SQL学习笔记-聚合查询
非聚合查询和聚合查询的概念及差别
1. 非聚合查询
非聚合查询(Non-Aggregate Query)是指不使用聚合函数的查询。这类查询通常用于从表中检索具体的行和列数据,返回的结果是表中的原始数据。
示例
假设有一个名为 employees 的表,包含以下列:id、name、department 和 salary。
SELECT id, name, department, salary
FROM employees;这个查询会返回 employees 表中的所有行和指定的列。
特点
-
返回原始数据:结果是表中的实际行数据。
-
不涉及数据汇总:不会对数据进行任何汇总或计算。
-
可以使用
WHERE子句过滤数据SELECT id, name, department, salary FROM employees WHERE department = 'Sales';
2. 聚合查询
聚合查询(Aggregate Query)是指使用聚合函数的查询。聚合函数用于对一组数据进行计算,返回单个值。常见的聚合函数包括 COUNT、SUM、AVG、MIN 和 MAX。
示例
假设我们想要统计每个部门的员工数量:
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department;这个查询会返回每个部门的名称和该部门的员工数量。
特点
-
返回汇总数据:结果是对一组数据进行计算后的汇总值。
-
必须使用
GROUP BY子句:如果查询中包含非聚合列,则需要使用GROUP BY子句对这些列进行分组。 -
可以使用
HAVING子句过滤分组SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department HAVING COUNT(*) > 5;
3. 聚合查询与非聚合查询的差别
| 特点 | 非聚合查询 | 聚合查询 |
|---|---|---|
| 返回数据类型 | 返回表中的原始行数据 | 返回汇总后的单个值 |
| 是否使用聚合函数 | 不使用聚合函数 | 使用聚合函数(如 COUNT、SUM、AVG 等) |
是否需要 GROUP BY | 不需要 | 如果查询中包含非聚合列,则需要 GROUP BY |
| 数据量 | 返回多行数据 | 返回较少的行(通常是汇总后的数据) |
| 用途 | 用于检索具体数据 | 用于数据汇总和统计 |
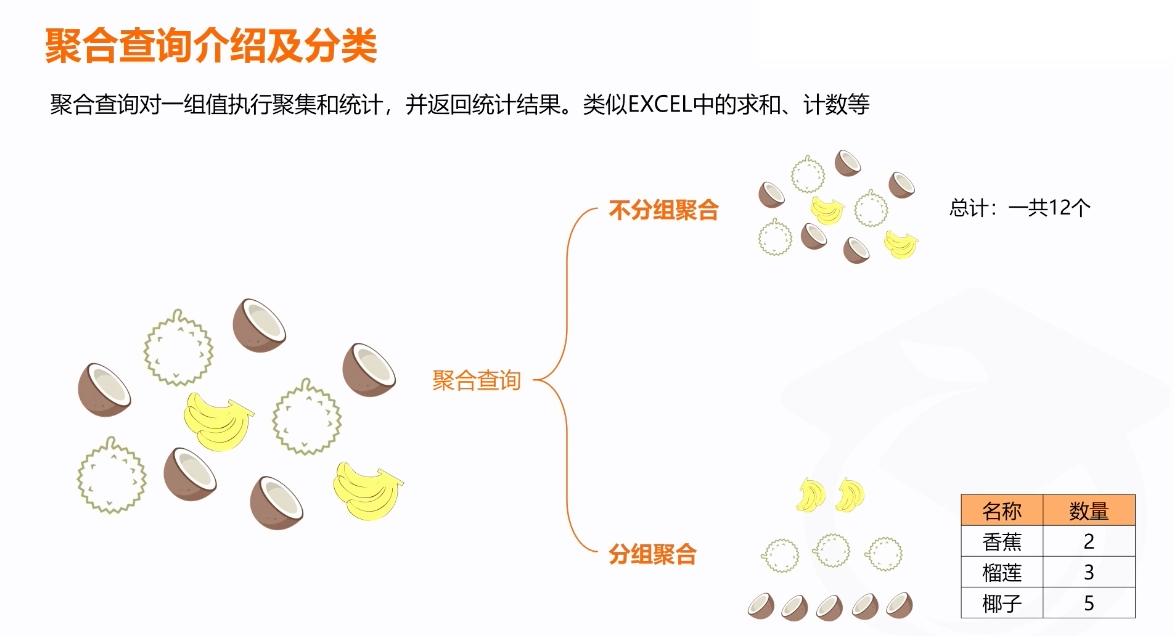
非分组聚合和分组聚合的概念和差别
在 SQL 中,分组聚合(Grouped Aggregation)和不分组聚合(Ungrouped Aggregation)是聚合查询的两种不同形式。它们的主要区别在于是否使用 GROUP BY 子句对数据进行分组。以下是对它们的概念和差别的详细解释。
1. 分组聚合(Grouped Aggregation)
分组聚合是指在执行聚合操作时,将数据分成多个组,每个组对应一个聚合结果。这通常通过 GROUP BY 子句实现。
概念
-
GROUP BY子句:用于将数据按指定列分组。 -
聚合函数:对每个分组的数据进行计算,返回每个分组的汇总值。

