instructor 实现 reranker 功能
目录
- 代码
- 代码解释
- 1. 导入和初始化
- 2. Label 类定义
- 3. RerankedResults 类
- 4. 重排序函数
- 示例
- 类似例子
- 例子中的jinjia模板语法
- 变量
- 2. 控制结构
- 条件语句
- 循环语句
代码
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator, ValidationInfo# Initialize the OpenAI client with Instructor
client = instructor.from_openai(OpenAI(api_key = "your api key",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"))class Label(BaseModel):chunk_id: str = Field(description="The unique identifier of the text chunk")chain_of_thought: str = Field(description="The reasoning process used to evaluate the relevance")relevancy: int = Field(description="Relevancy score from 0 to 10, where 10 is most relevant",ge=0,le=10,)@field_validator("chunk_id")@classmethoddef validate_chunk_id(cls, v: str, info: ValidationInfo) -> str:context = info.contextchunks = context.get("chunks", [])if v not in [chunk["id"] for chunk in chunks]:raise ValueError(f"Chunk with id {v} not found, must be one of {[chunk['id'] for chunk in chunks]}")return vclass RerankedResults(BaseModel):labels: list[Label] = Field(description="List of labeled and ranked chunks")@field_validator("labels")@classmethoddef model_validate(cls, v: list[Label]) -> list[Label]:return sorted(v, key=lambda x: x.relevancy, reverse=True)def rerank_results(query: str, chunks: list[dict]) -> RerankedResults:return client.chat.completions.create(model="qwen-turbo",response_model=RerankedResults,messages=[{"role": "system","content": """You are an expert search result ranker. Your task is to evaluate the relevance of each text chunk to the given query and assign a relevancy score.For each chunk:1. Analyze its content in relation to the query.2. Provide a chain of thought explaining your reasoning.3. Assign a relevancy score from 0 to 10, where 10 is most relevant.Be objective and consistent in your evaluations.""",},{"role": "user","content": """<query>{{ query }}</query><chunks_to_rank>{% for chunk in chunks %}<chunk chunk_id="{{ chunk.id }}">{{ chunk.text }}</chunk>{% endfor %}</chunks_to_rank>Please provide a RerankedResults object with a Label for each chunk.""",},],context={"query": query, "chunks": chunks},)
代码解释
1. 导入和初始化
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator, ValidationInfoclient = instructor.from_openai(OpenAI(...))
- 使用 instructor 增强 OpenAI 功能
- 使用 Pydantic 进行数据验证和序列化
2. Label 类定义
class Label(BaseModel):chunk_id: str = Field(...)chain_of_thought: str = Field(...)relevancy: int = Field(..., ge=0, le=10)
定义了文本块的标签模型:
chunk_id: 文本块的唯一标识符chain_of_thought: 相关性评估的推理过程relevancy: 0-10的相关性得分
包含了一个验证器:
@field_validator("chunk_id")
def validate_chunk_id(cls, v: str, info: ValidationInfo) -> str:
确保 chunk_id 存在于输入的文本块列表中
3. RerankedResults 类
class RerankedResults(BaseModel):labels: list[Label]
- 存储所有标签的容器类
- 包含一个验证器,按相关性得分降序排序结果
4. 重排序函数
def rerank_results(query: str, chunks: list[dict]) -> RerankedResults:
核心功能:
- 接收查询和文本块列表
- 使用 AI 模型评估相关性
- 返回排序后的结果
系统提示设置:
- 定义 AI 为专家排序系统
- 提供评估标准和打分规则
用户提示模板:
- 使用 Jinja2 模板语法
- 动态插入查询和文本块
- 格式化为结构化的 XML 格式
这个系统的主要用途:
- 智能文本相关性排序
- 提供透明的推理过程
- 确保结果的一致性和可验证性
示例
def main():# Sample query and chunksquery = "What are the health benefits of regular exercise?"chunks = [{"id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890","text": "Regular exercise can improve cardiovascular health and reduce the risk of heart disease.",},{"id": "b2c3d4e5-f6g7-8901-bcde-fg2345678901","text": "The price of gym memberships varies widely depending on location and facilities.",},{"id": "c3d4e5f6-g7h8-9012-cdef-gh3456789012","text": "Exercise has been shown to boost mood and reduce symptoms of depression and anxiety.",},{"id": "d4e5f6g7-h8i9-0123-defg-hi4567890123","text": "Proper nutrition is essential for maintaining a healthy lifestyle.",},{"id": "e5f6g7h8-i9j0-1234-efgh-ij5678901234","text": "Strength training can increase muscle mass and improve bone density, especially important as we age.",},]# Rerank the resultsresults = rerank_results(query, chunks)# Print the reranked resultsprint("Reranked results:")for label in results.labels:print(f"Chunk {label.chunk_id} (Relevancy: {label.relevancy}):")print(f"Text: {next(chunk['text'] for chunk in chunks if chunk['id'] == label.chunk_id)}")print(f"Reasoning: {label.chain_of_thought}")print()main()
