[数据结构]排序 --2
目录
8、快速排序
8.1、Hoare版
8.2、挖坑法
8.3、前后指针法
9、快速排序优化
9.1、三数取中法
9.2、采用插入排序
10、快速排序非递归
11、归并排序
12、归并排序非递归
13、排序类算法总结
14、计数排序
15、其他排序
15.1、基数排序
15.2、桶排序
8、快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法
基本思想:任取待排序元素序列中的某元 素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有 元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止
8.1、Hoare版
1. 把第一个值作为基准值 pivot
2. right 从右边走,遇到比 pivot 大的就停下;left 从左边走,遇到比 pivot 小的就停下
3. 交换 left 和 right 的值
4. left 和 right 继续走,直到 left 和 right 相遇
5. 相遇的位置就是要找的位置,把基准值与该位置交换
public static void quickSort(int[] array) {quick(array,0,array.length-1);}private static void quick(int[] array,int start,int end) {if(start >= end) {return;}int pivot = partitionHoare(array,start,end);quick(array,start,pivot-1);quick(array,pivot+1,end);}private static int partitionHoare(int[] array, int left, int right) {int tmp = array[left];int pivot = left;while (left < right) {// 单独的循环 不能一直减到超过最左边的边界while (left < right && array[right] >= tmp) {right--;}while (left < right && array[left] <= tmp) {left++;}swap(array,left,right);}swap(array,pivot,left);return left;}两个问题:
1. 为什么 array[right] >= tmp 必须带等于号
可能会出现 left 和 right 无限交换的死循环
2. 为什么从 right 先走而不是 left
如果 left 先走可能会出现相遇的是比基准大的数据,最后把大的数据放到了最前面
快速排序总结:
1. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
2. 时间复杂度:O(N*logN)
最好的情况下:O(N*logN)
最坏情况下:O(N^2) -- 逆序/有序
3. 空间复杂度:O(logN) -- 递归了logN层
最好的情况下:O(logN)
最坏情况下:O(N) -- 逆序/有序
4. 稳定性:不稳定
8.2、挖坑法
1. 把第一个值拿出来作为基准值 tmp,第一个值的位置就是第一个坑
2. right 从右边走,遇到比 pivot 大的就停下,然后把这个值放到上一个坑里,right 就形成了新的坑
3. left 从左边走,遇到比 tmp 小的就停下,然后把这个值放到坑里,left 就是新的坑
4. 循环2、3,直到 left 和 right 相遇
5. 相遇的位置就是要找的位置,把基准值放在这个位置
public static void quickSort(int[] array) {quick(array,0,array.length-1);}private static void quick(int[] array,int start,int end) {if(start >= end) {return;}int pivot = partitionHole(array,start,end);quick(array,start,pivot-1);quick(array,pivot+1,end);}private static int partitionHole(int[] array, int left, int right) {int tmp = array[left];while (left < right) {// 单独的循环 不能一直减到超过最左边的边界while (left < right && array[right] >= tmp) {right--;}array[left] = array[right];while (left < right && array[left] <= tmp) {left++;}array[right] = array[left];}array[left] = tmp;return left;}8.3、前后指针法
