机器学习之PCA主成分分析详解
文章目录
- 引言
- 一、PCA的概念
- 二、PCA的基本数学原理
- 2.1 内积与投影
- 2.2 基
- 2.3 基变换
- 2.4 关键问题及优化目标
- 2.5 方差
- 2.6 协方差
- 2.7 协方差矩阵
- 2.8 协方差矩阵对角化
- 三、PCA执行步骤总结
- 四、PCA计算实例
- 五、PCA参数解释
- 六、代码实现
- 七、PCA的优缺点
- 八、总结
引言
在机器学习领域,我们经常会遇到高维数据带来的"维度灾难"问题。随着特征数量的增加,数据稀疏性增强,模型复杂度飙升,计算成本大幅提高。主成分分析(PCA)作为一种经典的降维技术,能够有效解决这些问题。本文将深入浅出地介绍PCA的原理、实现和应用。
一、PCA的概念
主成分分析(Principal Component Analysis,PCA)是一种无监督的线性降维方法,它通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,这些新变量被称为"主成分"。
PCA的核心思想是:
- 将原始高维数据投影到低维子空间
- 保留数据中最重要的变异信息
- 用较少的变量解释原始数据中的大部分信息
二、PCA的基本数学原理
2.1 内积与投影
下面先看一个向量运算:内积。两个维数相同的向量的内积被定义为:

内积运算将两个向量映射为一个实数,其计算方式非常容易理解,但是其意义并不明显,下面我们分析内积的几何意义。假设A和B是两个n维向量,我们知道n维向量可以表示为n维空间中的一条从原点发射的有向线段,为了简单起见,我们假设A和B均为二维向量,则

那么在二维平面中A和B可以用两条从原点出发有向线段表示,如下图:

现在,我们作OA向量和AA’向量,然后我们从A点向B点所在直线引入一条垂线,垂足为A’ ,得到A在B上的投影 m=OA’向量,m称为投影向量。假设A与B的夹角为a,则投影的矢量长度为(矢量有方向,标量无方向):

其中

是向量A的模。若假设向量B的模为1,那么就变成了下面公式(也就是上面我们说的投影的矢量长度):

2.2 基
基:也称为基底,是描述、刻画向量空间的的基本工具。
我们经常使用线段终点的点的坐标表示向量,例如下面的向量可以表示为(3,2),不过只有一个(3,2)本身是不能够精确表示一个向量的,我们仔细看一下,这里的坐标(3,2)实际上表示的是向量在x轴上的投影值3,在y轴上的投影值为2。也就是说我们可以这样理解:以x轴和y轴上正方向长度为1的向量为标准,那么一个向量(3,2)实际上是说在x轴投影为3而y轴投影为2,而投影是矢量,可以为负。

所以向量(3,2)可以由这一组基表示:

因此向量(x,y)实际上表示线性组合,以x轴和y轴上正方向长度为1的向量为标准,:

可知,所有二维向量都可以表示为这样的线性组合,此处(1,0)和(0,1)叫做二维空间的一组基。

所以,要准确描述向量,首先要确定一组基,然后给出基所在的各个直线上的投影值,就可以了,只不过我们经常省略第一步,而默认以(1,0)和(0,1)为基。
我们之所以默认选择(1,0)和(0,1)为基,当然是比较方便,因为他们分别是x和y轴正方向上的单位向量,计算或者是直观观察很方便。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上的向量。
例如,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模式1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应于任何一个向量我们总可以找到其同方向上模为1的向量,只要让两个分量分别除以模就好了,例如上面的基就可以变为:(1/ √2, 1/ √2 ) 和 (-1/ √2, 1/ √2 )。
现在我们想获得(3,2)在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,不难得到新的坐标为(5/ √2, -1/ √2 )。
下图给出了新的基以及(3,2)在新基上坐标值的示意图:

2.3 基变换
基变换的表示方法很简单,还是拿上面的例子,想一下,将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。

那么其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标,例如(1,1),(2,2),(3,3)想变换到刚才那组基上,则可以变为这样:

于是一组向量的基变换被表示为矩阵的相乘。
一般地,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按照行组成矩阵A,,然后将向量按照列组成矩阵B,那么两个矩阵的乘积AB就是变换结果,其中AB的第m列为A中的第M列变换后的结果。
数学表示为:

总结来说基变换的含义就是两个矩阵相乘将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说:一个矩阵可以表示为一种线性变换。
2.4 关键问题及优化目标
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量的本身的维数,则可以达到降维的效果,但是我们还没有回答最关键的一个问题:如何选择基才是最优的,或者说如何才能最大程度保留原有的信息?
下面我们以一个具体的例子展开,假设我们的数据由五条记录组成,将它们表示为矩阵形式:

其中每一列为一条数据记录,而一行为一个字段,为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为0(这样做的好处后面可以看到)。
我们看上面的数据,第一个字段的均值为2,第二个字段的均值为3,所以变换后:

