【PyTorch项目实战】反卷积(Deconvolution)
文章目录
- 一、卷积(Convolution)
- 二、反卷积(Deconvolution) —— 又称去卷积
- 1. 反卷积(Richardson-Lucy,RL) —— —— 通过不断迭代更新图像估计值
- 2. 转置卷积(Transpose Convolution):torch.nn.ConvTranspose2d()
- (1)基础版本
- (2)增强版本:网络深度 + 残差网络 + 正则化
- 3. 分数步幅卷积(Fractionally Strided Convolution):torch.nn.ConvTranspose2d()
卷积(Convolution):是一种通过滑动窗口(卷积核)遍历整个图像,对每个像素进行加权求和的操作。
- 应用:
滤波器:如高斯滤波减少图像中的噪声、锐化滤波增强图像中的高频信息。边缘检测:如Sobel、Canny突出图像中的边缘。反卷积(Deconvolution):是卷积的逆运算,旨在通过迭代优化方法从模糊图像中恢复原始图像,减少模糊和失真。
- 常见算法:
Richardson-Lucy 反卷积:基于最大似然估计(MLE),通过迭代更新图像估计值来优化恢复效果。Wiener 反卷积:在频域中应用 Wiener 滤波,利用噪声功率谱进行去模糊。盲反卷积(Blind Deconvolution):同时估计模糊核(PSF)和原始图像,适用于未知模糊情况。
彻底搞懂CNN中的卷积和反卷积
GIF制作:卷积动画 + 转置卷积动画 + 膨胀卷积动画
一、卷积(Convolution)
卷积(Convolution)是一种数学操作,通常用于信号处理、图像处理和深度学习中,用于处理二维或多维数据。
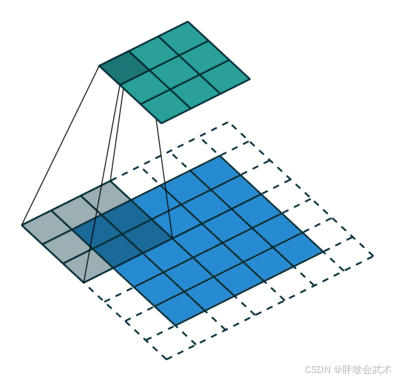
# 输入图像(input):下-蓝色区域(5, 5)
# 卷积核(kernel):下-移动阴影区域(3, 3)
# 填充(padding):下-白色区域(1)
# 步长(stride):下-卷积核每次滑动的长度(1)# 卷积核的卷积结果:上-移动阴影区域(1, 1)
# 输出图像(output):上-绿色区域(3, 3)
基于核函数的卷积操作(例如:高斯滤波)
二、反卷积(Deconvolution) —— 又称去卷积
反卷积(Deconvolution)、转置卷积(Transpose Convolution) 和 分数步幅卷积(Fractionally Strided Convolution) 是不同的概念。虽然它们有一定的相似性,但其应用、原理和实现方式是不同的。
- 1.
反卷积(Deconvolution)
- 概念:
是卷积的逆操作。采用最小化误差的方式迭代进行,最小化模糊图像与恢复图像之间的差异(例如 Richardson-Lucy)。- 应用:
- 去模糊:用于去除图像中的模糊,例如相机抖动引起的模糊。
- 盲反卷积:同时恢复图像和模糊核(PSF),用于图像恢复。
- 2.
转置卷积(Transpose Convolution)
- 概念:
并非严格意义上的反卷积。通过零填充(在每两个元素之间插入零)扩展输入图像的空间尺寸,然后再应用卷积操作,实现图像的上采样。- 应用:
- 图像生成:常用于生成对抗网络(GANs)中,将低分辨率的特征图恢复为高分辨率图像。
- 超分辨率:用于将低分辨率图像提升到更高的分辨率。
- 3.
分数步幅卷积(Fractionally Strided Convolution)
- 概念:
是一种介于标准卷积和转置卷积之间的操作。使用较小步幅(例如 1/2 或 1/4)进行卷积操作,实现图像的上采样。- 应用:
- 生成对抗网络(GANs):分数步幅卷积常用于生成对抗网络(GANs)中,用于图像的上采样。
1. 反卷积(Richardson-Lucy,RL) —— —— 通过不断迭代更新图像估计值
Richardson-Lucy (RL) 反卷积算法 —— 通过不断迭代更新图像估计值
2. 转置卷积(Transpose Convolution):torch.nn.ConvTranspose2d()
####################################################################
假设输入图像为 4x4,卷积核为 3x3,步长为 1,没有填充。输入图像(4x4)[ 1 2 3 45 6 7 89 10 11 1213 14 15 16 ]卷积核(3x3)[ 0 0 00 3 00 0 0 ]
####################################################################
1. 普通卷积输出图像(2x2)[ 18 2130 33]
2. 转置卷积(或反卷积)是卷积操作的“逆”过程,目的是将较小的特征图恢复成较大的特征图。(1)上采样:通过插入零将输入图像变为 6x6。插入的零是在图像的每两个相邻元素之间插入一个零。(2)该上采样后的图像与卷积核进行普通卷积操作,得到的输出图像尺寸将是 5x5。插值图像(7x7)[ 1 0 2 0 3 0 40 0 0 0 0 0 05 0 6 0 7 0 80 0 0 0 0 0 09 0 10 0 11 0 120 0 0 0 0 0 013 0 14 0 15 0 16 ]输出图像(5x5) [ 0 0 0 0 00 18 0 21 00 0 0 0 00 30 0 33 00 0 0 0 0 ]
(1)基础版本
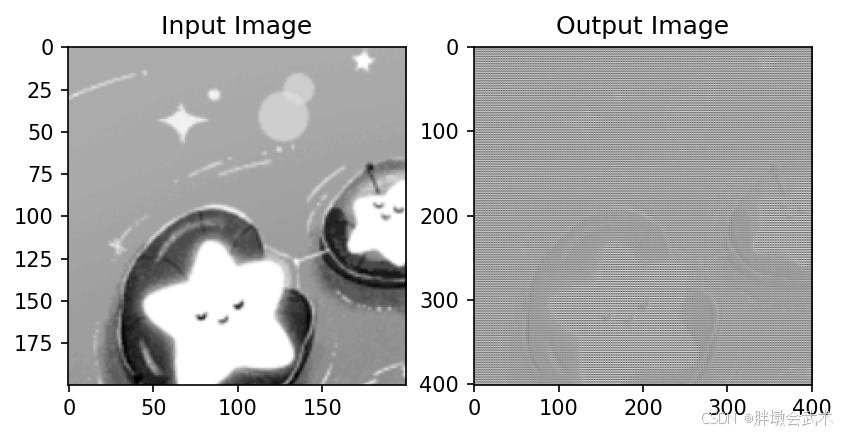
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import cv2
import numpy as npdef load_image(image_path):"""加载并预处理图像(灰度或彩色)"""img = cv2.imread(image_path) # 读取图像img = img[0:200, 0:200]if img.shape[2] == 3:img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图# img = cv2.resize(img, (64, 64)) # 调整图像大小为 64x64img = np.expand_dims(img, axis=0) # 添加批次维度img = np.expand_dims(img, axis=0) # 添加通道维度(如果是灰度图)img = torch.tensor(img, dtype=torch.float32) # 转换为 tensorimg /= 255.0 # 归一化至 [0, 1]return imgif __name__ == '__main__':# (1)加载图像input_image = load_image('image.jpg')print("Input size: ", input_image.shape) # torch.Size([1, 1, 245, 612])# (2)创建并执行转置卷积层conv_transpose = nn.ConvTranspose2d(in_channels=1, # 输入通道数,1代表灰度图,3代表RGB图out_channels=1, # 输出通道数kernel_size=3, # 卷积核大小stride=2, # 步幅padding=0, # 填充output_padding=0 # 输出填充)output_image = conv_transpose(input_image)print("Output size: ", output_image.shape) # torch.Size([1, 1, 491, 1225])"""####################################################################################Output Size = Stride × (Input Size − 1) + Kernel Size − 2 × Padding + Output Padding= 2 × (245 − 1) + 3 − 2 × 0 + 0 = 491= 2 × (612 − 1) + 3 − 2 × 0 + 0 = 1225####################################################################################"""# (3)可视化图像plt.subplot(1, 2, 1), plt.imshow(input_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Input Image')plt.subplot(1, 2, 2), plt.imshow(output_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Output Image')plt.show()"""####################################################################################
函数作用:二维转置卷积操作。将低维特征图上采样,生成高维特征图。
函数说明:
class torch.nn.ConvTranspose2d(in_channels: int,out_channels: int,kernel_size: Union[int, tuple[int, int]],stride: Union[int, tuple[int, int]] = 1,padding: Union[int, tuple[int, int]] = 0,output_padding: Union[int, tuple[int, int]] = 0,groups: int = 1,bias: bool = True,dilation: Union[int, tuple[int, int]] = 1,padding_mode: str = 'zeros',device: Any = None,dtype: Any = None
) -> None输入参数: in_channels: 输入张量的通道数。例如,输入图像是 RGB 图像,则通道数为 3;如果输入是灰度图,则为 1。out_channels: 输出张量的通道数,即卷积操作后的输出深度。通常根据需要的特征数来设置。kernel_size: 卷积核的大小。可以是一个整数(表示高度和宽度相同的卷积核),也可以是一个元组,指定高和宽的不同大小。例如 (3, 3) 或 3。stride: 步幅,用于控制上采样的倍数。步幅越大,输出的尺寸会越大。可以是一个整数或一个元组 (height, width),分别控制高度和宽度方向的步幅。padding: 输入的填充大小。可以是一个整数或一个元组 (height, width)。填充是为了保证卷积核能够覆盖图像的边界区域,避免丢失图像边缘的信息。output_padding: 输出填充,用于调节输出尺寸的参数。通常在应用转置卷积时,可以使用 output_padding 来确保输出尺寸与期望的尺寸匹配。groups: 分组卷积的分组数。用于深度可分离卷积等特定情况,通常保持为 1。分组卷积允许每个输入通道和输出通道分别进行卷积,从而减少参数数量。bias: 是否使用偏置项。如果为 True,则每个输出通道会添加一个可学习的偏置。dilation: 卷积核的膨胀大小,通常用于增加卷积的感受野。通过膨胀卷积核,可以增加卷积核元素之间的间距,从而扩展感受区域,增加对远距离像素的感知能力。padding_mode: 填充模式,控制填充的方式。常见的填充方式包括:"zeros"(默认值)、"reflect"、"replicate" 和 "circular"。device: 指定计算张量所使用的设备,如 'cpu' 或 'cuda'(GPU)。如果为 None,则默认使用当前默认设备。dtype: 指定张量的数据类型,如 torch.float32 或 torch.float64。如果为 None,则默认使用当前默认数据类型。
####################################################################################"""
(2)增强版本:网络深度 + 残差网络 + 正则化
为了增强反卷积的效果,你可以:
- 增加网络的深度,使用更复杂的网络结构。
- 加入正则化项,如 TV 正则化、Wiener 滤波,避免噪声放大。
- 采用批量归一化和残差网络,提高网络的稳定性和效果。
- 合理设置卷积核和步幅,确保特征不丢失且计算效率合理。
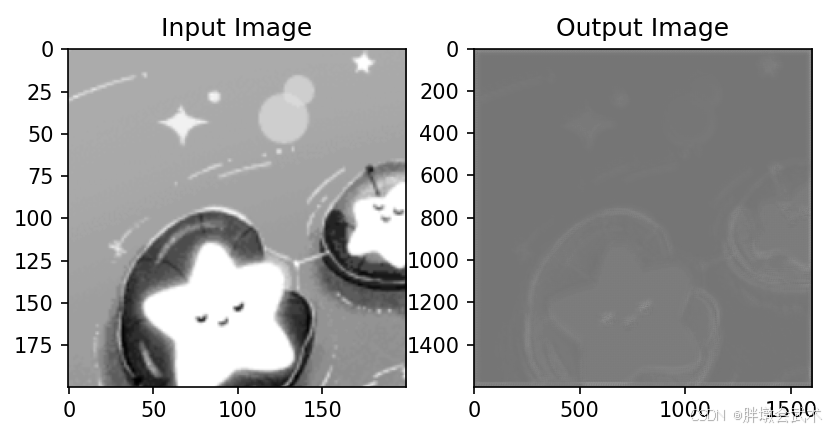
import torch
import torch.nn as nn
import torch.nn.functional as F
from skimage.restoration import denoise_tv_chambolle
import matplotlib.pyplot as plt
import numpy as np
import cv2def set_seed(seed=0):"""设置随机种子,确保可复现"""torch.manual_seed(seed) # 设置PyTorch在CPU上的随机种子,确保所有随机操作(如权重初始化、数据加载等)可复现# 设置CUDA的随机种子(用于GPU计算)torch.cuda.manual_seed(seed) # 为当前设备设置种子torch.cuda.manual_seed_all(seed) # 为所有GPU设备设置种子(如果使用多个GPU)import randomrandom.seed(seed) # 设置Python标准库中的random模块的随机种子import numpy as npnp.random.seed(seed) # 设置NumPy的随机数生成器种子torch.backends.cudnn.deterministic = True # 让PyTorch的卷积操作变得确定性(即每次运行时结果相同)torch.backends.cudnn.benchmark = False # 禁用CuDNN的自动优化,CuDNN会根据输入数据的形状和其他条件选择最优的计算算法(这通常会提高性能)。# TV 正则化