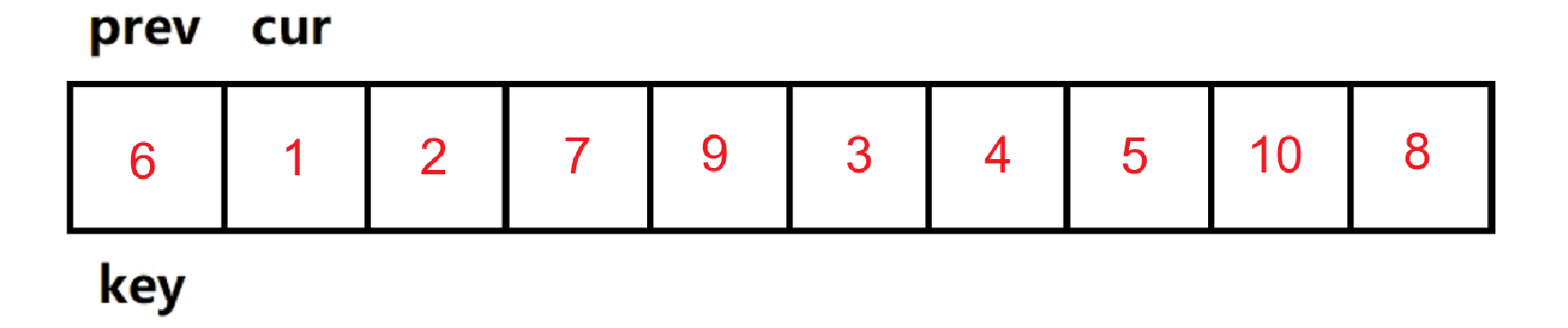
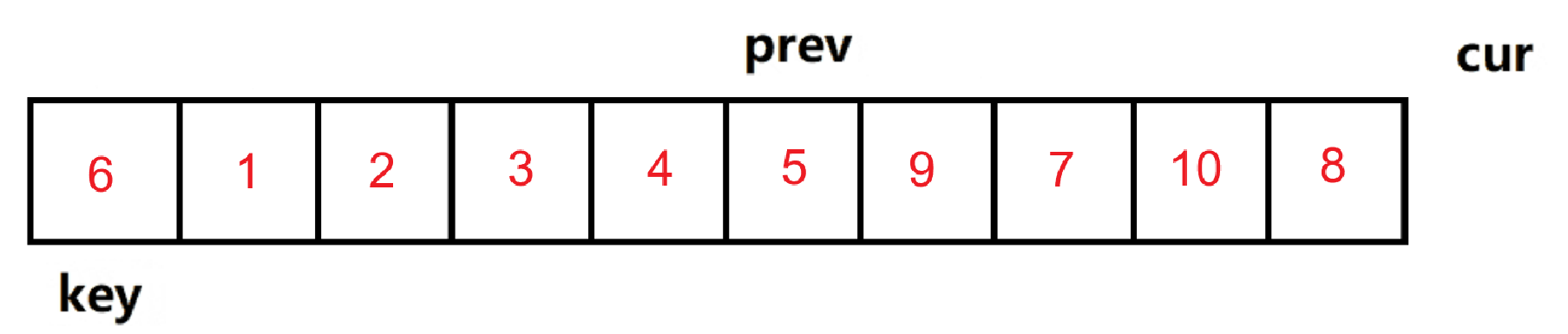
1. 定义两根指针cur和prev,初始位置如下图
2. cur开始往后走,如果遇到比key小的值,则++prev,然后交换prev和cur指向的元素,再++cur,如果遇到比key大的值,则只++cur
3. 当cur访问过最后一个元素后,将key的元素与prve访问的元素交换位置。cur访问完整个数组后的各元素位置如下图
private static int partition(int[] array, int left, int right) {int prev = left ;int cur = left+1;while (cur <= right) {if(array[cur] < array[left] && array[++prev] != array[cur]) {swap(array,cur,prev);}cur++;}swap(array,prev,left);return prev;
}
总结:
1. Hoare
2. 挖坑法
3. 前后指针法
这3种方式 每次划分之后的前后顺序 有可能是不一样的
9、快速排序优化
优化的出发点:减少递归的次数
9.1、三数取中法
既然有序数组或者有序数组片段会使效率下降,我们就可以让基准值每次都取大小靠中的数,然后在进行快速排序这样就可以避免了。但不是完全避免,只是减少了最坏情况出现的概率,最坏情况还是O(n²),但有效提升了运行效率,主要提升的部分是数组中有序的数组片段,减少了循环次数。
// 求中位数的下标private static int middleNum(int[] array,int left,int right) {int mid = (left+right)/2;if(array[left] < array[right]) {if(array[mid] < array[left]) {return left;}else if(array[mid] > array[right]) {return right;}else {return mid;}}else {//array[left] > array[right]if(array[mid] < array[right]) {return right;}else if(array[mid] > array[left]) {return left;}else {return mid;}}}private static void quick(int[] array,int start,int end) {if(start >= end) {return;}//1 2 3 4 5 6 7int index = middleNum(array,start,end);swap(array,index,start);//4 2 3 1 5 6 7int pivot = partition(array,start,end);quick(array,start,pivot-1);quick(array,pivot+1,end);}9.2、采用插入排序
往往一棵树的最后两层的结点占整棵树的绝大多数,所以当递归到一定深度时,采用直接插入排序
public static void insertSort(int[] array,int left,int right) {for (int i = left+1; i <= right; i++) {int tmp = array[i];int j = i-1;for (; j >= left ; j--) {if(array[j] > tmp) {array[j+1] = array[j];}else {break;}}array[j+1] = tmp;}}private static void quick(int[] array,int start,int end) {if(start >= end) {return;}if(end - start + 1 <= 15) {insertSort(array, start, end);return;}//1 2 3 4 5 6 7int index = middleNum(array,start,end);swap(array,index,start);//4 2 3 1 5 6 7int pivot = partition(array,start,end);quick(array,start,pivot-1);quick(array,pivot+1,end);}10、快速排序非递归
1. 先调用partition方法找到基准
