“破解”GPT-4o生图技术:万物皆可吉卜力的技术路线推测

👉目录
1 GPT-4o 的神奇魔法
2 GPT-4o 可能的技术路线推测
3 结语
最近 GPT-4o 生图模型横空出世,效果和玩法上都有突破性的进展,笔者整理了一下目前相关的技术,抛砖引玉一下,希望有更多大神分享讨论。

关注腾讯云开发者,一手技术干货提前解锁👇
鹅厂程序员面对面新一季直播继续,每周将邀请鹅厂明星技术大咖深入讲解技术话题,更有精美周边等你来拿,记得提前预约直播~👇
01
GPT-4o 的神奇魔法
最近GPT-4o生图模型横空出世,效果和玩法上都有突破性的进展,作为从SD开始一路跟进文生图模型技术的人来说看到这样的效果真的非常震惊,很好奇是怎么达到的,所以边研究边整理了一下目前相关的技术,抛砖引玉一下,希望有更多大神分享讨论(最好是OpenAI发技术报告多透露点)。
首先可能很多朋友只刷到过特别火也争议特别大的那个吉卜力风格化,但这其实不是什么新鲜的玩法了,只不过在效果上又更进一步。更加值得关注的其实是这次GPT-4o出了超多特别惊人的技术,基本上可以说是GPT本T长了手能画画了,不再存在GPT生成prompt命令呼叫DALLE3导致的信息损耗了。(最开始GPT还不会自己画图的时候,是通过调用文生图大模型DALLE3来画图的,而不是它本身能产生图片)
例如它可以写非常非常长的文字:

例如给定风格参考图让它画一个类似的海报:

例如直接通过对话修改图片:
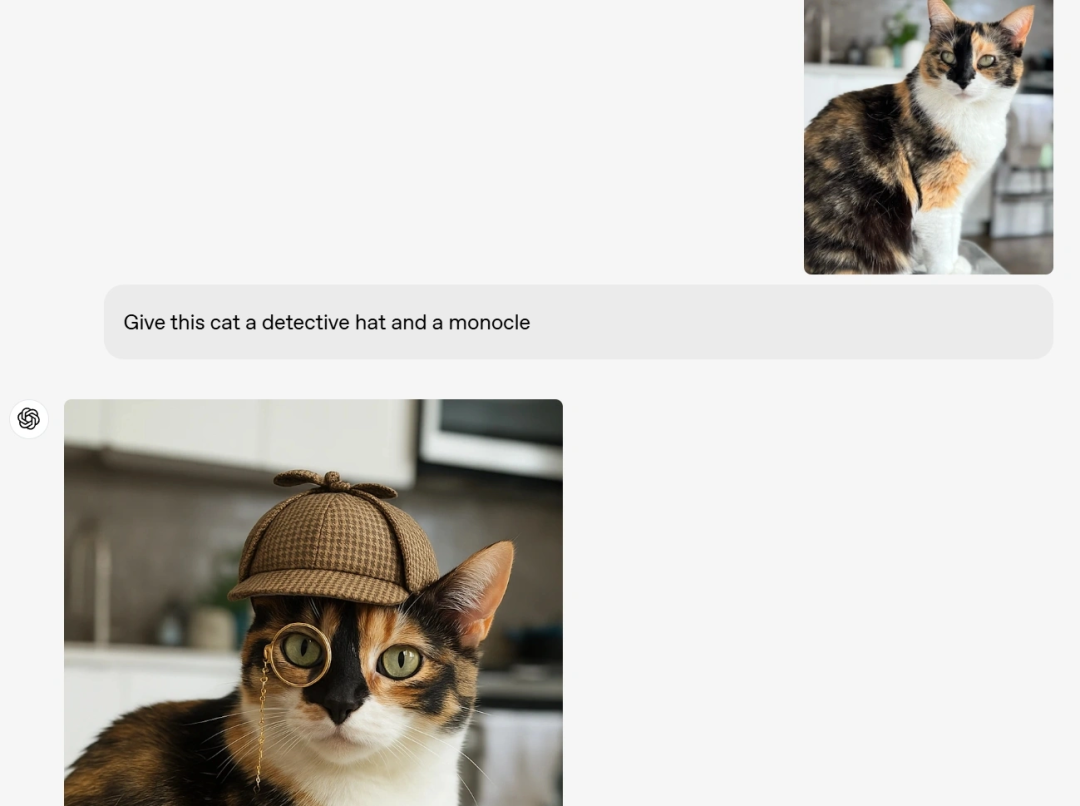
例如画一些漫画或者插画:

更多例子: https://openai.com/index/introducing-4o-image-generation/
这还只是官网的示例,这几天网友已经玩出更多层出不穷的花样了,比如转成动森风格、把家猫拟人化、制作表情包等等,只能说人类对GPT 4o生图能力的开发还不足1%。这些例子,都可以从各种意义上体现出,GPT模型自己长了个会画画的手,比调用另一个绘图模型在使用上有多大的变革。
比如说制造抹茶那个四格,如果是之前的流程,可能需要先让GPT生成抹茶做法的四个步骤,然后再让它把步骤转换成文生图模型的prompt,再调用DALLE3把图片画出来。每一个步骤都可能有损耗,尤其是最后一步,DALLE3可能没办法有这么好的文本对应性能精准画出这样的内容。但是GPT如果本来就会画画,事情就会变得很自然了。我们都知道GPT内部肯定是已经有关于如何制作抹茶的知识的,不止如此,GPT-4o还是一个多模态大模型。多模态的意思是它能够理解各种形式的信息,例如文字、图片、语言等。所以它同样也见过大量的“如何制作xx”这样的海报。于是它就可以直接结合这些知识生成这个结果。
又例如猫猫那张图给定参考图来画新的图和用对话编辑图片也是非常自然。原本如果要做这些,用过SD系列工具的人会知道,你需要有一个实现这些功能的workflow,把各种模块组合在一起,让这些参考图以各种形式注入信息到模型,然后diffusion模型再接受这些信息作为生成图片的条件去完成指令。但其实diffusion原生是不支持这些编辑功能的,所以每个功能都需要单独作为一个任务去训练优化。但是其实这些任务本质上都是差不多的,只不过diffusion没有auto regressive model这样一切皆可tokenized的flexibility(这部分技术后面再解释)。所以GPT一旦能够生成高质量的图片,这些图片编辑操作能做得比diffusion模型好是非常自然而然水到渠成的事情。
OpenAI在做GPT 3.5(也就是最初的ChatGPT)的时候就很喜欢这种大一统的路线,在大家都在做专用模型(翻译模型、打分模型、聊天机器人等)的时候坚持做通用模型(一个模型解决所有任务)。它们最开始的DALLE 1也是基于自回归的,从DALLE 2开始自回归效果被扩散模型超越,DALLE 3就是完全基于扩散模型了。但现在看来,它们内部应该一直没有放弃过自回归的路线,因为多模态自回归模型能够更好地把文字、图片、声音等信息统一到一起,从长远看来有更大的好处。
02
GPT-4o 可能的技术路线推测
那么GPT-4o是如何做到的呢?接下来我说的是我结合社区讨论的一些猜想,不代表实际使用的技术。
首先是以CloseAI著称的OpenAI依然几乎没有透露任何技术细节,只说了新模型是基于自回归(auto-regression)的。
The system uses an autoregressive approach — generating images sequentially from left to right and top to bottom, similar to how text is written — rather than the diffusion model technique used by most image generators (like DALL-E) that create the entire image at once. Goh speculates that this technical difference could be what gives Images in ChatGPT better text rendering and binding capabilities. 该系统采用自回归方法——按顺序从左到右、从上到下生成图像,类似于文本的书写方式——而不是大多数图像生成器(如 DALL-E)使用的扩散模型技术,后者一次创建整个图像。Goh 推测,这种技术差异可能是 ChatGPT 中的图像具有更好的文本渲染和绑定功能的原因。 (出自: https://www.theverge.com/openai/635118/chatgpt-sora-ai-image-generation-chatgpt) |