示例
假设有一个名为 employees 的表,包含以下列:id、name、department 和 salary。
SELECT department, COUNT(*) AS employee_count, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;这个查询会按 department 列对数据进行分组,并计算每个部门的员工数量和平均工资。
结果
假设表数据如下:
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | Sales | 5000 |
| 2 | Bob | Marketing | 6000 |
| 3 | Charlie | Sales | 5500 |
| 4 | David | IT | 7000 |
| 5 | Eve | Marketing | 6500 |
查询结果:
| department | employee_count | avg_salary |
|---|---|---|
| Sales | 2 | 5250 |
| Marketing | 2 | 6250 |
| IT | 1 | 7000 |
2. 不分组聚合(Ungrouped Aggregation)
不分组聚合是指对整个表的数据进行聚合操作,不进行分组。这种查询返回的是整个表的汇总值。
概念
-
聚合函数:对整个表的数据进行计算,返回单个汇总值。
-
不使用
GROUP BY子句:直接对整个表的数据进行聚合。
示例
假设有一个名为 employees 的表,包含以下列:id、name、department 和 salary。
SELECT COUNT(*) AS total_employees, AVG(salary) AS avg_salary
FROM employees;这个查询会计算整个表的员工总数和平均工资。
结果
假设表数据如下:
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | Sales | 5000 |
| 2 | Bob | Marketing | 6000 |
| 3 | Charlie | Sales | 5500 |
| 4 | David | IT | 7000 |
| 5 | Eve | Marketing | 6500 |
查询结果:
| total_employees | avg_salary |
|---|---|
| 5 | 6000 |
3. 分组聚合与不分组聚合的差别
| 特点 | 分组聚合(Grouped Aggregation) | 不分组聚合(Ungrouped Aggregation) |