我们可以看到五条数据在平面直角坐标系内的样子:

那么现在还是回到刚刚的问题:如何选择基才是最优的,或者说如何才能最大程度保留原有的信息?
这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在的直线上,用投影值表示原始记录,这是一个实际的二维降到一维的问题。
以上图为例,可以看出如果向x轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向y轴投影最上面的两个点和分布在x轴上的两个点也会重叠,所以看来x和y轴都不是最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的,如下图所示。

下面我们用数学方法表述这个问题。
2.5 方差
从上述来说,我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述,此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即:

由于上面我们已经将每个字段的均值都化0 了,因此方差可以直接用每个元素的平方和除以元素个数表示:

于是上面的问题变为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。(对于二维变一维来说)
2.6 协方差
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了,不过对于更高维,还有一个问题需要解决,考虑三维降到二维问题,与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
如果我们还是单纯的只选择方差最大的方向,很显然,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此应该有其他约束条件。从直观上讲,让两个字段尽可能表示更多的原始信息,我们是不希望他们之间存在线性相关性,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
而数字上可以用两个字段的协方差表示其相关性,协方差的公式为:

由于已经让每个字段均值为0,则:

可以看出,在字段均值为0的情况下,两个字段的协方差简洁的表示为其内积除以元素数m。
当协方差为0时,表示两个字段完全独立,为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此,我们得到了降维问题的优化目标:将一组N维向量降维K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的k个方差)。
2.7 协方差矩阵
假设我们有a,b两个字段,组成矩阵 X :

然后我们用X乘以X的转置,并乘上系数1/m:

这时候我们会发现,这个矩阵是一个是实对称矩阵,并且对角线上的两个元素分别是两个字段的方差,而其他元素是a和b的协方差,两者被统一到了一个矩阵的。

并且由实对称矩阵的特性可知:

2.8 协方差矩阵对角化
设原始数据矩阵X对于的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据,设Y的协方差矩阵为D,我们推导一下D与C的关系:

此时,优化目标变成了寻找一个矩阵P,满足PCPT是一个对角矩阵,并且对角元素按照从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
由上文知道,协方差矩阵C是一个实对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
- 实对称矩阵不同特征值对应的特征向量必然正交。
- 设特征向量 λ 重数为r,则必然存在r个线性无关的特征向量对应于 λ,因此可以将这r个特征向量单位正交化。
有上面两条可知,一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量,设这n个特征向量为e1, e2, …en,我们将其按照列组成矩阵:

则对协方差矩阵有如下结论:

其中 Λ 为对称矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。到这里,我们发现我们已经找到了需要的矩阵P:

P是协方差矩阵的特征向量单位化后按照行排列出的矩阵,其中每一行都是C的一个特征向量。
三、PCA执行步骤总结
求解步骤:
- 将原始数据按列组成n行m列矩阵X
- 将X的每一行(代表一个属性字段)进行零均值化(去平均值),即减去这一行的均值
- 求出协方差矩阵 C= 1/mXXT
- 求出协方差矩阵的特征值及对应的特征向量
- 将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P(保留最大的k各特征向量)
- Y=PX 即为降维到K维后的数据
四、PCA计算实例
下面我们用一个例子来帮助大家更好的理解PCA的计算步骤:




五、PCA参数解释
from sklearn.decomposition import PCA
从sklearn.decomposition导入PCA函数
PCA(n_components=None, copy=True, whiten=False, svd_solver=’auto’,tol=0.0, iterated_power=’auto’, random_state=None)
- n_components
功能:决定PCA算法应该保留的主成分数量。 取值: 整数k:表示保留前k个主成分。
小数(0,1]之间的数:表示保留的主成分的方差百分比,例如0.9表示保留90%的方差。 如果设置为None(默认值),则保留所有主成分。 - copy
功能:是否在运行算法时,将原始训练数据复制一份。 取值: True(默认值):复制数据,以免修改原始数据。
False:直接在原始数据上进行计算。 - whiten
功能:决定是否对数据进行白化处理。
取值:
True:对数据进行白化,即对每个特征进行归一化,使得每个特征的方差都为1。在某些应用中,白化可以提高数据的可解释性。
False(默认值):不进行白化。 - svd_solver
功能:决定使用的SVD(奇异值分解)求解器的类型。
取值:
‘auto’(默认值):根据输入数据的大小和特征数量自动选择最合适的求解器。
‘full’:使用传统的SVD方法,适用于较小的数据集。
‘arpack’:使用scipy库中的稀疏SVD实现,适用于大型数据集。
‘randomized’:使用一种随机算法来加快SVD的计算速度,适用于大型数据集且主成分数目较少的情况。 - tol
功能:决定奇异值分解的收敛容差。
取值:默认为0.0,表示使用默认的收敛容差。较小的值会产生更精确的结果,但也会增加计算时间。 - iterated_power
功能:决定幂迭代方法的迭代次数。
取值:默认为’auto’,表示使用一种启发式方法选择迭代次数。通常不需要手动调整这个参数。 - random_state
功能:决定随机数生成的种子
取值:如果设置为None,则随机生成器使用当前系统时间作为种子
设置为整数,则使用该整数作为随机数生成器的种子
六、代码实现
from sklearn.decomposition import PCA
import pandas as pd
from sklearn.model_selection import train_test_splitdata = pd.read_csv(r"./creditcard.csv")# 数据划分
X = data.iloc[:,:-1]
y = data.iloc[:,-1]pca = PCA(n_components=0.90) ## 实例化PCA对象
pca.fit(X) ##进行训练不需要传入yprint('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_)))
print(pca.explained_variance_ratio_)print('PCA降维后数据:')
new_x = pca.transform(X)
print(new_x) #数据X在主成分空间中的表示。具体来说,这个方法将数据X从原始特征空间转入x_train,x_test,y_train,y_test = \train_test_split(X,y,test_size=0.5,random_state=0)from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score #交叉验证的函数# 交叉验证选择较优惩罚因子
lr = LogisticRegression(penalty='l2')
lr.fit(x_train,y_train)from sklearn import metrics
train_predicted = lr.predict(x_train) #自测
print(metrics.classification_report(y_train,train_predicted))
# cm_plot(y_train,train_predicted).show()#预测结果
test_predicted = lr.predict(x_test) #小的数据集进行测试
print(metrics.classification_report(y_test,test_predicted)) #绘制混淆矩阵
下图是对数据使用PCA降维后得到的结果与未使用PCA降维后运行的结果,通过对比可知使用PCA对数据降维后模型的准确率稍微上升了一点,上升的不是很多。一般情况下,对数据使用PCA降维后模型性能应该会下降一点,因为降维会导致特征丢失。

七、PCA的优缺点
优点:
- 计算方法简单,容易实现
- 可以减少指标筛选的工作量
- 消除变量间的多重共线性
- 在一定程度上能减少噪声数据
缺点:
- 特征必须是连续型变量
- 无法解释降维后的数据是是什么
- 贡献率小的成分有可能更重要
八、总结
PCA作为一种经典且强大的降维工具,在机器学习领域有着广泛的应用。理解其数学原理和实现细节,能够帮助我们在实际项目中更好地使用它。需要注意的是,PCA并非适用于所有场景,在使用前应该仔细评估数据特性和需求,选择最合适的降维方法。
希望本文能帮助您掌握PCA的核心概念和应用技巧!
相关文章:
机器学习之PCA主成分分析详解
文章目录 引言一、PCA的概念二、PCA的基本数学原理2.1 内积与投影2.2 基2.3 基变换2.4 关键问题及优化目标2.5 方差2.6 协方差2.7 协方差矩阵2.8 协方差矩阵对角化 三、PCA执行步骤总结四、PCA计算实例五、PCA参数解释六、代码实现七、PCA的优缺点八、总结 引言 在机器学习领域…...

回溯——固定套路 | 面试算法12道
目录 输出二叉树所有路径 路径总和问题 组合总和问题 分割回文串 子集问题 排列问题 字母大小写全排列 单词搜索 复原IP地址 电话号码问题 括号生成问题 给我一种感觉是回溯需要画图思考是否需要剪枝。 元素个数n相当于树的宽度(横向)&#x…...

【11】Strongswan processor 详解1
processor_t结构体,声明了一些公用方法: get_total_threads获取总的线程数量; get_idle_threads获取空闲线程数量; get_working_threads按指定的优先级获取处理该优先级的job的线程数量; get_job_load 或取指定优先级j…...
Maven和MyBatis学习总结
目录 Maven 1.Maven的概念: 2.在具体的使用中意义: 3.与传统项目引入jar包做对比: 传统方式: 在maven项目当中: 4.在创建maven项目后,想要自定义一些maven配置 5.maven项目的结构 6.maven指令的生…...
)
普通通话CSFB方式(2g/3g)
一、CSFB的触发条件 当模块(或手机)驻留在 4G LTE网络 时,若发生以下事件,会触发CSFB流程: 主叫场景:用户主动拨打电话。被叫场景:接收到来电(MT Call)。紧急呼叫&…...

揭开人工智能与机器学习的神秘面纱:开发者的视角
李升伟 编译 人工智能(AI)和机器学习(ML)早已不再是空洞的流行语——它们正在彻底改变我们构建软件、做出决策以及与技术互动的方式。无论是自动化重复性任务,还是驱动自动驾驶汽车,AI/ML都是现代创新的核…...
AndroidTV 当贝播放器-v1.5.2-官方简洁无广告版
AndroidTV 当贝播放器 链接:https://pan.xunlei.com/s/VONXRf0g3cT0ECVt6GEsoODFA1?pwds4qv# AndroidTV 当贝播放器-v1.5.2-官方简洁无广告版...

