HarmonyOS中的多线程并发机制
目录
- 多线程并发
- 1. 多线程并发概述
- 2 多线程并发模型
- 3 TaskPool简介
- 4 Worker简介
- 4.1 Woker注意事项
- 4.2 Woker基本用法示例
- 5. TaskPool和Worker的对比
- 5.1 实现特点对比
- 5.2 适用场景对比
多线程并发
1. 多线程并发概述
并发模型是用来实现不同应用场景中并发任务的编程模型,常见的并发模型分为基于内存共享的并发模型和基于消息通信的并发模型。
Actor并发模型作为基于消息通信并发模型的典型代表,不需要开发者去面对锁带来的一系列复杂偶发的问题,同时并发度也相对较高,因此得到了广泛的支持和使用。
当前ArkTS提供了TaskPool和Worker两种并发能力,TaskPool和Worker都基于Actor并发模型实现。
2 多线程并发模型
内存共享并发模型指多线程同时执行任务,这些线程依赖同一内存并且都有权限访问,线程访问内存前需要抢占并锁定内存的使用劝,没有抢占到内存的线程需要等待其他线程释放使用权再执行。
Actor并发模型每一个线程都是一个独立Actor,每个Actor有自己独立的内存,Actor之间通过消息传递机制触发对方Actor行为,不同Actor之间不能直接访问对方的内存空间。
由于Actor并发模型线程之间不共享内存,需要通过线程间通信机制传输并发任务和任务结果。
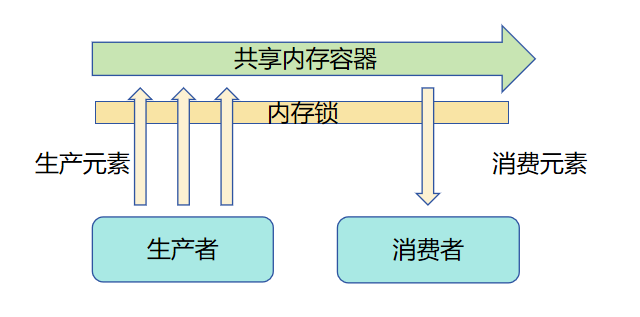
内存共享模型
内存共享模型指多线程同时执行任务,这些线程依赖同一内存并且都有权限访问,线程访问内存前需要抢占并锁定内存的使用权,没有抢占到内存的线程需要等待其他线程释放使用权再执行。同一时间只能有一个生产者或消费者访问该容器,也就是不同生产者和消费者争夺使用容器的锁。当一个角色获取锁之后其他角色需要等待该角色释放锁之后才能重新尝试获取锁以访问该容器。
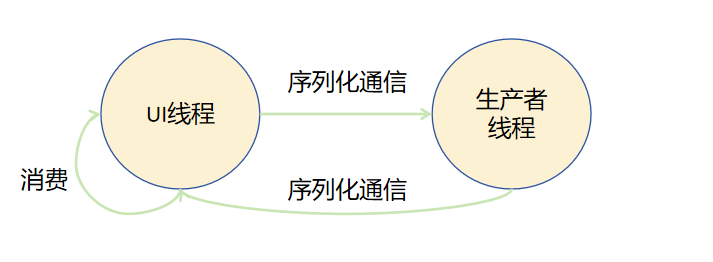
Actor模型
Actor模型不同角色之间并不共享内存,生产者线程和UI线程都有自己的虚拟机实例,两个虚拟机实例之间拥有独占的内存,相互隔离。生产者生产出结果后通过序列化通信将结果发送给UI线程,UI线程消费结果后再发送新的生产任务给生产者线程。
Actor并发模型对比内存共享并发模型的优势在于不同线程间内存隔离,不会产生不同线程竞争同一内存资源的问题。开发者不需要考虑对内存上锁导致的一系列功能、性能问题,提升了开发效率。
3 TaskPool简介
任务池(TaskPool)作用是为应用程序提供一个多线程的运行环境,降低整体资源的消耗、提高系统的整体性能,且您无需关心线程实例的生命周期。
TaskPook运作机制
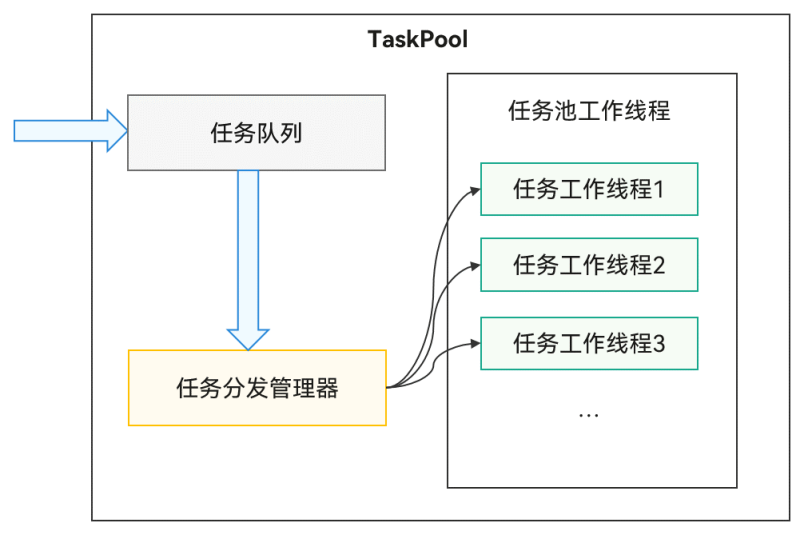
TaskPool支持开发者在宿主线程封装任务抛给任务队列,系统选择合适的工作线程,进行任务的分发及执行,再将结果返回给宿主线程。接口直观易用,支持任务的执行、取消,以及指定优先级的能力,同时通过系统统一线程管理,结合动态调度及负载均衡算法,可以节约系统资源。系统默认会启动一个任务工作线程,当任务较多时会扩容,工作线程数量上限跟当前设备的物理核数相关,具体数量内部管理,保证最优的调度及执行效率,长时间没有任务分发时会缩容,减少工作线程数量。
TaskPool注意事项
- 实现任务的函数需要使用@Concurrent装饰器标注,且仅支持在.ets文件中使用。
- 从API version 11开始,跨并发实例传递带方法的实例对象时,该类必须使用装饰器@Sendable装饰器标注,且仅支持在.ets文件中使用。
- 任务函数在TaskPool工作线程的执行耗时不能超过3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时),否则会被强制退出。
- 实现任务的函数入参需满足序列化支持的类型
- ArrayBuffer参数在TaskPool中默认转移,需要设置转移列表的话可通过接口setTransferList()设置。
- 由于不同线程中上下文对象是不同的,因此TaskPool工作线程只能使用线程安全的库,例如UI相关的非线程安全库不能使用。
- 序列化传输的数据量大小限制为16MB。
- Priority的IDLE优先级是用来标记需要在后台运行的耗时任务(例如数据同步、备份),它的优先级别是最低的。这种优先级标记的任务只会在所有线程都空闲的情况下触发执行,并且只会占用一个线程来执行。
- Promise不支持跨线程传递,如果TaskPool返回pending或rejected状态的Promise,会返回失败;对于fulfilled状态的Promise,TaskPool会解析返回的结果,如果结果可以跨线程传递,则返回成功。
- 不支持在TaskPool工作线程中使用AppStorage。
- TaskPool支持开发者在宿主线程封装任务抛给任务队列,理论上可以支持任意多的任务,但任务的执行受限于任务的优先级以及系统资源的影响,在工作线程扩容到最大后,可能会导致任务的执行效率下降。
说明
由于@Concurrent标记的函数不能访问闭包,因此@Concurrent标记的函数内部不能调用当前文件的其他函数,例如:
function bar() {
}@Concurrent
function foo() {
bar(); // 违反闭包原则,报错
}
4 Worker简介
Worker主要作用是为应用程序提供一个多线程的运行环境,可满足应用程序在执行过程中与宿主线程分离,在后台线程中运行一个脚本进行耗时操作,极大避免类似于计算密集型或高延迟的任务阻塞宿主线程的运行。
Worker运作机制
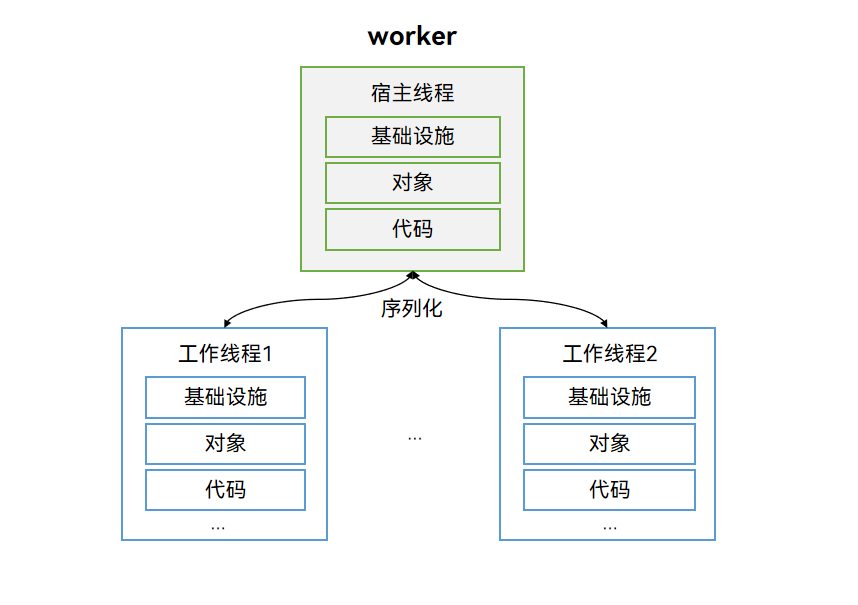
创建Worker的线程称为宿主线程(不一定是主线程,工作线程也支持创建Worker子线程),Worker自身的线程称为Worker子线程(或Actor线程、工作线程)。每个Worker子线程与宿主线程拥有独立的实例,包含基础设施、对象、代码段等,因此每个Worker启动存在一定的内存开销,需要限制Worker的子线程数量。Worker子线程和宿主线程之间的通信是基于消息传递的,Worker通过序列化机制与宿主线程之间相互通信,完成命令及数据交互。
