【NLP】 18. Tokenlisation 分词 BPE, WordPiece, Unigram/SentencePiece
1. 翻译系统性能评价方法
在机器翻译系统性能评估中,通常既有人工评价也有自动评价方法:
1.1 人工评价
人工评价主要关注以下几点:
- 流利度(Fluency): 判断翻译结果是否符合目标语言的语法和习惯。
- 充分性(Adequacy): 判断翻译是否传达了原文的全部信息。
- 评价方式: 可以通过打分(Rate)、排序(Rank)以及编辑比较(Edit & Compare)的方式进行人工评测。
1.2 自动评价指标
自动评价方法常用的包括基于字符 n-grams 的指标(如 chrF)和基于单词 n-grams 的指标(如 BLEU)。
chrF 指标
- 基本思想:
将翻译结果与参考译文在字符级别进行 n-gram 匹配,适合于捕捉词形变化(如“read”与“Reading”),适合处理小写、标点、甚至拼写错误等情况。 - 常用公式:
-
精确率(Precision):
precision = TP / (TP + FP) -
召回率(Recall):
recall = TP / (TP + FN) -
F-beita 分数(F_β-score):
F β = ( ( 1 + β 2 ) ⋅ T P ) / ( ( 1 + β 2 ) ⋅ T P + β 2 ⋅ F N + F P ) F_β = ((1+β^2)·TP) / ((1+β^2)·TP + β^2·FN + FP) Fβ=((1+β2)⋅TP)/((1+β2)⋅TP+β2⋅FN+FP)
其中,beita 参数控制精确率和召回率之间的权重。例如,F2-score中 β= 2(公式:F2 = 5TP/(5TP + 4FN + FP)),而 F0-score 则相当于Precision, 当β很大的时候,相当于Recall
-
当所评估句子数量较多时,chrF 能有效反映字符级匹配情况,但当匹配以单词为单位时,可能出现“没有4-gram匹配得分为0”的情况,因此常配合其他指标综合评估。
BLEU 指标
- 基本思想:
BLEU 通过对比翻译输出与参考译文的单词 n-grams(通常计算一元、二元、三元和四元 n-grams)精确率,并取几何平均后乘以一个惩罚因子(brevity penalty)来处理生成句子较短的问题。 - 局限性:
由于BLEU只计算精确率,不考虑单词的形态变化(例如“read”和“Reading”在严格匹配时视为不同)以及上下文语序,且几何平均在数据量不足时敏感,常常无法完全反映翻译的流利性和充分性。
对比
BLEU vs. chrF
| 特征 | BLEU | chrF |
|---|---|---|
| 全称 | Bilingual Evaluation Understudy | Character n-gram F-score |
| 单位 | 基于词级别(word-level) | 基于字符级别(character-level) |
| 匹配单位 | n-gram(如词组) | 字符n-gram(如连续的字符组合) |
| 语言适用性 | 英语/法语等空格分词语言效果较好 | 对形态复杂语言(如德语、芬兰语、中文)效果更好 |
| 对词形变化的鲁棒性 | 差(如“run”和“runs”会被认为不同) | 好(字符n-gram可以捕捉到词形变化) |
| 对词序敏感 | 非常敏感 | 不那么敏感 |
| 评价精度 | 偏向于流畅性(fluency) | 更能捕捉语义和词形匹配(adequacy) |
| 惩罚机制 | 有 Brevity Penalty 惩罚过短的句子 | 没有专门惩罚机制 |
| 实现工具 | NLTK、SacreBLEU | 官方工具:chrF++,也在 SacreBLEU 中支持 |
2. Tokenisation 的基本概念与问题
Tokenisation(分词或词元化)指的是将一段文本切分为基本单元(token),如单词、标点符号或子词单元。传统方法多采用基于空格分割,但存在以下问题:
2.1 基于空格分词的局限性
- 简单的空格分割:
通常将文本按照空格拆分出各个 token,此方法对于英文等基于空格分词的语言基本适用。但在实际情况中会遇到:- 缩写问题: 如 “won’t” 表示 “will not”,空格分词时可能作为一个整体或拆分为 “won” 和 “'t”。
- 标点处理: 如 “great!” 中的感叹号有可能被保留或删除,不同工具处理方式不一致。
- 罕见词或变体: 如 “taaaaaaasty” 可能有多种变体,直接按空格分割,无法解决拼写变化或冗余重复问题。
- 拼写错误或新词: 如 “laern” (原意 learn)和 “transformerify” 这样的新造词也会被简单拆分,而无法充分捕捉原有语义。
2.2 Tokenisation 帮助处理罕见词等问题
通过更细粒度的分词方法,可以减少由于拼写错误、变形或新词带来的问题。例如,将长词拆成子词单元,可以使得词形变化不至于使整个单词无法识别。
- 实例:
- “laern” 拆分为 “la##”, “ern”。
这样一来,即使遇到拼写错误或不常见的词,模型也能通过子词组合部分捕捉到词语的语义,从而提高整体泛化能力。
- “laern” 拆分为 “la##”, “ern”。
3. 子词分割策略与方法
为了更好地处理词形变化、罕见词及新词,现有许多基于子词单位的分词算法。主要包括以下三类:
3.1 Byte-Pair Encoding (BPE)
BPE 的基本算法步骤为:
- 初始化词汇表:
将词汇表设置为所有单独的字符。 - 查找频率最高的相邻字符对:
遍历语料,找出最常在一起出现的两个字符或子词。 - 合并:
将这一对合并,生成一个新的子词单位,并更新整个语料中的分词表示。 - 检查词汇表大小:
如果词汇表大小未达到预设目标(例如 100,000),则返回步骤2继续合并,直到达到要求。
这种方法简单高效,常用于许多现代 NLP 框架中。
假设我们现在的训练语料有以下 4 个词:
1. low
2. lower
3. newest
4. widest
