python+requests接口自动化测试框架实例教程
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快
前段时间由于公司测试方向的转型,由原来的web页面功能测试转变成接口测试,之前大多都是手工进行,利用postman和jmeter进行的接口测试,后来,组内有人讲原先web自动化的测试框架移驾成接口的自动化框架,使用的是java语言,但对于一个学java,却在学python的我来说,觉得python比起java更简单些,所以,我决定自己写python的接口自动化测试框架,由于本人也是刚学习python,这套自动化框架目前已经基本完成了,于是进行一些总结,便于以后回顾温习,有许多不完善的地方,也遇到了许多的问题,希望大神们多多指教。下面我就进行今天的主要内容吧。
首先,我们先来理一下思路
正常的接口测试流程是什么?
脑海里的反应是不是这样的:
确定测试接口的工具 —> 配置需要的接口参数 —> 进行测试 —> 检查测试结果(有的需要数据库辅助) —> 生成测试报告(html报告)
那么,我们就根据这样的过程来一步步搭建我们的框架。在这个过程中,我们需要做到业务和数据的分离,这样才能灵活,达到我们写框架的目的。只要好好做,一定可以成功。这也是我当初对自己说的。
接下来,我们来进行结构的划分。
我的结构是这样的,大家可以参考下:

common:存放一些共通的方法result:执行过程中生成的文件夹,里面存放每次测试的结果testCase:用于存放具体的测试casetestFile:存放测试过程中用到的文件,包括上传的文件,测试用例以及数据库的sql语句caselist:txt文件,配置每次执行的case名称config:配置一些常量,例如数据库的相关信息,接口的相关信息等readConfig: 用于读取config配置文件中的内容runAll:用于执行case
既然整体结构有了划分,接下来就该一步步的填充整个框架了,首先,我们先来看看config.ini和readConfig.py两个文件,从他们入手,个人觉得比较容易走下去哒。
我们来看下文件的内容是什么样子的:
[DATABASE]
host = 50.23.190.57
username = xxxxxx
password = ******
port = 3306
database = databasename[HTTP]
# 接口的url
baseurl = http://xx.xxxx.xx
port = 8080
timeout = 1.0[EMAIL]
mail_host = smtp.163.com
mail_user = xxx@163.com
mail_pass = *********
mail_port = 25
sender = xxx@163.com
receiver = xxxx@qq.com/xxxx@qq.com
subject = python
content = "All interface test has been complited\nplease read the report file about the detile of result in the attachment."
testuser = Someone
on_off = 1
相信大家都知道这样的配置文件,没错,所有一成不变的东西,我们都可以放到这里来。哈哈,怎么样,不错吧。
现在,我们已经做好了固定的“仓库”。来保存我们平时不动的东西,那么,我们要怎么把它拿出来为我所用呢?这时候,readConfig.py文件出世了,它成功的帮我们解决了这个问题,下面就让我们来一睹它的庐山真面目吧。
import os
import codecs
import configparserproDir = os.path.split(os.path.realpath(__file__))[0]
configPath = os.path.join(proDir, "config.ini")class ReadConfig:def __init__(self):fd = open(configPath)data = fd.read()# remove BOMif data[:3] == codecs.BOM_UTF8:data = data[3:]file = codecs.open(configPath, "w")file.write(data)file.close()fd.close()self.cf = configparser.ConfigParser()self.cf.read(configPath)def get_email(self, name):value = self.cf.get("EMAIL", name)return valuedef get_http(self, name):value = self.cf.get("HTTP", name)return valuedef get_db(self, name):value = self.cf.get("DATABASE", name)return value
怎么样,是不是看着很简单啊,我们定义的方法,根据名称取对应的值,是不是so easy?!当然了,这里我们只用到了get方法,还有其他的例如set方法,有兴趣的同学可以自己去探索下
话不多说,我们先来看下common到底有哪些东西。