def tv_regularization(image, weight=0.1):"""应用 TV 正则化来去除噪声并保留边缘细节"""return denoise_tv_chambolle(image, weight=weight)# 残差块
class ResidualBlock(nn.Module):def __init__(self, in_channels):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)self.relu = nn.ReLU()def forward(self, x):residual = xx = self.relu(self.conv1(x))x = self.conv2(x)x += residual # 加入残差return self.relu(x)# 增强生成网络
class EnhancedGenerator(nn.Module):def __init__(self, in_channels=3, out_channels=3):super(EnhancedGenerator, self).__init__()# 卷积层self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)# 残差块self.resblock1 = ResidualBlock(256)self.resblock2 = ResidualBlock(256)# 转置卷积层(上采样)self.deconv1 = nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1)self.deconv2 = nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1)self.deconv3 = nn.ConvTranspose2d(64, out_channels, kernel_size=4, stride=2, padding=1)# 批量归一化self.bn1 = nn.BatchNorm2d(64)self.bn2 = nn.BatchNorm2d(128)self.bn3 = nn.BatchNorm2d(256)def forward(self, x):# 卷积过程x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = F.relu(self.bn3(self.conv3(x)))# 残差块x = self.resblock1(x)x = self.resblock2(x)# 转置卷积过程x = F.relu(self.deconv1(x))x = F.relu(self.deconv2(x))x = self.deconv3(x)# 应用 TV 正则化x = tv_regularization(x.squeeze().cpu().detach().numpy(), weight=0.1)x = torch.tensor(x, dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 转换为 Tensorreturn xdef load_image(image_path):"""加载并预处理图像(灰度或彩色)"""img = cv2.imread(image_path) # 读取图像print(f"Loaded image shape: {img.shape}") # Loaded image shape: (245, 612, 3)img = img[0:200, 0:200] # 截取图像区域if img.shape[2] == 3:img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图# img = cv2.resize(img, (200, 200)) # 调整图像大小为 200x200# img = np.transpose(img, (2, 0, 1)) # 将通道维度放在第一个维度img = np.expand_dims(img, axis=0) # 添加批次维度img = np.expand_dims(img, axis=0) # 添加通道维度(如果是灰度图)img = torch.tensor(img, dtype=torch.float32) / 255.0 # 转换为 tensor 并归一化至 [0, 1]return imgif __name__ == '__main__':set_seed(5) # 设置固定种子"""由于卷积层的权重是随机初始化的,因此每次训练开始时,权重会有所不同。这种随机性会影响到模型的训练结果。在默认情况下,PyTorch 会自动使用一些初始化方法来为转置卷积层的权重赋予随机值(权重+偏置),具体取决于卷积核的类型。"""# 加载图像input_image = load_image('image.jpg')print("Input size: ", input_image.shape) # Input size: torch.Size([1, 3, 200, 200])# 创建模型model = EnhancedGenerator(in_channels=1, out_channels=1)# 前向传播output_image = model(input_image) * 255print("Output size: ", output_image.shape) # Output size: torch.Size([1, 3, 1600, 1600])# 显示结果plt.subplot(1, 2, 1), plt.imshow(input_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Input Image')plt.subplot(1, 2, 2), plt.imshow(output_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Output Image')plt.show()
3. 分数步幅卷积(Fractionally Strided Convolution):torch.nn.ConvTranspose2d()
- 提出问题:在 PyTorch 中 ConvTranspose2d 只支持整数步幅(stride),而不支持浮动的步幅值,如 0.5。
- 解决方案:分数步幅卷积通过 " 将卷积核中的每个元素之间插入零 " 来模拟步幅小于 1 的效果。
在这种卷积过程中,会有零填充或者 " 空隙 " 出现在卷积操作中,使得输出尺寸变得更大。这个过程与普通的转置卷积(ConvTranspose2d)有些相似,因为它本质上是在做 上采样,但不使用传统的插值方法。

