GPT - TransformerDecoderBlock
本节代码定义了一个 TransformerDecoderBlock 类,它是 Transformer 架构中解码器的一个基本模块。这个模块包含了多头自注意力(Multi-Head Attention)、前馈网络(Feed-Forward Network, FFN)和层归一化(Layer Normalization)。
⭐这一节代码理解即可,知道Transformer的关键组成部分:多头自注意力(Multi-Head Attention)、前馈网络(Feed-Forward Network, FFN)和层归一化(Layer Normalization),不同DecoderBlock 有不同的复现方式,本文只给出了自己的实现方式
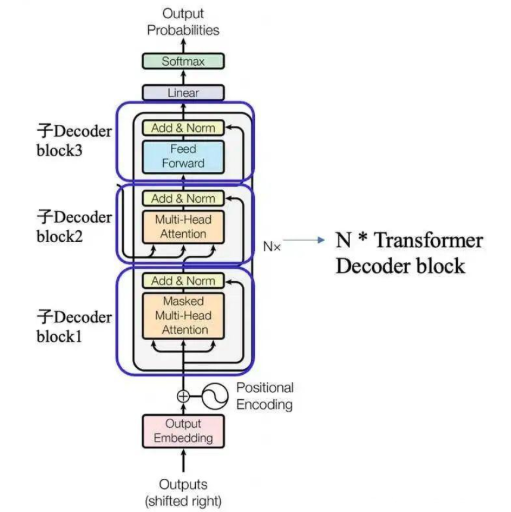
1. 初始化方法
def __init__(self, d_model, dff, dropout):super().__init__()self.linear1 = nn.Linear(d_model, dff)self.activation = nn.GELU()self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(dff, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)-
d_model:模型的维度,通常是嵌入维度。 -
dff:前馈网络的中间层维度。 -
dropout:Dropout 的概率。 -
num_heads:多头注意力机制中的头数(未在代码中定义,需要传入)。
2. 多头自注意力机制
self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)
self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)-
MultiHeadAttention是一个自定义的多头自注意力模块,通常包含查询(Q)、键(K)和值(V)的线性变换,以及多头注意力机制。 -
mha_block1和mha_block2分别表示两个多头自注意力模块。
3. 前馈网络
self.linear1 = nn.Linear(d_model, dff)
self.activation = nn.GELU()
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dff, d_model)-
前馈网络由两个线性层组成,中间使用激活函数(如 GELU 或 ReLU)和 Dropout。
-
linear1将输入从d_model映射到dff,linear2将输出从dff映射回d_model。
4. 层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)-
层归一化用于稳定训练过程,减少内部协变量偏移。
5. Dropout
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)-
Dropout 用于防止过拟合,通过随机丢弃一些神经元的输出来增强模型的泛化能力。
6. 前向传播
def forward(self, x, mask=None):x = self.norm1(x + self.dropout1(self.mha_block1(x, mask)))x = self.norm2(x + self.dropout2(self.mha_block2(x, mask)))x = self.norm3(self.linear2(self.dropout(self.activation(self.linear1(x)))))return x-
mha_block1和mha_block2:两个多头自注意力模块,分别处理输入x。 -
norm1和norm2:在每个自注意力模块后应用层归一化。 -
linear1和linear2:前馈网络的两个线性层,中间使用激活函数和 Dropout。 -
norm3:在前馈网络后应用层归一化。
需复现的完整代码(未标红部分为上节提到的多头自注意力机制)
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_project = nn.Linear(d_model, d_model)self.k_project = nn.Linear(d_model, d_model)self.v_project = nn.Linear(d_model, d_model)self.o_project = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, attn_mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = Q @ K.transpose(2, 3) / math.sqrt(self.d_k)if attn_mask is not None:attn_mask = attn_mask.unsqueeze(1)atten_scores = atten_scores.masked_fill(attn_mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)out = self.o_project(out)return self.dropout(out)
class TransformerDecoderBlock(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.linear1 = nn.Linear(d_model, dff)self.activation = nn.GELU()# self.activation = nn.ReLU()self.dropout = nn .Dropout(dropout)self.linear2 = nn.Linear(dff, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)def forward(self, x, mask=None):x = self.norm1(x + self.dropout1(self.mha_block1(x, mask)))x = self.norm2(x + self.dropout2(self.mha_block2(x, mask)))x = self.norm3(self.linear2(self.dropout(self.activation(self.linear1(x)))))return x相关文章:
GPT - TransformerDecoderBlock
本节代码定义了一个 TransformerDecoderBlock 类,它是 Transformer 架构中解码器的一个基本模块。这个模块包含了多头自注意力(Multi-Head Attention)、前馈网络(Feed-Forward Network, FFN)和层归一化(Lay…...

