Ollama调用多GPU实现负载均衡
文章目录
- 📊 背景说明
- 🛠️ 修改 systemd 服务配置
- 1. 配置文件路径
- 2. 编辑服务文件
- 2. 重新加载配置并重启服务
- 3. 验证配置是否成功
- 📈 应用效果示例
- 1. 调用单个70b模型
- 2. 调用多个模型(70b和32b模型)
- 总结
- 📌 附:自动化脚本(可选)
- 额外补充
- 🧠 1. Open WebUI多用户同时访问同一个模型,是否相互影响?
- 🔍 详细说明:
- ✅ 互不干扰的部分
- ⚠️ 可能“互相影响”的部分
- 📚 2. 使用知识库(向量检索/RAG)是否会影响模型?
- ✅ 简短回答
- 🔍 具体解释
默认的ollama调用的各种大模型,如deepseek 70b模型,每个模型实例只绑定一张 GPU,如果是多卡,其它卡会一直闲置,造成一定浪费。
本文档介绍如何通过 systemd 配置文件为 Ollama 服务添加 GPU 和调度相关的环境变量,从而实现多 GPU 的高效利用与负载均衡。
📊 背景说明
我们首先通过命令nvidia-smi查看有几张GPU,如下图,可以看到我们当前有4张卡,GPU编号是0,1,2,3(为了之后配置中设置数字)。
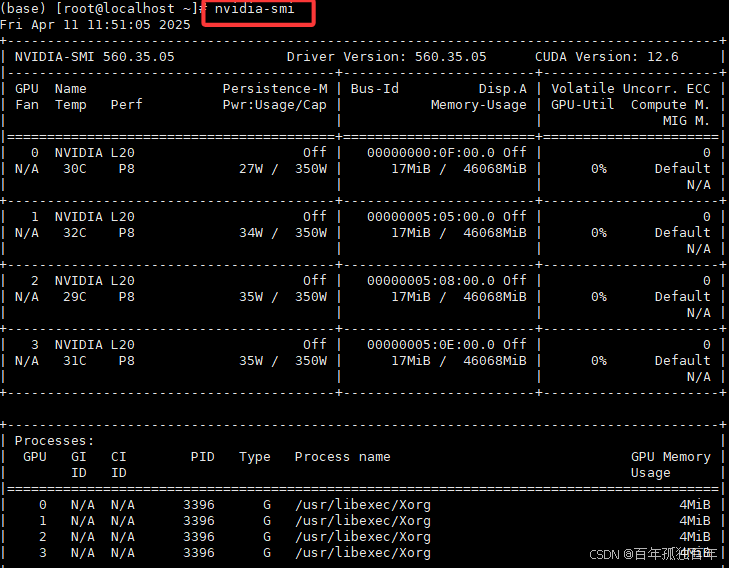
如果只是通过Open WebUI 使用ollama的deepseek-r1:70b模型,我们观察GPU使用情况,如下图,可以发现只有一张卡使用,即使是多个用户同时使用deepseek-r1:70b模型,也依然只有单个GPU使用,这造成了极大的资源浪费,没有相应的负载均衡。
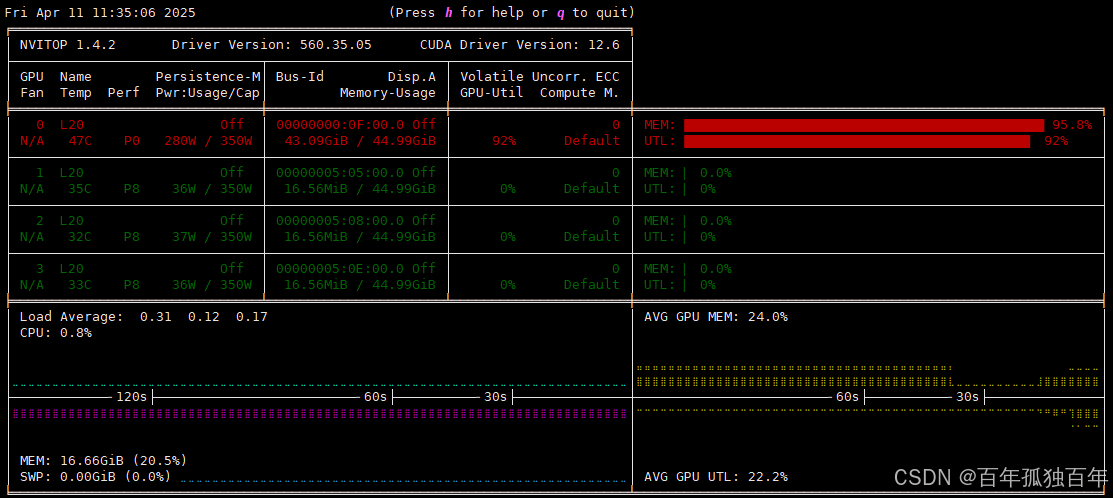
如果局域网内用户,几个人访问70b模型,几个人访问32b模型,第一张卡显存占满了之后,才会调用第二张卡,第三张卡和第四张卡永远都不用使用到,造成一定程度上的资源浪费。
Ollama 也只会在部分 GPU 上负载,其他 GPU 处于空闲状态。
Ollama 默认每个模型实例只绑定一张 GPU,并不具备自动负载均衡的能力。
为实现模型多卡部署与更高的吞吐量,我们可以通过设置环境变量来调整 Ollama 的调度行为。
因此我们需要相应的环境设置,设置也很简单。
🛠️ 修改 systemd 服务配置
1. 配置文件路径
Ollama 的 systemd 服务配置文件路径如下:
/etc/systemd/system/ollama.service
2. 编辑服务文件
