关于 Spring Batch 的详细解析及其同类框架的对比分析,以及如何自己设计一个java批处理框架(类似spring batch)的步骤
以下是关于 Spring Batch 的详细解析及其同类框架的对比分析:
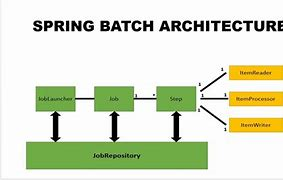
一、Spring Batch 核心详解
1. 核心概念
-
作业(Job):批处理任务的顶层容器,由多个步骤(Step)组成。
-
步骤(Step):最小执行单元,分为 Chunk-oriented(分块处理)和 Tasklet(自定义任务)。
-
分块处理(Chunk):
// 读取 → 处理 → 写入的分块模式 ItemReader → ItemProcessor → ItemWriter- ItemReader:从数据源(数据库、文件等)读取数据。
- ItemProcessor:对数据进行转换或过滤。
- ItemWriter:批量写入结果(如数据库、文件)。
-
事务管理:通过
Chunk的事务边界控制(如每100条提交一次)。 -
重启与恢复:支持作业中断后从断点恢复(通过
JobRepository记录状态)。
2. 核心组件
| 组件 | 作用 |
|---|---|
| JobLauncher | 启动作业 |
| JobRepository | 存储作业执行状态(如数据库表) |
| JobParameters | 传递作业运行时参数(如时间戳、文件路径) |
| TaskExecutor | 线程管理(如并发步骤执行) |
3. 典型场景
- 数据迁移:如从旧数据库迁移到新数据库。
- 报表生成:每日生成销售统计报表。
- ETL任务:从文件/数据库提取数据并转换加载到数据仓库。
4. 代码示例(分块处理)
@Configuration
public class BatchConfig {@Beanpublic Step step(ItemReader<User> reader,ItemProcessor<User, User> processor,ItemWriter<User> writer) {return steps.get("myStep").<User, User>chunk(10) // 每10条提交一次.reader(reader).processor(processor).writer(writer).build();}@Beanpublic Job job(Step step) {return jobs.get("myJob").start(step).build();}
}
二、Spring Batch 同类框架对比
1. 主流框架对比
| 框架 | 类型 | 优势 | 适用场景 | 缺点 |
|---|---|---|---|---|
| Spring Batch | Java批处理 | Java生态友好、事务控制精细、适合中等规模数据 | 企业级Java应用、复杂分步处理 | 性能不如Spark/Flink,分布式能力有限 |
| Apache Spark | 大数据批处理 | 内存加速计算、支持SQL/DSL、适合海量数据 | 大数据ETL、机器学习数据预处理 | 需要集群资源,学习成本高 |
| Apache Flink | 流批一体 | 流批统一处理、低延迟、状态管理 | 实时+批处理混合场景 | 配置复杂,社区活跃度低于Spark |
| Apache Airflow | 任务调度 | DAG可视化、动态依赖、支持Python/Java | 复杂依赖关系、跨系统调度 | 资源消耗大,需独立集群 |
| Luigi | 任务调度 | 简单易用、Python原生支持 | 小规模任务调度 | 可视化能力弱 |
| Hadoop MapReduce | 传统批处理 | 成熟稳定、适合离线批处理 | 传统Hadoop生态 | 性能低,编程模型复杂 |
| Dask | Python批处理 | 类Pandas接口、轻量级、适合快速开发 | 中等规模数据处理、Python生态 | 分布式性能有限 |
| Celery | 任务队列 | 分布式任务队列、支持异步/定时任务 | 实时任务与批处理结合 | 依赖消息中间件(如RabbitMQ) |
2. 关键维度对比
| 维度 | Spring Batch | Apache Spark | Apache Airflow |
|---|---|---|---|
| 语言支持 | Java | 多语言(Scala/Python/Java) | Python/Java(通过插件) |
| 分布式能力 | 有限(需集群扩展) | 原生分布式 | 支持分布式任务调度 |
| 事务控制 | 细粒度(Chunk级) | 全局事务(需配合Flink) | 依赖底层工具(如Spark/Flink) |
| 可视化 | 无内置UI | 通过Spark UI | 内置Web UI查看DAG |
| 学习成本 | 中等(需熟悉Spring生态) | 高(需掌握分布式概念) | 中等(DAG设计) |
三、选择建议
-
Spring Batch 适用场景:
- Java生态:与Spring Boot/Spring Cloud深度集成。
- 中等规模数据:单机或小规模集群,需精细控制事务和分步处理。
- 企业级需求:需要重启、监控、事务回滚的稳定任务。
-
替代方案选择:
- 大数据量:Spark/Flink(Spark适合批处理,Flink适合流批一体)。
- 复杂调度:Airflow(可视化DAG管理跨系统任务)。
- 轻量级Python:Dask(快速开发,类Pandas接口)。
- 实时任务:Flink 或 Celery(结合Kafka触发)。
四、Spring Batch 最佳实践
-
性能优化:
- 调整
chunk size(如增大到500-1000条)。 - 使用
GridSize或MultiResourceItemReader并行读取文件。 - 启用
TaskExecutor实现多线程处理。
- 调整
-
监控与日志:
- 集成 Spring Boot Actuator 监控作业状态。
- 使用 ELK Stack 或 Prometheus 记录作业指标。
-
扩展性:
- 通过
Partitioner将作业分片到多节点(分布式处理)。 - 与 Airflow 集成,实现跨框架任务调度。
- 通过
五、总结表格
| 需求 | 推荐框架 |
|---|---|
| Java生态+精细事务控制 | Spring Batch |
