基于【Lang Chain】构建智能问答系统的实战指南

🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是Lang Chain
2、LangChain在问答系统中的核心优势
二、环境搭建与基础准备
1、开发环境配置(Python、LangChain、LLM模型选择)
2、安装FAISS数据库
3、FAISS数据库介绍
三、代码部分
1、向量化文档
2、创建问答
3、完整代码
4、运行
一、引言
1、什么是Lang Chain
什么是 LangChain?🤖📚
LangChain 是一个帮助开发者轻松构建与 语言模型(如 GPT-3 或 GPT-4)互动的工具包。它为开发者提供了一整套现成的模块和功能,使得开发者能够快速创建强大的语言模型应用,无需从零开始。
🌟 通俗比喻:
想象你有一个超级聪明的助手(就是语言模型),它能够帮助你理解和生成各种文字内容📝。但是,如果你要让这个助手处理大量的信息,比如从多个文档中提取知识、或者在海量数据中找到特定的答案,事情就变得有点复杂了。
这时,LangChain 就像是一个智能助手管理系统,它将处理这些复杂任务的各种功能模块(如文本处理、数据检索、模型生成等)都打包在一起,简化了操作,让你更轻松地与这些强大的语言模型互动。

🔧 LangChain 做了什么?
文本处理 📄
-
有大量的文本数据(例如文章、书籍、报告等),LangChain 可以帮助你将它们切割成更小、更易于处理的块。这样,语言模型就能更好地理解和分析这些文本。
信息检索 🔍
-
LangChain 能够将文本数据转化为“向量”形式,方便后续的查询和比较。就像你用 Google 搜索 查找信息一样,LangChain 会帮你找到最相关的内容。
问答系统 ❓
-
想构建一个智能问答系统吗?LangChain 可以根据你的文档和数据库内容,自动从中提取出答案。你只需提出问题,系统会帮你查找最相关的答案。
多轮对话 💬
-
如果你想要创建一个能够与人进行多轮对话的聊天机器人,LangChain 也能帮你管理对话的上下文。这样,机器人不仅能记住之前的对话,还能根据对话内容作出更智能的回答。

