解决 Elasticsearch 分页查询性能瓶颈——从10分钟到秒级的优化实践
大家好,我是铭毅天下,一名专注于 Elasticsearch (以下简称ES)技术栈的技术爱好者。

今天我们来聊聊球友提出的一个实际问题:
ES分页查询性能很差,使用from/size方式检索居然需要10分钟!

这是一个非常典型的问题,尤其在大数据量、多索引场景下特别常见。
我会从问题根源出发,逐步分析原因,并给出详细的优化方案和实现代码,希望能帮到遇到类似问题的朋友。
一、问题引出:为什么查询这么慢?
球友的场景是这样的:
他们通过ES的范围查询(range query)和排序(sort)从多个索引(applcation*)中分页检索数据,DSL如下:
curl -X POST "http://elasticsearch.elastic:9201/applcation*/_search" -H 'Content-Type: application/json' -d '
{"from": 0,"query": {"bool": {"filter": {"range": {"timestamp": {"from": "1743609600000","include_lower": true,"include_upper": false,"to": "1744214400000"}}}}},"size": 100,"sort": [{"timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" }},{"_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" }}]
}'这个查询的目标很简单:
从多个索引中查询时间戳在
1743609600000到1744214400000之间(约7天)的记录。按
timestamp和_uuid_降序排序。每次返回100条数据(
size=100),从第0条开始(from=0)。
但问题来了:查询耗时高达10分钟(磁盘原因如下图说明,可以降到2分钟,但依然有很大优化空间)!