初始我们会把每个词都拆成字符 + 特殊结束符号 </w>来防止词和词连接在一起:
l o w </w>
l o w e r </w>
n e w e s t </w>
w i d e s t </w>
🔁 步骤 0:统计所有字符对频率
从上面所有词中,统计所有相邻字符对的频率(包括 </w>):
| Pair | Count |
|---|---|
| l o | 2 |
| o w | 2 |
| w | 1 |
| w e | 1 |
| e r | 1 |
| r | 1 |
| n e | 1 |
| e w | 1 |
| w e | 1 |
| e s | 2 |
| s t | 2 |
| t | 2 |
| w i | 1 |
| i d | 1 |
| d e | 1 |
注意:
w e出现了两次(一次是 “lower”,一次是 “newest”);e s、s t和t </w>是在 “newest” 和 “widest” 中反复出现的。
🔨 步骤 1:合并频率最高的字符对
我们假设 s t 是当前频率最高的(2 次)。那我们合并 s t → st。
现在变成:
l o w </w>
l o w e r </w>
n e w e st </w>
w i d e st </w>
🔁 步骤 2:重新统计字符对频率
重新统计所有字符对(只列几个):
| Pair | Count |
|---|---|
| l o | 2 |
| o w | 2 |
| e st | 2 |
| st | 2 |
| … | … |
我们发现 e st 和 st </w> 又很频繁 → 合并 e st → est
🔨 步骤 3:合并 e st → est
结果:
bashCopyEditl o w </w>
l o w e r </w>
n e w est </w>
w i d est </w>
你看,“newest” 和 “widest” 的后缀变成了统一的 est,这就是 BPE 的威力!
🔁 再来几轮(每次合并频率最高的)
假设继续合并:
| Round | 合并操作 | 影响 |
|---|---|---|
| 4 | l o → lo | 得到 lo w |
| 5 | lo w → low | 得到完整词 low |
| 6 | e r → er | 合并 “lower” 的尾部 |
| 7 | w e → we | 合并 “newest” 的 “we” 部分 |
| 8 | we + r → wer | 可得 “lower” 更完整 |
每合并一次,词汇表中就新增一个子词(如 low、est、er 等),最终我们就有一个子词词表,用于之后的分词。
✅ 最终效果(假设分词完成后):
| 原始词 | 分词结果 |
|---|---|
| low | low |
| lower | low + er |
| newest | new + est |
| widest | wid + est |
这样,即使将来出现一个从没见过的词,比如 bravest,我们也可以分成:
brav + est
🧠 总结亮点
- BPE 把频繁出现的字符组合合并成更长的单元;
- 最终词汇表里既有完整词(如
low),也有子词(如est,er); - 能处理拼写变化、形态变化、新词;
- 是 GPT、BERT、RoBERTa、T5 等模型使用的标准方法。
3.2 WordPiece
WordPiece 最早由 Google 提出,其主要步骤与 BPE 类似,但在合并步骤中使用更复杂的决策标准:
- 训练一个 n-gram 语言模型,
并考虑所有可能的词汇对,选择那个加入后能最大程度降低困惑度perplexity的组合; - HuggingFace 实现的 WordPiece 则有时选择使得合并后 token 的概率比例满足某个公式,例如选择使得
“|combined| / (|first symbol| * |second symbol|)” 最大的词对。
这种方法可在一定程度上更好地平衡子词与完整词的表达效果。
✂️ 分词示例(WordPiece)
以 playing 为例,假设词表中包含:
[ "play", "##ing", "##er", "##est", "##s" ]
那 playing 会被分为:
play + ##ing
再比如 unbelievable:
如果词表中有:
["un", "##believable", "##able", "##lievable", ...]
则可能被分为:
un + ##believable
(如果没有 “believable”,那就会继续拆成 ##believe + ##able)
🎯 WordPiece 构建流程(简要)
- 初始化词表:包含所有单字符 token(如 a, b, c,…);
- 基于最大似然概率计算所有可能合并的对;
- 每轮合并一对,使得整体训练语料的似然性最大;
- 直到词表达到预设大小(如 30,000 个 token)为止;
这比 BPE 更慢,但能得到更“语言合理”的子词。
🔍 分词过程总结
WordPiece 是一种贪心最长匹配算法,遵循以下原则:
- 从词首开始;
- 找到最长可匹配的 token(如 “unbelievable” → “un”);
- 然后从该点继续向右,查找
##前缀的匹配; - 直到整个词完成或无法继续拆分;
🧠 举个例子(完整流程)
假设词表里有:
["un", "##believe", "##able", "##believable"]
处理 unbelievable:
unbelievable→un+##believable
再处理 unbelievably:
如果 ##ly 也在词表中,就可以是:
un+##believable+##ly
如果 ##believable 不在词表中:
- 尝试
un+##believe+##able
✅ 总结
BPE 看频率,WordPiece 看语言模型概率。
WordPiece 更“聪明”,但 BPE 更“高效”。它们都用来解决“词太多”和“未知词”的问题。
WordPiece vs. BPE 的区别
| 特性 | BPE | WordPiece |
|---|---|---|