2、LangChain在问答系统中的核心优势
1. 强大的信息检索功能 🔍
LangChain 能够轻松整合 信息检索(IR)系统,让问答系统不仅依赖于语言模型的生成能力,还能从大量数据中检索出最相关的信息。
-
向量数据库支持:LangChain 支持集成 FAISS 等高效向量数据库,能够将文本数据转化为向量,提升查询效率。
-
精确匹配:可以根据用户的查询,快速查找到相关文档或数据,并为语言模型提供更精确的上下文。
2. 自动化文档处理和文本切割 📝✂️
在问答系统中,我们往往需要处理大量的文档和文本数据。LangChain 提供了强大的文本切割和预处理功能:
-
自动分割长文档:LangChain 提供文本切割工具(如
RecursiveCharacterTextSplitter),将长文本分割成较小的片段,便于更高效地进行处理和查询。 -
文本清洗和格式化:它帮助开发者自动处理文本数据,去除无关信息,确保模型输入的文本是干净且易于理解的。
二、环境搭建与基础准备
1、开发环境配置(Python、LangChain、LLM模型选择)
Python版本:3.12.7
安装 LangChain 工具包
pip install langchain_community langchain_openai langchain langchain_openaiLLM,这里的大模型我们使用 OpenAI 的大模型,如果还没有申请OpenAI 的KEY,可以参考:
《LangChain 安装与环境搭建,并调用OpenAI与Ollama本地大模型》这篇文章
2、安装FAISS数据库
执行以下命令:
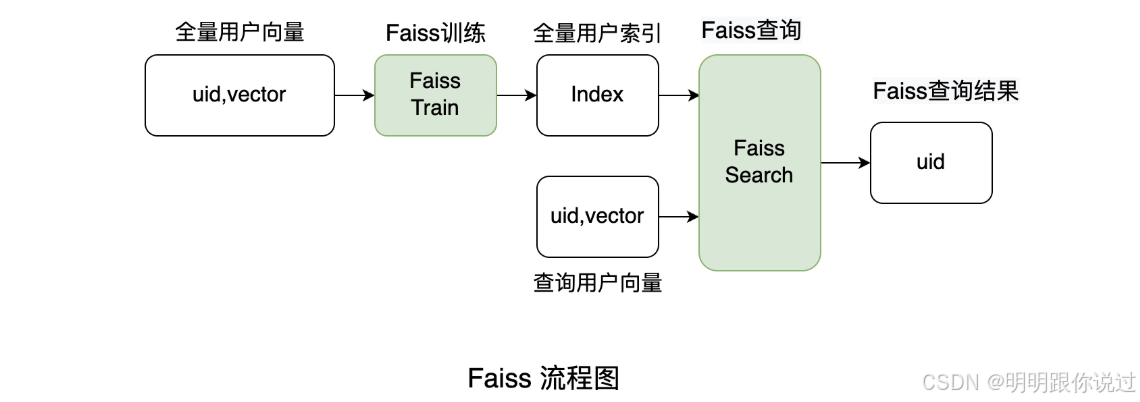
pip install faiss-cpu3、FAISS数据库介绍
📊🔍FAISS(Facebook AI Similarity Search)是一个由 Facebook AI Research 开发的高效向量检索库,专为处理大规模高维数据集中的 相似性搜索 设计。FAISS 是一个 开源 项目,旨在提供 快速的近似最近邻(ANN) 搜索功能,广泛应用于机器学习、自然语言处理、推荐系统等领域。
FAISS 的核心优势在于它能在处理海量数据时提供 高效的检索,尤其是在计算 向量相似性 时,性能远超传统的数据库系统。
FAISS 的核心特点 🌟
高效的向量相似性搜索 🔍
-
FAISS 可以在大规模数据集中进行 高效的向量相似性搜索,帮助用户从海量数据中找到最相似的项。
-
它支持 内存中索引(例如,使用 CPU 或 GPU)以及 磁盘存储索引,即使在数据集非常庞大的情况下也能提供快速的检索。
支持多种距离度量 📏
-
FAISS 支持 欧氏距离(L2)、内积等常见的距离度量方法,能够根据不同应用场景灵活选择合适的度量方式。
-
这些距离度量对于处理 文本、图像、音频 等多模态数据非常有用。
支持高维数据 🔢
-
FAISS 能处理 高维(几百维、几千维甚至更多)的数据,尤其适用于机器学习中通过 嵌入(embedding)生成的高维向量。
-
例如,处理文本时,FAISS 能够高效地检索基于语言模型生成的 词向量 或 句向量。
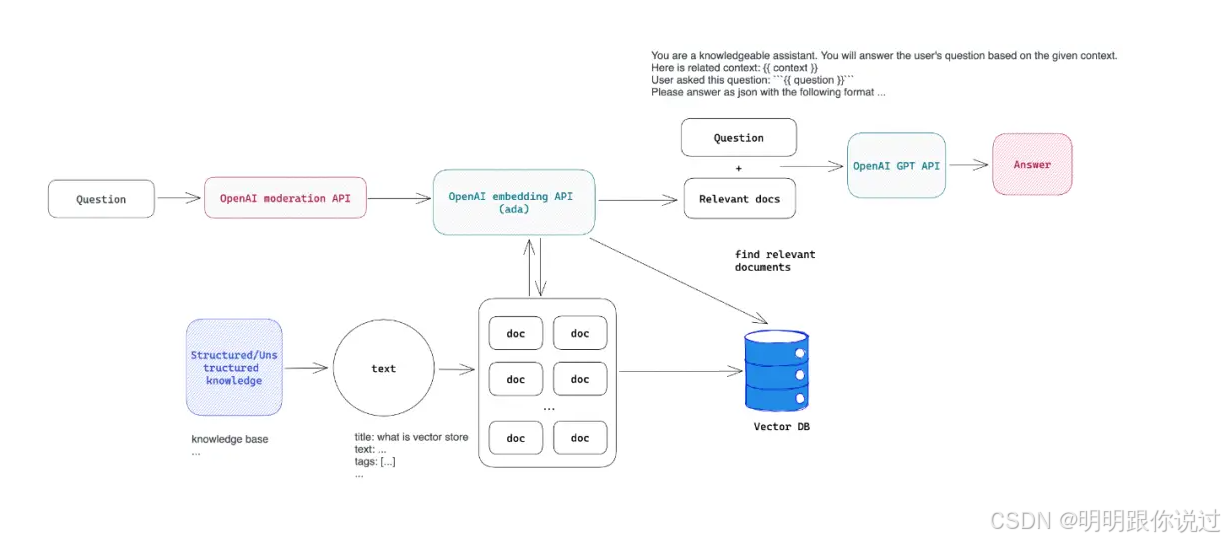
FAISS 如何工作? 🛠️
FAISS 的工作原理可以分为以下几个步骤:
数据向量化 📈
-
首先,数据(如文本、图像、音频)需要被转化为 向量,这通常通过 深度学习模型(例如,BERT、ResNet、VGG)生成。
-
这些向量是高维的,表示数据中的某些特征。
构建索引 🗄️
-
使用 FAISS 的不同索引结构(如 Flat、IVF、HNSW 等)将向量数据进行 索引。这一步骤的目的是加速查询过程。
查询和相似性搜索 🔍
-
用户提出查询,FAISS 会通过 计算查询向量与数据集中向量的相似度(如计算内积或欧氏距离)来找出最相似的项。
-
FAISS 提供近似最近邻搜索,通常在 大规模数据集 中可以显著提高检索速度。
FAISS 应用场景 🚀
FAISS 广泛应用于 自然语言处理、计算机视觉 和 推荐系统 等领域,以下是一些典型的应用:
推荐系统 🎯
-
FAISS 可以帮助根据用户历史行为或偏好从庞大的商品或内容库中找到相似的商品或内容,提供个性化推荐。
文本相似性检索 📝
-
在处理大量文本数据时(如文档、文章、问题解答等),FAISS 可以高效地查询最相关的文本,支持 问答系统、信息检索系统等应用。
图像检索 🖼️
-
在计算机视觉领域,FAISS 能够从 图像特征向量 中找到相似图像,广泛应用于 图像检索、图像分类 和 面部识别 等任务。
三、代码部分
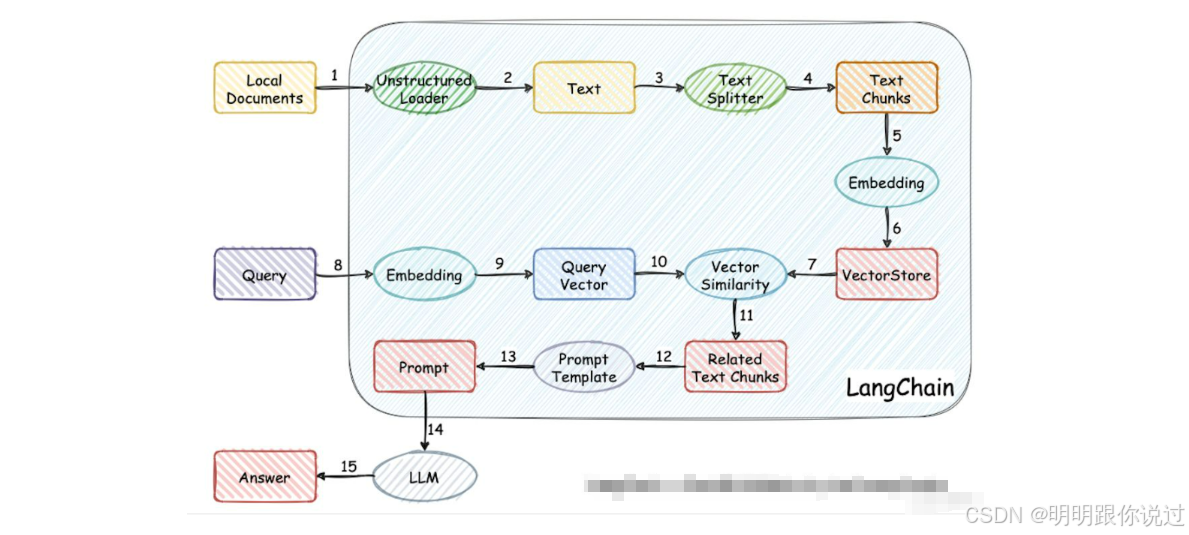
1、向量化文档
代码如下:
# 加载文档
docs = ["三星 W25 手机512G价格为¥15999", "三星 W25 手机1T价格为¥17999",]# 将字符串转换为 Document 对象
documents = [Document(page_content=doc) for doc in docs]# 文本切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = text_splitter.split_documents(documents)# 创建Embedding
embeddings = OpenAIEmbeddings()# 使用FAISS创建向量数据库
db = FAISS.from_documents(split_docs, embeddings)# 保存数据库
db.save_local("faiss_index")1. 加载文档 📄
- 这里创建了一个简单的 文档列表(
docs),其中包含两条字符串,每条字符串描述了一个三星手机的不同存储版本和价格。
2. 将字符串转换为 Document 对象 📝
- 将每个字符串(文档内容)转换为
Document对象。Document是 LangChain 中的一个类,用于封装文本数据及其相关元数据。这里的page_content=doc将字符串作为文档的内容。
3. 文本切割(分割长文本) ✂️
- 使用
RecursiveCharacterTextSplitter来切割文档。这个工具将文档按照一定的字符数量(这里是 1000 字符)进行切割,同时允许文档切割片段之间有 200 字符的重叠。这样做的目的是确保文档在切割后,仍然能够保持上下文的连贯性。
4. 创建文档的嵌入(Embedding) 🧠
OpenAIEmbeddings是 LangChain 提供的一个工具,用于将文本转换为 向量嵌入(embedding)。嵌入是将文本表示为数字向量,这些向量能够捕捉到文本的语义信息。在此例中,使用的是 OpenAI 的嵌入模型。