4.1 Woker注意事项
- 创建Worker时,有手动和自动两种创建方式,手动创建Worker线程目录及文件时,还需同步进行相关配置,。
- 使用Worker能力时,构造函数中传入的Worker线程文件的路径在不同版本有不同的规则。
- Worker创建后需要手动管理生命周期,且最多同时运行的Worker子线程数量为64个。
- 由于不同线程中上下文对象是不同的,因此Worker线程只能使用线程安全的库,例如UI相关的非线程安全库不能使用。
- 序列化传输的数据量大小限制为16MB。
- 使用Worker模块时,需要在宿主线程中注册onerror接口,否则当Worker线程出现异常时会发生jscrash问题。
- 不支持跨HAP使用Worker线程文件。
- 引用HAR/HSP前,需要先配置对HAR/HSP的依赖。
- 不支持在Worker工作线程中使用AppStorage。
创建Worker的注意事项
Worker线程文件需要放在"{moduleName}/src/main/ets/"目录层级之下,否则不会被打包到应用中。有手动和自动两种创建Worker线程目录及文件的方式。
-
手动创建:开发者手动创建相关目录及文件,此时需要配置build-profile.json5的相关字段信息,Worker线程文件才能确保被打包到应用中。
Stage模型:
"buildOption": {"sourceOption": {"workers": ["./src/main/ets/workers/worker.ets"]} }FA模型:
"buildOption": {"sourceOption": {"workers": ["./src/main/ets/MainAbility/workers/worker.ets"]} } -
自动创建:DevEco Studio支持一键生成Worker,在对应的{moduleName}目录下任意位置,点击鼠标右键 > New > Worker,即可自动生成Worker的模板文件及配置信息,无需再手动在build-profile.json5中进行相关配置。
文件路径注意事项
当使用Worker模块具体功能时,均需先构造Worker实例对象,其构造函数与API版本相关,且构造函数需要传入Worker线程文件的路径(scriptURL)。
// 导入模块
import { worker } from '@kit.ArkTS';// API 9及之后版本使用:
const worker1: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/worker.ets');
// API 8及之前版本使用:
const worker2: worker.Worker = new worker.Worker('entry/ets/workers/worker.ets');
Stage模型下的文件路径规则
构造函数中的scriptURL要求如下:
- scriptURL的组成包含 {moduleName}/ets 和相对路径 relativePath。
- relativePath是Worker线程文件相对于"{moduleName}/src/main/ets/"目录的相对路径。
1) 加载Ability中Worker线程文件场景
加载Ability中的worker线程文件,加载路径规则:{moduleName}/ets/{relativePath}。
import { worker } from '@kit.ArkTS';// worker线程文件所在路径:"entry/src/main/ets/workers/worker.ets"
const workerStage1: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/worker.ets');// worker线程文件所在路径:"testworkers/src/main/ets/ThreadFile/workers/worker.ets"
const workerStage2: worker.ThreadWorker = new worker.ThreadWorker('testworkers/ets/ThreadFile/workers/worker.ets');
2) 加载HSP中Worker线程文件场景
加载HSP中worker线程文件,加载路径规则:{moduleName}/ets/{relativePath}。
import { worker } from '@kit.ArkTS';// worker线程文件所在路径: "hsp/src/main/ets/workers/worker.ets"
const workerStage3: worker.ThreadWorker = new worker.ThreadWorker('hsp/ets/workers/worker.ets');
3) 加载HAR中Worker线程文件场景
加载HAR中worker线程文件存在以下两种情况:
- @标识路径加载形式:所有种类的模块加载本地HAR中的Worker线程文件,加载路径规则:@{moduleName}/ets/{relativePath}。
- 相对路径加载形式:本地HAR加载该包内的Worker线程文件,加载路径规则:创建Worker对象所在文件与Worker线程文件的相对路径。
说明
当开启useNormalizedOHMUrl(即将工程目录中与entry同级别的应用级build-profile.json5文件中strictMode属性的useNormalizedOHMUrl字段配置为true)或HAR包会被打包成三方包使用时,则HAR包中使用Worker仅支持通过相对路径的加载形式创建。
import { worker } from '@kit.ArkTS';// @标识路径加载形式:
// worker线程文件所在路径: "har/src/main/ets/workers/worker.ets"
const workerStage4: worker.ThreadWorker = new worker.ThreadWorker('@har/ets/workers/worker.ets');// 相对路径加载形式:
// worker线程文件所在路径: "har/src/main/ets/workers/worker.ets"
// 创建Worker对象的文件所在路径:"har/src/main/ets/components/mainpage/MainPage.ets"
const workerStage5: worker.ThreadWorker = new worker.ThreadWorker('../../workers/worker.ets');
FA模型下的文件路径规则
构造函数中的scriptURL为:Worker线程文件与"{moduleName}/src/main/ets/MainAbility"的相对路径。
import { worker } from '@kit.ArkTS';// 主要说明以下三种场景:// 场景1: Worker线程文件所在路径:"{moduleName}/src/main/ets/MainAbility/workers/worker.ets"
const workerFA1: worker.ThreadWorker = new worker.ThreadWorker("workers/worker.ets", {name:"first worker in FA model"});// 场景2: Worker线程文件所在路径:"{moduleName}/src/main/ets/workers/worker.ets"
const workerFA2: worker.ThreadWorker = new worker.ThreadWorker("../workers/worker.ets");// 场景3: Worker线程文件所在路径:"{moduleName}/src/main/ets/MainAbility/ThreadFile/workers/worker.ets"
const workerFA3: worker.ThreadWorker = new worker.ThreadWorker("ThreadFile/workers/worker.ets");
生命周期注意事项
- Worker的创建和销毁耗费性能,建议开发者合理管理已创建的Worker并重复使用。Worker空闲时也会一直运行,因此当不需要Worker时,可以调用terminate()]接口或close()方法主动销毁Worker。若Worker处于已销毁或正在销毁等非运行状态时,调用其功能接口,会抛出相应的错误。
- Worker的数量由内存管理策略决定,设定的内存阈值为1.5GB和设备物理内存的60%中的较小者。在内存允许的情况下,系统最多可以同时运行64个Worker。如果尝试创建的Worker数量超出这一上限,系统将抛出错误:“Worker initialization failure, the number of workers exceeds the maximum.”。实际运行的Worker数量会根据当前内存使用情况动态调整。一旦所有Worker和主线程的累积内存占用超过了设定的阈值,系统将触发内存溢出(OOM)错误,导致应用程序崩溃。
4.2 Woker基本用法示例
-
DevEco Studio支持一键生成Worker,在对应的{moduleName}目录下任意位置,点击鼠标右键 > New > Worker,即可自动生成Worker的模板文件及配置信息。本文以创建“worker”为例。
-
导入Worker模块。
// Index.ets import { ErrorEvent, MessageEvents, worker } from '@kit.ArkTS' -
在宿主线程中通过调用ThreadWorker的constructor()方法创建Worker对象,当前线程为宿主线程,并注册回调函数。
// Index.ets @Entry @Component struct Index {@State message: string = 'Hello World';build() {RelativeContainer() {Text(this.message).id('HelloWorld').fontSize(50).fontWeight(FontWeight.Bold).alignRules({center: { anchor: '__container__', align: VerticalAlign.Center },middle: { anchor: '__container__', align: HorizontalAlign.Center }}).onClick(() => {// 创建Worker对象let workerInstance = new worker.ThreadWorker('entry/ets/workers/worker.ets');// 注册onmessage回调,当宿主线程接收到来自其创建的Worker通过workerPort.postMessage接口发送的消息时被调用,在宿主线程执行workerInstance.onmessage = (e: MessageEvents) => {let data: string = e.data;console.info("workerInstance onmessage is: ", data);}// 注册onerror回调,当Worker在执行过程中发生异常时被调用,在宿主线程执行workerInstance.onerror = (err: ErrorEvent) => {console.info("workerInstance onerror message is: " + err.message);}// 注册onmessageerror回调,当Worker对象接收到一条无法被序列化的消息时被调用,在宿主线程执行workerInstance.onmessageerror = () => {console.info('workerInstance onmessageerror');}// 注册onexit回调,当Worker销毁时被调用,在宿主线程执行workerInstance.onexit = (e: number) => {// 当Worker正常退出时code为0,异常退出时code为1console.info("workerInstance onexit code is: ", e);}// 向Worker线程发送消息workerInstance.postMessage('1');})}.height('100%').width('100%')} } -
