Series和 DataFrame是 Pandas 库中的两种核心数据结构
Series 和 DataFrame 是 Pandas 库中的两种核心数据结构,它们各有特点和用途。理解它们之间的区别有助于更高效地进行数据分析和处理。以下是 Series 和 DataFrame 的主要区别:
1. 维度
- Series:是一维的数组,可以存储任何类型的数据(整数、字符串、浮点数等),并且每个元素都有一个标签(索引)。
- DataFrame:是二维的表格型数据结构,包含一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。它既有行索引也有列索引。
2. 结构
- Series:类似于一维数组或固定大小的字典。每个元素通过唯一的索引(标签)访问。
s = pd.Series([1, 2, 3], index=['a', 'b', 'c']) - DataFrame:类似于表格或 Excel 表格。每一列可以有不同的数据类型,并且可以通过行索引和列名来访问数据。
df = pd.DataFrame({'A': [1, 2, 3],'B': ['a', 'b', 'c'] })
3. 索引方式
- Series:支持基于位置的索引(如
s[0])和基于标签的索引(如s['a'])。 - DataFrame:支持基于位置的索引(如
df.iloc[0])和基于标签的索引(如df.loc[0]或df['A'])。还可以同时使用行和列的索引来获取特定单元格的数据(如df.loc[0, 'A'])。
4. 操作与方法
- Series:提供了许多针对一维数据的方法,例如统计计算(
mean,sum,std等),以及一些特有的方法如value_counts()来统计唯一值的频率。 - DataFrame:提供了更多复杂的数据操作方法,如分组聚合 (
groupby)、合并 (merge,join)、透视表 (pivot_table) 等。
5. 缺失值处理
- Series:自动处理缺失值(通常表示为
NaN),并且在进行统计计算时会自动忽略这些缺失值。 - DataFrame:同样自动处理缺失值,并且可以对整个 DataFrame 或者单独的列进行缺失值处理(如填充
fillna()或删除dropna())。
6. 应用场景
- Series:适用于简单的一维数据集,如时间序列数据、单个变量的不同观测值等。
- DataFrame:适用于更复杂的数据集,尤其是需要多变量分析的情况,如表格数据、数据库记录、CSV 文件内容等。
示例对比
创建 Series 和 DataFrame
import pandas as pd# 创建 Series
s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
print(s)
# 输出:
# a 1
# b 2
# c 3
# dtype: int64# 创建 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': ['a', 'b', 'c']
})
print(df)
# 输出:
# A B
# 0 1 a
# 1 2 b
# 2 3 c
访问数据
# 访问 Series 中的数据
print(s['a']) # 输出: 1# 访问 DataFrame 中的数据
print(df['A']) # 输出:
# 0 1
# 1 2
# 2 3
# Name: A, dtype: int64print(df.loc[0, 'B']) # 输出: a
何时使用series
Series 是 Pandas 中最基础的数据结构,适合处理单一类型的线性数据。它非常适合用于以下几种场景:
1. 单变量的时间序列分析
- 当你需要处理按时间顺序排列的单一变量数据时,
Series非常适用。例如,股票价格、温度变化、网站访问量等。
示例:
import pandas as pd# 创建一个时间序列 Series
dates = pd.date_range('20230101', periods=5)
series = pd.Series([10, 20, 30, 40, 50], index=dates)print(series)
输出:
2023-01-01 10
2023-01-02 20
2023-01-03 30
2023-01-04 40
2023-01-05 50
Freq: D, dtype: int64
2. 简单的统计计算
- 如果你只需要对一维数组进行简单的统计计算(如均值、中位数、标准差等),使用
Series就足够了。
示例:
# 计算均值和标准差
data = pd.Series([1, 2, 3, 4, 5])
mean_value = data.mean()
std_value = data.std()print(f"均值: {mean_value}, 标准差: {std_value}")
输出:
均值: 3.0, 标准差: 1.4142135623730951
3. 数据清洗与预处理
- 在进行数据清洗时,
Series提供了许多方便的方法来处理缺失值、重复值和异常值。
示例:
# 创建一个带有缺失值的 Series
data = pd.Series([1, 2, None, 4, 5])# 填充缺失值
filled_data = data.fillna(method='ffill') # 使用前向填充方法
print(filled_data)
输出:
0 1.0
1 2.0
2 2.0
3 4.0
4 5.0
dtype: float64
4. 标签索引
Series支持基于标签的索引,这使得你可以更直观地访问数据,而不仅仅是通过位置索引。
示例:
# 创建一个带标签的 Series
s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])# 使用标签索引
print(s['b']) # 输出: 2
5. 字符串操作
- 对于包含文本数据的
Series,Pandas 提供了许多便捷的字符串操作方法。
示例:
# 创建一个包含文本数据的 Series
text_series = pd.Series(['apple', 'banana', 'cherry'])# 转换为大写
upper_text = text_series.str.upper()
print(upper_text)
输出:
0 APPLE
1 BANANA
2 CHERRY
dtype: object
6. 简单聚合操作
- 当你需要对一组数据进行简单的聚合操作时,
Series可以直接应用这些操作。
示例:
# 创建一个 Series
sales = pd.Series([100, 200, 300, 400])# 求和
total_sales = sales.sum()
print(total_sales) # 输出: 1000
7. 与其他数据结构的集成
DataFrame的每一列实际上是一个Series,因此在处理DataFrame时,经常会单独处理其中的某一列作为Series。
示例:
# 创建一个 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': ['a', 'b', 'c']
})# 获取列 A 作为一个 Series
column_a = df['A']
print(column_a)
输出:
0 1
1 2
2 3
Name: A, dtype: int64
总结
你应该使用 Series 的情况包括但不限于:
- 处理单一类型的一维数据集。
- 进行简单的时间序列分析。
- 执行基本的统计计算。
- 数据清洗和预处理。
- 需要灵活的标签索引或字符串操作。
- 从
DataFrame中提取某一列进行单独处理。
Series 简单且高效,**适用于大多数需要处理一维数据的情况。**如果你的数据集更为复杂,涉及多个变量和多维数据,则应考虑使用 DataFrame。然而,即使在这种情况下,Series 仍然可以作为 DataFrame 的一部分被频繁使用。
总结
- Series 是 Pandas 中最基础的数据结构,适合处理单一类型的线性数据。
- DataFrame 则是一个更复杂的二维数据结构,能够处理多种不同类型的数据,并提供丰富的数据操作功能。
选择使用 Series 还是 DataFrame 取决于你的具体需求:
- 如果你只需要处理一维数据,
Series是更合适的选择。 - 如果你需要处理多变量的数据集,并且需要进行复杂的数据操作,
DataFrame则更为适用。实际上,DataFrame的每一列都是一个Series,这使得它们之间可以非常方便地进行转换和操作。
相关文章:

Series和 DataFrame是 Pandas 库中的两种核心数据结构
Series 和 DataFrame 是 Pandas 库中的两种核心数据结构,它们各有特点和用途。理解它们之间的区别有助于更高效地进行数据分析和处理。以下是 Series 和 DataFrame 的主要区别: 1. 维度 Series:是一维的数组,可以存储任何类型的…...

关于异步消息队列的详细解析,涵盖JMS模式对比、常用组件分析、Spring Boot集成示例及总结
以下是关于异步消息队列的详细解析,涵盖JMS模式对比、常用组件分析、Spring Boot集成示例及总结: 一、异步消息核心概念与JMS模式对比 1. 异步消息核心组件 组件作用生产者发送消息到消息代理(如RabbitMQ、Kafka)。消息代理中间…...

利用 Python 进行股票数据可视化分析
在金融市场中,股票数据的可视化分析对于投资者和分析师来说至关重要。通过可视化,我们可以更直观地观察股票价格的走势、交易量的变化以及不同股票之间的相关性等。 Python 作为一种功能强大的编程语言,拥有丰富的数据处理和可视化库…...

【Docker】离线安装Docker
背景 离线安装Docker的必要性,第一,在目前数据安全升级的情况下,很多外网已经基本不好访问了。第二,如果公司有对外部署的需求,那么难免会存在对方只有内网的情况,那么我们就要做到学会离线安装。 下载安…...

kubectl命令补全以及oc命令补全
kubectl命令补全 1.安装bash-completion 如果你用的是Bash(默认情况下是),先安装补全功能支持包 sudo apt update sudo apt install bash-completion -y2.为kubectl 启用补全功能 会话中临时: source <(kubectl completion bash)持久化配置&#x…...