5. 使用 FAISS 创建向量数据库 🔣
- 使用 FAISS 向量数据库来存储文本的嵌入。FAISS 是一个高效的相似性搜索库,可以对文本进行向量化处理后快速查询相似的内容。
split_docs是切割后的文档,embeddings是生成这些文档的嵌入的工具。from_documents方法会将文档转换为向量,并将它们存储在 FAISS 向量数据库中。这个数据库支持高效的相似性查询。
6. 保存向量数据库 💾
- 最后,将构建好的 FAISS 向量数据库保存到本地文件系统。数据库会保存在名为
faiss_index的文件夹中。我们可以将其用于后续的查询和检索操作。
2、创建问答
代码如下:
# 加载FAISS数据库
db = FAISS.load_local("C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index", embeddings, allow_dangerous_deserialization=True)# 初始化语言模型(这里用的是OpenAI)
llm = ChatOpenAI(model="gpt-4o")
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="map_reduce", retriever=db.as_retriever())# 查询
query = "三星 W25 手机512G价格是多少"
response = qa_chain.invoke(query)print(response)1. 加载 FAISS 数据库 📂
-
这行代码从本地路径加载已保存的 FAISS 向量数据库。路径
"C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index"指向之前存储的 FAISS 索引文件。 -
embeddings:使用的嵌入工具,用于将文本转换为向量的工具。 -
allow_dangerous_deserialization=True:这是一个安全选项,表示允许加载通过 pickle 存储的 FAISS 数据库文件。这个选项的作用是为了防止可能来自不受信任源的恶意代码执行。
2. 初始化语言模型(OpenAI GPT) 🤖
- 这里使用的是 OpenAI GPT-4 模型(
gpt-4o),作为问答系统的核心语言模型。
3. 创建问答链(QA Chain) 🔗
-
这里创建了一个 问答链(QA Chain),该链将使用 FAISS 向量数据库来检索与查询最相关的文档,并利用 GPT-4 生成回答。
-
from_chain_type:这个方法用于从指定的链类型创建问答链。-
llm=llm:将先前初始化的 GPT-4 模型作为问答链的语言模型。 -
chain_type="map_reduce":指定链的类型为 map_reduce,这意味着系统会先检索相关文档,然后将它们的内容传递给语言模型,模型再进行处理和整合最终的答案。 -
retriever=db.as_retriever():将 FAISS 向量数据库转换为检索器(retriever)。检索器负责从 FAISS 数据库中检索与查询最相似的文档。
-
4. 执行查询并获取回答 🧐💬
-
query = "三星 W25 手机512G价格是多少":这是用户输入的查询,目的是询问三星 W25 手机512G版本的价格。 -
qa_chain.invoke(query):通过问答链(QA Chain)执行查询。这个方法将根据用户的查询去 FAISS 数据库中查找相关文档,并将这些文档输入到 GPT-4 模型中,生成一个回答。
5. 打印答案 🖨️
- 最后,打印出从模型生成的回答,这个回答是针对用户查询的最佳匹配。
3、完整代码
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI# 加载文档
docs = ["三星 W25 手机512G价格为¥15999", "三星 W25 手机1T价格为¥17999",]# 将字符串转换为 Document 对象
documents = [Document(page_content=doc) for doc in docs]# 文本切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = text_splitter.split_documents(documents)# 创建Embedding
embeddings = OpenAIEmbeddings()# 使用FAISS创建向量数据库
db = FAISS.from_documents(split_docs, embeddings)# 保存数据库
db.save_local("faiss_index")# 加载FAISS数据库
db = FAISS.load_local("C:/Users/LMT/PycharmProjects/AI/LangChain/faiss_index", embeddings, allow_dangerous_deserialization=True)# 初始化语言模型(这里用的是OpenAI)
llm = ChatOpenAI(model="gpt-4o")
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="map_reduce", retriever=db.as_retriever())# 查询
query = "三星 W25 手机512G价格是多少"
response = qa_chain.invoke(query)print(response)这段代码的功能是构建一个基于 FAISS 向量数据库 和 OpenAI GPT-4 的问答系统。它将文档转化为向量,存储在 FAISS 数据库中,使用 GPT-4 来生成对用户查询的答案。问答系统的主要步骤是:
-
加载文档并切割成片段。
-
创建嵌入并存储到 FAISS 向量数据库中。
-
加载 FAISS 数据库并初始化 GPT-4 模型。
-
使用检索和生成模型回答用户的查询。
这个系统可以用于各种信息检索任务,比如产品信息查询、文档检索、FAQ 自动化等。
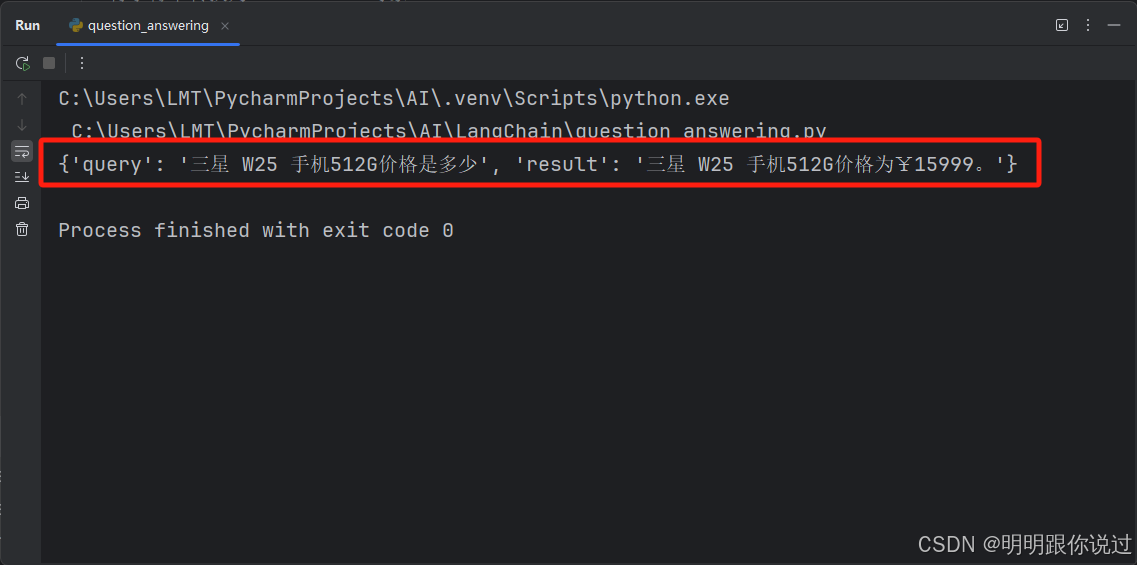
4、运行
代码执行后,结果如下:
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
相关文章:
基于【Lang Chain】构建智能问答系统的实战指南
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Lang Chain 2、LangChain在问答系统中的核心优…...