| 合并策略 | 每次合并频率最高的 pair | 每次合并带来最大 语言模型概率提升 的 pair |
| 评分标准 | 纯粹基于频率 | 基于最大似然估计(MLE) |
| 分词方式 | 贪心从左到右合并 | 也使用贪心,但遵循“最大匹配”原则 |
| 应用例子 | GPT、RoBERTa、OpenNMT | BERT、ALBERT、DistilBERT 等 |
| 词边标记 | 可无(GPT类) | 用 ## 表示词中间部分(如 play ##ing) |
3.3 Unigram / SentencePiece
Unigram 模型(或称 SentencePiece)采取另一种策略,不是从最小单元不断合并,而是:
- 初始化:
从所有字符以及语料中频率较高的连续字符序列(甚至包括完整单词)构建一个较大的初始词汇表; - 精简:
通过一种复杂的概率模型和迭代过程,逐步删除贡献较小的词汇项,直到词汇表达到预期大小。
这种方法的优势在于能够同时考虑大单元和小单元的信息,从而得到更优的子词表示。
用 Unigram 分词 internationalization
假设词表中有:
["international", "##ization", "inter", "##national", "##ize", "##ation", "##al", "##i", "##zation"]
Unigram 会考虑所有可能组合:
- international + ization
- inter + national + ization
- inter + nation + al + ization
- …
对每个组合计算 概率乘积(P(a) × P(b) × P© …),然后选取概率 最大的组合方式。
比如:
international + ization → P1
inter + national + ization → P2
inter + nation + al + ization → P3
选取 max(P1, P2, P3) 那个组合。
3.4 各方法的比较
- BPE: 简单、直接,广泛应用,合并依据频率;
- WordPiece: 考虑对语言模型困惑度的影响,通常效果更好,但实现较复杂;
- Unigram/SentencePiece: 允许初始词汇同时包含较大和较小单元,通过概率模型精简词汇,具有更大的灵活性。
Unigram vs. BPE/WordPiece
| 特性 | Unigram(SentencePiece) | BPE | WordPiece |
|---|---|---|---|
| 分词方式 | 选择概率最高的子词组合(非贪心) | 左到右合并字符对(贪心) | 贪心最长匹配 |
| 词表生成方式 | 预设大词表 → EM算法删掉低概率的子词 | 每轮合并频率最高的 pair | 每轮合并最大增益的 pair |
| 分词结果是否唯一 | ❌ 可能多个组合概率差不多 | ✅ 唯一贪心路径 | ✅ 贪心最长匹配 |
| 优点 | 更灵活,能找到最优子词拆法 | 简单快速 | 精确但复杂 |
| 模型代表 | ALBERT, XLNet, T5, mBART, SentencePiece | RoBERTa, GPT, MarianMT | BERT, DistilBERT |
| 特殊符号 | 不需要空格、可直接处理未空格文本 | 需提前空格/处理标记 | 通常需要空格 |
4. 特殊常见词(例如“the”)的处理
在分词和词嵌入训练中,常见词(如 “the”、“is”、“and” 等)通常出现频率极高,这会带来两个问题:
- 模型训练时的影响:
高频词容易主导模型权重,导致训练过程中对低频实义词的信息关注不足。为此,许多方法会在训练时对这些高频词进行下采样(sub-sampling),降低它们在训练中的出现频率。 - 评价指标的匹配:
在翻译评价、自动摘要或其他生成任务中,通常不希望因为 “the” 这种功能词的不同写法(例如大小写问题)产生低分。在实际 tokenisation 中,往往会将所有单词统一小写,或者对停用词单独处理,从而确保这些高频但语义信息较弱的词对整体模型影响较小。
例如,在 BLEU 计算中,尽管 “read” 和 “Reading” 在大小写和形态上有所不同,但通常在预处理阶段会进行小写化;而在子词分割中,“the” 可能不再被拆分,因为它本身已经十分常见而且具有固定形式。因此,“the” 通常被保留为一个完整的 token,同时在训练和评价中通过下采样等方式控制其权重。
5. 实际案例补充
假设我们有一段英文文本作为翻译系统的输入与参考译文,并希望利用自动评价指标来评估翻译质量,同时考虑分词细节:
案例 1:翻译评价中 chrF 指标计算
- 参考译文: “I like to read too”
- 机器译文: “Reading, I too like”
- 处理流程:
-
分词:
利用子词分割策略处理标点和缩写,确保“Reading”可以与“read”在字符 n-gram 层面匹配。 -
计算字符 n-gram 匹配:
对机器译文和参考译文分别计算字符 n-grams,再计算精确率和召回率。 -
Fbeita 分数计算:
-
结果说明:
通过字符匹配,可以部分容忍由于词形变化(例如 “read” 与 “Reading”)而带来的微小差异。
-
案例 2:使用 BPE 处理新词
假设文本中出现一个新词 “transformerify”,传统的词汇表中可能未收录。通过 BPE 分词过程:
- 初始化:
将 “transformerify” 拆分为单个字符,即 [“t”, “r”, “a”, “n”, “s”, “f”, “o”, “r”, “m”, “e”, “r”, “i”, “f”, “y”]。 - 迭代合并:
统计在整个语料中最频繁出现的相邻字符对,如果 “er” 出现次数最多,则将“e”与“r”合并为 “er”。不断进行,直到达到预定词汇大小。 - 结果:
最终可能将 “transformerify” 分割为 “transforme” 和 “##ify”,使得即使新词未见过,也能利用已有的子词表示捕捉部分语义。
相关文章:

【NLP】 18. Tokenlisation 分词 BPE, WordPiece, Unigram/SentencePiece
1. 翻译系统性能评价方法 在机器翻译系统性能评估中,通常既有人工评价也有自动评价方法: 1.1 人工评价 人工评价主要关注以下几点: 流利度(Fluency): 判断翻译结果是否符合目标语言的语法和习惯。充分性…...

Android游戏逆向工程全面指南
文章目录 第一部分:基础概念与环境搭建1.1 游戏逆向工程概述1.2 法律与道德考量1.3 开发环境准备基础工具集:环境配置示例: 第二部分:静态分析技术2.1 APK反编译与资源提取使用Apktool解包:关键文件分析: 2…...

ip route show 命令详解
《Linux 中 ip route show 输出结果解析及关键概念》 以下是对 ip route show 输出结果的详细解析,帮助你理解每条路由的含义及作用: 一、路由表整体结构 Linux 路由表中的每条条目包含 目标网络 / 主机、下一跳网关、出接口、路由协议、作用域、源地…...

antv x6使用(支持节点排序、新增节点、编辑节点、删除节点、选中节点)
项目需要实现如下效果流程图,功能包括节点排序、新增节点、编辑节点、删除节点、选中节点等 html部分如下: <template><div class"MindMapContent"><el-button size"small" click"addNode">新增节点&…...

DP主站如何华丽变身Modbus TCP网关!
DP主站如何华丽变身Modbus TCP网关! 在工业自动化领域,Profibus DP和Modbus TCP是两种常用的通信协议。Profibus DP通常应用于制造业自动化场景,而Modbus TCP则广泛使用于工业自动化和楼宇自动化等领域。为了实现这两种协议之间的互联互通&a…...

