BERT - MLM 和 NSP
本节代码将实现BERT模型的两个主要预训练任务:掩码语言模型(Masked Language Model, MLM) 和 下一句预测(Next Sentence Prediction, NSP)。
1. create_nsp_dataset 函数
这个函数用于生成NSP任务的数据集。
def create_nsp_dataset(corpus):nsp_dataset = []for i in range(len(corpus)-1):next_sentence = corpus[i+1]rand_id = random.randint(0, len(corpus) - 1)while abs(rand_id - i) <= 1:rand_id = random.randint(0, len(corpus) - 1)negt_sentence = corpus[rand_id]nsp_dataset.append((corpus[i], next_sentence, 1)) # 正样本nsp_dataset.append((corpus[i], negt_sentence, 0)) # 负样本return nsp_dataset-
正样本:
corpus[i]和corpus[i+1]是连续的句子对,标记为1,表示它们是相邻的句子。 -
负样本:
corpus[i]和随机选择的句子corpus[rand_id]组成一个句子对,标记为0,表示它们不是相邻的句子。 -
随机选择负样本:通过随机选择句子来生成负样本,确保模型能够学习区分相邻句子和非相邻句子。
2. BERTDataset 类
这个类继承自 torch.utils.data.Dataset,用于加载和处理BERT预训练任务的数据。
def __init__(self, nsp_dataset, tokenizer: BertTokenizer, max_length):self.nsp_dataset = nsp_datasetself.tokenizer = tokenizerself.max_length = max_lengthself.cls_id = tokenizer.cls_token_idself.sep_id = tokenizer.sep_token_idself.pad_id = tokenizer.pad_token_idself.mask_id = tokenizer.mask_token_id-
nsp_dataset:存储NSP任务的数据集,每个样本是一个三元组(sent1, sent2, nsp_label)。 -
tokenizer:用于将文本转换为词索引(token IDs)。 -
max_length:序列的最大长度,用于填充或截断。 -
特殊标记:
-
self.cls_id:[CLS]标记的索引。 -
self.sep_id:[SEP]标记的索引。 -
self.pad_id:[PAD]标记的索引。 -
self.mask_id:[MASK]标记的索引。
-
__len__ 方法
def __len__(self):return len(self.nsp_dataset)-
返回数据集的大小,即样本数量。
__getitem__ 方法
def __getitem__(self, idx):sent1, sent2, nsp_label = self.nsp_dataset[idx]sent1_ids = self.tokenizer.encode(sent1, add_special_tokens=False)sent2_ids = self.tokenizer.encode(sent2, add_special_tokens=False)tok_ids = [self.cls_id] + sent1_ids + [self.sep_id] + sent2_ids + [self.sep_id]seg_ids = [0]*(len(sent1_ids)+2) + [1]*(len(sent2_ids) + 1)mlm_tok_ids, mlm_labels = self.build_mlm_dataset(tok_ids)mlm_tok_ids = self.pad_to_seq_len(mlm_tok_ids, 0)seg_ids = self.pad_to_seq_len(seg_ids, 2)mlm_labels = self.pad_to_seq_len(mlm_labels, -100)mask = (mlm_tok_ids != 0)return {"mlm_tok_ids": mlm_tok_ids,"seg_ids": seg_ids,"mask": mask,"mlm_labels": mlm_labels,"nsp_labels": torch.tensor(nsp_label)}-
句子编码:
-
sent1_ids和sent2_ids分别是两个句子的词索引列表。 -
使用
self.tokenizer.encode将句子转换为词索引,add_special_tokens=False表示不添加特殊标记([CLS]和[SEP])。
-
-
构建输入序列:
-
tok_ids:将两个句子的词索引列表组合成一个序列,中间用[SEP]分隔,并在开头添加[CLS]。 -
seg_ids:段嵌入索引,第一个句子使用0,第二个句子使用1。
-
-
MLM任务:
-
mlm_tok_ids和mlm_labels是通过build_mlm_dataset方法生成的,用于MLM任务。
-
-
填充和截断:
-
使用
pad_to_seq_len方法将mlm_tok_ids、seg_ids和mlm_labels填充或截断到max_length。
-
-
掩码:
-
mask:生成一个掩码,用于标记哪些位置是有效的输入(非填充部分)。
-
pad_to_seq_len 方法
def pad_to_seq_len(self, seq, pad_value):seq = seq[:self.max_length]pad_num = self.max_length - len(seq)return torch.tensor(seq + pad_num * [pad_value])设计原因
-
将序列截断到
max_length,并用pad_value填充到max_length。
build_mlm_dataset 方法
def build_mlm_dataset(self, tok_ids):mlm_tok_ids = tok_ids.copy()mlm_labels = [-100] * len(tok_ids)for i in range(len(tok_ids)):if tok_ids[i] not in [self.cls_id, self.sep_id, self.pad_id]:if random.random() < 0.15:mlm_labels[i] = tok_ids[i]if random.random() < 0.8:mlm_tok_ids[i] = self.mask_idelif random.random() < 0.9:mlm_tok_ids[i] = random.randint(106, self.tokenizer.vocab_size - 1)return mlm_tok_ids, mlm_labels-