LabVIEW 控制电机需注意的关键问题
在自动化控制系统中,LabVIEW 作为图形化编程平台,因其高度可视化、易于集成硬件等优势,被广泛应用于电机控制场景。然而,要实现稳定、精确、高效的电机控制,仅有软件并不足够,还需结合硬件选型、控制逻辑设…...

CSS 定位属性的生动比喻:以排队为例理解 relative 与 absolute
目录 一、理解标准流与队伍的类比 二、relative 定位:队伍中 “小范围活动” 的人 三、absolute 定位:队伍中 “彻底离队” 的人 在学习 CSS 的过程中,定位属性relative和absolute常常让初学者感到困惑。它们的行为方式和对页面布局的影响较为抽象,不过,我们可以通过一个…...
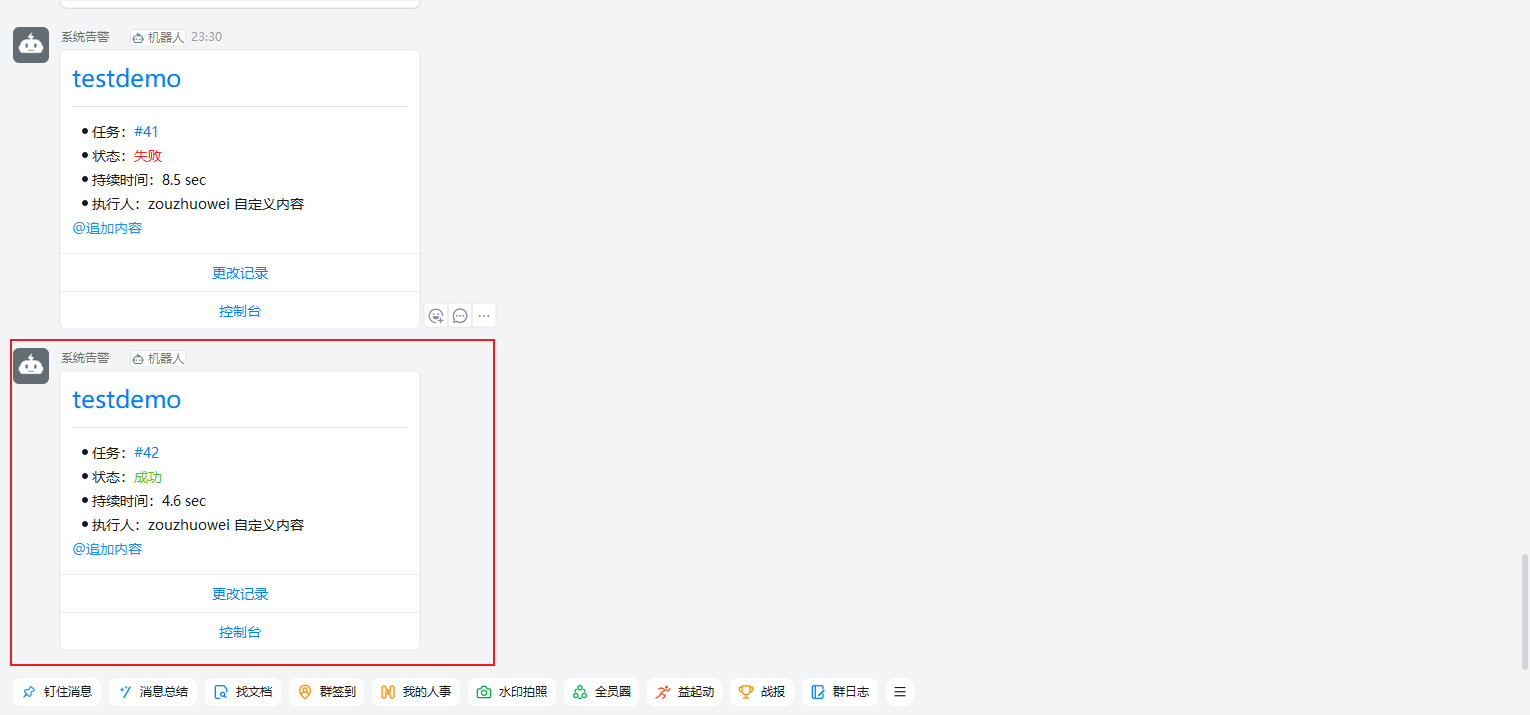
Jenkins 发送钉钉消息
这里不介绍 Jenkins 的安装,可以网上找到很多安装教程,重点介绍如何集成钉钉消息。 需要提前准备钉钉机器人的 webhook 地址。(网上找下,很多教程) 下面开始配置钉钉机器人,登录 Jenkins,下载 …...