| 大数据处理 | Apache Spark/Flink |
| 复杂任务调度 | Apache Airflow |
| 实时+批处理混合场景 | Apache Flink |
| 轻量级Python开发 | Dask |
如需具体场景的配置示例(如分布式分片、与Airflow集成),可进一步说明需求。
番外
以下是针对 Java 生态 中主流批处理框架的详细对比分析,涵盖核心功能、适用场景及优缺点:
一、核心 Java 批处理框架对比
1. Spring Batch
- 定位:企业级 Java 批处理框架,专注于复杂任务的事务管理和可恢复性。
- 核心特性:
- 分块处理(Chunk-based):读取 → 处理 → 写入的事务性分块模式。
- 事务控制:支持细粒度事务边界(如每100条提交一次)。
- 重启与恢复:通过
JobRepository记录状态,支持从断点恢复。 - 分布式扩展:通过分片(Partitioning)实现多节点并行处理。
- 适用场景:
- 企业级 Java 应用(如数据迁移、报表生成)。
- 需要事务控制、复杂分步处理的场景。
- 优缺点:
- 优点:与 Spring 生态深度集成,功能全面,学习曲线适中。
- 缺点:分布式性能有限,需额外配置集群。
2. Hadoop MapReduce
- 定位:传统分布式批处理框架,适合海量数据离线处理。
- 核心特性:
- 分布式计算:通过 Map(分片)和 Reduce(聚合)阶段处理数据。
- 容错性:基于 HDFS 存储,支持任务重试。
- 生态支持:与 Hadoop 生态(如 Hive、HBase)无缝集成。
- 适用场景:
- 大规模数据 ETL(如日志分析、数据仓库构建)。
- 需要与 Hadoop 生态整合的场景。
- 优缺点:
- 优点:成熟稳定,适合海量数据离线处理。
- 缺点:编程模型复杂,性能较低,学习成本高。
3. Apache Spark(Java SDK)
- 定位:高性能内存计算框架,支持 Java API 的大数据批处理。
- 核心特性:
- 内存加速:利用内存计算提升性能(比 Hadoop 快10-100倍)。
- DataFrame/Dataset API:提供类似 SQL 的数据处理能力。
- 流批一体:通过 Spark Streaming 支持实时+批处理。
- 适用场景:
- 大规模数据清洗、转换、聚合(如用户行为分析)。
- 需要快速迭代计算的场景(如机器学习预处理)。
- 优缺点:
- 优点:性能优异,支持丰富的数据格式(Parquet、JSON)。
- 缺点:需管理集群资源,分布式配置复杂。
4. Apache Flink(Java SDK)
- 定位:流批一体框架,Java API 支持复杂事件处理。
- 核心特性:
- 流批统一:通过相同 API 处理流数据和批数据。
- 状态管理:内置状态后端(如 RocksDB),支持高吞吐低延迟。
- Exactly-Once 语义:保证数据处理的精确一次。
- 适用场景:
- 需要流批混合处理的场景(如实时报表+离线分析)。
- 高并发、低延迟的批处理任务。
- 优缺点:
- 优点:流批统一,容错性强,适合复杂场景。
- 缺点:配置复杂,社区活跃度低于 Spark。
5. Quartz Scheduler
- 定位:任务调度框架,常用于简单批处理触发。
- 核心特性:
- 定时任务:支持 Cron 表达式定义任务执行时间。
- 分布式调度:通过集群模式实现高可用。
- 轻量级:适合简单任务调度。
- 适用场景:
- 触发其他批处理框架的任务(如定时启动 Spark 作业)。
- 独立的轻量级定时任务(如每日数据同步)。
- 优缺点:
- 优点:简单易用,Java 原生支持。
- 缺点:无数据处理能力,需结合其他框架。
6. Apache Beam(Java SDK)
- 定位:跨框架批流统一编程模型,支持多种执行引擎(如 Spark/Flink)。
- 核心特性:
- 统一 API:通过 Pipeline 定义任务,支持切换执行引擎。
- 可移植性:代码一次编写,可在不同后端运行。
- 复杂转换:支持窗口、状态管理等高级功能。
- 适用场景:
- 需要跨平台兼容性(如同时支持 Spark 和 Flink)。
- 复杂的数据转换逻辑。
- 优缺点:
- 优点:抽象层降低框架切换成本。
- 缺点:学习曲线陡峭,需理解底层引擎差异。
二、关键对比维度分析
1. 性能对比
| 框架 | 吞吐量 | 延迟 | 资源占用 |
|---|---|---|---|
| Spark | 高 | 中 | 高(内存密集) |
| Flink | 高 | 低 | 中 |
| Spring Batch | 中 | 高 | 低 |
| MapReduce | 低 | 高 | 高 |
| Quartz | 无 | 无 | 极低 |
2. 适用场景对比
| 需求 | 推荐框架 |
|---|---|
| 企业级 Java 事务控制 | Spring Batch |
| 大数据离线处理 | Spark |
| 流批一体处理 | Flink |
| 简单任务调度 | Quartz |
| 跨引擎兼容性 | Apache Beam |
3. 学习与生态
| 框架 | 学习成本 | 社区支持 | 生态集成 |
|---|---|---|---|
| Spring Batch | 中 | 高(Spring 生态) | 与 Spring Boot 深度集成 |
| Spark | 高 | 高 | 大数据生态(Hadoop/Kafka) |
| Flink | 高 | 中 | 流处理生态(Kubernetes) |
| Quartz | 低 | 中 | 独立调度,需结合其他框架 |
三、选择建议
-
优先选 Spring Batch:
- 场景:企业级 Java 应用、需要事务控制、与 Spring 生态整合。
- 示例:每日订单数据汇总、用户画像生成。
-
选择 Spark/Flink:
- 场景:海量数据处理(TB/PB 级)、需高性能计算。
- 示例:日志分析、用户行为统计。
-
使用 Quartz:
- 场景:简单定时任务触发(如每周数据备份)。
-
尝试 Apache Beam:
- 场景:需同时支持 Spark 和 Flink 的混合架构。
四、代码示例(Spring Batch 分片处理)
@Configuration
