Java雪花算法
以下是用Java实现的雪花算法代码示例,包含详细注释和异常处理:
代码下面有解析
public class SnowflakeIdGenerator {// 起始时间戳(2020-01-01 00:00:00)private static final long START_TIMESTAMP = 1577836800000L;// 各部分的位数private static final long DATA_CENTER_ID_BITS = 5L; // 数据中心ID占5位private static final long WORKER_ID_BITS = 5L; // 工作节点ID占5位private static final long SEQUENCE_BITS = 12L; // 序列号占12位// 最大值计算(位运算)private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);private static final long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);// 左移位数private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;private final long dataCenterId; // 数据中心IDprivate final long workerId; // 工作节点IDprivate long sequence = 0L; // 序列号private long lastTimestamp = -1L; // 上次生成时间/*** 构造函数* @param dataCenterId 数据中心ID (0~31)* @param workerId 工作节点ID (0~31)*/public SnowflakeIdGenerator(long dataCenterId, long workerId) {if (dataCenterId > MAX_DATA_CENTER_ID || dataCenterId < 0) {throw new IllegalArgumentException("DataCenter ID 超出范围");}if (workerId > MAX_WORKER_ID || workerId < 0) {throw new IllegalArgumentException("Worker ID 超出范围");}this.dataCenterId = dataCenterId;this.workerId = workerId;}/*** 生成下一个ID(线程安全)*/public synchronized long nextId() {long currentTimestamp = System.currentTimeMillis();// 时钟回拨检查if (currentTimestamp < lastTimestamp) {throw new RuntimeException("时钟回拨,拒绝生成ID");}if (currentTimestamp == lastTimestamp) {// 同一毫秒内序列号递增sequence = (sequence + 1) & MAX_SEQUENCE;if (sequence == 0) {// 当前毫秒序列号用完,等待下一毫秒currentTimestamp = waitNextMillis(lastTimestamp);}} else {// 新毫秒重置序列号sequence = 0L;}lastTimestamp = currentTimestamp;// 组合各部分生成IDreturn ((currentTimestamp - START_TIMESTAMP) << TIMESTAMP_SHIFT)| (dataCenterId << DATA_CENTER_ID_SHIFT)| (workerId << WORKER_ID_SHIFT)| sequence;}/*** 阻塞等待直到下一毫秒*/private long waitNextMillis(long lastTimestamp) {long currentTimestamp = System.currentTimeMillis();while (currentTimestamp <= lastTimestamp) {currentTimestamp = System.currentTimeMillis();}return currentTimestamp;}public static void main(String[] args) {// 示例用法SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1, 1);for (int i = 0; i < 10; i++) {System.out.println("生成的ID: " + idGenerator.nextId());}}
}
好的!我来用更简单的方式分步讲解雪花算法的分布式核心逻辑,以及Java代码的关键部分。
第一步:为什么需要分布式ID?
在单机系统中,可以用数据库自增ID。但在分布式系统中,多个节点同时生成ID时,自增ID会冲突。雪花算法通过结构划分,让每个节点独立生成全局唯一ID。
第二步:雪花ID的结构(64位)
想象把64位的数字分成四个部分,像切蛋糕一样:
- 符号位(1位):固定为0,保证ID是正数(蛋糕边角料,几乎不用管)。
- 时间戳(41位):记录ID生成的时间(精确到毫秒),保证ID随时间递增。
- 机器ID(10位):分配给不同机器的编号,确保不同机器的ID不冲突。
- 序列号(12位):同一毫秒内,如果生成多个ID,用序列号区分。