MLM任务:
-
随机选择一些词(概率为15%),并将它们替换为
[MASK](80%)、随机词(10%)或保持不变(10%)。 -
mlm_labels用于存储被替换词的真实索引,未被替换的位置标记为-100(PyTorch中忽略计算损失的标记)。
-
Bert完整代码(标红部分为本节所提到部分)
import re
import math
import torch
import random
import torch.nn as nnfrom transformers import BertTokenizer
from torch.utils.data import Dataset, DataLoader# nn.TransformerEncoderLayerclass MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_proj = nn.Linear(d_model, d_model)self.k_proj = nn.Linear(d_model, d_model)self.v_proj = nn.Linear(d_model, d_model)self.o_proj = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = (Q @ K.transpose(-2, -1)) / math.sqrt(self.d_k)if mask is not None:mask = mask.unsqueeze(1).unsqueeze(1)atten_scores = atten_scores.masked_fill(mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)return self.dropout(self.o_proj(out))class FeedForward(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.W1 = nn.Linear(d_model, dff)self.act = nn.GELU()self.W2 = nn.Linear(dff, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):return self.W2(self.dropout(self.act(self.W1(x))))class TransformerEncoderBlock(nn.Module):def __init__(self, d_model, num_heads, dropout, dff):super().__init__()self.mha_block = MultiHeadAttention(d_model, num_heads, dropout)self.ffn_block = FeedForward(d_model, dff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self, x, mask=None):res1 = self.norm1(x + self.dropout1(self.mha_block(x, mask)))res2 = self.norm2(res1 + self.dropout2(self.ffn_block(res1)))return res2class BertModel(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff):super().__init__()self.tok_emb = nn.Embedding(vocab_size, d_model)self.seg_emb = nn.Embedding(3, d_model)self.pos_emb = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerEncoderBlock(d_model, num_heads, dropout, dff)for _ in range(N_blocks)])self.norm = nn.LayerNorm(d_model)self.drop = nn.Dropout(dropout)def forward(self, x, seg_ids, mask):pos = torch.arange(x.shape[1])tok_emb = self.tok_emb(x)seg_emb = self.seg_emb(seg_ids)pos_emb = self.pos_emb(pos)x = tok_emb + seg_emb + pos_embfor layer in self.layers:x = layer(x, mask)x = self.norm(x)return xclass BERT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff):super().__init__()self.bert = BertModel(vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff)self.mlm_head = nn.Linear(d_model, vocab_size)self.nsp_head = nn.Linear(d_model, 2)def forward(self, mlm_tok_ids, seg_ids, mask):bert_out = self.bert(mlm_tok_ids, seg_ids, mask)cls_token = bert_out[:, 0, :]mlm_logits = self.mlm_head(bert_out)nsp_logits = self.nsp_head(cls_token)return mlm_logits, nsp_logitsdef read_data(file):with open(file, "r", encoding="utf-8") as f:data = f.read().strip().replace("\n", "")corpus = re.split(r'[。,“”:;!