下图所示。
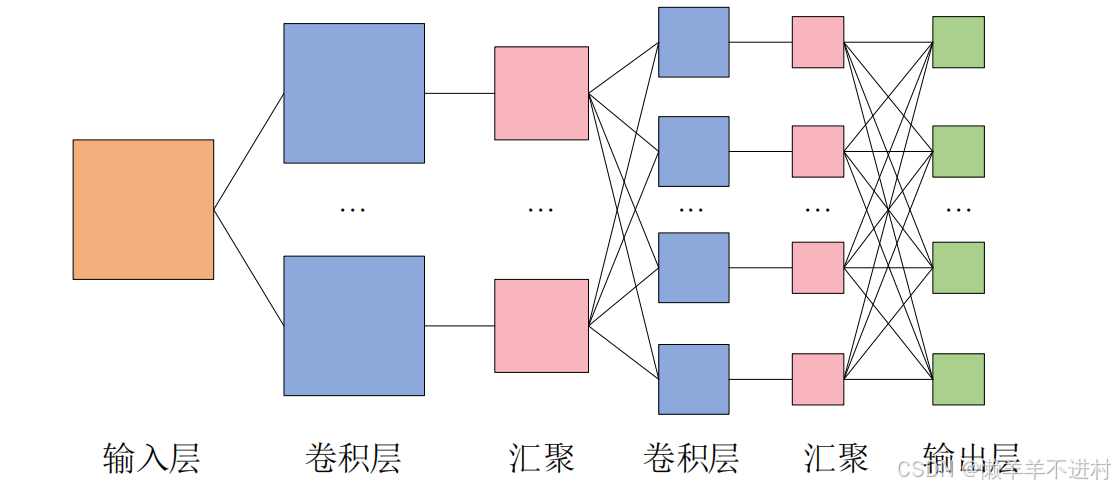
而卷积层可以保持输入数据的维数不变,当输入数据是二维图像时,卷积层会以多维数据的形式接收输入数据,并同样以多维数据的形式输出至下一层,如下图所示。
卷积层
CNN 中的卷积层与 DNN 中的全连接层是平级关系,全连接层中的权重与偏置即y = ω1x1 + ω2x2 + ω3x3 + b中的 ω 与 b,卷积层中的权重与偏置变得稍微复杂。
-
内部参数:权重(卷积核)
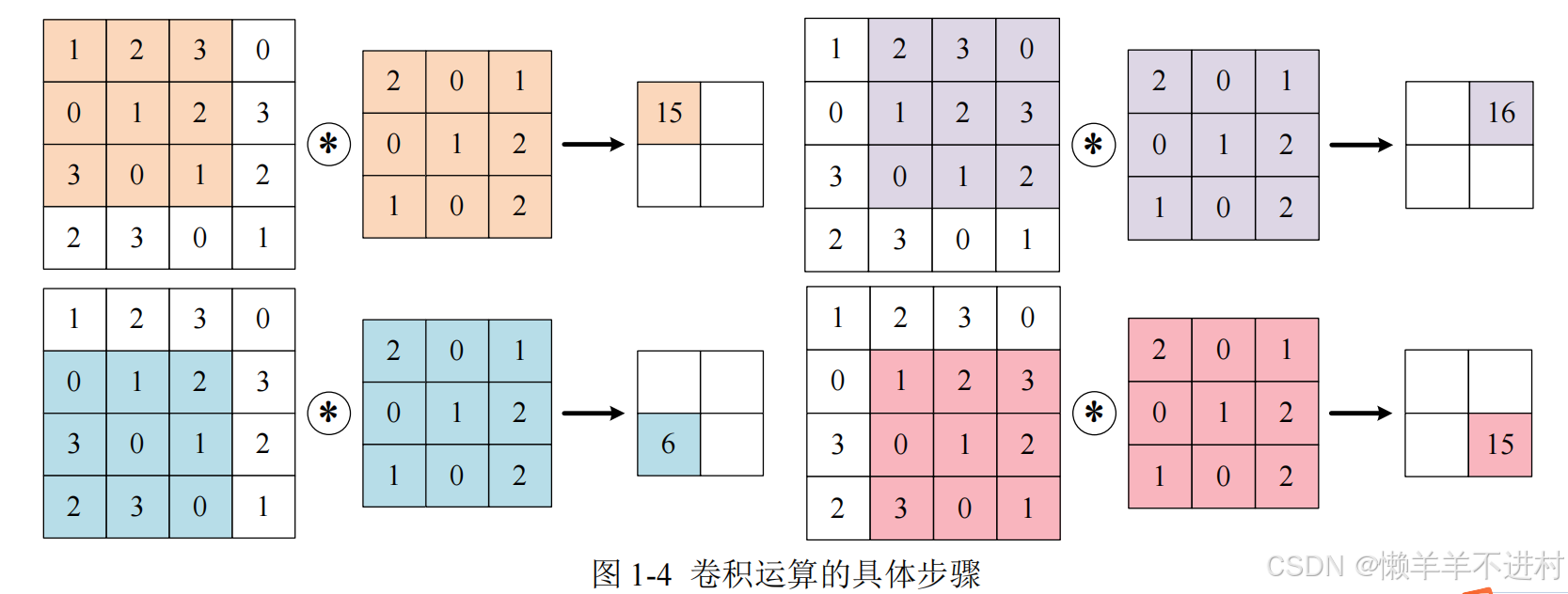
当输入数据进入卷积层后,输入数据会与卷积核进行卷积运算,如下图:

上图中的输入大小是(4,4),卷积核大小事(3,3),输出大小是(2,2)卷积运算的原理是逐元素乘积后再相加。
-
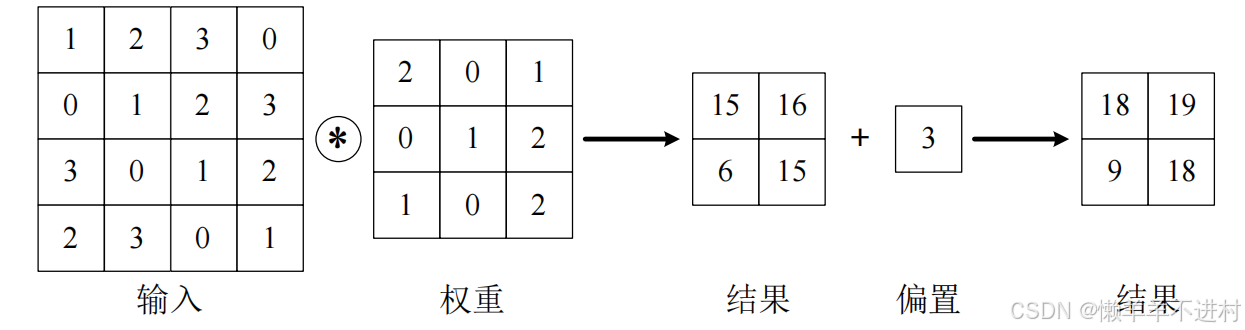
内部参数:偏置
在卷积运算的过程中也存在偏置,如下图所示:
-
外部参数:补充
为了防止经过多个卷积层后图像越卷越小,可以在进行卷积层的处理之前,向输入数据的周围填入固定的数据(比如 0),这称为填充(padding)。
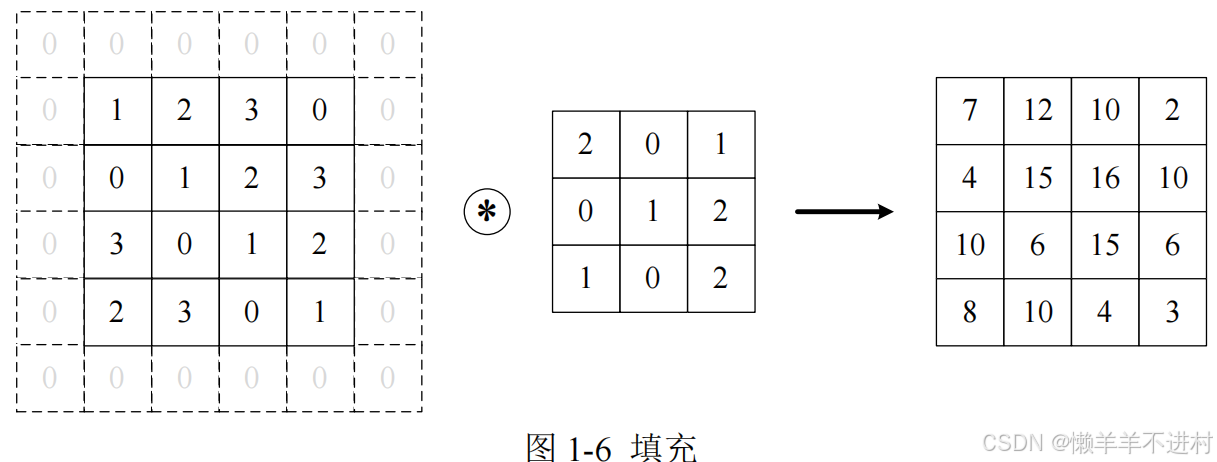
对上图大小为(4, 4)的输入数据应用了幅度为 1 的填充,填充值为 0。 -
外部参数:步幅
使用卷积核的位置间隔被称为步幅(stride),之前的例子中步幅都是 1,如果将步幅设为 2,此时使用卷积核的窗口的间隔变为 2。
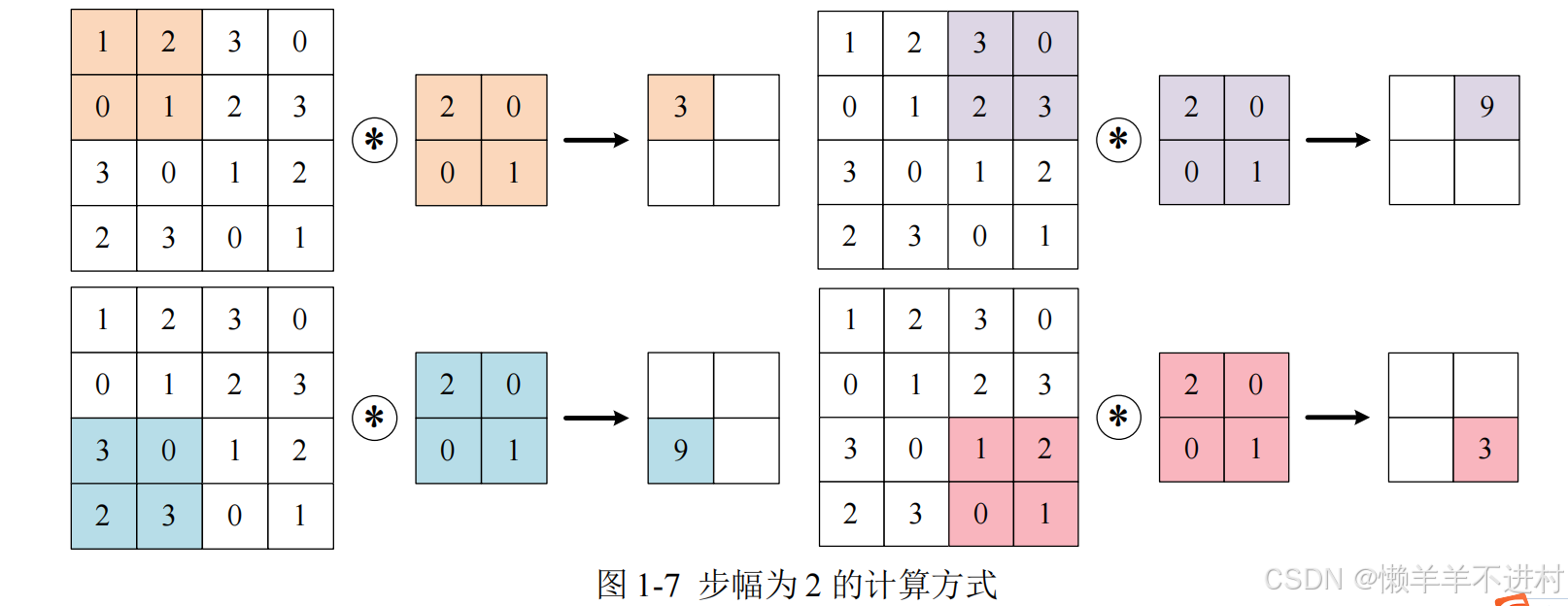
综上,增大填充后,输出尺寸会变大;而增大步幅后,输出尺寸会变小 -
输入与输出尺寸的关系
假设输入尺寸为(H, W),卷积核的尺寸为(FH, FW),填充为 P,步幅为 S。则输出尺寸(OH, OW)的计算公式为
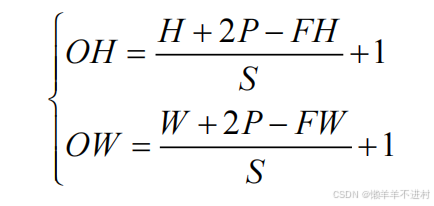
多通道
在上一小节讲的卷积层,仅仅针对二维的输入与输出数据(一般是灰度图像),可称之为单通道。
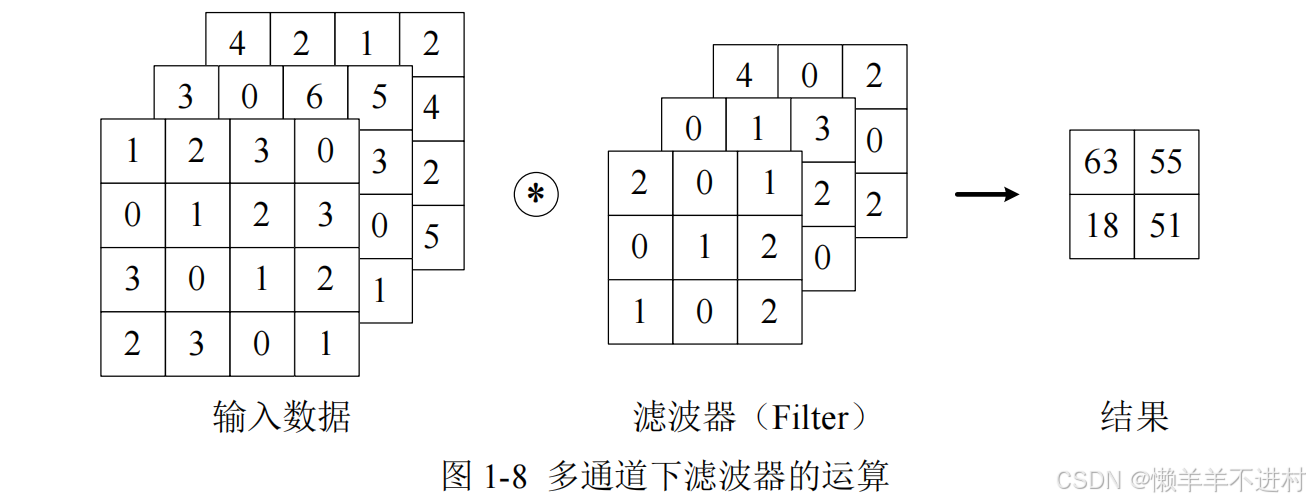
但是,彩色图像除了高、长两个维度之外,还有第三个维度:通道(channel)。例如,以 RGB 三原色为基础的彩色图像,其通道方向就有红、黄、蓝三部分,可视为 3 个单通道二维图像的混合叠加。一般的,当输入数据是二维时,权重被称为卷积核(Kernel);当输入数据是三维或更高时,权重被称为滤波器(Filter)。
1.多通道输入
对三维数据的卷积操作如图 1-8 所示,输入数据与滤波器的通道数必须要设为相同的值,可以发现,这种情况下的输出结果降级为了二维
将数据和滤波器看作长方体,如图 1-9 所示