sudo vim /etc/systemd/system/ollama.service
默认的整体配置如下:
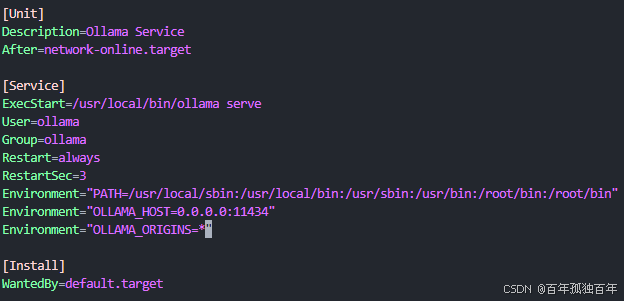
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/bin"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"[Install]
WantedBy=default.target
按下
i进入插入模式,找到[Service]段,我们需要在[Service]的下面添加几个环境变量设置,如下:
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"
Environment="OLLAMA_SCHED_SPREAD=1"
Environment="OLLAMA_KEEP_ALIVE=-1"
✨参数说明:
- Environment=“CUDA_VISIBLE_DEVICES=0,1,2,3” 代表让ollama能识别到第几张显卡,因为4张显卡,从0开始编号,所以为0,1,2,3。根据你的显卡数量进行设置。
- Environment=“OLLAMA_SCHED_SPREAD=1” 这几张卡均衡使用
- Environment=“OLLAMA_KEEP_ALIVE=-1” 模型一直加载, 不自动卸载,这个设置会一直占用显存不释放,相应会快一些。如果不经常使用模型,可以把这个去掉,啥时候通过Open Webui访问,然后啥时候加载模型,第一次加载一般会慢一些。
添加之后的完整配置:
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/root/bin"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
### 添加如下配置,下面三个是新增的
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"
Environment="OLLAMA_SCHED_SPREAD=1"
Environment="OLLAMA_KEEP_ALIVE=-1"[Install]
WantedBy=default.target
按下 Esc,然后输入 :wq 保存并退出。
2. 重新加载配置并重启服务
使用如下命令:
sudo systemctl daemon-reload
sudo systemctl restart ollama