idea的快捷键使用以及相关设置
文章目录 快捷键常用设置 快捷键 快捷键作用ctrlshift/注释选中内容Ctrl /注释一行/** Enter文档注释ALT SHIFT ↑, ALT SHIFT ↓上下移动当前代码Ctrl ALT L格式化代码Ctrl X删除所在行并复制该行Ctrl D复制当前行数据到下一行main/psvm快速生成入口程序soutSystem.o…...
TestHubo安装及入门指南
TestHubo是一款开源免费的测试管理工具,提供一站式测试解决方案,涵盖功能测试、接口测试、性能测试以及 Web 和 App 测试等多个维度。TestHubo 整合了全面的测试能力,使团队可以在一个平台内完成所有测试需求。本文将介绍如何快速安装配置及入…...
react tailwindcss最简单的开始
参考教程: Install Tailwind CSS with Vite - TailwindCSS中文文档 | TailwindCSS中文网https://www.tailwindcss.cn/docs/guides/vite操作过程: Microsoft Windows [版本 10.0.26100.3476] (c) Microsoft Corporation。保留所有权利。D:\gitee\tailwi…...

openGauss新特性 | 自动参数化执行计划缓存
目录 自动化参数执行计划缓存简介 SQL参数化及约束条件 一般常量参数化示例 总结 自动化参数执行计划缓存简介 执行计划缓存用于减少执行计划的生成次数。openGauss数据库会缓存之前生成的执行计划,以便在下次执行该SQL时直接使用,可…...
3、组件:魔法傀儡的诞生——React 19 组件化开发全解析
一、开篇:魔法傀儡的觉醒 "每个React组件都像一具魔法傀儡,"邓布利多校长挥动魔杖,空中浮现出闪烁的代码字符,"它们能自主思考、协同工作,甚至能跨越时空(服务器与客户端)执行任…...