BERT - MLM 和 NSP
本节代码将实现BERT模型的两个主要预训练任务:掩码语言模型(Masked Language Model, MLM) 和 下一句预测(Next Sentence Prediction, NSP)。 1. create_nsp_dataset 函数 这个函数用于生成NSP任务的数据集。 def cr…...

Python生成exe
其中的 -w 参数是 PyInstaller 用于窗口模式(Windowed mode),它会关闭命令行窗口的输出,这通常用于 图形界面程序(GUI),比如使用 PyQt6, Tkinter, PySide6 等。 所以: 如果你在没有…...
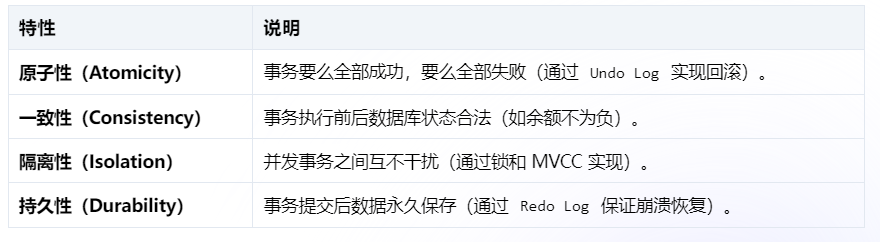
MySql 自我总结
目录 1. 数据库约束 1.1约束类型 2. 表的设计 2.1 一对一 2.2 一对多 2.3 多对多 3. 新增 4. 查询 4.1 聚合查询 4.2 GROUP BY 4.3 HAVING 4.4 联合查询 4.5 内连接 4.5.1 内连接的核心概念 4.5.2 内连接的语法 4.5.3 ON 与 WHERE 的区别 4.6 自连接 4.6.1 定…...
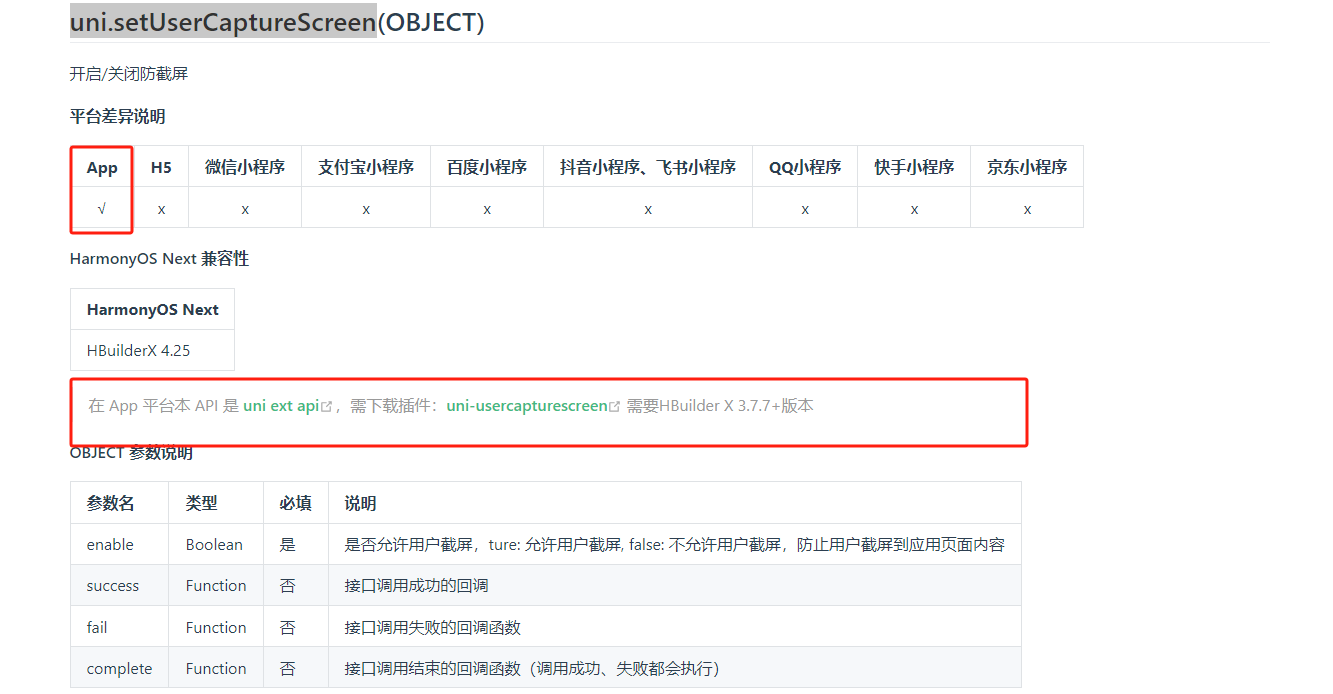
uni-app app 安卓和ios防截屏
首先可参考文档 uni.setUserCaptureScreen 这里需要在项目中引入这个插件 uni-usercapturescreen - DCloud 插件市场 否则会报错,在需要防止截屏录屏的页面中,加入 uni.setUserCaptureScreen({enable: false,success() {console.log(全局截屏录屏功能已禁用);},fail(err)…...
)
Android Input——查找并添加目标窗口(七)
在 Android 输入系统中,InputDispatcher 的核心职责之一是将输入事件正确地传递到目标窗口。上一篇文章我们介绍到 InputDispatcher 事件分发调用到 findFocusedWindowTargetsLocked() 函数查找焦点窗口,并将焦点窗口添加到目标窗口,这里我们继续往下看。 一、获取焦点窗口…...