|---|---|---|
是否使用 GROUP BY | 是 | 否 |
| 返回结果 | 每个分组的汇总值 | 整个表的汇总值 |
| 结果行数 | 与分组数相同 | 通常为一行 |
| 用途 | 对数据进行分组汇总,适用于多维度分析 | 对整个表的数据进行汇总,适用于全局统计 |
| 示例 | 按部门统计员工数量和平均工资 | 统计整个公司的员工总数和平均工资 |
4. 示例对比
假设我们有以下 employees 表:
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | Sales | 5000 |
| 2 | Bob | Marketing | 6000 |
| 3 | Charlie | Sales | 5500 |
| 4 | David | IT | 7000 |
| 5 | Eve | Marketing | 6500 |
分组聚合
SELECT department, COUNT(*) AS employee_count, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;结果:
| department | employee_count | avg_salary |
|---|---|---|
| Sales | 2 | 5250 |
| Marketing | 2 | 6250 |
| IT | 1 | 7000 |
不分组聚合
SELECT COUNT(*) AS total_employees, AVG(salary) AS avg_salary
FROM employees;结果:
| total_employees | avg_salary |
|---|---|
| 5 | 6000 |
总结
-
分组聚合:通过
GROUP BY子句对数据进行分组,返回每个分组的汇总值,适用于多维度分析。 -
不分组聚合:对整个表的数据进行聚合,返回整个表的汇总值,适用于全局统计。
图示差别
 常见使用错误点
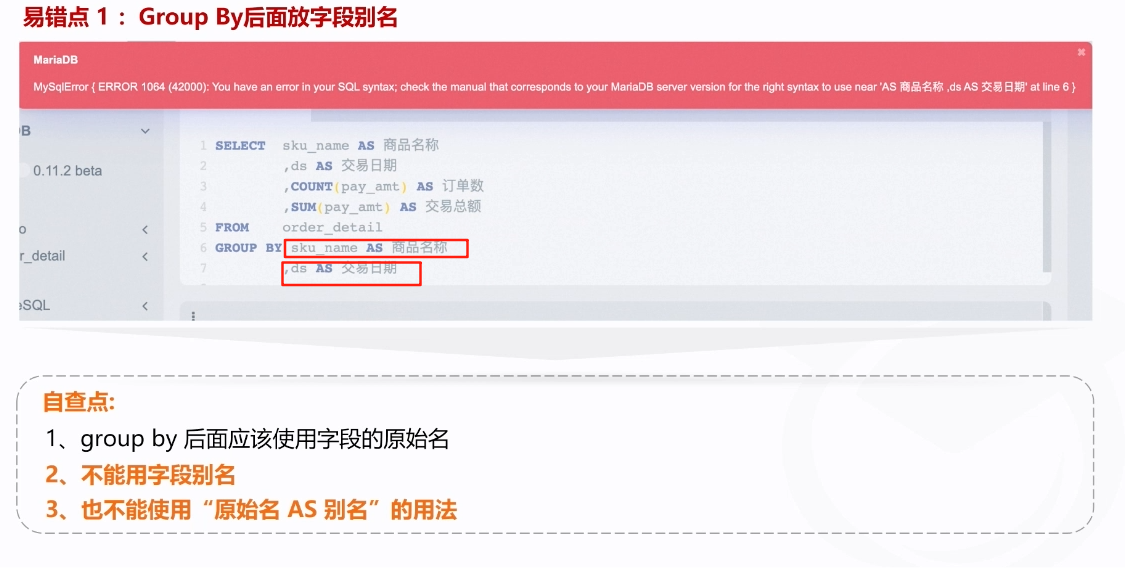
常见使用错误点
1.group by中使用了字段别名
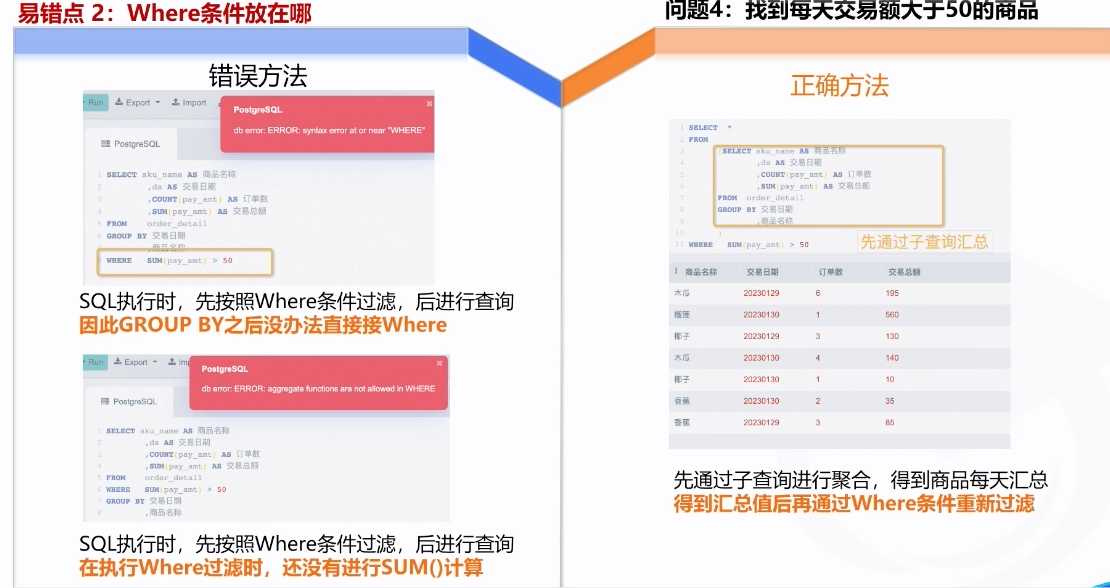
2.where条件设置不对
3.selct和group by中的字段未一一映射
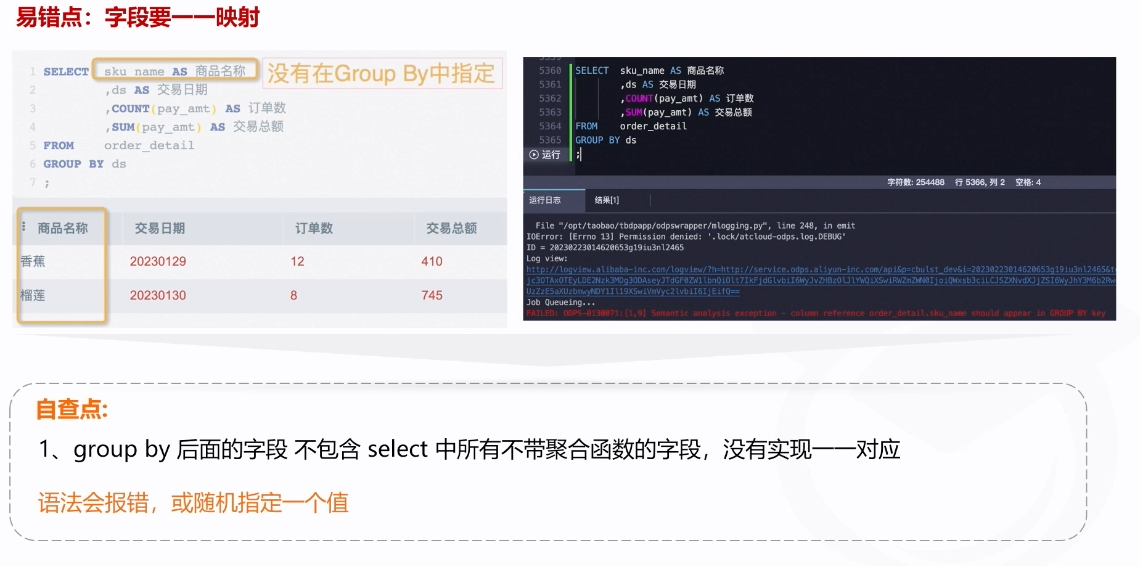
通过group去去重,将同一个名字或者同一个时间的内容聚合成一条数据去去重 ,可以类比成筛选(个人理解,如果有错误请评论区指正)
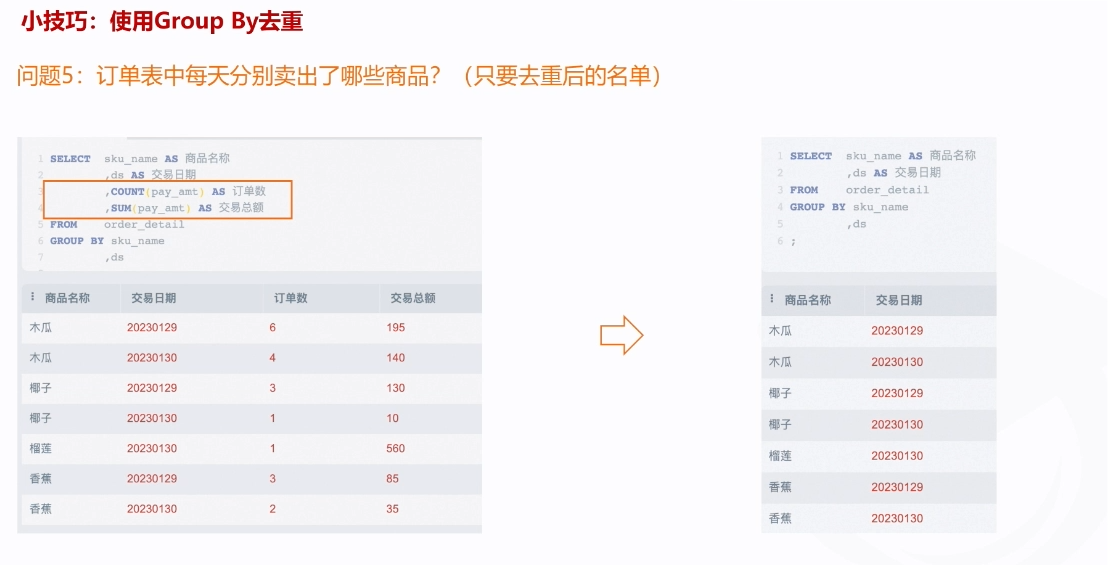
回顾

