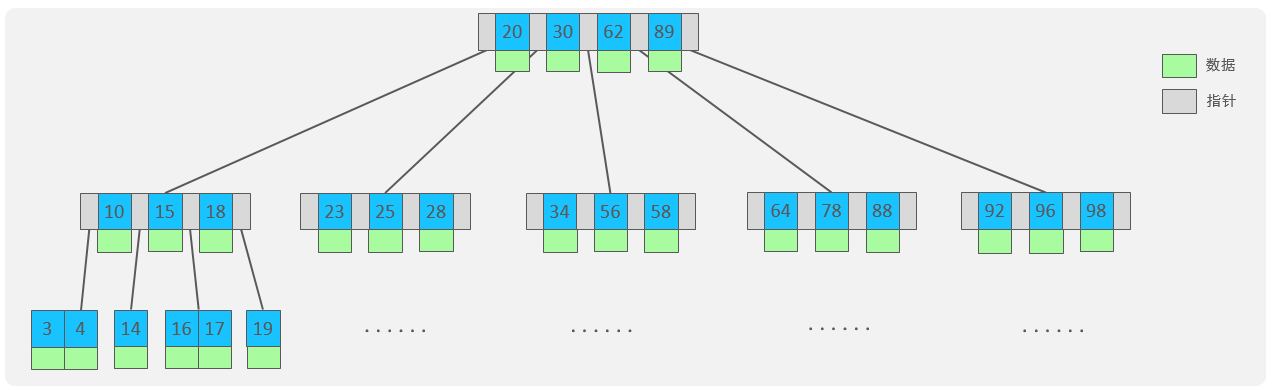
MySQL-存储引擎索引
存储引擎
MySQL体系结构
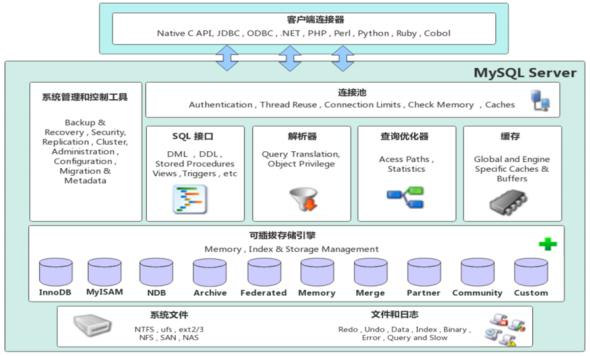
1). 连接层
最上层是一些客户端和链接服务,包含本地sock 通信和大多数基于客户端/服务端工具实现的类似于 TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程 池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
2). 服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询, SQL的分析和优化,部 分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。在该层, 服务器会解 析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利用索引等, 最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存,如果缓存空间足够大, 这样在解决大量读操作的环境中能够很好的提升系统的性能。
3). 引擎层
存储引擎层, 存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通 信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。数据库 中的索引是在存储引擎层实现的。
4). 存储层
数据存储层, 主要是将数据(如 : redolog、 undolog、数据、索引、二进制日志、错误日志、查询 日志、慢查询日志等)存储在文件系统之上,并完成与存储引擎的交互。
和其他数据库相比, MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎上,插件式的存储引擎架构,将查询处理和其他的系统任务以及数据的存储提取分离。 这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
存储引擎介绍

大家可能没有听说过存储引擎,但是一定听过引擎这个词,引擎就是发动机,是一个机器的核心组件。 比如,对于舰载机、直升机、火箭来说,他们都有各自的引擎,是他们最为核心的组件。而我们在选择 引擎的时候,需要在合适的场景,选择合适的存储引擎,就像在直升机上,我们不能选择舰载机的引擎 一样。
而对于存储引擎,也是一样,他是mysql数据库的核心,我们也需要在合适的场景选择合适的存储引 擎。接下来就来介绍一下存储引擎。
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是 基于库的,所以存储引擎也可被称为表类型。我们可以在创建表的时候,来指定选择的存储引擎,如果 没有指定将自动选择默认的存储引擎。
1). 建表时指定存储引擎
CREATE TABLE 表名 (
字段1 字段1类型 [ COMMENT 字段1注释 ],
......
字段n 字段n类型 [COMMENT 字段n注释 ]
) ENGINE = INNODB [ COMMENT 表注释 ] ;
2). 查询当前数据库支持的存储引擎
show engines;