、]', data)corpus = [sentence for sentence in corpus if sentence.strip()]return corpusdef create_nsp_dataset(corpus):nsp_dataset = []for i in range(len(corpus)-1):next_sentence = corpus[i+1]rand_id = random.randint(0, len(corpus) - 1)while abs(rand_id - i) <= 1:rand_id = random.randint(0, len(corpus) - 1)negt_sentence = corpus[rand_id]nsp_dataset.append((corpus[i], next_sentence, 1)) # 正样本nsp_dataset.append((corpus[i], negt_sentence, 0)) # 负样本return nsp_datasetclass BERTDataset(Dataset):def __init__(self, nsp_dataset, tokenizer: BertTokenizer, max_length):self.nsp_dataset = nsp_datasetself.tokenizer = tokenizerself.max_length = max_lengthself.cls_id = tokenizer.cls_token_idself.sep_id = tokenizer.sep_token_idself.pad_id = tokenizer.pad_token_idself.mask_id = tokenizer.mask_token_iddef __len__(self):return len(self.nsp_dataset)def __getitem__(self, idx):sent1, sent2, nsp_label = self.nsp_dataset[idx]sent1_ids = self.tokenizer.encode(sent1, add_special_tokens=False)sent2_ids = self.tokenizer.encode(sent2, add_special_tokens=False)tok_ids = [self.cls_id] + sent1_ids + [self.sep_id] + sent2_ids + [self.sep_id]seg_ids = [0]*(len(sent1_ids)+2) + [1]*(len(sent2_ids) + 1)mlm_tok_ids, mlm_labels = self.build_mlm_dataset(tok_ids)mlm_tok_ids = self.pad_to_seq_len(mlm_tok_ids, 0)seg_ids = self.pad_to_seq_len(seg_ids, 2)mlm_labels = self.pad_to_seq_len(mlm_labels, -100)mask = (mlm_tok_ids != 0)return {"mlm_tok_ids": mlm_tok_ids,"seg_ids": seg_ids,"mask": mask,"mlm_labels": mlm_labels,"nsp_labels": torch.tensor(nsp_label)}def pad_to_seq_len(self, seq, pad_value):seq = seq[:self.max_length]pad_num = self.max_length - len(seq)return torch.tensor(seq + pad_num * [pad_value])def build_mlm_dataset(self, tok_ids):mlm_tok_ids = tok_ids.copy()mlm_labels = [-100] * len(tok_ids)for i in range(len(tok_ids)):if tok_ids[i] not in [self.cls_id, self.sep_id, self.pad_id]:if random.random() < 0.15:mlm_labels[i] = tok_ids[i]if random.random() < 0.8:mlm_tok_ids[i] = self.mask_idelif random.random() < 0.9:mlm_tok_ids[i] = random.randint(106, self.tokenizer.vocab_size - 1)return mlm_tok_ids, mlm_labelsif __name__ == "__main__":data_file = "4.10-BERT/背影.txt"model_path = "/Users/azen/Desktop/llm/models/bert-base-chinese"tokenizer = BertTokenizer.from_pretrained(model_path)corpus = read_data(data_file)max_length = 25 # len(max(corpus, key=len))print("Max length of dataset: {}".format(max_length))nsp_dataset = create_nsp_dataset(corpus)trainset = BERTDataset(nsp_dataset, tokenizer, max_length)batch_size = 16trainloader = DataLoader(trainset, batch_size, shuffle=True)vocab_size = tokenizer.vocab_sized_model = 768N_blocks = 2num_heads = 12dropout = 0.1dff = 4*d_modelmodel = BERT(vocab_size, d_model, max_length, N_blocks, num_heads, dropout, dff)lr = 1e-3optim = torch.optim.Adam(model.parameters(), lr=lr)loss_fn = nn.CrossEntropyLoss()epochs = 20for epoch in range(epochs):for batch in trainloader:batch_mlm_tok_ids = batch["mlm_tok_ids"]batch_seg_ids = batch["seg_ids"]batch_mask = batch["mask"]batch_mlm_labels = batch["mlm_labels"]batch_nsp_labels = batch["nsp_labels"]mlm_logits, nsp_logits = model(batch_mlm_tok_ids, batch_seg_ids, batch_mask)loss_mlm = loss_fn(mlm_logits.view(-1, vocab_size), batch_mlm_labels.view(-1))loss_nsp = loss_fn(nsp_logits, batch_nsp_labels)loss = loss_mlm + loss_nsploss.backward()optim.step()optim.zero_grad()print("Epoch: {}, MLM Loss: {}, NSP Loss: {}".format(epoch, loss_mlm, loss_nsp))passpass相关文章:

BERT - MLM 和 NSP
本节代码将实现BERT模型的两个主要预训练任务:掩码语言模型(Masked Language Model, MLM) 和 下一句预测(Next Sentence Prediction, NSP)。 1. create_nsp_dataset 函数 这个函数用于生成NSP任务的数据集。 def cr…...

Python生成exe
其中的 -w 参数是 PyInstaller 用于窗口模式(Windowed mode),它会关闭命令行窗口的输出,这通常用于 图形界面程序(GUI),比如使用 PyQt6, Tkinter, PySide6 等。 所以: 如果你在没有…...
MySql 自我总结
目录 1. 数据库约束 1.1约束类型 2. 表的设计 2.1 一对一 2.2 一对多 2.3 多对多 3. 新增 4. 查询 4.1 聚合查询 4.2 GROUP BY 4.3 HAVING 4.4 联合查询 4.5 内连接 4.5.1 内连接的核心概念 4.5.2 内连接的语法 4.5.3 ON 与 WHERE 的区别 4.6 自连接 4.6.1 定…...
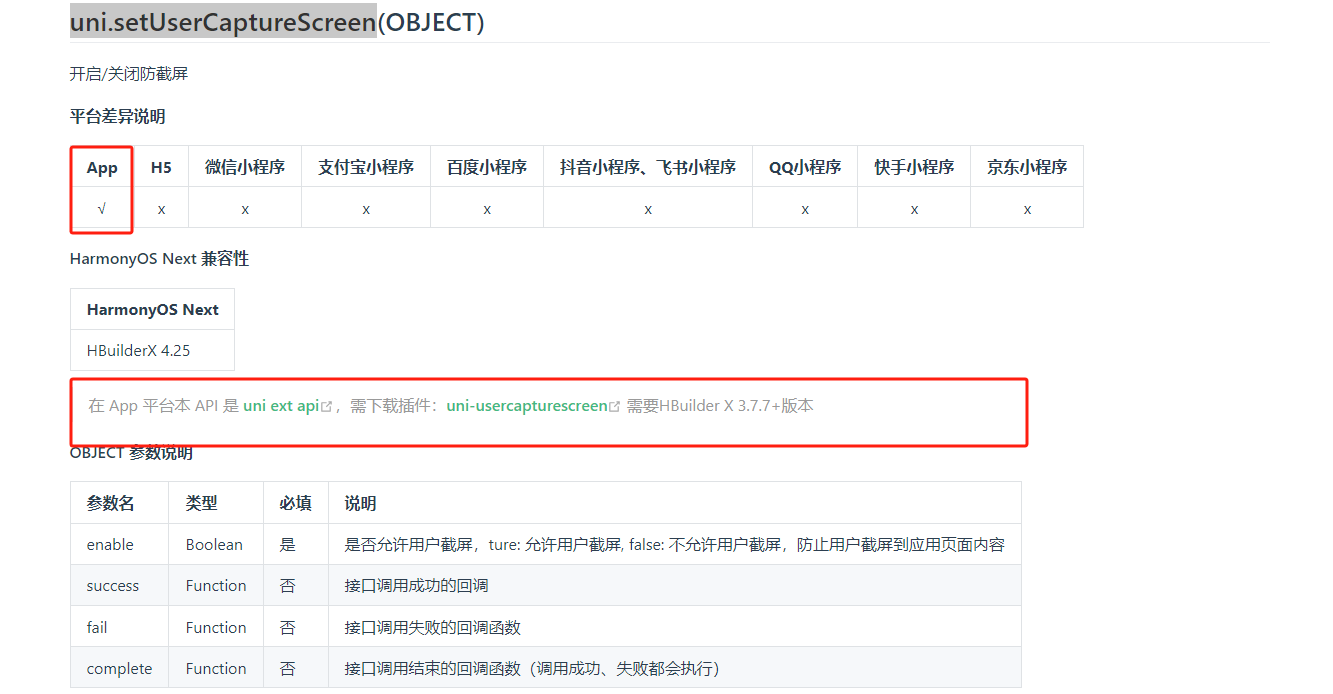
uni-app app 安卓和ios防截屏
首先可参考文档 uni.setUserCaptureScreen 这里需要在项目中引入这个插件 uni-usercapturescreen - DCloud 插件市场 否则会报错,在需要防止截屏录屏的页面中,加入 uni.setUserCaptureScreen({enable: false,success() {console.log(全局截屏录屏功能已禁用);},fail(err)…...
)
Android Input——查找并添加目标窗口(七)
在 Android 输入系统中,InputDispatcher 的核心职责之一是将输入事件正确地传递到目标窗口。上一篇文章我们介绍到 InputDispatcher 事件分发调用到 findFocusedWindowTargetsLocked() 函数查找焦点窗口,并将焦点窗口添加到目标窗口,这里我们继续往下看。 一、获取焦点窗口…...