榕壹云在线商城系统:基于THinkPHP+ Mysql+UniApp全端适配、高效部署的电商解决方案
项目背景:解决多端电商开发的痛点 随着移动互联网的普及和用户购物习惯的碎片化,传统电商系统面临以下挑战: 1. 多平台适配成本高:需要同时开发App、小程序、H5等多端应用,重复开发导致资源浪费。 2. 技术依赖第三方…...

Pinia最基本用法
1. 定义 Store 首先,定义一个 Pinia Store,使用组合式 API 风格和 ref 来管理状态。 示例:stores/ids.js import { defineStore } from pinia; import { ref } from vue;export const useIdsStore defineStore(ids, () > {const ids …...

Android studio打包uniapp插件
一.参考资料与环境准备 原生工程配置需要使用到Android studio和HbuilderX 当前测试的as版本-20240301,下载地址:HbuilderX版本:4.36 二.插件创建流程 1.导入下载的UniPlugin-Hello-AS工程(下载地址见参考资料) 2.生成jks证书…...
App Cleaner Pro for Mac 中 Mac软件卸载工具
App Cleaner Pro for Mac 中 Mac软件卸载工具 一、介绍 App Cleaner & Uninstaller Pro Mac破解,是一款Mac软件卸载工具,残余垃圾清除工具!可以卸载应用程序或只删除不需要的服务文件,甚至可以删除以前删除的应用程序中的文…...

多线程与Tkinter界面交互
在现代图形用户界面(GUI)应用程序中,可能会遇到需要长时间运行的任务,例如网络请求、数据处理或文件读取等。如果这些任务直接在主线程中运行,会导致GUI界面“卡顿”或“不响应”。为了保持界面流畅和响应用户操作,我们可以通过使用多线程来将这些任务移到后台运行。然而…...
开发规范——Restful风格
目录 Restful Apifox 介绍 端口号8080怎么来的? 为什么要使用Apifox? Restful 如果请求方式是Post,那我就知道了要执行新增操作,要新增一个用户 如果请求方式是Put,那就代表我要修改用户 具体要对这些资源进行什么样的操…...

大模型——Llama Stack快速入门 部署构建AI大模型指南
Llama Stack快速入门 部署构建AI大模型指南 介绍 Llama Stack 是一组标准化和有主见的接口,用于如何构建规范的工具链组件(微调、合成数据生成)和代理应用程序。我们希望这些接口能够在整个生态系统中得到采用,这将有助于更轻松地实现互操作性。 Llama Stack 定义并标准化…...

符号右移“ >>= “ 与 无符号右移“ >>>= “ 的区别
符号右移" >> " 与 无符号右移" >>> " 的区别 一、符号右移" >> " 与 无符号右移" >>> " 的区别1. 符号右移(>>)与无符号右移(>>>)的区别…...

利用阿里云企业邮箱服务实现Python群发邮件
目录 一、阿里云企业邮箱群发邮件全流程实现 1. 准备工作与环境配置 2. 收件人列表管理 3. 邮件内容构建 4. 附件添加实现 5. 邮件发送核心逻辑 二、开发过程中遇到的问题与解决方案 1. 附件发送失败问题 2. 中文文件名乱码问题 3. 企业邮箱认证失败 三、完整工作流…...