在Worker文件中注册回调函数。
// worker.ets import { ErrorEvent, MessageEvents, ThreadWorkerGlobalScope, worker } from '@kit.ArkTS';const workerPort: ThreadWorkerGlobalScope = worker.workerPort;// 注册onmessage回调,当Worker线程收到来自其宿主线程通过postMessage接口发送的消息时被调用,在Worker线程执行 workerPort.onmessage = (e: MessageEvents) => {let data: string = e.data;console.info('workerPort onmessage is: ', data);// 向主线程发送消息workerPort.postMessage('2'); }// 注册onmessageerror回调,当Worker对象接收到一条无法被序列化的消息时被调用,在Worker线程执行 workerPort.onmessageerror = () => {console.info('workerPort onmessageerror'); }// 注册onerror回调,当Worker在执行过程中发生异常被调用,在Worker线程执行 workerPort.onerror = (err: ErrorEvent) => {console.info('workerPort onerror err is: ', err.message); }
5. TaskPool和Worker的对比
TaskPool(任务池)和Worker的作用是为应用程序提供一个多线程的运行环境,用于处理耗时的计算任务或其他密集型任务。可以有效地避免这些任务阻塞宿主线程,从而最大化系统的利用率,降低整体资源消耗,并提高系统的整体性能。
5.1 实现特点对比
| 实现 | TaskPool | Worker |
|---|---|---|
| 内存模型 | 线程间隔离,内存不共享。 | 线程间隔离,内存不共享。 |
| 参数传递机制 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。支持ArrayBuffer转移和SharedArrayBuffer共享。 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。支持ArrayBuffer转移和SharedArrayBuffer共享。 |
| 参数传递 | 直接传递,无需封装,默认进行transfer。 | 消息对象唯一参数,需要自己封装。 |
| 方法调用 | 直接将方法传入调用。 | 在Worker线程中进行消息解析并调用对应方法。 |
| 返回值 | 异步调用后默认返回。 | 主动发送消息,需在onmessage解析赋值。 |
| 生命周期 | TaskPool自行管理生命周期,无需关心任务负载高低。 | 开发者自行管理Worker的数量及生命周期。 |
| 任务池个数上限 | 自动管理,无需配置。 | 同个进程下,最多支持同时开启64个Worker线程,实际数量由进程内存决定。 |
| 任务执行时长上限 | 3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时),长时任务无执行时长上限。 | 无限制。 |
| 设置任务的优先级 | 支持配置任务优先级。 | 不支持。 |
| 执行任务的取消 | 支持取消已经发起的任务。 | 不支持。 |
| 线程复用 | 支持。 | 不支持。 |
| 任务延时执行 | 支持。 | 不支持。 |
| 设置任务依赖关系 | 支持。 | 不支持。 |
| 串行队列 | 支持。 | 不支持。 |
| 任务组 | 支持。 | 不支持。 |
5.2 适用场景对比
由于TaskPool的工作线程会绑定系统的调度优先级,并且支持负载均衡(自动扩缩容),而Worker需要开发者自行创建,存在创建耗时以及不支持设置调度优先级,故在性能方面使用TaskPool会优于Worker,因此大多数场景推荐使用TaskPool。
常见的一些开发场景及适用具体说明如下:
- 运行时间超过3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时)的任务。例如后台进行1小时的预测算法训练等CPU密集型任务,需要使用Worker。
- 有关联的一系列同步任务。例如在一些需要创建、使用句柄的场景中,句柄创建每次都是不同的,该句柄需永久保存,保证使用该句柄进行操作,需要使用Worker。
- 需要设置优先级的任务。例如图库直方图绘制场景,后台计算的直方图数据会用于前台界面的显示,影响用户体验,需要高优先级处理,需要使用TaskPool。
- 需要频繁取消的任务。例如图库大图浏览场景,为提升体验,会同时缓存当前图片左右侧各2张图片,往一侧滑动跳到下一张图片时,要取消另一侧的一个缓存任务,需要使用TaskPool。
- 大量或者调度点较分散的任务。例如大型应用的多个模块包含多个耗时任务,不方便使用Worker去做负载管理,推荐采用TaskPool。
- 对于需要频繁数据库操作的场景,由于读写数据库存在耗时,因此推荐在子线程中操作,避免阻塞UI线程,推荐使用TaskPool。
相关文章:
HarmonyOS中的多线程并发机制
目录 多线程并发1. 多线程并发概述2 多线程并发模型3 TaskPool简介4 Worker简介4.1 Woker注意事项4.2 Woker基本用法示例 5. TaskPool和Worker的对比5.1 实现特点对比5.2 适用场景对比 多线程并发 1. 多线程并发概述 并发模型是用来实现不同应用场景中并发任务的编程模型&…...