public class BatchConfig {@Beanpublic Step step(ItemReader<User> reader, ItemWriter<User> writer) {return steps.get("step").<User, User>chunk(100).reader(reader).writer(writer).build();}@Beanpublic Job job(Step step) {return jobs.get("job").start(step).build();}@Beanpublic Partitioner partitioner() {return new MultiResourcePartitioner(); // 分片读取多个文件}
}
五、总结
| 框架 | 最佳使用场景 | 避坑提示 |
|---|---|---|
| Spring Batch | 企业级 Java 应用、事务敏感型任务 | 避免处理 PB 级数据 |
| Spark | 大数据离线处理、需内存加速 | 需管理集群资源 |
| Flink | 流批一体、低延迟场景 | 配置复杂,需熟悉状态管理 |
| Quartz | 独立任务调度 | 无数据处理能力,需组合其他框架 |
如需具体场景的配置细节(如 Spark 集群部署、Flink 状态后端配置),可进一步说明需求。
以下是设计和开发一个类似 Spring Batch 的 Java 批处理框架的详细步骤和核心模块设计,涵盖架构设计、核心组件实现、扩展性及性能优化:
一、总体设计目标
-
核心目标:
- 支持 分块处理(Chunk-based) 和 任务(Tasklet) 模式。
- 提供 事务控制 和 作业状态管理(如重启、暂停、失败恢复)。
- 支持 分布式分片 和 多线程处理。
- 提供 监控与日志 功能(如作业进度、错误记录)。
-
设计原则:
- 模块化:核心组件可插拔(如数据源、处理器、存储)。
- 可扩展性:通过 SPI(Service Provider Interface)扩展算法或适配器。
- 轻量级:避免依赖复杂外部库,核心功能自包含。
二、核心组件设计
1. 作业(Job)
- 定义:批处理任务的顶层容器,由多个步骤(Step)组成。
- 关键接口:
public interface Job {JobExecution execute(JobParameters parameters); }public class SimpleJob implements Job {private List<Step> steps;@Overridepublic JobExecution execute(JobParameters parameters) {JobExecution execution = new JobExecution();for (Step step : steps) {StepExecution stepExecution = step.execute(parameters);execution.addStepExecution(stepExecution);if (stepExecution.getStatus() == Status.FAILED) {execution.setStatus(Status.FAILED);break;}}return execution;} }
2. 步骤(Step)
- 两种模式:
- 分块处理(Chunk-oriented):读取 → 处理 → 写入。
- 任务(Tasklet):自定义单步骤任务(如执行 SQL 脚本)。
- 核心接口:
public interface Step {StepExecution execute(JobParameters parameters); }public class ChunkStep implements Step {private ItemReader<?> reader;private ItemProcessor<?, ?> processor;private ItemWriter<?> writer;private int chunkSize;@Overridepublic StepExecution execute(JobParameters parameters) {StepExecution execution = new StepExecution();List items = new ArrayList<>(chunkSize);while (true) {Object item = reader.read();if (item == null) break;items.add(processor.process(item));if (items.size() == chunkSize) {writer.write(items);items.clear();}}if (!items.isEmpty()) writer.write(items);execution.setStatus(Status.COMPLETED);return execution;} }
3. 作业执行器(JobLauncher)
- 职责:启动作业并管理其生命周期。
- 实现:
public class SimpleJobLauncher {public JobExecution run(Job job, JobParameters parameters) {return job.execute(parameters);} }
4. 作业仓库(JobRepository)
- 职责:持久化作业状态(如数据库表记录)。
- 核心接口:
public interface JobRepository {void saveExecution(JobExecution execution);JobExecution getLastJobExecution(String jobName); }
5. 数据源与处理器
- ItemReader:从数据库、文件或消息队列读取数据。
- ItemProcessor:数据转换或过滤(如字段映射、数据清洗)。
- ItemWriter:批量写入结果(如数据库、文件)。
6. 事务管理
- 分块事务:每
chunkSize条数据提交一次事务。 - 实现:
@Transactional public void processChunk(List items) {// 处理并提交事务 }
三、扩展与优化
1. 分布式分片(Partitioning)
- 场景:将作业分片到多个节点并行处理。
- 实现步骤:
- 分片生成器:定义分片策略(如按文件分片、按数据库分页)。
- 分片执行器:通过
TaskExecutor并行执行分片任务。
public class Partitioner {public Map<String, ExecutionContext> partition(int gridSize) {Map<String, ExecutionContext> partitions = new HashMap<>();for (int i = 0; i < gridSize; i++) {ExecutionContext context = new ExecutionContext();context.putInt("partitionId", i);partitions.put("partition" + i, context);}return partitions;} }
2. 任务执行器(TaskExecutor)
- 多线程支持:通过
ThreadPoolTaskExecutor实现并行处理。 - 配置:
public class ThreadPoolTaskExecutor implements TaskExecutor {private ExecutorService executor;public void execute(Runnable task) {executor.submit(task);} }
3. 监控与日志
- 作业状态跟踪:通过
JobExecution记录进度、错误日志。 - 集成监控工具:如 Prometheus、ELK Stack。
- 实现:
public class JobExecution {private Status status;private List<StepExecution> stepExecutions;private Date startTime;private Date endTime;// getters/setters }
4. 异常处理与重试
- 重试机制:通过
RetryTemplate实现失败重试。 - 配置:
public class RetryTemplate {public void executeWithRetry(RetryCallback callback) {int retryCount = 0;while (retryCount < maxAttempts) {try {callback.doWithRetry();break;} catch (Exception e) {retryCount++;}}} }
四、架构设计图(文字描述)
五、实现步骤
1. 模块划分
| 模块 | 职责 |
|---|---|
| core | 核心接口与基础实现(Job/Step/Item) |
| repository | 作业状态持久化(数据库/内存) |
| executor | 任务调度与并行执行 |
| monitor | 作业监控与日志 |
| extensions | 扩展模块(如分片、重试、适配器) |
2. 开发流程
- 定义核心接口:Job、Step、ItemReader/Processor/Writer。
- 实现基础组件:SimpleJob、ChunkStep、Tasklet。
- 集成事务管理:通过
@Transactional或手动管理。 - 实现分片与并行:Partitioner + TaskExecutor。
- 持久化状态:JobRepository 的数据库实现。
- 添加监控与日志:记录作业执行状态。
- 测试与优化:压力测试、性能调优(如分块大小、线程池配置)。
3. 示例代码结构
// 定义作业
public class MyJob implements Job {@Overridepublic JobExecution execute(JobParameters parameters) {Step step = new ChunkStep().reader(new DatabaseReader()).processor(new DataTransformer()).writer(new FileWriter()).chunkSize(100);return step.execute(parameters);}
}// 启动作业
public class Main {public static void main(String[] args) {JobLauncher launcher = new SimpleJobLauncher();Job job = new MyJob();JobExecution execution = launcher.run(job, new JobParameters());}
}
六、性能优化建议
- 分块大小优化:
- 根据数据量和内存容量调整
chunkSize(如 100-1000 条)。
- 根据数据量和内存容量调整
- 并行处理:
- 使用
ThreadPoolTaskExecutor并行执行步骤或分片。
- 使用
- 资源管理:
- 避免在
ItemReader中频繁打开/关闭数据库连接。
- 避免在
- 缓存中间结果:
- 对于重复计算的数据(如字典映射),使用内存缓存。
七、常见问题与解决方案
1. 作业状态丢失
- 原因:未实现
JobRepository持久化。 - 解决:集成数据库存储(如 MySQL、H2)。
2. 分片数据不均衡
- 原因:分片策略不合理(如固定分片数)。
- 解决:动态分片(如按数据总量分配)。
3. 事务性能瓶颈
- 原因:过大的分块导致事务提交耗时。
- 解决:调整分块大小或使用更高效的数据库索引。
八、总结
通过以上步骤,可以逐步构建一个具备核心功能的批处理框架。关键点在于:
- 模块化设计:将作业、步骤、数据处理分离。
- 事务与状态管理:确保作业的可恢复性。
- 扩展性:通过 SPI 或插件机制支持自定义组件。
如需进一步优化(如与 Spring Boot 集成、支持流处理),可参考 Spring Batch 的实现细节并逐步扩展。
相关文章:
关于 Spring Batch 的详细解析及其同类框架的对比分析,以及如何自己设计一个java批处理框架(类似spring batch)的步骤
以下是关于 Spring Batch 的详细解析及其同类框架的对比分析: 一、Spring Batch 核心详解 1. 核心概念 作业(Job):批处理任务的顶层容器,由多个步骤(Step)组成。 步骤(Step&#…...