2. 基准左边和右边有没有2个及以上个元素,有就把下标放到栈中3. 判断栈空不空,不空出栈2个,第一个是新的end,第二个是新的start
4. 栈不为空时,循环执行上述1.2.3
public static void quickSortNor(int[] array) {int start = 0;int end = array.length-1;Stack<Integer> stack = new Stack<>();int pivot = partition(array,start,end);if(pivot > start+1) {stack.push(start);stack.push(pivot-1);}if(pivot+1 < end) {stack.push(pivot+1);stack.push(end);}while (!stack.isEmpty()) {end = stack.pop();start = stack.pop();pivot = partition(array,start,end);if(pivot > start+1) {stack.push(start);stack.push(pivot-1);}if(pivot+1 < end) {stack.push(pivot+1);stack.push(end);}}}11、归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并
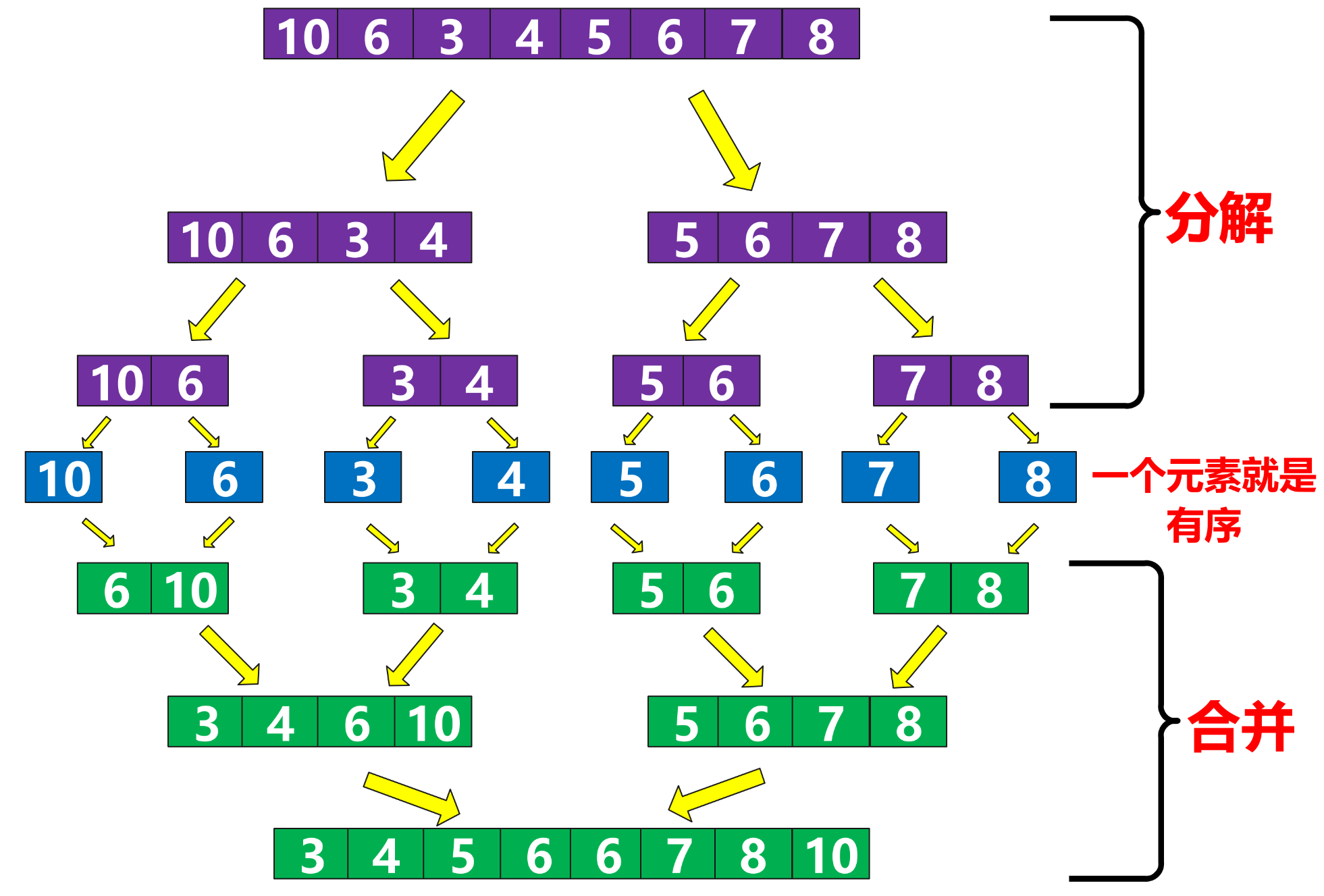
public static void mergeSort(int[] array) {mergeSortFun(array,0,array.length-1);}private static void mergeSortFun(int[] array,int start,int end) {if(start >= end) {return;}int mid = (start+end)/2;mergeSortFun(array,start,mid);mergeSortFun(array,mid+1,end);//合并merge(array,start,mid,end);}private static void merge(int[] array, int left, int mid, int right) {// s1,e1,s2,e2 可以不定义,这样写为了好理解int s1 = left;int e1 = mid;int s2 = mid+1;int e2 = right;//定义一个新的数组int[] tmpArr = new int[right-left+1];int k = 0;//tmpArr数组的下标//同时满足 证明两个归并段 都有数据while (s1 <= e1 && s2 <= e2) {if(array[s1] <= array[s2]) {tmpArr[k++] = array[s1++];}else {tmpArr[k++] = array[s2++];}}while (s1 <= e1) {tmpArr[k++] = array[s1++];}while (s2 <= e2) {tmpArr[k++] = array[s2++];}//把排好序的数据 拷贝回原来的数组array当中for (int i = 0; i < tmpArr.length; i++) {array[i+left] = tmpArr[i];}}两个有序数组合并为一个有序数组代码:
public static int[] mergeArray(int[] arrayl,int[] array2) {// 注意判断参数int[] tmp = new int[array1.length+array2.length];int k = 0;int s1 = 0;int el = array1.length-1;int s2 = 0;int e2 = array2.length-1;while (s1 <= el && s2 <= e2) {if(array1[s1] <= array2[s2]) {tmp[k++] = array1[s1++];}else {tmp[k++]=array2[s2++];}}while (s1 <= el) {tmp[k++] = array1[s1++];}while (s2 <= e2) {tmp[k++]= array2[s2++];}return tmp;
}归并排序总结
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序更多的是解决在磁盘中的外排序问题。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)递归调用栈空间:O(logN)
合并操作空间:O(N)
4. 稳定性:稳定
海量数据的排序
外部排序:排序过程需要在磁盘等外部存储进行的排序
前提:内存只有 1G,需要排序的数据有 100G