机器学习 | 强化学习方法分类汇总 | 概念向
文章目录 📚Model-Free RL vs Model-Based RL🐇核心定义🐇核心区别📚Policy-Based RL vs Value-Based RL🐇核心定义🐇 核心区别📚Monte-Carlo update vs Temporal-Difference update🐇核心定义🐇核心区别📚On-Policy vs Off-Policy🐇核心定义🐇核心区别…...

构件与中间件技术:概念、复用、分类及标准全解析
以下是对构件与中间件技术相关内容更详细的介绍: 一、构件与中间件技术的概念 1.构件技术 定义:构件是具有特定功能、可独立部署和替换的软件模块,它遵循一定的规范和接口标准,能够在不同的软件系统中被复用。构件技术就是以构…...
【随手笔记】QT避坑一(串口readyRead信号不产生)
问题描述: 使用QT5.15.2版本 测试串口readyRead绑定槽函数,接收到数据后 不能触发 试了很多网友的程序,他们的发布版本可以,但是源码我编译后就不能触发,判断不是代码的问题 看到有人提到QT版本的问题,于…...

基于 RabbitMQ 优先级队列的订阅推送服务详细设计方案
基于 RabbitMQ 优先级队列的订阅推送服务详细设计方案 一、架构设计 分层架构: 订阅管理层(Spring Boot)消息分发层(RabbitMQ Cluster)推送执行层(Spring Cloud Stream)数据存储层(Redis + MySQL)核心组件: +-------------------+ +-------------------+ …...

5.11 GitHub API调试五大高频坑:从JSON异常到异步阻塞的实战避坑指南
GitHub API调试五大高频坑:从JSON异常到异步阻塞的实战避坑指南 关键词:GitHub API 调试、JSON 解析异常、提示工程优化、异步任务阻塞、数据清洗策略 5.5 测试与调试:调试常见问题 问题1:GitHub API 调用异常 现象: requests.exceptions.HTTPError: 403 Client Error…...

反序列化漏洞介绍与挖掘指南
目录 反序列化漏洞介绍与挖掘指南 一、漏洞核心原理与危害 二、漏洞成因与常见场景 1. 漏洞根源 2. 高危场景 三、漏洞挖掘方法论 1. 静态分析 2. 动态测试 3. 利用链构造 四、防御与修复策略 1. 代码层防护 2. 架构优化 3. 运维实践 五、工具与资源推荐 总结 反…...
【产品】ToB产品需求分析
需求分析流程 合格产品经理 帮助用户、引导用户、分析需求、判断需求、设计方案 不能苛求用户提出合理、严谨的需求,这不是用户的责任和义务,而应该通过自己的专业能力来完成需求的采集工作 #mermaid-svg-ASu8vocank48X6FI {font-family:"trebuche…...
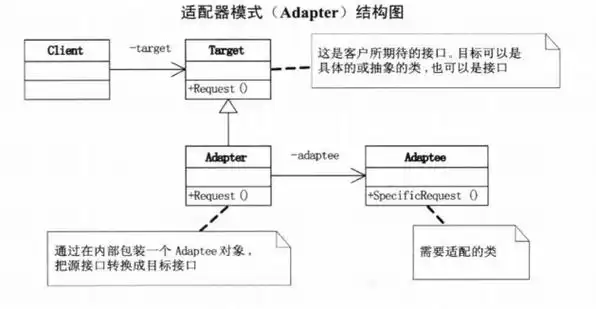
驱动开发硬核特训 · Day 10 (理论上篇):设备模型 ≈ 运行时的适配器机制
🔍 B站相应的视屏教程: 📌 内核:博文视频 - 总线驱动模型实战全解析 敬请关注,记得标为原始粉丝。 在 Linux 驱动开发中,设备模型(Device Model)是理解驱动架构的核心。而从软件工程…...

AWS服务器 磁盘空间升级到100G后,怎么使其生效?
在AWS(Amazon Web Services)上扩展EBS(Elastic Block Store)卷的大小后,服务器操作系统并不会自动识别新增的空间。要使操作系统识别并使用新增的磁盘空间,您需要进行一些额外的步骤。以下是详细的指导和说…...
flutter 打包mac程序 dmg教程
✅ 前提条件 ✅ 你已经在 macOS 上安装了 Android Studio Flutter SDK。 ✅ Flutter 支持 macOS 构建。 运行下面命令确认是否支持: Plain Text bash 复制编辑 flutter doctor ---## 🧱 第一步:启用 macOS 支持如果是新项目,…...
【数据结构与算法】——堆(补充)
前言 上一篇文章讲解了堆的概念和堆排序,本文是对堆的内容补充 主要包括:堆排序的时间复杂度、TOP 这里写目录标题 前言正文堆排序的时间复杂度TOP-K 正文 堆排序的时间复杂度 前文提到,利用堆的思想完成的堆排序的代码如下(包…...
atypica.AI:用「语言模型」为「主观世界」建模
人们不是在处理概率,而是在处理故事。 —— 丹尼尔卡尼曼 People dont choose between things, they choose between descriptions of things. —— Daniel Kahneman 商业研究是一门理解人类决策的学问。人并不只是根据纯粹理性做决策,而是受到叙事、情…...
LLaMA-Factory双卡4090微调DeepSeek-R1-Distill-Qwen-14B医学领域
unsloth单卡4090微调DeepSeek-R1-Distill-Qwen-14B医学领域后,跑通一下多卡微调。 1,准备2卡RTX 4090 2,准备数据集 医学领域 pip install -U huggingface_hub export HF_ENDPOINThttps://hf-mirror.com huggingface-cli download --resum…...

【WPF】自定义控件:ShellEditControl-同列单元格编辑支持文本框、下拉框和弹窗
需要实现表格同一列,单元格可以使用文本框直接输入编辑、下拉框选择和弹窗,文本框只能输入数字,弹窗中的数据是若干位的二进制值。 本文提供了两种实现单元格编辑状态下,不同编辑控件的方法: 1、DataTrigger控制控件的…...