💡 注意:若出现
Failed信息,仅为非关键错误,通常不影响实际运行。
sudo systemctl daemon-reload命令解释:
重新加载 systemd 管理器的配置文件。当你修改了服务的配置文件(比如 /etc/systemd/system/ollama.service)后,systemd 并不会自动发现这些改动,你需要显式告诉它:“配置文件变了,请重新读取”。
sudo systemctl restart ollama命令解释:
停止再重新启动 ollama 服务,使其立即应用你新修改的配置。
3. 验证配置是否成功
查看服务状态:
systemctl status ollama
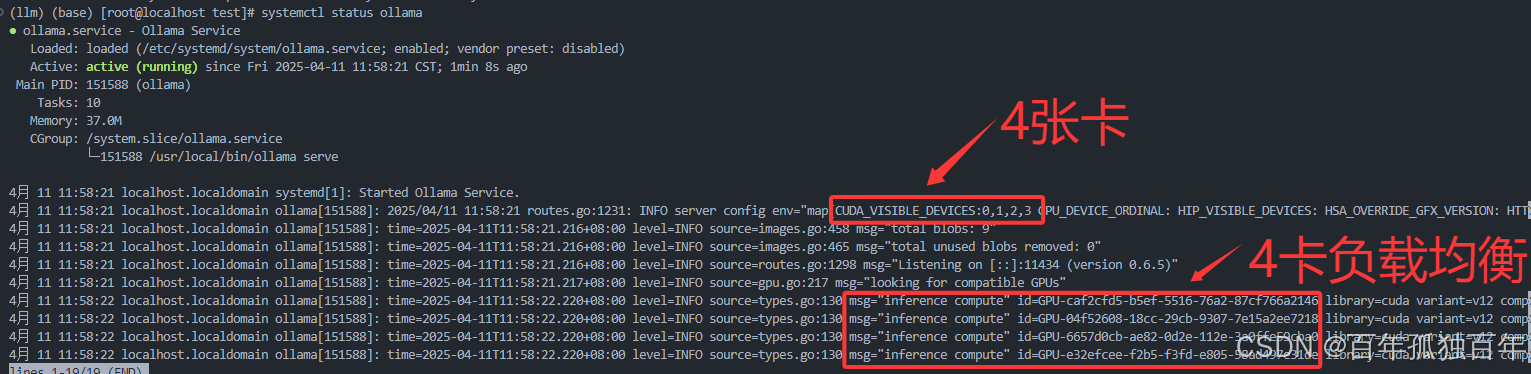
检查环境变量是否注入成功:
sudo systemctl show ollama | grep Environment
你应当看到如下输出:
Environment=CUDA_VISIBLE_DEVICES=0,1,2,3
Environment=OLLAMA_SCHED_SPREAD=1
Environment=OLLAMA_KEEP_ALIVE=-1
参数说明
| 参数 | 含义 |
|---|---|
CUDA_VISIBLE_DEVICES=0,1,2,3 | 指定可用的 GPU 编号(0 到 3),表示总共使用 4 张显卡 |
OLLAMA_SCHED_SPREAD=1 | 启用多 GPU 均衡调度,让模型推理在多卡之间分摊负载 |
OLLAMA_KEEP_ALIVE=-1 | 模型常驻内存,保持加载状态,防止自动卸载,提高响应速度 |
📈 应用效果示例
1. 调用单个70b模型
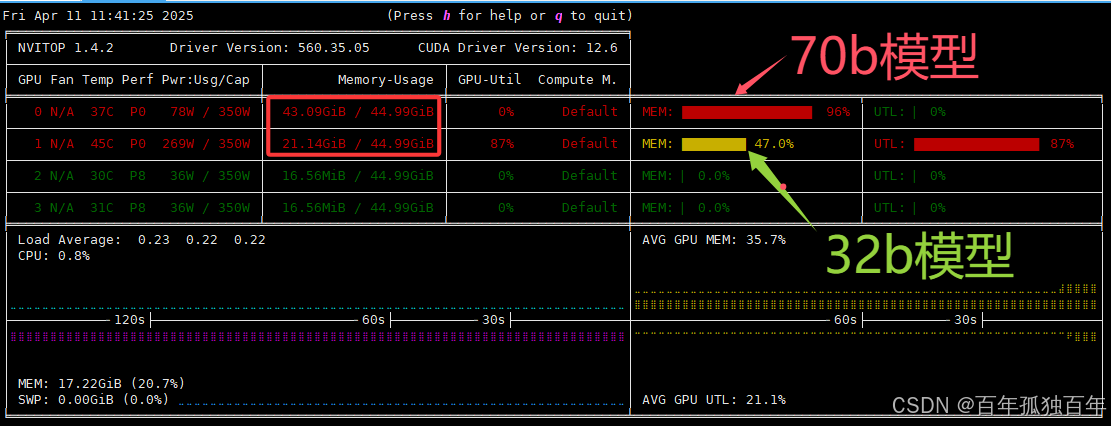
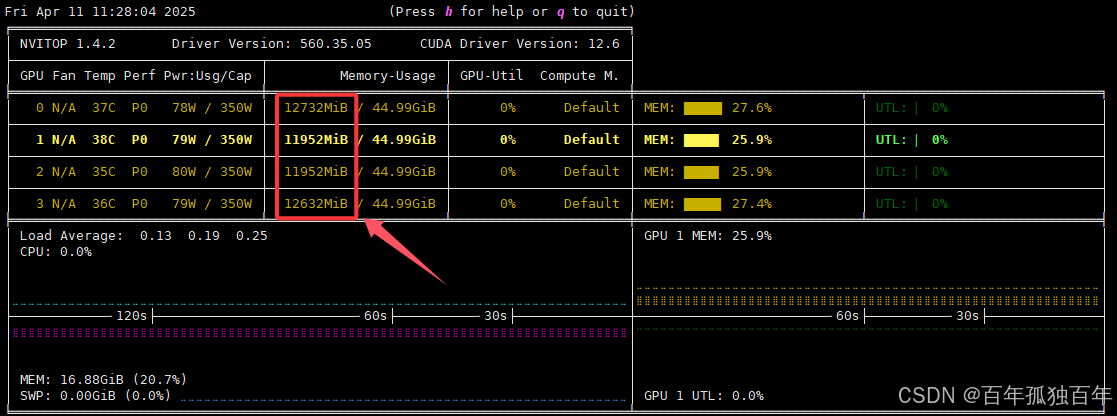
进行上述设置之后,我们通过Open Webui访问70b模型,如下