示例

相关文章:
SQL学习笔记-聚合查询
非聚合查询和聚合查询的概念及差别 1. 非聚合查询 非聚合查询(Non-Aggregate Query)是指不使用聚合函数的查询。这类查询通常用于从表中检索具体的行和列数据,返回的结果是表中的原始数据。 示例 假设有一个名为 employees 的表ÿ…...
【Vue 3 + Element Plus 实现产品标签的动态添加、删除与回显】
🚀Vue 3 Element Plus 实现产品标签的动态添加、删除与回显 在后台管理系统中,我们经常需要对表单数据进行动态处理,尤其是类似“产品标签”这样的字段,它需要用户能够灵活添加、删除,并在编辑时自动回显。今天我们就…...

【NLP】23.小结:选择60题
Question 1: What does the fixed lookup table in traditional NLP represent? A. A table of one‐hot vectors B. A table of pre‐trained dense word embeddings C. A dictionary of word definitions D. A table of n-gram counts Answer (中文): 答案选 B。传统NLP中“…...
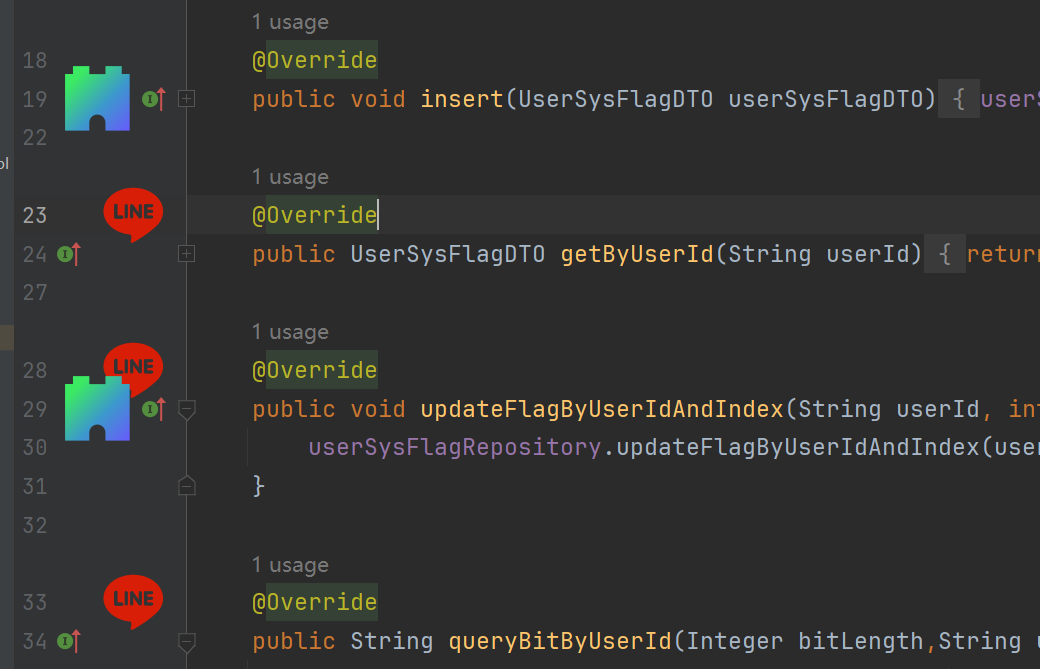
IntelliJ 配置(二)配置相关类库(2)LineMarkerProvider
一、介绍 LineMarkerProvider 是 IntelliJ 平台插件开发中的一个接口,它的作用是在编辑器左侧的“行标记区域”(就是代码行号左边那一栏)添加各种图标、标记或导航链接。比如Java 类中看到的: 小绿色三角形(可以点击运…...
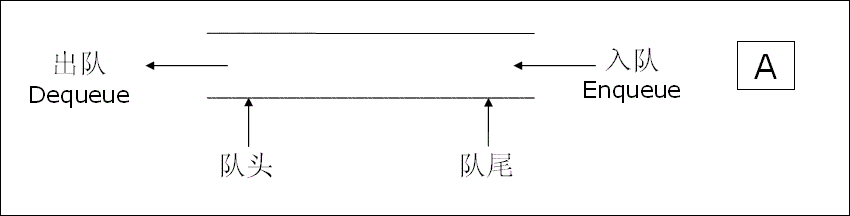
从零开始学java--线性表
数据结构基础 目录 数据结构基础 线性表 顺序表 链表 顺序表和链表的区别: 栈 队列 线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表中的元素个数就是线性表的长度,表的起始位置称为表头&am…...
AD917X系列JESD204B MODE7使用
MODE7特殊在F8,M4使用2个复数通道 CH0_NCO10MHz CH1_NCO30MHZ DP_NCO50MHz DDS1偏移20MHz DDS2偏移40MHz...
Spring Cloud之远程调用OpenFeign最佳实践
目录 OpenFeign最佳实践 问题引入 Feign 继承方式 创建Module 引入依赖 编写接口 打Jar包 服务提供方 服务消费方 启动服务并访问 Feign 抽取方式 创建Module 引入依赖 编写接口 打Jar包 服务消费方 启动服务并访问 服务部署 修改pom.xml文件 观察Nacos控制…...

【Python爬虫】详细入门指南
目录 一、简单介绍 二、详细工作流程以及组成部分 三、 简单案例实现 一、简单介绍 在当今数字化信息飞速发展的时代,数据的获取与分析变得愈发重要,而网络爬虫技术作为一种能够从互联网海量信息中自动抓取所需数据的有效手段,正逐渐走入…...