C、H、W 是固定的顺序,通道数要写在高与宽的前面
图 1-9 可看出,仅通过一个卷积层,三维就被降成二维了。大多数时候我们想让三维的特征多经过几个卷积层,因此就需要多通道输出,如图 1-10 所示。
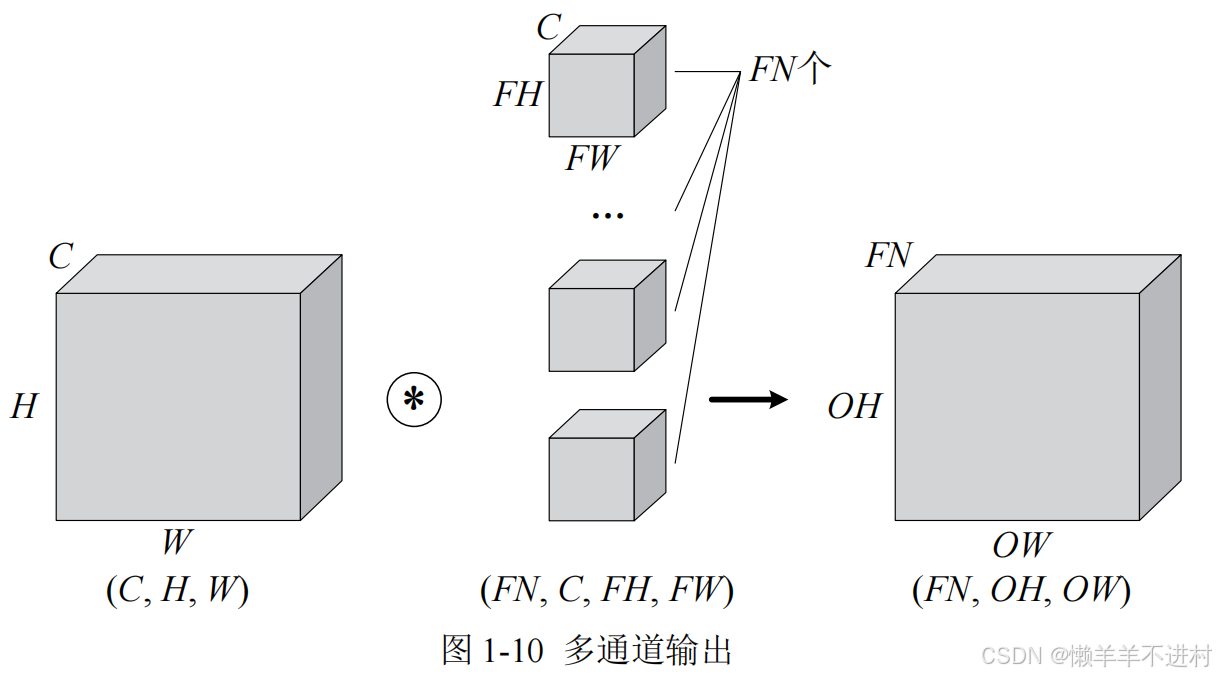
别忘了,卷积运算中存在偏置,如果进一步追加偏置的加法运算处理,则结果如图 1-11 所示,每个通道都有一个单独的偏置。

汇聚(很多教材也叫做池化)
汇聚(Pooling)仅仅是从一定范围内提取一个特征值,所以不存在要学习的内部参数。一般有平均汇聚与最大值汇聚。
-
平均汇聚
一个以步幅为2进行的2*2窗口的平均汇聚,如图1-12所示