nt!KeRemoveQueue 函数分析之加入队列后进入等待状态
第一部分: 参考例子:应用程序调用kernel32!GetQueuedCompletionStatus后会调用nt!KeRemoveQueue函数进入进入等待状态 0: kd> g Breakpoint 8 hit nt!KiDeliverApc: 80a3c776 55 push ebp 0: kd> kc # 00 nt!KiDeliverApc 01 nt…...

OpenCV 风格迁移
一、引言 在计算机视觉和图像处理领域,风格迁移是一项令人着迷的技术。它能够将一幅图像(风格图像)的艺术风格,如梵高画作的笔触风格、莫奈的色彩风格等,迁移到另一幅图像(内容图像)上&#x…...

35.Java线程池(线程池概述、线程池的架构、线程池的种类与创建、线程池的底层原理、线程池的工作流程、线程池的拒绝策略、自定义线程池)
一、线程池概述 1、线程池的优势 线程池是一种线程使用模式,线程过多会带来调度开销,进而影响缓存局部性和整体性能,而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务,这避免了在处理短时间任务时创建与…...
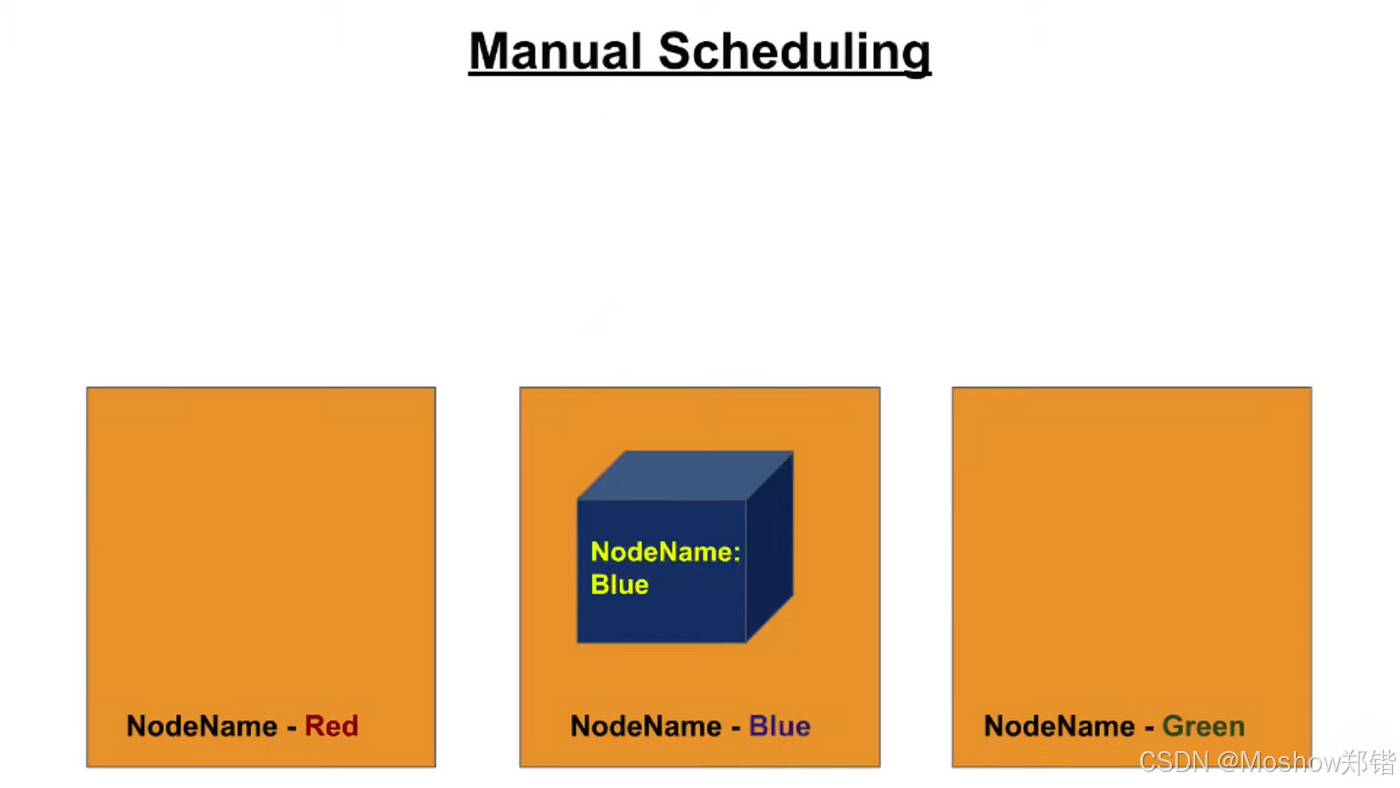
Kubernetes nodeName Manual Scheduling practice (K8S节点名称绑定以及手工调度)
Manual Scheduling 在 Kubernetes 中,手动调度框架允许您将 Pod 分配到特定节点,而无需依赖默认调度器。这对于测试、调试或处理特定工作负载非常有用。您可以通过在 Pod 的规范中设置 nodeName 字段来实现手动调度。以下是一个示例: apiVe…...