Win11系统 VMware虚拟机 安装教程
Win11系统 VMware虚拟机 安装教程 一、介绍 Windows 11是由微软公司(Microsoft)开发的操作系统,应用于计算机和平板电脑等设备 。于2021年6月24日发布 ,2021年10月5日发行 。 Windows 11提供了许多创新功能,增加了新…...
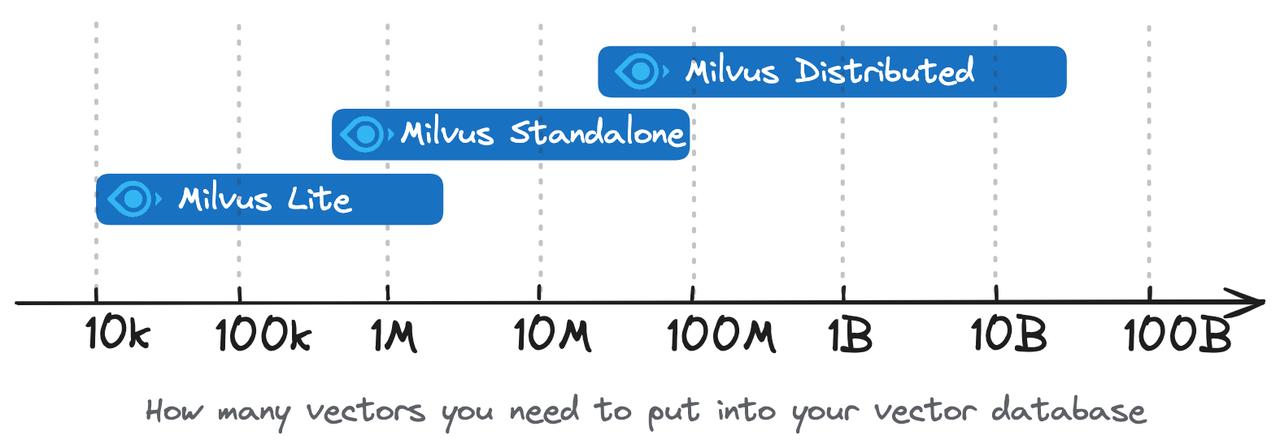
打造AI应用基础设施:Milvus向量数据库部署与运维
目录 打造AI应用基础设施:Milvus向量数据库部署与运维1. Milvus介绍1.1 什么是向量数据库?1.2 Milvus主要特点 2. Milvus部署方案对比2.1 Milvus Lite2.2 Milvus Standalone2.3 Milvus Distributed2.4 部署方案对比表 3. Milvus部署操作命令实战3.1 Milv…...

对于客户端数据存储方案——SQLite的思考
SQLite 比较适合进行本地小型数据的存储,在功能丰富性和并发能力上不如 MySQL。 数据类型差异 SQLite 使用动态类型系统:只有 5 种基本存储类 (NULL, INTEGER, REAL, TEXT, BLOB) 类型亲和性:SQLite 会将声明的列类型映射到最接近的存储类 …...