import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import cv2
import numpy as npdef set_seed(seed=0):"""设置随机种子,确保可复现"""torch.manual_seed(seed) # 设置PyTorch在CPU上的随机种子,确保所有随机操作(如权重初始化、数据加载等)可复现# 设置CUDA的随机种子(用于GPU计算)torch.cuda.manual_seed(seed) # 为当前设备设置种子torch.cuda.manual_seed_all(seed) # 为所有GPU设备设置种子(如果使用多个GPU)import randomrandom.seed(seed) # 设置Python标准库中的random模块的随机种子import numpy as npnp.random.seed(seed) # 设置NumPy的随机数生成器种子torch.backends.cudnn.deterministic = True # 让PyTorch的卷积操作变得确定性(即每次运行时结果相同)torch.backends.cudnn.benchmark = False # 禁用CuDNN的自动优化,CuDNN会根据输入数据的形状和其他条件选择最优的计算算法(这通常会提高性能)。def load_image(image_path):"""加载并预处理图像(灰度或彩色)"""img = cv2.imread(image_path) # 读取图像img = img[0:200, 0:200]if img.shape[2] == 3:img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图# img = cv2.resize(img, (64, 64)) # 调整图像大小为 64x64img = np.expand_dims(img, axis=0) # 添加批次维度img = np.expand_dims(img, axis=0) # 添加通道维度(如果是灰度图)img = torch.tensor(img, dtype=torch.float32) # 转换为 tensorimg /= 255.0 # 归一化至 [0, 1]return imgclass FractionalStrideConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=2):super(FractionalStrideConv2d, self).__init__()self.kernel_size = kernel_sizeself.stride = stride# 使用卷积操作,步幅为 1self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=kernel_size//2)def forward(self, x):batch_size, channels, height, width = x.size()# 计算新的高度和宽度,确保 stride 是整数new_height = height * self.stridenew_width = width * self.stride# 插入零到高和宽维度x = x.view(batch_size, channels, height, 1, width, 1) # 在每两个像素之间插入一个零# 扩展张量以插入零,确保传入的是整数x = x.expand(batch_size, channels, height, int(self.stride), width, int(self.stride)) # 扩展尺寸x = x.contiguous().view(batch_size, channels, new_height, new_width) # 重塑# 使用卷积x = self.conv(x)return xif __name__ == '__main__':set_seed(5) # 设置固定种子"""由于卷积层的权重是随机初始化的,因此每次训练开始时,权重会有所不同。这种随机性会影响到模型的训练结果。在默认情况下,PyTorch 会自动使用一些初始化方法来为转置卷积层的权重赋予随机值(权重+偏置),具体取决于卷积核的类型。"""# (1)加载图像input_image = load_image('image.jpg')print("Input size: ", input_image.shape) # torch.Size([1, 1, 245, 612])# input_image = torch.randn(1, 3, 64, 64) # 假设输入是 64x64 的 3 通道图像model = FractionalStrideConv2d(in_channels=1, out_channels=64, kernel_size=3, stride=2)output_image = model(input_image)print(output_image.shape) # 输出图像的尺寸model = FractionalStrideConv2d(in_channels=1, out_channels=64, kernel_size=3, stride=3)output_image2 = model(input_image)# 显示图像plt.figure(figsize=(8, 8))plt.subplot(1, 3, 1), plt.imshow(input_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Input Image')plt.subplot(1, 3, 2), plt.imshow(output_image[0, 0].detach().numpy(),cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Output Image(stride=2)')plt.subplot(1, 3, 3), plt.imshow(output_image2[0, 0].detach().numpy(),cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Output Image(stride=3)')plt.show()plt.show()相关文章:
【PyTorch项目实战】反卷积(Deconvolution)
文章目录 一、卷积(Convolution)二、反卷积(Deconvolution) —— 又称去卷积1. 反卷积(Richardson-Lucy,RL) —— —— 通过不断迭代更新图像估计值2. 转置卷积(Transpose Convoluti…...