QML中访问c++数据,并实现类似C#中mvvm模式详细方法
1. 背景需求2. 实现步骤 2.1. 定义 Model(数据模型) 2.1.1. DataModel.h2.1.2. DataModel.cpp 2.2. 定义 ViewModel(视图模型) 2.2.1. PersonViewModel.h2.2.2. PersonViewModel.cpp 2.3. 在 QML 中使用 ViewModel 2.3.1. main.cp…...

React 获得dom节点和组件通信
通过REF 实例对象的.current属性获得绑定的DOM节点 组件通信 组件通信 1 父传子 父组件传递数据 子组件接受数据 通过pros对象接受 子组件的形参列表props只读 props中数据不可修改 特殊情况 在子传父的过程中没有直接给子组件添加属性,而是向父组件中添加其他…...
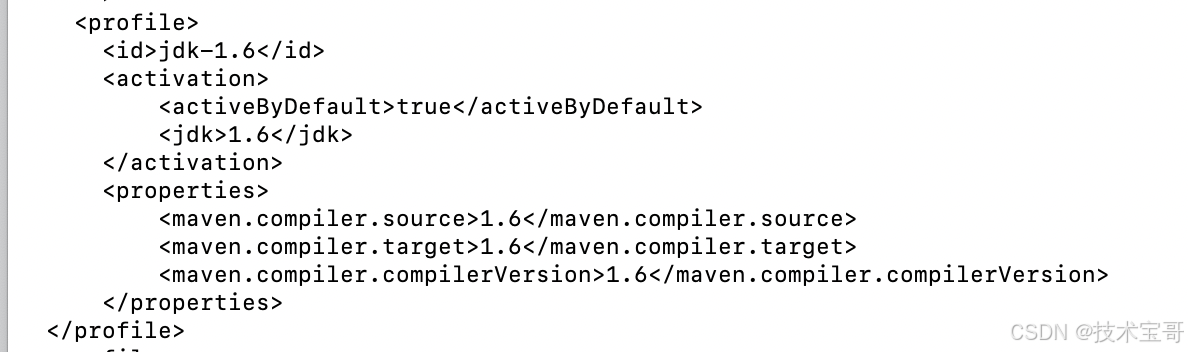
代码,Java Maven项目打包遇到的环境问题
这几天在写一些Java版本的Langchain4J的 AI 测试case,有一段时间不运行的Java环境,反复出现环境问题,记录下 1、Java编译版本的问题 修改编译版本: 2、在IDE中运行遇到Maven中JDK版本问题 在ide中执行maven命令,遇到下…...

fisco-bcos 关于服务bash status.sh启动runing 中但是5002端口监听不到,出错的问题
bash status.sh Server com.webank.webase.front.Application Port 5002 is running PID(4587) yjmyjm-VMware-Virtual-Platform:~/webase-front$ sudo netstat -anlp | grep 5002 没有端口信息输出 此时可以查看log文件夹下的WeBASE-front.log,找到报错信息如下…...