【Java面试系列】Spring Cloud微服务架构中的分布式事务实现与性能优化详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Cloud微服务架构中的分布式事务实现与性能优化详解 - 3-5年Java开发必备知识 引言 在微服务架构中,分布式事务是一个不可避免的挑战。随着业务复杂度的提升,如何保证跨服务的数据一致性成为面试中的高频问题。本文将从基础到进…...

【第十三届“泰迪杯”数据挖掘挑战赛】【2025泰迪杯】【论文篇+改进】A题解题全流程(持续更新)
【第十三届“泰迪杯”数据挖掘挑战赛】【2025泰迪杯】【论文篇改进】A题解题全流程(持续更新) 写在前面: 我是一个人,没有团队,所以出的比较慢,每年只做一次赛题,泰迪杯,我会认真对…...
)
Linux系统常见磁盘扩容操作(Common Disk Expansion Operations in Linux Systems)
Linux系统常见磁盘扩容操作 目录说明 一、准备工作:获取目标磁盘信息 (1)确认分区表格式和文件系统 二、扩容已有MBR分区 (1)分区后扩容 ext为例 xfs为例 三、扩容已有GPT分区 (1)分区…...

数据结构——哈希详解
数据结构——哈希详解 目录 一、哈希的定义 二、六种哈希函数的构造方法 2.1 除留取余法 2.2 平方取中法 2.3 随机数法 2.4 折叠法 2.5 数字分析法 2.6 直接定值法 三、四种解决哈希冲突的方法 3.1 开放地址法 3.1.1 线性探测法 3.1.2 二次探测法 3.2 链地址法 3…...
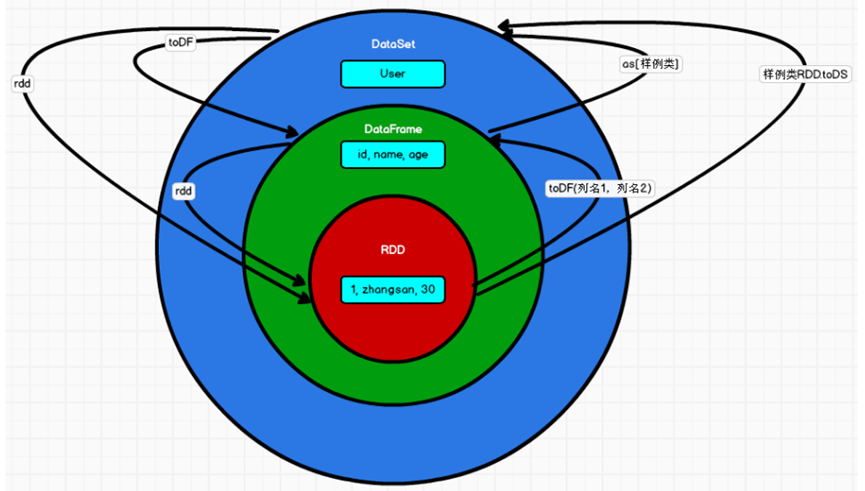
Spark-SQL核心编程
简介 Hadoop与Spark-SQL的对比 Hadoop在处理结构化数据方面存在局限性,无法有效处理某些类型的数据。 Spark应运而生,特别设计了处理结构化数据的模块,称为Spark SQL(原称Shark)。 SparkSQL的发展历程: Sp…...