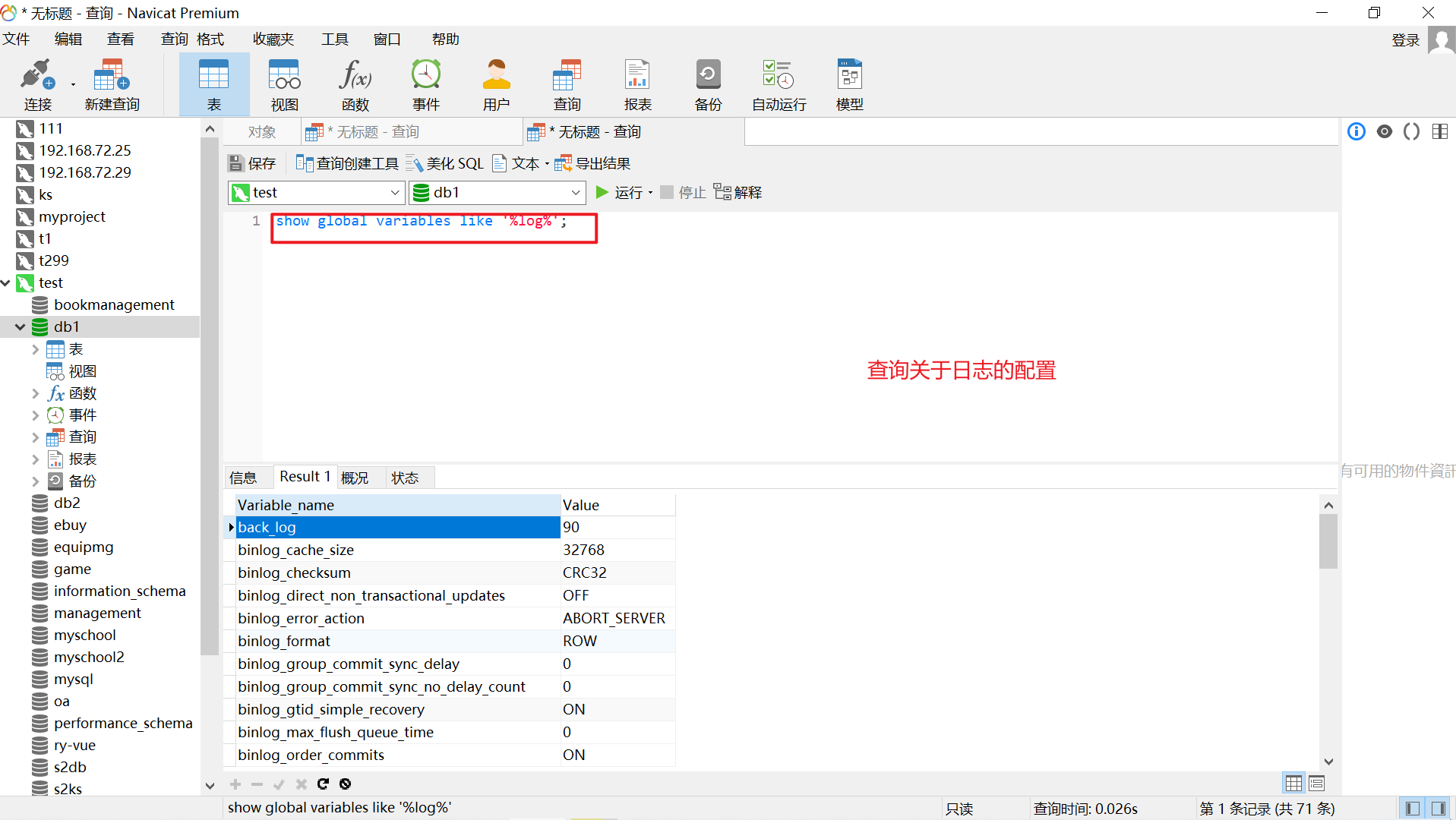
示例演示 :
A. 查询建表语句 --- 默认存储引擎 : InnoDB
create table dept(
id int auto_increment comment 'ID' primary key,
name varchar(50) not null comment '部门名称'
)comment '部门表';show create table dept;
可以看到,创建表时,即使我们没有指定存储疫情,数据库也会自动选择默认的存储引擎。
B.创建表 my_myisam , 并指定MyISAM存储引擎
create table my_myisam(
id int,
name varchar (10)
) engine = myisam ;
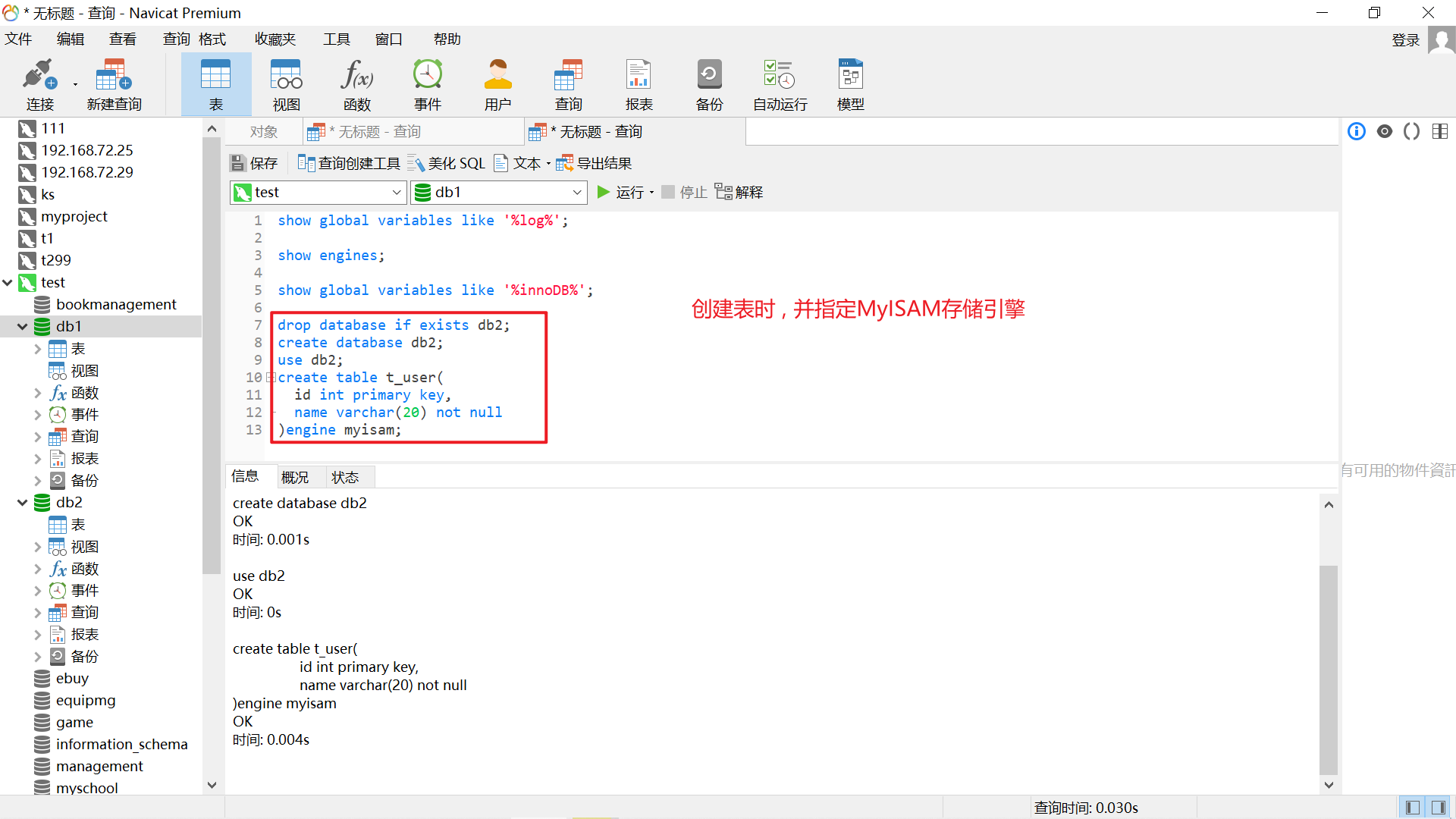
C.创建表 my_memory , 指定Memory存储引擎
create table my_memory (
id int,
name varchar (10)
) engine = Memory ;
存储引擎特点
上面我们介绍了什么是存储引擎,以及如何在建表时如何指定存储引擎,接下来我们就来介绍下来上面 重点提到的三种存储引擎 InnoDB、 MyISAM、 Memory的特点。
InnoDB
1). 介绍
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在 MySQL 5.5 之后, InnoDB是默认的 MySQL 存储引擎。
2). 特点
-
DML操作遵循ACID模型,支持事务;
-
行级锁,提高并发访问性能;
-
支持外键FOREIGN KEY约束,保证数据的完整性和正确性;
3). 文件
xxx.ibd: xxx代表的是表名, innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结 构( frm-早期的 、 sdi-新版的)、数据和索引。
参数: innodb_file_per_table
show variables like 'innodb_file_per_table ';
如果该参数开启,代表对于InnoDB引擎的表,每一张表都对应一个ibd文件。 我们直接打开MySQL的数据存放目录:/var/lib/mysql , 这个目录下有很多文件夹,不同的文件夹代表不同的数据库,我们直接打开db2文件夹。
[root@localhost db2]# ll
总用量 248
-rw-r-----. 1 mysql mysql 67 10月 30 08:18 db.opt
-rw-r-----. 1 mysql mysql 8600 10月 30 08:20 dept.frm
-rw-r-----. 1 mysql mysql 98304 10月 30 08:26 dept.ibd
-rw-r-----. 1 mysql mysql 8672 10月 30 08:25 emp.frm
-rw-r-----. 1 mysql mysql 98304 10月 30 08:26 emp.ibd
-rw-r-----. 1 mysql mysql 8586 10月 30 08:31 my_memory.frm
-rw-r-----. 1 mysql mysql 8586 10月 30 08:30 my_myisam.frm
-rw-r-----. 1 mysql mysql 0 10月 30 08:30 my_myisam.MYD
-rw-r-----. 1 mysql mysql 1024 10月 30 08:30 my_myisam.MYI
可以看到里面有很多的ibd文件,每一个ibd文件就对应一张表,比如:我们有一张表 emp,就有这样的一个emp.ibd文件,而在这个ibd文件中不仅存放表结构、数据,还会存放该表对应的索引信息。
frm的意思为“表定义”,是描述数据表结构的文件。frm文件是用来保存每个数据表的元数据信息,包括表结构的定义等。frm文件跟数据库存储引擎无关,也就是任何存储引擎的数据表都必须有frm文件,命名方式为“数据表名.frm”。
4). 逻辑存储结构
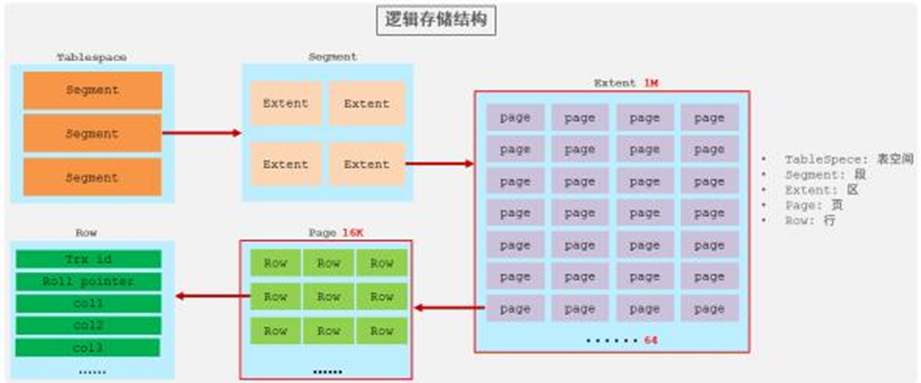
-
表空间 : InnoDB存储引擎逻辑结构的最高层, ibd文件其实就是表空间文件,在表空间中可以包含多个Segment段。
-
段 : 表空间是由各个段组成的, 常见的段有数据段、索引段、回滚段等。 InnoDB中对于段的管理,都是引擎自身完成,不需要人为对其控制,一个段中包含多个区。
-
区 : 区是表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
-
页 : 页是组成区的最小单元, 页也是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性, InnoDB 存储引擎每次从磁盘申请 4-5 个区。
-
行 : InnoDB 存储引擎是面向行的,也就是说数据是按行进行存放的,在每一行中除了定义表时所指定的字段以外,还包含两个隐藏字段(后面会详细介绍)。
MyISAM
1). 介绍
MyISAM是MySQL早期的默认存储引擎。
2). 特点
-
不支持事务,不支持外键
-
支持表锁,不支持行锁
-
访问速度快
3). 文件
xxx.frm(xxx.sdi):存储表结构信息
xxx.MYD: 存储数据
xxx.MYI: 存储索引