C++ 数据结构之图:从理论到实践
一、图的基本概念 1.1 图的定义与组成 图(Graph)由顶点(Vertex)和边(Edge)组成,形式化定义为: G (V, E) 顶点集合 V:表示实体(如城市、用户) …...

linux多线(进)程编程——(5)虚拟内存与内存映射
前言(前情回顾) 进程君开发了管道这门技术后,修真界的各种沟通越来越频繁,这天进程君正与自己的孩子沟通,进程君的孩子说道: “爸爸,昨天我看他们斗法,小明一拳打到了小刚的肚子上&…...

SpringBoot 动态路由菜单 权限系统开发 菜单权限 数据库设计 不同角色对应不同权限
介绍 系统中的路由配置可以根据用户的身份、角色或其他权限信息动态生成,而不是固定在系统中。不同的用户根据其权限会看到不同的路由,访问不同的页面。对应各部门不同的权限。 效果 [{"id": 1,"menuName": "用户管理"…...
[dp8_子数组] 乘积为正数的最长子数组长度 | 等差数列划分 | 最长湍流子数组
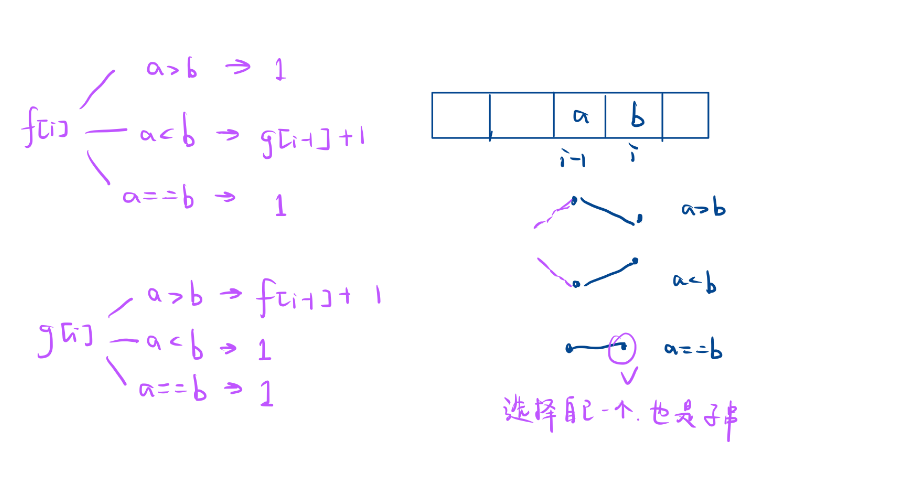
目录 1.乘积为正数的最长子数组长度 2.等差数列划分 3.最长湍流子数组 写代码做到,只用维护好自己的一小步 1.乘积为正数的最长子数组长度 链接:1567. 乘积为正数的最长子数组长度 给你一个整数数组 nums ,请你求出乘积为正数的最长子数…...

资深词源学家提示词
Role: 资深词源学家 Profile: Language: 中文Description: 作为在词源学领域的卓越专家,具备深厚且多元的学术背景。精通拉丁语、古希腊语、梵语等一众古老语言,能够精准解析这些语言的古代文献,为探寻词汇起源挖掘第一手资料。在汉语研究方…...

深入探讨MySQL存储引擎:选择最适合你的数据库解决方案
前言 大家好,今天我们将详细探讨MySQL中几种主要的存储引擎,了解它们的工作机制、适用场景以及各自的优缺点。通过这篇文章,希望能帮助你根据具体需求选择最合适的存储引擎,优化数据库性能。 1. InnoDB - 默认且强大的事务性存储…...

【图像处理基石】什么是通透感?
一、画面的通透感定义 画面的通透感指图像在色彩鲜明度、空间层次感、物体轮廓清晰度三方面的综合表现,具体表现为: 色彩鲜明:颜色纯净且饱和度适中,无灰暗或浑浊感;层次分明:明暗过渡自然,光…...