使用Python实现矢量路径的压缩、解压与可视化
引言 在图形设计和Web开发中,矢量路径数据的高效存储与传输至关重要。本文将通过一个Python示例,展示如何将复杂的矢量路径命令序列压缩为JSON格式,再将其解压还原,并通过matplotlib进行可视化。这一过程可应用于字体设计、矢量图…...
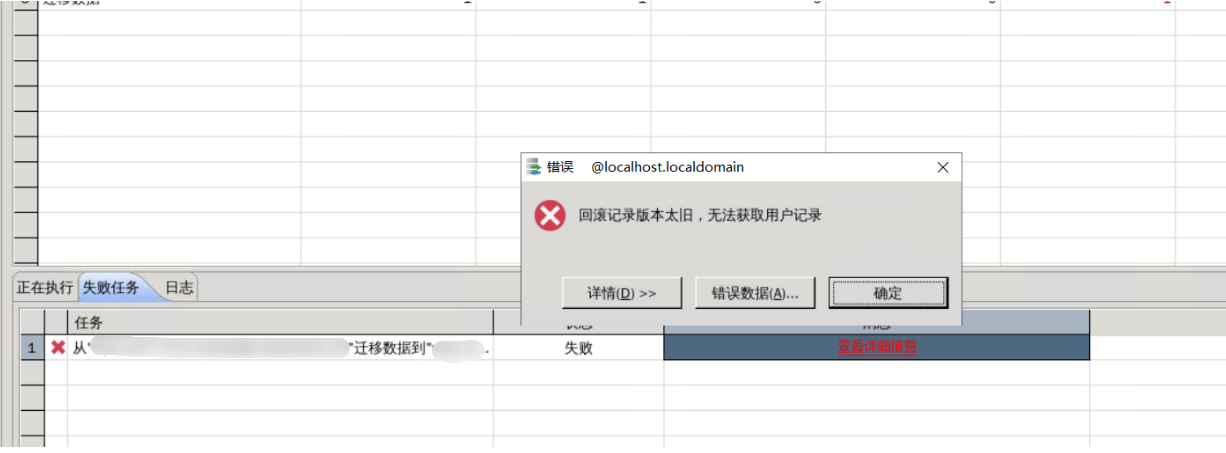
达梦数据库迁移问题总结
更多技术博客,请关注微信公众号:运维之美 问题一、DTS工具运行乱码 开启图形化 [rootlocalhost ~]# xhost #如果命令不存在执行sudo yum install xorg-x11-server-utils xhost: unable to open display "" [rootlocalhost ~]# su - dmd…...