Reranked results:
Chunk a1b2c3d4-e5f6-7890-abcd-ef1234567890 (Relevancy: 10):
Text: Regular exercise can improve cardiovascular health and reduce the risk of heart disease.
Reasoning: This chunk directly discusses the health benefits of exercise, specifically improving cardiovascular health and reducing heart disease risk.Chunk c3d4e5f6-g7h8-9012-cdef-gh3456789012 (Relevancy: 8):
Text: Exercise has been shown to boost mood and reduce symptoms of depression and anxiety.
Reasoning: This chunk talks about how exercise can boost mood and reduce symptoms of depression and anxiety, which are health benefits.Chunk e5f6g7h8-i9j0-1234-efgh-ij5678901234 (Relevancy: 7):
Text: Strength training can increase muscle mass and improve bone density, especially important as we age.
Reasoning: Strength training's effects on muscle mass and bone density are health benefits associated with exercise.Chunk d4e5f6g7-h8i9-0123-defg-hi4567890123 (Relevancy: 2):
Text: Proper nutrition is essential for maintaining a healthy lifestyle.
Reasoning: While nutrition is important, this chunk does not discuss the health benefits of exercise itself.Chunk b2c3d4e5-f6g7-8901-bcde-fg2345678901 (Relevancy: 0):
Text: The price of gym memberships varies widely depending on location and facilities.
Reasoning: This chunk is about gym membership prices, which is unrelated to the health benefits of exercise.
类似例子
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator, ValidationInfo# 初始化 OpenAI 客户端
client = instructor.from_openai(OpenAI(api_key = "your api key",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"))class ReviewLabel(BaseModel):review_id: str = Field(description="评论的唯一标识符")chain_of_thought: str = Field(description="评估相关性的推理过程")relevancy: int = Field(description="相关性得分,0-10分,10分最相关",ge=0,le=10,)@field_validator("review_id")@classmethoddef validate_review_id(cls, v: str, info: ValidationInfo) -> str:context = info.contextreviews = context.get("reviews", [])if v not in [review["id"] for review in reviews]:raise ValueError(f"找不到ID为 {v} 的评论,必须是以下ID之一: {[review['id'] for review in reviews]}")return vclass RankedReviews(BaseModel):labels: list[ReviewLabel] = Field(description="已标记和排序的评论列表")@field_validator("labels")@classmethoddef model_validate(cls, v: list[ReviewLabel]) -> list[ReviewLabel]:return sorted(v, key=lambda x: x.relevancy, reverse=True)def rank_reviews(movie_title: str, reviews: list[dict]) -> RankedReviews:return client.chat.completions.create(model="qwen-turbo",response_model=RankedReviews,messages=[{"role": "system","content": """你是一个专业的电影评论分析专家。你的任务是评估每条评论与给定电影的相关性,并给出相关性得分。对每条评论:1. 分析评论内容与电影的相关程度2. 提供推理过程说明你的评分理由3. 给出0-10的相关性得分,10分表示最相关请保持客观和一致性。""",},{"role": "user","content": """<movie>{{ movie_title }}</movie><reviews_to_rank>{% for review in reviews %}<review review_id="{{ review.id }}">{{ review.text }}</review>{% endfor %}</reviews_to_rank>请提供一个包含每条评论标签的RankedReviews对象。""",},],context={"movie_title": movie_title, "reviews": reviews},)def main():# 示例数据movie_title = "泰坦尼克号"reviews = [{"id": "rev001","text": "这部电影完美展现了泰坦尼克号的悲剧,演员表演令人动容。",},{"id": "rev002","text": "最近电影票价格上涨了不少,看电影越来越贵了。",},{"id": "rev003","text": "Jack和Rose的爱情故事让人难忘,经典场景依然令人感动。",},{"id": "rev004","text": "这家电影院的爆米花很好吃,推荐尝试。",},{"id": "rev005","text": "电影的特效和场景还原都很精良,展现了那个年代的奢华。",},]# 对评论进行排序results = rank_reviews(movie_title, reviews)# 打印排序结果print("评论排序结果:")for label in results.labels:print(f"评论 {label.review_id} (相关性得分: {label.relevancy}):")print(f"内容: {next(review['text'] for review in reviews if review['id'] == label.review_id)}")print(f"推理过程: {label.chain_of_thought}")print()main()
评论排序结果:
评论 rev001 (相关性得分: 10):
内容: 这部电影完美展现了泰坦尼克号的悲剧,演员表演令人动容。
推理过程: 评论直接提到电影《泰坦尼克号》,并赞扬其悲剧展现和演员表演,明显与电影高度相关。评论 rev003 (相关性得分: 9):
内容: Jack和Rose的爱情故事让人难忘,经典场景依然令人感动。
推理过程: 评论聚焦于电影中的爱情故事和经典场景,与《泰坦尼克号》的主题紧密相关。评论 rev005 (相关性得分: 8):
内容: 电影的特效和场景还原都很精良,展现了那个年代的奢华。
推理过程: 评论称赞电影的特效和场景还原,这与《泰坦尼克号》的内容直接相关。评论 rev002 (相关性得分: 2):