——铭毅补充说明:Elastic 集群最好独立部署!
更夸张的是,命中数据量达到了6亿多条 。这显然不是正常现象,我们得找到性能瓶颈。
二、问题分析:性能瓶颈在哪里?
通过DSL和聊天记录,我梳理出以下几个关键问题:
2.1 分页方式问题:from/size的深分页缺陷
ES的from/size分页是通过跳过前from条记录来实现的。当from很大时(比如翻到第10000页),ES需要在所有匹配的6亿条数据中排序后跳过大量记录,这会导致内存和计算资源的极大浪费。
干货 | 全方位深度解读 Elasticsearch 分页查询
当前from=0还不算深分页,但size=100结合6亿条命中数据,依然会触发大量数据扫描和排序。
2.2 数据范围过大:7天的数据量爆炸
时间戳范围从1743609600000(2025-03-01)到1744214400000(2025-03-08),整整7天。
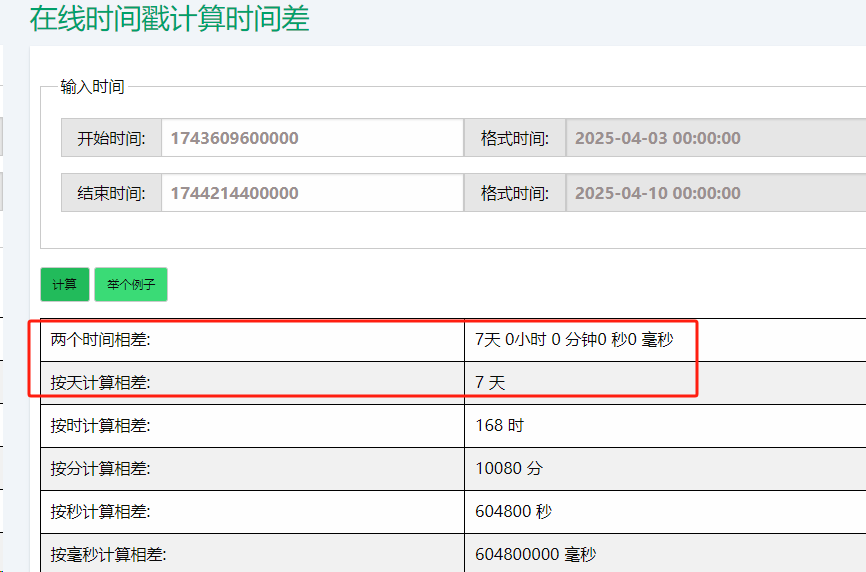
以6亿条命中数据计算,每天平均约8571万条,数据量非常恐怖。
ES需要扫描整个范围内的数据,即使加了filter,依然要处理海量记录。
2.3 多索引查询:通配符的性能隐患
使用applcation*通配符查询多个索引,可能涉及几十甚至上百个索引。
每个索引都需要独立扫描、分片计算,最终再合并结果,性能开销自然翻倍。
2.4 单次返回数据量:size=100的影响
每次返回100条数据不算多,但如果单条数据体积较大(比如包含复杂嵌套字段或大文本),网络传输和序列化开销会显著增加。
2.5 排序开销:双字段排序的代价
按timestamp和_uuid_排序需要对所有命中数据构建排序堆,
尤其在数据量大时,内存和CPU消耗会非常高。
总结一下:深分页+大范围数据+多索引+排序 ,这几大因素叠加,导致查询性能崩盘。接下来,我们探讨优化方案。
三、方案探讨:如何破局?
针对上述问题,我提出了三大优化方向,并结合ES的最佳实践,逐步解决问题:
3.1. 减少单次返回数据量
问题 :
size=100可能过大,尤其是单条数据体积大时。优化思路 :将
size调整为更小的值,比如10条(企业常见分页需求) ,减少每次返回的数据量。效果 :降低网络传输和序列化开销,同时减少排序堆的压力。
3.2. 缩小查询时间范围
问题 :7天的数据量高达6亿条,扫描范围过大。
优化思路 :引导用户缩短查询时间范围,比如从7天改为1天或几小时 。
效果 :大幅减少命中数据量,从根本上降低计算成本。
3.3. 替换分页方式:从from/size到search_after
问题 :
from/size不适合大数据量场景。优化思路 :使用
search_after,基于上一页的最后一条记录的排序值进行分页,避免深分页的性能问题。
效果 :查询时间从分钟级降到秒级,特别适合连续翻页场景。
3.4. 优化索引管理:引入别名机制
问题 :多索引通配符查询效率低,和“缩小查询时间范围”一致。。
优化思路 :为不同时间段的数据创建别名 (比如按天或按月),查询时指定具体别名而不是通配符。
效果 :减少扫描的索引数量,提升查询效率。
综合来看,这四个方向是层层递进的:先从简单调整(size和时间范围)入手,再到技术升级(search_after和别名)。
下面是具体实现。
四、方案实现:优化后的DSL与步骤
步骤1:调整size和时间范围
先尝试最简单的优化,将size从100改为10,时间范围从7天缩小到1天:
POST /applcation*/_search
{
"from": 0,
"query": {"bool": {"filter": {"range": {"timestamp": {"from": "1743609600000","include_lower": true,"include_upper": false,"to": "1743696000000" // 缩短为1天}}}}},
"size": 10, // 减少返回条数
"sort": [{ "timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } },{ "_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } }]
}效果推论:假设1天数据量为8571万条,命中量减少到原来的1/7,性能会有明显提升。
步骤2:切换到search_after
如果用户必须查询 7 天数据,且需要翻页,我们改用search_after。首次查询如下:
POST /applcation*/_search
{
"from": 0,
"query": {"bool": {"filter": {"range": {"timestamp": {"from": "1743609600000","include_lower": true,"include_upper": false,"to": "1743696000000" // 缩短为1天}}}}},
"size": 10, // 减少返回条数
"sort": [{ "timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } },{ "_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } }]
}返回结果中,记录最后一条数据的排序值,比如:
{"hits": {"hits": [{"_source": {...}, "sort": ["1744214399999", "uuid123"]},...{"_source": {...}, "sort": ["1744214380000", "uuid456"]} // 最后一条]}
}下一页查询使用search_after:
POST /applcation*/_search
{
"query": {"bool": {"filter": {"range": {"timestamp": {"from": "1743609600000","include_lower": true,"include_upper": false,"to": "1744214400000"}}}}},
"size": 10,
"search_after": ["1744214380000", "uuid456"], // 使用上一页最后一条的sort值
"sort": [{ "timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } },{ "_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } }]
}注意 :search_after要求排序字段具有唯一性,这里用timestamp和_uuid_组合,确保结果稳定。
步骤3:引入别名机制
假设数据按天分索引(如applcation-2025-03-01),我们可以创建按天的别名:

POST /_aliases
{"actions": [{ "add": { "index": "applcation-2025-03-01", "alias": "applcation-day-20250301" } },{ "add": { "index": "applcation-2025-03-02", "alias": "applcation-day-20250302" } }]
}查询时指定别名:
POST /applcation-day-20250301/_search
{
"query": {"bool": {"filter": {"range": {"timestamp": {"from": "1743609600000","include_lower": true,"include_upper": false,"to": "1743696000000"}}}}},
"size": 10,
"sort": [{ "timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } },{ "_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } }]
}效果 :只查询单日索引,扫描范围大幅缩小。
五、总结
从10分钟到秒级的蜕变通过以上优化,我们从多个角度解决了性能问题:
减少数据量——
size从100降到10,降低传输和计算压力。缩小时间范围——从7天到1天,命中数据量减少到1/7。
切换分页方式——
search_after替代from/size,彻底解决深分页问题。优化索引管理——别名机制减少多索引扫描开销。
实际效果如何?以6亿条数据为例:
原查询:扫描6亿条,排序后返回100条,耗时10分钟。
优化后:扫描单日8571万条,使用
search_after返回10条,耗时可能降到几秒。
最后给球友的建议:
如果用户需求固定,可以先尝试调整
size和时间范围。如果需要大数据量翻页,果断上
search_after。长远来看,优化索引设计(按时间分片+别名)是根本之道。
希望这篇文章能帮到大家,有问题欢迎随时交流!
我是铭毅天下,咱们下期见!
Composite 聚合——Elasticsearch 聚合后分页新实现
干货 | 全方位深度解读 Elasticsearch 分页查询
Elasticsearch聚合后分页深入详解

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
相关文章:
解决 Elasticsearch 分页查询性能瓶颈——从10分钟到秒级的优化实践
大家好,我是铭毅天下,一名专注于 Elasticsearch (以下简称ES)技术栈的技术爱好者。 今天我们来聊聊球友提出的一个实际问题: ES分页查询性能很差,使用from/size方式检索居然需要10分钟! 这是一个…...
记录IBM服务器检测到备份GPT损坏警告排查解决过程
服务器设备:IBM x3550 M4 Server IMM默认IP地址:192.168.70.125 用户名:USERID 密码:PASSW0RD(注意是零0) 操作系统:Windows Hyper-V Server 2016 IMM Web System Status Warning࿱…...

毫米波测试套装速递!高效赋能5G/6G、新材料及智能超表面(RIS)研发
德思特(Tesight)作为全球领先的测试测量解决方案提供商,始终致力于为前沿技术研发提供高精度、高效率的测试工具。 针对毫米波技术在高频通信、智能超表面(RIS)、新材料等领域的快速应用需求,我们推出毫米…...

Linux中卸载宝塔面板
输入命令 wget http://download.bt.cn/install/bt-uninstall.sh 执行脚本命令 sh bt-uninstall.sh 根据自己的情况选择1还是2 卸载完成校验 bt 这样我们的宝塔面板就卸载完了...

无人机的振动与噪声控制技术!
一、振动控制技术要点 1. 振动源分析 气动振动:旋翼桨叶涡脱落(如叶尖涡干涉)、动态失速(Dynamic Stall)引发的周期性气动激振力(频率与转速相关)。 机械振动:电机偏心、传动轴不…...
 gcc编译)
Linux(CentOS10) gcc编译
本例子摘自《鸟哥的linux私房菜-基础学习第四版》 21.3 用make进行宏编译 书中的代码在本机器(版本见下)编译出错,改正代码后发布此文章: #kernel version: rootlocalhost:~/testmake# uname -a Linux localhost 6.12.0-65.el10.x86_64 #1…...

【蓝桥杯】第十六届蓝桥杯 JAVA B组记录
试题 A: 逃离高塔 很简单,签到题,但是需要注意精度,用int会有溢出风险 答案:202 package lanqiao.t1;import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.io.PrintWrit…...