-
最大值汇聚
一个以步幅为 2 进行 2*2 窗口的最大值汇聚,如图 1-13 所示
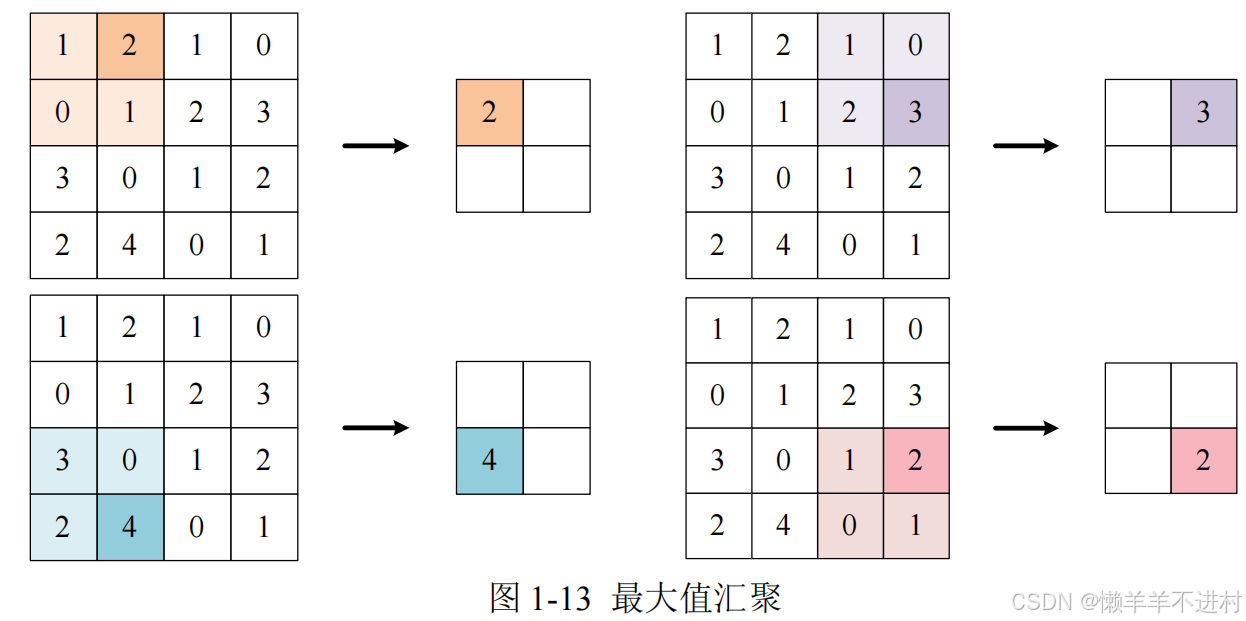
汇聚对图像的高 H 和宽 W 进行特征提取,不改变通道数 C。
尺寸变换总结
- 卷积层
现假设卷积层的填充为P,步幅为S,由
- 输入数据的尺寸是:( C,H,W) 。
- 滤波器的尺寸是:(FN,C,FH,FW)。
- 输出数据的尺寸是:(FN,OH,OW) 。
可得
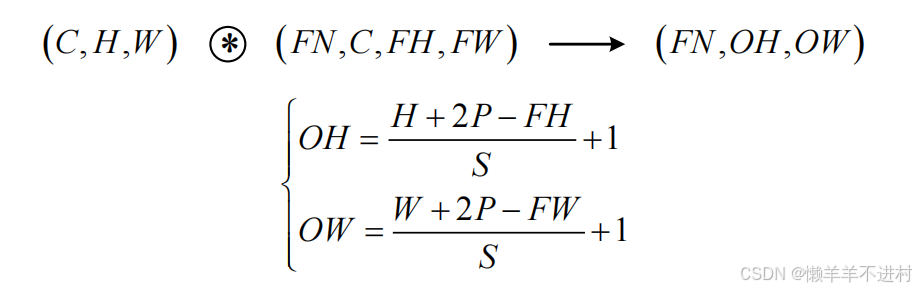
2. 汇聚
现假设汇聚的步幅为 S,由
- 输入数据的尺寸是:( C,H,W) 。
- 输出数据的尺寸是:(C,OH,OW) 。
可得
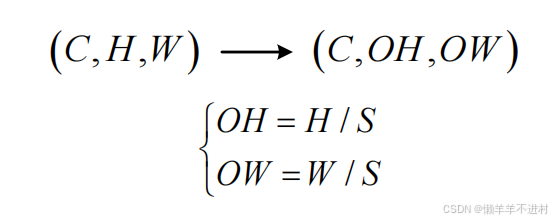
LeNet-5
网络结构
LeNet-5 虽诞生于 1998 年,但基于它的手写数字识别系统则非常成功。
该网络共 7 层,输入图像尺寸为 28×28,输出则是 10 个神经元,分别表示某手写数字是 0 至 9 的概率。
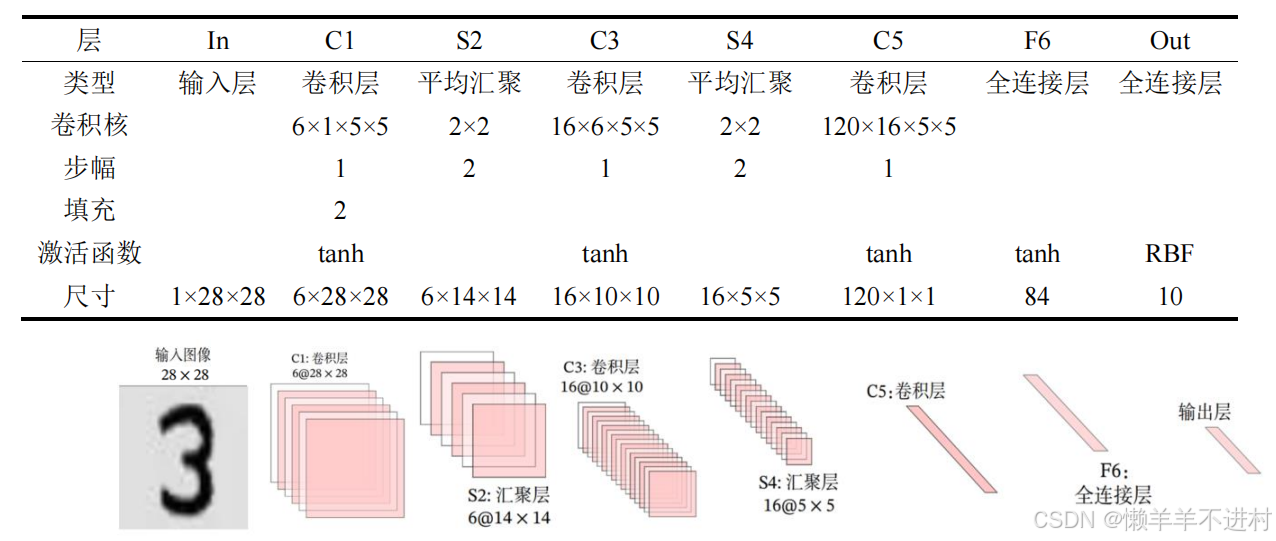
PS:输出层由 10 个径向基函数 RBF 组成,用于归一化最终的结果,目前RBF 已被 Softmax 取代。
根据网络结构,在 PyTorch 的 nn.Sequential 中编写为
self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(), # C1:卷积层nn.AvgPool2d(kernel_size=2, stride=2), # S2:平均汇聚nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(), # C3:卷积层nn.AvgPool2d(kernel_size=2, stride=2), # S4:平均汇聚nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(), # C5:卷积层nn.Flatten(), # 把图像铺平成一维nn.Linear(120, 84), nn.Tanh(), # F5:全连接层nn.Linear(84, 10) # F6:全连接层
)
其中,nn.Conv2d( )需要四个参数,分别为
- in_channel:此层输入图像的通道数;
- out_channel:此层输出图像的通道数;
- kernel_size:卷积核尺寸;
- padding:填充;
- stride:步幅。
制作数据集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.MNIST(root = 'D:/Jupyter/dataset/mnist/', # 下载路径train = True, # 是 train 集download = True, # 如果该路径没有该数据集,就下载transform = transform # 数据集转换参数
)
test_Data = datasets.MNIST(root = 'D:/Jupyter/dataset/mnist/', # 下载路径train = False, # 是 test 集download = True, # 如果该路径没有该数据集,就下载transform = transform # 数据集转换参数
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=256)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=256)
搭建神经网络
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(),nn.Flatten(),nn.Linear(120, 84), nn.Tanh(),nn.Linear(84, 10))def forward(self, x):y = self.net(x)return y
# 查看网络结构
X = torch.rand(size= (1, 1, 28, 28))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )

# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
# 优化算法的选择
learning_rate = 0.9 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 5
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
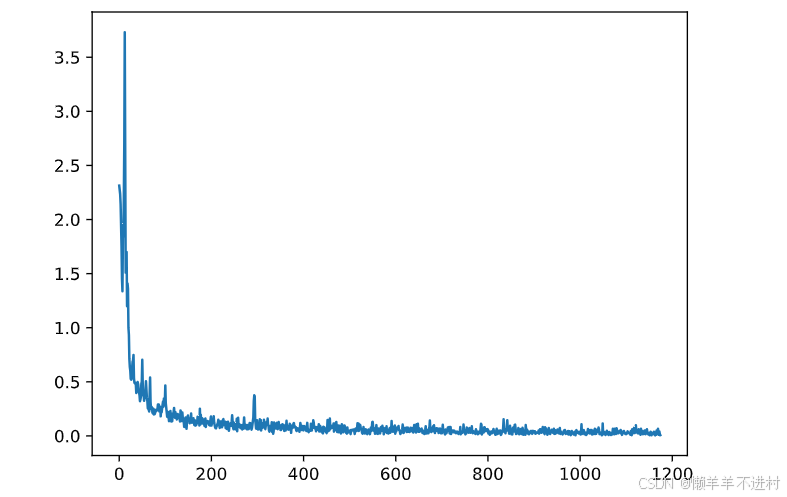
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0) print(f'测试集精准度: {100*correct/total} %') #OUT:测试集精准度: 9.569999694824219 %
AlexNet
网络结构
AlexNet 是第一个现代深度卷积网络模型,其首次使用了很多现代网络的技术方法,作为 2012 年 ImageNet 图像分类竞赛冠军,输入为 3×224×224 的图像,输出为 1000 个类别的条件概率。
考虑到如果使用 ImageNet 训练集会导致训练时间过长,这里使用稍低亿档的 1×28×28 的 MNIST 数据集,并手动将其分辨率从 1×28×28 提到 1×224×224,同时输出从 1000 个类别降到 10 个,修改后的网络结构见下表。
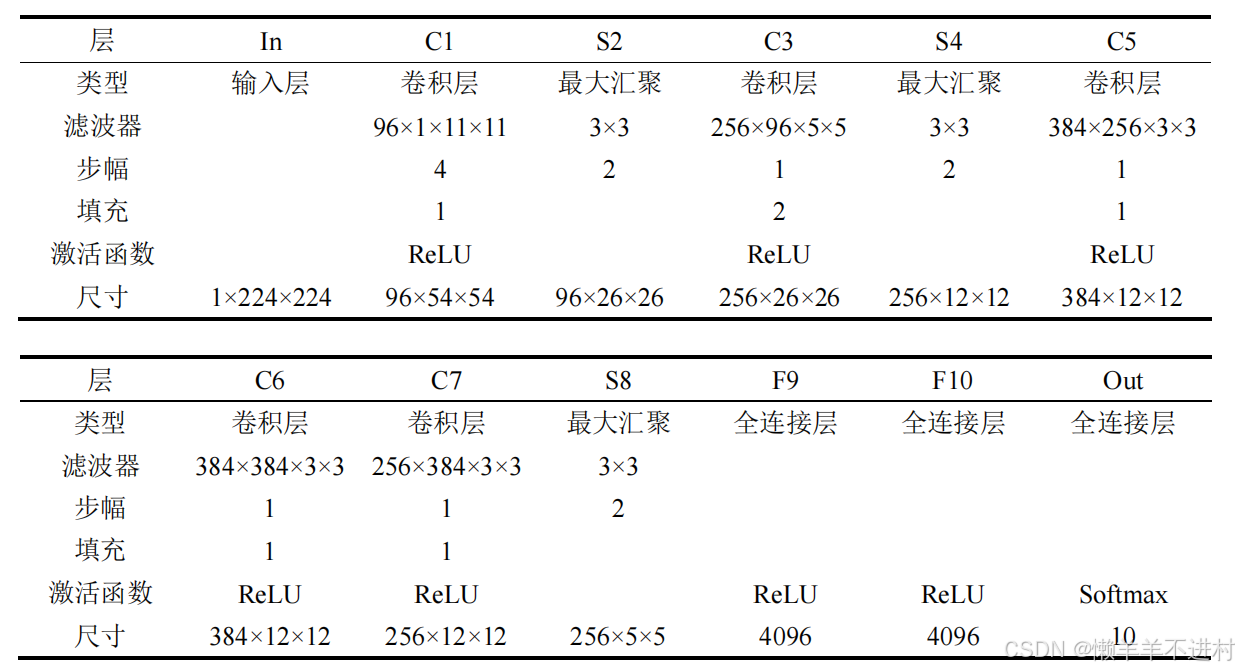
根据网络结构,在 PyTorch 的 nn.Sequential 中编写为
self.net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5), # Dropout——随机丢弃权重nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5), # 按概率 p 随机丢弃突触nn.Linear(4096, 10)
)
制作数据集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([transforms.ToTensor(),transforms.Resize(224),transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神经网络
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10))def forward(self, x):y = self.net(x)return y
# 查看网络结构
X = torch.rand(size= (1, 1, 224, 224))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
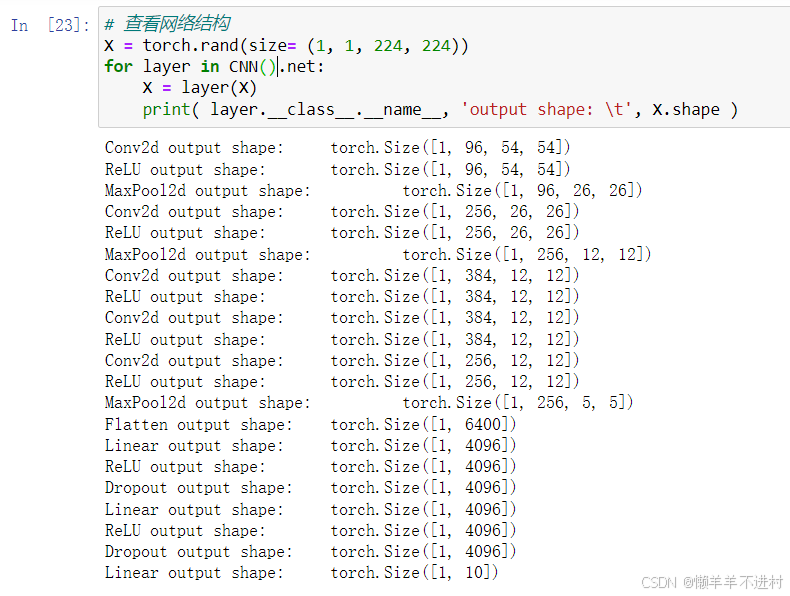
# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
# 优化算法的选择
learning_rate = 0.1 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 10
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)
print(f'测试集精准度: {100*correct/total} %')
GoogLeNet
网络结构
2014 年,获得 ImageNet 图像分类竞赛的冠军是 GoogLeNet,其解决了一个重要问题:滤波器超参数选择困难,如何能够自动找到最佳的情况。
其在网络中引入了一个小网络——Inception 块,由 4 条并行路径组成,4 条路径互不干扰。这样一来,超参数最好的分支的那条分支,其权重会在训练过程中不断增加,这就类似于帮我们挑选最佳的超参数,如示例所示。
# 一个 Inception 块
class Inception(nn.Module):def __init__(self, in_channels):super(Inception, self).__init__()self.branch1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch2 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=3, padding=1),nn.Conv2d(24, 24, kernel_size=3, padding=1))self.branch3 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=5, padding=2))self.branch4 = nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
此外,分支 2 和分支 3 上增加了额外 1×1 的滤波器,这是为了减少通道数,降低模型复杂度。
GoogLeNet 之所以叫 GoogLeNet,是为了向 LeNet 致敬,其网络结构为
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 10, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=10),nn.Conv2d(88, 20, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=20),nn.Flatten(),nn.Linear(1408, 10) )def forward(self, x):y = self.net(x)return y
制作数据集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神经网络
# 一个 Inception 块
class Inception(nn.Module):def __init__(self, in_channels):super(Inception, self).__init__()self.branch1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch2 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=3, padding=1),nn.Conv2d(24, 24, kernel_size=3, padding=1))self.branch3 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=5, padding=2))self.branch4 = nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 10, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=10),nn.Conv2d(88, 20, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=20),nn.Flatten(),nn.Linear(1408, 10))def forward(self, x):y = self.net(x) return y
# 查看网络结构
X = torch.rand(size= (1, 1, 28, 28))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss()
# 优化算法的选择
learning_rate = 0.1 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 10
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)print(f'测试集精准度: {100*correct/total} %')
ResNet
网络结构
残差网络(Residual Network,ResNet)荣获 2015 年的 ImageNet 图像分类竞赛冠军,其可以缓解深度神经网络中增加深度带来的“梯度消失”问题。
在反向传播计算梯度时,梯度是不断相乘的,假如训练到后期,各层的梯度均小于 1,则其相乘起来就会不断趋于 0。因此,深度学习的隐藏层并非越多越好,隐藏层越深,梯度越趋于 0,此之谓“梯度消失”。
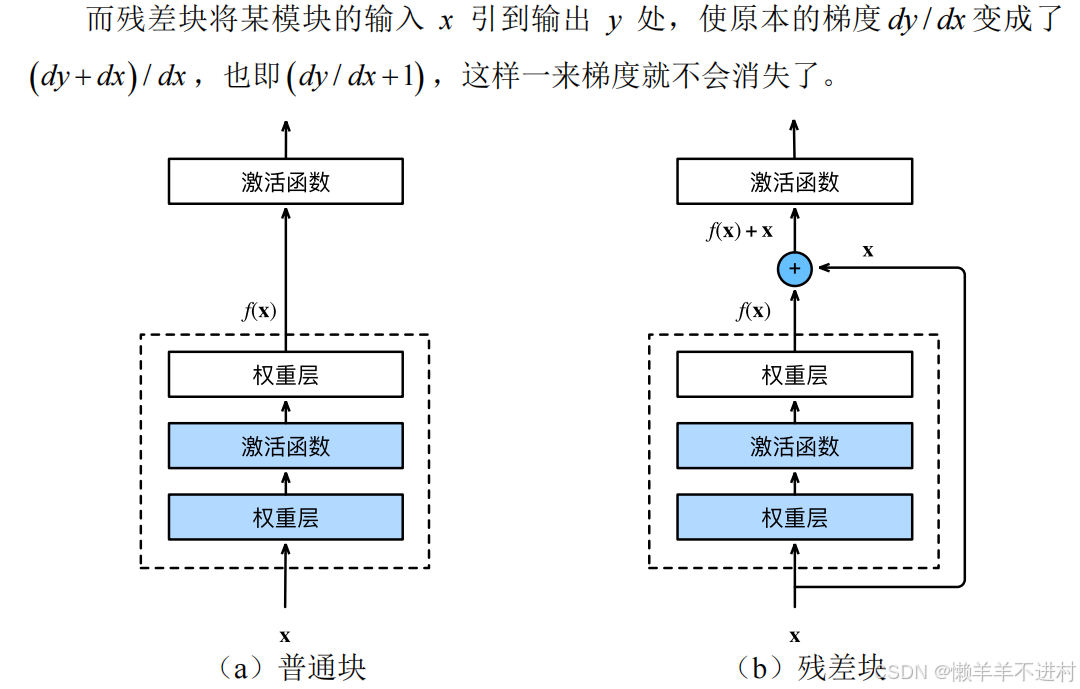
制作数据集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神经网络
# 残差块
class ResidualBlock(nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.net = nn.Sequential(nn.Conv2d(channels, channels, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(channels, channels, kernel_size=3, padding=1),)def forward(self, x):y = self.net(x)return nn.functional.relu(x+y)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5), nn.ReLU(),nn.MaxPool2d(2), ResidualBlock(16),nn.Conv2d(16, 32, kernel_size=5), nn.ReLU(),nn.MaxPool2d(2), ResidualBlock(32),nn.Flatten(),nn.Linear(512, 10))def forward(self, x):y = self.net(x) return y
# 查看网络结构
X = torch.rand(size= (1, 1, 28, 28))for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss()
# 优化算法的选择
learning_rate = 0.1 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 10
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)
print(f'测试集精准度: {100*correct/total} %')
相关文章:
Python深度学习基础——卷积神经网络(CNN)(PyTorch)
CNN原理 从DNN到CNN 卷积层与汇聚 深度神经网络DNN中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(Pooling)。DNN 的全连接…...
Python判断语句全面解析:从基础到高级模式匹配)
Python(11)Python判断语句全面解析:从基础到高级模式匹配
目录 一、条件逻辑的工程价值1.1 真实项目中的逻辑判断1.2 判断语句类型矩阵 二、基础判断深度解析2.1 多条件联合判断2.2 类型安全判断 三、模式匹配进阶应用3.1 结构化数据匹配3.2 对象模式匹配 四、判断语句优化策略4.1 逻辑表达式优化4.2 性能对比测试 五、典型应用场景实战…...