内容: 最近电影票价格上涨了不少,看电影越来越贵了。
推理过程: 评论讨论的是电影票价上涨的问题,与具体电影《泰坦尼克号》无关,因此相关性较低。评论 rev004 (相关性得分: 1):
内容: 这家电影院的爆米花很好吃,推荐尝试。
推理过程: 评论谈论的是电影院的爆米花,与电影本身无直接关系,因此相关性很低。
例子中的jinjia模板语法
例子中用到Jinja 模板语法的核心概念:
变量
{{ 变量名 }}
用于在模板中插入变量值,例如:
"你好,{{ username }}" # 如果 username = "小明",输出: "你好,小明"
2. 控制结构
条件语句
{% if 条件 %}内容1
{% else %}内容2
{% endif %}
循环语句
{% for item in items %}{{ item }}
{% endfor %}
Jinja 模板的主要优势:
- 代码复用
- 逻辑与展示分离
- 动态内容生成
- 安全性(自动转义)
- 灵活的扩展性
这些特性使得 Jinja2 成为 Python 生态系统中最流行的模板引擎之一。
例子1:
from instructor.templating import handle_templating
from instructor.mode import Mode
# 输入参数示例
kwargs = {"messages": [{"role": "system","content": "你是一个专业的{{ domain }}助手"},{"role": "user","content": "请分析关于{{ topic }}的问题"}]
}mode = Mode.TOOLS # 使用 OpenAI 格式context = {"domain": "医疗","topic": "心脏病预防"
}# 调用函数
result = handle_templating(kwargs, mode, context)# 输出结果
print(result){'messages': [{'role': 'system', 'content': '你是一个专业的医疗助手'}, {'role': 'user', 'content': '请分析关于心脏病预防的问题'}]}
例子2:
query = "What are the health benefits of regular exercise?"
chunks = [{"id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890","text": "Regular exercise can improve cardiovascular health and reduce the risk of heart disease.",},{"id": "b2c3d4e5-f6g7-8901-bcde-fg2345678901","text": "The price of gym memberships varies widely depending on location and facilities.",},{"id": "c3d4e5f6-g7h8-9012-cdef-gh3456789012","text": "Exercise has been shown to boost mood and reduce symptoms of depression and anxiety.",},{"id": "d4e5f6g7-h8i9-0123-defg-hi4567890123","text": "Proper nutrition is essential for maintaining a healthy lifestyle.",},{"id": "e5f6g7h8-i9j0-1234-efgh-ij5678901234","text": "Strength training can increase muscle mass and improve bone density, especially important as we age.",},
]kwargs = {"messages": [{"role": "system","content": """You are an expert search result ranker. Your task is to evaluate the relevance of each text chunk to the given query and assign a relevancy score.For each chunk:1. Analyze its content in relation to the query.2. Provide a chain of thought explaining your reasoning.3. Assign a relevancy score from 0 to 10, where 10 is most relevant.Be objective and consistent in your evaluations.""",},{"role": "user","content": """<query>{{ query }}</query><chunks_to_rank>{% for chunk in chunks %}<chunk chunk_id="{{ chunk.id }}">{{ chunk.text }}</chunk>{% endfor %}</chunks_to_rank>Please provide a RerankedResults object with a Label for each chunk.""",},]
}context={"query": query, "chunks": chunks}mode = Mode.TOOLS # 使用 OpenAI 格式# 调用函数
handle_templating(kwargs, mode, context){'messages': [{'role': 'system','content': '\nYou are an expert search result ranker. Your task is to evaluate the relevance of each text chunk to the given query and assign a relevancy score.\n\nFor each chunk:\n1. Analyze its content in relation to the query.\n2. Provide a chain of thought explaining your reasoning.\n3. Assign a relevancy score from 0 to 10, where 10 is most relevant.\n\nBe objective and consistent in your evaluations.\n'},{'role': 'user','content': '\n<query>What are the health benefits of regular exercise?</query>\n\n<chunks_to_rank>\n\n<chunk chunk_id="a1b2c3d4-e5f6-7890-abcd-ef1234567890">\n Regular exercise can improve cardiovascular health and reduce the risk of heart disease.\n</chunk>\n\n<chunk chunk_id="b2c3d4e5-f6g7-8901-bcde-fg2345678901">\n The price of gym memberships varies widely depending on location and facilities.\n</chunk>\n\n<chunk chunk_id="c3d4e5f6-g7h8-9012-cdef-gh3456789012">\n Exercise has been shown to boost mood and reduce symptoms of depression and anxiety.\n</chunk>\n\n<chunk chunk_id="d4e5f6g7-h8i9-0123-defg-hi4567890123">\n Proper nutrition is essential for maintaining a healthy lifestyle.\n</chunk>\n\n<chunk chunk_id="e5f6g7h8-i9j0-1234-efgh-ij5678901234">\n Strength training can increase muscle mass and improve bone density, especially important as we age.\n</chunk>\n\n</chunks_to_rank>\n\nPlease provide a RerankedResults object with a Label for each chunk.\n'}]}
参考链接:https://github.com/instructor-ai/instructor/tree/main
相关文章:

instructor 实现 reranker 功能
目录 代码代码解释1. 导入和初始化2. Label 类定义3. RerankedResults 类4. 重排序函数 示例类似例子例子中的jinjia模板语法变量2. 控制结构条件语句循环语句 代码 import instructor from openai import OpenAI from pydantic import BaseModel, Field, field_validator, Va…...

门极驱动器DRV8353M设计(二)
目录 13.3.4.4 MOSFET VDS 感测 (SPI Only) 13.3.5 Gate Driver保护回路 13.3.5.1 VM 电源和 VDRAIN 欠压锁定 (UVLO) 13.3.5.2 VCP 电荷泵和 VGLS 稳压器欠压锁定 (GDUV) 13.3.5.3 MOSFET VDS过流保护 (VDS_OCP) 13.3.5.3.1 VDS Latched Shutdown (OCP_MODE 00b) 13.…...
学点概率论,打破认识误区
概率论是统计分析和机器学习的核心。掌握概率论对于理解和开发稳健的模型至关重要,因为数据科学家需要掌握概率论。本博客将带您了解概率论中的关键概念,从集合论的基础知识到高级贝叶斯推理,并提供详细的解释和实际示例。 目录 简介 基本集合…...
NVIDIA AI Aerial
NVIDIA AI Aerial 适用于无线研发的 NVIDIA AI Aerial 基础模组Aerial CUDA 加速 RANAerial Omniverse 数字孪生Aerial AI 无线电框架 用例构建商业 5G 网络加速 5G生成式 AI 和 5G 数据中心 加速 6G 研究基于云的工具 优势100% 软件定义通过部署在数字孪生中进行测试6G 标准化…...