OSPF的接口网络类型【复习篇】
OSPF在不同网络环境下默认的不同工作方式 [a3]display ospf interface g 0/0/0 # 查看ospf接口的网络类型网络类型OSPF接口的网络类型(工作方式)计时器BMA(以太网)broadcast ,需要DR/BDR的选举hello:10s…...

微信小程序运行机制详解
微信小程序运行机制详解 微信小程序是介于 Web 和原生 App 之间的一种应用形态,具有无需安装、用完即走、体验流畅的特点。本文将从架构层面、运行环境、通信机制等方面深入剖析微信小程序的运行机制。 一、小程序运行架构概览 微信小程序采用双线程模型ÿ…...

python+requests接口自动化测试框架实例教程
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 前段时间由于公司测试方向的转型,由原来的web页面功能测试转变成接口测试,之前大多都是手工进行,利用postman和jmeter进行…...
2021第十二届蓝桥杯大赛软件赛省赛C/C++ 大学 B 组
记录刷题的过程、感悟、题解。 希望能帮到,那些与我一同前行的,来自远方的朋友😉 大纲: 1、空间-(题解)-字节单位转换 2、卡片-(题解)-可以不用当组合来写,思维题 3、直…...

spark课后总结
Spark运行架构 : 运行架构 Spark 采用master - slave(主从)结构。Driver 相当于master,负责管理集群中的作业任务调度;Executor 相当于slave,负责实际执行任务 核心组件 Driver:是Spark驱动…...

智能资源管理机制-重传机制
一、发送端资源管理的核心机制 1. 滑动窗口(Sliding Window) 这是TCP协议的核心优化设计: 窗口动态滑动:发送端不需要保留所有已发送的分组,只需维护一个"发送窗口"窗口大小:由接收方通告的接…...

设计模式 --- 原型模式
原型模式是创建型模式的一种,是在一个原型的基础上,建立一致的复制对象的方式。这个原型通常是我们在应用程序生命周期中需要创建多次的一个典型对象。为了避免初始化新对象潜在的性能开销,我们可以使用原型模式来建立一个非常类似于复印机的…...

基于SiamFC的红外目标跟踪
基于SiamFC的红外目标跟踪 1,背景与原理2,SiamFC跟踪方法概述2.1 核心思想2.2 算法优势3,基于SiamFC的红外跟踪代码详解3.1 网络定义与交叉相关模块3.2 SiamFC 跟踪器实现3.3 主程序:利用 OpenCV 实现视频跟踪4,总结与展望在红外监控、无人机防御以及低光照场景中,红外图…...
驱动高中差异化教学策略研究)
多模态学习分析(MLA)驱动高中差异化教学策略研究
一、引言 1.1 研究背景 在当今时代,教育数字化转型的浪潮正席卷全球,深刻地改变着教育的面貌。这一转型不仅是技术的革新,更是教育理念、教学模式和教育管理的全面变革。随着互联网、大数据、人工智能等现代信息技术在教育领域的广泛应用&a…...

设计模式 - 单例
单例设计模式 单例设计模式是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。 在 JavaScript 里,有多种实现单例设计模式的方式,下面为你详细介绍: 1. 简单对象字面量实现 这是…...
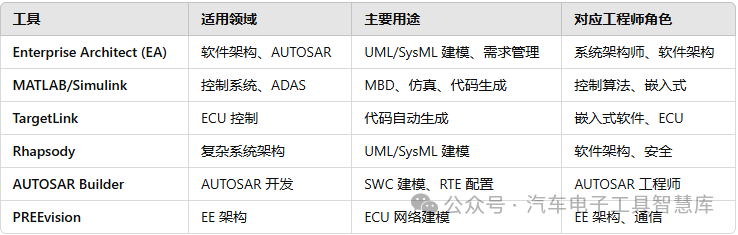
汽车软件开发常用的建模工具汇总
目录 往期推荐 1.Enterprise Architect(EA) 2.MATLAB/Simulink 3.TargetLink 4.Rational Rhapsody 5.AUTOSAR Builder 6.PREEvision 总结 往期推荐 2025汽车行业新宠:欧企都在用的工具软件ETAS工具链自动化实战指南<一&am…...