既然配置文件和读取配置文件我们都已经完成了,也看到了common里的内容,接下来就可以写common里的共通方法了,从哪个下手呢?今天,我们就来翻“Log.py”的牌吧,因为它是比较独立的,我们单独跟他打交道,也为了以后它能为我们服务打下良好基础。
这里呢,我想跟大家多说两句,对于这个log文件呢,我给它单独启用了一个线程,这样在整个运行过程中,我们在写log的时候也会比较方便,看名字大家也知道了,这里就是我们对输出的日志的所有操作了,主要是对输出格式的规定,输出等级的定义以及其他一些输出的定义等等。总之,你想对log做的任何事情,都可以放到这里来。我们来看下代码,没有比这个更直接有效的了。
import logging
from datetime import datetime
import threading
首先,我们要像上面那样,引入需要的模块,才能进行接下来的操作。
class Log:def __init__(self):global logPath, resultPath, proDirproDir = readConfig.proDirresultPath = os.path.join(proDir, "result")# create result file if it doesn't existif not os.path.exists(resultPath):os.mkdir(resultPath)# defined test result file name by localtimelogPath = os.path.join(resultPath, str(datetime.now().strftime("%Y%m%d%H%M%S")))# create test result file if it doesn't existif not os.path.exists(logPath):os.mkdir(logPath)# defined loggerself.logger = logging.getLogger()# defined log levelself.logger.setLevel(logging.INFO)# defined handlerhandler = logging.FileHandler(os.path.join(logPath, "output.log"))# defined formatterformatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')# defined formatterhandler.setFormatter(formatter)# add handlerself.logger.addHandler(handler)
现在,我们创建了上面的Log类,在__init__初始化方法中,我们进行了log的相关初始化操作。具体的操作内容,注释已经写得很清楚了(英文有点儿差,大家看得懂就行,嘿嘿……),这样,log的基本格式已经定义完成了,至于其他的方法,就靠大家自己发挥了,毕竟每个人的需求也不同,我们就只写普遍的共用方法啦。接下来,就是把它放进一个线程内了,请看下面的代码:
class MyLog:log = Nonemutex = threading.Lock()def __init__(self):pass@staticmethoddef get_log():if MyLog.log is None:MyLog.mutex.acquire()MyLog.log = Log()MyLog.mutex.release()return MyLog.log
看起来是不是没有想象中的那样复杂啊,哈哈哈,就是这样简单,python比java简单了许多,这也是我为什么选择它的原因,虽然小编我也是刚刚学习,还有很多不懂的地方。
好了,至此log的内容也结束了,是不是感觉自己棒棒哒~其实,无论什么时候,都不要感到害怕,要相信“世上无难事只怕有心人”。
下面,我们继续搭建,这次要做的,是configHttp.py的内容。没错,我们开始配置接口文件啦!(终于写到接口了,是不是很开心啊~)
下面是接口文件中主要部分的内容,让我们一起来看看吧。
import requests
import readConfig as readConfig
from common.Log import MyLog as LoglocalReadConfig = readConfig.ReadConfig()class ConfigHttp:def __init__(self):global host, port, timeouthost = localReadConfig.get_http("baseurl")port = localReadConfig.get_http("port")timeout = localReadConfig.get_http("timeout")self.log = Log.get_log()self.logger = self.log.get_logger()self.headers = {}self.params = {}self.data = {}self.url = Noneself.files = {}def set_url(self, url):self.url = host + urldef set_headers(self, header):self.headers = headerdef set_params(self, param):self.params = paramdef set_data(self, data):self.data = datadef set_files(self, file):self.files = file# defined http get methoddef get(self):try:response = requests.get(self.url, params=self.params, headers=self.headers, timeout=float(timeout))# response.raise_for_status()return responseexcept TimeoutError:self.logger.error("Time out!")return None# defined http post methoddef post(self):try:response = requests.post(self.url, headers=self.headers, data=self.data, files=self.files, timeout=float(timeout))# response.raise_for_status()return responseexcept TimeoutError:self.logger.error("Time out!")return None