【深度学习与大模型基础】第11章-Bernoulli分布,Multinoulli分布
一、Bernoulli分布 1. 基本概念 想象你抛一枚硬币: 正面朝上(记为 1)概率是 p(比如 0.6)。 反面朝上(记为 0)概率是 1-p(比如 0.4)。 这就是一个Bernoulli分布&…...
基于Windows通过nginx代理访问Oracle数据库
基于Windows通过nginx代理访问Oracle数据库 环境说明: 生产环境是一套一主一备的ADG架构服务器,用户需要访问生产数据,基于安全考虑,生产IP地址不能直接对外服务,所以需要在DMZ部署一个前置机,并在该前置机…...
北斗和GPS信号频率重叠-兼容与互操作
越来越多的同学们发现北斗三代信号的B1C,B2a信号居然和美国GPS L1,L5处在同样频率上? 为什么美国会允许这样的事情发生?同频率难道不干扰彼此的信号吗? 思博伦卫星导航技术支持文章TED 这事得从2006年联合国成立全球卫星导航系统…...
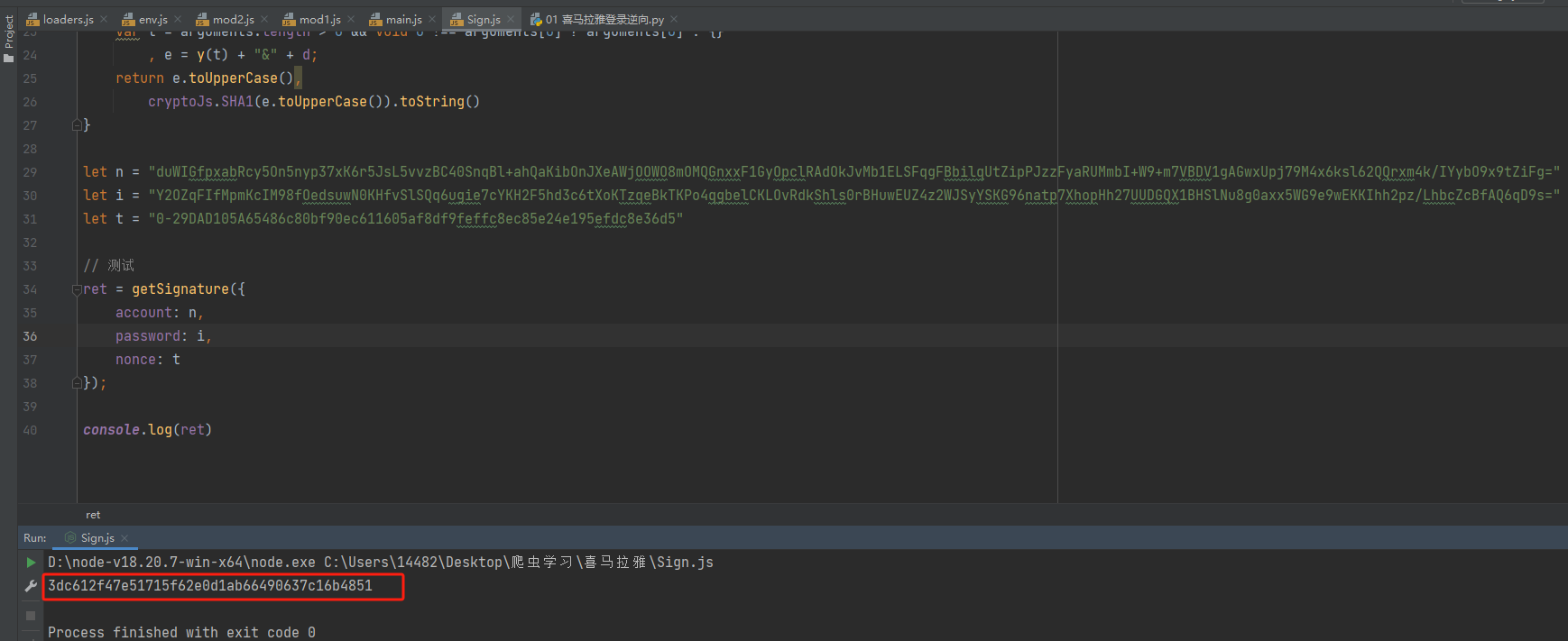
python爬虫:喜马拉雅案例(破解sign值)
声明: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 根据上一篇文章,我们破解了本网站的,手机号和密码验证&#x…...