pywebview 常用问题分享
文章目录 前言问题描述与方案(待补充)1、动态设置本地调试目录和打包目录2、构建后运行程序白屏 前言 最近做一个pywebview项目,遇到了一些问题,记录一下,分享给大家,希望能帮助有遇到相似问题的人事。 问题描述与方案(待补充) …...
))
系统设计模块之安全架构设计(身份认证与授权(OAuth2.0、JWT、RBAC/ABAC))
一、OAuth 2.0:开放授权框架 OAuth 2.0 是一种标准化的授权协议,允许第三方应用在用户授权下访问其资源,而无需直接暴露用户密码。其核心目标是 分离身份验证与授权,提升安全性与灵活性。 1. 核心概念与流程 角色划分ÿ…...
Docker 与 Podman常用知识汇总
一、常用命令的对比汇总 1、基础说明 Docker:传统的容器引擎,使用 dockerd 守护进程。 Podman:无守护进程、无root容器引擎,兼容 Docker CLI。 Podman 命令几乎完全兼容 Docker 命令,只需将 docker 替换为 podman。…...

如何通过自动化解决方案提升企业运营效率?
引言 在现代企业中,运营效率直接影响着企业的成本、速度与竞争力。尤其是随着科技的不断发展,传统手工操作和低效的流程逐渐无法满足企业的需求。自动化解决方案正成为企业提升运营效率、降低成本和提高生产力的关键。无论是大型跨国公司,还…...

unity100天学习计划
以下是一个为期100天的Unity学习大纲,涵盖从零基础到独立开发完整游戏的全流程,结合理论、实践和项目实战,每天学习2-3小时: 第一阶段:基础奠基(Day 1-20) 目标:掌握Unity引擎基础与C#编程 Day 1-5:引擎入门 安装Unity Hub和Unity Editor(LTS版本)熟悉Unity界面:S…...

多坐标系变换全解析:从相机到WGS-84的空间坐标系详解
多坐标系变换全解析:从相机到WGS-84的空间坐标系详解 一、常见坐标系简介二、各坐标系的功能和使用场景1. WGS-84 大地坐标系(经纬高)2. 地心直角坐标系(ECEF)3. 本地 ENU / NED 坐标系4. 平台坐标系(Body)5. 相机坐标系三、坐标变换流程图四、如何选用合适的坐标系?五…...

SpringCloud Alibaba 之分布式全局事务 Seata 原理分析
1. 什么是 Seata?为什么需要它? 想象一下,你去银行转账: 操作1:从你的账户扣款 1000 元操作2:向对方账户增加 1000 元 如果 操作1 成功,但 操作2 失败了,你的钱就凭空消失了&…...
)
作业帮前端面试题及参考答案 (100道面试题-上)
HTML5 的优势是什么? HTML5 作为 HTML 语言的新一代标准,具有众多显著优势,为现代网页开发带来了诸多便利与革新。 在语义化方面,HTML5 引入了大量具有明确语义的标签,如<header>、<nav>、<article>、<section>、<aside>、<footer>等…...

Large Language Model(LLM)的训练和微调
之前一个偏工程向的论文中了,但是当时对工程理论其实不算很了解,就来了解一下 工程流程 横轴叫智能追寻 竖轴上下文优化 Prompt不行的情况下加shot(提示),如果每次都要加提示,就可以试试知识库增强检索来给提示。 如果希望增强…...

统计销量前十的订单
传入参数: 传入begin和end两个时间 返回参数 返回nameList和numberList两个String类型的列表 controller层 GetMapping("/top10")public Result<SalesTop10ReportVO> top10(DateTimeFormat(pattern "yyyy-MM-dd") LocalDate begin,Dat…...
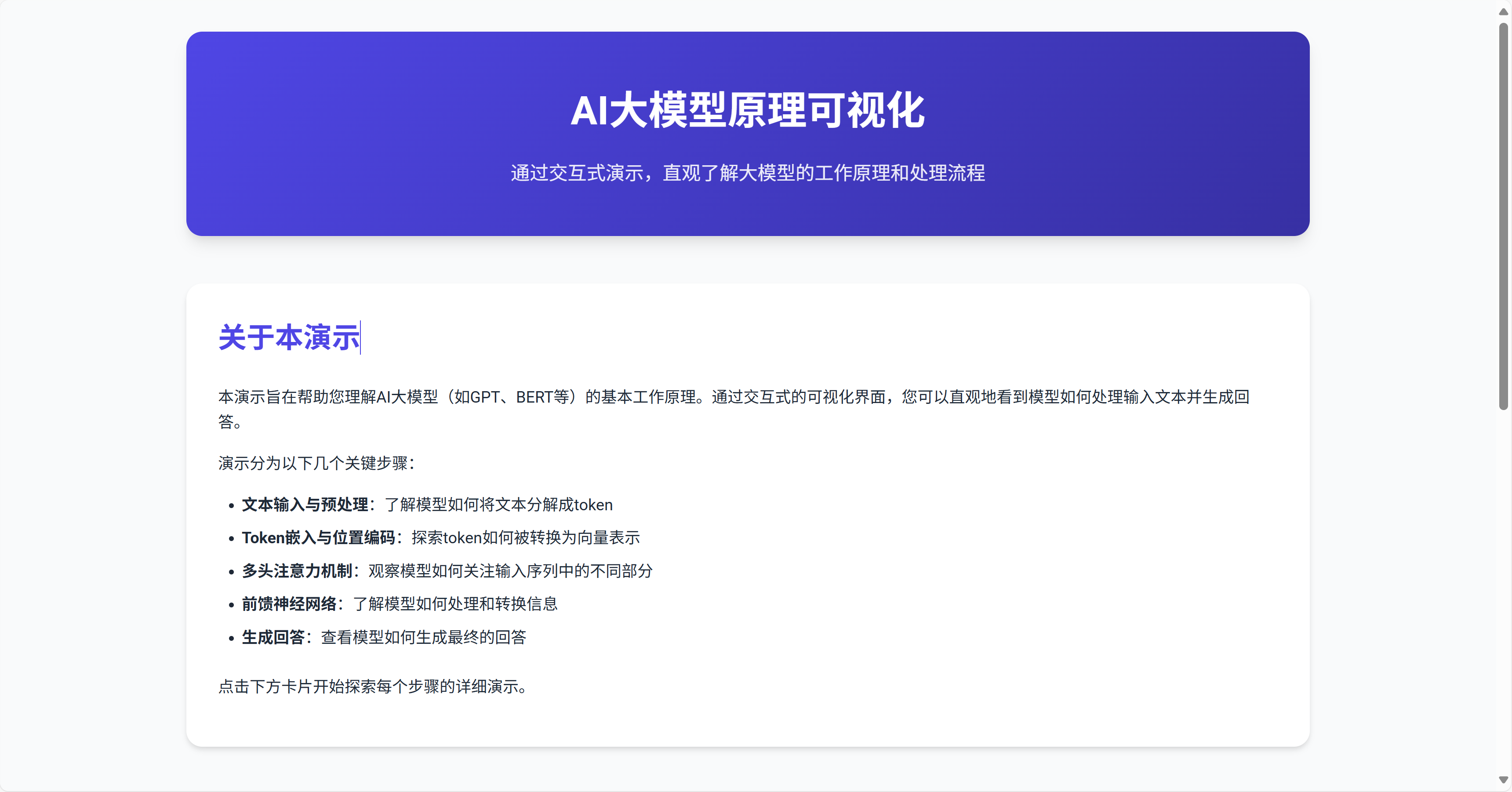
AI大模型原理可视化工具:深入浅出理解大语言模型的工作原理
AI大模型原理可视化工具:深入浅出理解大语言模型的工作原理 在人工智能快速发展的今天,大语言模型(如GPT、BERT等)已经成为改变世界的重要技术。但对于很多人来说,理解这些模型的工作原理仍然是一个挑战。为了帮助更多…...