ruby内置全局变量
以下是 Ruby 中常见的 内置全局变量 及其用途的详细说明。这些变量以 $ 开头,由 Ruby 解释器自动管理,用于访问系统状态、异常、输入输出等核心信息。 一、异常处理相关 全局变量说明示例$!当前作用域最后抛出的异常对象(等同于 rescue >…...

pytorch查询字典、列表维度
输出tensor变量维度 print(a.shape)输出字典维度 for key, value in output_dict.items():if isinstance(value, torch.Tensor):print(f"{key} shape:", value.shape)输出列表维度 def get_list_dimensions(lst):# 基线条件:如果lst不是列表࿰…...
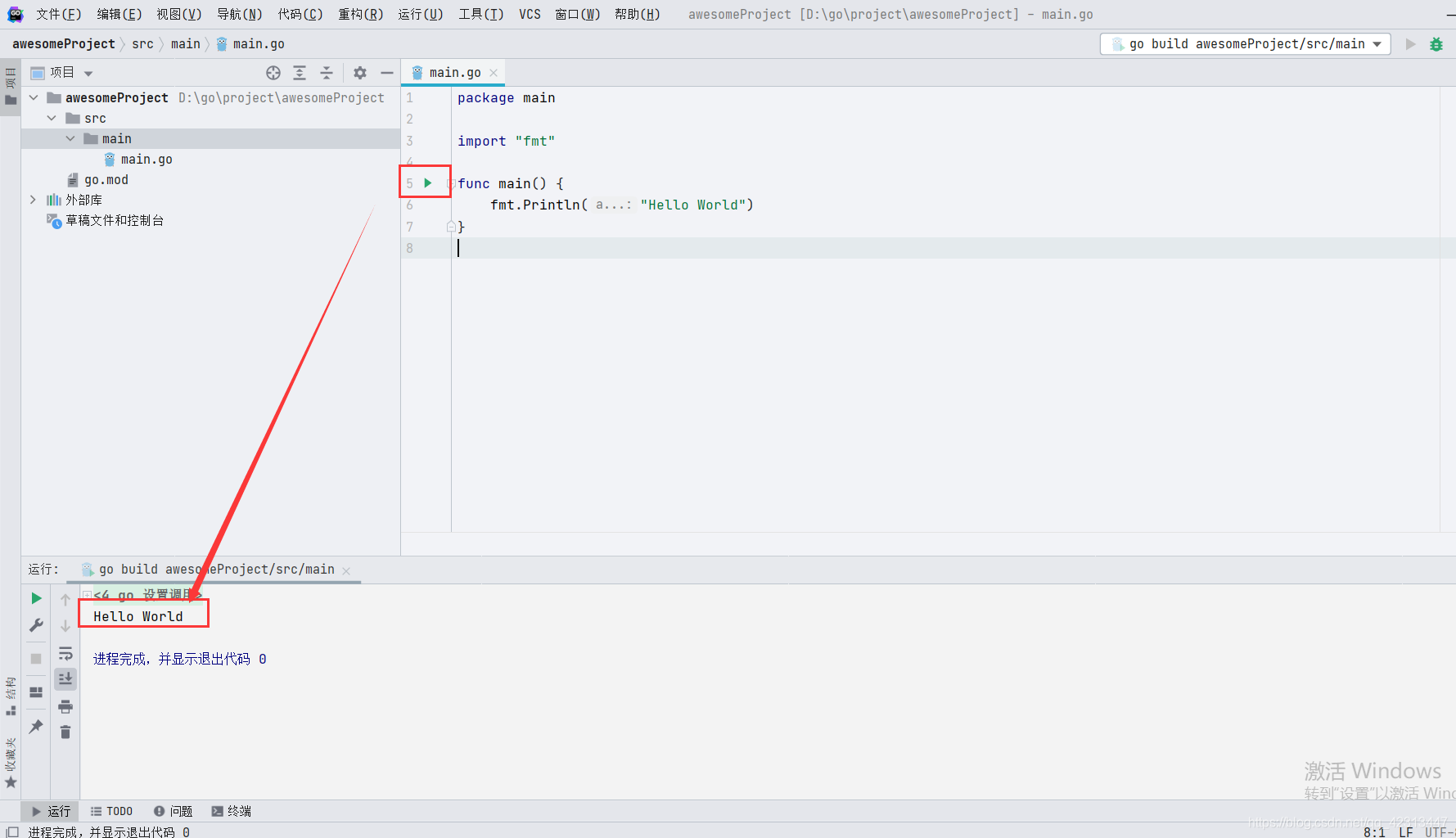
【Go】windows下的Go安装与配置,并运行第一个Go程序
【Go】windows下的Go安装与配置,并运行第一个Go程序 安装环境:windows10 64位 安装版本:go1.16 windows/amd64 一、安装配置步骤 1.到官方网址下载安装包 https://golang.google.cn/dl/ 默认情况下 .msi 文件会安装在 c:\Go 目录下。可自行配…...