)
21天Python计划:零障碍学语法(更新完毕)
目录 序号标题链接day1Python下载和开发工具介绍https://blog.csdn.net/XiaoRungen/article/details/146583769?spm1001.2014.3001.5501day2数据类型、字符编码、文件处理https://blog.csdn.net/XiaoRungen/article/details/146603325?spm1011.2415.3001.5331day3基础语法与…...

深入剖析C++单例模式的八种实现演进与工程实践
深入剖析C单例模式的八种实现演进与工程实践 一、从基础到工业级:单例模式的演进图谱 1.1 基础实现的致命缺陷分析 // 初级版(非线程安全) class NaiveSingleton { public:static NaiveSingleton* getInstance() {if (!instance) {instanc…...
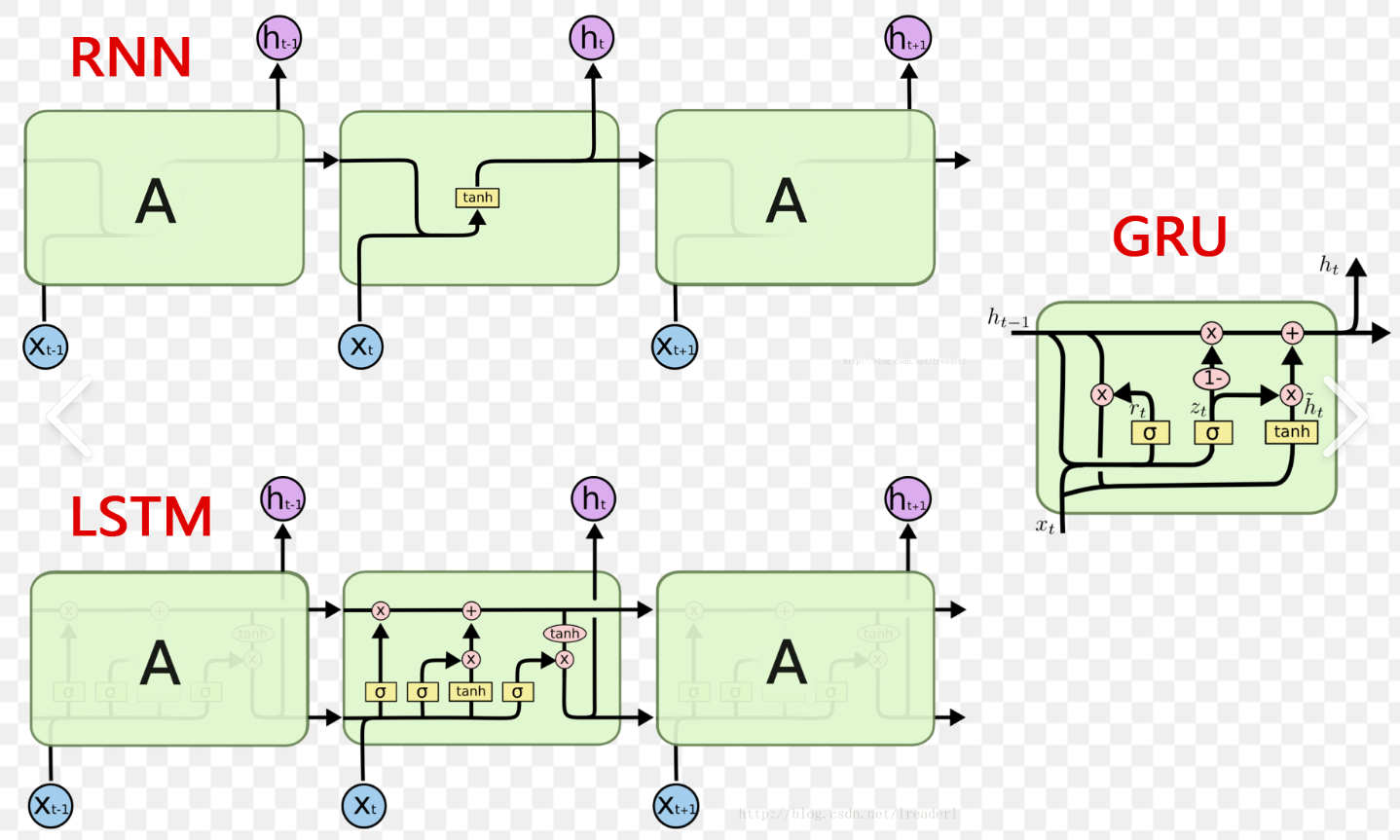
Seq2Seq - GRU补充讲解
nn.GRU 是 PyTorch 中实现门控循环单元(Gated Recurrent Unit, GRU)的模块。GRU 是一种循环神经网络(RNN)的变体,用于处理序列数据,能够更好地捕捉长距离依赖关系。 ⭐重点掌握输入输出部分输入张量&#…...

从零开始学Python游戏编程19-游戏循环模式1
在《从零开始学Python游戏编程18-函数3》中提到,可以对游戏代码进行重构,把某些代码写入函数中,主程序再调用这些函数,这样使得代码程序更容易理解和维护。游戏循环模式实际上也是把代码写入到若干个函数中,通过循环的…...

KWDB创作者计划—KWDB认知跃迁:多模架构与AI原生的数据库范式革命
引言:从存储到认知的范式迁移 在数字化转型进入深水区的2025年,全球每日新增数据量已突破3.5ZB,传统数据库的"存储-计算"二分法正面临根本性挑战。当AlphaFold4实现蛋白质全序列预测,工业数字孪生需处理百万级设备实时数…...