MTK7628基于原厂的mtk-openwrt-sdk-20160324-8f8e4f1e.tar.bz2 源代码包,配置成单网口模式的方法
一、配置. 在SDK工程下,运行make kernel_menuconfig,如下图所示: Ralink Module --->选上“One Port Only”,如下图所示: 如果P0网口实现WAN口,就配置成W/LLLL,否则就配置成LLLL/W. 二、修改网口的原代…...
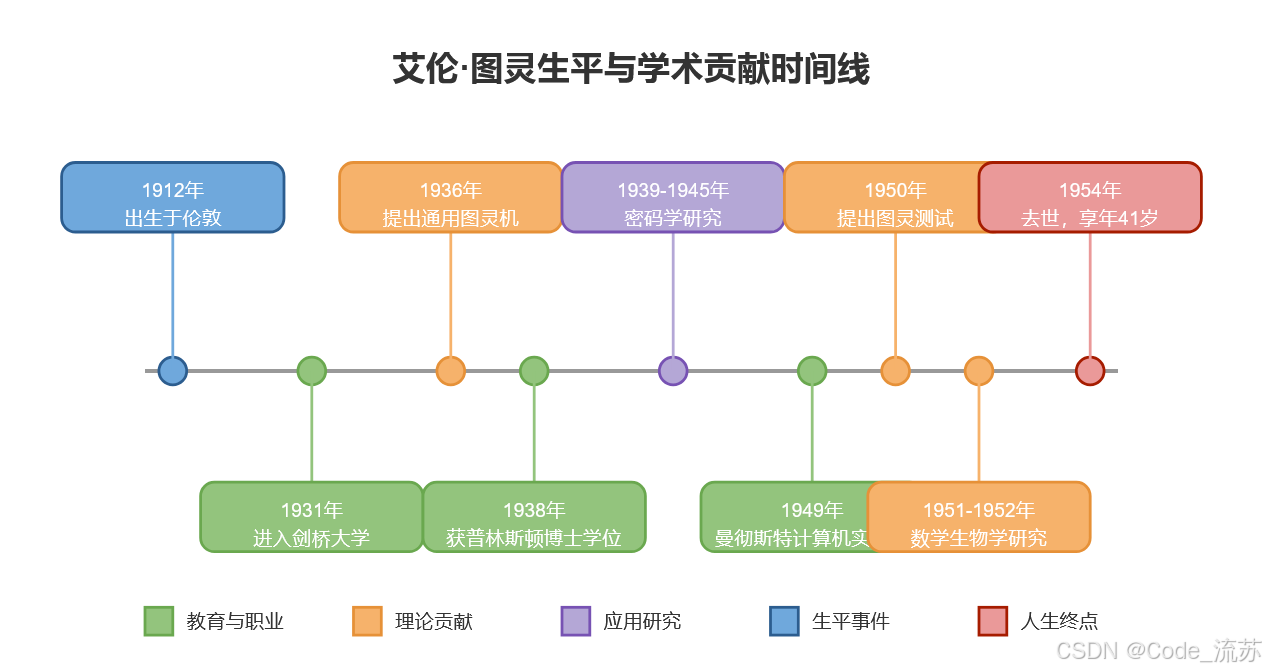
艾伦·图灵:计算机科学与人工智能之父
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 艾伦图灵:计算机科学与人工智能之父 一、天才的诞生与早期生涯 1912年6月…...
策略模式实现 Bean 注入时怎么知道具体注入的是哪个 Bean?
Autowire Resource 的区别 1.来源不同:其中 Autowire 是 Spring2.5 定义的注解,而 Resource 是 Java 定义的注解 2.依赖查找的顺序不同: 依赖注入的功能,是通过先在 Spring IoC 容器中查找对象,再将对象注入引入到当…...
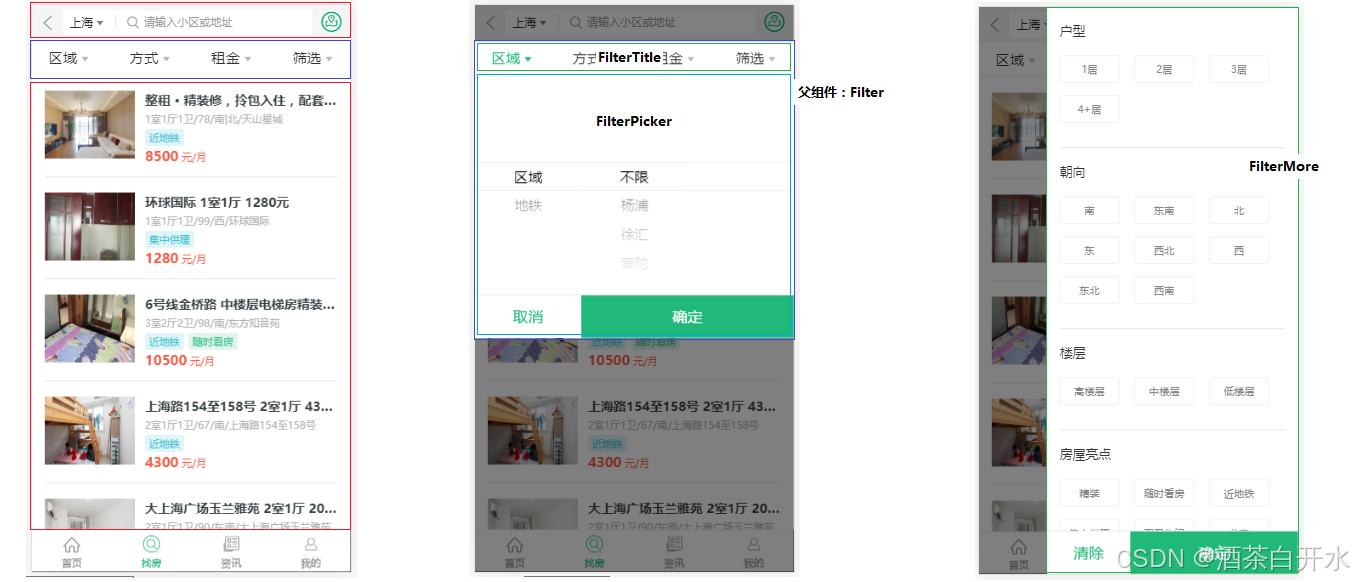
React九案例中
代码下载 地图找房模块 顶部导航栏 封装NavHeader组件实现城市选择,地图找房页面的复用,在 components 目录中创建组件 NavHeader,把之前城市列表写过的样式复制到 NavHeader.scss 下,在该组件中封装 antd-mobile 组件库中的 N…...

