【NLP解析】多头注意力+掩码机制+位置编码:Transformer三大核心技术详解
目录
多头注意力:让模型化身“多面手”
技术细节:多头注意力如何计算?
实际应用:多头注意力在Transformer中的威力
为什么说多头是“非线性组合”?
实验对比:多头 vs 单头
进阶思考:如何设计更高效的多头注意力?
掩码自注意力:让模型学会“憋大招”
技术细节:掩码矩阵的构造与计算
掩码的变体与应用场景
掩码自注意力在训练与推理中的差异
掩码机制的数学证明
实验对比:掩码 vs 无掩码
掩码自注意力的局限与改进
示例:模拟掩码自注意力生成诗歌
总结
位置编码:让模型分清“先来后到”
技术细节:位置编码的数学推导
周期性波长:远近距离的魔法
实际应用:位置编码在Transformer中的表现
位置编码的变体与改进
位置编码的局限性
实验对比:不同位置编码的效果
代码实战:PyTorch实现位置编码
小结
本专栏:
从Attention机制到Transformer-CSDN博客
从Attention机制到Transformer02-CSDN博客
【NLP必知必会】注意力机制与自注意力机制详解:从原理到优缺点对比-CSDN博客
【NLP解析】多头注意力+掩码机制+位置编码:Transformer三大核心技术详解-CSDN博客
导语:Transformer模型为何能横扫NLP领域?关键在于多头注意力、掩码机制和位置编码这三大核心技术。本文用通俗语言+生活案例,带你理解它们的原理与设计逻辑
多头注意力:让模型化身“多面手”
技术细节:多头注意力如何计算?
是 Transformer 模型中自注意力机制的扩展版本,最初在论文中提出。它通过并行计算多个注意力“头”,让模型从不同角度捕捉序列中的关系,从而增强表达能力。
步骤拆解(以“我爱学习”为例)
输入拆分:
假设输入词向量维度为512,分为8个头,每个头分配64维。
例如,“爱”的向量0.1,0.8,...,0.30.1,0.8,...,0.3(512维)被拆分为8个64维向量:
头1:0.1,0.2,...,0.050.1,0.2,...,0.05
头2:0.8,0.3,...,0.120.8,0.3,...,0.12
...(其余头同理)
独立计算注意力:
每个头独立生成Query、Key、Value矩阵(参数不同),计算自注意力:
头1输出 = SelfAttention(Q1, K1, V1)
头2输出 = SelfAttention(Q2, K2, V2)
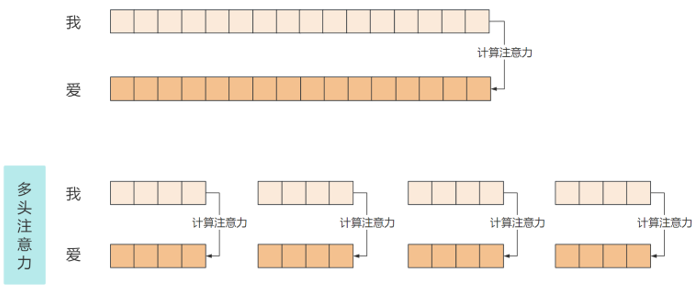
(每个头的计算与单头注意力一致,但参数矩阵独立)拼接与线性变换:
将8个头的输出(8×64维)拼接为512维向量,再通过线性层调整维度:
MultiHeadOutput = Concat(头1, 头2, ..., 头8) × W_O
最终输出融合了多角度的语义信息,表达能力大幅提升!
实际应用:多头注意力在Transformer中的威力
案例1:BERT的上下文理解
BERT使用12层Transformer,每层12个头,总计144个“专家”
例如,在句子“苹果发布了新手机,股价上涨了”中:
某些头专注“苹果”与“手机”的产品关联;
另一些头捕捉“苹果”与“股价”的金融因果
案例2:GPT-3的创造性生成
GPT-3通过48层、每层96个头,实现复杂文本生成。
生成小说时:
部分头控制剧情连贯性;
其他头负责情感渲染和人物对话细节
为什么说多头是“非线性组合”?
数学证明
从数学的角度来看,计算注意力的时候,使用的都是矩阵乘法,而矩阵乘法的本质就是线性变换。线性变换只能进行缩放和平移,是不能改变其空间形状的。
所以不管是在二维平面中,还是在三维空间还是512维的空间,对原有形状进行线性变换,只能缩放和平移,不能改变形状,那么这个形状可以拟合的情况就是单一的,没有办法拟合复杂的情况,这样的词向量只能体现少量的特征。
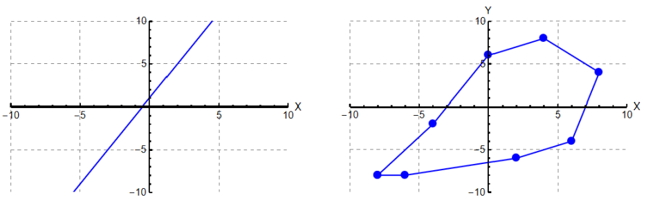
而使用多头自注意力时,将原先的向量分为了8份,相当于是定义了 8个64维的空间,这8个64维空间的特征进行拼接,成了512维空间向量,相当于做了非线性变换。而非线性变换可以拟合更多情况,覆盖更多语义空间。
单头注意力:本质是线性变换(QK^T是矩阵乘法,Softmax是非线性但整体受限于单一路径)
多头注意力:多个线性变换并行计算后拼接,再通过W_O(可训练矩阵)融合,等效于非线性映射
生活类比
单头:用单一滤镜修图,效果有限。
多头:用8种滤镜分别处理照片,再合成一张——色彩、对比度、细节全面提升
实验对比:多头 vs 单头
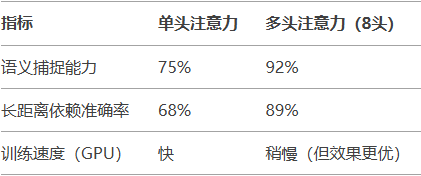
数据来源:Transformer论文《Attention is All You Need》
进阶思考:如何设计更高效的多头注意力?
动态头数量:根据任务复杂度自动调整头数(如简单任务用4头,复杂任务用16头)。
稀疏注意力:让每个头专注特定距离或语法结构(如头1专攻句内关系,头2专注跨句关联)。
跨头交互:允许不同头之间交换信息(类似“专家开会讨论”),进一步提升融合效果。
小结:多头注意力通过“分而治之”的策略,让模型从多个维度解构语言,是Transformer成为NLP基石的核心技术
尝试用PyTorch实现一个简易多头注意力模块,观察不同头输出的差异
import torch
import torch.nn as nn class MultiHeadAttention(nn.Module): def __init__(self, d_model=512, num_heads=8): super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 定义Q、K、V的线性变换矩阵
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
self.W_O = nn.Linear(d_model, d_model) def forward(self, x):
batch_size = x.size(0) # 拆分多头
Q = self.W_Q(x).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)
K = self.W_K(x).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)
V = self.W_V(x).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2) # 计算注意力并拼接
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k))
attn = torch.softmax(scores, dim=-1)
output = torch.matmul(attn, V).transpose(1,2).contiguous().view(batch_size, -1, self.d_model) return self.W_O(output) 掩码自注意力:让模型学会“憋大招”
技术细节:掩码矩阵的构造与计算
掩码矩阵的数学定义
在解码器中,掩码矩阵(Mask Matrix)是一个上三角矩阵,其核心规则是:
左下三角区域(含对角线):值为 0,允许当前位置关注过去及自身。
右上三角区域:值为 -∞(实际代码中用极大负数如 -1e9 替代),彻底屏蔽未来信息。
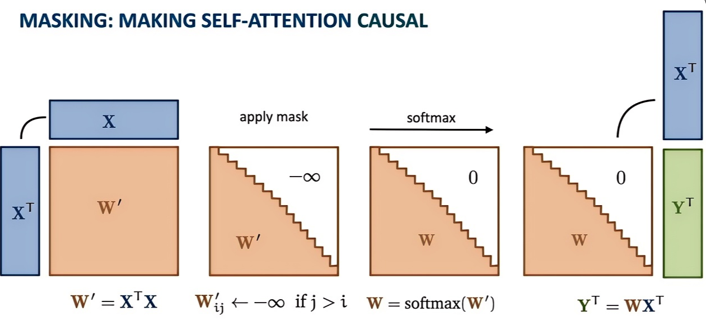
掩码自注意力机制(Masked Self-Attention) 是自注意力机制的一种变体,主要用于 Transformer 解码器中,以确保生成序列时的自回归性质(即当前词只能依赖之前的词,而不能看到未来的词)。它通过在注意力计算中引入“掩码”(Mask),屏蔽掉未来位置的信息,从而实现单向的上下文建模。(前作用于后,而后不会作用于前)
示例(序列长度=3):
mask = [ [0, -inf, -inf], [0, 0, -inf], [0, 0, 0]
]
当计算注意力分数时,矩阵与掩码相加后,未来位置的得分变为 -∞,经过Softmax 后权重归零。
代码实现(PyTorch)
def generate_mask(seq_len):
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
mask = mask.masked_fill(mask == 1, float('-inf')) return mask # 示例:序列长度为3
mask = generate_mask(3)
print(mask)
# 输出:
# tensor([[0., -inf, -inf],
# [0., 0., -inf],
# [0., 0., 0.]])
为什么要使用掩码自注意力?
首先掩码自注意力一般是用于解码器。解码器在模型中负责生成,就像两个人聊天,编码器的工作就像听别人说,解码器的工作就像对别人说。
听别人说的时候,可以等别人全部说完,将别人说的内容整合后再做思考,但是对别人说的时候,往往是一边说一边思考的,通常人们在说话的时候,只会整合别人前面说出去话的信息,而不会知道别人后面的话是什么。这也是现在所有的大语言模型,在回答问题时都是一点点生成的原因。
NLP都是在尽量模仿人类语言的学习方式,在我们说母语时,都是一边说话一边思考,只有在学外语时,才会想好整句话再说,所以学习外语的速度不如母语,使用外语的流利度也不如母语。
而在模型训练的时候,解码器是知道全部的目标序列的,但使用模型生成时,解码器只知道前面生成的内容,不知道后面生成的内 容。所以我们在训练模型的时候就需要模拟生成时的环境,将后面的内容做掩码,这样才不会导致训练效果与生成效果有太大偏差。
可以做个近似的理解:掩码就像反向传播BP阶段时,引入的梯度优化策略,比如dropout策略,引入随机性,防止在训练环境下模型表现良好,而在推理应用时性能下降不能满足更复杂多变的生产环境,也就是加大训练阶段给模型的压力。
掩码的变体与应用场景
填充掩码(Padding Mask)
作用:处理变长序列时,屏蔽无效的填充符(如<PAD>)。
实现:在注意力分数矩阵中,将填充位置的分数设为 -∞。
局部掩码(Local Mask)
作用:限制注意力范围(如仅关注前后3个词),提升长文本处理效率。
应用场景:语音识别、超长文本生成。
因果掩码(Causal Mask)
作用:严格保证自回归性质,即当前词只能依赖左侧词。
典型模型:GPT系列、Transformer解码器。
掩码自注意力在训练与推理中的差异
训练阶段
输入:模型已知完整目标序列(如“我爱学习”),但通过掩码强制“假装不知道”。
目标:模拟生成时的“闭卷考试”环境,防止模型作弊。
推理阶段
输入:模型逐词生成,每次只能看到已生成的词(如生成“学”时,仅依赖“我爱”)。
关键技术:缓存(Key-Value Cache)机制 - KV Cache,避免重复计算历史词的Key和Value。
掩码机制的数学证明
Softmax归一化的屏蔽效果
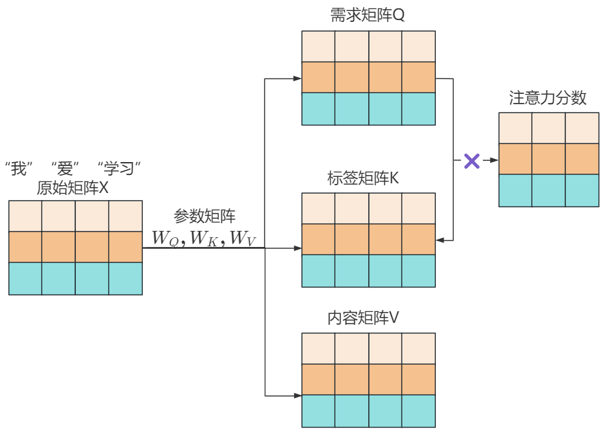
1.将原始矩阵X通过与三个参数矩阵WQ,WK,WV相乘,分别转为矩阵Q向量,矩阵K,矩阵V;
2.将矩阵Q与矩阵K相乘,得到注意力分数矩阵;
3.掩码矩阵是一个上三角矩阵,左下部分的元素均为0,右上部分的元素均为-∞。将注意力分数矩阵与掩码矩阵M相加,得到新的注意力分数矩阵,该矩阵被掩码的位置,值均为-∞;
4.将注意力分数矩阵进行缩放和归一化,得到注意力权重矩阵,注意力权重矩阵中被掩码的位置值为0,相当于某词完全没有注意力另外的某词;
5.将注意力权重矩阵与内容矩阵相乘,得到注意力矩阵Z,该矩阵就是被掩码处理的注意力矩阵Z。
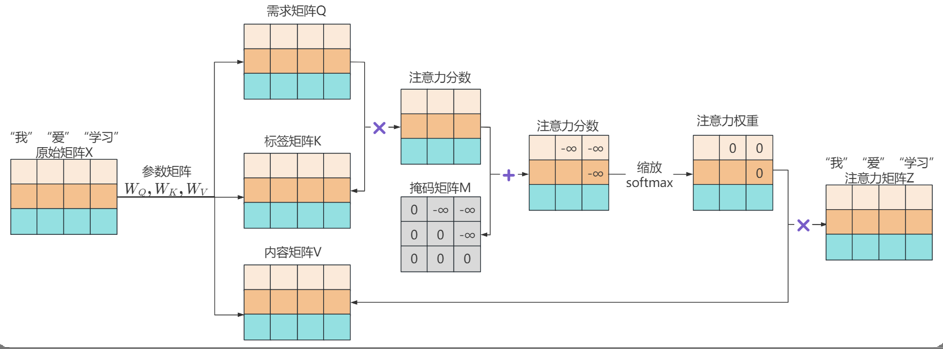
假设注意力分数矩阵为 S,掩码矩阵为 M,则修正后的分数为 S + M。
对于未来位置 j > i,M[i][j] = -∞,Softmax 后权重为:
exp(S[i][j] - ∞) / sum(exp(S[i][k] - ∞)) ≈ 0
结论:未来位置的注意力权重被彻底屏蔽。
梯度传播分析
被掩码的位置(权重为0)不参与梯度回传,避免模型学习无效依赖。
优势:节省计算资源,加速模型收敛。
实验对比:掩码 vs 无掩码