另外在官方示例的这张板书上写了“compose autoregressive prior with a powerful decoder”,右下角也写了tokens->[transformer]->[diffusion] pixels。所以现在社区上最主流的推测是使用了基于transformer的自回归架构,配合强大的diffusion decoder,达到的现在的效果。
2.1 自回归与tokenization
首先解释一下自回归,自回归被大量用于文字领域,因为它说白了就是一个接龙的过程。自回归模型把生成内容看成一系列无法穷举但是有固定范围的序列,这个序列可以是固定长度的也可以是不固定的,每次生成的时候会输入之前的所有结果。
例如“你是谁?”模型在回答的时候就会先预测第一个字“我”,然后输入变成了“你是谁?我”,模型会认为下一个字大概率是“是”,之后再给模型输入“你是谁?我是”以此类推,一直到模型认为可以结束了,就会输出一个[END]的标记。遇到这个标记就可以停止继续生成了。
这个自回归模型被大量用在文字上,因为文字非常天然地符合自回归生成的逻辑。自回归模型的经典架构就是transformer,因为transformer对于较长的输入有着比之前的算法更优的计算方式(注意力机制,这个以后有机会再解释),所以在transformer问世之后在NLP领域嘎嘎乱杀一直到现在大语言模型发展得如此迅猛。
但是主流的文生图模型并不是基于自回归架构的,而是扩散模型。扩散模型是一种非自回归模型(Non Auto-Regressive Generation,NAR),它的图片是一次性生成全图再逐渐细化。
当然openAI早在2020年就尝试过了自回归生成图片: https://openai.com/index/image-gpt/就是逐行生成图片的,只不过后面自回归这条技术路线逐渐被扩散模型超越取代。自回归方式生成图片遇到的第一个问题就是,图片的可能性太多了。
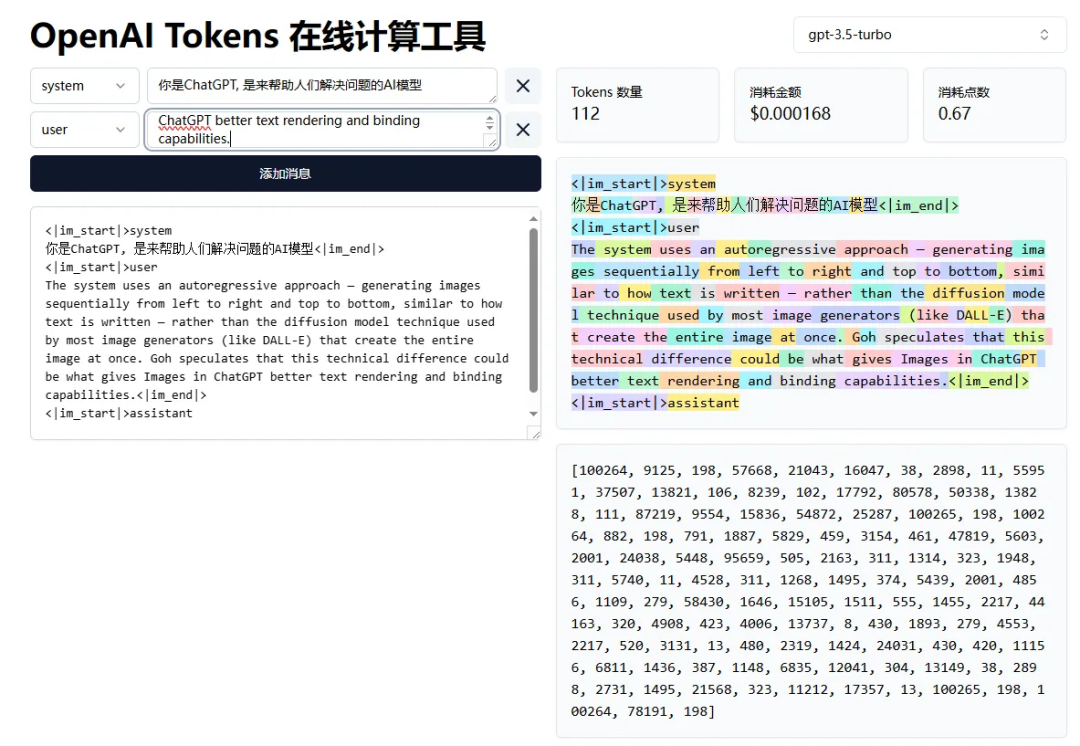
自回归里有一个重要的概念叫token,就是GPT里按token收费的那个token。所有的tokens组成codebook,这个codebook也不能太大,越大计算量就越大(自回归的每一次生成可以近似看成分类问题,而记录所有类别的表格就是这个codebook)。自回归本质上是token接龙,比如在中文里,每个中文汉字可以是一个token,因为汉字的数量是有限的。在英文里,英文单词也可以是一个token,不过实际上是用词根作为token,因为英文随时会出现新造的单词,这些单词依然可以用已有的词根组成。可以看到,文字是很好tokenized的,这也是自回归在语言模型被广泛使用的原因之一。
这里是一个token可视化的在线工具的分析结果:https://tiktoken.aigc2d.com/
所以基于自回归的多模态大模型,本质上依然也是这些token接龙,只不过多模态支持图像,声音等作为输入、输出,那就必须要把这些媒介也转换成可穷举的tokens。
直接拿像素点作为token可行吗?一个像素有RGB三个通道,每个通道有0~255个取值,一共就是255^3 种可能,是可以穷举的。但是这样的话生成速度太慢了。一张1024* 1024的图相当于一段一百万字的文章(为方便理解假设一个字是一个token)。于是很自然地,大家想到了使用auto-encoder对图像进行压缩。
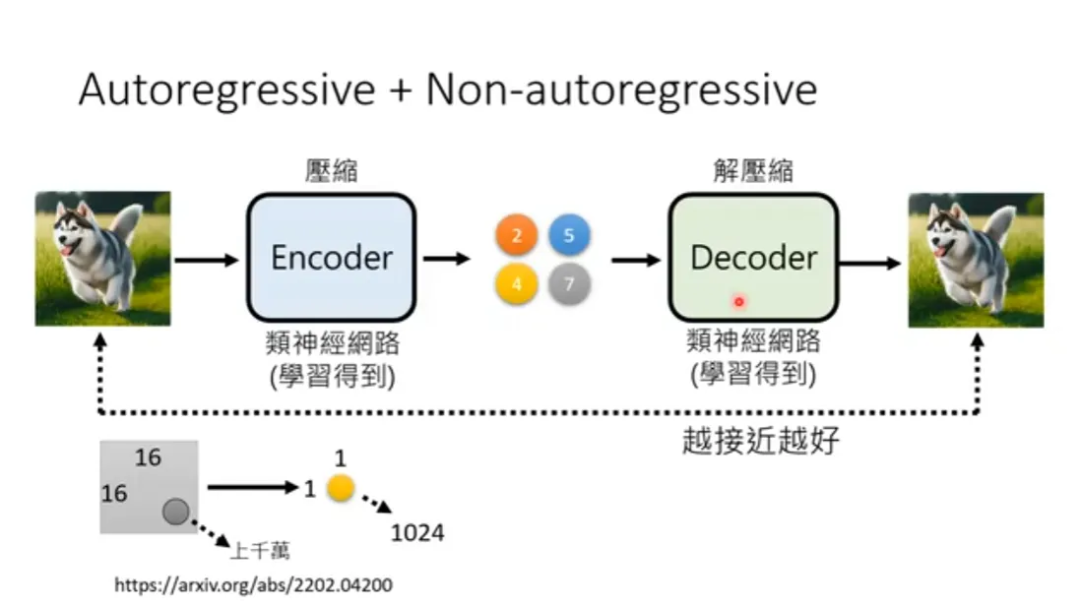
有了 auto-encoder 以后就可以把压缩后的 token 拿去训练自回归网络,然后让自回归网络做 token 接龙,再拿 decoder 把 token 转换回图片了。
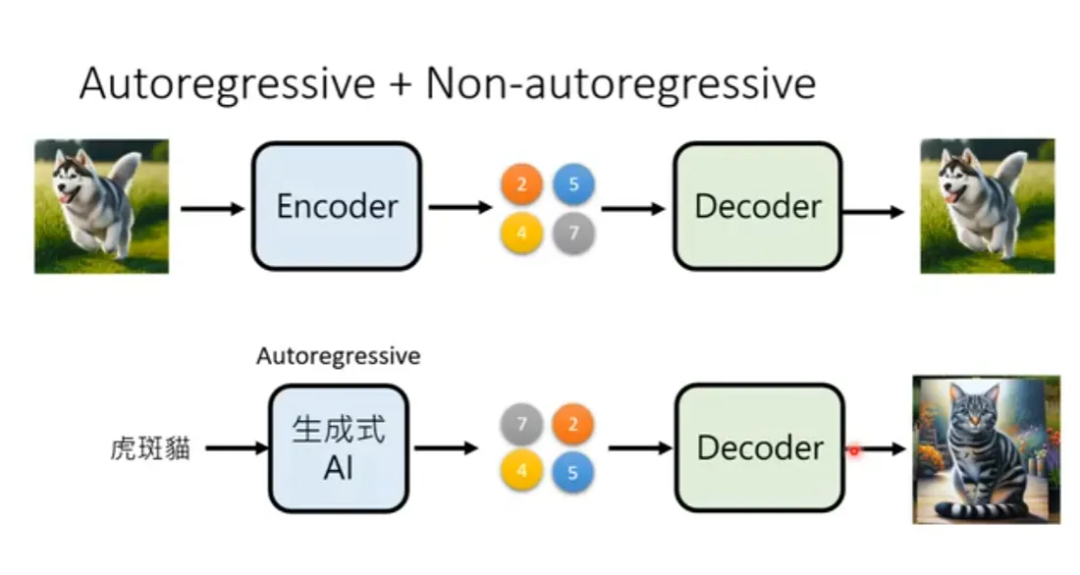
(图源:李宏毅《生成式AI导论 2024》)
2.2 图像 Tokenizer 进阶之路
VQ-VAE
提到Auto-encoder一定会第一个想到VAE。VAE就是一个基于卷积的对称的压缩-解码结构,它可以把图片压缩到一个非常小的空间上(latent space)然后再解压缩还原为原图。知名的stable diffusion(和后续的绝大部分主流文生图模型)都有使用VAE来先把图片进行压缩,再在latent维度上做去噪。VAE的性能是直接和生图效果挂钩的,比如之前SD很难生成低分辨率的小人脸,如果你直接把图片过一遍VAE你会发现只是用VAE复原回去以后脸就糊了,因为信息被高度压缩了,而不(只)是因为生图过程的不准确造成的。
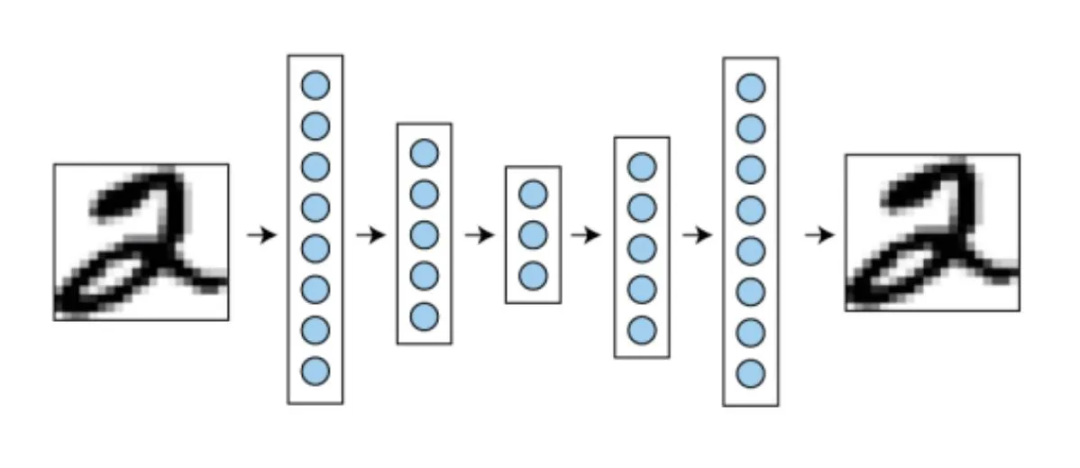
自回归和diffusion model使用的VAE不一样的地方在于,自回归的codebook大小是有限的,而VAE的latent space是连续的,所以会多出一个离散化(量化)的步骤,也就是VQ-VAE。这里的VQ就是vector quantization,向量量化。向量量化可以类比理解为一个hash或者聚类过程,把连续的值以特定方式映射到codebook中。量化的本质是为了进一步压缩信息和降维,同时也是自回归生成的前提(预测元素需要是可穷举的)。
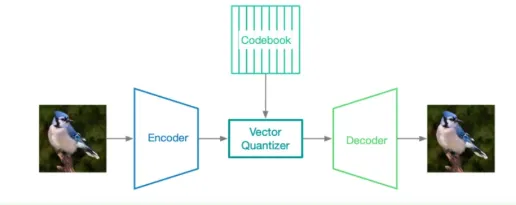
图源:图像 Token 化:视觉数据转换的关键技术(https://www.breezedeus.com/article/image-tokenizers)