ruby内置全局变量
以下是 Ruby 中常见的 内置全局变量 及其用途的详细说明。这些变量以 $ 开头,由 Ruby 解释器自动管理,用于访问系统状态、异常、输入输出等核心信息。 一、异常处理相关 全局变量说明示例$!当前作用域最后抛出的异常对象(等同于 rescue >…...

pytorch查询字典、列表维度
输出tensor变量维度 print(a.shape)输出字典维度 for key, value in output_dict.items():if isinstance(value, torch.Tensor):print(f"{key} shape:", value.shape)输出列表维度 def get_list_dimensions(lst):# 基线条件:如果lst不是列表࿰…...
【Go】windows下的Go安装与配置,并运行第一个Go程序
【Go】windows下的Go安装与配置,并运行第一个Go程序 安装环境:windows10 64位 安装版本:go1.16 windows/amd64 一、安装配置步骤 1.到官方网址下载安装包 https://golang.google.cn/dl/ 默认情况下 .msi 文件会安装在 c:\Go 目录下。可自行配…...

Windows上使用Qt搭建ARM开发环境
在 Windows 上使用 Qt 和 g++-arm-linux-gnueabihf 进行 ARM Linux 交叉编译(例如针对树莓派或嵌入式设备),需要配置 交叉编译工具链 和 Qt for ARM Linux。以下是详细步骤: 1. 安装工具链 方法 1:使用 MSYS2(推荐) MSYS2 提供 mingw-w64 的 ARM Linux 交叉编译工具链…...
)
CNN(卷积神经网络)
什么是CNN CNN(卷积神经网络),是通过提取特征来压缩计算的一个网络结构,主要由卷积层、池化层、全连接层组成。 卷积层 在卷积层中,通过卷积核的移动对不同的区域提取特征生成一个新的矩阵,比如一个原始…...

Linux 内核网络协议栈中的 struct packet_type:以 ip_packet_type 为例
在 Linux 内核的网络协议栈中,struct packet_type 是一个核心数据结构,用于注册特定协议类型的数据包处理逻辑。它定义了如何处理特定协议的数据包,并通过协议类型匹配机制实现协议分发。本文将通过分析 ip_packet_type 的定义和作用,深入探讨其在网络协议栈中的重要性。 …...

网络问题之TCP/UDP协议
1. TCP是什么? TCP(Transmission Control Protocol,传输控制协议)是互联网核心协议之一,属于传输层协议,为应用程序提供可靠的、面向连接的字节流服务。 基本特性 可靠性:通过确认机制、重传机…...

vue3腾讯云直播 前端拉流(前端页面展示直播)
1、引入文件,在index.html <link href"https://tcsdk.com/player/tcplayer/release/v5.3.2/tcplayer.min.css" rel"stylesheet" /><!--播放器脚本文件--><script src"https://tcsdk.com/player/tcplayer/release/v5.3.2/t…...
【MYSQL从入门到精通】数据库基础操作、数据类型
目录 一些基础操作语句 创建库名 选择要操作的数据库 删除数据库 磁盘中删除文件的原理 数据库安全的各种措置 查看MYSQL的帮助 数值类型 字符串类型 日期类型 一些基础操作语句 1.使用客户端工具连接数据库服务器:mysql -uroot -p 2.查看所有数据库&am…...

JS里对于集合的简单介绍
JS的集合 前言一、集合二、基本使用1. 创建集合2. 添加元素3. 删除元素4. 检查元素5. 清空集合6. 集合的大小 三、扩展使用1. 遍历集合2. 从数组创建集合3. 集合的应用场景 四、总结 前言 JS里对于集合的简单介绍 同数学的集合,有无序性、唯一性 注意:…...
论文阅读笔记——Multi-Token Attention
MTA 论文 在 Transformer 中计算注意力权重时,仅依赖单个 Q 和 K 的相似度,无法有效捕捉多标记组合信息。(对于 A、B 两个词,单标记注意力需要分别计算两个词的注意力分数,再通过后处理定位共同出现的位置或通过多层隐…...

Sql with as 语句
在SQL查询中,经常会遇到需要重复使用的子查询。为了简化查询语句并提高可读性,SQL引入了WITH AS语法。通过使用WITH AS,我们可以创建临时表或视图,将子查询的结果保存起来,并在主查询中使用。本文将通过示例介绍SQL中W…...

vue3 antdesign table表格特定单元格背景变色
效果: <a-table :columns"columnsAll" :data-source"tableAllData"bordered size"middle" :scroll"{ x: 100,y: 600 }" :pagination"false"style"margin: 0 10px 10px 10px;" ><template #…...