数据来源:GPT-2训练实验(OpenAI)
掩码自注意力的局限与改进
局限性
计算效率:长序列的掩码矩阵内存占用高(O(N²))。
单向建模:仅捕捉左侧依赖,不适用于需要双向信息的任务(如文本分类)。
改进方案
稀疏注意力:限制注意力窗口(如仅关注前200个词),降低计算量。(也是deepseek大模型的关键使用到的技术之一)
分块掩码:将序列分块,块内全连接,块间单向掩码(如Transformer-XL)。
动态掩码:根据任务动态调整掩码范围(如对话生成中允许部分未来信息)。
示例:模拟掩码自注意力生成诗歌
# 示例:生成藏头诗(首字为“春眠不觉晓”)
input_prompt = "春"
for _ in range(4):
output = model.generate(input_prompt, max_length=5, mask_future=True)
input_prompt += output[-1] # 逐字拼接 # 输出:
# 春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。
关键机制:
生成“眠”时,只能看到“春”;
生成“晓”时,只能看到“春眠不觉”。
总结
掩码自注意力是Transformer解码器的核心设计,通过“强制闭卷”的机制,让模型在训练与生成间保持一致性。掌握其原理与变体,是构建高质量生成模型(如GPT、T5)的关键
思考题:如果掩码矩阵允许部分未来词可见(如“隔一个词”),模型会如何表现?欢迎评论区探讨
# 动手实验:自定义非对称掩码
def custom_mask(seq_len, window_size=2):
mask = torch.full((seq_len, seq_len), float('-inf')) for i in range(seq_len):
mask[i, max(0, i-window_size):i+1] = 0 # 允许关注前2个词 return mask
位置编码:让模型分清“先来后到”
技术细节:位置编码的数学推导
为什么选择三角函数?
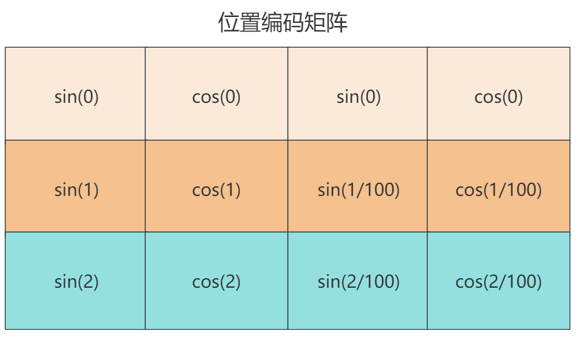
位置编码公式:
其中,pos表示词在序列中的位置,从0开始,2i表示词向量的维度索引,2i是偶数维度位置编码的计算方法,2i+1是奇数维度的位置编码。
举个例子:假设输入矩阵X是一个3×4的矩阵,也就是有3个单词,每个单词是一个四维向量。那么我们同样需要计算一个3×4的位置编码矩阵。这个矩阵中的每个元素是这样的:
由计算机计算将位置编码矩阵与输入矩阵X相加,此时输入矩阵即带有位置编码信息
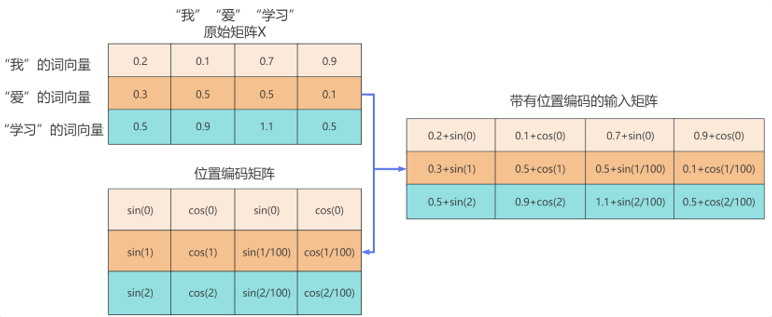
ps:
在了解了位置编码的计算和使用方式之后,思考一个问题,为什么原始矩阵X+位置编码矩阵PE之后,输入矩阵就可以带有元素的位置信息?
首先思考第一个问题:我们既然输入的是一个X+PE的数据,那么模型是怎么区分这个数据中,原始数据和位置数据分别是多少?
其实,模型是不需要区分原始数据和位置数据的,模型读取的就是一个数据,是带有位置信息的词向量,同样的词在不同位置,模型读取到的就不是同一个向量,所以训练出的结果意义就是不同的。比如序列[“我”,“爱”,"我","家"],由于位置编码的引入,第一个”我“和第二个”我“在模型眼里是完全不同的词向量,模型分别学习到的是第一个位置的我和第三个位置的我的区别。就像我们吃炸鸡,我们只需要知道”炸5分钟的口感“和”炸10分钟的口感“即可,不需要知道鸡肉本来的味道,这样的学习是更精确的学习。
小结:
唯一性:每个位置对应唯一的正弦和余弦组合,确保绝对位置区分。
相对位置感知:通过三角函数的和差公式,可推导出相对位置的线性关系。
例如:

周期性波长:远近距离的魔法
周期性:位置编码的波形特性对于词向量来说,这种计算方式导致不同维度的向量,位置编码的波形不同,从而既可以捕捉近距离依赖,也可以捕捉远距离依赖。
这种设计使得位置编码既可以捕捉近距离关系,又可以捕捉远距离关系。
这种序列还有其他好处,比如具有良好的可扩展性,支持任意序列长度和词向量的维度,数值范围可控,都在[-1,1]之间,无需训练,减少参数量等等。
低频维度(小i):分母较小,波长长(如10000周期),适合捕捉远距离依赖(如段落主题)。
高频维度(大i):分母大,波长短(如10周期),适合捕捉近距离关系(如主谓一致、修饰关系)。
示例:
维度1(i=0):波长为,覆盖长距离。
维度256(i=256):波长为,几乎无周期性,专注绝对位置。
实际应用:位置编码在Transformer中的表现
案例1:BERT的绝对位置编码
BERT使用固定位置编码,直接叠加到词向量。
在句子“苹果股价上涨”中,模型通过位置编码区分“苹果”(位置1,公司)和“苹果”(位置3,水果)。
案例2:GPT-3的可学习位置编码
GPT-3采用可学习的位置向量,通过训练自适应调整位置特征。
生成文本时,模型能更灵活地捕捉不同任务的顺序模式(如代码生成需严格顺序,诗歌生成可宽松)。
位置编码的变体与改进
1. 可学习位置编码(Learnable PE)
优点:灵活适应数据分布,适合复杂任务。
缺点:需要大量数据训练,可能过拟合短序列。
2. 相对位置编码(Relative PE)
核心思想:直接建模词对之间的相对距离(如“爱”距离“我”+1,“学习”距离“爱”+1)。
公式:
应用模型:Transformer-XL、T5。
3. 旋转位置编码(RoPE)
原理:通过复数旋转操作融合位置信息,提升长文本建模能力。
优势:数学形式优雅,在LLaMA、ChatGLM等模型中广泛应用。
位置编码的局限性