SpringBoot无法访问静态资源文件CSS、Js问题
在做一个关于基于IDEASpringBootMaveThymeleaf的系统实现实验时候遇到了这个问题一直无法解决 后来看到一篇博客终于解决了。 springboot项目在自动生成的时候会有两个文件夹,一个是static,一个是templates,如果我们使用 <dependency><groupI…...

powerbi制作中国式复杂报表
今天主要想实现的功能是使用powerbi制作一个中国式的复杂报表,其中需要多表头,另外需要多个度量值如图我们最终要实现的样式是这样的: 错误示范 因为这些作为多表头的维度需要在同一行上作为不同的列显示所以他们需要来自于同一个字段&#…...

CMake中set_property接口及属性作用详解
在 CMake 中,set_property 是一个用于设置 属性(Property) 的核心命令。属性是 CMake 中用于控制构建过程的核心机制之一,可以理解为与特定对象(如目标、目录、源文件等)关联的键值对,用于存储配…...

设计模式——抽象工厂模式总结
理解了前面的工厂模式后,再理解抽象工厂模式就很容易了。 工厂模式:https://blog.csdn.net/inside802/article/details/147170118?spm1011.2415.3001.10575&sharefrommp_manage_link 抽象工厂模式就是工厂模式的更加抽象化,父类不仅不承…...

ChatGPT-如何让AI写作不那么生硬!
在使用聊天机器人撰写文章时,可能会遇到频繁使用“首先”、“其次”、“再次”等转折连接词,这会让文章显得呆板和机械,降低了阅读体验。 解决这个问题可以尝试以下方式! 多样化连接词: 使用更多多样的连接词和过渡短…...

禁止页面滚动的方法-微信小程序
在微信小程序中,有几种方法可以禁止页面滚动: 一、通过页面配置禁止滚动 在页面的JSON配置文件中设置,此方法完全禁止页面的滚动行为: {"disableScroll": true }二、通过 CSS 样式禁止滚动 在页面的WXSS文件中添加&…...
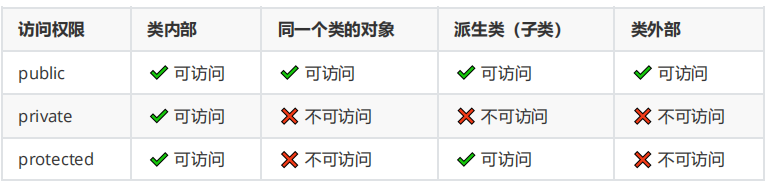
C++——继承、权限对继承的影响
目录 继承基本概念 编程示例 1.基类(父类)Person 代码特点说明 权限对类的影响 编辑 编程示例 1. 公有继承 (public inheritance) 2. 保护继承 (protected inheritance) 3. 私有继承 (private inheritance) 重要规则 实际应用 继承基本概…...
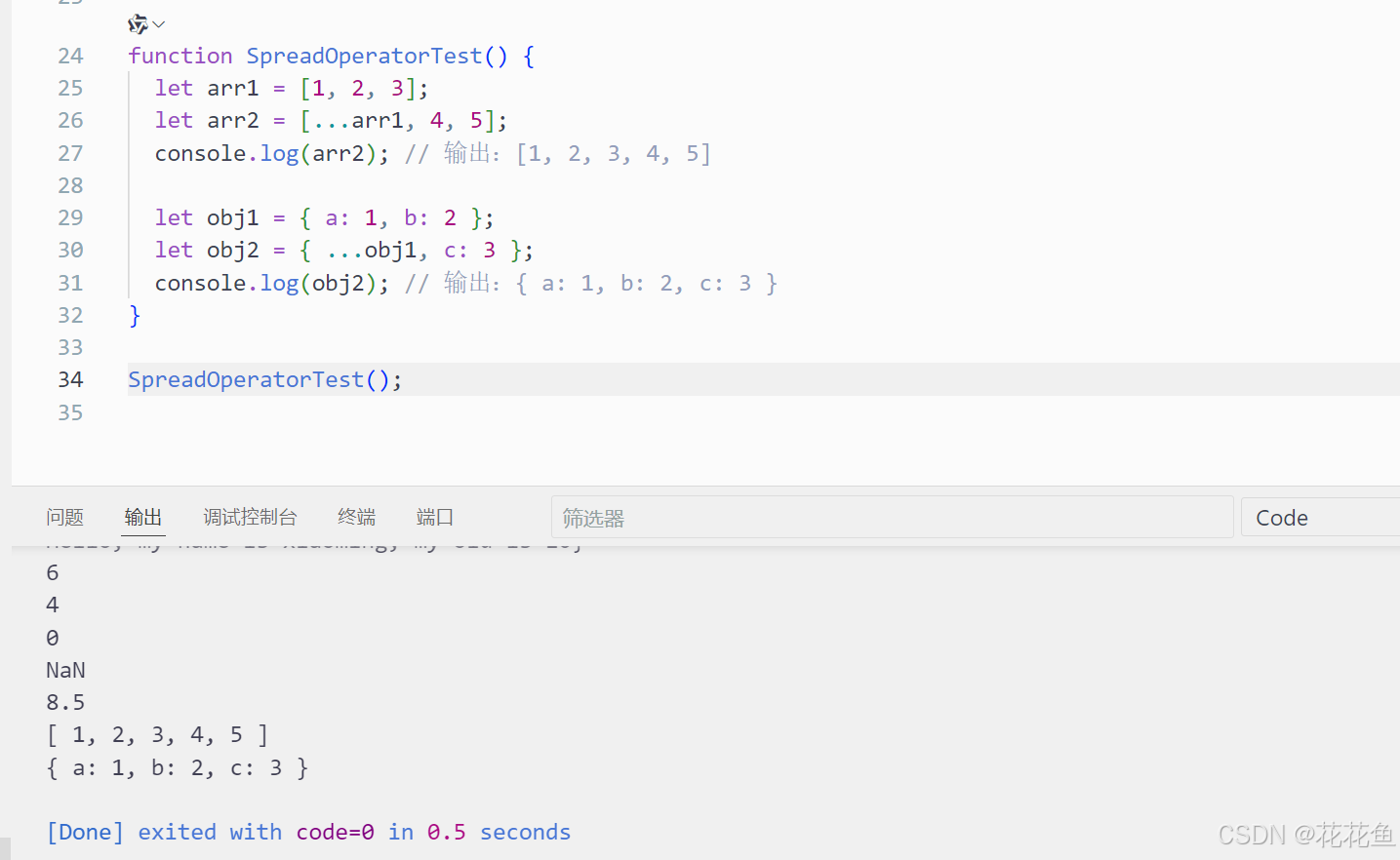
js中 剩余运算符(Rest Operator )(...)和展开运算符(Spread Operator)(...)的区别及用法
1、基本说明 在JavaScript中,剩余运算符(Rest Operator)和展开运算符(Spread Operator)虽然在某些方面有相似之处,但它们各自有不同的用途和功能。下面详细解释这两种运算符的区别: 1.1. 剩余…...
)
雅思练习总结(二十六)
雅思练习总结(二十六) 本文章是雅思练习总结(二十六),总结了文章《MAKING EVERYDROP COUNT》,内容包括原文精翻,文章脉络总结,单词扩展学习3个部分 1 文章原文及翻译 MAKING EVERYDROP COUNT 翻译:让每一滴水,都充满价值 A The history of human civilisation i…...
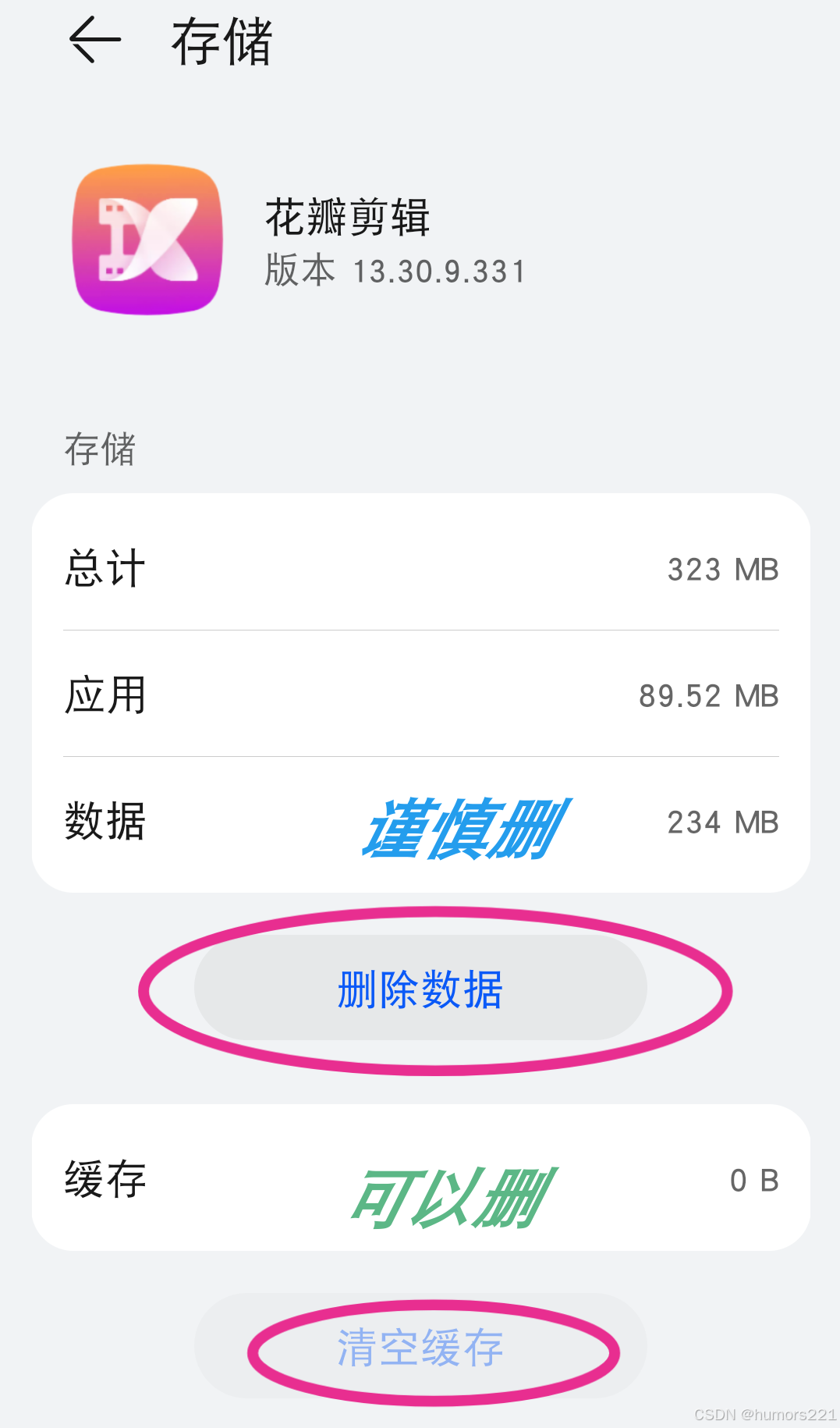
华为手机清理大数据的方法
清理手机最大的问题是,手动和自动清理了多次,花费了很长时间,但是只腾挪出来了一点点空间,还是有很大空间无法使用,这篇文章就告诉你怎样做,以花瓣剪辑为例,如下: 删除数据ÿ…...