Memory
1). 介绍
Memory引擎的表数据时存储在内存中的,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。
2). 特点
-
内存存放
-
hash索引(默认)
3).文件
xxx.frm(xxx.sdi):存储表结构信息
区别及特点
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持 | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
面试题 :
InnoDB引擎与MyISAM引擎的区别 ?
① . InnoDB引擎 , 支持事务 , 而MyISAM不支持。
② . InnoDB引擎 , 支持行锁和表锁 , 而MyISAM仅支持表锁 , 不支持行锁。
③ . InnoDB引擎 , 支持外键 , 而MyISAM是不支持的。
存储引擎选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据 实际情况选择多种存储引擎进行组合。
-
InnoDB: 是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
-
MyISAM : 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
-
MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。 MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
索引
索引概述
介绍
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足 特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构 上实现高级查找算法,这种数据结构就是索引。

一提到数据结构,大家都会有所担心,担心自己不能理解,跟不上节奏。不过在这里大家完全不用担 心,我们后面在讲解时,会详细介绍。
演示
表结构及其数据如下:
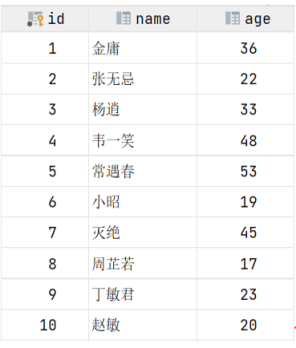
假如我们要执行的SQL语句为 : select * from user where age = 45;
1). 无索引情况
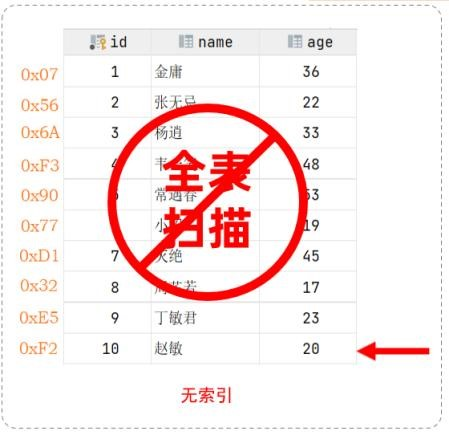
在无索引情况下,就需要从第一行开始扫描,一直扫描到最后一行,我们称之为全表扫描,性能很低。
2). 有索引情况
如果我们针对于这张表建立了索引,假设索引结构就是二叉树,那么也就意味着,会对age这个字段建 立一个二叉树的索引结构。

此时我们在进行查询时,只需要扫描三次就可以找到数据了,极大的提高的查询的效率。
特点
| 优势 | 劣势 |
|---|---|
| 提高数据检索的效率,降低数据库 的IO成本 | 索引列也是要占用空间的。 |
| 通过索引列对数据进行排序,降低 数据排序的成本,降低CPU的消耗。 | 索引大大提高了查询效率,同时却也降低更新表的速度, 如对表进行INSERT、 UPDATE、 DELETE时,效率降低。 |
索引结构
概述
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持 B+ 树索引 |
| Hash索引 | 底层数据结构是用哈希表实现的 , 只有精确匹配索引列的查询才有效 , 不 支持范围查询 |
| R-tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类 型,通常使用较少 |
| Full-text(全文索引 ) | 是一种通过建立倒排索引 ,快速匹配文档的方式。类似于 Lucene,Solr,ES |
上述是MySQL中所支持的所有的索引结构,接下来,我们再来看看不同的存储引擎对于索引结构的支持 情况。
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
二叉树
假如说MySQL的索引结构采用二叉树的数据结构,比较理想的结构如下:
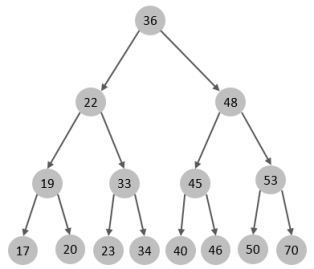
如果主键是顺序插入的,则会形成一个单向链表,结构如下:

所以,如果选择二叉树作为索引结构,会存在以下缺点:
-
顺序插入时,会形成一个链表,查询性能大大降低。
-
大数据量情况下,层级较深,检索速度慢。
此时大家可能会想到,我们可以选择红黑树,红黑树是一颗自平衡二叉树,那这样即使是顺序插入数 据,最终形成的数据结构也是一颗平衡的二叉树 ,结构如下 :
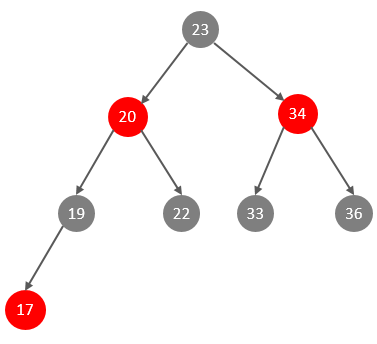
但是,即使如此,由于红黑树也是一颗二叉树,所以也会存在一个缺点:
-
大数据量情况下,层级较深,检索速度慢。
所以,在MySQL的索引结构中,并没有选择二叉树或者红黑树,而选择的是B+Tree,那么什么是 B+Tree呢?在详解B+Tree之前,先来介绍一个B-Tree。
B-Tree
B-Tree, B树是一种多叉路衡查找树,相对于二叉树, B树每个节点可以有多个分支,即多叉。以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key,5个指针:
知识小贴士: 树的度数指的是一个节点的子节点个数
数据结构可视化的网站。B-Tree Visualization