但是如果把一张图片的latent vector对应到codebook里的一个token,很明显decoder的信息量是不够的,因为把信息压缩得太极限了。所以通常会把图片切为一个个小格(patch),这样就够用了,这个操作的名字叫patchify。对应的,如果基于自回归,图片也会以一个一个token按顺序生成,最后经过解码组成一张大图,这个操作叫做Unpatchify。
VQ-GAN
接下来的路线搞CV的应该很熟悉。可以看出来图像tokenize有两个最重要的指标,一个是图片压缩度,一个是图片还原度。而还原图片的质量和Decoder的能力是强相关的。VAE在图像生成上有各种硬伤,例如图片会趋向于模糊。于是很自然地,大家就想到增加对抗loss来提升效果,这就是VQ-GAN。
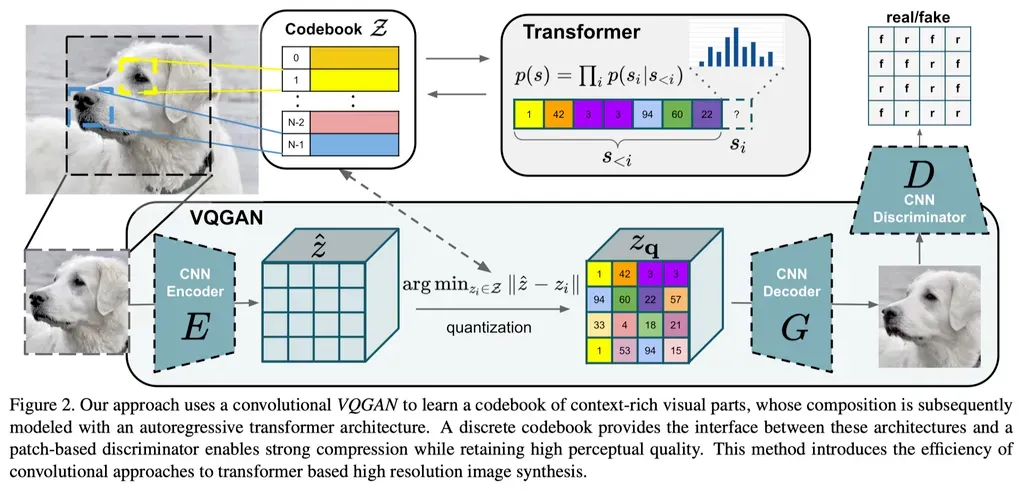
图源: Taming Transformers for High-Resolution Image Synthesis (https://compvis.github.io/taming-transformers/)
可以看到从结构上主要是比VQ-VAE多了一个判别器,同时训练上也使用了GAN常用的感知损失代替VAE的像素级损失(如MSE),可以简单理解为前者对比的是生成数据和训练数据更高层级的特征对应性(通过预训练的神经网络提取特征),后者则是简单计算两张图片的距离(每个像素之间差多少)。图片tokenizer并不是自回归的专属,后续的一些扩散模型如SD 3也引入了VQ-GAN来提升生成质量。
FlowMo
按照这个发展脉络,接下来就该轮到diffusion model出场了。李飞飞团队出了一篇新的paper叫Flow to the Mode(感觉在玩fly me to the moon的梗),简称FlowMo,就是采用了目前最流行的MMDiT(多模态transformer结构的扩散模型)和Rectified flow(比传统扩散模型更高效的一种“走直线”的求解方法)的方法训练Decoder。
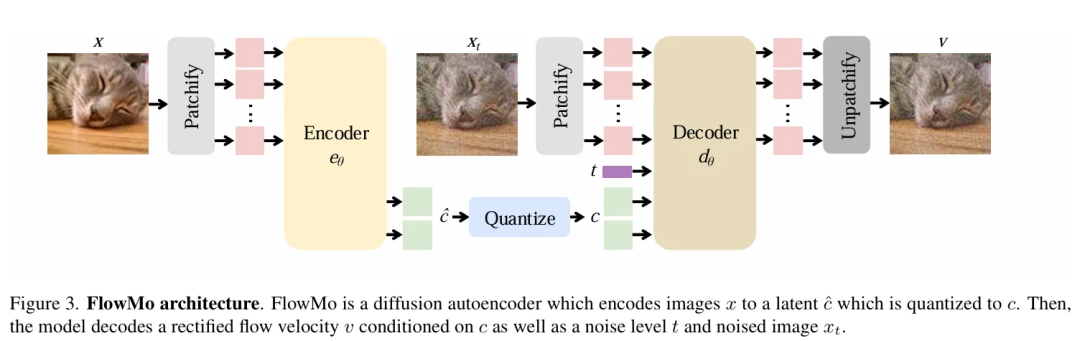
图源:Flow to the Mode(https://arxiv.org/pdf/2503.11056)
FlowMo的Encoder和Decoder架构都是MMDiT,不含任何卷积层,其中Decoder相比之前的架构,还多一个t作为输入,对应扩散模型的多步渲染。FlowMo在训练时分为了两个阶段,第一个阶段Decoder只做一步去噪,训练好Encoder、VQ、Decoder后,第二个阶段还会固定Encoder,单独对Decoder在8步去噪上进一步训练,以提升Decoder的生成效果。这个方法也在图像压缩上取得了目前最好的效果,也就是可以在最少的信息量(BPP,Bits per Pixel)上最好地还原图片。当然我想耗时肯定也是比之前的方法慢很多的,GPT-4o的图像生成确实是慢一些,不过相比带来的好处,这点耗时也是可以接受的。而且相比于训练上的极大开销,通过适当延长推理耗时来提升效果也是一个性价比极高的操作,例如Deepseek R1的深度思考或者说Chain of thought。
有了这类更强力的图像tokenization和训练策略的提升,最后的结果就是GPT-4o一旦训练好,在图像生成、控制、编辑、语义理解等维度超出现有方法很多很多,并且是一个通用模型而不是专家模型(只专精于特定任务)。
2.3 自回归:Next-Token Prediction is All You Need
以Emu3为例,我们来看看基于自回归的多模态大模型有哪些特殊之处。
Token统一化
Emu3是一个纯粹基于自回归预测下一个token,把图像、文本和视频编码为同一个离散空间训练的多模态大模型。和纯文本LLM相比,它的codebook除了文本token还包含了视觉token(基于SBER-MoVQGAN),为了统一格式,使用了如下的特殊标记:
[BOS]{文本}[SOV]{元数据}[SOT]{视觉tokens}[EOV][EOS][BOS]和[EOS]是文本的开始和结束符号。
[SOV]和[EOV]是视觉输入的开始和结束符号。
[SOT]是视觉tokens的开始符号。
通过这样的结构,纯文本数据和图文数据对(图片+caption)都可以统一输入给模型训练。
大模型训练策略
然后是训练策略,这部分和纯文本LLM比较相似。让我们先回顾一下ChatGPT为首的LLM训练流程:
预训练阶段:也就是准备海量的数据让模型看,提供丰富的前置知识。此时模型只会模仿人类的数据,例如你问模型“世界上最高的山峰是什么?”模型有可能会输出:“A,阿尔卑斯山,B,珠穆朗玛峰……)因为它也有见过这样的数据,在和人类需求做对齐(alignment)之前,它不能理解你要它干什么,只是一味模仿。
监督微调阶段:也就是使用一些高质量的人类标记数据,让模型的输出方式更符合我们的使用习惯,在ChatGPT里,就是使用GPT 3在一些问答数据上微调。例如给他”[用户]:“世界上最高的山峰是什么?[模型]:珠穆朗玛峰。“这些数据以后,它可能就可以理解自己需要给用户答案。
强化学习阶段:经过SFT以后模型已经可以有一个能回答人类问题的语言模型了,此时可以让人类对模型的答案进行打分,让模型学习生成更能让人类满意的答案,这就是大名鼎鼎的RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)。
在Emu3也有类似的几个阶段:
预训练阶段:准备大量的文本、图片、视频资料进行训练,其中先使用文本和图片训练,再加入视频数据。
质量微调阶段:使用高质量数据进行微调,如更高筛选标准和更高分辨率的优质图片。
DPO强化学习阶段:使用SFT模型生成多个结果,通过人类打分作为反馈进行强化训练,打分的重点在于生成质量和文本对齐程度。
这是Emu3的生图效果:

从这个论文的效果来看,自回归生成图片的结果也是潜力很大的,不过这篇论文没有在图像编辑、风格转换等图像领域常见的任务上做训练和评测,猜想GPT-4o应该增加了不少这类任务的SFT数据去做对齐。这类训练数据可以通过从一些专家模型中蒸馏、人工PS等方式制造,再使用多模态视觉理解模型(相比生图模型较为成熟的一项技术)去打分筛选数据。大致流程可以参考这篇OmniEdit(https://arxiv.org/pdf/2411.07199):
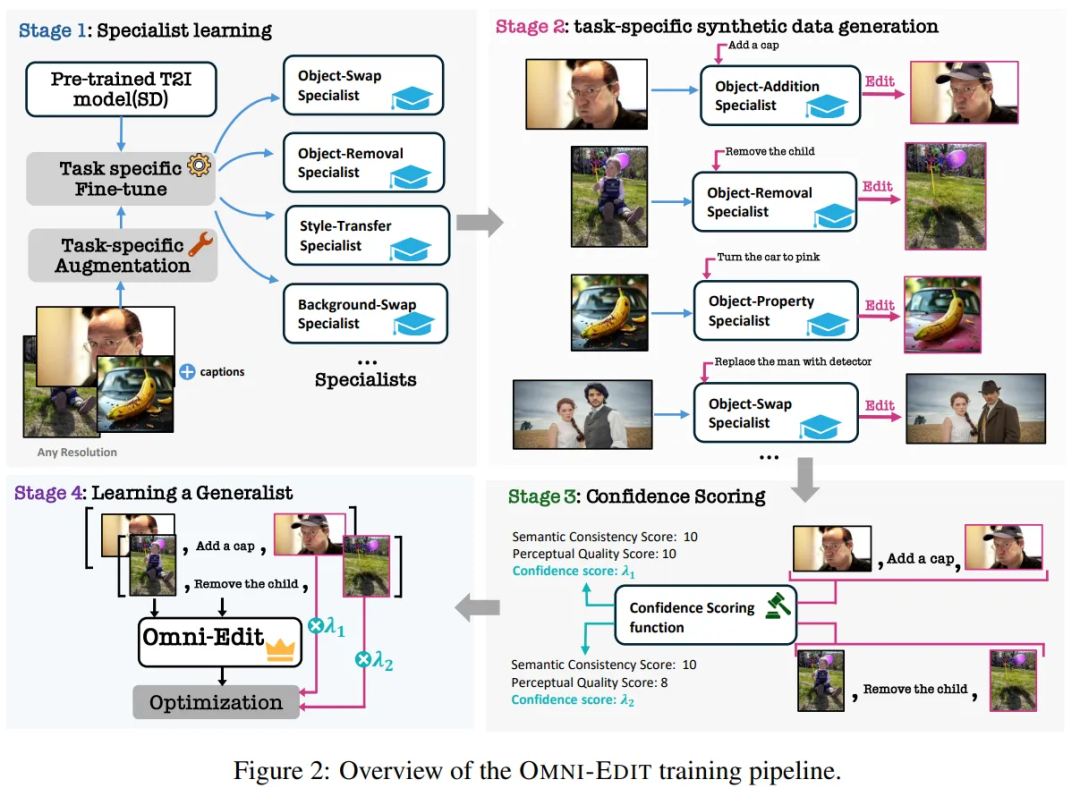
03
结语
自回归做图像生成并不是一个很新鲜的事情,但由于训练困难、生成较慢被扩散模型取代。但是扩散模型很难像自回归模型这样做一个很完整的通用模型,每个任务都有专门的方法去进行适配,并且图文之间的信息交互也会有损失。GPT 3.5(第一代ChatGPT)相比于GPT 3在模型架构上并没有非常明显的改进,但是通过极大扩充训练集、参数量,增加大量的人类标注做SFT和强化学习,在性能上就立刻把模型提升到非常可用的高度。我想GPT-4o应该也是类似的技术路线,相比简单易懂的原理,效果的提升更重要的还是依赖背后的工程和训练方法。
-End-
原创作者|周艺超
感谢你读到这里,不如关注一下?👇