【C语言】--- 编译和链接
编译和链接 1. 翻译环境和运行环境2. 翻译环境2.1 预处理2.2 编译2.2.1 词法分析2.2.2 语法分析2.2.3 语义分析 2.3 汇编2.4 链接 3. 运行环境 1. 翻译环境和运行环境 计算机只能运行二进制指令,所以我们的.c的文本程序需要先翻译为二进制程序才能被计算机执行。在…...

Qwen2.5-7B-Instruct FastApi 部署调用教程
1 环境准备 基础环境最低要求说明: 环境名称版本信息1Ubuntu22.04.4 LTSCudaV12.1.105Python3.12.4NVIDIA CorporationRTX 3090 首先 pip 换源加速下载并安装依赖包 # 升级pip python -m pip install --upgrade pip # 更换 pypi 源加速库的安装 pip config set g…...

深入解析Python爬虫技术:从基础到实战的功能工具开发指南
一、引言:Python 爬虫技术的核心价值 在数据驱动的时代,网络爬虫作为获取公开数据的重要工具,正发挥着越来越关键的作用。Python 凭借其简洁的语法、丰富的生态工具以及强大的扩展性,成为爬虫开发的首选语言。根据 Stack Overflow 2024 年开发者调查,68% 的专业爬虫开发者…...
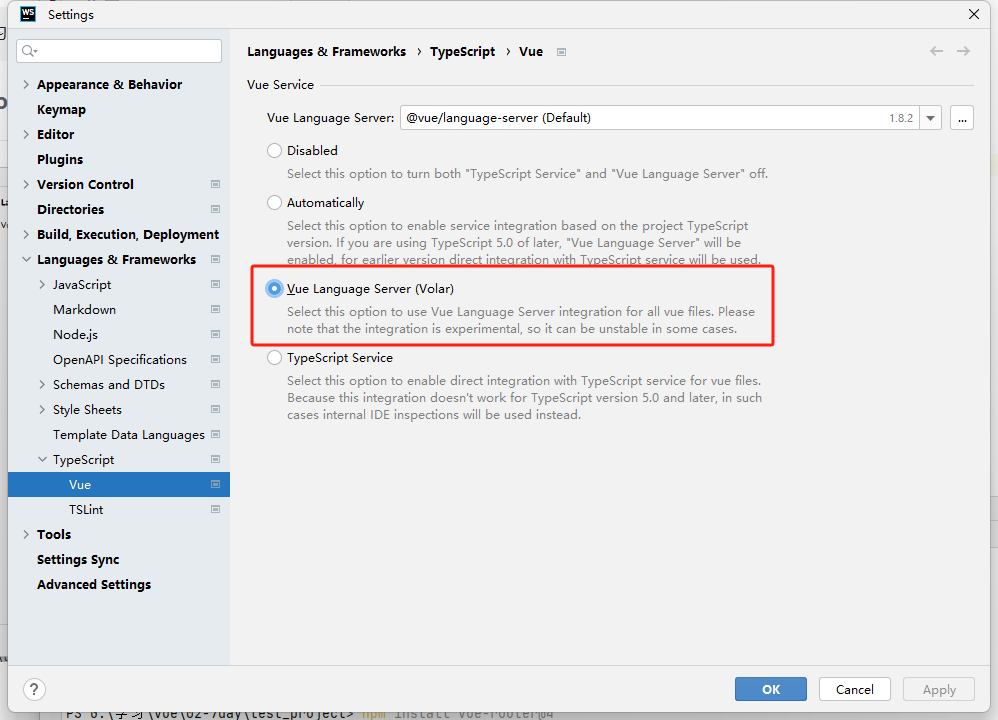
前端 Vue: Cannot find module XX or its corresponding type declarations.
记一个常见错误,每次创建完新的vuetsvite项目,在配置路由的时候总会找不到vue文件,我用的是Webstorm,在设置里面修改以下设置,即可消除警告。...
数字内容体验案例解析与行业应用
数字内容案例深度解析 在零售行业头部品牌的实践中,数字内容体验的革新直接推动了用户行为模式的转变。某国际美妆集团通过搭建智能内容中台,将产品信息库与消费者行为数据实时对接,实现不同渠道的动态内容生成。其电商平台首页的交互式AR试…...