此时查看显存占用,如下图,可以发现此时会同时使用4张卡,模型占用的43G左右的显存会均衡分布在4张卡中,而不是用单个卡推理。
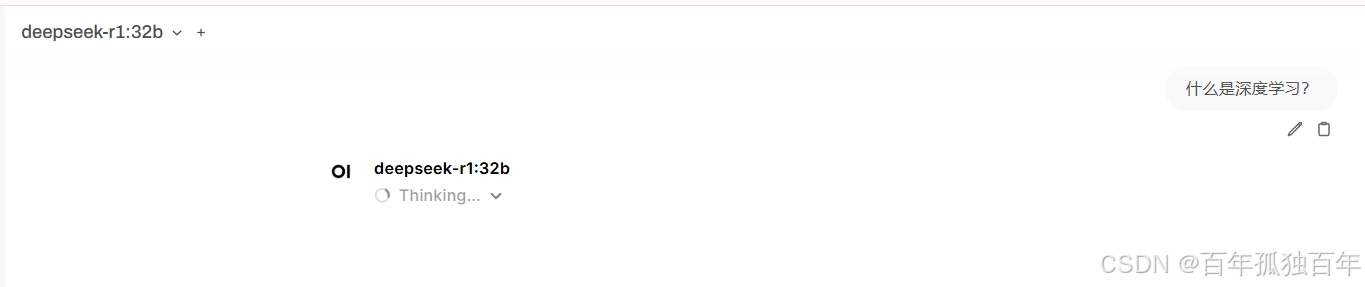
2. 调用多个模型(70b和32b模型)
此时再访问32b的模型,如下:
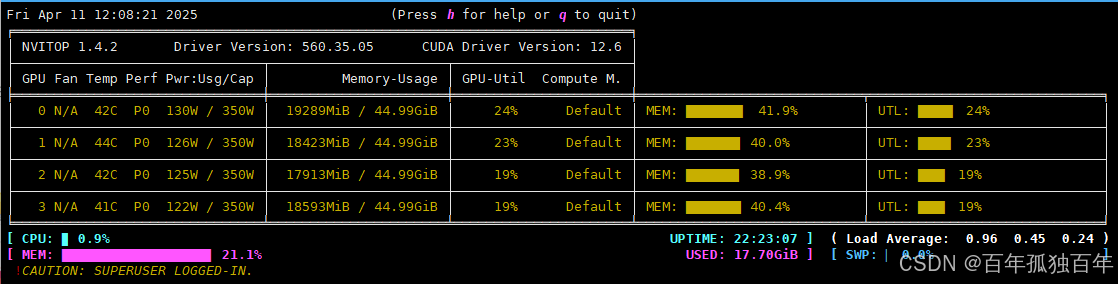
此时显存占用如下图,可以发现依然会均衡的调用每个GPU,而不会使用单个GPU。
总结
通过为 systemd 添加环境变量配置,Ollama 可以实现:
- 多 GPU 推理任务的自动均衡调度
- 模型常驻显存,减少加载时间
- 灵活控制资源占用,提升整体性能表现
该方法适用于高并发场景、长时间部署服务、模型启动延迟敏感等使用场景。
📌 附:自动化脚本(可选)
如需自动完成上述步骤,可使用以下脚本:
#!/bin/bashSERVICE_FILE="/etc/systemd/system/ollama.service"# 插入环境变量(如果没有手动加过)
sudo sed -i '/^\[Service\]/a Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"\nEnvironment="OLLAMA_SCHED_SPREAD=1"\nEnvironment="OLLAMA_KEEP_ALIVE=-1"' "$SERVICE_FILE"# 重新加载并重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama# 检查状态
sudo systemctl status ollama
额外补充
🧠 1. Open WebUI多用户同时访问同一个模型,是否相互影响?
🔍 详细说明:
✅ 互不干扰的部分
- 推理上下文是隔离的:每个用户的输入输出在 WebUI 层面是分开的,彼此看不到对方内容。
- 会话状态是用户独立的:对话记录、聊天上下文、调用参数不会混淆。
⚠️ 可能“互相影响”的部分
- GPU 显存竞争:
- 70B 模型非常吃显存,如果同时多个用户发起推理,可能卡顿、OOM、速度变慢。
- 尤其是 batch size、上下文长度较大时会挤爆内存。
- 此时你看到的“互相影响”其实是性能瓶颈,不是逻辑混乱。
- 线程/队列调度:
- 如果使用的是单实例模型服务(比如 Ollama 只加载一次模型),请求会被排队处理。
- 一个用户长时间生成内容可能导致另一个用户响应慢。
📚 2. 使用知识库(向量检索/RAG)是否会影响模型?
✅ 简短回答
不会直接影响模型本身,但会影响模型的“输出内容”。
🔍 具体解释
- 模型本体(参数、权重)是静态的,不会被修改。
- 知识库的作用是提供额外的上下文信息(通过检索,拼接在 prompt 前),相当于给模型“补充资料”。
- 所以:
- 每个用户的知识库是独立配置的话,互不影响。
- 如果多个用户使用同一个知识库,那检索到的内容可能类似,影响回答的风格/方向,但不至于“污染”模型。
- 不会长期改变模型行为,只是短暂地影响一次回答。
参考链接:
https://bbs.huaweicloud.com/blogs/447392
相关文章:
Ollama调用多GPU实现负载均衡
文章目录 📊 背景说明🛠️ 修改 systemd 服务配置1. 配置文件路径2. 编辑服务文件2. 重新加载配置并重启服务3. 验证配置是否成功 📈 应用效果示例1. 调用单个70b模型2. 调用多个模型(70b和32b模型) 总结📌…...
WebRTC实时通话EasyRTC嵌入式音视频通信SDK,构建智慧医疗远程会诊高效方案
一、方案背景 当前医疗领域,医疗资源分布不均问题尤为突出,大城市和发达地区优质医疗资源集中,偏远地区医疗设施陈旧、人才稀缺,患者难以获得高质量的医疗服务,制约医疗事业均衡发展。 EasyRTC技术基于WebRTC等先进技…...