探秘 Ruby 与 JavaScript:动态语言的多面风采
1 语法特性对比:简洁与灵活 1.1 Ruby 的语法优雅 Ruby 的语法设计旨在让代码读起来像自然语言一样流畅。它拥有简洁而富有表现力的语法结构,例如代码块、符号等。 以下是一个使用 Ruby 进行数组操作的简单示例: # 定义一个数组 numbers [1…...
08-JVM 面试题-mk
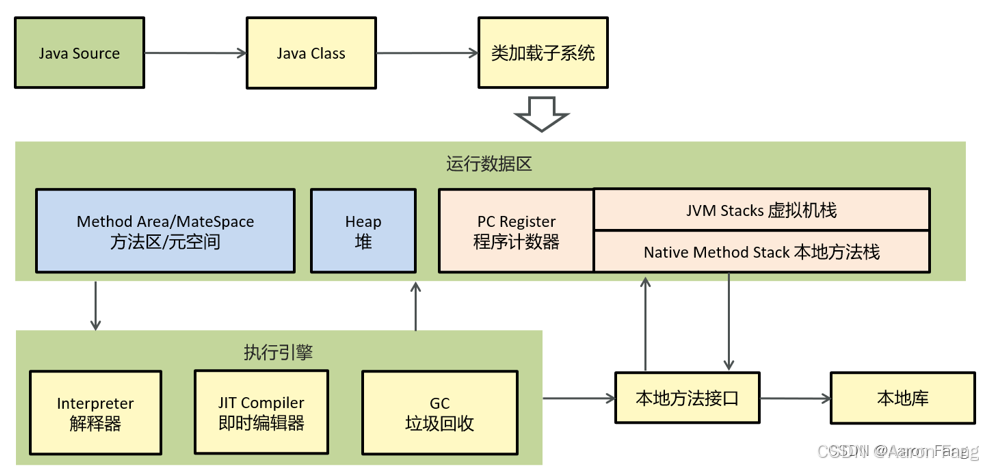
文章目录 1.JVM 的各部分组成2.运行时数据区2.1.什么是程序计数器?2.2.你能给我详细的介绍Java堆吗?2.3.能不能解释一下方法区?2.3.1常量池2.3.2.运行时常量池2.4.什么是虚拟机栈?2.4.1.垃圾回收是否涉及栈内存?2.4.2.栈内存分配越大越好吗?2.4.3.方法内的局部变量是否线…...

PostgreSQL技术大讲堂 - 第86讲:数据安全之--data_checksums天使与魔鬼
PostgreSQL技术大讲堂 - 第86讲,主题:数据安全之--data_checksums天使与魔鬼 1、data_checksums特性 2、避开DML规则,嫁接非法数据并合法化 3、避开约束规则,嫁接非法数据到表中 4、避开数据检查,读取坏块中的数据…...

DOM解析XML:Java程序员的“乐高积木式“数据搭建
各位代码建筑师们!今天我们要玩一个把XML变成内存乐高城堡的游戏——DOM解析!和SAX那种"边看监控边破案"的刺激不同,DOM就像把整个乐高说明书一次性倒进大脑,然后慢慢拼装(内存:你不要过来啊&…...

C++ 入门六:多态 —— 同一接口的多种实现之道
在面向对象编程中,多态是最具魅力的特性之一。它允许我们通过统一的接口处理不同类型的对象,实现 “一个接口,多种实现”。本章将从基础概念到实战案例,逐步解析多态的核心原理与应用场景,帮助新手掌握这一关键技术。 …...

关于获取文件大小的方法总结
编程开发中,获取文件大小是一项常见的需求,无论是进行文件管理、数据传输还是资源监控等操作,都可能需要知道文件的具体大小。下面将介绍几种常见的获取文件大小的方式,并进行对比分析。 几种可行的文件大小获取方式 1. 使用 fs…...

从宇树摇操avp_teleoperate到unitree_IL_lerobot:如何基于宇树人形进行二次开发(含Open-TeleVision源码解析)
前言 如之前的文章所述,我司「七月在线」正在并行开发多个订单,目前正在全力做好每一个订单,因为保密协议的原因,暂时没法拿出太多细节出来分享 但可以持续解读我们所创新改造或二次开发的对象,即解读paper和开源库…...

告别 ifconfig:为什么现代 Linux 系统推荐使用 ip 命令
告别 ifconfig:为什么现代 Linux 系统推荐使用 ip 命令 ifconfig 指令已经被视为过时的工具,不再是查看和配置网络接口的推荐方式。 与 netstat 被 ss 替代类似。 本文简要介绍 ip addr 命令的使用 简介ip ifconfig 属于 net-tools 包,这个…...
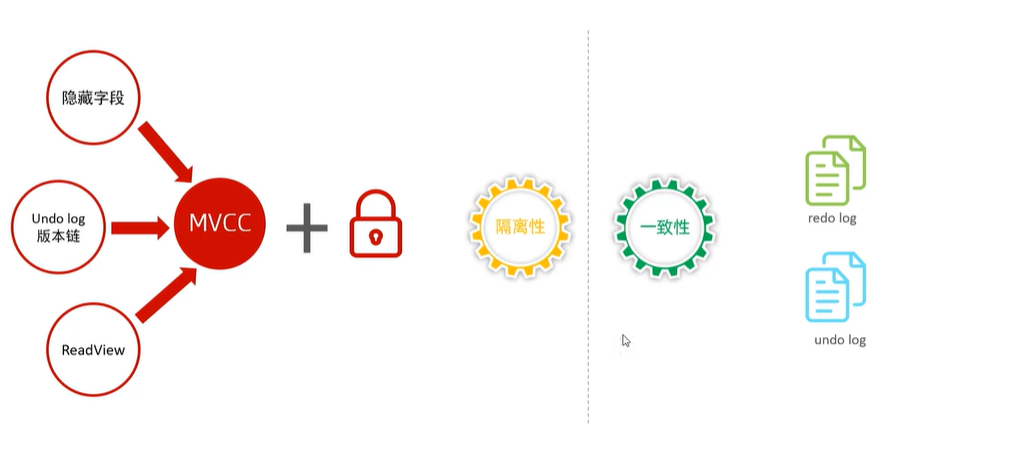
MySQL——MVCC(多版本并发控制)
目录 1.MVCC多版本并发控制的一些基本概念 MVCC实现原理 记录中的隐藏字段 undo log undo log 版本链 ReadView 数据访问规则 具体实现逻辑 总结 1.MVCC多版本并发控制的一些基本概念 当前读:该取的是记录的最新版本,读取时还要保证其他并发事务…...