📢📢DeepSeek怎么文生图?点击下方立刻探索👇


你觉得GPT-4o还能作用在什么方面?欢迎评论留言补充。我们将选取1则优质的评论,送出腾讯云定制文件袋套装1个(见下图)。4月17日中午12点开奖。






相关文章:
“破解”GPT-4o生图技术:万物皆可吉卜力的技术路线推测
👉目录 1 GPT-4o 的神奇魔法 2 GPT-4o 可能的技术路线推测 3 结语 最近 GPT-4o 生图模型横空出世,效果和玩法上都有突破性的进展,笔者整理了一下目前相关的技术,抛砖引玉一下,希望有更多大神分享讨论。 图源小红书恶魔…...
基于SpringBoot的电影订票系统(源码+数据库+万字文档+ppt)
504基于SpringBoot的电影订票系统,系统包含两种角色:管理员、用户主要功能如下。 【用户功能】 首页:浏览系统电影动态。 资讯信息:获取有关电影行业的新闻和资讯。 电影信息:查看电影的详细信息和排片情况。 公告信…...
07-算法打卡-链表-移除链表-leetcode(203)-第七天
1 题目地址 203. 移除链表元素 - 力扣(LeetCode)203. 移除链表元素 - 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 示例 1:[https://assets.leetc…...

[C++面试] 初始化相关面试点深究
一、入门 1、C中基础类型的初始化方式有哪些?请举例说明 默认初始化 对于全局变量和静态变量,基础类型(如int、float、double等)会被初始化为 0;而对于局部变量,其值是未定义的,包含随机…...

在线地图支持天地图和腾讯地图,仪表板和数据大屏支持发布功能,DataEase开源BI工具v2.10.7 LTS版本发布
2025年4月11日,人人可用的开源BI工具DataEase正式发布v2.10.7 LTS版本。 这一版本的功能变动包括:数据源方面,Oracle数据源支持获取和查询物化视图;图表方面,在线地图支持天地图、腾讯地图;新增子弹图&…...

粉末冶金齿轮学习笔记分享
有一段小段时间没有更新了,不知道小伙们有没有忘记我。最近总听到粉末冶金齿轮这个概念,花点时间来学习一下,总结一篇笔记分享给大家。废话不多说,直接开始: “粉末冶金”是一种制造工艺,包括在高压下压实…...
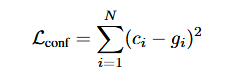
Retina:部署在神经硬件的SNN眼动追踪算法
论文链接:Retina : Low-Power Eye Tracking with Event Camera and Spiking Hardware 这是一篇发表在2024CVPRW上的文章,做了三个contribution: 将SNN放在Eye Tracking任务上。提出了Ini-30数据集部署到了Spike硬件上 还是挺有趣的。但是由于…...
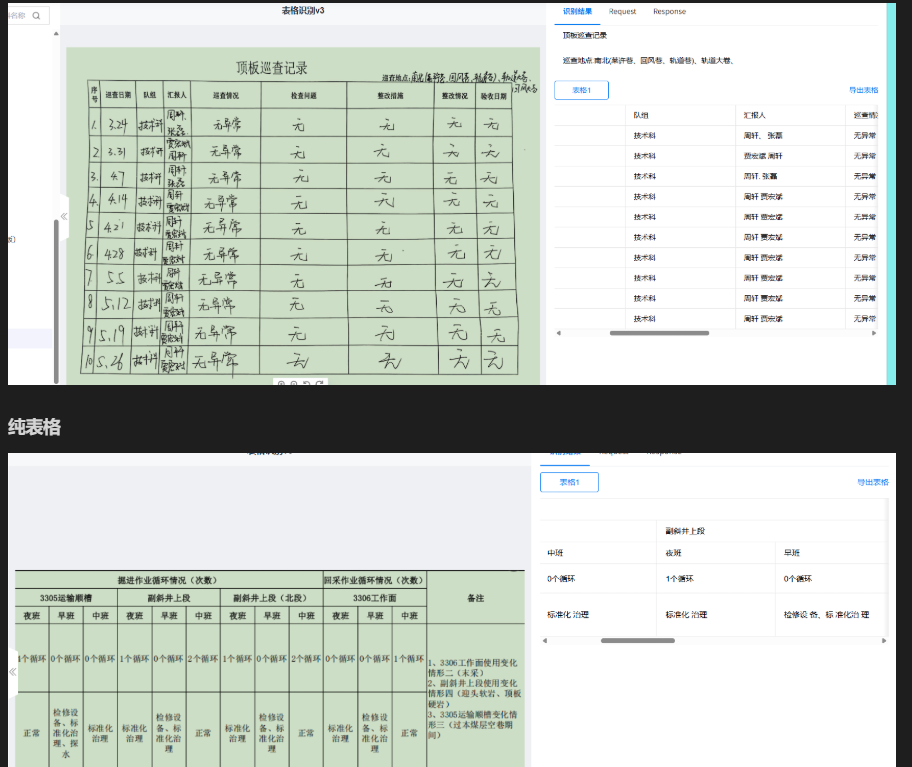
OCR API识别对比
OCR 识别DEMO OCR识别 demo 文档由来 最开始想使用百度开源的 paddlepaddle大模型 研究了几天,发现表格识别会跨行,手写识别的也不很准确。最终还是得使用现成提供的api。。 文档说明 三个体验下来 腾讯的识别度比较高,不论是手写还是识别表…...