插入一组数据: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88 120 268 250 。然后观察一些数据插入过程中,节点的变化情况。
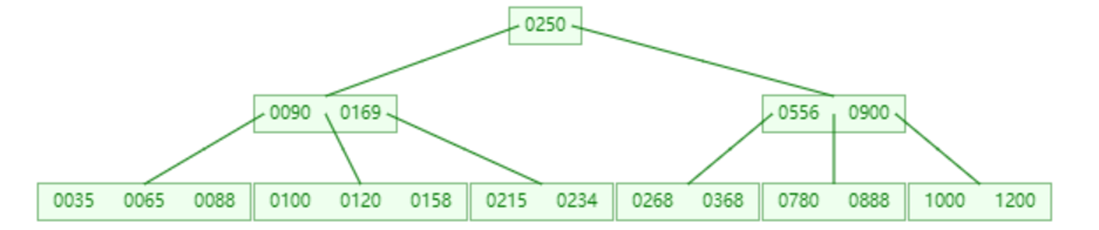
特点:
-
5阶的B树,每一个节点最多存储4个key,对应5个指针。
-
一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂。
-
在B树中,非叶子节点和叶子节点都会存放数据。
B+Tree
B+Tree是B-Tree的变种,我们以一颗最大度数(max-degree)为4 (4阶)的b+tree为例,来看一 下其结构示意图:
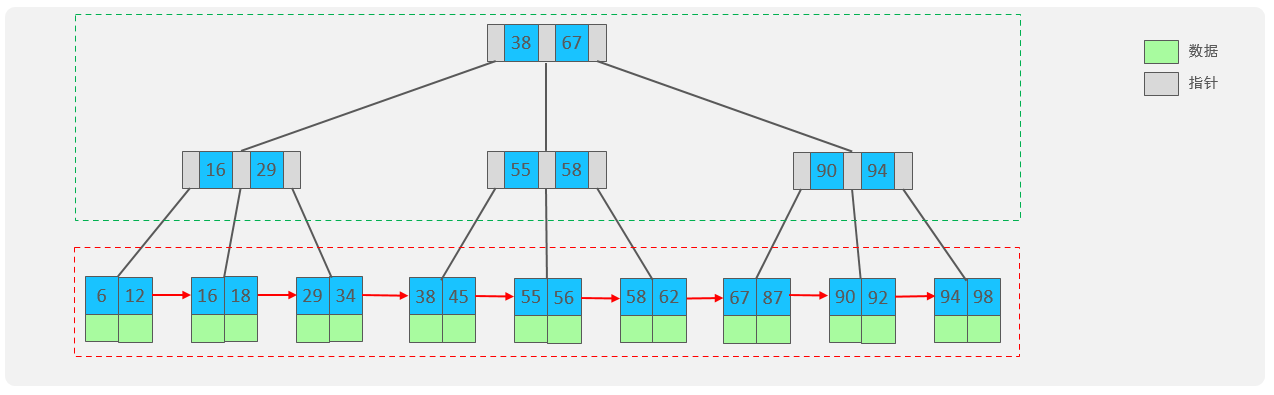
我们可以看到,两部分:
-
绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
-
红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
数据结构可视化的网站来。 B+ Tree Visualization