Gateway-网关-分布式服务部署
前言 什么是API⽹关 API⽹关(简称⽹关)也是⼀个服务, 通常是后端服务的唯⼀⼊⼝. 它的定义类似设计模式中的Facade模式(⻔⾯模式, 也称外观模式). 它就类似整个微服务架构的⻔⾯, 所有的外部客⼾端访问, 都需要经过它来进⾏调度和过滤. 常⻅⽹关实现 Spring Cloud Gateway&a…...

火影 遇上 python Baby_Brother_GGY
上视频先~ 66666 import pygame import random import sys import math from pygame.locals import *# 初始化pygame pygame.init() pygame.mixer.init()# 屏幕设置 WIDTH, HEIGHT 1480, 750 screen pygame.display.set_mode((WIDTH, HEIGHT)) py…...
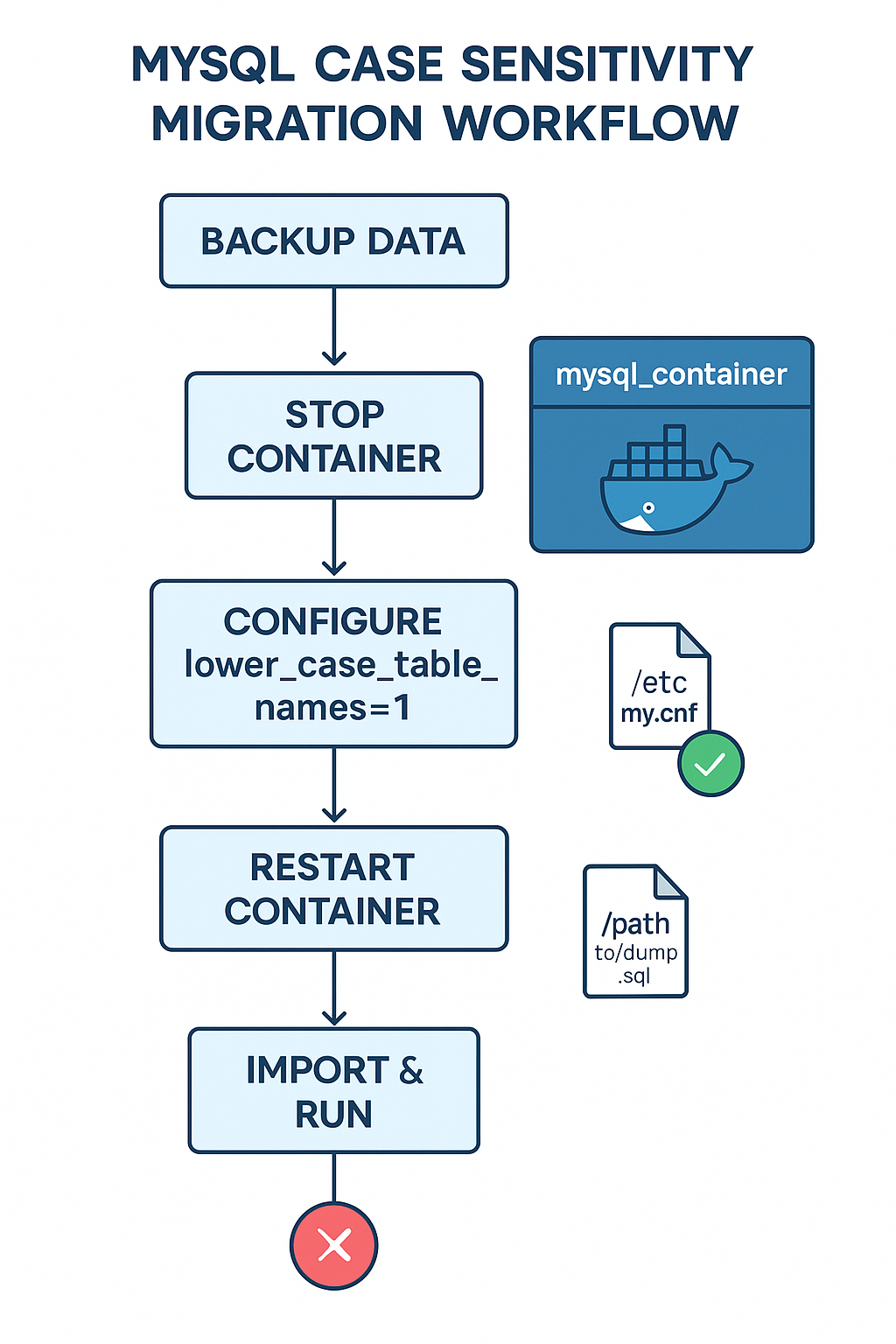
Docker部署MySQL大小写不敏感配置与数据迁移实战20250409
Docker部署MySQL大小写不敏感配置与数据迁移实战 🧭 引言 在企业实际应用中,尤其是使用Java、Hibernate等框架开发的系统,MySQL默认的大小写敏感特性容易引发各种兼容性问题。特别是在Linux系统中部署Docker版MySQL时,默认行为可…...