第三步:机器ID的分配(分布式核心)
• 问题:如果多台机器生成ID,如何确保它们的ID不重复?
• 解决方案:为每台机器分配一个唯一编号(比如:数据中心ID + 工作节点ID)。
• 示例:5位数据中心ID(031) + 5位工作节点ID(031) → 最多支持 32×32=1024 台机器。
• 分配方式:手动配置或通过ZooKeeper等工具动态分配。
第四步:Java代码关键点拆解
1. 定义各部分的位数
private static final long DATA_CENTER_ID_BITS = 5L; // 数据中心ID占5位
private static final long WORKER_ID_BITS = 5L; // 工作节点ID占5位
private static final long SEQUENCE_BITS = 12L; // 序列号占12位
2. 计算最大值(防止溢出)
// 5位最大值是 2^5-1 = 31
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
3. 生成ID的核心逻辑
public synchronized long nextId() {long currentTimestamp = System.currentTimeMillis();// 1. 检查时钟回拨(时间不能倒流)if (currentTimestamp < lastTimestamp) {throw new RuntimeException("时钟回拨!");}// 2. 同一毫秒内生成多个IDif (currentTimestamp == lastTimestamp) {sequence++; // 序列号+1if (sequence > MAX_SEQUENCE) {// 当前毫秒的序列号用完了,等待下一毫秒currentTimestamp = waitNextMillis(lastTimestamp);sequence = 0;}} else {sequence = 0; // 新的一毫秒,序列号重置}lastTimestamp = currentTimestamp;// 3. 拼接各部分(位运算)return (时间戳部分) | (机器ID部分) | (序列号部分);
}
4. 位运算如何拼接?
假设时间差是 1000ms,数据中心ID=1,工作节点ID=1,序列号=0:
时间戳部分:1000ms << 22位(左移后占据高位)
机器ID部分:1 << 17位(左移后占据中间)
工作节点部分:1 << 12位(左移后占据中间)
序列号部分:0(占据最后12位)最终二进制:
0000000000000000000000011111101000 00001 00001 000000000000
第五步:分布式场景示例
• 机器A:数据中心ID=1,工作节点ID=1
• 机器B:数据中心ID=1,工作节点ID=2
• 机器C:数据中心ID=2,工作节点ID=1
同一毫秒内,三台机器生成的ID:
机器A:时间戳 | 1(数据中心) | 1(工作节点) | 序列号
机器B:时间戳 | 1(数据中心) | 2(工作节点) | 序列号
机器C:时间戳 | 2(数据中心) | 1(工作节点) | 序列号
即使时间戳和序列号相同,机器ID不同 → 最终ID不同!
第六步:常见问题解答
1. 为什么时间戳占41位?
• 41位二进制能表示的时间范围是 2^41 / 1000 / 3600 / 24 / 365 ≈ 69年。
• 如果从2020年开始,可以用到2089年。
2. 时钟回拨怎么办?
• 原因:服务器时间被手动调整或NTP同步导致时间倒退。
• 处理:代码中直接抛出异常(生产环境可优化为等待时钟追上)。
3. 序列号为什么是12位?
• 12位支持每毫秒生成 4096个ID(2^12 = 4096),足够大多数场景使用。
总结
雪花算法的分布式核心就是:
- 分蛋糕:把64位分成时间、机器ID、序列号。
- 唯一机器ID:确保不同机器的ID不冲突。
- 时间有序:时间戳保证ID整体递增,适合数据库索引。
代码中的位运算就像拼乐高积木,把时间、机器编号、序列号拼成一个完整的ID。你提到的这一点非常重要!这里涉及到位运算和二进制补码的知识,我来详细拆解这个计算过程,保证彻底讲清楚。
问题聚焦
代码中的这两行:
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
为什么 DATA_CENTER_ID_BITS = 5 时,MAX_DATA_CENTER_ID = 31?如何通过位运算得出这个结果?