OpenHarmony荷兰研习会回顾 | 仓颉语言赋能原生应用开发实践
近日,由全球顶级学术峰会EuroSys/ASPLOS和OpenHarmony社区在荷兰鹿特丹合办的操作系统深度研习会圆满收官,本次研习会以"架构探秘-开发实践-创新实验"三位一体的进阶模式,为全球开发者构建了沉浸式技术探索平台。其中,由…...

【远程工具】0 std::process::Command 介绍
std::process::Command 是 Rust 标准库中用于创建和配置子进程的主要类型。它允许你启动新的进程、设置其参数和环境变量、重定向输入/输出等。 基本用法 use std::process::Command;let output Command::new("echo").arg("Hello, world!").output().ex…...

【JAVA】JVM 堆内存“缓冲空间”的压缩机制及调整方法
1. 缓冲空间是否可压缩? 是的,JVM 会在满足条件时自动收缩堆内存,将未使用的缓冲空间释放回操作系统。但需满足以下条件: GC 触发堆收缩:某些垃圾回收器(如 G1、Serial、Parallel)在 Full GC …...

RV1126 人脸识别门禁系统解决方案
1. 方案简介 本方案为类人脸门禁机的产品级解决方案,已为用户构建一个带调度框架的UI应用工程;准备好我司的easyeai-api链接调用;准备好UI的开发环境。具备低模块耦合度的特点。其目的在于方便用户快速拓展自定义的业务功能模块,以及快速更换UI皮肤。 2. 快速上手 2.1 开…...
matlab内置的git软件版本管理功能
1、matlab多人协作开发比普通的嵌入式软件开发困难很多 用过matlab的人都知道,版本管理对于matlab来说真的很费劲,今天介绍的这个工具也不是说它就解决了这个痛点,只是让它变得简单一点。版本管理肯定是不可或缺的,干就完了 2、操作说明 如图所示,源代码管理,选项罗列的…...

【问题排查】SQLite安装失败
启动 Django 自带的开发服务器 python manage.py runserver出现如下报错: [rootiZ2zedudtf2cwzi9argky2Z myproject]# python manage.py runserver Watching for file changes with StatReloader Performing system checks...System check identified no issues (…...
详解:从零开始掌握(2))
Express中间件(Middleware)详解:从零开始掌握(2)
1. 请求耗时中间件的增强版 问题:原版只能记录到控制台,如何记录到文件? 改进点: 使用process.hrtime()是什么?获取更高精度的时间支持将日志写入文件记录更多信息(IP地址、状态码)工厂函数模式使中间件可配置 con…...

《前端面试题之 CSS篇(第一集)》
目录 1、CSS的盒模型2、CSS选择器及其优先级3、隐藏元素的方法有那些4、px、em、rem的区别及使用场景5、重排、重绘有什么区别6、水平垂直居中的实现7、CSS中可继承与不可继承属性有哪些8、Sass、Less 是什么?为什么要使用他们?9、CSS预处理器/后处理器是…...

MySQL部分总结
mysql学习笔记,如有不足还请指出,谢谢。 外连接,内连接,全连接 外连接:左外、右外 内连接:自己和自己连接 全连接:左外连接右外链接 mysql unique字段 unique可以在数据库层面避免插入相同…...