如何高效查询订单销售情况与售罄率:从SQL到架构优化的全流程设计
在电商平台、SaaS多租户系统中,订单数据作为核心数据之一,承载了关键的运营指标,如销售额、商品售罄率、订单转化等。随着数据量的持续增长,如何在大数据量条件下快速、稳定地获取统计信息,成为系统设计的重点之一。 本文将从查询目标分析入手,结合数据库设计优化与典型…...

机器学习:让数据开口说话的科技魔法
在人工智能飞速发展的今天,「机器学习」已成为推动数字化转型的核心引擎。无论是手机的人脸解锁、网购平台的推荐系统,还是自动驾驶汽车的决策能力,背后都离不开机器学习的技术支撑。那么,机器学习究竟是什么?它又有哪…...

51单片机波特率与溢出率的关系
1. 波特率与溢出率的基本关系 波特率(Baud Rate)表示串口通信中每秒传输的位数(bps),而溢出率是定时器每秒溢出的次数。在51单片机中,波特率通常通过定时器的溢出率来生成。 公式关系: 波特率=溢出率/分频系数 其中,分频系数与定时器的工作模…...

Java 8 CompletableFuture:异步编程的利器与最佳实践
目录 1. 创建异步任务 1.1 使用默认线程池 1.2 使用自定义线程池 2. 异步回调处理 2.1 thenApply 和 thenApplyAsync 2.2 thenAccept 和 thenAcceptAsync 2.3 thenRun 和 thenRunAsync 3. 异常处理 3.1 whenComplete 和 whenCompleteAsync 3.2 handle 和 handleAsync…...

Podman与行业趋势分析 ——兼论与Docker的对比及未来发展方向
1. Podman核心概念与架构解析 1.1 定义与定位 Podman(Pod Manager)是由Red Hat主导开发的开源容器引擎,遵循OCI(Open Container Initiative)标准,专注于提供无守护进程(Daemonless)…...

摄影测量——单像空间后方交会
空间后方交会的求解是一个非线性问题,通常采用最小二乘法进行迭代解算。下面我将详细介绍具体的求解步骤: 1. 基本公式(共线条件方程) 共线条件方程是后方交会的基础: 复制 x - x₀ -f * [m₁₁(X-Xₛ) m₁₂(Y-…...

ros2_01
note01 ROS2和ROS最大的区别中间件 中间件: 介于某两个或者多个节点中间的组件;提供多个节点中间通信; ROS1:中间件是ROS组织自己基于TCP机制建立的,随着现在传感器的升级,数据量越来越大,原…...

C++中的高阶函数
C中的高阶函数 高阶函数是指可以接受其他函数作为参数或返回函数作为结果的函数。在C中,有几种方式可以实现高阶函数的功能: 1. 函数指针 #include <iostream>int add(int a, int b) { return a b; } int subtract(int a, int b) { return a -…...