第一期:[特殊字符] 深入理解MyBatis[特殊字符]从JDBC到MyBatis——持久层开发的转折点[特殊字符]
前言 🌟 在软件开发的过程中,持久层(或数据访问层)是与数据库进行交互的关键部分。早期,开发者通常使用 JDBC(Java Database Connectivity)来实现与数据库的连接与操作。虽然 JDBC 在一定程度上…...
Adobe Photoshop 2025 Mac中文 Ps图像编辑
Adobe Photoshop 2025 Mac中文 Ps图像编辑 一、介绍 Adobe Photoshop 2025 Mac版集成了多种强大的图像编辑、处理和创作功能。①强化了Adobe Sensei AI的应用,通过智能抠图、自动修复、图像生成等功能,用户能够快速而精确地编辑图像。②3D编辑和动画功…...

用纯Qt实现GB28181协议/实时视频/云台控制/预置位/录像回放和下载/事件订阅/语音对讲
一、前言 在技术的长河中探索,有些目标一旦确立,便如同璀璨星辰,指引着我们不断前行。早在2014年,我心中就种下了用纯Qt实现GB28181协议的种子,如今回首,一晃十年已逝,好在整体框架和逻辑终于打…...

让你方便快捷实现主题色切换(useCssVar)
文章目录 前言一、useCssVar是什么?二、使用步骤1.安装依赖2.实现主题色切换 总结 前言 使用 CSS 变量(CSS Custom Properties)实现主题色切换是一种高效且易于维护的方法。通过将主题颜色定义为 CSS 变量,你可以轻松地在不同主题…...
面试之《websocket》
配置环境 mkdir express cd express npm init npm install express ws// index.js var app require("express")(); var WebSocket require("ws");var wss new WebSocket.Server({ port: 8888 });wss.on(connection, function connection(ws) {ws.on(m…...

Linux 内存调优之系统内存全面监控
写在前面 博文内容涉及 Linux 全局内存监控监控方式包括传统工具 vmstat/top/free/sar/slabtop ,以及 systemd-cgtop,proc 内存伪文件系统监控内容包括进程内存使用情况, 内存全局数据统计,内存事件指标,以及进程内存段数据监控理解不足小伙伴帮忙指正 😃,生活加油我看远…...
:cat)
每天学一个 Linux 命令(14):cat
Linux 文件查看与合并命令:cat cat(全称 concatenate)是 Linux 中用于查看文件内容、合并文件或创建简单文件的基础命令。它操作简单但功能灵活,是日常文件处理的常用工具。 1. 命令作用 查看文件内容:直接输出文件内容到终端。合并文件:将多个文件内容合并输出或保存到…...
L36.【LeetCode题解】查找总价格为目标值的两个商品(剑指offer:和为s的两个数字) (双指针思想,内含详细的优化过程)
目录 1.LeetCode题目 2.分析 方法1:暴力枚举(未优化的双指针) 方法2:双指针优化:利用有序数组的单调性 版本1代码 提问:版本1代码有可以优化的空间吗? 版本2代码 提问:版本2代码有可以优化的空间吗? 版本3代码(★推荐★) 3.牛客网题目:和为s的数字 1.LeetCode题目 …...