OpenCV 关键点定位
一、Opencv关键点定位介绍 关键点定位在计算机视觉领域占据着核心地位,它能够精准识别图像里物体的关键特征点。OpenCV 作为功能强大的计算机视觉库,提供了多种实用的关键点定位方法。本文将详细阐述关键点定位的基本原理,深入探讨 OpenCV 中…...

C++ 重构muduo网络库
本项目参考的陈硕老师的思想 1. 基础概念 进程里有 Reactor、Acceptor、Handler 这三个对象 Reactor 对象的作用是监听和分发事件;Acceptor 对象的作用是获取连接;Handler 对象的作用是处理业务; 先说说 阻塞I/O,非阻塞I/O&…...

SDHC接口协议底层传输数据是安全的
SDHC(Secure Digital High Capacity)接口协议在底层数据传输过程中确实包含校验机制,以确保数据的完整性和可靠性。以下是关键点的详细说明: 物理层与数据链路层的校验机制 物理层(Electrical Layer)&…...
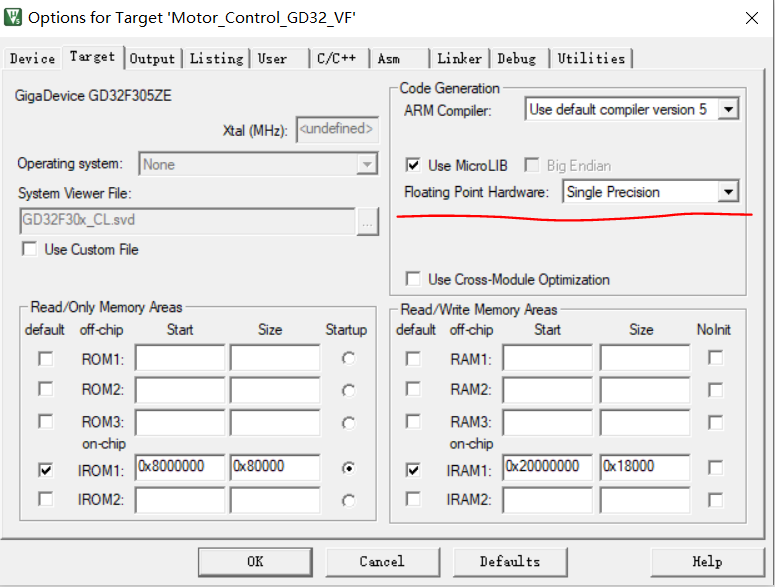
arm_math.h、arm_const_structs.h 和 arm_common_tables.h
在 FOC(Field-Oriented Control,磁场定向控制) 中,arm_math.h、arm_const_structs.h 和 arm_common_tables.h 是 CMSIS-DSP 库的核心组件,用于实现高效的数学运算、预定义结构和查表操作。以下是它们在 FOC 控…...