第一步:理解二进制补码
在计算机中,负数用补码表示。例如:
• -1 的二进制补码形式是:11111111 11111111 ... 11111111(64位全1)。
**第二步:分步计算 **~(-1L << 5)
以 DATA_CENTER_ID_BITS = 5 为例:
- **计算 **
-1L << 5
•-1L的二进制:11111111 11111111 ... 11111111(64位全1)。
• 左移5位后:
11111111 11111111 ... 11111111 00000
↑ 左侧丢弃5位,右侧补5个0
• 结果仍是一个负数(最高位是1)。
- 按位取反
~操作
• 对111...11100000取反:
00000000 00000000 ... 00000000 11111
↑ 所有位取反(0变1,1变0)
• 此时最高位是0,表示正数。
- 转换为十进制
• 二进制000...0011111的十进制是2^4 + 2^3 + 2^2 + 2^1 + 2^0 = 31。
通用公式
• 对于 n 位:~(-1L << n) = 2^n - 1
例如:
• n=5 → 2^5-1=31
• n=10 → 2^10-1=1023
为什么不用 2^n - 1 直接赋值?
代码中通过位运算动态计算最大值,有两个优点:
- 可读性:直接体现“用n位表示最大值”的逻辑。
- 可维护性:若未来调整位数(如改为6位),无需手动计算
2^6-1=63,代码自动适应。
代码中的验证逻辑
构造函数中检查数据中心ID和工作节点ID是否超过最大值:
public SnowflakeIdGenerator(long dataCenterId, long workerId) {if (dataCenterId > MAX_DATA_CENTER_ID || dataCenterId < 0) {throw new IllegalArgumentException("DataCenter ID 超出范围");}// 同理检查workerId
}
• 若传入 dataCenterId=32(超过31),会直接抛出异常,防止生成重复ID。
举例验证
假设 DATA_CENTER_ID_BITS = 3(最大值应为 2^3-1=7):
-1L << 3→111...11111111000(64位)。- 取反后 →
000...00000000111(二进制7)。 MAX_DATA_CENTER_ID = 7。
总结
• 核心逻辑:通过左移和取反计算n位能表示的最大正整数。
• 位运算技巧:利用补码和位移动态计算最大值,避免硬编码。
• 设计意图:确保机器ID在指定范围内,防止分布式系统中ID冲突。好的!我再用一个更生活化的比喻和分步拆解,确保彻底讲明白这段代码的逻辑。
比喻:楼层与房间号
想象你要为一家全球连锁酒店设计房间号,规则如下:
- 酒店编号:区分不同国家/城市的酒店(如北京=01,上海=02)。
- 分店编号:同一城市的不同分店(如北京分店A=001,分店B=002)。
- 时间戳:记录房间分配的日期(如20231025)。
- 序列号:同一天内分配的房间顺序(如0001, 0002)。
最终房间号格式:时间戳 + 酒店编号 + 分店编号 + 序列号,例如:
20231025 01 001 0001 → 北京分店A在2023年10月25日分配的第1个房间。
对应雪花算法
将上述规则映射到雪花算法的64位ID:
• 时间戳:占据高位(相当于日期)。
• 数据中心ID(酒店编号):区分不同数据中心。
• 工作节点ID(分店编号):同一数据中心的不同机器。
• 序列号:同一毫秒内的顺序号。
代码逐行拆解
1. 定义左移位数
private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;
private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;
• 作用:计算每个部分在二进制中的起始位置。
• 示例(假设配置):
• 序列号占12位(SEQUENCE_BITS=12)
• 工作节点ID占5位(WORKER_ID_BITS=5)
• 数据中心ID占5位(DATA_CENTER_ID_BITS=5)
• 计算逻辑:
• 工作节点ID需要左移序列号的位数(12位),占据第13~17位。
• 数据中心ID需要左移序列号+工作节点ID位数(12+5=17位),占据第18~22位。
• 时间戳需要左移序列号+工作节点ID+数据中心ID位数(12+5+5=22位),占据第23~63位。