单元测试原则之——不要过度模拟
什么是过度模拟? 过度模拟(over-mocking)是指在单元测试中,模拟了太多依赖项,甚至模拟了本不需要模拟的简单对象或行为。过度模拟会导致: 测试代码变得复杂,难以阅读和维护。测试逻辑偏离了实际业务逻辑,无法验证真实代码的行为。忽略了被测单元与依赖项之间的真实交互…...
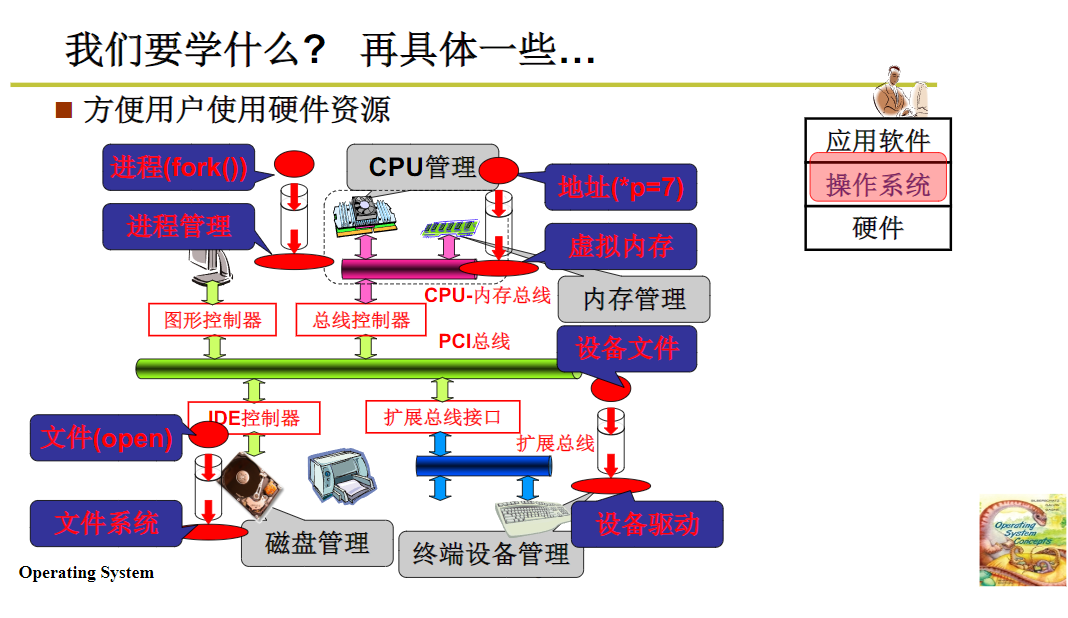
操作系统基础:07 我们的任务
课程回顾与后续规划 上节课我们探讨了操作系统的历史。了解历史能让我们明智,从操作系统的发展历程中,我们总结出两个核心的里程碑式图像:多进程(多任务切换)图像和文件操作图像 。Unix和Windows等系统的成功…...
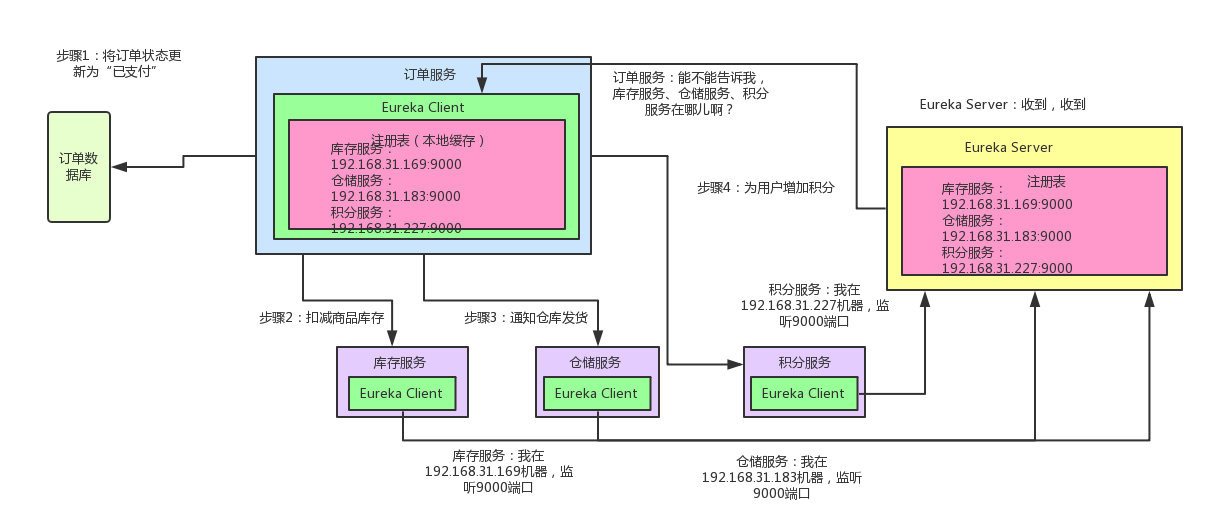
微服务的服务调用详解以及常见解决方案对比
微服务服务调用详解 1. 服务调用分类 服务调用根据通信方式、同步性、实现模式可分为以下类型: 按通信协议分类 类型典型协议/框架特点RPC(远程过程调用)Dubbo、gRPC、Apache Thrift高性能、二进制协议、强类型定义HTTP/RESTSpring RestTe…...