-
插入一组数据: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88 120 268 250 。然后观察一些数据插入过程中,节点的变化情况。
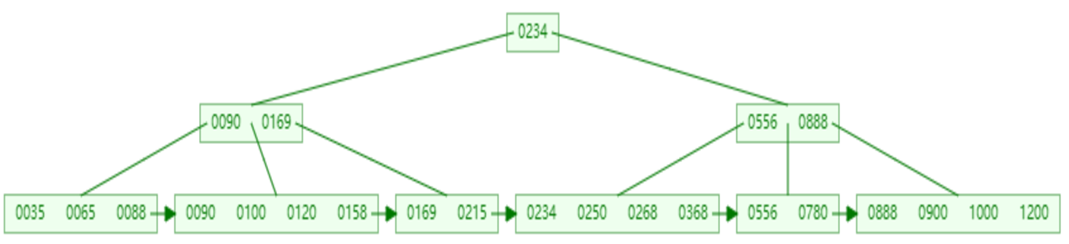
最终我们看到, B+Tree 与 B-Tree相比,主要有以下三点区别:
-
所有的数据都会出现在叶子节点。
-
叶子节点形成一个单向链表。
-
非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
上述我们所看到的结构是标准的B+Tree的数据结构,接下来,我们再来看看MySQL中优化之后的 B+Tree。
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点 的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。
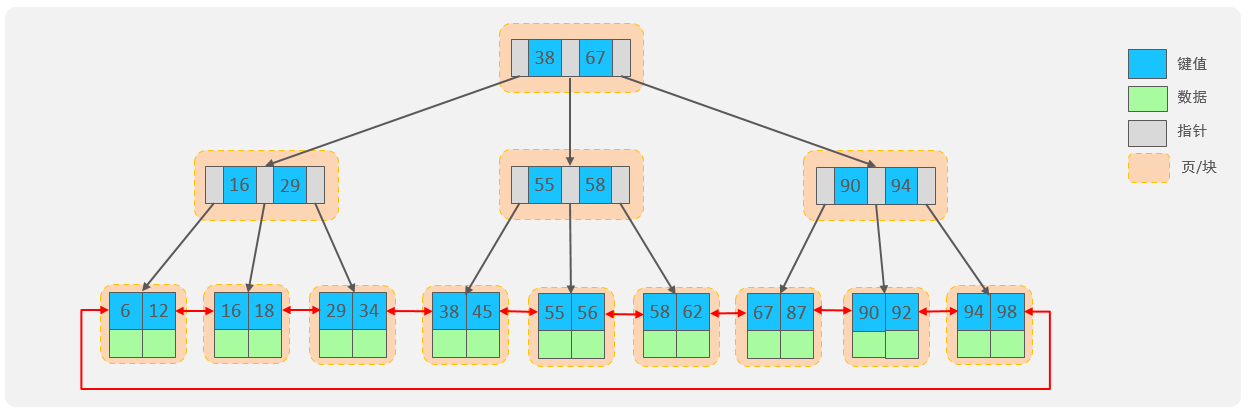
Hash
MySQL中除了支持B+Tree索引,还支持一种索引类型---Hash索引。
1). 结构
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
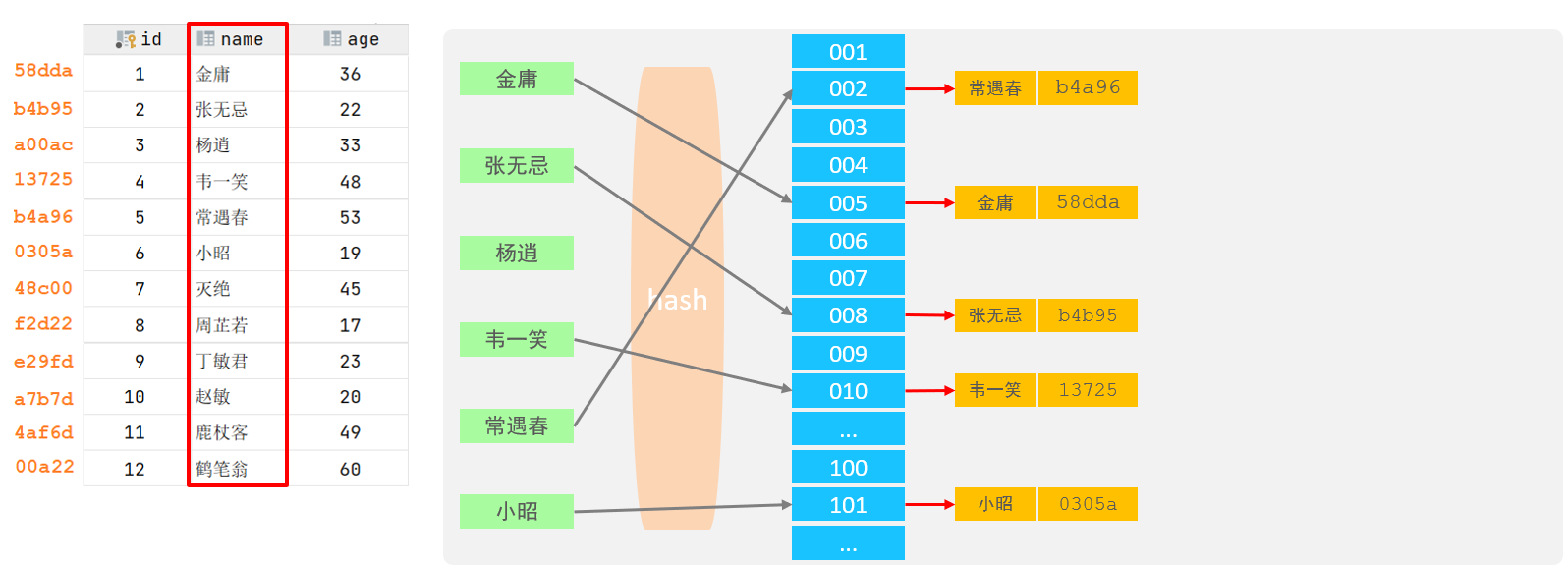
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可 以通过链表来解决。
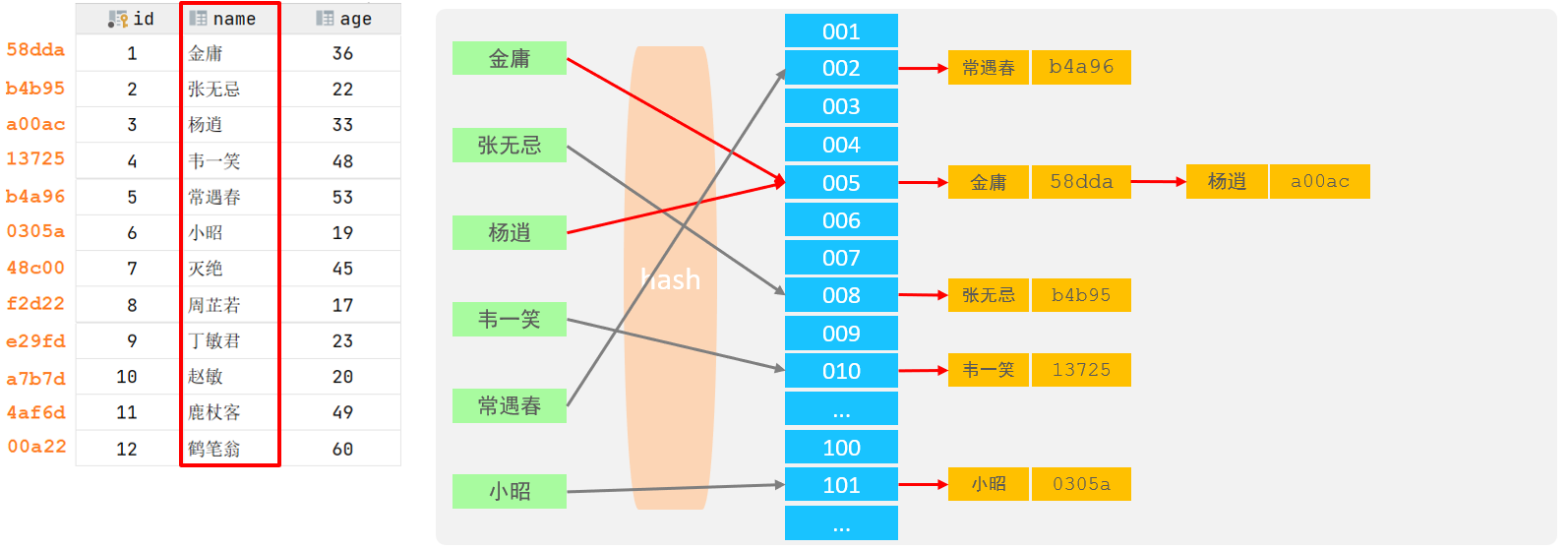
2). 特点
A. Hash索引只能用于对等比较 (=, in),不支持范围查询(between, >, < , ...)
B. 无法利用索引完成排序操作
C. 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索 引
3). 存储引擎支持
在MySQL中,支持hash索引的是Memory存储引擎。 而InnoDB中具有自适应hash功能, hash索引是 InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
思考题: 为什么InnoDB存储引擎选择使用B+tree索引结构?
A. 相对于二叉树,层级更少,搜索效率高; B. 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低; C. 相对Hash索引,B+tree支持范围匹配及排序操作;
索引分类
索引分类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建 , 只能 有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比 较索引中的值 | 可以有多个 | FULLTEXT |
聚集索引&二级索引
而在在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 (Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有 ,而且只 有一个 |
| 二级索引 (Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关 联的是对应的主键 | 可以存在多个 |
聚集索引选取规则 :
-
如果存在主键,主键索引就是聚集索引。
-
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
-
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索 引。
聚集索引和二级索引的具体结构如下:

-
聚集索引的叶子节点下挂的是这一行的数据 。
-
二级索引的叶子节点下挂的是该字段值对应的主键值。
接下来,我们来分析一下,当我们执行如下的SQL语句时,具体的查找过程是什么样子的。
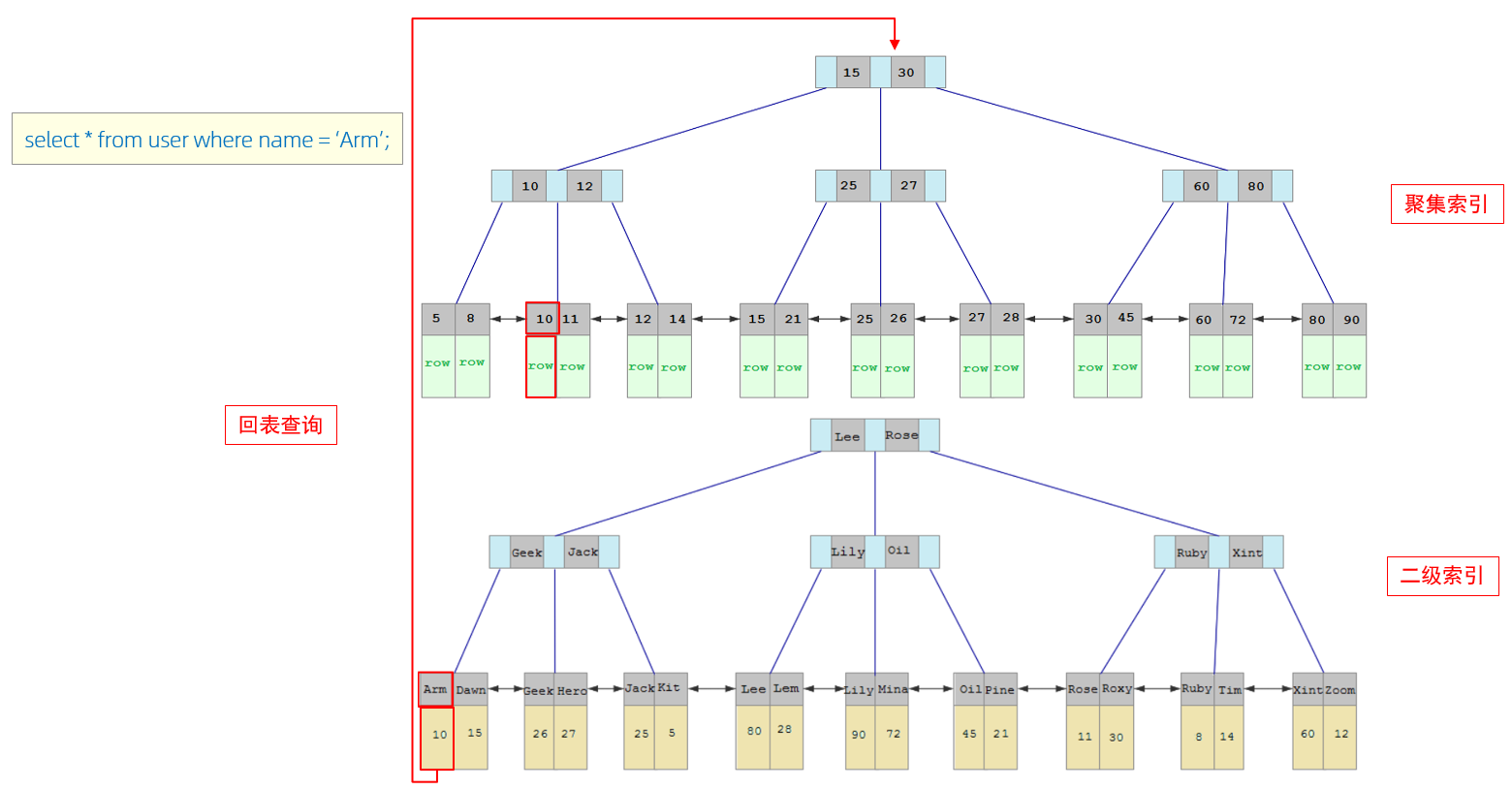
具体过程如下 :
① . 由于是根据name字段进行查询,所以先根据name='Arm'到name字段的二级索引中进行匹配查 找。但是在二级索引中只能查找到 Arm 对应的主键值 10。
② . 由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最 终找到10对应的行row。
③ . 最终拿到这一行的数据,直接返回即可。
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
思考题: 以下两条SQL语句,那个执行效率高? 为什么? A. select * from user where id = 10 ; B. select * from user where name = 'Arm' ; 备注: id为主键,name字段创建的有索引; 解答: A 语句的执行性能要高于B 语句。 因为A语句直接走聚集索引,直接返回数据。 而B语句需要先查询name字段的二级索引,然 后再查询聚集索引,也就是需要进行回表查询。
思考题: InnoDB主键索引的B+tree高度为多高呢?
假设: 一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB的指针占用6个字节的空 间,主键即使为bigint,占用字节数为8。 高度为2: n * 8 + (n + 1) * 6 = 161024 , 算出n约为 1170 1171 16 = 18736 也就是说,如果树的高度为2,则可以存储 18000 多条记录。 高度为3: 1171 * 1171 * 16 = 21939856 也就是说,如果树的高度为3,则可以存储 2200w 左右的记录。
相关文章:
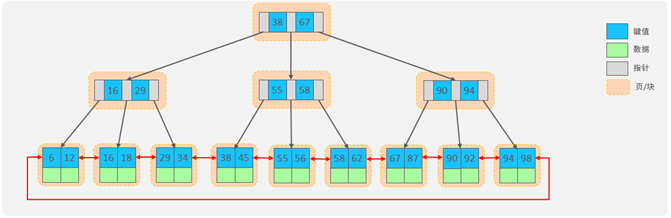
MySQL-存储引擎索引
存储引擎 MySQL体系结构 1). 连接层 最上层是一些客户端和链接服务,包含本地sock 通信和大多数基于客户端/服务端工具实现的类似于 TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程 池的概念,为通过认证安…...

图像处理有哪些核心技术?技术发展现状如何?
在数字化信息爆炸的时代,文档图像预处理技术正悄然改变着我们处理文字信息的方式。无论是手持拍摄的收据、扫描仪中的身份证,还是工业机器人采集的复杂文档,预处理技术都在背后默默提升着OCR(光学字符识别)系统的性能。…...

【小沐学GIS】基于C++绘制三维数字地球Earth(QT5、OpenGL、GIS、卫星)第五期
🍺三维数字地球系列相关文章如下🍺:1【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第一期2【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第二期3【小沐学GIS】…...

KEGG注释脚本kofam2kegg.py--脚本010
采用kofam结合kegg官网htxt进行注释 用法: python kofam2kegg.py kofam.out ath00001.keg my_kegg_output code: import sys from collections import defaultdictdef parse_kofam_file(kofam_file):ko_to_genes defaultdict(list)with open(kofam_file) as f:…...
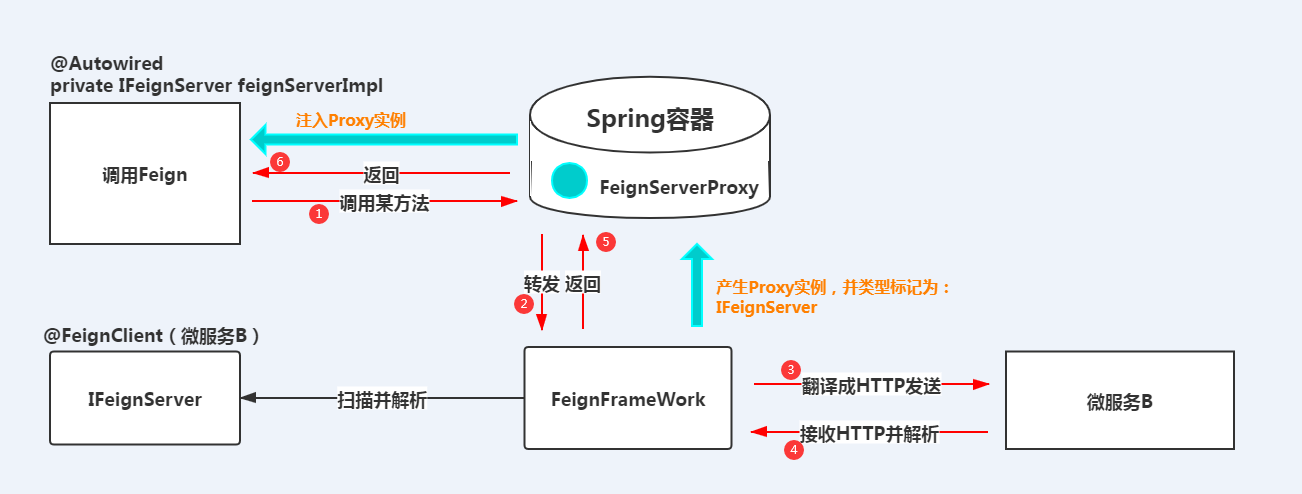
spring cloud OpenFeign 详解:安装配置、客户端负载均衡、声明式调用原理及代码示例
OpenFeign 详解:安装配置、客户端负载均衡、声明式调用原理及代码示例 1. OpenFeign 安装与配置 (1) 依赖管理 <!-- pom.xml 添加以下依赖 --> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud…...