2. 成员变量
private final long dataCenterId; // 数据中心ID(如:1)
private final long workerId; // 工作节点ID(如:2)
private long sequence = 0L; // 序列号(每毫秒从0开始)
private long lastTimestamp = -1L; // 上一次生成ID的时间(毫秒级)
• 作用:
• dataCenterId和workerId:唯一标识一台机器(类似酒店和分店编号)。
• sequence:同一毫秒内的递增序号(解决并发问题)。
• lastTimestamp:记录上一次生成ID的时间,用于检测时钟回拨。
分步演示生成ID
假设数据:
• 当前时间戳:1609459205000(2020-01-01 00:00:05)
• 数据中心ID:1(二进制 00001)
• 工作节点ID:2(二进制 00010)
• 序列号:3(二进制 000000000011)
步骤1:计算时间差
long timestampDiff = currentTimestamp - START_TIMESTAMP;
// 1609459205000 - 1609459200000 = 5000(毫秒)
步骤2:各部分左移
• 时间戳部分
5000 << 22
二进制:0000000000000000000000000000000000000000010011100010000000000000
• 数据中心ID部分
1 << 17
二进制:0000000000000000000000000000000000000000000000000010000000000000
• 工作节点ID部分
2 << 12
二进制:0000000000000000000000000000000000000000000000000000001000000000
• 序列号部分
3
二进制:0000000000000000000000000000000000000000000000000000000000000011
步骤3:合并各部分(按位或运算)
时间戳部分 | 数据中心ID部分 | 工作节点ID部分 | 序列号部分
= 0000000000000000000000000000000000000000010011100010000000000000| 0000000000000000000000000000000000000000000000000010000000000000| 0000000000000000000000000000000000000000000000000000001000000000| 0000000000000000000000000000000000000000000000000000000000000011
= 0000000000000000000000000000000000000000010011100010001000000011
十进制结果:5000 << 22 | 1 << 17 | 2 << 12 | 3 = 20971520000 + 131072 + 8192 + 3 = 20972852787
关键设计思想
- 唯一性:通过
dataCenterId和workerId区分不同机器。 - 有序性:时间戳在高位,整体ID趋势递增。
- 高性能:位运算和本地计算,无需网络请求。
总结
• 位移常量:决定每部分在ID中的位置(类似酒店房间号的“区段”)。
• 成员变量:存储机器标识和时间信息,通过位移拼接成唯一ID。
• 本质:把时间、机器、序列号信息编码到一个64位数字中,像拼图一样严丝合缝。
相关文章:
Java雪花算法
以下是用Java实现的雪花算法代码示例,包含详细注释和异常处理: 代码下面有解析 public class SnowflakeIdGenerator {// 起始时间戳(2020-01-01 00:00:00)private static final long START_TIMESTAMP 1577836800000L;// 各部分…...