Webpack中的文件指纹:给资源戴上个“名牌”
你是否想过,当你修改代码后,浏览器为什么仍然拿着旧版资源不放?秘密就在于——文件指纹!简单来说,文件指纹就像给每个构建出来的文件贴上独一无二的“姓名牌”,告诉浏览器:“嘿,我更…...

HBuilderX中uni-app打包Android(apk)全流程超详细打包
一、Android生成打包证书 1、Android平台签名证书(.keystore)生成指南_android 签名生成-CSDN博客(如果不上架应用商店可以跳过,可以使用云端证书) 二、打开manifest.json配置基础设置 三、配置安卓应用图标 四、配置安卓启动页图片 五、…...

多模态大模型重塑自动驾驶:技术融合与实践路径全解析
目录 1、 引言:AI与自动驾驶的革命性融合 2、五大领先多模态模型解析 2.1 Qwen2.5-Omni:全模态集大成者 2.2. LLaVA:视觉语言理解专家 2.3. Qwen2-VL:长视频理解能手 2.4. X-InstructBLIP:跨模态理解框架 2.5. …...

MySQL 中查询 VARCHAR 类型 JSON 数据的
在数据库设计中,有时我们会将 JSON 数据存储在 VARCHAR 或 TEXT 类型字段中。这种方式虽然灵活,但在查询时需要特别注意。本文将详细介绍如何在 MySQL 中有效查询存储为 VARCHAR 类型的 JSON 数据。 一、问题背景 当 JSON 数据存储在 VARCHAR 列中时&a…...
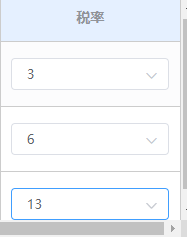
vue2 el-element中el-select选中值,数据已经改变但选择框中不显示值,需要其他输入框输入值才显示这个选择框才会显示刚才选中的值。
项目场景: <el-table-column label"税率" prop"TaxRate" width"180" align"center" show-overflow-tooltip><template slot-scope"{row, $index}"><el-form-item :prop"InquiryItemList. …...
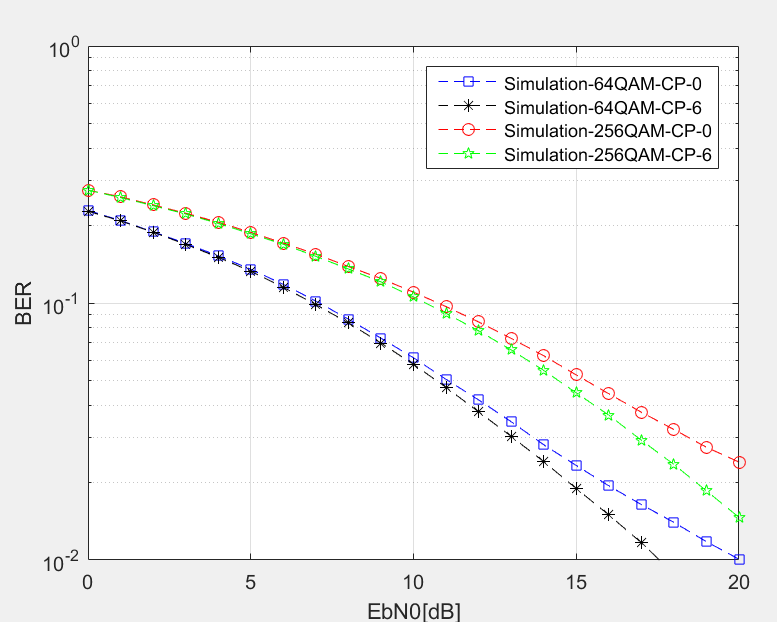
OFDM CP 对解码影响
OFDM符号间会存在ISI,为了解决该问题在符号间插入了循环前缀,可以说这个发明是OFDM能够实用的关键,在多径信道中CP可以有效的解决符号间干扰。3GPP中对于不同SCS 定义了不同的CP长度: 5G Cyclic Prefix (CP) Design -5G Physical …...

oracle em修复之路
很早以前写的文章,再草稿中存放太久了,今天开始整理20年来工作体会,以后陆续发出,希望给大家提供小小的帮助。 去年做的项目使用的oracle数据库,最近要看一下,启动机器进入系统,出现无法加载数…...