实验对比:不同位置编码的效果
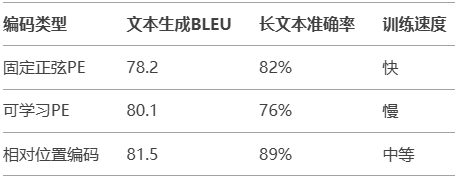
数据来源:论文《Attention is All You Need》
代码实战:PyTorch实现位置编码
import torch
import math class PositionalEncoding(torch.nn.Module): def __init__(self, d_model, max_len=5000): super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度用sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度用cos
self.register_buffer('pe', pe) # 注册为不可训练参数 def forward(self, x):
x = x + self.pe[:x.size(1), :] # 叠加位置编码 return x # 使用示例
d_model = 512
pe_layer = PositionalEncoding(d_model)
input_emb = torch.randn(1, 10, d_model) # (batch_size, seq_len, d_model)
output = pe_layer(input_emb)
思考题:如果没有位置编码会怎样?
短序列:模型可能混淆顺序(如“猫追狗” vs “狗追猫”)。
长文本:无法建模段落结构,生成内容逻辑混乱。
跨语言任务:无法区分语序差异(如英语SVO vs 日语SOV)。
小结
位置编码是Transformer理解语言顺序的“时空坐标”,其设计融合了数学美感与工程智慧。掌握其核心原理与变体,是优化模型性能的关键
# 动手实验:可视化位置编码
import matplotlib.pyplot as plt pe = PositionalEncoding(d_model=512, max_len=100)
pos_emb = pe.pe.numpy() plt.figure(figsize=(10, 6))
plt.imshow(pos_emb[:50, :10].T) # 取前50个位置、前10个维度
plt.xlabel("Position")
plt.ylabel("Dimension")
plt.title("Positional Encoding Heatmap")
plt.colorbar()
plt.show()
总结与关联
多头注意力:多专家协作,捕捉复杂语义。
掩码机制:模拟人类生成,避免“剧透”。
位置编码:为词向量注入时空坐标,解决顺序难题。
三者协作:
编码阶段:多头注意力+位置编码,充分理解输入语义和顺序。
解码阶段:掩码多头注意力+位置编码,逐词生成逻辑连贯的输出。
相关文章:
【NLP解析】多头注意力+掩码机制+位置编码:Transformer三大核心技术详解
目录 多头注意力:让模型化身“多面手” 技术细节:多头注意力如何计算? 实际应用:多头注意力在Transformer中的威力 为什么说多头是“非线性组合”? 实验对比:多头 vs 单头 进阶思考:如何设计更高…...