前端大屏可视化项目 局部全屏(指定盒子全屏)
需求是这样的,我用的项目是vue admin 项目 现在需要在做大屏项目 不希望显示除了大屏的其他东西 于是想了这个办法 至于大屏适配问题 请看我文章 底部的代码直接复制就可以运行 vue2 px转rem 大屏适配方案 postcss-pxtorem-CSDN博客 <template><div …...

Android studio消息同步机制:消息本地存储,服务器交互减压
文章目录 后端(Flask)代码前端(Android Studio Java)代码同步机制1. 放在 Activity 中2. 放在 Service 中3. 放在 DataManager 类中 放在Service中的具体实现1. 后台执行2. 独立于活动3. 系统管理4. 绑定服务5. 进程间通信&#x…...
)
P8667 [蓝桥杯 2018 省 B] 递增三元组(摘自洛谷)
给定三个整数数组 A[A1,A2,⋯,AN],B[B1,B2,⋯,BN],C[C1,C2,⋯,CN]。 请你统计有多少个三元组 (i,j,k) 满足: 1≤i,j,k≤NAi<Bj<Ck 输入格式 第一行包含一个整数 N。 第二行包含 N 个整数 A1,A2,⋯,AN…...

【Kafka基础】监控与维护:动态配置管理,灵活调整集群行为
1 基础配置操作 1.1 修改主题保留时间 /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-configs.sh --alter \--bootstrap-server 192.168.10.33:9092 \--entity-type topics \--entity-name yourtopic \--add-config retention.ms86400000 参数说明: retention…...
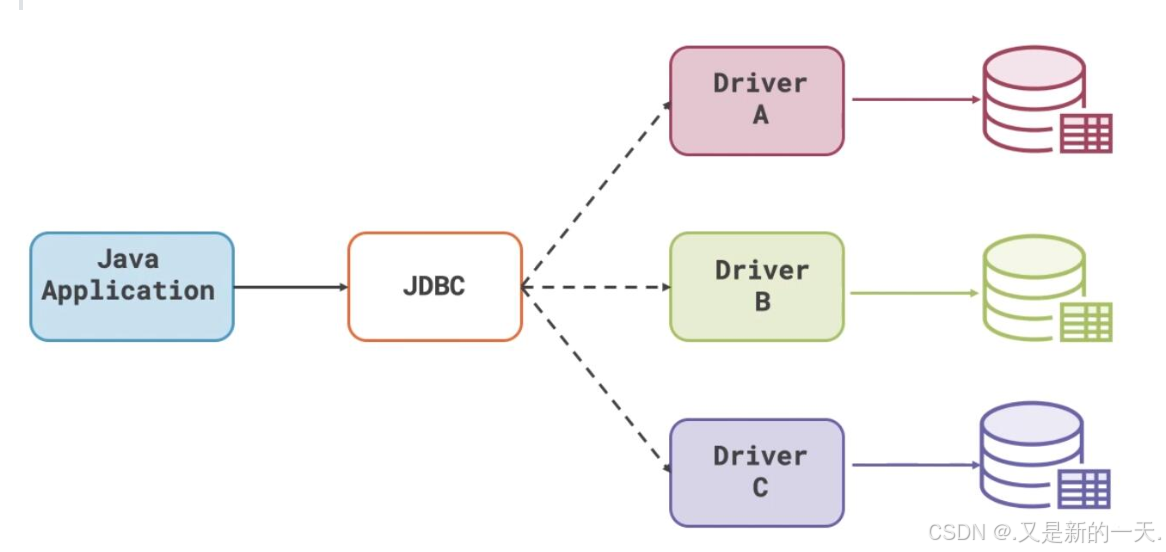
01_JDBC
文章目录 一、概述1.1、什么是JDBC1.2、JDBC原理 二、JDBC入门2.1、准备工作2.1.1、建库建表2.1.2、新建项目 2.2、建立连接2.2.1、准备四大参数2.2.2、加载驱动2.2.3、准备SQL语句2.2.4、建立连接2.2.5、常见问题 2.3、获取发送SQL的对象2.4、执行SQL语句2.5、处理结果2.6、释…...

STM32 HAL库 HC - SR04 超声波测距模块驱动实现
一、引言 在现代嵌入式系统开发中,传感器技术起着至关重要的作用。超声波测距模块作为一种常用的距离测量传感器,因其成本低、精度较高、使用方便等优点,被广泛应用于机器人避障、液位检测、工业自动化等领域。HC - SR04 超声波测距模块是一…...