Verilog:LED呼吸灯
模块接口说明 信号方向描述clk输入系统时钟(100MHz,周期10ns)rst_n输入低电平有效的异步复位信号led_en输入总使能信号(1开启呼吸灯,0关闭)speed_en输入呼吸速度调节使能信号speed[2:0]输入呼吸速度分级&a…...
一个很好用的vue2在线签名组件
在前端开发的日常工作中,我们常常会遇到需要用户进行在线签名的需求,比如电子合同签署、表单确认等场景。最近,我在项目里使用了一款极为好用的 Vue2 在线签名组件,今天就来和大家分享一下使用心得。 效果图 上代码 在 views 下…...

C语言实现TcpDump
一、 在 C 语言中实现 TCP 抓包功能,通常可以使用 libpcap 库。libpcap 是一个广泛使用的网络抓包库,它提供了捕获网络数据包的接口。 libpcap 是一个广泛使用的 C 语言库,用于捕获和过滤网络数据包。它提供了一个通用接口,用于访…...
迁移学习|项目基本周期)
吴恩达深度学习复盘(14)迁移学习|项目基本周期
迁移学习 迁移学习是一种机器学习技术,它允许我们将从一个任务中学习到的知识应用到另一个相关的任务中。其核心思想在于,很多情况下,从头开始训练一个模型需要大量的数据和计算资源,而迁移学习能够复用在已有数据上训练好的模型…...