这里我们就挑重点来说吧。首先,可以看到,小编这次是用python自带的requests来进行接口测试的,相信有心的朋友已经看出来了,python+requests这个模式是很好用的,它已经帮我们封装好了测试接口的方法,用起来很方便。这里呢,我就拿get和post两个方法来说吧。(平时用的最多的就是这两个方法了,其他方法,大家可以仿照着自行扩展)
get方法
接口测试中见到最多的就是get方法和post方法,其中,get方法用于获取接口的测试,说白了,就是说,使用get的接口,都不会对后台数据进行更改,而且get方法在传递参数后,url的格式是这样的:
http://接口地址?key1=value1&key2=value2
对于requests提供的get方法,有几个常用的参数:
url:显而易见,就是接口的地址url啦
headers:定制请求头(headers),例如:content-type = application/x-www-form-urlencoded
params:用于传递测试接口所要用的参数,这里我们用python中的字典形式(key:value)进行参数的传递。
timeout:设置接口连接的最大时间(超过该时间会抛出超时错误)
现在,各个参数我们已经知道是什么意思了,剩下的就是往里面填值啦,是不是机械式的应用啊,哈哈,小编我就是这样机械般的学习的啦~
举个栗子:
url=‘http://api.shein.com/v2/member/logout’
header={‘content-type’:application/x-www-form-urlencoded}
param={‘user_id’: 123456,‘email’: 123456@163.com}
timeout=0.5
requests.get(url, headers=header, params=param, timeout=timeout)
post方法
与get方法类似,只要设置好对应的参数,就可以了。下面就直接举个栗子,直接上代码吧:
url=‘http://api.shein.com/v2/member/login’
header={‘content-type’:application/x-www-form-urlencoded}
data={‘email’: 123456@163.com,‘password’: 123456}
timeout=0.5
requests.post(url, headers=header, data=data, timeout=timeout)
怎么样,是不是也很简单啊。这里我们需要说明一下,post方法中的参数,我们不在使用params进行传递,而是改用data进行传递了。哈哈哈,终于说完啦,下面我们来探(了)讨(解)下接口的返回值。
依然只说常用的返回值的操作。
text:获取接口返回值的文本格式
json():获取接口返回值的json()格式
status_code:返回状态码(成功为:200)
headers:返回完整的请求头信息(headers['name']:返回指定的headers内容)
encoding:返回字符编码格式
url:返回接口的完整url地址
以上这些,就是常用的方法啦,大家可自行取之。
关于失败请求抛出异常,我们可以使用“raise_for_status()”来完成,那么,当我们的请求发生错误时,就会抛出异常。在这里提醒下各位朋友,如果你的接口,在地址不正确的时候,会有相应的错误提示(有时也需要进行测试),这时,千万不能使用这个方法来抛出错误,因为python自己在链接接口时就已经把错误抛出,那么,后面你将无法测试期望的内容。而且程序会直接在这里当掉,以错误来计。(别问我怎么知道的,因为我就是测试的时候发现的)
好了,快,我想学(看)习(看)common.py里的内容。
import os
from xlrd import open_workbook
from xml.etree import ElementTree as ElementTree
from common.Log import MyLog as LoglocalConfigHttp = configHttp.ConfigHttp()
log = Log.get_log()
logger = log.get_logger()# 从excel文件中读取测试用例
def get_xls(xls_name, sheet_name):cls = []# get xls file's pathxlsPath = os.path.join(proDir, "testFile", xls_name)# open xls filefile = open_workbook(xlsPath)# get sheet by namesheet = file.sheet_by_name(sheet_name)# get one sheet's rowsnrows = sheet.nrowsfor i in range(nrows):if sheet.row_values(i)[0] != u'case_name':cls.append(sheet.row_values(i))return cls# 从xml文件中读取sql语句
database = {}
def set_xml():if len(database) == 0:sql_path = os.path.join(proDir, "testFile", "SQL.xml")tree = ElementTree.parse(sql_path)for db in tree.findall("database"):db_name = db.get("name")# print(db_name)table = {}for tb in db.getchildren():table_name = tb.get("name")# print(table_name)sql = {}for data in tb.getchildren():sql_id = data.get("id")# print(sql_id)sql[sql_id] = data.texttable[table_name] = sqldatabase[db_name] = tabledef get_xml_dict(database_name, table_name):set_xml()database_dict = database.get(database_name).get(table_name)return database_dictdef get_sql(database_name, table_name, sql_id):db = get_xml_dict(database_name, table_name)sql = db.get(sql_id)return sql
上面就是我们common的两大主要内容了,什么?还不知道是什么吗?让我告诉你吧。
-
我们利用xml.etree.Element来对xml文件进行操作,然后通过我们自定义的方法,根据传递不同的参数取得不(想)同(要)的值。
-
利用xlrd来操作excel文件,注意啦,我们是用excel文件来管理测试用例的。
听起来会不会有点儿懵,小编刚学时也很懵,看文件就好理解了。
excel文件:

xml文件:

至于具体的方法,我就不再一点点讲解了
接下来,我们看看数据库和发送邮件吧(也可根据需要,不写该部分内容)
先看老朋友“数据库”吧。
小编这次使用的是MySQL数据库,所以我们就以它为例吧。
import pymysql
import readConfig as readConfig
from common.Log import MyLog as LoglocalReadConfig = readConfig.ReadConfig()class MyDB:global host, username, password, port, database, confighost = localReadConfig.get_db("host")username = localReadConfig.get_db("username")password = localReadConfig.get_db("password")port = localReadConfig.get_db("port")database = localReadConfig.get_db("database")config = {'host': str(host),'user': username,'passwd': password,'port': int(port),'db': database}def __init__(self):self.log = Log.get_log()self.logger = self.log.get_logger()self.db = Noneself.cursor = Nonedef connectDB(self):try:# connect to DBself.db = pymysql.connect(**config)# create cursorself.cursor = self.db.cursor()print("Connect DB successfully!")except ConnectionError as ex:self.logger.error(str(ex))def executeSQL(self, sql, params):self.connectDB()# executing sqlself.cursor.execute(sql, params)# executing by committing to DBself.db.commit()return self.cursordef get_all(self, cursor):value = cursor.fetchall()return valuedef get_one(self, cursor):value = cursor.fetchone()return valuedef closeDB(self):self.db.close()print("Database closed!")
这就是完整的数据库的文件啦。因为小编的需求对数据库的操作不是很复杂,所以这些已基本满足要求啦。注意下啦,在此之前,请朋友们先把pymysql装起来!pymysql装起来!pymysql装起来!(重要的事情说三遍),安装的方法很简单,由于小编是使用pip来管理python包安装的,所以只要进入python安装路径下的pip文件夹下,执行以下命令即可:
pip install pymysql
哈哈哈,这样我们就可以利用python链接数据库啦~
小伙伴们发现没,在整个文件中,我们并没有出现具体的变量值哦,为什么呢?没错,因为前面我们写了config.ini文件,所有的数据库配置信息都在这个文件内哦,是不是感觉很方便呢,以后就算变更数据库了,也只要修改config.ini文件的内容就可以了,结合前面测试用例的管理(excel文件),sql语句的存放(xml文件),还有接下来我们要说的,businessCommon.py和存放具体case的文件夹,那么我们就已经将数据和业务分开啦,哈哈哈,想想以后修改测试用例内容,sql语句神马的工作,再也不用每个case都修改,只要改几个固定的文件,是不是顿时开心了呢?
回归上面的configDB.py文件,内容很简单,相信大家都能看得懂,就是连接数据库,执行sql,获取结果,最后关闭数据库,没有什么不一样的地方。
该谈谈邮件啦,你是不是也遇到过这样的问题:每次测试完之后,都需要给开发一份测试报告。那么,对于我这样的懒人,是不愿意老是找人家开发的,所以,我就想,每次测试完,我们可以让程序自己给开发人员发一封email,告诉他们,测试已经结束了,并且把测试报告以附件的形式,通过email发送给开发者的邮箱,这样岂不是爽哉!
所以,configEmail.py应运而生。当当当当……请看:
import os
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from datetime import datetime
import threading
import readConfig as readConfig
from common.Log import MyLog
import zipfile
import globlocalReadConfig = readConfig.ReadConfig()class Email:def __init__(self):global host, user, password, port, sender, title, contenthost = localReadConfig.get_email("mail_host")user = localReadConfig.get_email("mail_user")password = localReadConfig.get_email("mail_pass")port = localReadConfig.get_email("mail_port")sender = localReadConfig.get_email("sender")title = localReadConfig.get_email("subject")content = localReadConfig.get_email("content")self.value = localReadConfig.get_email("receiver")self.receiver = []# get receiver listfor n in str(self.value).split("/"):self.receiver.append(n)# defined email subjectdate = datetime.now().strftime("%Y-%m-%d %H:%M:%S")self.subject = title + " " + dateself.log = MyLog.get_log()self.logger = self.log.get_logger()self.msg = MIMEMultipart('mixed')def config_header(self):self.msg['subject'] = self.subjectself.msg['from'] = senderself.msg['to'] = ";".join(self.receiver)def config_content(self):content_plain = MIMEText(content, 'plain', 'utf-8')self.msg.attach(content_plain)def config_file(self):# if the file content is not null, then config the email fileif self.check_file():reportpath = self.log.get_result_path()zippath = os.path.join(readConfig.proDir, "result", "test.zip")# zip filefiles = glob.glob(reportpath + '\*')f = zipfile.ZipFile(zippath, 'w', zipfile.ZIP_DEFLATED)for file in files:f.write(file)f.close()reportfile = open(zippath, 'rb').read()filehtml = MIMEText(reportfile, 'base64', 'utf-8')filehtml['Content-Type'] = 'application/octet-stream'filehtml['Content-Disposition'] = 'attachment; filename="test.zip"'self.msg.attach(filehtml)def check_file(self):reportpath = self.log.get_report_path()if os.path.isfile(reportpath) and not os.stat(reportpath) == 0:return Trueelse:return Falsedef send_email(self):self.config_header()self.config_content()self.config_file()try:smtp = smtplib.SMTP()smtp.connect(host)smtp.login(user, password)smtp.sendmail(sender, self.receiver, self.msg.as_string())smtp.quit()self.logger.info("The test report has send to developer by email.")except Exception as ex:self.logger.error(str(ex))class MyEmail:email = Nonemutex = threading.Lock()def __init__(self):pass@staticmethoddef get_email():if MyEmail.email is None:MyEmail.mutex.acquire()MyEmail.email = Email()MyEmail.mutex.release()return MyEmail.emailif __name__ == "__main__":email = MyEmail.get_email()
这里就是完整的文件内容了,不过可惜的是,小编我遇到一个问题
问题:使用163免费邮箱服务器进行邮件的发送,但是,每次发送邮件,都会被163邮件服务器退信,抛出的错误码是:554
官方说明如下:

但是,however,but……小编在整合email进本框架之前写的发送email的小demo是可以正常发送邮件的。这个问题困扰着我,目前仍没有解决。
离成功不远了,什么?想知道生成测试报告的样子?好,这就满足好奇的你:

好了,重头戏来了,就是我们的runAll.py啦。请看主角登场。
这是我们整个框架运行的入口,上面内容完成后,这是最后一步啦,写完它,我们的框架就算是完成了。(鼓掌,撒花~)
import unittest
import HTMLTestRunnerdef set_case_list(self):fb = open(self.caseListFile)for value in fb.readlines():data = str(value)if data != '' and not data.startswith("#"):self.caseList.append(data.replace("\n", ""))fb.close()def set_case_suite(self):self.set_case_list()test_suite = unittest.TestSuite()suite_model = []for case in self.caseList:case_file = os.path.join(readConfig.proDir, "testCase")print(case_file)case_name = case.split("/")[-1]print(case_name+".py")discover = unittest.defaultTestLoader.discover(case_file, pattern=case_name + '.py', top_level_dir=None)suite_model.append(discover)if len(suite_model) > 0:for suite in suite_model:for test_name in suite:test_suite.addTest(test_name)else:return Nonereturn test_suitedef run(self):try:suit = self.set_case_suite()if suit is not None:logger.info("********TEST START********")fp = open(resultPath, 'wb')runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title='Test Report', description='Test Description')runner.run(suit)else:logger.info("Have no case to test.")except Exception as ex:logger.error(str(ex))finally:logger.info("*********TEST END*********")# send test report by emailif int(on_off) == 0:self.email.send_email()elif int(on_off) == 1:logger.info("Doesn't send report email to developer.")else:logger.info("Unknow state.")
上面我贴出了runAll里面的主要部分,首先我们要从caselist.txt文件中读取需要执行的case名称,然后将他们添加到python自带的unittest测试集中,最后执行run()函数,执行测试集。
终于呢,整个接口自动化框架已经讲完了,大家是不是看明白了呢?什么?之前的之前贴出的目录结构中的文件还有没说到的?嘿嘿,,,相信不用小编多说,大家也大概知道了,剩下文件夹的作用了。嗯~思索万千,还是决定简单谈谈吧。直接上图,简单明了:

result文件夹会在首次执行case时生成,并且以后的测试结果都会被保存在该文件夹下,同时每次测试的文件夹都是用系统时间命名,里面包含了两个文件,log文件和测试报告。

testCase文件夹下,存放我们写的具体的测试case啦,上面这些就是小编写的一些。注意喽,所有的case名称都要以test开头来命名哦,这是因为,unittest在进行测试时会自动匹配testCase文件夹下面所有test开头的.py文件

testFile文件夹下,放置我们测试时用来管理测试用例的excel文件和用于数据库查询的sql语句的xml文件哦。
最后就是caselist.txt文件了,就让你们瞄一眼吧:

凡是没有被注释掉的,都是要被执行的case名称啦。在这里写上你要执行的case名称就可以啦。
总结
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。

相关文章:
python+requests接口自动化测试框架实例教程
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 前段时间由于公司测试方向的转型,由原来的web页面功能测试转变成接口测试,之前大多都是手工进行,利用postman和jmeter进行…...
2021第十二届蓝桥杯大赛软件赛省赛C/C++ 大学 B 组
记录刷题的过程、感悟、题解。 希望能帮到,那些与我一同前行的,来自远方的朋友😉 大纲: 1、空间-(题解)-字节单位转换 2、卡片-(题解)-可以不用当组合来写,思维题 3、直…...

spark课后总结
Spark运行架构 : 运行架构 Spark 采用master - slave(主从)结构。Driver 相当于master,负责管理集群中的作业任务调度;Executor 相当于slave,负责实际执行任务 核心组件 Driver:是Spark驱动…...

智能资源管理机制-重传机制
一、发送端资源管理的核心机制 1. 滑动窗口(Sliding Window) 这是TCP协议的核心优化设计: 窗口动态滑动:发送端不需要保留所有已发送的分组,只需维护一个"发送窗口"窗口大小:由接收方通告的接…...

设计模式 --- 原型模式
原型模式是创建型模式的一种,是在一个原型的基础上,建立一致的复制对象的方式。这个原型通常是我们在应用程序生命周期中需要创建多次的一个典型对象。为了避免初始化新对象潜在的性能开销,我们可以使用原型模式来建立一个非常类似于复印机的…...