Spring Boot 热部署详解,包含详细的配置项说明
Spring Boot 热部署详解 1. 热部署简介 热部署(Hot Deployment)允许在应用运行时修改代码或配置文件,无需重启应用即可使更改生效。Spring Boot 通过 spring-boot-devtools 模块实现这一功能,其核心依赖于 LiveReload 技术和自动…...
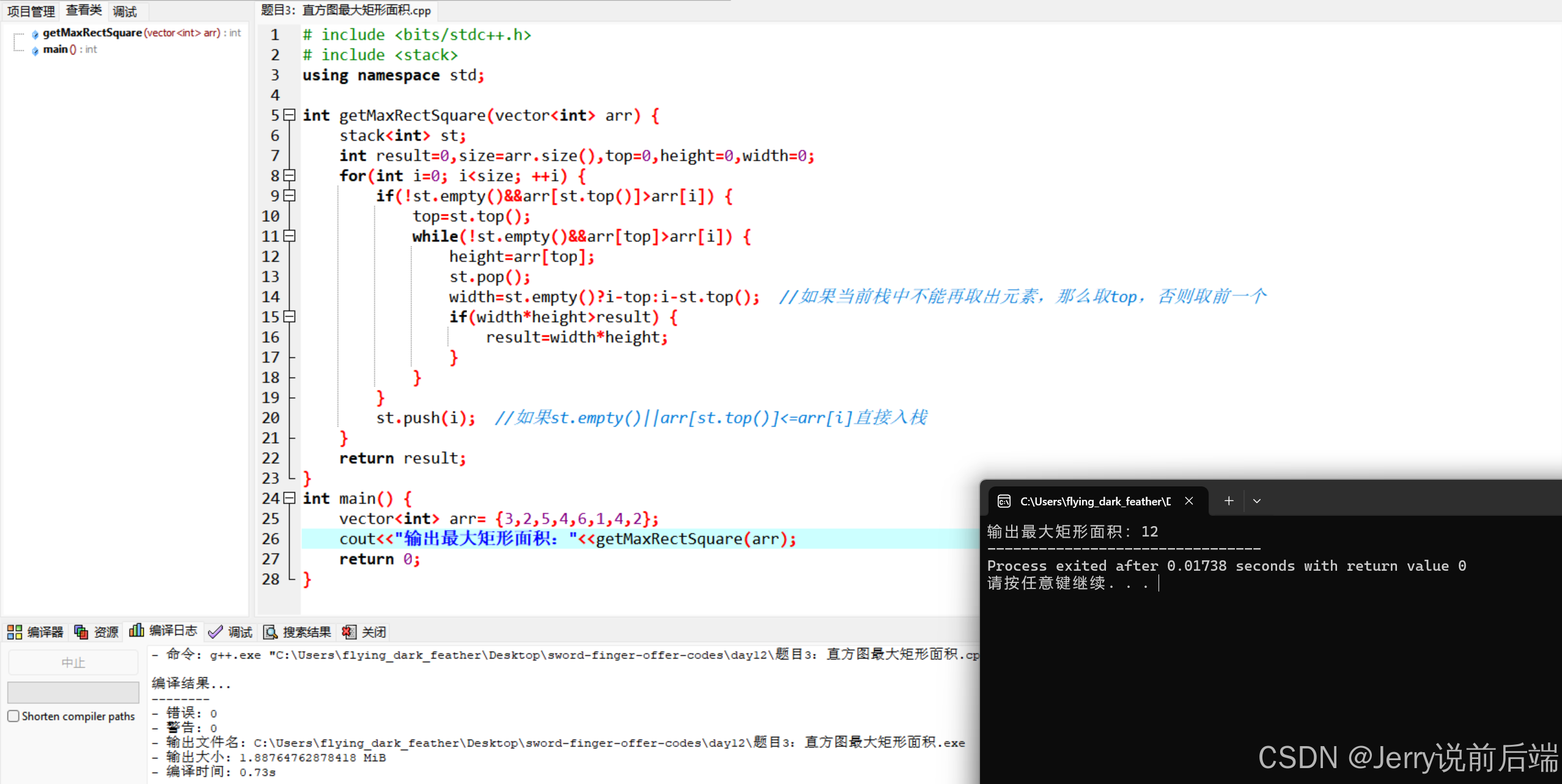
剑指Offer(数据结构与算法面试题精讲)C++版——day12
剑指Offer(数据结构与算法面试题精讲)C版——day12 题目一:小行星碰撞题目二:每日温度题目三:直方图最大矩形面积附录:源码gitee仓库 题目一:小行星碰撞 题目:输入一个表示小行星的数…...
(java)距离相等的条形码)
贪心算法(18)(java)距离相等的条形码
在一个仓库里,有一排条形码,其中第 i 个条形码为 barcodes[i]。 请你重新排列这些条形码,使其中任意两个相邻的条形码不能相等。 你可以返回任何满足该要求的答案,此题保证存在答案。 示例 1: 输入:barco…...
Docker学习笔记-docker安装、删除
一、在centOS 7中docker的默认安装目录 # Docker 主配置文件目录 ls /etc/docker# Docker 数据目录(镜像、容器、卷等) ls /var/lib/docker# Docker 可执行文件路径 which docker # 输出类似 /usr/bin/docker 二、docker文件目录说明 目录/文件用途/…...
【Python 开源】你的 Windows 关机助手——PyQt5 版定时关机工具
🖥️ 你的 Windows 关机助手——PyQt5 版定时关机工具 相关资源文件已经打包成EXE文件,可双击直接运行程序,且文章末尾已附上相关源码,以供大家学习交流,博主主页还有更多Python相关程序案例,秉着开源精神的…...