深入理解计算机系统记录
在 C 语言中,struct(结构体)和 union(联合体)都是用来存储多个不同类型的数据成员,但它们在内存分配和数据存储方式上有显著区别。下面详细说明它们的主要区别: 1. 内存分配 结构体(…...

【笔记】对抗训练-GAN
对抗训练-GAN 深度学习中 GAN 的对抗目标函数详解与最优解推导一、GAN 的基本对抗目标函数二、判别器与生成器的博弈目标三、判别器的最优解推导四、最优判别器的含义五、总结六、WGAN 的动机(为后续铺垫) 深度学习中 GAN 的对抗目标函数详解与最优解推导…...
安卓开发中数据存储之Room详解)
(二十三)安卓开发中数据存储之Room详解
在安卓开发中,Room 是一个强大的本地数据库解决方案,它是 Android Jetpack 的一部分,基于 SQLite 构建,提供了更高层次的抽象。Room 简化了数据库操作,减少了样板代码,同时支持与 LiveData 和 ViewModel 的…...

AIoT 智变浪潮演讲实录 | 刘浩然:让硬件会思考:边缘大模型网关助力硬件智能革新
4 月 2 日,由火山引擎与英特尔联合主办的 AIoT “智变浪潮”技术沙龙在深圳成功举行,活动聚焦 AI 硬件产业的技术落地与生态协同,吸引了芯片厂商、技术方案商、品牌方及投资机构代表等 700 多位嘉宾参会。 会上,火山引擎边缘智能高…...
【Windows】系统安全移除移动存储设备指南:告别「设备被占用」弹窗
Windows系统安全移除移动存储设备指南:告别「设备被占用」弹窗 解决移动硬盘和U盘正在被占用无法弹出 一、问题背景 使用Windows系统时,经常遇到移动硬盘/U盘弹出失败提示「设备正在使用中」,即使已关闭所有可见程序。本文将系统梳理已验证…...

C++运算符重载全面总结
C运算符重载全面总结 运算符重载是C中一项强大的特性,它允许程序员为自定义类型定义运算符的行为。以下是关于C运算符重载的详细总结: 一、基本概念 1. 什么是运算符重载 运算符重载是指为自定义类型(类或结构体)重新定义或重…...
ArmSoM Sige5 CM5:RK3576 上 Ultralytics YOLOv11 边缘计算新标杆
在计算机视觉技术加速落地的今天,ArmSoM 正式宣布其基于 Rockchip RK3576 的旗舰产品 Sige5 开发板 和 CM5 核心板 全面支持 Ultralytics YOLOv11 模型的 RKNN 部署。这一突破标志着边缘计算领域迎来新一代高性能、低功耗的 AI 解决方案&am…...

【计算机网络】什么是路由?核心概念与实战详解
📌 引言 路由(Routing)是互联网的“导航系统”,负责将数据包从源设备精准送达目标设备。无论是浏览网页、发送消息还是视频通话,背后都依赖路由技术。本文将用通俗类比技术深度的方式,解析路由的核心机制。…...
【ubuntu】linux开机自启动
目录 开机自启动: /etc/rc.loacl system V 使用/etc/rc*.d/系统运行优先级 遇到的问题: 1. Linux 系统启动阶段概述 方法1:/etc/rc5.d/ 脚本延时日志 方法二:使用 udev 规则来触发脚本执行 开机自启动: /etc/…...

dnf install openssl失败的原因和解决办法
网上有很多编译OpenSSL源码(3.x版本)为RPM包的文章,这些文章在安装RPM包时都是执行rpm -ivh openssl-xxx.rpm --nodeps --force 这个命令能在缺少依赖包的情况下能强行执行安装 其实根据Centos的文档,安装RPM包一般是执行yum install或dnf install。后者…...

Java 在人工智能领域的突围:从企业级架构到边缘计算的技术革新
一、Java AI 的底层逻辑:从语言特性到生态重构 在 Python 占据 AI 开发主导地位的当下,Java 正通过技术重构实现突围。作为拥有 30 年企业级开发经验的编程语言,Java 的核心优势在于强类型安全、内存管理能力和分布式系统支持,这…...

操作系统导论——第19章 分页:快速地址转换(TLB)
使用分页作为核心机制来实现虚拟内存,可能会带来较高的性能开销。使用分页,就要将内存地址空间切分成大量固定大小的单元(页),并且需要记录这些单元的地址映射信息。因为这些映射信息一般存储在物理内存中,…...

计算机网络:流量控制与可靠传输机制
目录 基本概念 流量控制:别噎着啦! 可靠传输:快递必达服务 传输差错:现实中的意外 滑动窗口 基本概念 换句话说:批量发货排队验收 停止-等待协议 SW(发1份等1份) 超时重传:…...