因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序
1. 先把文件切分成 200 份,每个 512 M
2. 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以
3. 进行2路归并,同时对 200 份有序文件做归并过程,最终结果就有序了(在外部存储进行)
12、归并排序非递归
1. 找到 left、mid、right 的位置和关系,然后调用merge合并
2. 定义 gap 表示当前的分组是每组几个数据
public static void mergeSortNor(int[] array) {int gap = 1;//每组几个数据while (gap < array.length) {for (int i = 0; i < array.length; i = i+gap*2) {int left = i;// mid、right 可能会越界int mid = left+gap-1;int right = mid+gap;if(mid >= array.length) {mid = array.length-1;}if(right >= array.length) {right = array.length-1;}merge(array,left,mid,right);}gap*=2;}13、排序类算法总结
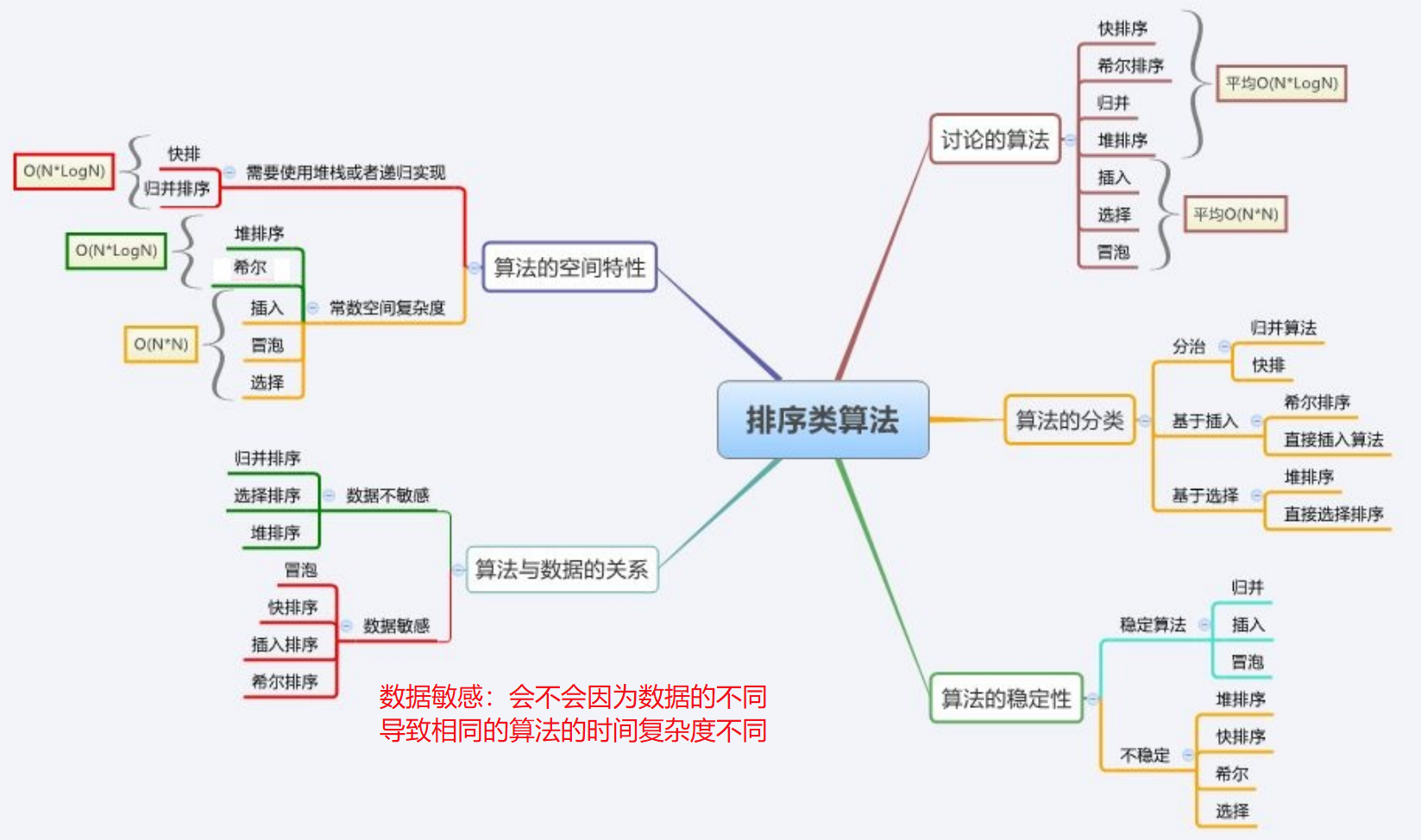
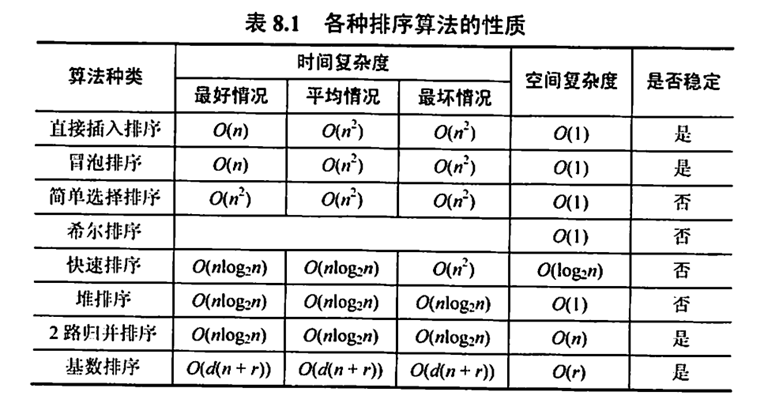
14、计数排序
思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。 操作步骤:
1. 统计相同元素出现次数
2. 根据统计的结果将序列回收到原来的序列中具体实现:
1.申请一个数组count,大小为待排序数组array的范围 M
2.遍历待排序数组array,把数字对应的count数组的下标内容进行++
3.遍历计数数组count 写回到待排序数组array,此时需要注意写的次数和元素值要一样
4. 最后数组array中存储的就是有序的序列
public static void countSort(int[] array) {//求数组的最大值 和 最小值 O(N)int minVal = array[0];int maxVal = array[0];for (int i = 1; i < array.length; i++) {if(array[i] < minVal) {minVal = array[i];}if(array[i] > maxVal) {maxVal = array[i];}}//确定计数数组的 长度int len = maxVal - minVal + 1;int[] count = new int[len];//遍历array数组 把数据出现的次数存储到计数数组当中 O(N)for (int i = 0; i < array.length; i++) {count[array[i]-minVal]++;}//计数数组已经存放了每个数据出现的次数//遍历计数数组 把实际的数据写回array数组 O(M) M表示数据范围int index = 0;for (int i = 0; i < count.length; i++) {while (count[i] > 0) {//这里需要重写写回array 意味着得从array的0位置开始写array[index] = i+minVal;index++;count[i]--;}}}计数排序的特性总结
1.计数排序是非基于比较的排序2. 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限;计数排序的场景:指定范围内的数据
3. 时间复杂度:O(MAX(N,M)) M表示数据范围
4. 空间复杂度:O(M)
5. 稳定性:稳定;上述代码是不稳定的写法
15、其他排序
15.1、基数排序
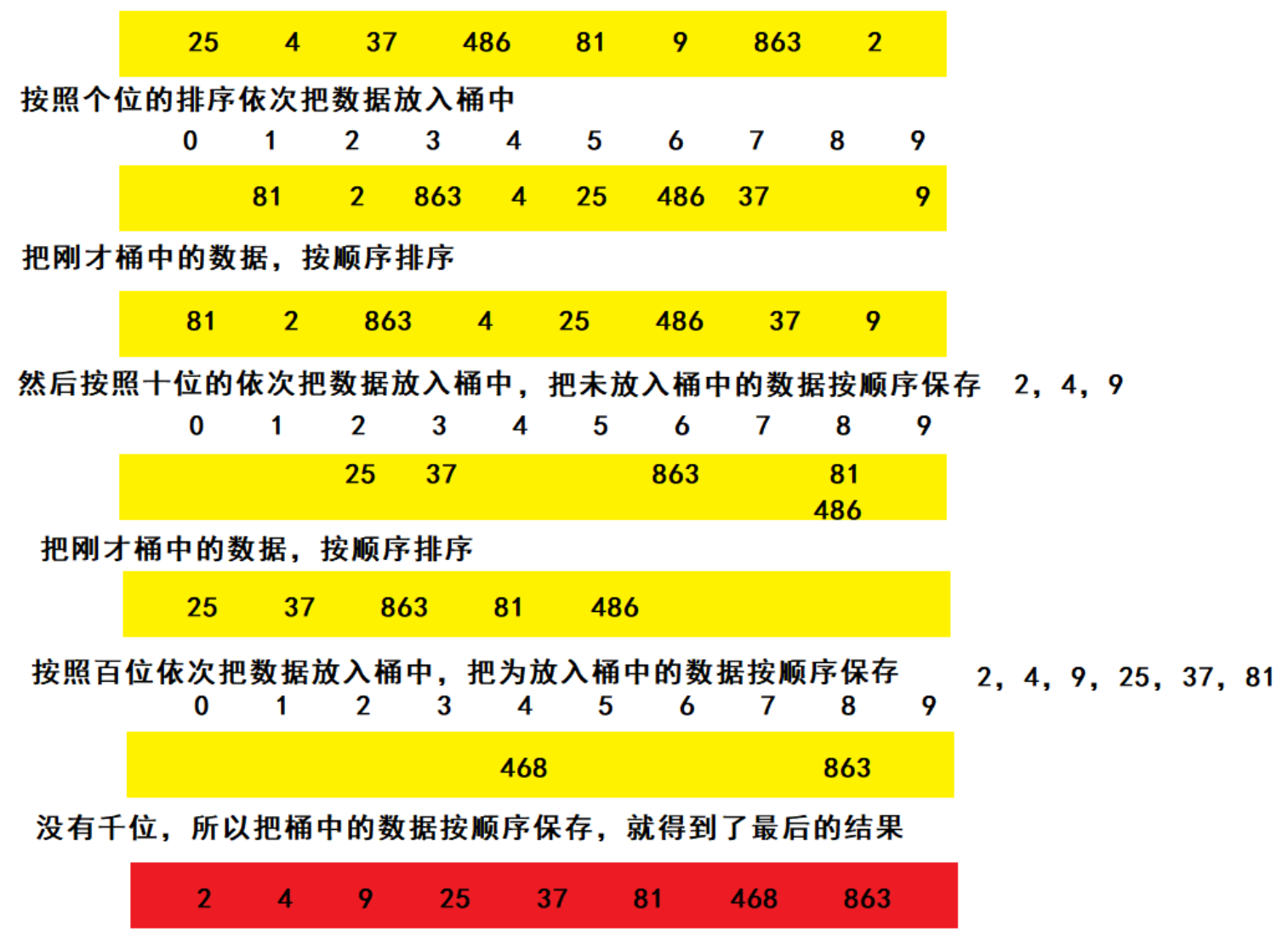
基数排序(Radix Sort)是一种非比较型的排序算法,它通过逐位比较元素的每一位(从最低位到最高位)来实现排序。基数排序的核心思想是将整数按位数切割成不同的数字,然后按每个位数分别进行排序。基数排序的时间复杂度为 O(d*(n+r)),其中 n 为元素个数,d 是最大数字的位数,r 为基数(桶的个数)
时间复杂度分析:
分配依次将每个数放到对应的桶中 O(n)
收集依次将每个桶里的元素拿出来 O(r) (桶里的元素是用链表连接的)
每轮:分配+收集 O(n+r)
如果最大的数字有d位,就需要排d轮
所以时间复杂度为:O(d*(n+r))
15.2、桶排序
算法思想:划分多个范围相同的区间,每个子区间自排序,最后合并
计数排序、基数排序、桶排序 都是非基于比较的排序
相关文章:

[数据结构]排序 --2
目录 8、快速排序 8.1、Hoare版 8.2、挖坑法 8.3、前后指针法 9、快速排序优化 9.1、三数取中法 9.2、采用插入排序 10、快速排序非递归 11、归并排序 12、归并排序非递归 13、排序类算法总结 14、计数排序 15、其他排序 15.1、基数排序 15.2、桶排序 8、快速排…...
第16届蓝桥杯c++省赛c组个人题解
偷偷吐槽: c组没人写题解吗,找不到题解啊 P12162 [蓝桥杯 2025 省 C/研究生组] 数位倍数 题目背景 本站蓝桥杯 2025 省赛测试数据均为洛谷自造,与官方数据可能存在差异,仅供学习参考。 题目描述 请问在 1 至 202504ÿ…...
记一次InternVL3- 2B 8B的部署测验日志
1、模型下载魔搭社区 2、运行环境: 1、硬件 RTX 3090*1 云主机[普通性能] 8核15G 200G 免费 32 Mbps付费68Mbps ubuntu22.04 cuda12.4 2、软件: flash_attn(好像不用装 忘记了) numpy Pillow10.3.0 Requests2.31.0 transfo…...

Android PowerManager功能接口详解
PowerManager 是 Android 系统中用于管理设备电源状态的核心服务,开发者可以通过它控制设备的唤醒、休眠、屏幕亮灭等行为。以下是对 PowerManager 核心功能接口的详细说明,包含使用场景、注意事项和代码示例。 1. 获取 PowerManager 实例 通过 Context…...