【STM32】STemWin库,使用template API
目录 CubeMX配置 工程文件配置 Keil配置 STemwin配置 GUIConf.c LCDConf.c 打点函数 修改屏幕分辨率 GUI_X.c 主函数 添加区域填充函数 移植过程中需要一些参考手册,如下 STemwin使用指南 emWin User Guide & Reference Manual CubeMX配置 参考驱…...
Matlab Add Legend To Graph-图例添加到图
Add Legeng To Graph: Matlab的legend()函数-图例添加到图 将图例添加到图 ,图例是标记绘制在图上的数据序列的有用方法。 下列示例说明如何创建图例并进行一些常见修改,例如更改位置、设置字体大小以及添加标题。您还可以创建具有多列的图…...

AI基础04-日志数据采集
上篇文章我们学习了视频的数据采集,今天主要了解一下日志数据采集的方法。日志数据采集的目的通常是:调试、运维监控和业务分析。调试主要是工程师在程序异常时针对关键环节把相关参数通过日志打印出来,找出哪个环节出现了问题。运维监控主要…...
)
文章记单词 | 第29篇(六级)
一,单词释义 AI /ˌeɪ ˈaɪ/ abbr. 人工智能(Artificial Intelligence)inventory /ˈɪnvəntri/ n. 存货清单;财产清单;库存货物;存货;v. 编制目录;开列清单;盘存cha…...
 字符串子链)
Arduino示例代码讲解:String substring() 字符串子链
Arduino示例代码讲解:String substring 字符串子链 String substring() 字符串子链程序功能概述功能:硬件要求:输出:代码结构`setup()` 函数`loop()` 函数创建字符串:提取子字符串:无限循环:运行过程代码输出解释原始字符串:提取子字符串:注意事项String substring() …...

2025年七星棋牌跨平台完整源码解析(200+地方子游戏+APP+H5+小程序支持,附服务器镜像导入思路)
目前市面上成熟的棋牌游戏源码很多,但能做到平台全覆盖、地方玩法丰富、交付方式标准化的系统却不多。今天这套七星棋牌2023完整源码具备安卓/iOS/H5/微信小程序端四端互通能力,附带200多款地方子游戏,还配备了后台管理与自动热更系统&#x…...

Odoo 部署本地 把現時的excel計算表格部署上odoo 教程
要将现有的 Excel 计算表格部署到 Odoo 平台上,您可以按照以下步骤进行操作: 将 Excel 表格中的数据转移到 Odoo 模块中:首先,您需要将 Excel 表格中的数据导出为 CSV 格式,然后可以使用 Odoo 的数据导入功能将这些数据…...

compose map 源码解析
目录 TileCanvas ZoomPanRotateState ZoomPanRotate 布局,手势处理完了,就开始要计算tile了 MapState TileCanvasState telephoto的源码已经分析过了.它的封装好,扩展好,适用于各种view. 最近又看到一个用compose写的map,用不同的方式,有点意思.分析一下它的实现流程与原…...
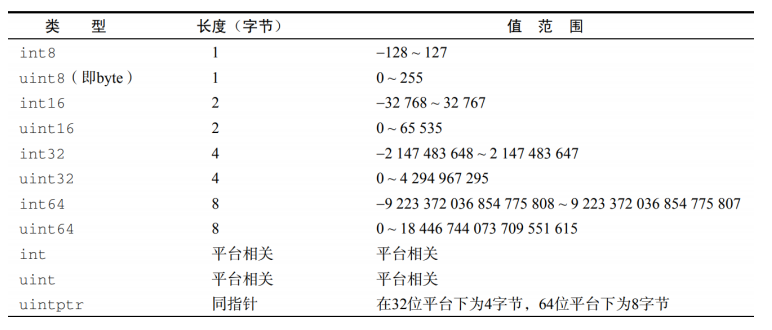
Go语言--语法基础4--基本数据类型--整数类型
整型是所有编程语言里最基础的数据类型。 Go 语言支持如下所示的这些整型类型。 需要注意的是, int 和 int32 在 Go 语言里被认为是两种不同的类型,编译器也不会帮你自动做类型转换, 比如以下的例子会有编译错误: var value2 in…...

mysql事务脏读 不可重复读 幻读 事务隔离级别关系
看了很多文档,发现针对事务并发执行过程中的数据一致性问题,即脏读、不可重复读、幻读的解释一塌糊涂,这也不能说什么,因为官方SQL标准中的定义也模糊不清。 按照mysql中遵循的事务隔离级别,可以梳理一下其中的关系 隔…...

智慧乡村数字化农业全产业链服务平台建设方案PPT(99页)
1. 农业全产业链概念 农业全产业链是依托数字化、电子商务、云计算等技术,整合规划咨询、应用软件设计与开发等服务,推动农业产业升级和价值重塑,构建IT产业融合新生态。 2. 产业链技术支撑 利用云计算、大数据、区块链等技术,为…...

信息系统项目管理师-软考高级(软考高项)2025最新(二)
个人笔记整理---仅供参考 第二章信息技术发展 2.1信息技术及其发展 2.1.1计算机软硬件 2.1.2计算机网络 2.1.3存储和数据库 2.1.4信息安全 公钥公开,私钥保密 2.1.5信息技术的发展 2.2新一代信息技术及应用 2.2.1物联网 2.2.2云计算 2.2.3大数据 2.2.4区块链 2.2.5…...