STM32 HAL库 ADC+TIM+DMA 3路 1S采样一次电压
一、引言 在很多嵌入式系统应用中,需要对多路模拟信号进行周期性采样,例如在工业控制、环境监测等领域。STM32F407 是一款高性能的微控制器,其丰富的外设资源可以方便地实现这样的功能。通过结合 ADC(模拟 - 数字转换器ÿ…...

汉诺塔问题——用贪心算法解决
目录 一:起源 二:问题描述 三:规律 三:解决方案 递归算法 四:代码实现 复杂度分析 一:起源 汉诺塔(Tower of Hanoi)问题起源于一个印度的古老传说。在世界中心贝拿勒斯&#…...

【Python爬虫】简单介绍
目录 一、基本概念 1.1 什么是爬虫 1.2 Python为什么适合爬虫 1.3 Python爬虫应用领域 (1)数据采集与分析 市场调研 学术研究 (2)内容聚合与推荐 新闻聚合 视频内容聚合 (3)金融领域 股票数据获…...

使用MCP服务通过自然语言操作数据库(vscode+cline版本)
使用MCP服务操纵数据库(vscodecline版本) 本文主要介绍,在vscode中使用cline插件调用deepseek模型,通过MCP服务器 使用自然语言去操作指定数据库。本文使用的是以己经创建号的珠海航展数据库。 理解MCP服务: MCP(Model Context…...

Vue 3 + TypeScript 实现一个多语言国际化组件(支持语言切换与内容加载)
文章目录 一、项目背景与功能概览二、项目技术架构与依赖安装2.1 技术栈2.2 安装依赖 三、国际化组件实现3.1 创建 i18n 实例3.2 配置 i18n 到 Vue 应用3.3 在组件中使用国际化内容3.4 支持语言切换 四、支持类型安全4.1 添加类型支持4.2 自动加载语言文件 一、项目背景与功能概…...
PhalApi 2.x:让PHP接口开发从“简单”到“极简”的开源框架
—— 专为高效开发而生,助你轻松构建高可用API接口 一、为什么选择PhalApi 2.x? 1.轻量高效,性能卓越 PhalApi 2.x 是一款专为接口开发设计的轻量级PHP框架,其核心代码精简但功能强大。根据开发者实测,在2核2G服务器…...

库magnet使用指南
Magnet 多线程控制库使用指南 目录 库功能概述环境配置核心类与接口基础使用示例代码生成工具高级功能与改进建议完整示例代码常见问题解答 https://blink.csdn.net/details/1872803?spm1001.2014.3001.5501 1. 库功能概述 Magnet 库提供以下核心功能: 多线程…...
 导出、导入补充>)
Oracle数据库数据编程SQL<9.3 数据库逻辑备份和迁移Data Pump (EXPDP/IMPDP) 导出、导入补充>
Oracle Data Pump 是 Oracle 10g 引入的高效数据迁移工具,相比传统的 EXP/IMP 工具,它提供了更强大的功能和显著的性能提升。以下是对 EXPDP 和 IMPDP 工具的全面讲解。 目录 一、高级功能扩展 1. 数据过滤与转换 2. 加密与安全 二、性能调优进阶 1. 并行处理优化 2. …...

Java 企业级应用:SOA 与微服务的对比与选择
企业级应用开发中,架构设计是决定系统可扩展性、可维护性和性能的关键因素。SOA(面向服务的架构)和微服务架构是两种主流的架构模式,它们各自有着独特的和设计理念适用场景。本文将深入探讨 SOA 和微服务架构的对比,并…...
)
Linux LED驱动(设备树)
Linux LED驱动(设备树) 之前的LED驱动直接在驱动文件中定义有关寄存器物理地址,然后使用io_remap函数进行内存映射,得到对应的虚拟地址,最后操作寄存器对应的虚拟地址完成对GPIO的初始化。 但也可以先在设备树文件中创…...