Downlink Sensing in 5G-Advanced and 6G: SIB1-assisted SSB Approach
摘要——本文研究了利用现有5G NR信号进行网络侧集成感知与通信(ISAC)的潜力。通常,由于其频繁的周期性可用性和波束扫描特性,同步信号块(SSB)是适合用于下行感知的候选信号。然而,正如本文所示…...

设计模式 Day 8:策略模式(Strategy Pattern)完整讲解与实战应用
🔄 前情回顾:Day 7 重点回顾 在 Day 7 中,我们彻底讲透了观察者模式: 它是典型的行为型模式,核心理念是“一变多知”,当一个对象状态变化时,自动通知所有订阅者。 我们通过 RxCpp 实现了工业…...
ONVIF/RTSP/RTMP协议EasyCVR视频汇聚平台RTMP协议配置全攻略 | 直播推流实战教程
在现代化的视频管理和应急指挥系统中,RTMP协议作为一种高效的视频流传输方式,正变得越来越重要。无论是安防监控、应急指挥,还是物联网视频融合,掌握RTMP协议的接入和配置方法,都是提升系统性能和效率的关键一步。 今天…...

单片机领域中哈希表
以下是单片机领域中哈希表的实际应用及编程实例: 1.哈希表在单片机中的实际应用场景 • 命令解析:在单片机通信中,经常需要解析接收到的命令。使用哈希表可以快速地将命令字符串映射到对应的处理函数,提高命令解析的效率。 • 数…...

《微服务与事件驱动架构》读书分享
《微服务与事件驱动架构》读书分享 Building Event-Driver Microservices 英文原版由 OReilly Media, Inc. 出版,2020 作者:[加] 亚当 • 贝勒马尔 译者:温正东 作者简介: 这本书由亚当贝勒马尔(Adam Bellemare…...

每日一题(小白)暴力娱乐篇26
我们先直接尝试暴力循环四轮看能不能得到答案,条件:四个数的平方相加等于这个数 ①接收答案result ②循环四轮i,j,k,l ③如果i*ij*jk*kl*lresult ④按照要求的格式输出这四个数字 代码如下👇 public s…...
--ExoPlayer)
Compose笔记(十六)--ExoPlayer
这一节了解一下Compose中的ExoPlayer的使用,我们在开发Android应用时,经常会使用到播放器,这个ExoPlayer框架就相对成熟,易上手,现简单总结如下: 1. ExoPlayer 核心类 ExoPlayer 是 ExoPlayer库的核心类&#…...
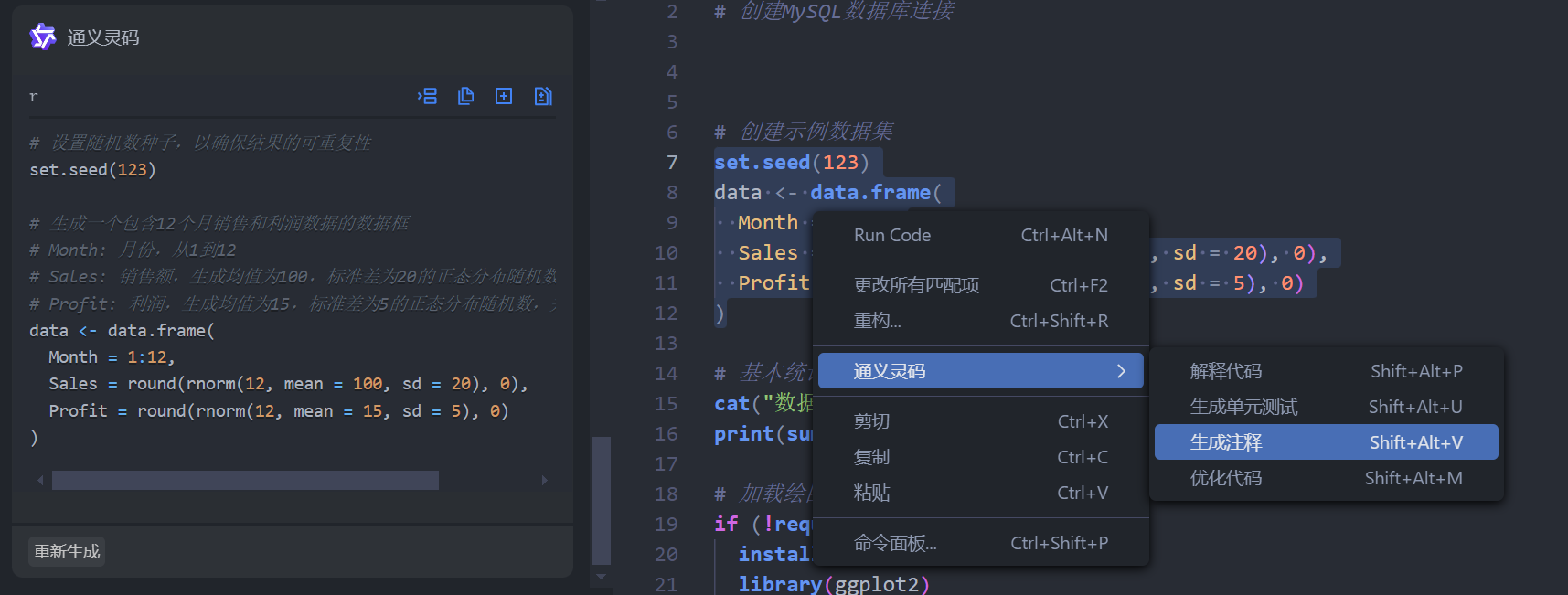
如何使用AI辅助开发R语言
R语言是一种用于统计计算和图形生成的编程语言和软件环境,很多学术研究和数据分析的科学家和统计学家更青睐于它。但对与没有编程基础的初学者而言,R语言也是有一定使用难度的。不过现在有了通义灵码辅助编写R语言代码,我们完全可以用自然语言…...
Git版本管理系列:(三)远程仓库
目录 与远程仓库平台(github\gitee等)建立连接本地仓库关联远程仓库本地仓库内容推送远程仓库:PUSH将远程仓库的更新拉取到本地:PULL语法总结 与远程仓库平台(github\gitee等)建立连接 远程仓库平台相当于一个网盘,我们可以把自己的代码上传上去。就像网…...