SaaS、Paas、IaaS、MaaS、BaaS五大云计算服务模式
科普版:通俗理解五大云计算服务模式 1. SaaS(软件即服务) 一句话解释:像“租用公寓”,直接使用现成的软件,无需操心维护。 案例:使用钉钉办公、在网页版WPS编辑文档。服务提供商负责软件更新和…...

计算机网络 - 三次握手相关问题
通过一些问题来讨论 TCP 协议中的三次握手机制 说一下三次握手的大致过程?为什么需要三次握手?2 次不可以吗?第三次握手,可以携带数据吗?第二次呢?三次握手连接阶段,最后一次ACK包丢失…...

通过使用 include 语句加载并执行一个CMake脚本来引入第三方库
通过使用 include 语句加载并执行一个CMake脚本来引入第三方库 当项目中使用到第三方库时,可以通过使用 include 语句来加载并执行一个CMake脚本,在引入的CMake脚本中进行第三方库的下载、构建和库查找路径的设置等操作,以这种方式简化项目中…...

架构生命周期(高软57)
系列文章目录 架构生命周期 文章目录 系列文章目录前言一、软件架构是什么?二、软件架构的内容三、软件设计阶段四、构件总结 前言 本节讲明架构设计的架构生命周期概念。 一、软件架构是什么? 二、软件架构的内容 三、软件设计阶段 四、构件 总结 就…...
JMeter使用
1.简介 1.1 打开方式 ①点击bat,打开 ②添加JMeter系统环境变量,输⼊命令jmeter即可启动JMeter⼯具 1.2 配置 简体中文 放大字体 1.3 使用 ①添加线程组 ②创建http请求 2. 组件 2.1 线程组 控制JMeter将⽤于执⾏测试的线程数,也可以把⼀个线程理解为⼀个测…...

Ant Design Vue 表格复杂数据合并单元格
Ant Design Vue 表格复杂数据合并单元格 官方合并效果 官方示例 表头只支持列合并,使用 column 里的 colSpan 进行设置。 表格支持行/列合并,使用 render 里的单元格属性 colSpan 或者 rowSpan 设值为 0 时,设置的表格不会渲染。 <temp…...

Fiddler为什么可以看到一次HTTP请求数据?
1、作为代理服务器 Fiddler作为代理服务器,拦截了设备与互联网服务器之间的所有HTTP和HTTPS流量。当客户端(如浏览器)发送请求时,请求先到达Fiddler,然后由Fiddler转发到目标服务器;服务器的响应也会返回给…...

第十九讲 | XGBoost 与集成学习:精准高效的地学建模新范式
🟨 一、为什么要学习集成学习? 集成学习(Ensemble Learning) 是一种将多个弱学习器(如决策树)组合成一个强学习器的策略。它在地理学、生态学、遥感分类等领域表现尤为突出。 📌 应用优势&#…...

基于 GoFrame 框架的电子邮件发送实践:优势、特色与经验分享
1. 引言 如果你是一位有1-2年Go开发经验的后端开发者,可能已经熟悉了Go语言在性能和并发上的天然优势,也曾在项目中遇到过邮件发送的需求——无论是用户注册时的激活邮件、系统异常时的通知,还是营销活动中的批量促销邮件,邮件功…...
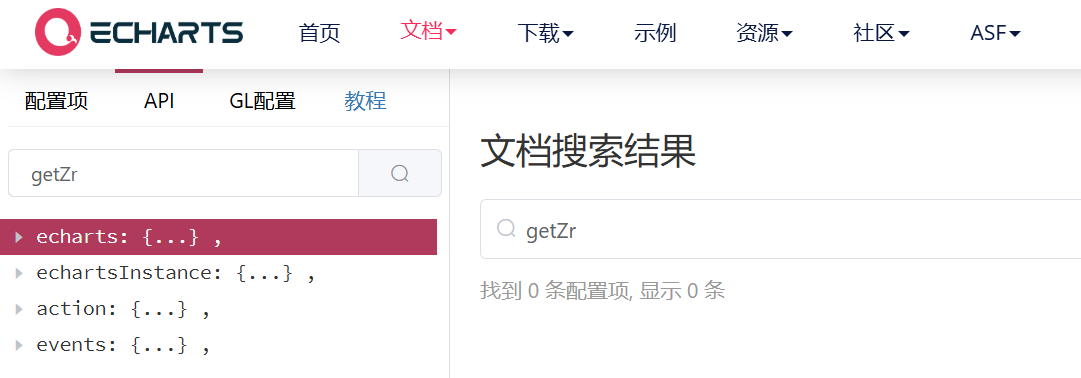
ECharts 如何实现柱状图悬停时,整个背景区域均可触发点击事件
1. 前言 ECharts 柱状图的点击事件默认仅响应柱子本身的点击,本文旨在实现整个背景区域均可触发点击事件 2. 实现思路 核心:全局监听 坐标判断 数据转换 通过 getZr() 监听整个画布点击,结合像素坐标判断是否在图表区域内通过 containPi…...