Windows上使用Qt搭建ARM开发环境
在 Windows 上使用 Qt 和 g++-arm-linux-gnueabihf 进行 ARM Linux 交叉编译(例如针对树莓派或嵌入式设备),需要配置 交叉编译工具链 和 Qt for ARM Linux。以下是详细步骤: 1. 安装工具链 方法 1:使用 MSYS2(推荐) MSYS2 提供 mingw-w64 的 ARM Linux 交叉编译工具链…...
)
CNN(卷积神经网络)
什么是CNN CNN(卷积神经网络),是通过提取特征来压缩计算的一个网络结构,主要由卷积层、池化层、全连接层组成。 卷积层 在卷积层中,通过卷积核的移动对不同的区域提取特征生成一个新的矩阵,比如一个原始…...

Linux 内核网络协议栈中的 struct packet_type:以 ip_packet_type 为例
在 Linux 内核的网络协议栈中,struct packet_type 是一个核心数据结构,用于注册特定协议类型的数据包处理逻辑。它定义了如何处理特定协议的数据包,并通过协议类型匹配机制实现协议分发。本文将通过分析 ip_packet_type 的定义和作用,深入探讨其在网络协议栈中的重要性。 …...

网络问题之TCP/UDP协议
1. TCP是什么? TCP(Transmission Control Protocol,传输控制协议)是互联网核心协议之一,属于传输层协议,为应用程序提供可靠的、面向连接的字节流服务。 基本特性 可靠性:通过确认机制、重传机…...

vue3腾讯云直播 前端拉流(前端页面展示直播)
1、引入文件,在index.html <link href"https://tcsdk.com/player/tcplayer/release/v5.3.2/tcplayer.min.css" rel"stylesheet" /><!--播放器脚本文件--><script src"https://tcsdk.com/player/tcplayer/release/v5.3.2/t…...
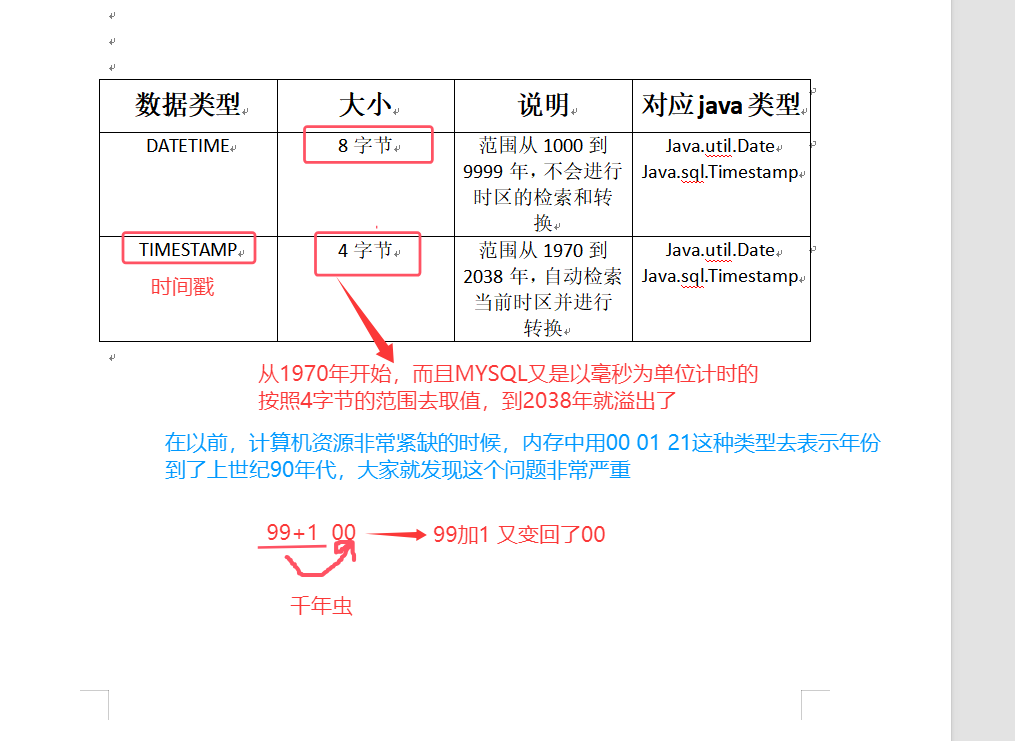
【MYSQL从入门到精通】数据库基础操作、数据类型
目录 一些基础操作语句 创建库名 选择要操作的数据库 删除数据库 磁盘中删除文件的原理 数据库安全的各种措置 查看MYSQL的帮助 数值类型 字符串类型 日期类型 一些基础操作语句 1.使用客户端工具连接数据库服务器:mysql -uroot -p 2.查看所有数据库&am…...