nodejs构建项目
从零到一搭建 Node.js 框架 搭建一个 Node.js 框架是理解 Web 应用架构的绝佳方式。本指南将带您完成创建一个轻量级但功能完善的 Node.js 框架的全过程,类似于 Express 或 Koa,但规模更小,便于理解。 目录 项目初始化创建核心应用类路由系…...
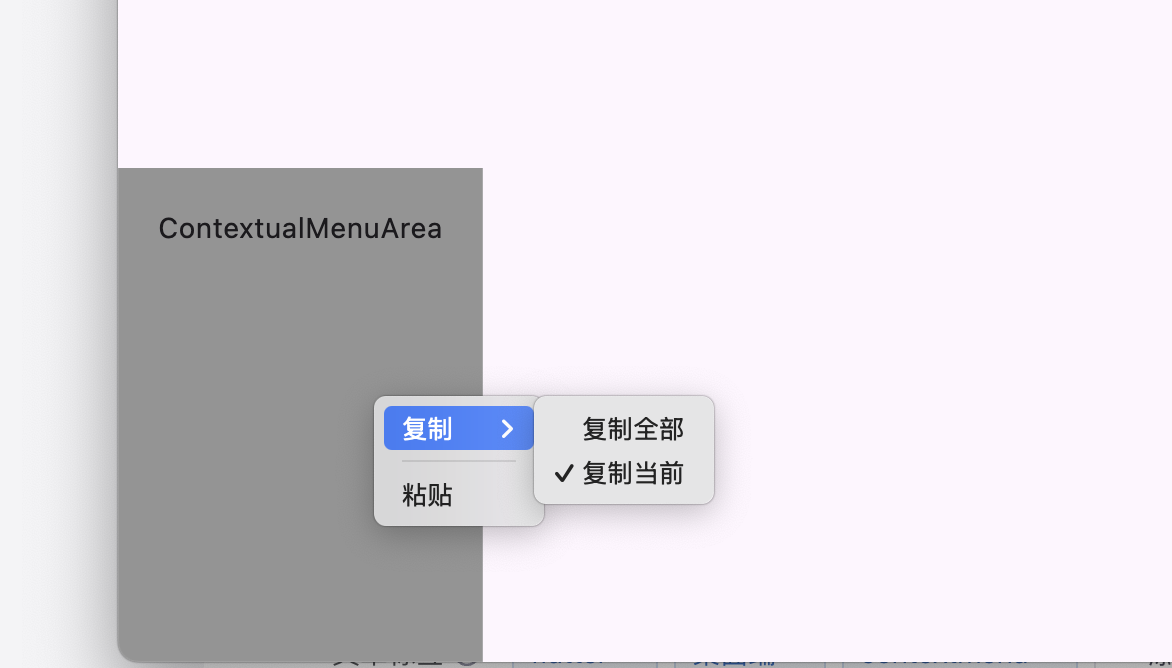
flutter 桌面应用之右键菜单
在 Flutter 桌面应用开发中,context_menu 和 contextual_menu 是两款常用的右键菜单插件,各有特色。以下是对它们的对比分析: context_menu 集成方式:通过 ContextMenuArea 组件包裹目标组件,定义菜单项。掘金…...
Cygwin编译安装Acise
本文记录Windows下使用Cygwin编译安装Acise的流程。 零、环境 操作系统Windows11Visual Studio CodeVisual Studio Code 1.92.0Cygwin 一、工具及依赖 1.1 Visual Studio Code 下载并安装Visual Studio Code, 同时安装以下插件, Task Explorer Output Colorizer …...

基于STM32、HAL库的IP6525S快充协议芯片简介及驱动程序设计
一、简介: IP6525S是一款高性能的同步降压DC-DC转换器芯片,具有以下特点: 输入电压范围:4.5V至32V 输出电压范围:0.8V至30V 最大输出电流:5A 效率高达95% 可编程开关频率(100kHz-1MHz) 支持PWM和PFM模式 内置过流保护、过温保护等功能 该芯片常用于工业控制、通信设备…...

RabbitMQ惰性队列的工作原理、消息持久化机制、同步刷盘的概念、延迟插件的使用方法
惰性队列工作原理 惰性队列通过尽可能多地将消息存储到磁盘上来减少内存的使用。与传统队列相比,惰性队列不会主动将消息加载到内存中,而是尽量让消息停留在磁盘上,从而降低内存占用。尽管如此,它并不保证所有操作都是同步写入磁…...

MySQL与Oracle深度对比
MySQL与Oracle深度对比:数据类型与SQL差异 一、数据类型差异 1. 数值类型对比 数据类型MySQLOracle整数TINYINT, SMALLINT, MEDIUMINT, INT, BIGINTNUMBER(精度) 或直接INT(内部仍为NUMBER)小数DECIMAL(p,s), FLOAT, DOUBLENUMBER(p,s), FLOAT, BINARY_FLOAT, BI…...

【Leetcode 每日一题】1922. 统计好数字的数目
问题背景 我们称一个数字字符串是 好数字 当它满足(下标从 0 0 0 开始)偶数 下标处的数字为 偶数 且 奇数 下标处的数字为 质数 ( 2 , 3 , 5 (2, \ 3, \ 5 (2, 3, 5 或 7 ) 7) 7)。 比方说,“2582” 是好数字,因为偶数下标处…...

pyqtgraph.opengl.items.GLSurfacePlotItem.GLSurfacePlotItem 报了一个错
1. 需求是这个样子的 有一个 pyqtgraph.opengl.GLViewWidget ,在应用启动时存在QMainWindow中,即父对象是QMainWindow,当业务需要时,修改它的父对象变为一个QDialog,可以让它从QMainWindow中弹出显示在QDialog里&#…...
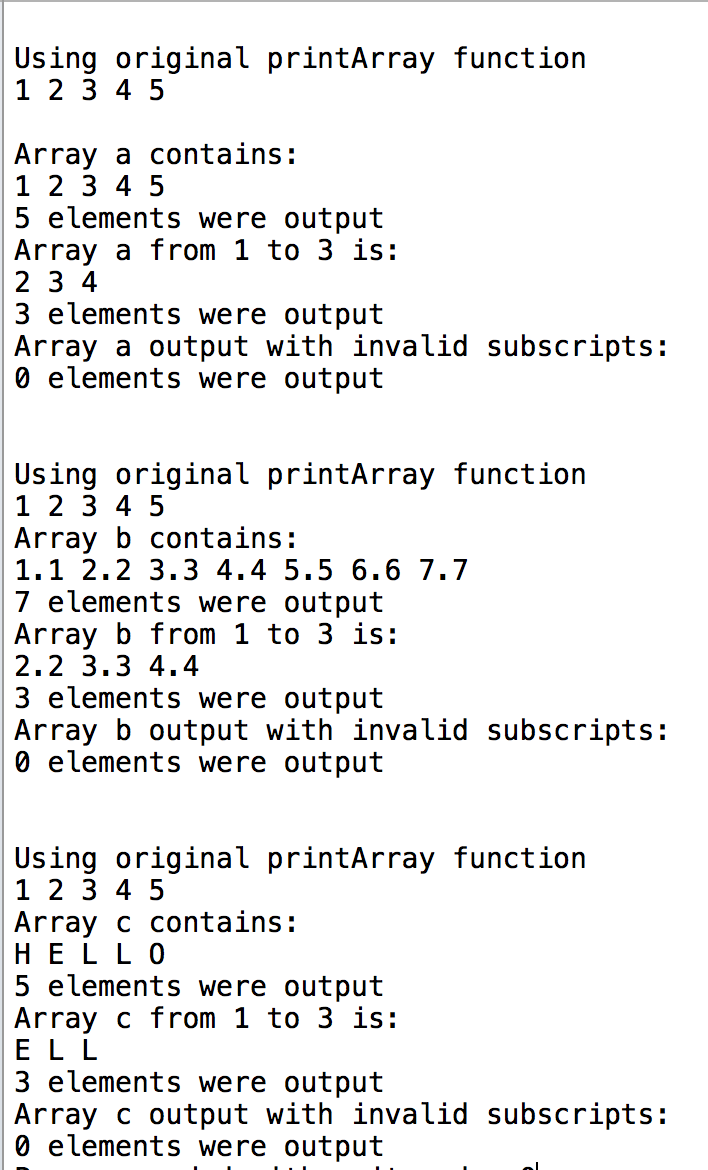
【C++初学】课后作业汇总复习(六) 函数模板
1、函数模板 思考:如果重载的函数,其解决问题的逻辑是一致的、函数体语句相同,只是处理的数据类型不同,那么写多个相同的函数体,是重复劳动,而且还可能因为代码的冗余造成不一致性。 解决:使用…...
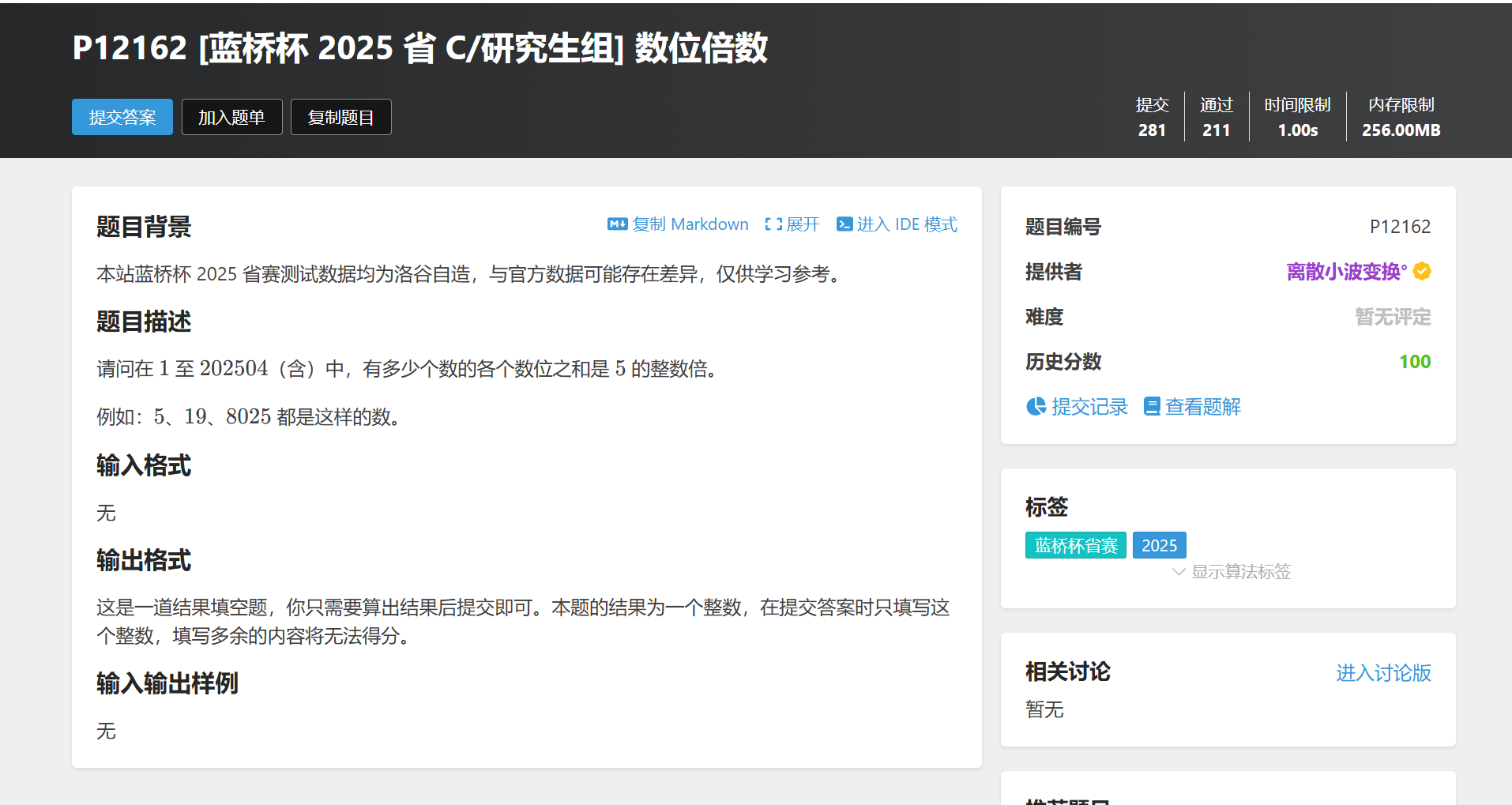
【第16届蓝桥杯C++C组】--- 数位倍数
Hello呀,小伙伴们,第16届蓝桥杯也完美结束了,无论大家考的如何,都要放平心态,今年我刚上大一,也第一次参加蓝桥杯,刷的算法题也只有200来道,但是还是考的不咋滴,但是拿不…...