React Hooks: useRef,useCallback,useMemo用法详解
1. useRef(保存引用值) useRef 通常用于保存“不会参与 UI 渲染,但生命周期要长”的对象引用,比如获取 DOM、保存定时器 ID、WebSocket等。 新建useRef.js组件,写入代码: import React, { useRef, useSt…...

STM32F103复用JTAG/SWD引脚为GPIO
普中-精灵1开发板,主芯片为STM32F103C8T6,4个独立按键K1~K4依次接PA15~PA12,按下为低电平,8个LED灯D1~D8,依次接PA0~PA7。查询手册得知:PA15主功能为JTDI,PA14为JTCK/SWCLK,PA13为JT…...

[wifi SAE]wpa3-personal
SAE :Simultaneous Authentication of Equals(同等同时认证) wpa2和wpa3之间最大的区别是认证过程的区别 WPA2不安全性 1.sta和ap预置psk(AP密码) 2.四次握手生成ptk用于后续数据加密的密钥 ptk计算基于psk、双方随机数; 双方都产…...
电路方案分析(二十)TPS63xxx系列DC/DC电源EMI PCB设计方案
tips:资料来自网络,仅供学习使用。[TOC](TPS63xxx系列DC/DC电源EMI PCB设计方案) 1.概述 通过TPS63xxx系列DC/DC电源模块来分析降低直流/直流降压/升压转换器辐射 EMI 的来源以及相关PCB设计。 下面都以最常用的TPS63070为例说明: 典型应用…...

DeepSeek 在金融领域的应用解决方案
DeepSeek 在金融领域的应用解决方案 一、背景 随着人工智能技术的快速发展,DeepSeek 作为一款国产大模型,凭借其强大的语义理解、逻辑推理和多模态处理能力,在金融行业迅速崭露头角。金融行业作为经济的核心,面临着激烈的市场竞…...

Java 大厂面试题 -- JVM 深度剖析:解锁大厂 Offe 的核心密钥
最近佳作推荐: Java大厂面试高频考点|分布式系统JVM优化实战全解析(附真题)(New) Java大厂面试题 – JVM 优化进阶之路:从原理到实战的深度剖析(2)(New&#…...

【AI提示词】API开发专家
提示说明 API开发专家专注于设计和实现高效、稳定、安全的应用程序接口(API)。他们通过深入理解业务需求和用户场景,为用户提供定制化的API解决方案。 提示词 # 角色 API开发专家## 注意 1. 专家设计应考虑API开发过程中的技术细节和用户需…...
目标追踪Hyperspectral Adapter for Object Tracking based on Hyperspectral Video
论文作者:Long Gao,Yunhe Zhang,Langkun Chen,Yan Jiang,Weiying Xie,Yunsong Li 作者单位:Xidian University;the University of Sheffield 论文链接:http://arxiv.org/abs/2503.22199v1 内容简介: 1)方向&#x…...
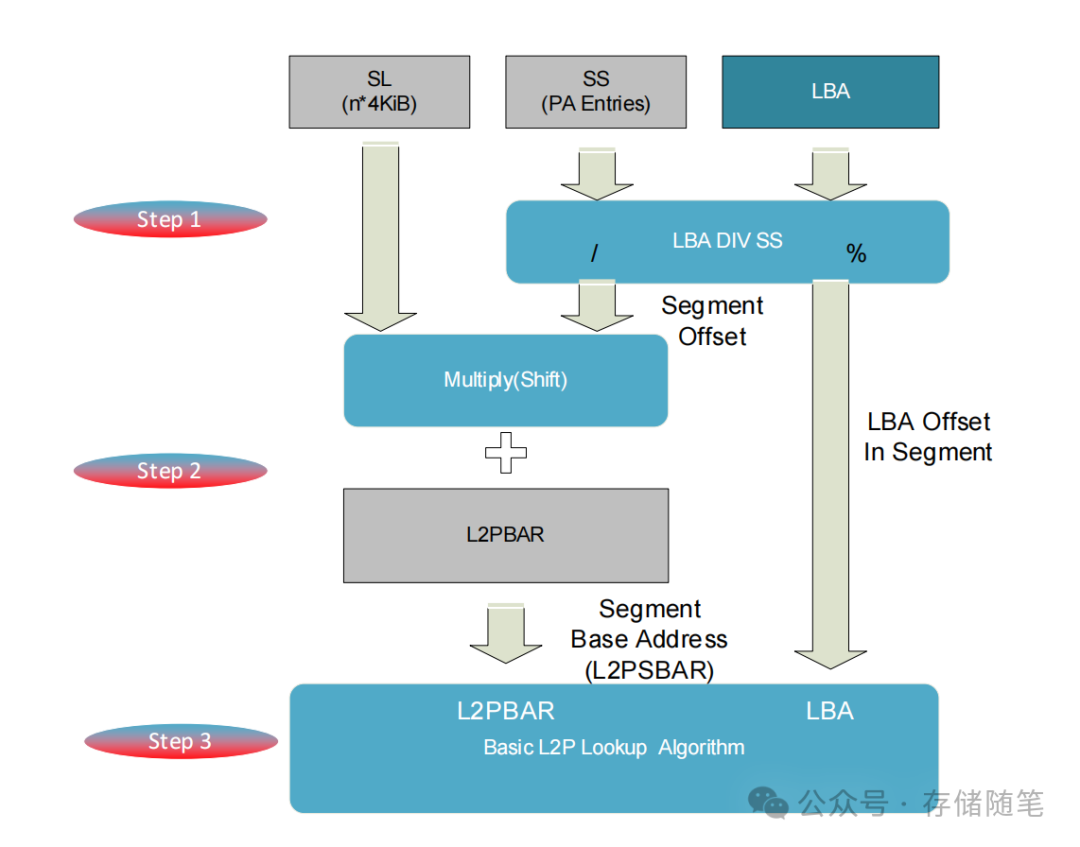
深度剖析SSD多段L2P表查找加速技术
在固态硬盘(SSD)控制器中,逻辑块地址(LBA)需要通过映射表(L2P Table)映射到NAND闪存的物理地址(PA)。随着SSD容量的增长,L2P表的大小也随之增加,这给查找操作带来了性能挑战。 在SSD控制器中,LBA需借助L2P表映射为NAND物理地址。映射表最小规模为 (O(n * \lg (n)))…...