JS里对于集合的简单介绍
JS的集合 前言一、集合二、基本使用1. 创建集合2. 添加元素3. 删除元素4. 检查元素5. 清空集合6. 集合的大小 三、扩展使用1. 遍历集合2. 从数组创建集合3. 集合的应用场景 四、总结 前言 JS里对于集合的简单介绍 同数学的集合,有无序性、唯一性 注意:…...
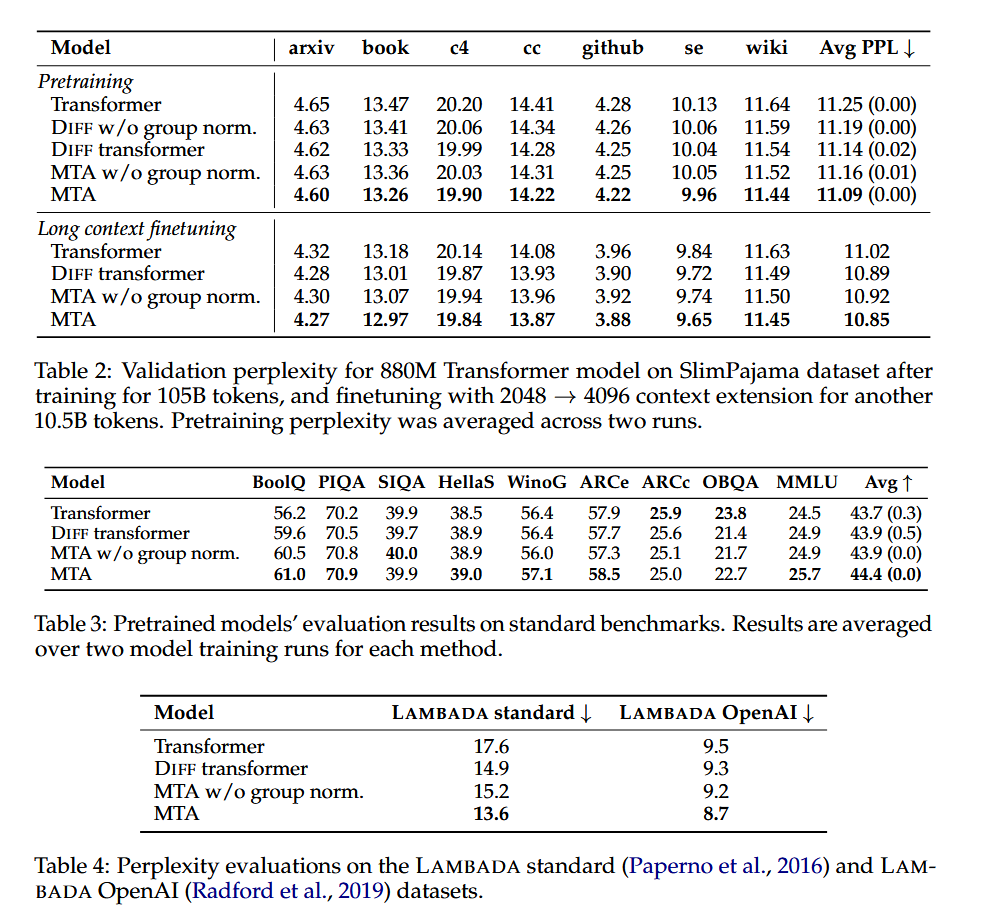
论文阅读笔记——Multi-Token Attention
MTA 论文 在 Transformer 中计算注意力权重时,仅依赖单个 Q 和 K 的相似度,无法有效捕捉多标记组合信息。(对于 A、B 两个词,单标记注意力需要分别计算两个词的注意力分数,再通过后处理定位共同出现的位置或通过多层隐…...