使用SSH解决在IDEA中Push出现403的问题
错误截图: 控制台日志: 12:15:34.649: [xxx] git -c core.quotepathfalse -c log.showSignaturefalse push --progress --porcelain master refs/heads/master:master fatal: unable to access https://github.com/xxx.git/: The requested URL return…...

Tauri 2.3.1+Leptos 0.7.8开发桌面应用--Sqlite数据库的写入、展示和选择删除
在前期工作的基础上(Tauri2Leptos开发桌面应用--Sqlite数据库操作_tauri sqlite-CSDN博客),尝试制作产品化学成分录入界面,并展示数据库内容,删除选中的数据。具体效果如下: 一、前端Leptos程序 前端程序主…...
技术的详细说明,涵盖 GraalVM 的配置、Spring Boot 3.x 的集成、使用示例及优缺点对比)
关于 Java 预先编译(AOT)技术的详细说明,涵盖 GraalVM 的配置、Spring Boot 3.x 的集成、使用示例及优缺点对比
以下是关于 Java 预先编译(AOT)技术的详细说明,涵盖 GraalVM 的配置、Spring Boot 3.x 的集成、使用示例及优缺点对比: 1. 预先编译(AOT)技术详解 1.1 核心概念 AOT(Ahead-of-Time)…...

《车辆人机工程-》实验报告
汽车驾驶操纵实验 汽车操纵装置有哪几种,各有什么特点 汽车操纵装置是驾驶员直接控制车辆行驶状态的关键部件,主要包括以下几种,其特点如下: 一、方向盘(转向操纵装置) 作用:控制车辆行驶方向…...

使用多进程和 Socket 接收解析数据并推送到 Kafka 的高性能架构
使用多进程和 Socket 接收解析数据并推送到 Kafka 的高性能架构 在现代应用程序中,实时数据处理和高并发性能是至关重要的。本文将介绍如何使用 Python 的多进程和 Socket 技术来接收和解析数据,并将处理后的数据推送到 Kafka,从而实现高效的…...
Redis 哨兵模式 搭建
1 . 哨兵模式拓扑 与 简介 本文介绍如何搭建 单主双从 多哨兵模式的搭建 哨兵有12个作用 。通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。 当哨兵监测到master宕机,会自动将slave切换成master,然后通过…...

【网络安全 | 项目开发】Web 安全响应头扫描器(提升网站安全性)
原创项目,未经许可,不得转载。 文章目录 项目简介工作流程示例输出技术栈项目代码使用说明项目简介 安全响应头是防止常见 Web 攻击(如点击劫持、跨站脚本攻击等)的有效防线,因此合理的配置这些头部信息对任何网站的安全至关重要。 Web 安全响应头扫描器(Security Head…...

构建灵活的接口抽象层:支持多种后端数据存取的实战指南
构建灵活的接口抽象层:支持多种后端数据存取的实战指南 引言 在现代软件开发中,数据存取成为业务逻辑的核心组成部分。然而,由于后端数据存储方式的多样性(如关系型数据库、NoSQL数据库和文件存储),如何设计一套能够适配多种后端数据存取的接口抽象层,成为技术团队关注…...

计算机的发展及应用
一、计算机的发展历程 计算机的发展经历了从机械计算到电子计算的跨越,其核心驱动力是 硬件技术革新 和 体系结构演进,大致可分为以下阶段: 1. 前电子计算机时代(19世纪-20世纪40年代) 机械计算装置: 16…...

深入理解linux操作系统---第4讲 用户、组和密码管理
4.1 UNIX系统的用户和组 4.1.1 用户与UID UID定义:用户身份唯一标识符,16位或32位整数,范围0-65535。系统用户UID为0(root)、1-999(系统服务),普通用户从1000开始分配特殊UID&…...