金融简单介绍及金融诈骗防范
在当今社会,金融学如同一股无形却强大的力量,深刻影响着我们生活的方方面面。无论是个人的日常收支、投资理财,还是国家的宏观经济调控,都与金融学紧密相连。 一、金融学的概念 金融学,简单来说,是研…...

cursor+高德MCP:制作一份旅游攻略
高德开放平台 | 高德地图API (amap.com) 1.注册成为开发者 2.进入控制台选择应用管理----->我的应用 3.新建应用 4.点击添加Key 5.在高德开发平台找到MCP的文档 6.按照快速接入的步骤,进行操作 一定要按照最新版的cursor, 如果之前已经安装旧的版本卸载掉重新安…...

软件版本命名规范Semantic Versioning
语义化版本控制(Semantic Versioning,简称 SemVer)是一种广泛采用的版本号管理规范,旨在通过版本号传达软件更新的性质和影响,帮助开发者和用户理解每次发布的变更内容 🔢 版本号结构 语义化版本号通常采…...

Uniapp: 大纲
目录 一、基础巩固1.1、Uniapp:下拉选择框ba-tree-picker1.2、Uniapp:确认框1.3、Uniapp:消息提示1.4、Uniapp:获取当前定位坐标 二、项目配置2.1、Uniapp:修改端口号2.2、Uniapp:本地存储 一、基础巩固 1.1、Uniapp:…...
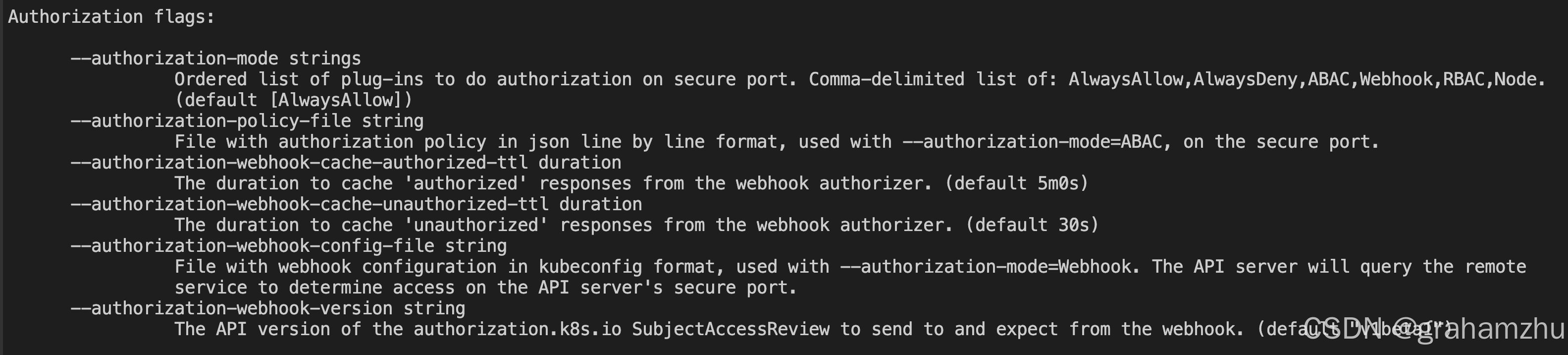
Kubernetes控制平面组件:API Server Webhook 授权机制 详解
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...