基于SiamFC的红外目标跟踪
基于SiamFC的红外目标跟踪 1,背景与原理2,SiamFC跟踪方法概述2.1 核心思想2.2 算法优势3,基于SiamFC的红外跟踪代码详解3.1 网络定义与交叉相关模块3.2 SiamFC 跟踪器实现3.3 主程序:利用 OpenCV 实现视频跟踪4,总结与展望在红外监控、无人机防御以及低光照场景中,红外图…...
驱动高中差异化教学策略研究)
多模态学习分析(MLA)驱动高中差异化教学策略研究
一、引言 1.1 研究背景 在当今时代,教育数字化转型的浪潮正席卷全球,深刻地改变着教育的面貌。这一转型不仅是技术的革新,更是教育理念、教学模式和教育管理的全面变革。随着互联网、大数据、人工智能等现代信息技术在教育领域的广泛应用&a…...

设计模式 - 单例
单例设计模式 单例设计模式是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。 在 JavaScript 里,有多种实现单例设计模式的方式,下面为你详细介绍: 1. 简单对象字面量实现 这是…...
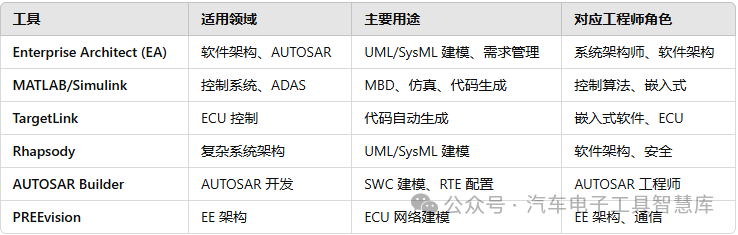
汽车软件开发常用的建模工具汇总
目录 往期推荐 1.Enterprise Architect(EA) 2.MATLAB/Simulink 3.TargetLink 4.Rational Rhapsody 5.AUTOSAR Builder 6.PREEvision 总结 往期推荐 2025汽车行业新宠:欧企都在用的工具软件ETAS工具链自动化实战指南<一&am…...

SSM废品买卖回收管理系统的设计与实现
🍅点赞收藏关注 → 添加文档最下方联系方式咨询本源代码、数据库🍅 本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。🍅关注我不迷路🍅 项目视频 07…...

@SchedulerLock 防止分布式环境下定时任务并发执行
背景 在一个有多个服务实例的分布式系统中,如果你用 Scheduled 来定义定时任务,所有实例都会执行这个任务。ShedLock 的目标是只让一个实例在某一时刻执行这个定时任务。 使用步骤 引入依赖 当前以redisTemplate为例子,MongoDB、Zookeeper…...

实信号的傅里叶变换为何属于埃尔米特函数?从数学原理到 MATLAB 动态演示
引言 在信号处理领域,傅里叶变换是分析信号在频域表现的重要工具。特别是对于实信号,实信号是指在时间或空间域内取值为实数的信号,例如音频信号、温度变化等,它的傅里叶变换展现了一个非常特殊的数学性质——共轭对称性…...
【VitePress】新增md文件后自动更新侧边栏导航
目录 说在前面先看效果代码结构详细说明侧边栏格式utils监听文件变化使用pm2管理监听进程 说在前面 操作系统:windows11node版本:v18.19.0npm版本:10.2.3vitepress版本:1.6.3完整代码:github 先看效果 模板用的就是官…...
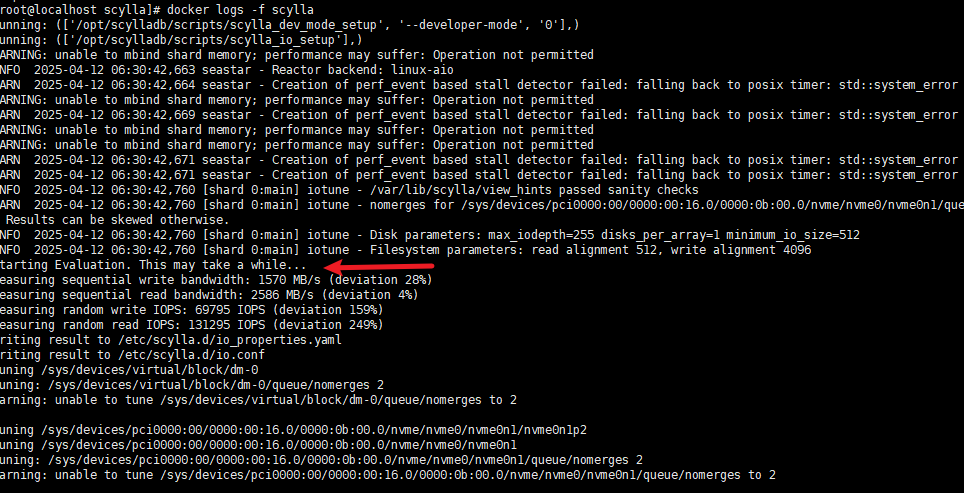
docker部署scylladb
创建存储数据的目录和配置目录 mkdir -p /root/docker/scylla/data/data /root/docker/scylla/data/commitlog /root/docker/scylla/data/hints /root/docker/scylla/data/view_hints /root/docker/scylla/conf快速启动拷贝配置文件 docker run -d \--name scylla \scylladb/…...
Android 16应用适配指南
Android 16版本特性介绍 https://developer.android.com/about/versions/16?hlzh-cn Android 16 所有功能和 API 概览 https://developer.android.com/about/versions/16/features?hlzh-cn#language-switching Android 16 发布时间 Android 16 适配指南 Google开发平台&…...