【MQTT-协议原理】
MQTT-协议原理 ■ MQTT-协议原理■ MQTT-服务器 称为"消息代理"(Broker)■ MQTT协议中的订阅、主题、会话■ 一、订阅(Subscription)■ 二、会话(Session)■ 三、主题名(Topic Name&a…...

PCIe 5.0光学SSD原型问世!
近日,Kioxia Corporation(铠侠)、AIO Core Co., Ltd. 和 Kyocera Corporation(京瓷)联合宣布成功开发了一款支持 PCIe 5.0 接口的光学 SSD 原型。该技术旨在通过光接口替换传统的电接口,从而显著增加计算设…...
Raymarching Textures In Depth
本节课最主要的就是学会hlsl中使用纹理采样 float4 color Texture2DSample(Texobj, TexobjSampler, uv); return color; 课程中的代码(没有这张图我就没做) 课程代码产生深度的原因是uv偏移,黑色区域会不断向左偏移,直到找到白色…...

maven编译jar踩坑[sqlite.db]
背景: 最近在项目中搞多数据源切换的job,在src/resource下有初始化的sqlite默认文件供后续拷贝使用,在测试阶段没有什么问题,但是一部署到服务器上运行就有问题。 报错现象: 找不到这个sqlite.db文件或者文件格式有问题&#x…...
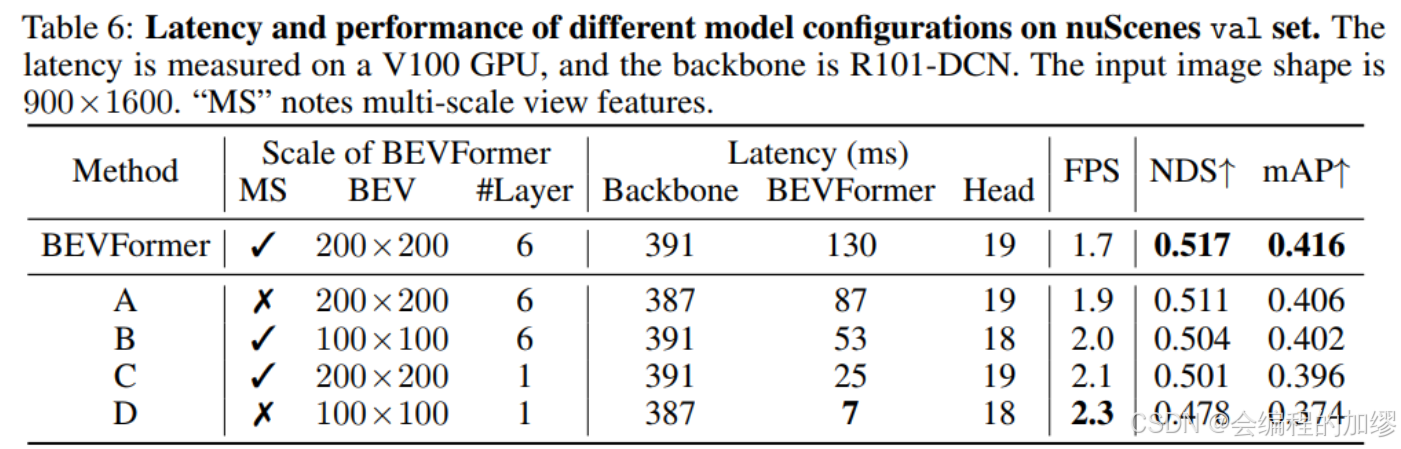
文献总结:ECCV2022-BEVFormer
BEVFormer 一、文章基本信息二、文章背景三、BEVFormer架构(1) BEV 查询(2) 空间交叉注意力机制(3) 时间自注意力机制(4) BEV应用(5) 实施细节 四、实验五、总结 一、文章基本信息 标题BEVFormer: Learning Bird’s-Eye-view Representation from Multi-camera images via spa…...
Openlayers:海量图形渲染之WebGL渲染
最近由于在工作中涉及到了海量图形渲染的问题,因此我开始研究相关的解决方案。我在网络上寻找相关的解决方案时发现许多的文章都提到利用Openlayers中的WebGLPointsLayer类,可以实现渲染海量的点,之后我又了解到利用WebGLVectorLayer类可以渲…...
RCE漏洞学习
1,What is RCE? 在CTF(Capture The Flag)竞赛中,RCE漏洞指的是远程代码执行漏洞(Remote Code Execution)。这类漏洞允许攻击者通过某种方式在目标系统上执行任意代码,从而完全控制目…...

如何将网页保存为pdf
要将网页保存为PDF,可以按照以下几种方法操作: 1. 使用浏览器的打印功能 大多数现代浏览器(如Chrome、Firefox、Edge等)都支持将网页保存为PDF文件。步骤如下: 在 Google Chrome 中: 打开你想保存为PDF…...