SSM废品买卖回收管理系统的设计与实现
🍅点赞收藏关注 → 添加文档最下方联系方式咨询本源代码、数据库🍅 本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。🍅关注我不迷路🍅 项目视频 07…...

@SchedulerLock 防止分布式环境下定时任务并发执行
背景 在一个有多个服务实例的分布式系统中,如果你用 Scheduled 来定义定时任务,所有实例都会执行这个任务。ShedLock 的目标是只让一个实例在某一时刻执行这个定时任务。 使用步骤 引入依赖 当前以redisTemplate为例子,MongoDB、Zookeeper…...

实信号的傅里叶变换为何属于埃尔米特函数?从数学原理到 MATLAB 动态演示
引言 在信号处理领域,傅里叶变换是分析信号在频域表现的重要工具。特别是对于实信号,实信号是指在时间或空间域内取值为实数的信号,例如音频信号、温度变化等,它的傅里叶变换展现了一个非常特殊的数学性质——共轭对称性…...
【VitePress】新增md文件后自动更新侧边栏导航
目录 说在前面先看效果代码结构详细说明侧边栏格式utils监听文件变化使用pm2管理监听进程 说在前面 操作系统:windows11node版本:v18.19.0npm版本:10.2.3vitepress版本:1.6.3完整代码:github 先看效果 模板用的就是官…...
docker部署scylladb
创建存储数据的目录和配置目录 mkdir -p /root/docker/scylla/data/data /root/docker/scylla/data/commitlog /root/docker/scylla/data/hints /root/docker/scylla/data/view_hints /root/docker/scylla/conf快速启动拷贝配置文件 docker run -d \--name scylla \scylladb/…...
Android 16应用适配指南
Android 16版本特性介绍 https://developer.android.com/about/versions/16?hlzh-cn Android 16 所有功能和 API 概览 https://developer.android.com/about/versions/16/features?hlzh-cn#language-switching Android 16 发布时间 Android 16 适配指南 Google开发平台&…...

2.2goweb解析http请求信息
Go语言的net/http包提供了一些列用于表示HTTP报文的解构。我们可以使用它处理请求和发送响应。其中request结构体代表了客户端发生的请求报文。 核心字段获取方法 1. 请求行信息 通过 http.Request 结构体获取: func handler(w http.ResponseWriter, r *http.Req…...

本地部署大模型(ollama模式)
分享记录一下本地部署大模型步骤。 大模型应用部署可以选择 ollama 或者 LM Studio。本文介绍ollama本地部署 ollama官网为:https://ollama.com/ 进入官网,下载ollama。 ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型&…...

KWDB创作者计划—KWDB:国产分布式多模数据库的创新实践
在数字化转型的浪潮中,数据管理技术正经历着前所未有的变革。随着物联网、人工智能等技术的飞速发展,企业面临着海量多源异构数据的管理挑战。KWDB(KaiwuDB Community Edition)作为一款面向AIoT场景的分布式多模数据库,…...
redis之缓存击穿
一、前言 本期我们聊一下缓存击穿,其实缓存击穿和缓存穿透很相似,区别就是,缓存穿透是一些黑客故意请求压根不存在的数据从而达到拖垮系统的目的,是恶意的,有针对性的。缓存击穿的情况是,数据确实存在&…...
txt、Csv、Excel、JSON、SQL文件读取(Python)
txt、Csv、Excel、JSON、SQL文件读取(Python) txt文件读写 创建一个txt文件 fopen(rtext.txt,r,encodingutf-8) sf.read() f.close() print(s)open( )是打开文件的方法 text.txt’文件名 在同一个文件夹下所以可以省略路径 如果不在同一个文件夹下 ‘…...

【学习笔记】两个类之间的数据交互方式
在面向对象编程中,两个类之间的数据交互可以通过以下几种方式实现,具体选择取决于需求和设计模式: 1. 通过方法调用 一个类通过调用另一个类的公共方法来获取或传递数据。这是最常见的方式,符合封装原则。 class ClassA:def __…...