【Java八股】
JVM JVM中有哪些引用 在Java中,引用(Reference)是指向对象的一个变量。Java中的引用不仅仅有常规的直接引用,还有不同类型的引用,用于控制垃圾回收(GC)的行为和优化性能。JVM中有四种引用类型…...

用 Deepseek 写的uniapp血型遗传查询工具
引言 在现代社会中,了解血型遗传规律对于优生优育、医疗健康等方面都有重要意义。本文将介绍如何使用Uniapp开发一个跨平台的血型遗传查询工具,帮助用户预测孩子可能的血型。 一、血型遗传基础知识 人类的ABO血型系统由三个等位基因决定:I…...
:4A广告代理公司与行业资质解读)
程序化广告行业(84/89):4A广告代理公司与行业资质解读
程序化广告行业(84/89):4A广告代理公司与行业资质解读 大家好!在探索程序化广告行业的道路上,每一次知识的分享都是我们共同进步的阶梯。一直以来,我都希望能和大家携手前行,深入了解这个充满机…...

go语言gRPC使用流程
1. 安装工具和依赖 安装 Protocol Buffers 编译器 (protoc) 下载地址:https://github.com/protocolbuffers/protobuf/releases 使用说明:https://protobuf.dev/ 【centos环境】yum方式安装:protoc[rootlocalhost demo-first]# yum install …...
【眼底辅助诊断开放平台】项目笔记
这是一个标题 任务一前端页面开发:后端接口配置: 任务二自行部署接入服务 日志修改样式和解析MD文档接入服务 Note前端登陆不进去/更改后端api接口304 Not Modifiedlogin.cache.jsonERR_CONNECTION_TIMED_OUT跨域一般提交格式proxy.ts src/coponents 目录…...

Java笔记5——面向对象(下)
目录 一、抽象类和接口 1-1、抽象类(包含抽象方法的类) 1-2、接口 编辑编辑 二、多态 编辑 1. 自动类型转换(向上转型) 示例: 注意: 2. 强制类型转换(向下转型) 示…...
NI的LABVIEW工具安装及卸载步骤说明
一.介绍 最近接到个转交的项目,项目主要作为上位机工具开发,在对接下位机时,有用到NI的labview工具。labview软件是由美国国家仪器(NI)公司研制开发的一种程序开发环境,主要用于汽车测试、数据采集、芯片测…...
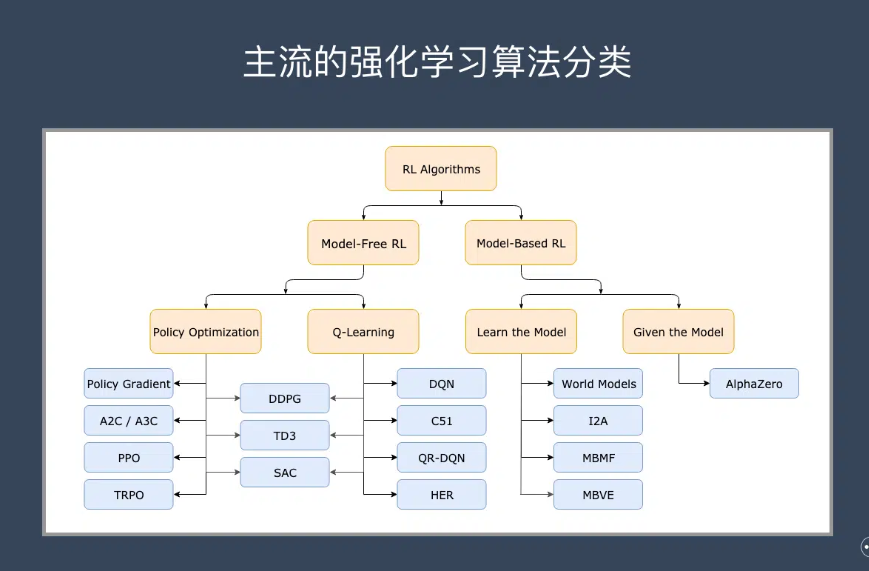
[reinforcement learning] 是什么 | 应用场景 | Andrew Barto and Richard Sutton
目录 什么是强化学习? 强化学习的应用场景 广告和推荐 对话系统 强化学习的主流算法 纽约时报:Turing Award Goes to 2 Pioneers of Artificial Intelligence wiki 资料混合:youtube, wiki, github 今天下午上课刷到了不少࿰…...

css一些注意事项
css一些注意事项 .bg_ {background-image: url(/static/photo/activity_bg.png);background-size: 100% auto;background-repeat: no-repeat;background: linear-gradient(to bottom, #CADCEA, #E8F3F6);min-height: 100vh; } 背景图片路径正确但是并没有显示 // 方案1&…...

[从零开始学数据库] 基本SQL
注意我们的主机就是我们的Mysql数据库服务器 这里我们可以用多个库 SQL分类(核心是字段的CRUD) 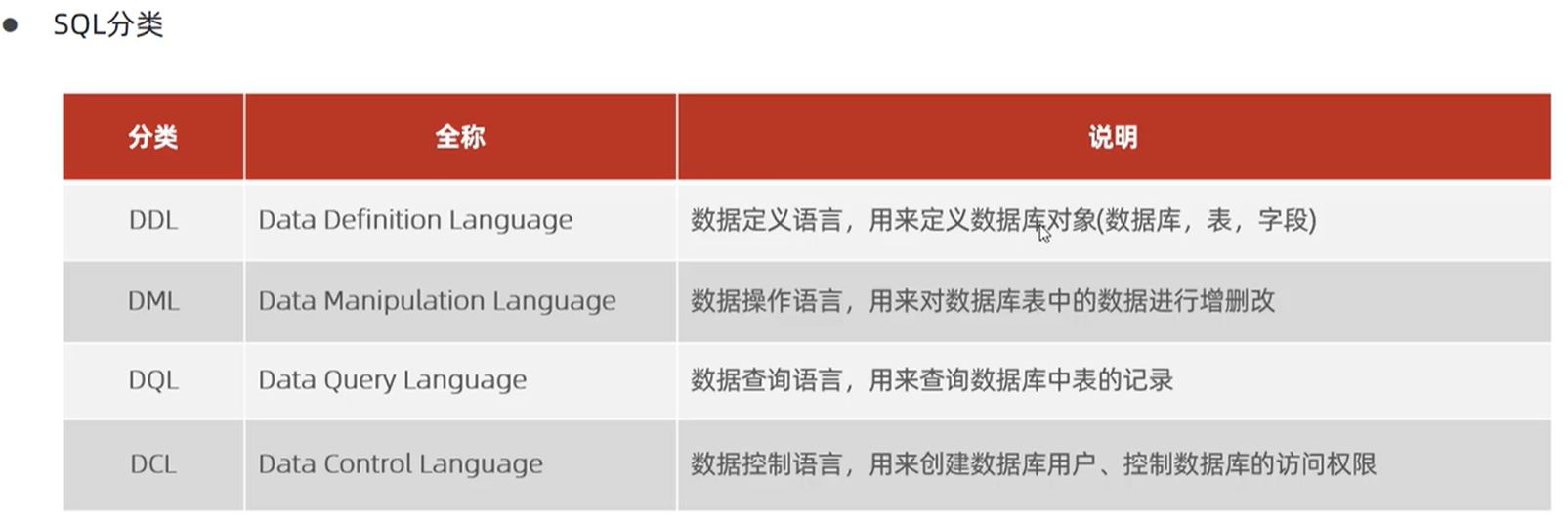 重点是我…...