无锡无人机超视距驾驶证怎么考?
无锡无人机超视距驾驶证怎么考?在近年来,无人机技术的迅猛发展使得无人机的应用场景变得愈发广泛,其不仅在环境监测、农业喷洒、快递配送等领域展现出真金白银的价值,同时也推动了无人机驾驶证的需求。尤其是在无锡,随…...

213、【图论】有向图的完全联通(Python)
题目描述 原题链接:105. 有向图的完全联通 代码实现 import collectionsn, k list(map(int, input().split())) adjacency collections.defaultdict(list) for _ in range(k):head, tail list(map(int, input().split()))adjacency[head].append(tail)visited_…...
安卓开发中的数据存储之SQLite简单使用)
(二十二)安卓开发中的数据存储之SQLite简单使用
在Android开发中,SQLite是一种非常常用的数据库存储方式。它轻量、简单,非常适合移动设备上的数据管理。本文将通过通俗易懂的语言,结合代码示例和具体场景,详细讲解SQLite在Android中的使用。 1. 什么是SQLite? SQLite是一个开…...

图像形态学操作对比(Opencv)
形态学基于图像的形状进行操作,用于处理二值化图像,主要包括腐蚀和膨胀两种基本操作。这些操作通常用于去除噪声、分隔或连接相邻的元素以及寻找图像中显著的最大点和最小点。 1. 形态学操作 import cv2 import numpy as np import matplotlib.pyplot …...

复刻系列-星穹铁道 3.2 版本先行展示页
复刻星穹铁道 3.2 版本先行展示页 0. 视频 手搓~星穹铁道~展示页~~~ 1. 基本信息 作者: 啊是特嗷桃系列: 复刻系列官方的网站: 《崩坏:星穹铁道》3.2版本「走过安眠地的花丛」专题展示页现已上线复刻的网…...