buuctf sql注入类练习
BUU SQL COURSE 1 1 实例无法访问 / Instance cant be reached at that time | BUUCTF但是这个地方很迷惑就是这个 一个 # 我们不抓包就不知道这个是sql注入类的判断是 get 类型的sql注入直接使用sqlmap我们放入到1.txt中 目的是 优先检测 ?id1>python3 sqlmap.py -r 1.t…...

具身导航中的视觉语言注意力蒸馏!Vi-LAD:实现动态环境中的社会意识机器人导航
作者:Mohamed Elnoor 1 ^{1} 1, Kasun Weerakoon 1 ^{1} 1, Gershom Seneviratne 1 ^{1} 1, Jing Liang 2 ^{2} 2, Vignesh Rajagopal 3 ^{3} 3, and Dinesh Manocha 1 , 2 ^{1,2} 1,2单位: 1 ^{1} 1马里兰大学帕克分校电气与计算机工程系, 2…...

全局前置守卫与购物车页面鉴权
在很多应用里,并非所有页面都能随意访问。例如购物车页面,用户需先登录才能查看。这时可以利用全局前置守卫来实现这一鉴权功能。 全局前置守卫的书写位置在 router/index.js 文件中,在创建 router 对象之后,暴露 router 对象之前…...

vue3 ts 自定义指令 app.directive
在 Vue 3 中,app.directive 是一个全局 API,用于注册或获取全局自定义指令。以下是关于 app.directive 的详细说明和使用方法 app.directive 用于定义全局指令,这些指令可以用于直接操作 DOM 元素。自定义指令在 Vue 3 中非常强大࿰…...
layui 弹窗-调整窗口的缩放拖拽几次就看不到标题、被遮挡了怎么解决
拖拽几次,调整窗口的缩放,就出现了弹出的页面,右上角叉号调不出来了,窗口关不掉 废话不多说直入主题: 在使用layer.alert layer.confirm layer.msg 等等弹窗时,发现看不到弹窗,然后通过控制台检查代码发现…...

网络空间安全(57)K8s安全加固
一、升级K8s版本和组件 原因:K8s新版本通常会引入一系列安全功能,提供关键的安全补丁,能够补救已知的安全风险,减少攻击面。 操作:将K8s部署更新到最新稳定版本,并使用到达stable状态的API。 二、启用RBAC&…...

2025蓝桥杯C++A组省赛 题解
昨天打完蓝桥杯本来想写个 p y t h o n python python A A A 组的题解,结果被队友截胡了。今天上课把 C A CA CA 组的题看了,感觉挺简单的,所以来水一篇题解。 这场 B B B 是一个爆搜, C C C 利用取余的性质比较好写&#…...
论文学习:《通过基于元学习的图变换探索冷启动场景下的药物-靶标相互作用预测》
原文标题:Exploring drug-target interaction prediction on cold-start scenarios via meta-learning-based graph transformer 原文链接:https://www.sciencedirect.com/science/article/pii/S1046202324002470 药物-靶点相互作用(DTI&…...

【题解-洛谷】P1824 进击的奶牛
题目:P1824 进击的奶牛 题目描述 Farmer John 建造了一个有 N N N( 2 ≤ N ≤...