面试题之网络相关
最近开始面试了,410面试了一家公司 问了我几个网络相关的问题,我都不会!!现在来恶补一下,整理到博客中,好难记啊,虽然整理下来了。在这里先祝愿大家在现有公司好好沉淀,定位好自己的…...

使用MPI-IO并行读写HDF5文件
使用MPI-IO并行读写HDF5文件 HDF5支持通过MPI-IO进行并行读写,这对于大规模科学计算应用非常重要。下面我将提供C和Fortran的示例程序,展示如何使用MPI-IO并行读写HDF5文件。 准备工作 在使用MPI-IO的HDF5之前,需要确保: HDF5库编译时启用…...
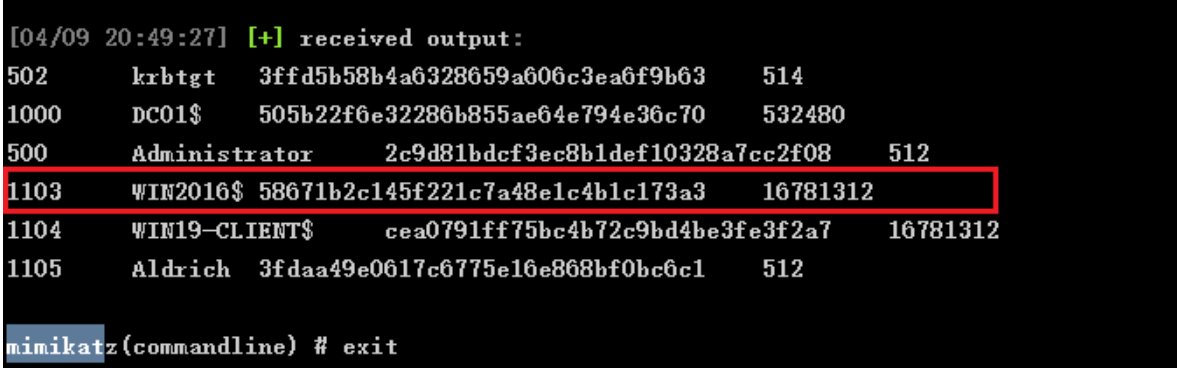
[春秋云镜] Tsclient仿真场景
文章目录 靶标介绍:外网mssql弱口令SweetPotato提权上线CSCS注入在线用户进程上线 内网chisel搭建代理密码喷洒攻击映像劫持 -- 放大镜提权krbrelayup提权Dcsync 参考文章 考点: mssql弱口令SweetPotato提权CS注入在线用户进程上线共享文件CS不出网转发上线密码喷洒…...

在人工智能与计算机技术融合的框架下探索高中教育数字化教学模式的创新路径
一、引言 1.1 研究背景 在数字中国战略与《中国教育现代化 2035》的政策导向下,人工智能与计算机技术的深度融合正深刻地重构着教育生态。随着科技的飞速发展,全球范围内的高中教育都面临着培养具备数字化素养人才的紧迫需求,传统的教学模式…...