请你说一说测试用例的边界
一、什么是测试用例的边界? 边界是指输入、输出、状态或操作的极限条件,是系统行为可能发生变化的临界点。例如: 输入字段的最小值、最大值、空值、超长值; 循环的第0次、第1次、最后一次; 时间相关的闰年、月末、跨时区操作等。 边界测试的核心思想是:缺陷更容易出现在…...
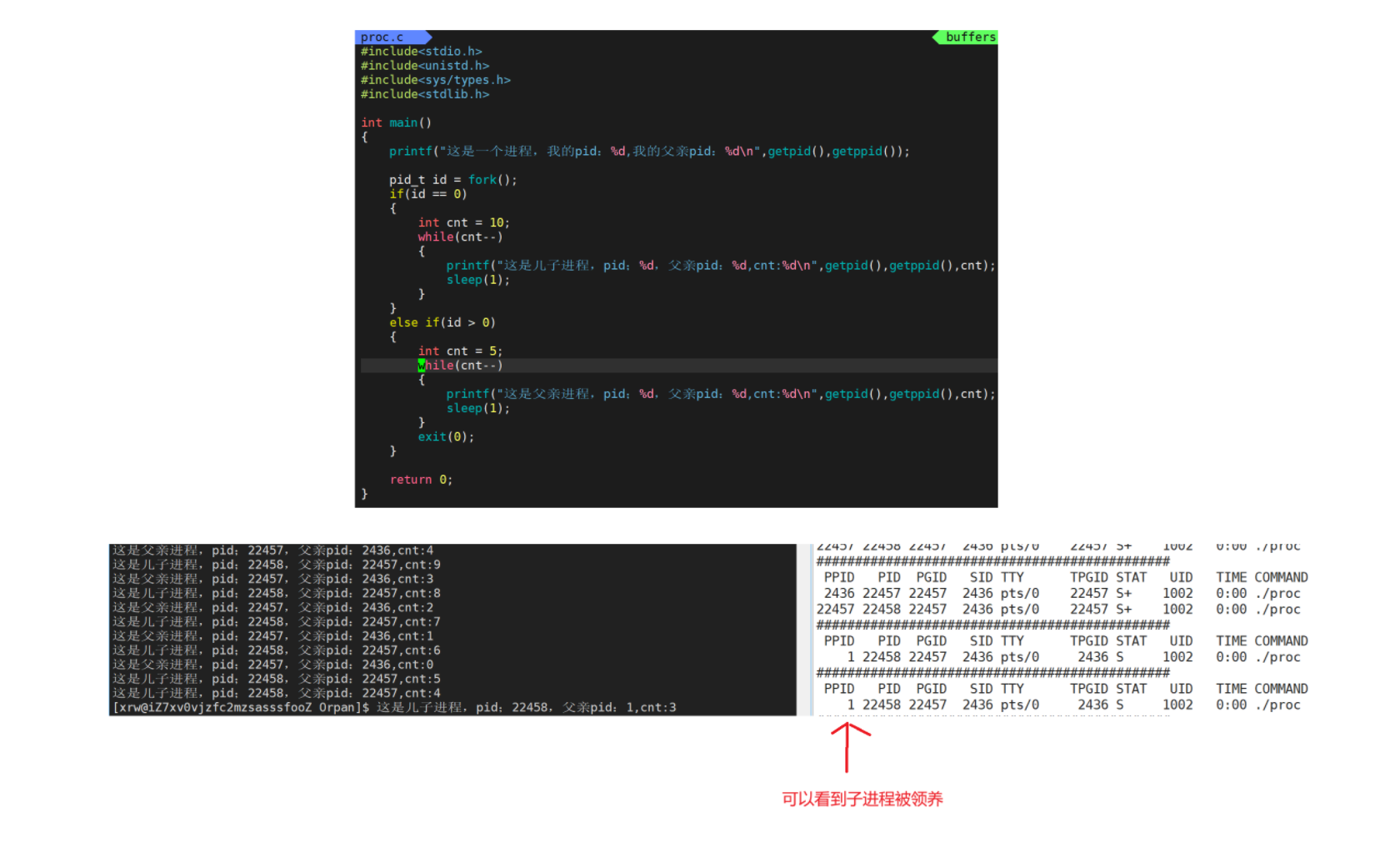
Linux:进程理解1(查看进程,创造进程,进程状态)
进程理解 (一)查看进程通过系统调用获取进程标示* (二)创造进程(fork)1. 创造的子进程的PCB代码数据怎么来?2.一个函数为什么有两个返回值?3. 为什么这里会有 两个 id值?…...
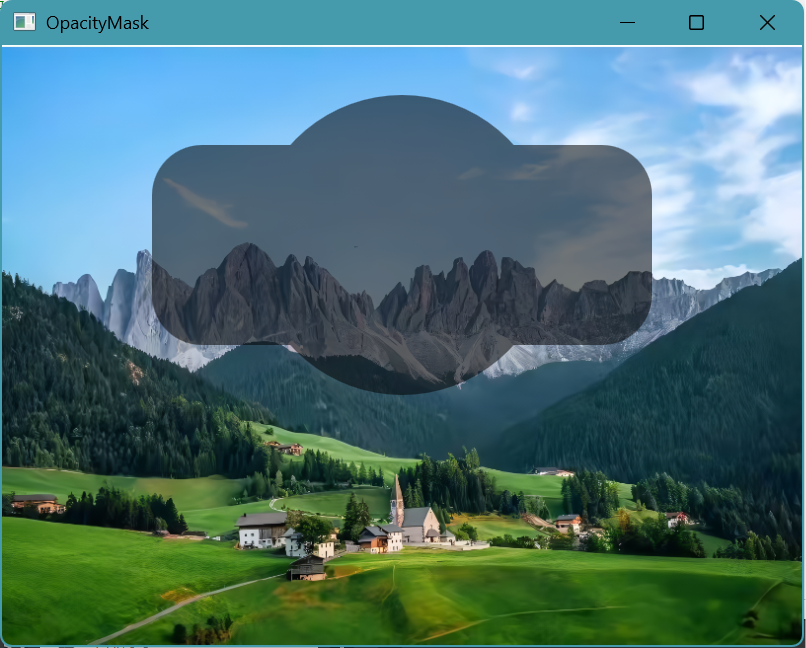
异形遮罩之QML中的 `OpacityMask` 实战
文章目录 🌧️ 传统实现的问题👉 效果图 🌈 使用 OpacityMask 的理想方案👉代码如下🎯 最终效果: ✨ 延伸应用🧠 总结 在 UI 设计中,经常希望实现一些“异形区域”拥有统一透明度或颜…...