Sql with as 语句
在SQL查询中,经常会遇到需要重复使用的子查询。为了简化查询语句并提高可读性,SQL引入了WITH AS语法。通过使用WITH AS,我们可以创建临时表或视图,将子查询的结果保存起来,并在主查询中使用。本文将通过示例介绍SQL中W…...

vue3 antdesign table表格特定单元格背景变色
效果: <a-table :columns"columnsAll" :data-source"tableAllData"bordered size"middle" :scroll"{ x: 100,y: 600 }" :pagination"false"style"margin: 0 10px 10px 10px;" ><template #…...

【C语言】--- 编译和链接
编译和链接 1. 翻译环境和运行环境2. 翻译环境2.1 预处理2.2 编译2.2.1 词法分析2.2.2 语法分析2.2.3 语义分析 2.3 汇编2.4 链接 3. 运行环境 1. 翻译环境和运行环境 计算机只能运行二进制指令,所以我们的.c的文本程序需要先翻译为二进制程序才能被计算机执行。在…...

Qwen2.5-7B-Instruct FastApi 部署调用教程
1 环境准备 基础环境最低要求说明: 环境名称版本信息1Ubuntu22.04.4 LTSCudaV12.1.105Python3.12.4NVIDIA CorporationRTX 3090 首先 pip 换源加速下载并安装依赖包 # 升级pip python -m pip install --upgrade pip # 更换 pypi 源加速库的安装 pip config set g…...

深入解析Python爬虫技术:从基础到实战的功能工具开发指南
一、引言:Python 爬虫技术的核心价值 在数据驱动的时代,网络爬虫作为获取公开数据的重要工具,正发挥着越来越关键的作用。Python 凭借其简洁的语法、丰富的生态工具以及强大的扩展性,成为爬虫开发的首选语言。根据 Stack Overflow 2024 年开发者调查,68% 的专业爬虫开发者…...
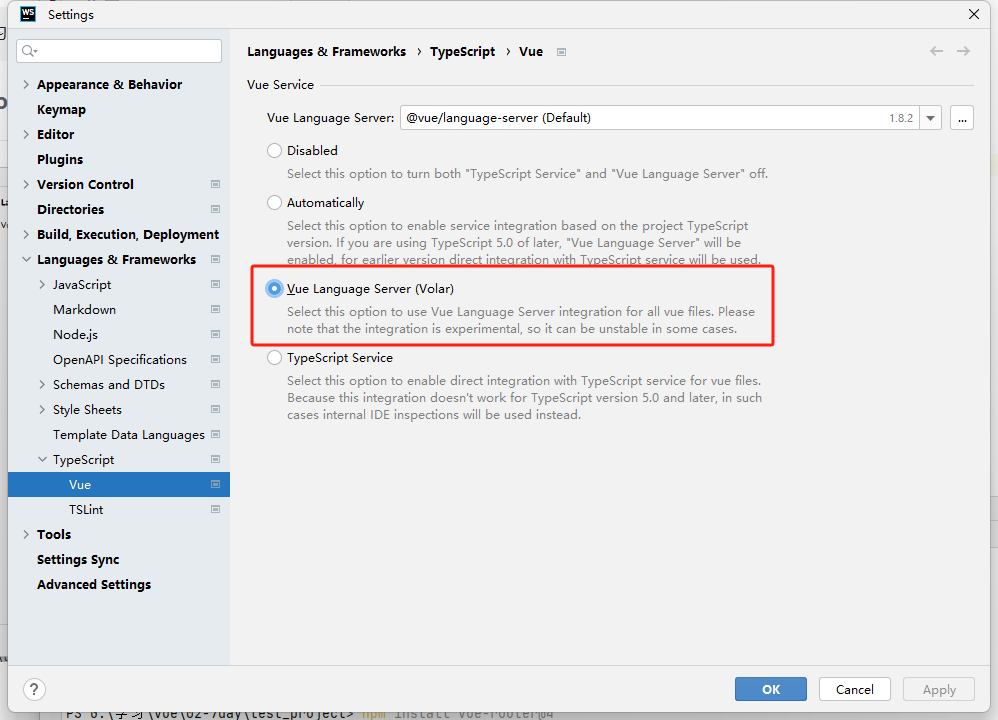
前端 Vue: Cannot find module XX or its corresponding type declarations.
记一个常见错误,每次创建完新的vuetsvite项目,在配置路由的时候总会找不到vue文件,我用的是Webstorm,在设置里面修改以下设置,即可消除警告。...
数字内容体验案例解析与行业应用
数字内容案例深度解析 在零售行业头部品牌的实践中,数字内容体验的革新直接推动了用户行为模式的转变。某国际美妆集团通过搭建智能内容中台,将产品信息库与消费者行为数据实时对接,实现不同渠道的动态内容生成。其电商平台首页的交互式AR试…...