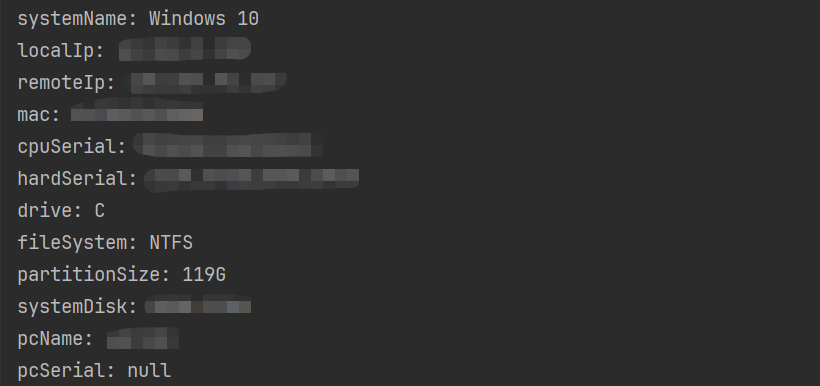
Java获取终端设备信息工具类
在很多场景中需要获取到终端设备的一些硬件信息等,获取的字段如下: 返回参数 参数含义备注systemName系统名称remoteIp公网iplocalIp本地ip取IPV4macmac地址去掉地址中的"-“或”:"进行记录cpuSerialcpu序列号hardSerial硬盘序列号drive盘符…...
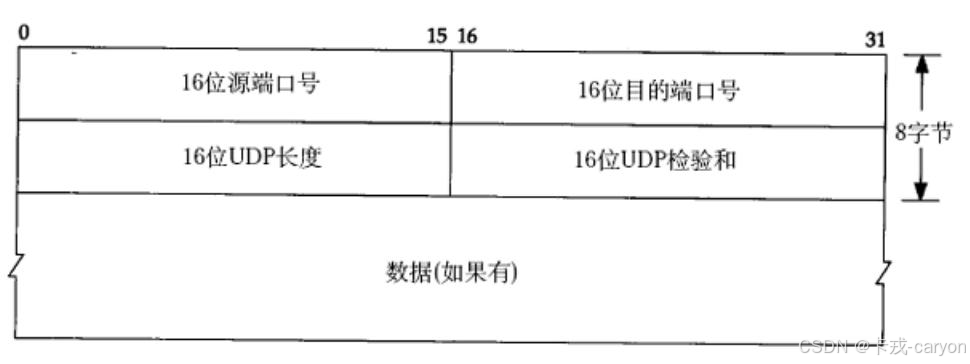
【Linux网络与网络编程】08.传输层协议 UDP
传输层协议负责将数据从发送端传输到接收端。 一、再谈端口号 端口号标识了一个主机上进行通信的不同的应用程序。在 TCP/IP 协议中,用 "源IP","源端口号","目的 IP","目的端口号"&…...
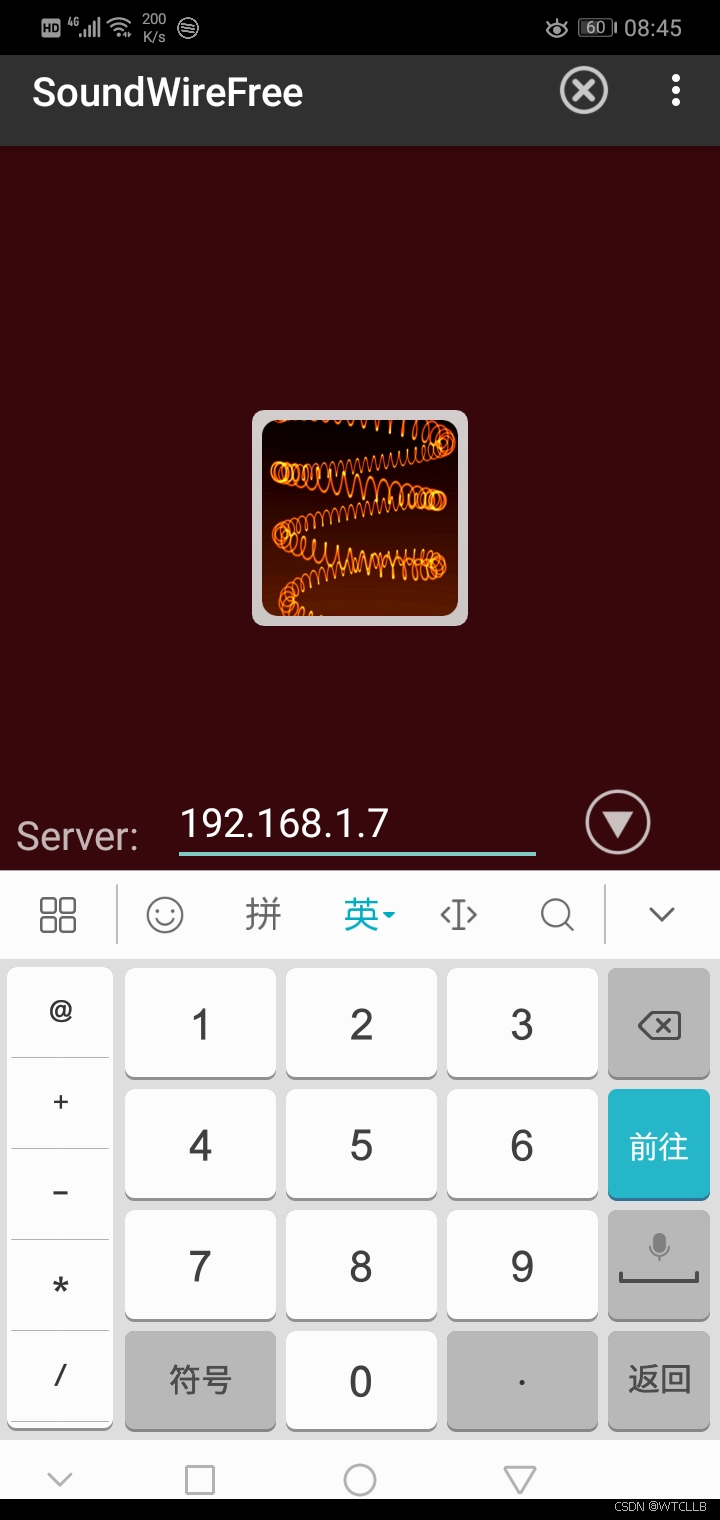
没音响没耳机,把台式电脑声音播放到手机上
第一步,电脑端下载安装e2eSoft VSC虚拟声卡(安装完成后关闭,不要点击和设置) 第二步,电脑端下载安装(SoundWire Server)(安装完成后不要关闭,保持默认配置) 第…...