机械革命 无界15X 自带的 有线网卡 YT6801 debian12下 的驱动方法
这网卡是国货啊。。。 而且人家发了驱动程序 Motorcomm Microelectronics. YT6801 Gigabit Ethernet Controller [1f0a:6801] 网卡YT6801在Linux环境中的安装方法 下载网址 yt6801-linux-driver-1.0.29.zip 我不知道别的系统是否按照说明安装就行了 但是debian12不行&…...
十八、TCP多线程、多进程并发服务器
1、TCP多线程并发服务器 服务端: #include<stdio.h> #include <arpa/inet.h> #include<stdlib.h> #include<string.h> #include <sys/types.h> /* See NOTES */ #include <sys/socket.h> #include <pthread.h>…...

JAVA中正则表达式的入门与使用
JAVA中正则表达式的入门与使用 一,基础概念 正则表达式(Regex) 用于匹配字符串中的特定模式,Java 中通过 java.util.regex 包实现,核心类为: Pattern:编译后的正则表达式对象。 Matcher&#…...

AIGC-文生图与图生图
在之前的文章中,我们知道了如何通过Web UI和Confy UI两种SD工具来进行图片生成,今天进一步地讲解其中的参数用处及如何调节。 文生图 参数详解 所谓文生图,就是通过文字描述我们想要图片包含的内容。初学的话,还是以Web UI为例…...
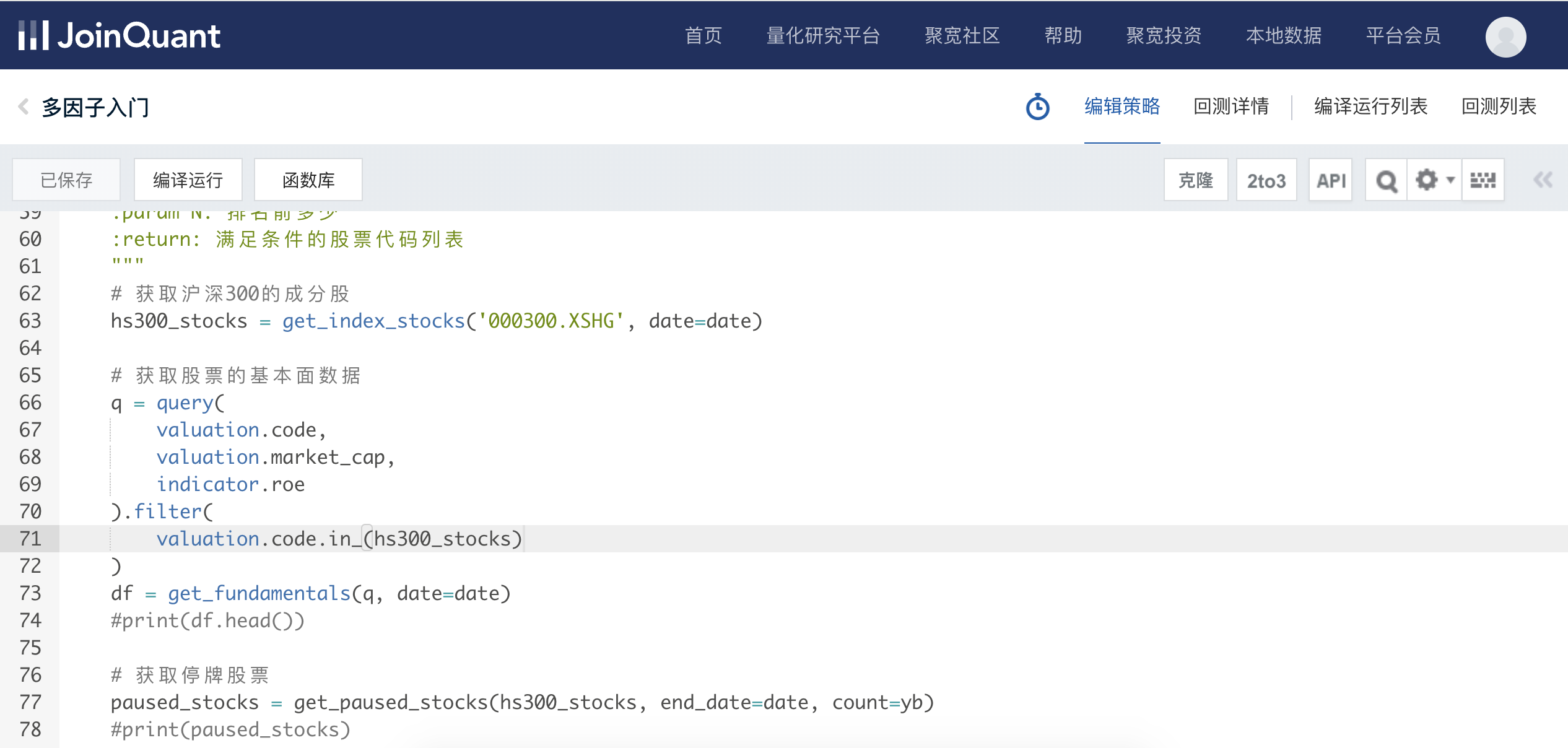
量化交易 - 聚宽joinquant - 多因子入门研究 - 源码开源
先看一下我们的收益: JoinQuant直达这里看看 下面讲解原理和代码。 目录 一、是否为st 二、是否停牌 三、市值小、roe大 四、编写回测代码 今天来研究一下多因子回测模型,这里以‘市值’、‘roe’作为例子。 几个标准:沪深300里选股&am…...