2025第十六届蓝桥杯PythonB组部分题解
一、攻击次数 题目描述 小蓝操控三个英雄攻击敌人,敌人初始血量2025: 第一个英雄每回合固定攻击5点第二个英雄奇数回合攻击15点,偶数回合攻击2点第三个英雄根据回合数除以3的余数攻击:余1攻2点,余2攻10点࿰…...

RocketMQ 中的 MessageStore 组件:消息存储的核心枢纽
引言 在现代分布式系统中,消息队列扮演着至关重要的角色,它能够实现系统间的异步通信、解耦服务以及削峰填谷等功能。RocketMQ 作为一款高性能、高可靠的分布式消息队列,在众多企业级应用中得到了广泛的应用。而在 RocketMQ 的架构体系里&am…...
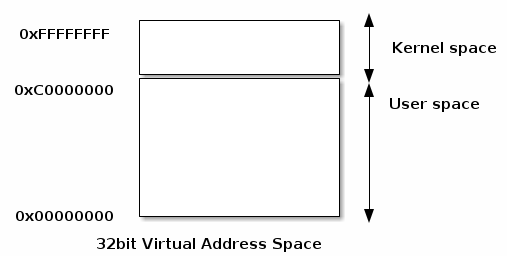
Linux Kernel 2
地址空间(Address Space) 一、物理地址空间(Physical Address Space) 物理地址空间 是指 RAM 和设备内存 在系统内存总线上所呈现的地址布局。 举例:在典型的 32 32 32 位 Intel 架构中, RAM(…...
AndroidTV D贝桌面-v3.2.5-[支持文件传输]
AndroidTV D贝桌面 链接:https://pan.xunlei.com/s/VONXSBtgn8S_BsZxzjH_mHlAA1?pwdzet2# AndroidTV D贝桌面-v3.2.5[支持文件传输] 第一次使用的话,壁纸默认去掉的,不需要按遥控器上键,自己更换壁纸即可...
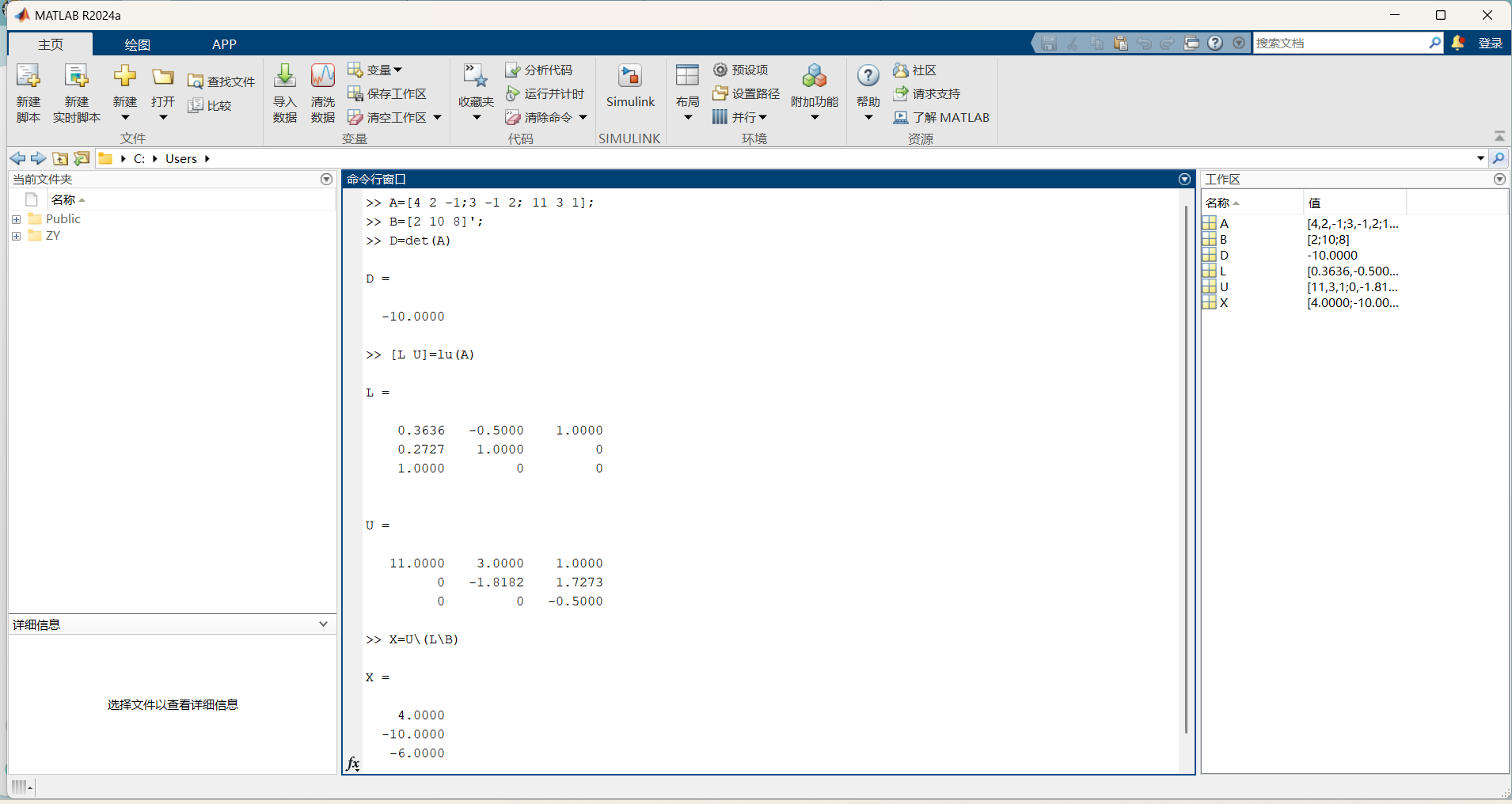
线性方程组的解法
文章目录 线性方程组的解法认识一些基本的矩阵函数MATLAB 实现机电工程学院教学函数构造1.高斯消元法2.列主元消去法3. L U LU LU分解法 线性方程组的解法 看到以下线性方程组的一般形式:设有以下的 n n n阶线性方程组: A x b \mathbf{Ax}\mathbf{b} A…...