如何为您的设计应用选择高速连接器
电气应用的设计过程需要考虑诸多因素,尤其是在设计高速网络时。许多连接器用户可能没有意识到,除了在两个互连之间组装导电线路之外,还需要考虑各种工艺。在建立高速连接并确保适当的信号完整性时,必须考虑蚀刻、公差、屏蔽等因素…...

mongodb 4.0+多文档事务的实现原理
1. 副本集事务实现(4.0) 非严格依赖二阶段提交 MongoDB 4.0 在副本集环境中通过 全局逻辑时钟(Logical Clock) 和 快照隔离(Snapshot Isolation) 实现多文档事务,事务提交时通过…...
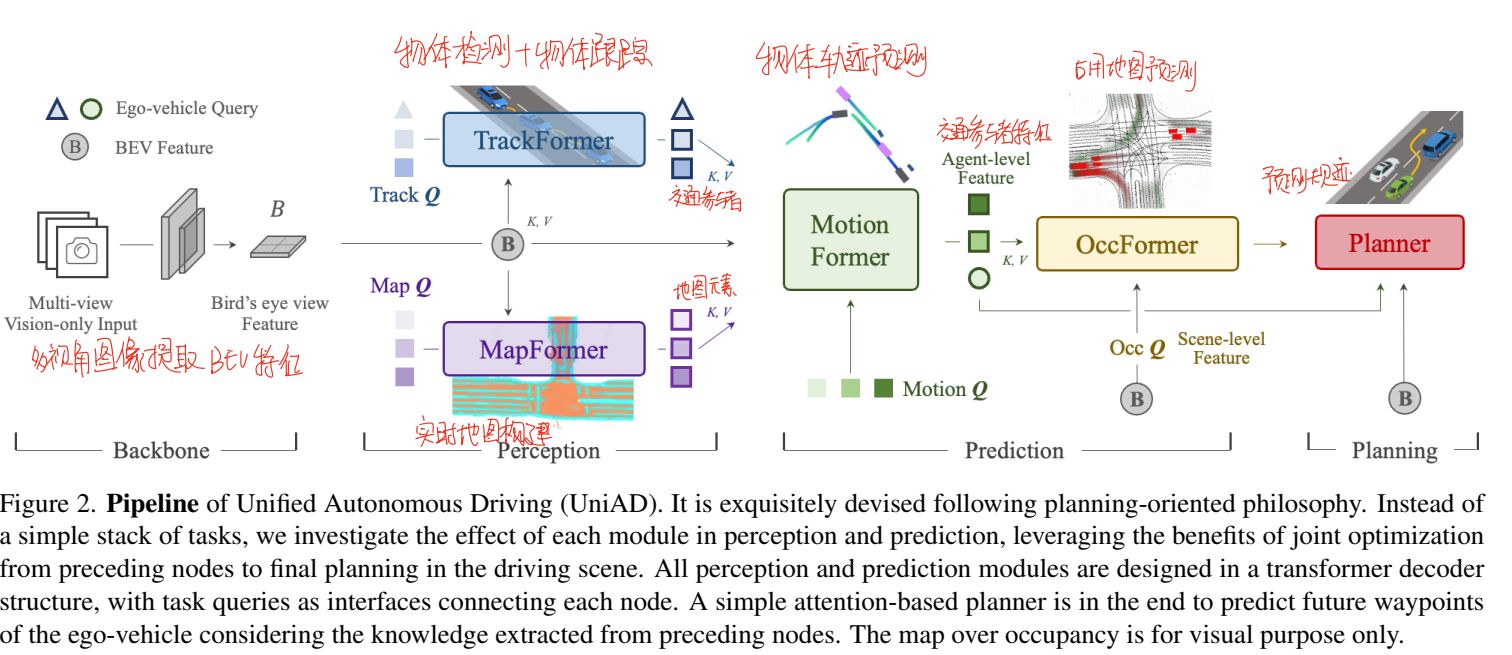
【论文阅读】UniAD: Planning-oriented Autonomous Driving
一、Introduction 传统的无人驾驶采用了区分子模块的设计,即将无人驾驶拆分为感知规划控制三个模块,这虽然能够让无人驾驶以一个很清晰的结构实现,但是感知的结果在传达到规划部分的时候,会导致部分信息丢失,这势必会…...