【NLP】18. Encoder 和 Decoder
1. Encoder 和 Decoder 概述 在序列到序列(sequence-to-sequence,简称 seq2seq)的模型中,整个系统通常分为两大部分:Encoder(编码器)和 Decoder(解码器)。 Encoder&…...

Npfs!NpFsdCreate函数分析之从NpCreateClientEnd函数分析到Npfs!NpSetConnectedPipeState
第一部分: 1: kd> g Breakpoint 5 hit Npfs!NpFsdCreate: baaecba6 55 push ebp 1: kd> kc # 00 Npfs!NpFsdCreate 01 nt!IofCallDriver 02 nt!IopParseDevice 03 nt!ObpLookupObjectName 04 nt!ObOpenObjectByName 05 nt!IopCreateFile 06…...
基于PySide6与pycatia的CATIA绘图比例智能调节工具开发全解析
引言:工程图纸自动化处理的技术革新 在机械设计领域,CATIA图纸的比例调整是高频且重复性极强的操作。传统手动调整方式效率低下且易出错。本文基于PySide6+pycatia技术栈,提出一种支持智能比例匹配、实时视图控制、异常自处理的图纸批处理方案,其核心突破体现在: 操作效…...

STM32硬件IIC+DMA驱动OLED显示——释放CPU资源,提升实时性
目录 前言 一、软件IIC与硬件IIC 1、软件IIC 2、硬件IIC 二、STM32CubeMX配置KEIL配置 三、OLED驱动示例 1、0.96寸OLED 2、OLED驱动程序 3、运用示例 4、效果展示 总结 前言 0.96寸OLED屏是一个很常见的显示模块,其驱动方式在用采IIC通讯时,常用软件IIC…...

Spring Bean的创建过程与三级缓存的关系详解
以下以 Bean A 和 Bean B 互相依赖为例,结合源码和流程图,详细说明 Bean 的创建过程与三级缓存的交互。 1. Bean 的完整生命周期(简化版) #mermaid-svg-uwqaB5dgOFDQ97Yd {font-family:"trebuchet ms",verdana,arial,sa…...

IDEA 调用 Generate 生成 Getter/Setter 快捷键
快捷键不会用? 快捷键:AltInsert 全选键:CtrlA IDEA 调用 Generate 生成 Getter/Setter 快捷键 - 爱吃西瓜的番茄酱 - 博客园...
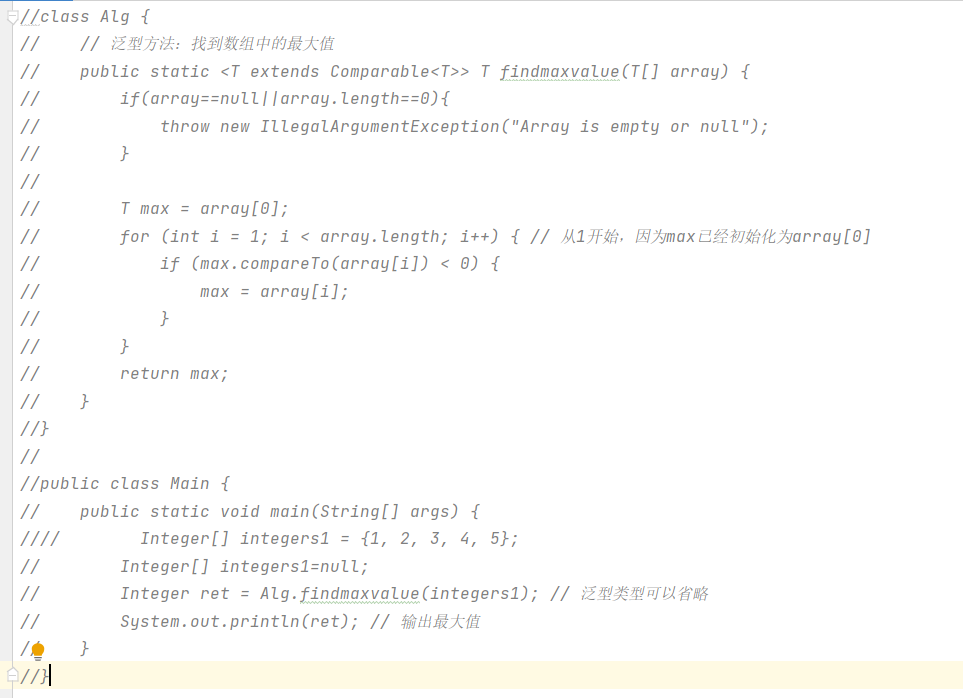
泛型的二三事
泛型(Generics)是Java语言的一个重要特性,它允许在定义类、接口和方法时使用类型参数(Type Parameters),从而实现类型安全的代码重用。泛型在Java 5中被引入,极大地增强了代码的灵活性和安全性。…...