本地缓存方案Guava Cache
Guava Cache 是 Google 的 Guava 库提供的一个高效内存缓存解决方案,适用于需要快速访问且不频繁变更的数据。 // 普通缓存 Cache<Key, Value> cache CacheBuilder.newBuilder().maximumSize(1000) // 最大条目数.expireAfterWrite(10, TimeUnit.MINUTES) /…...
)
虚拟列表react-virtualized使用(npm install react-virtualized)
1. 虚拟化列表 (List) // 1. 虚拟化列表 (List)import { List } from react-virtualized; import react-virtualized/styles.css; // 只导入一次样式// 示例数据 const list Array(1000).fill().map((_, index) > ({id: index,name: Item ${index},description: This is i…...

解释型语言和编译型语言的区别
Python 的执行过程通常涉及字节码,而不是直接将代码编译为机器码。以下是详细的解释: ### **Python 的执行过程** 1. **源代码到字节码**: - Python 源代码(.py 文件)首先被编译为字节码(.pyc 文件&…...

猫咪如厕检测与分类识别系统系列【三】融合yolov11目标检测
✅ 前情提要 家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠…...

sql server 字段逗号分割取后面的值
在 SQL Server 中,如果你有一个字段(字段类型通常是字符串),其中包含用逗号分隔的值,并且你想提取这些值中逗号后面的特定部分,你可以使用多种方法来实现这一点。这里我将介绍几种常见的方法: …...

FPGA 37 ,FPGA千兆以太网设计实战:RGMII接口时序实现全解析( RGMII接口时序设计,RGMII~GMII,GMII~RGMII 接口转换 )
目录 前言 一、设计流程 1.1 需求理解 1.2 模块划分 1.3 测试验证 二、模块分工 2.1 RGMII→GMII(接收方向,rgmii_rx 模块) 2.2 GMII→RGMII(发送方向,rgmii_tx 模块) 三、代码实现 3.1 顶层模块 …...

上篇:《排序算法的奇妙世界:如何让数据井然有序?》
个人主页:strive-debug 排序算法精讲:从理论到实践 一、排序概念及应用 1.1 基本概念 **排序**:将一组记录按照特定关键字(如数值大小)进行递增或递减排列的操作。 1.2 常见排序算法分类 - **简单低效型**ÿ…...

红宝书第三十四讲:零基础学会单元测试框架:Jest、Mocha、QUnit
红宝书第三十四讲:零基础学会单元测试框架:Jest、Mocha、QUnit 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、单元测试是什么? 就像给代码做“体检”,帮你检查…...