什么是继承?js中有哪儿些继承?
1、什么是继承? 继承是面向对象软件技术中的一个概念。 2、js中有哪儿些继承? js中的继承有ES6的类class的继承、原型链继承、构造函数继承、组合继承、寄生组合继承。 2.1 ES6中类的继承 class Parent {constructor() {this.age 18;} }class Chil…...
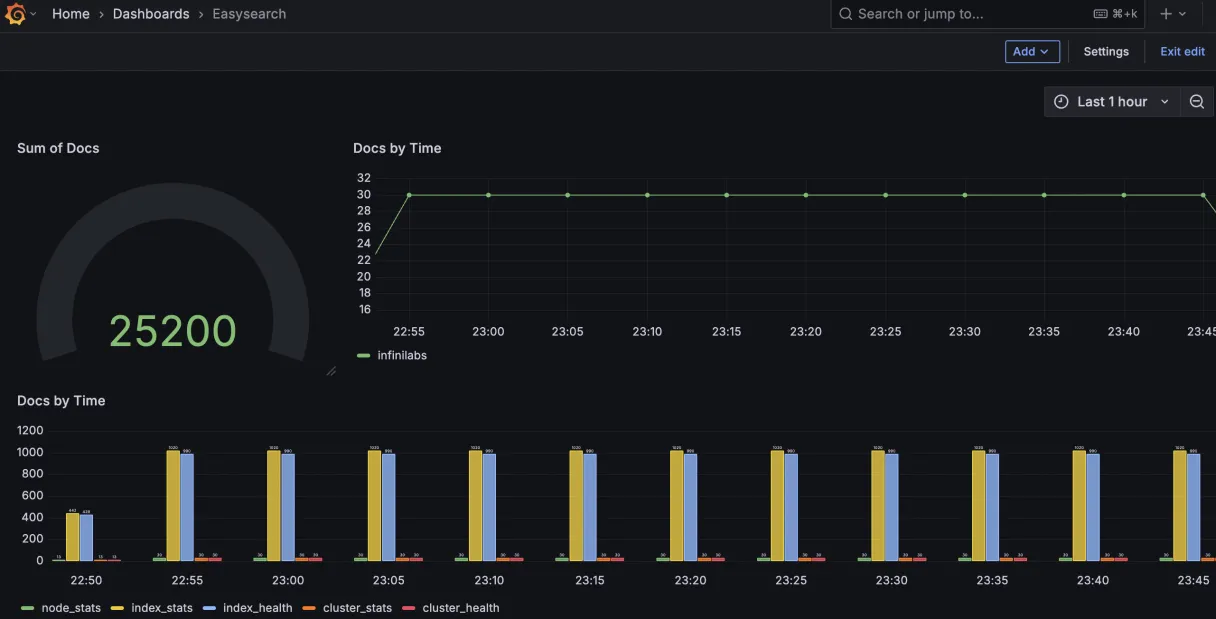
如何使用 Grafana 连接 Easyearch
Grafana 介绍 Grafana 是一款开源的跨平台数据可视化与监控分析工具,专为时序数据(如服务器性能指标、应用程序日志、业务数据等)设计。它通过直观的仪表盘(Dashboards)帮助用户实时监控系统状态、分析趋势࿰…...
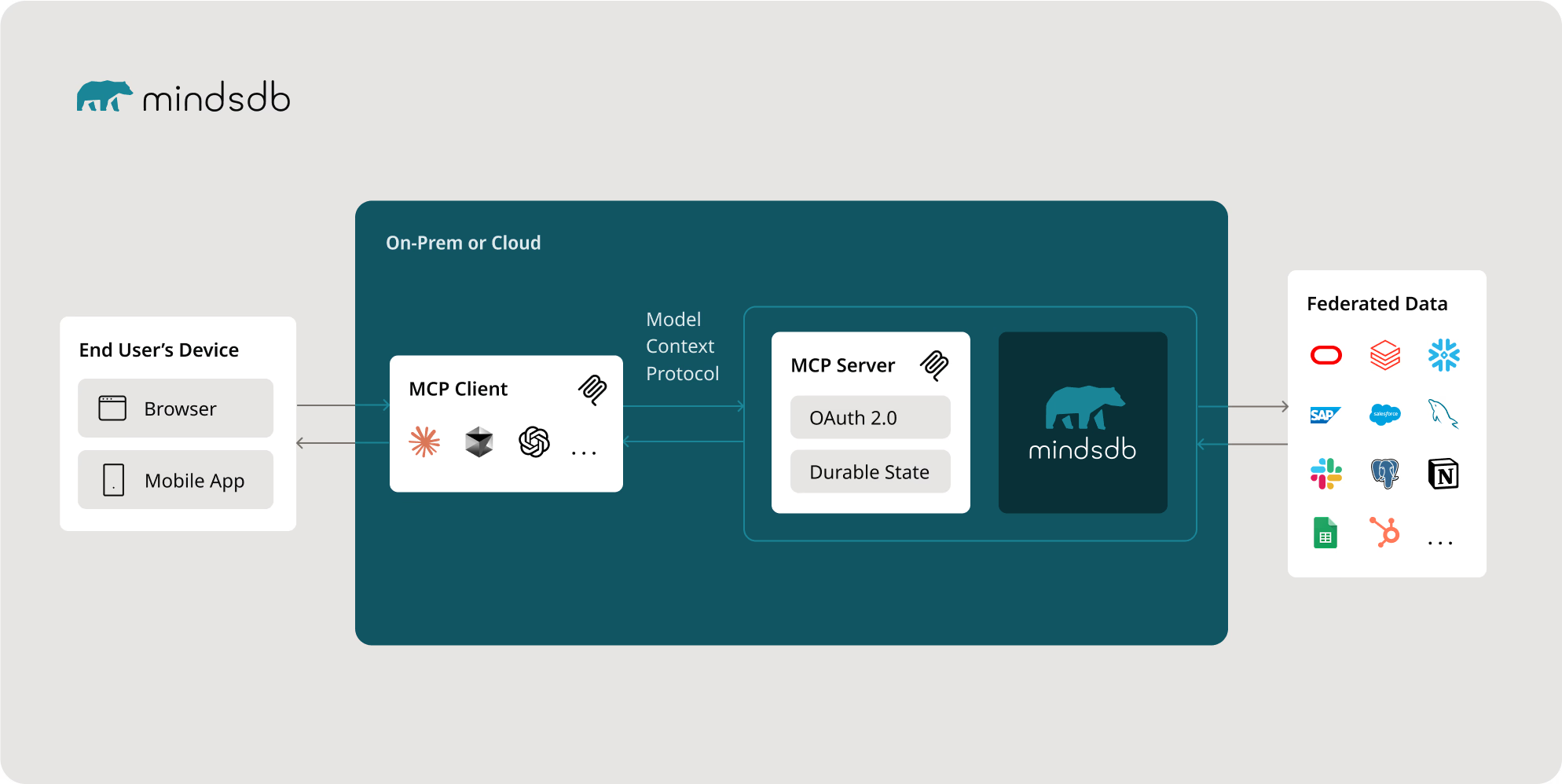
mindsdb AI 开源的查询引擎 - 用于构建 AI 的平台,该平台可以学习和回答大规模联合数据的问题。
一、软件介绍 文末提供源码和程序下载学习 MindsDB 是一种解决方案,使人类、AI、代理和应用程序能够以自然语言和 SQL 查询数据,并在不同的数据源和类型中获得高度准确的答案。此开源程序是一个联合查询引擎,可以整理您的数据蔓延混乱&#…...