MCP 认证考试常见技术难题实战分析与解决方案
MCP(Microsoft Certified Professional)认证考试在全球范围内被广泛认可,是衡量个人在微软技术领域专业能力的重要标准。然而,在备考和参加 MCP 认证考试过程中,考生常常会遇到各种技术难题。以下将对一些常见技术难题进行实战分析,并提供相应的解决方案。 一、网络配…...
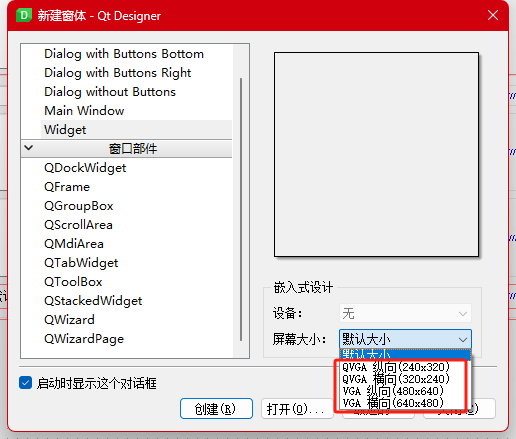
qt designer 创建窗体选择哪种屏幕大小
1. 新建窗体时选择QVGA还是VGA 下面这个图展示了区别 这里我还是选择默认,因为没有特殊需求,只是在PC端使用...

Spark-SQL核心编程(一)
一、Spark-SQL 基础概念 1.定义与起源:Spark SQL 是 Spark 用于结构化数据处理的模块,前身是 Shark。Shark 基于 Hive 开发,提升了 SQL-on-Hadoop 的性能,但因对 Hive 依赖过多限制了 Spark 发展,后被 SparkSQL 取代&…...

Android WiFi获取动态IP地址
Android开发中获取WiFi动态IP地址可通过以下方法实现,需结合网络状态管理和API调用: 一、权限配置 在AndroidManifest.xml中添加必要权限: <uses-permission android:name"android.permission.ACCESS_WIFI_STATE" /> <…...
)
正则表达式使用知识(日常翻阅)
正则表达式使用 一、字符匹配 1. 普通字符 描述:直接匹配字符本身。示例: abc 匹配字符串中的 “abc”。Hello 匹配字符串中的 “Hello”。 2. 特殊字符 .(点号): 描述:匹配任意单个字符(…...
AI与无人驾驶汽车:如何通过机器学习提升自动驾驶系统的安全性?
引言 想象一下,在高速公路上,一辆无人驾驶汽车正平稳行驶。突然,前方的车辆紧急刹车,而旁边车道有一辆摩托车正快速接近。在这千钧一发的瞬间,自动驾驶系统迅速分析路况,判断最安全的避险方案,精…...

第5篇:Linux程序访问控制FPGA端LEDR<三>
Q:如何具体设计.c程序代码访问控制FPGA端外设? A:以控制DE1-SoC开发板的LEDR为例的Linux .C程序代码。头文件fcntl.h和sys/mman.h用于使用/dev/mem文件,以及mmap和munmap内核函数;address_map_arm.h指定了DE1-SoC_Com…...