如何在Spring Boot中集成Dubbo?)
Dubbo(53)如何在Spring Boot中集成Dubbo?
在Spring Boot中集成Dubbo可以通过Spring Boot Starter来简化配置,以下是详细的步骤和相关代码示例。 1. 引入依赖 首先,在Spring Boot项目的 pom.xml 中添加Dubbo相关的依赖: <dependencies><!-- Spring Boot Starter --><…...
)
go学习记录(第一天)
%v,和%q是什么意思 %v —— 默认格式("value" 的缩写) 作用:按值的默认格式输出,适用于任何类型。 代码示例: fmt.Printf("%v\n", "Hello") // 输出: Hello fmt.Printf…...

XDocument和XmlDocument的区别及用法
因为这几天用到了不熟悉的xml统计数据,啃了网上的资料解决了问题,故总结下xml知识。 1.什么是XML?2.XDocument和XmlDocument的区别3.XDocument示例1示例2:示例3: 4.XmlDocument5.LINQ to XML6.XML序列化(Serialize)与反序列化(De…...

error: failed to run custom build command for `yeslogic-fontconfig-sys v6.0.0`
rust使用plotters时遇到编译错误。 一、错误 error: failed to run custom build command for yeslogic-fontconfig-sys v6.0.0 二、解决方法 我用的是opensuse,使用下面命令可以解决问题。 sudo zypper in fontconfig-devel...
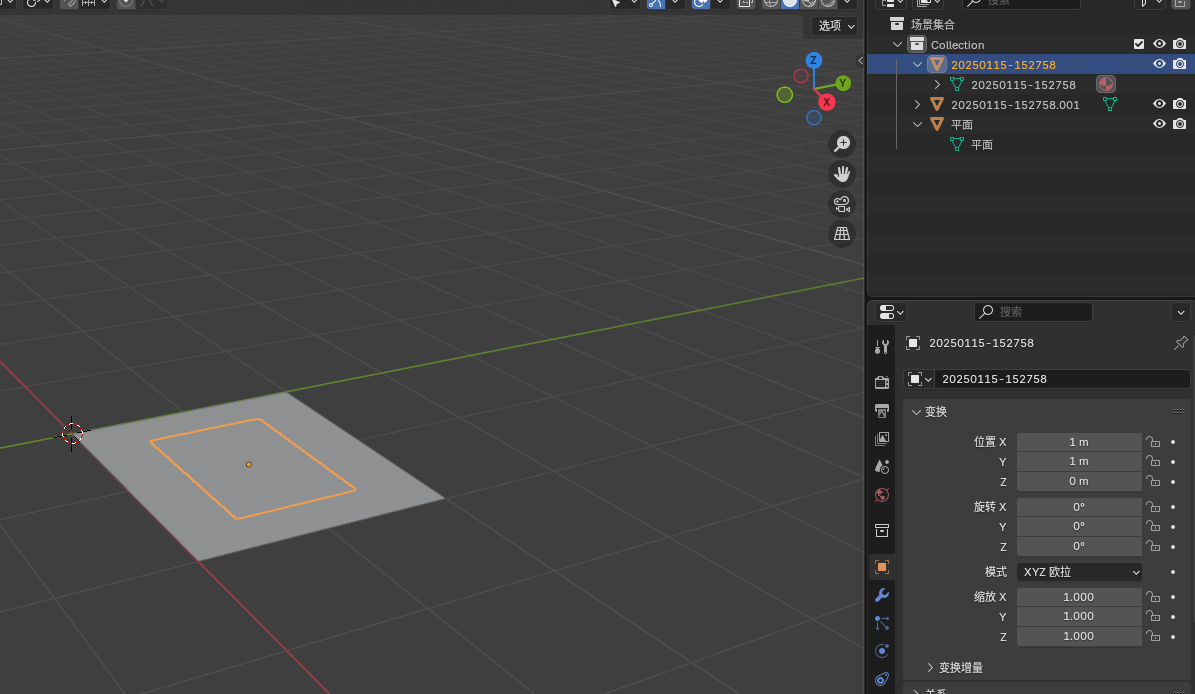
Blender安装基础使用教程
本博客记录安装Blender和基础使用,可以按如下操作来绘制标靶场景、道路标识牌等。 目录 1.安装Blender 2.创建面板资源 步骤 1: 设置 Blender 场景 步骤 2: 创建一个平面 步骤 3: 将 PDF 转换为图像 步骤 4-方法1: 添加材质并贴图 步骤4-方法2:创…...

GPT-4、Grok 3与Gemini 2.0 Pro:三大AI模型的语气、风格与能力深度对比
更新后的完整CSDN博客文章 以下是基于您的要求,包含修正后的幻觉率部分并保留原始信息的完整CSDN博客风格文章。幻觉率已调整为更符合逻辑的描述,其他部分保持不变。 GPT-4、Grok 3与Gemini 2.0 Pro:三大AI模型的语气、风格与能力深度对比 …...

【Git】从零开始使用git --- git 的基本使用
哪怕是野火焚烧,哪怕是冰霜覆盖, 依然是志向不改,依然是信念不衰。 --- 《悟空传》--- 从零开始使用git 了解 Gitgit创建本地仓库初步理解git结构版本回退 了解 Git 开发场景中,文档可能会经历若干版本的迭代。假如我们不进行…...