ASP.NET Core 性能优化:客户端响应缓存
文章目录 前言一、什么是缓存二、客户端缓存核心机制:HTTP缓存头1)使用[ResponseCache]属性(推荐)2)预定义缓存配置(CacheProfile)3)手动设置HTTP头4)缓存验证机制&#…...
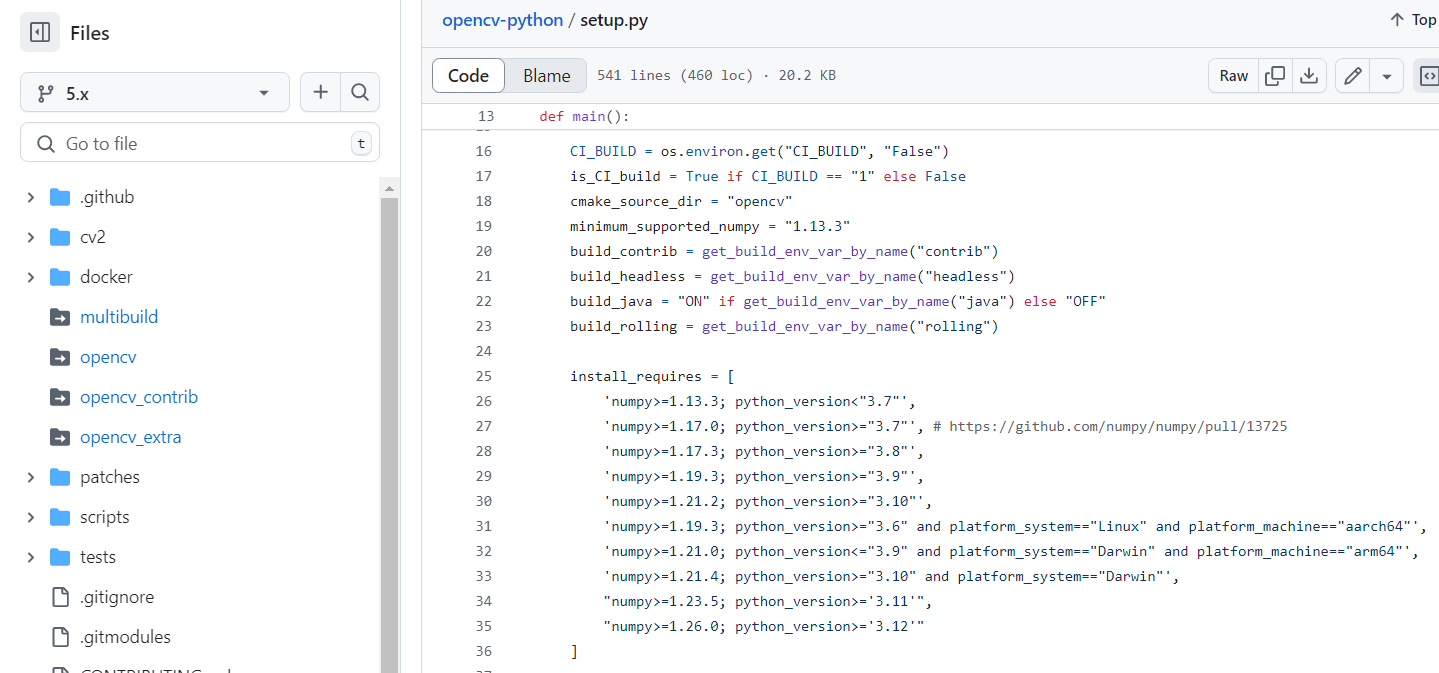
Numpy和OpenCV库匹配查询,安装OpenCV ABI错误
文章目录 地址opencv-python:4.x版本的对应numpyopencv-python:5.x版本的对应numpy方法2 ps:装个opencv遇到ABI错误无语了,翻了官网,github文档啥都没,记录下 地址 opencv-python:4.x版本的对应…...
)
全球变暖(蓝桥杯 2018 年第九届省赛)
题目描述 你有一张某海域 NN 像素的照片,. 表示海洋、 # 表示陆地,如下所示: ....... .##.... .##.... ....##. ..####. ...###. .......其中 "上下左右" 四个方向上连在一起的一片陆地组成一座岛屿。例如上图就有 2 座岛屿。 由…...
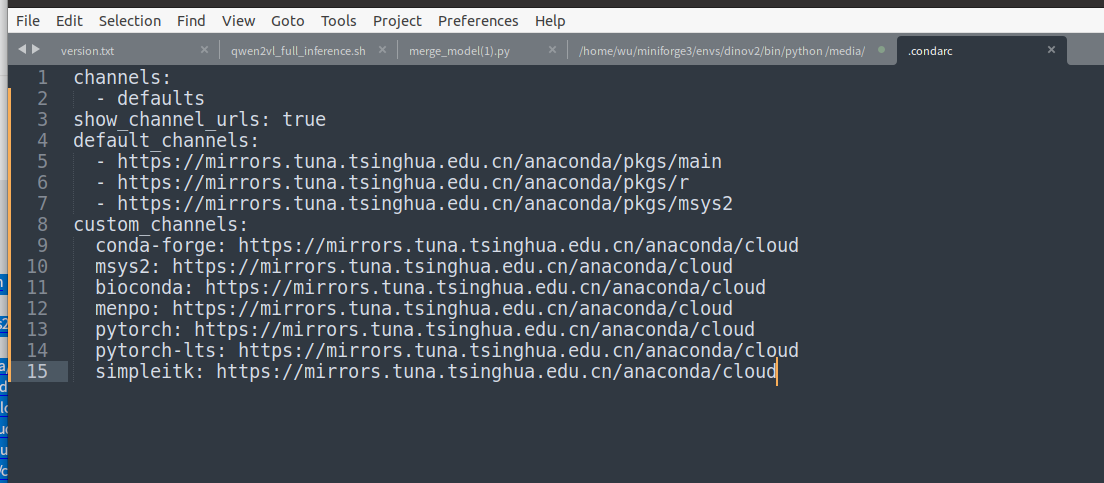
ubuntu18.04安装miniforge3
1.下载安装文件 略(注:从同事哪里拖来的安装包) 2.修改安装文件权限 chmod x Miniforge3-Linux-x86_64.sh 3.将它安装到指定位置 micromamba activate /home/xxx/fxp/fromDukto/miniforge3 4.激活 /home/xxx/fxp/fromDukto/miniforge3…...