2.2goweb解析http请求信息
Go语言的net/http包提供了一些列用于表示HTTP报文的解构。我们可以使用它处理请求和发送响应。其中request结构体代表了客户端发生的请求报文。 核心字段获取方法 1. 请求行信息 通过 http.Request 结构体获取: func handler(w http.ResponseWriter, r *http.Req…...

本地部署大模型(ollama模式)
分享记录一下本地部署大模型步骤。 大模型应用部署可以选择 ollama 或者 LM Studio。本文介绍ollama本地部署 ollama官网为:https://ollama.com/ 进入官网,下载ollama。 ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型&…...

KWDB创作者计划—KWDB:国产分布式多模数据库的创新实践
在数字化转型的浪潮中,数据管理技术正经历着前所未有的变革。随着物联网、人工智能等技术的飞速发展,企业面临着海量多源异构数据的管理挑战。KWDB(KaiwuDB Community Edition)作为一款面向AIoT场景的分布式多模数据库,…...
redis之缓存击穿
一、前言 本期我们聊一下缓存击穿,其实缓存击穿和缓存穿透很相似,区别就是,缓存穿透是一些黑客故意请求压根不存在的数据从而达到拖垮系统的目的,是恶意的,有针对性的。缓存击穿的情况是,数据确实存在&…...
txt、Csv、Excel、JSON、SQL文件读取(Python)
txt、Csv、Excel、JSON、SQL文件读取(Python) txt文件读写 创建一个txt文件 fopen(rtext.txt,r,encodingutf-8) sf.read() f.close() print(s)open( )是打开文件的方法 text.txt’文件名 在同一个文件夹下所以可以省略路径 如果不在同一个文件夹下 ‘…...

【学习笔记】两个类之间的数据交互方式
在面向对象编程中,两个类之间的数据交互可以通过以下几种方式实现,具体选择取决于需求和设计模式: 1. 通过方法调用 一个类通过调用另一个类的公共方法来获取或传递数据。这是最常见的方式,符合封装原则。 class ClassA:def __…...
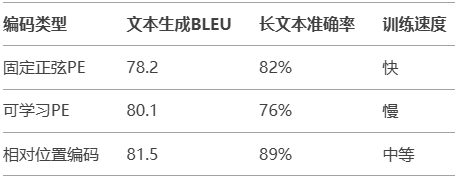
【NLP解析】多头注意力+掩码机制+位置编码:Transformer三大核心技术详解
目录 多头注意力:让模型化身“多面手” 技术细节:多头注意力如何计算? 实际应用:多头注意力在Transformer中的威力 为什么说多头是“非线性组合”? 实验对比:多头 vs 单头 进阶思考:如何设计更高…...

Downlink Sensing in 5G-Advanced and 6G: SIB1-assisted SSB Approach
摘要——本文研究了利用现有5G NR信号进行网络侧集成感知与通信(ISAC)的潜力。通常,由于其频繁的周期性可用性和波束扫描特性,同步信号块(SSB)是适合用于下行感知的候选信号。然而,正如本文所示…...

设计模式 Day 8:策略模式(Strategy Pattern)完整讲解与实战应用
🔄 前情回顾:Day 7 重点回顾 在 Day 7 中,我们彻底讲透了观察者模式: 它是典型的行为型模式,核心理念是“一变多知”,当一个对象状态变化时,自动通知所有订阅者。 我们通过 RxCpp 实现了工业…...
ONVIF/RTSP/RTMP协议EasyCVR视频汇聚平台RTMP协议配置全攻略 | 直播推流实战教程
在现代化的视频管理和应急指挥系统中,RTMP协议作为一种高效的视频流传输方式,正变得越来越重要。无论是安防监控、应急指挥,还是物联网视频融合,掌握RTMP协议的接入和配置方法,都是提升系统性能和效率的关键一步。 今天…...