Zookeeper的典型应用场景?
大家好,我是锋哥。今天分享关于【Zookeeper的典型应用场景?】面试题。希望对大家有帮助; Zookeeper的典型应用场景? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 ZooKeeper 是一个开源的分布式协调服务,主要用于管理和协调大…...
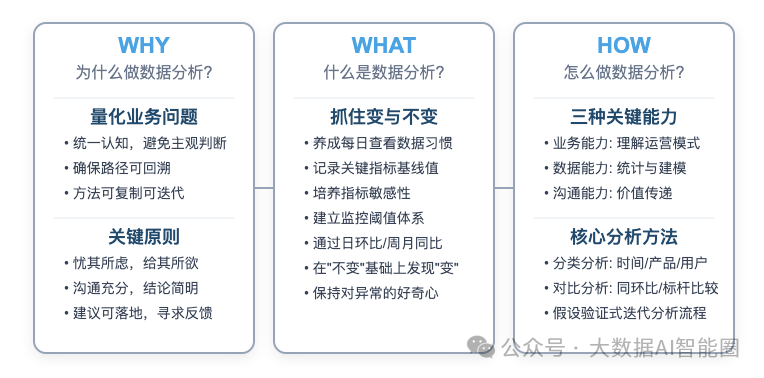
数据分析不只是跑个SQL!
数据分析不只是跑个SQL! 数据分析五大闭环,你做到哪一步了?闭环一:认识现状闭环二:原因分析闭环三:优化表现闭环四:预测走势闭环五:主动解读数据 数据思维:WHY-WHAT-HOW模…...
面试篇 - GPT-3(Generative Pre-trained Transformer 3)模型
GPT-3(Generative Pre-trained Transformer 3)模型 模型结构 与GPT-2一样,但是应用了Sparse attention: Dense attention:每个token之间两两计算attention,复杂度为O(n2)。 Sparse attention:…...
Dify智能体平台源码二次开发笔记(4) - 多租户的SAAS版实现
前言 Dify 的多租户功能是其商业版的标准功能,我们应当尊重其盈利模式。只有保持良性的商业运作,Dify 才能持续发展,并为用户提供更优质的功能。因此,此功能仅限学习使用。 我们的需求是:实现类似 SaaS 版的账号隔离&a…...

C# 13新特性 - .NET 9
转载: C# 13 中的新增功能 | Microsoft Learn C# 13 包括以下新增功能。 可以使用最新的 Visual Studio 2022 版本或 .NET 9 SDK 尝试这些功能:Introduced in Visual Studio 2022 Version 17.12 and newer when using C# 13 C# 13 中的新增功能 | Micr…...

【Code】《代码整洁之道》笔记-Chapter9-单元测试
第9章 单元测试 过去十年以来,编程专业领域进步很大。1997年时,没人听说过测试驱动开发。对于我们之中的大多数人来说,单元测试是那种用来确保程序“可运行”的用过即扔的短代码。我们辛勤地编写类和方法,再弄出一些特殊代码来测…...

java -jar 如何持久化运行
在 Linux 中,直接通过 java -jar 启动服务后关闭 SSH 客户端(如 Xshell)会导致服务终止,因为进程默认与当前终端会话绑定。以下是几种解决方案,确保服务在后台持久运行: (1)使用nohup命令,让进程忽略挂断信号,并在后台运行。 ps -ef | grep xxx.jar 或者 ps -ef …...
layui中transfer两个table展示不同的数据列
在项目的任务开发中需要达到transfer右侧table需要有下拉框可选择状态,左侧table不变 使用的layui版本为2.4.5,该版本没有对transfer可自定义数据列的配置,所以改动transfer.js中的源码 以下为transfer.js部分源码 也是transfer.js去render的…...