高并发短信系统设计:基于SharingJDBC的分库分表、大数据同步与实时计算方案
高并发短信系统设计:基于SharingJDBC的分库分表、大数据同步与实时计算方案 一、概述 在当今互联网应用中,短信服务是极为重要的一环。面对每天发送2000万条短信的需求,我们需要一个能够处理海量数据(一年下来达到数千万亿级别&…...

OceanBase企业版集群部署:oatcli命令行方式
OceanBase企业版集群部署:oatcli命令行方式 安装包准备服务器准备最低资源配置是否部署ODP组件?仲裁服务器 服务器配置操作系统内核参数BIOS设置磁盘挂载网卡设置 安装OAT部署工具初始化OBServer服务器使用oatcli部署三副本集群安装OceanBase软件初始化O…...

SQL 查询中涉及的表及其作用说明
SQL 查询中涉及的表及其作用说明: 涉及的数据库表 表名别名/用途关联关系dbo.s_orderSO(主表)存储订单主信息(订单号、日期、客户等)dbo.s_orderdetailSoD(订单明细)通过 billid SO.billid 关…...

智能手机功耗测试
随着智能手机发展,用户体验对手机的续航功耗要求越来越高。需要对手机进行功耗测试及分解优化,将手机的性能与功耗平衡。低功耗技术推动了手机的用户体验。手机功耗测试可以采用powermonitor或者NI仪表在功耗版上进行测试与优化。作为一个多功能的智能终端,手机的功耗组成极…...
 的两种接口)
UNIX域套接字(Unix Domain Sockets, UDS) 的两种接口
目录 1. 流式套接字(SOCK_STREAM)特点类比典型使用场景代码示例(伪代码) 2. 数据报套接字(SOCK_DGRAM)特点类比典型使用场景代码示例(伪代码) 3. 两者的核心区别对比4. 为什么 UNIX …...
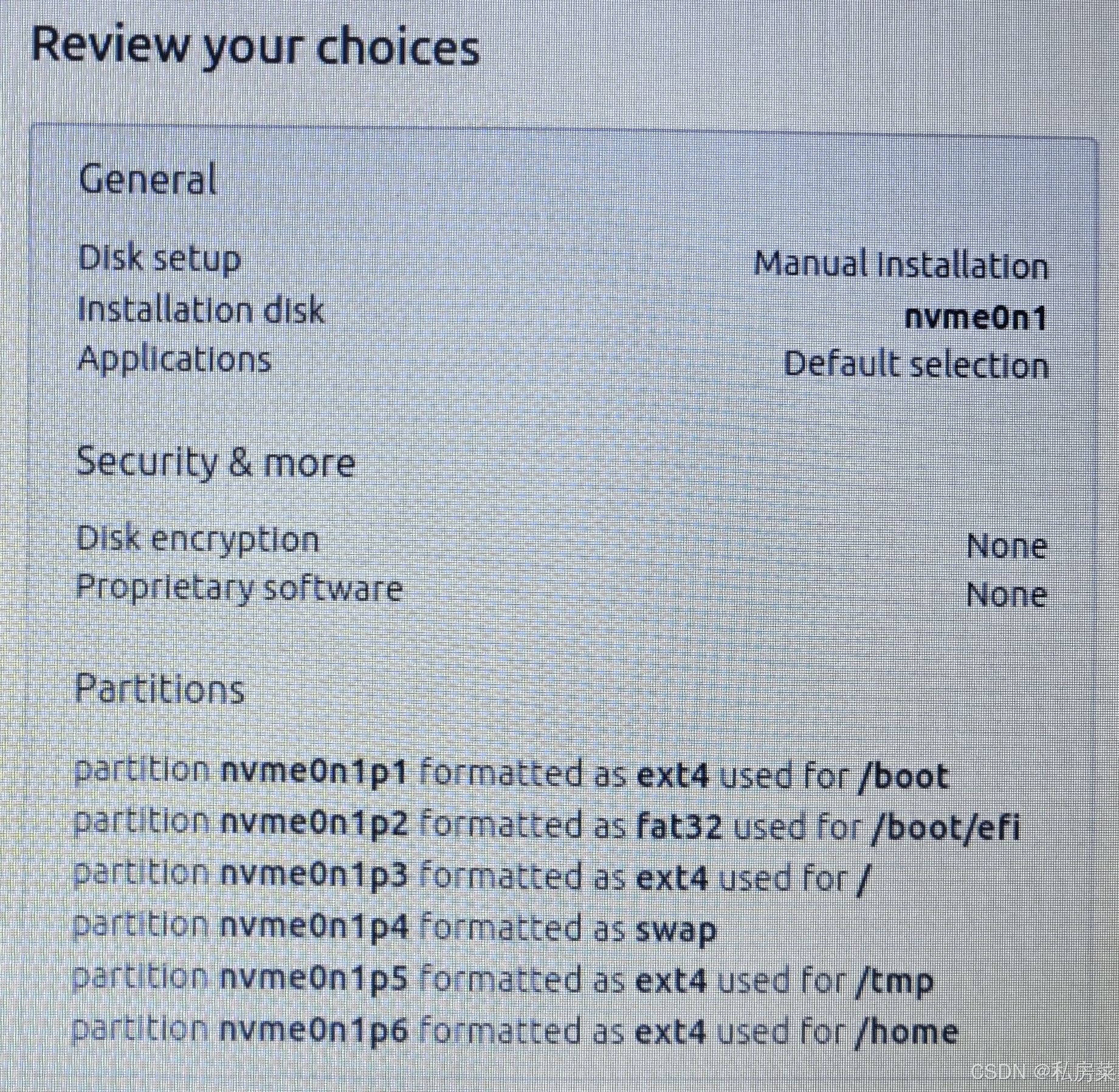
使用U盘安装 ubuntu 系统
1. 准备U 盘制作镜像 1.1 下载 ubuntu iso https://ubuntu.com/download/ 这里有多个版本以供下载,本文选择桌面版。 1.2 下载rufus https://rufus.ie/downloads/ 1.3 以管理员身份运行 rufus 设备选择你用来制作启动项的U盘,不能选错了;点…...

安全厂商安全理念分析
奇安信(toB企业安全) 安全理念:率先提出 “内生安全” 理念。即把安全能力内置到信息化环境中,通过信息化系统和安全系统的聚合、业务数据和安全数据的聚合、IT 人才和安全人才的聚合,让安全系统像人的免疫系统一样&a…...

Redis如何判断哨兵模式下节点之间数据是否一致
在哨兵模式下判断两个Redis节点的数据一致性,可以通过以下几种方法实现: 一、检查主从复制偏移量 使用INFO replication命令 分别在主节点和从节点执行该命令,比较两者的master_repl_offset(主节点)和slave_repl_offs…...