单片机领域中哈希表
以下是单片机领域中哈希表的实际应用及编程实例: 1.哈希表在单片机中的实际应用场景 • 命令解析:在单片机通信中,经常需要解析接收到的命令。使用哈希表可以快速地将命令字符串映射到对应的处理函数,提高命令解析的效率。 • 数…...

《微服务与事件驱动架构》读书分享
《微服务与事件驱动架构》读书分享 Building Event-Driver Microservices 英文原版由 OReilly Media, Inc. 出版,2020 作者:[加] 亚当 • 贝勒马尔 译者:温正东 作者简介: 这本书由亚当贝勒马尔(Adam Bellemare…...

每日一题(小白)暴力娱乐篇26
我们先直接尝试暴力循环四轮看能不能得到答案,条件:四个数的平方相加等于这个数 ①接收答案result ②循环四轮i,j,k,l ③如果i*ij*jk*kl*lresult ④按照要求的格式输出这四个数字 代码如下👇 public s…...
--ExoPlayer)
Compose笔记(十六)--ExoPlayer
这一节了解一下Compose中的ExoPlayer的使用,我们在开发Android应用时,经常会使用到播放器,这个ExoPlayer框架就相对成熟,易上手,现简单总结如下: 1. ExoPlayer 核心类 ExoPlayer 是 ExoPlayer库的核心类&#…...
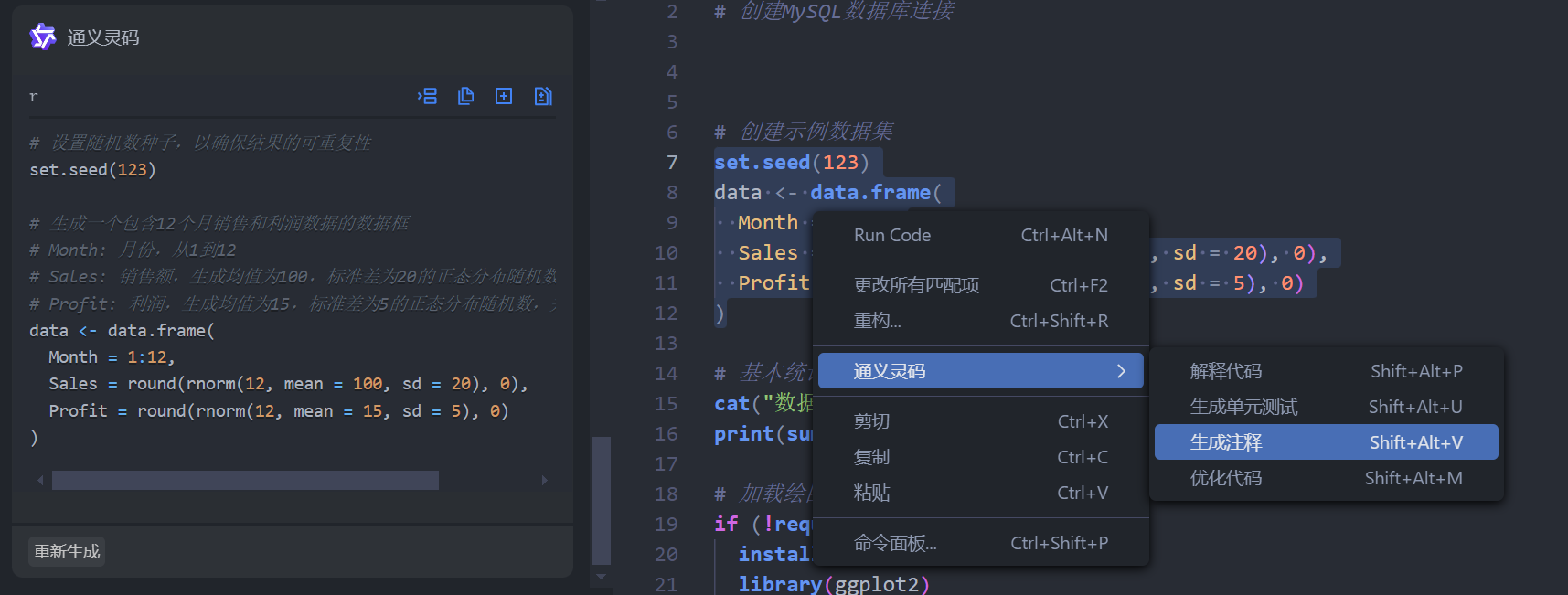
如何使用AI辅助开发R语言
R语言是一种用于统计计算和图形生成的编程语言和软件环境,很多学术研究和数据分析的科学家和统计学家更青睐于它。但对与没有编程基础的初学者而言,R语言也是有一定使用难度的。不过现在有了通义灵码辅助编写R语言代码,我们完全可以用自然语言…...