react/vue中前端多图片展示页面优化图片加载速度的五种方案
需求背景 在多项目中 例如官网项目中 会出现很多大图片显示的情况 这个时候就会出现图片过大 公司带宽不够之类导致页面加载速度过慢及页面出现后图片仍然占位但并未加载出来 或者因为网络问题导致图片区域黑块等等场景 这个时候我们就要对图片和当前场景进行优化 方案定…...

qt中的正则表达式
问题: 1.在文本中把dog替换成cat,但可能会把dog1替换成cat1,如果原本不想替换dog1,就会出现问题 2文本中想获取某种以.txt为结尾的多有文本,普通的不能使用 3如果需要找到在不同的系统中寻找换行符,可以…...

AT_abc400_e [ABC400E] Ringo‘s Favorite Numbers 3 题解
题目传送门 题目大意 题目描述 对于正整数 N N N,当且仅当满足以下两个条件时, N N N 被称为 400 number: N N N 恰好有 2 2 2 种不同的素因数。对于 N N N 的每个素因数 p p p, N N N 被 p p p 整除的次数为偶数次。更严…...

git 提交标签
Git 提交标签 提交消息格式: <type>: <description> (示例:git commit -m "feat: add user login API") 标签适用场景feat新增功能(Feature)。fix修复 Bug(Bug fix&…...
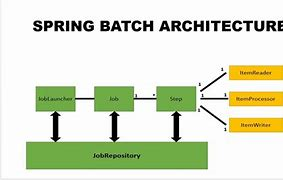
关于 Spring Batch 的详细解析及其同类框架的对比分析,以及如何自己设计一个java批处理框架(类似spring batch)的步骤
以下是关于 Spring Batch 的详细解析及其同类框架的对比分析: 一、Spring Batch 核心详解 1. 核心概念 作业(Job):批处理任务的顶层容器,由多个步骤(Step)组成。 步骤(Step&#…...

【Java面试系列】Spring Cloud微服务架构中的分布式事务实现与性能优化详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Cloud微服务架构中的分布式事务实现与性能优化详解 - 3-5年Java开发必备知识 引言 在微服务架构中,分布式事务是一个不可避免的挑战。随着业务复杂度的提升,如何保证跨服务的数据一致性成为面试中的高频问题。本文将从基础到进…...

【第十三届“泰迪杯”数据挖掘挑战赛】【2025泰迪杯】【论文篇+改进】A题解题全流程(持续更新)
【第十三届“泰迪杯”数据挖掘挑战赛】【2025泰迪杯】【论文篇改进】A题解题全流程(持续更新) 写在前面: 我是一个人,没有团队,所以出的比较慢,每年只做一次赛题,泰迪杯,我会认真对…...
)
Linux系统常见磁盘扩容操作(Common Disk Expansion Operations in Linux Systems)
Linux系统常见磁盘扩容操作 目录说明 一、准备工作:获取目标磁盘信息 (1)确认分区表格式和文件系统 二、扩容已有MBR分区 (1)分区后扩容 ext为例 xfs为例 三、扩容已有GPT分区 (1)分区…...

数据结构——哈希详解
数据结构——哈希详解 目录 一、哈希的定义 二、六种哈希函数的构造方法 2.1 除留取余法 2.2 平方取中法 2.3 随机数法 2.4 折叠法 2.5 数字分析法 2.6 直接定值法 三、四种解决哈希冲突的方法 3.1 开放地址法 3.1.1 线性探测法 3.1.2 二次探测法 3.2 链地址法 3…...
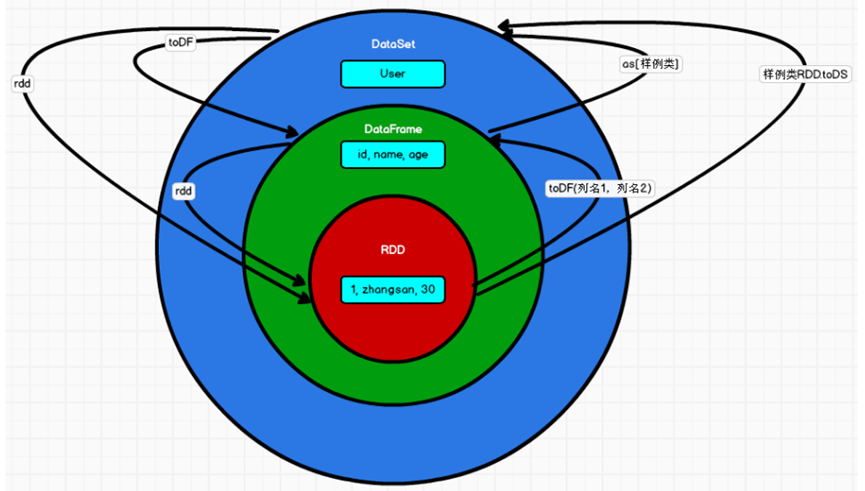
Spark-SQL核心编程
简介 Hadoop与Spark-SQL的对比 Hadoop在处理结构化数据方面存在局限性,无法有效处理某些类型的数据。 Spark应运而生,特别设计了处理结构化数据的模块,称为Spark SQL(原称Shark)。 SparkSQL的发展历程: Sp…...

pywebview 常用问题分享
文章目录 前言问题描述与方案(待补充)1、动态设置本地调试目录和打包目录2、构建后运行程序白屏 前言 最近做一个pywebview项目,遇到了一些问题,记录一下,分享给大家,希望能帮助有遇到相似问题的人事。 问题描述与方案(待补充) …...
))
系统设计模块之安全架构设计(身份认证与授权(OAuth2.0、JWT、RBAC/ABAC))
一、OAuth 2.0:开放授权框架 OAuth 2.0 是一种标准化的授权协议,允许第三方应用在用户授权下访问其资源,而无需直接暴露用户密码。其核心目标是 分离身份验证与授权,提升安全性与灵活性。 1. 核心概念与流程 角色划分ÿ…...
Docker 与 Podman常用知识汇总
一、常用命令的对比汇总 1、基础说明 Docker:传统的容器引擎,使用 dockerd 守护进程。 Podman:无守护进程、无root容器引擎,兼容 Docker CLI。 Podman 命令几乎完全兼容 Docker 命令,只需将 docker 替换为 podman。…...

如何通过自动化解决方案提升企业运营效率?
引言 在现代企业中,运营效率直接影响着企业的成本、速度与竞争力。尤其是随着科技的不断发展,传统手工操作和低效的流程逐渐无法满足企业的需求。自动化解决方案正成为企业提升运营效率、降低成本和提高生产力的关键。无论是大型跨国公司,还…...

unity100天学习计划
以下是一个为期100天的Unity学习大纲,涵盖从零基础到独立开发完整游戏的全流程,结合理论、实践和项目实战,每天学习2-3小时: 第一阶段:基础奠基(Day 1-20) 目标:掌握Unity引擎基础与C#编程 Day 1-5:引擎入门 安装Unity Hub和Unity Editor(LTS版本)熟悉Unity界面:S…...