计算机视觉与深度学习 | 钢筋捆数识别
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 钢筋捆数 1、初始结果2、处理效果不佳时的改进方法1、预处理增强2、后…...
)
L3-027 可怜的复杂度(纯暴力)
暴力解答,肯定超时,因为我刚开始把所有答案,存到了ans这个vector里面了,然后进行枚举情况,后面发现因为这个阶数很高的时候,就会直接炸内存,所以我直接选择了在dfs里面进行统计答案,…...

基于RV1126开发板的人脸姿态估计算法开发
1. 人脸姿态估计简介 人脸姿态估计是通过对一张人脸图像进行分析,获得脸部朝向的角度信息。姿态估计是多姿态问题中较为关键的步骤。一般可以用旋转矩阵、旋转向量、四元数或欧拉角表示。人脸的姿态变化通常包括上下俯仰(pitch)、左右旋转(yaw)以及平面内角度旋转(r…...
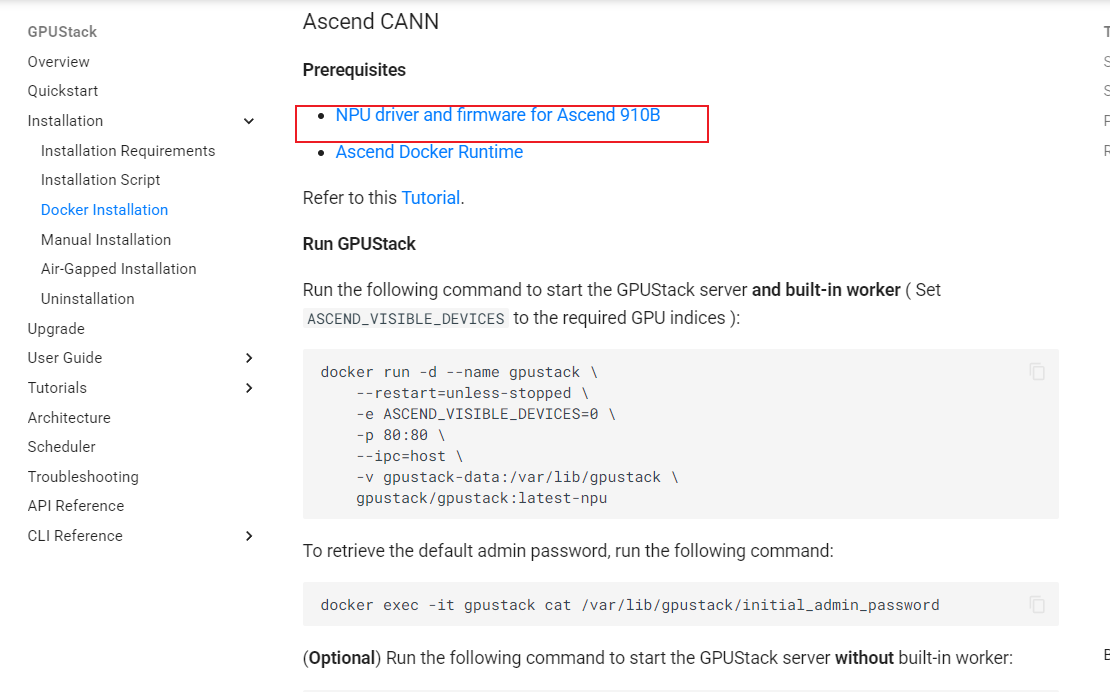
鲲鹏+昇腾部署集群管理软件GPUStack,两台服务器搭建双节点集群【实战详细踩坑篇】
前期说明 配置:2台鲲鹏32C2 2Atlas300I duo,之前看网上文档,目前GPUstack只支持910B芯片,想尝试一下能不能310P也部署试试,毕竟华为的集群软件要收费。 系统:openEuler22.03-LTS 驱动:24.1.rc…...

【C#】CAN通信的使用
在C#中实现CAN通信通常需要借助第三方库或硬件设备的驱动程序,因为C#本身并没有直接内置支持CAN通信的功能。以下是一个关于如何使用C#实现CAN通信的基本指南,包括所需的步骤和常用工具。 1. 硬件准备 要进行CAN通信,首先需要一个支持CAN协…...

火山引擎旗下的产品
用户问的是火山引擎旗下的产品,我需要详细列出各个类别下的产品。首先,我得确认火山引擎有哪些主要业务领域,比如云计算、大数据、人工智能这些。然后,每个领域下具体有哪些产品呢?比如云计算方面可能有云服务器、容器…...

Elasticsearch 故障转移及水平扩容
一、故障转移 Elasticsearch 的故障转移(Failover)机制是其高可用性的核心,通过分布式设计、自动检测和恢复策略确保集群在节点故障时持续服务。 1.1 故障转移的核心组件 组件作用Master 节点管理集群状态(分片分配、索引创建&…...