编程思想——FP、OOP、FRP、AOP、IOC、DI、MVC、DTO、DAO
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

实现一个动态验证码生成器:Canvas与JavaScript的完美结合
验证码(CAPTCHA)是现代网站中常见的安全机制,用于区分人类用户和自动化程序。本文将详细介绍如何使用HTML5 Canvas和JavaScript创建一个美观且功能完整的验证码生成器。 一、核心功能概述 这个验证码生成器具有以下特点: 随机生…...

python中 “with” 关键字的取舍问题
自动管理资源(自动关闭文件) 当你使用 with 打开文件时,文件会在 with 代码块结束后自动关闭,无论是否发生异常。这意味着你不需要显式地调用 f.close() 来关闭文件 示例: with open("words.txt", "r…...
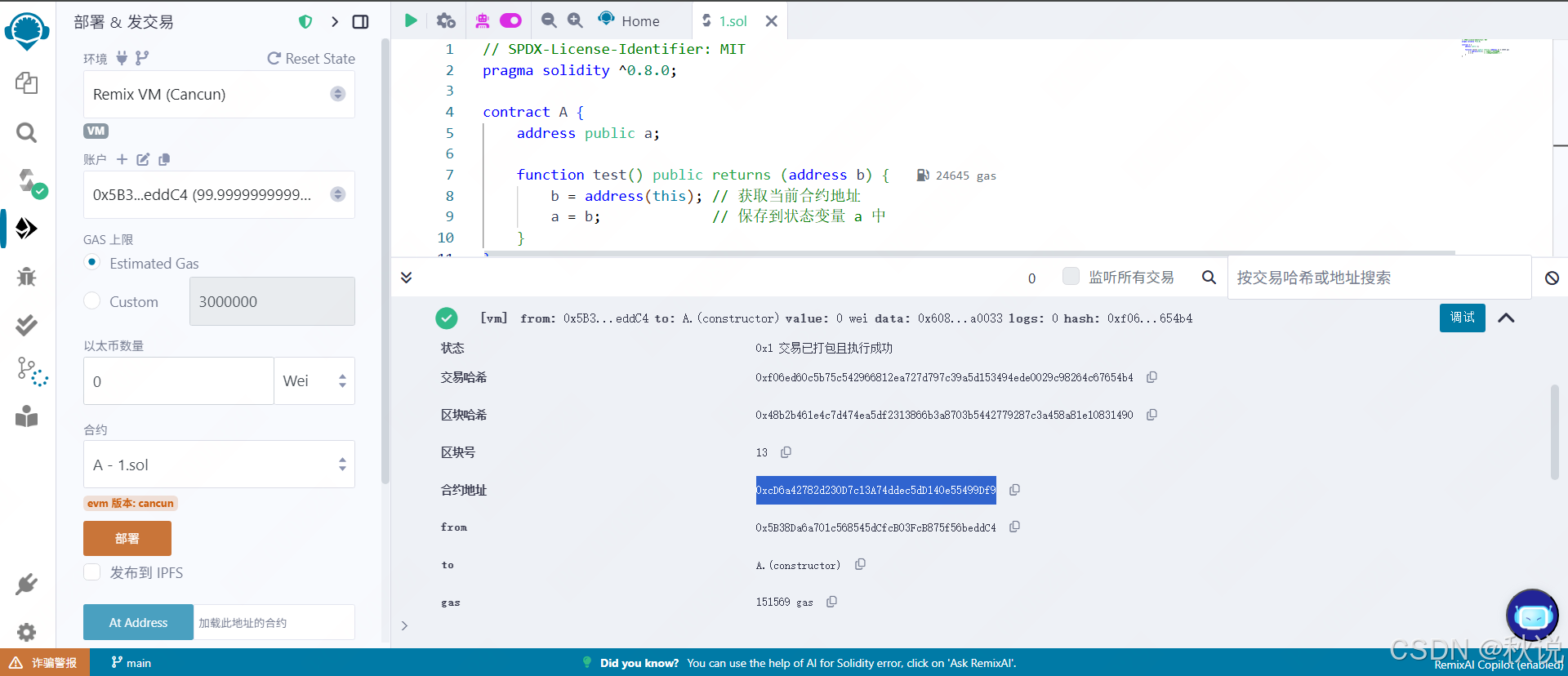
【区块链安全 | 第三十九篇】合约审计之delegatecall(一)
文章目录 外部调用函数calldelegatecallcall 与 delegatecall 的区别示例部署后初始状态调用B.testCall()函数调用B.testDelegatecall()函数区别总结漏洞代码代码审计攻击代码攻击原理解析攻击流程修复建议审计思路外部调用函数 在 Solidity 中,常见的两种底层外部函数调用方…...

Nginx部署spa单页面的小bug
没部署过,都是给后端干的,自己尝试部署了一个下午终于成功了 我遇到的最大的bug是进入后只有首页正常显示 其他页面全是404,于是问问问才知道,需要这个 location / { try_files $uri $uri/ /index.html; } 让…...

linux多线(进)程编程——(6)共享内存
前言 话说进程君的儿子经过父亲点播后就开始闭关,它想要开发出一种全新的传音神通。他想,如果两个人的大脑生长到了一起,那不是就可以直接知道对方在想什么了吗,这样不是可以避免通过语言传递照成的浪费吗? 下面就是它…...

【愚公系列】《Python网络爬虫从入门到精通》050-搭建 Scrapy 爬虫框架
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...
信息安全管理与评估2021年国赛正式卷答案截图以及十套国赛卷
2021年全国职业院校技能大赛高职组 “信息安全管理与评估”赛项 任务书1 赛项时间 共计X小时。 赛项信息 赛项内容 竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 第一阶段 平台搭建与安全设备配置防护 任务1 网络平台搭建 任务2 网络安全设备配置与防护 第二…...

讲解贪心算法
贪心算法是一种常用的算法思想,其在解决问题时每一步都做出在当前状态下看起来最优的选择,从而希望最终能够获得全局最优解。C作为一种流行的编程语言,可以很好地应用于贪心算法的实现。下面我们来讲一篇关于C贪心算法的文章。 目录 贪心算法…...