城市应急安防系统EasyCVR视频融合平台:如何实现多源视频资源高效汇聚与应急指挥协同
一、方案背景 1)项目背景 在当今数字化时代,随着信息技术的飞速发展,视频监控和应急指挥系统在公共安全、城市应急等领域的重要性日益凸显。尤其是在关键场所,高效的视频资源整合与传输能力对于应对突发公共事件、实现快速精准的…...

主流程序员接单平台的分类整理与分析
一、主流推荐平台 1.程序员客栈 特点:国内知名度高,需求池模式自动匹配项目,项目经理介入协调争议,流程规范。 优势:适合新手到资深开发者,资金托管安全性高,交易纠纷处理专业。 不足&…...
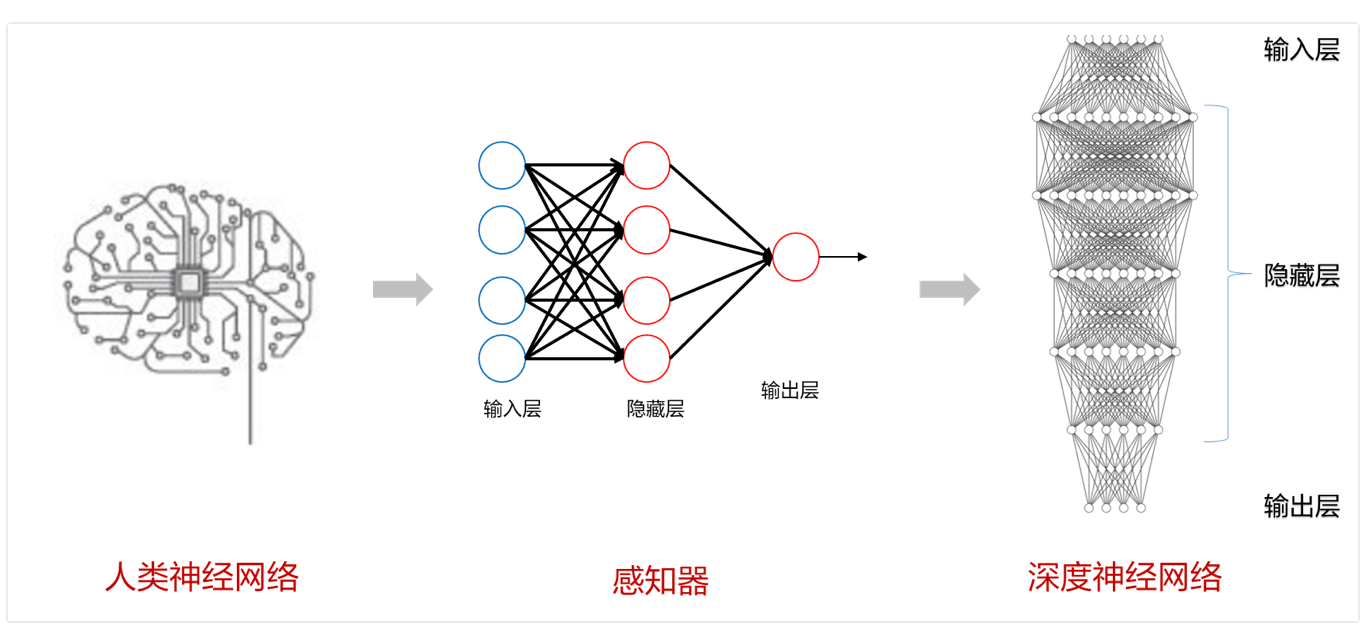
【笔记ing】AI大模型-03深度学习基础理论
神经网络:A neural network is a network or circuit of neurons,or in a modern sense,an artificial neural network,composed of artificial neurons or nodes.神经网络是神经元的网络或回路,或者在现在意义上来说,是一个由人工神经元或节…...

Hutool工具包中`copyProperties`和`toBean`的区别
前言 在Java开发中,对象转换是一项常见且重要的操作。Hutool作为一个功能强大的Java工具包,提供了copyProperties和toBean这两个实用的方法来帮助我们进行对象转换。然而,很多开发者对这两个方法的区别和使用场景并不十分清楚。 一、Hutool…...

高德地图 JS-SDK 实现教程
高德地图 JS-SDK 实现教程:定位、地图选点、地址解析等 适用地点选择、地址显示、表单填写等场景,全面支持移动端、手机浏览器和 PC端环境 一、创建应用&Key 前端(JS-SDK、地图组件) 登陆 高德开放平台创建应用,…...

07软件测试需求分析案例-修改用户信息
修改用户信息是后台管理菜单的一个功能模块,只有admin才有修改权限。包括查询用户名进行显示用户相关信息,并且修改用户相关信息的功能。 1.1 通读文档 通读需求规格说明书是提取信息,提出问题,输出具有逻辑、规则、流程的业务…...