英语学习4.9
cordial 形容词: 热情友好的,诚恳的 表示一个人态度温和、亲切,给人温暖和善的感觉。 令人愉快的,和睦的 形容关系融洽、氛围和谐。 例句: The two leaders had a cordial but formal discussion. &am…...

HBuilderX 开发的uniapp项目在微信开发者工具中调试运行
HBuilderX 开发的uniapp项目在微信开发者工具中调试运行 或者运行失败 https://blog.csdn.net/m0_74141658/article/details/129541365?fromshareblogdetail&sharetypeblogdetail&sharerId129541365&sharereferPC&sharesourceweixin_48616345&sharefromf…...

【特权FPGA】之乘法器
完整代码如下: timescale 1ns / 1ps// Company: // Engineer: // // Create Date: 23:08:36 04/21/08 // Design Name: // Module Name: mux_16bit // Project Name: // Target Device: // Tool versions: // Description: // // Dependencies: …...
MyBatis-Plus 核心功能
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、条件构造器1、核心 Wrapper 类型基础查询示例SQL 查询使用 QueryWrapper 实现查询 更新操作示例场景一:基础更新SQL 查询使用 QueryWrapper 实现更新…...

前端工程化-包管理NPM-package.json 和 package-lock.json 详解
package.json 和 package-lock.json 详解 1.package.json 基本概念 package.json 是 Node.js 项目的核心配置文件,它定义了项目的基本信息、依赖项、脚本命令等。 主要字段 基本信息字段 name: 项目名称(必填) version: 项目版本…...
Day22 -php开发01--留言板+知识点(超全局变量 文件包含 数据库操作 第三方插件)
环境要求:php7.0.9 小皮 navicat phpstorm24.1 知识点:会写(留言板 留言板后台) 超全局变量 三方插件的使用 文件包含 1、开启小皮并利用navicat新建一个数据库 注意:本地的服务mysql关闭后 才可打开小皮。属…...
Java工具类-assert断言
我们可能经常在项目的单元测试或者一些源码中看到别人在使用assert关键字,当然也不只是Java语言,很多编程语言也都能看到,我们大概知道断言可以用于测试中条件的校验,但却不经常使用,本文总结了Java中该工具类的使用。…...

A2A协议分析报告
A2A协议分析报告 一、引言 在人工智能快速发展的背景下,智能体(Agent)技术逐步成为企业数字化转型的关键支撑。为了打破不同智能体之间协作壁垒,提升多模态协同效率,Google 于2025年推出了“Agent-to-Agentÿ…...
人工智能、机器学习与深度学习-AI基础Day2
核心概念与技术全景解析 近年来,人工智能(AI)技术飞速发展,逐渐渗透到生活的方方面面。然而,对于许多人来说,AI、机器学习(ML)、深度学习(DL)以及生成式人工…...

GGML源码逐行调试(上)
目录 前言1. 简述2. 环境配置3. ggml核心概念3.1 gguf3.2 ggml_tensor3.3 ggml_backend_buffer3.4 ggml_context3.5 backend3.6 ggml_cgraph3.7 ggml_gallocr 4. 推理流程整体梳理4.1 时间初始化与参数设置4.2 模型加载与词汇表构建4.3 计算图与内存分配4.4 文本预处理与推理过…...
SpringCloud-OpenFeign
前言 1.存在问题 远程调用可以像Autowired一样吗 服务之间的通信⽅式,通常有两种:RPC和HTTP. 在SpringCloud中,默认是使⽤HTTP来进⾏微服务的通信,最常⽤的实现形式有两种: RestTemplate OpenFeign RPC(RemoteProcedureCall)远程过程调⽤&…...
撰写学位论文Word图表目录的自动生成
第一步:为图片和表格添加题注 选中图片或表格 右键点击需要编号的图片或表格,选择 【插入题注】(或通过菜单栏 引用 → 插入题注)。 设置题注标签 在弹窗中选择 标签(如默认有“图”“表”,若无需自定义标…...
Web 项目实战:构建属于自己的博客系统
目录 项目效果演示 代码 Gitee 地址 1. 准备工作 1.1 建表 1.2 引入 MyBatis-plus 依赖 1.3 配置数据库连接 1.4 项目架构 2. 实体类准备 - pojo 包 2.1 dataobject 包 2.2 request 包 2.3 response 包 2.3.1 统一响应结果类 - Result 2.3.2 用户登录响应类 2.3.3…...

分库分表设计与Java实践:从理论到实现
在分布式系统和高并发场景下,单一数据库的性能瓶颈逐渐显现,分库分表成为提升数据库扩展性和性能的重要手段。作为Java开发者,掌握分库分表的设计原则和实现方法,不仅能应对海量数据和高并发的挑战,还能优化系统架构的…...

P8667 [蓝桥杯 2018 省 B] 递增三元组
P8667 [蓝桥杯 2018 省 B] 递增三元组 题目描述 给定三个整数数组 A [ A 1 , A 2 , ⋯ , A N ] A [A_1, A_2,\cdots, A_N] A[A1,A2,⋯,AN], B [ B 1 , B 2 , ⋯ , B N ] B [B_1, B_2,\cdots, B_N] B[B1,B2,⋯,BN], C [ C 1 , C 2 , …...
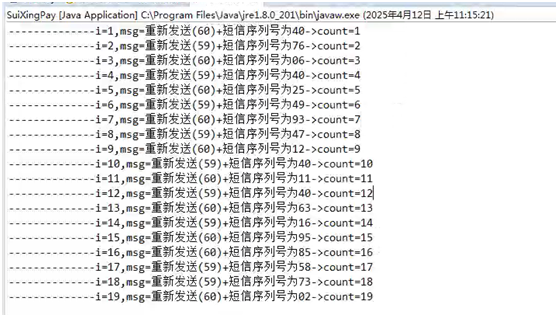
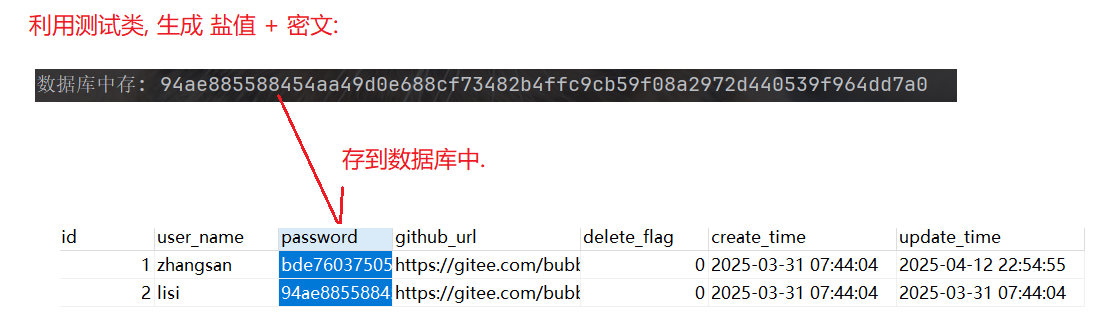
【随行付-注册安全分析报告-无验证方式导致隐患】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 1. 暴力破解密码,造成用户信息泄露 2. 短信盗刷的安全问题,影响业务及导致用户投诉 3. 带来经济损失,尤其是后付费客户,风险巨大,造…...