轻量级锁是什么?轻在哪里?重量级锁是什么?重在哪里?
轻量级锁 vs 重量级锁:核心区别与设计哲学 在JVM的锁优化体系中,轻量级锁和重量级锁是两种不同竞争强度下的解决方案。它们的核心差异体现在 资源消耗、适用场景和实现机制 上。以下是详细对比: 一、轻量级锁(Thin Lockÿ…...
Python赋能量子计算:算法创新与应用拓展
量子计算与Python结合的算法开发与应用研究 摘要 量子计算作为计算机科学的前沿技术,凭借其独特的计算能力在解决复杂问题方面展现出巨大潜力。Python作为一种高效、灵活的编程语言,为量子计算算法的开发提供了强大的支持。本文从研究学者的视角,系统探讨了量子计算与Pytho…...

Java学习笔记(多线程):ReentrantLock 源码分析
本文是自己的学习笔记,主要参考资料如下 JavaSE文档 1、AQS 概述1.1、锁的原理1.2、任务队列1.2.1、结点的状态变化 1.3、加锁和解锁的简单流程 2、ReentrantLock2.1、加锁源码分析2.1.1、tryAcquire()的具体实现2.1.2、acquirQueued()的具体实现2.1.3、tryLock的具…...
(Go语言版))
【LeetCode 热题100】二叉树构造题精讲:前序 + 中序建树 有序数组构造 BST(力扣105 / 108)(Go语言版)
🌱 二叉树构造题精讲:前序 中序建树 & 有序数组构造 BST 本文围绕二叉树的两类构造类题目展开解析: 从前序与中序遍历序列构造二叉树 将有序数组转换为二叉搜索树 我们将从「已知遍历构造树」和「平衡构造 BST」两个角度,拆…...

【软考系统架构设计师】系统配置与性能评价知识点
1、 常见的性能指标 主频外频*倍频 主频1/CPU时钟周期 CPI(Clock Per Instruction)平均每条指令的平均时间周期数 IPC(Instruction Per Clock)每时钟周期运行指令数 MIPS百万条指令每秒 MFLOPS百万个浮点操作每秒 字长影响运算的…...

【android bluetooth 协议分析 01】【HCI 层介绍 1】【hci_packets.pdl 介绍】
在 AOSP 的蓝牙协议栈 (Gabeldorsche) 中,hci_packets.pdl 是一个 协议描述语言文件,用于定义 HCI (Host Controller Interface) 层的数据包结构和通信协议。以下是详细解析: 1. 文件作用 system/gd/hci/hci_packets.pdl 协议自动化生成&…...

低资源需求的大模型训练项目---调研0.5B大语言模型
一、主流0.5B大语言模型及性能对比 1. Qwen系列(阿里) • Qwen2.5-0.5B:阿里2024年9月开源的通义千问系列最小尺寸模型,支持32K上下文长度和8K生成长度。在中文场景下表现优异,指令跟踪、JSON结构化输出能力突出&…...

Spring Boot 中集成 Disruptor_高性能事件处理框架
1. 引言 1.1 什么是 Disruptor Disruptor 是一个高性能的事件处理框架,广泛应用于金融交易系统、日志记录、消息队列等领域。它通过无锁机制和环形缓冲区(Ring Buffer)实现高效的事件处理,具有极低的延迟和高吞吐量的特点。 1.2 为什么使用 Disruptor 高性能:通过无锁机…...