《 C++ 点滴漫谈: 三十三 》当函数成为参数:解密 C++ 回调函数的全部姿势
一、前言 在现代软件开发中,“解耦” 与 “可扩展性” 已成为衡量一个系统架构优劣的重要标准。而在众多实现解耦机制的技术手段中,“回调函数” 无疑是一种高效且广泛使用的模式。你是否曾经在编写排序算法时,希望允许用户自定义排序规则&a…...
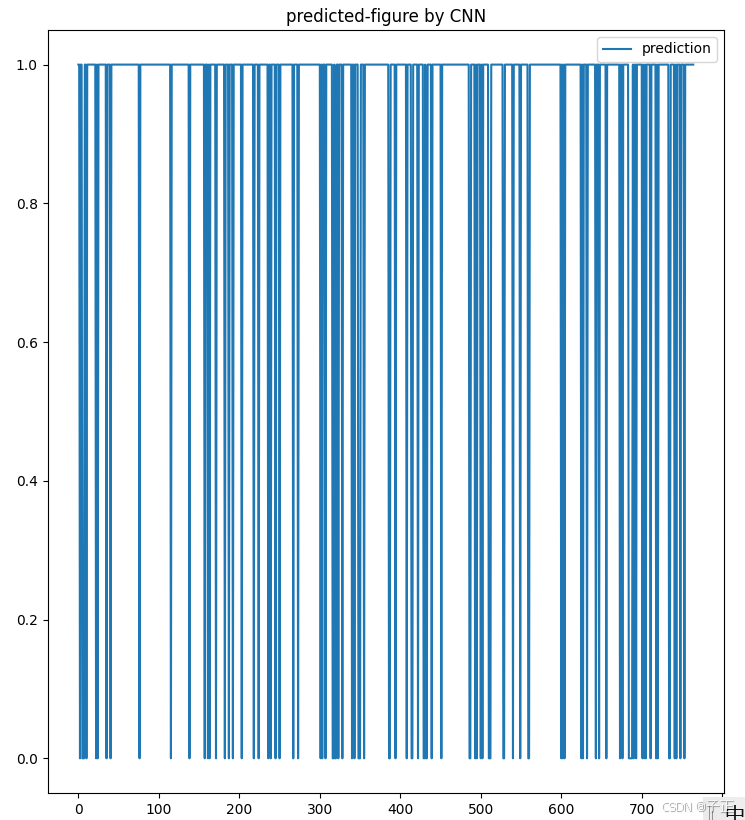
极简cnn-based手写数字识别程序
1.先看看识别效果: 这个程序识别的是0~9的一组手写数字,这是最终的识别效果,为1,代表识别成功,0为失败。 然后数据源是:ds deeplake.load(hub://activeloop/optical-handwritten-digits-train)里面是一组…...
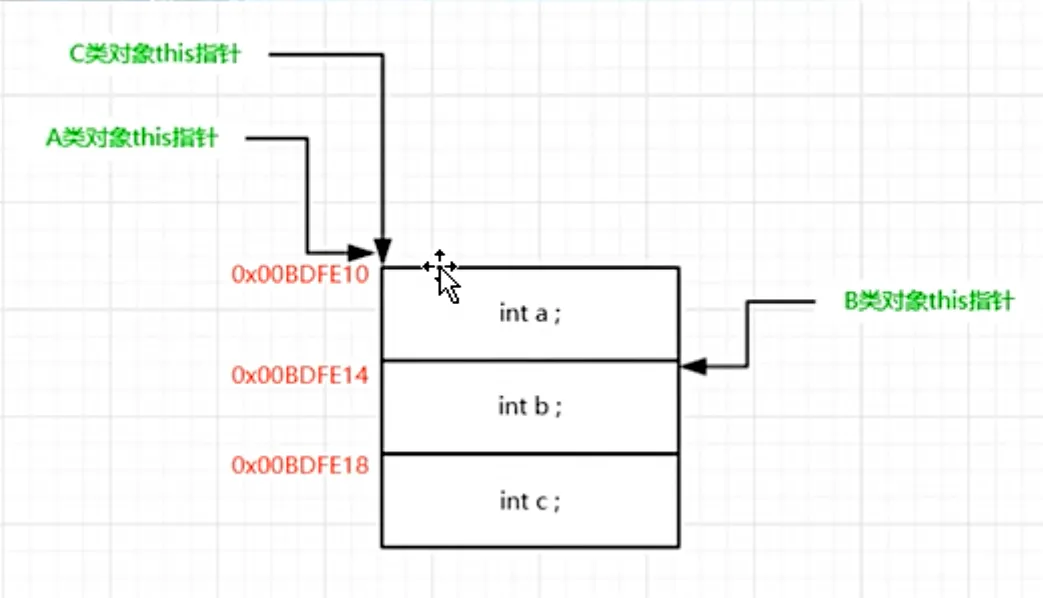
C++核心机制-this 指针传递与内存布局分析
示例代码 #include<iostream> using namespace std;class A { public:int a;A() {printf("A:A()的this指针:%p!\n", this);}void funcA() {printf("A:funcA()的this指针:%p!\n", this);} };class B { public:int b;B() {prin…...

vue3 history路由模式刷新页面报错问题解决
在使用history路由模式时刷新网页提示404错误,这是改怎么办呢。 官方解决办法 https://router.vuejs.org/zh/guide/essentials/history-mode.html...

PHP爬虫教程:使用cURL和Simple HTML DOM Parser
一个关于如何使用PHP的cURL和HTML解析器来创建爬虫的教程,特别是处理代理信息的部分。首先,我需要确定用户的需求是什么。可能他们想从某个网站抓取数据,但遇到了反爬措施,需要使用代理来避免被封IP。不过用户没有提到具体的目标网…...
)
Web前端开发——格式化文本与段落(上)
一、学习目标 网页内容的排版包括文本格式化、段落格式化和整个页面的格式化,这是设计个网页的基础。文本格式化标记分为字体标记、文字修饰标记。字体标记和文字修饰标记包括对于字体样式的一些特殊修改。段落格式化标记分为段落标记、换行记、水平分隔线标记等。…...

技术方案选型要考虑哪些点?
在概要设计阶段,技术方案选型是核心环节之一,需综合考虑系统需求、技术可行性、团队能力及长期维护成本。以下是技术方案选型需包含的核心内容及设计要点,结合行业实践和搜索结果中的方法论: 理论 一、系统架构选型 整体架构模式…...

前端工程化之自动化构建
自动化构建 自动化构建的基本知识历史云构建 和 自动化构建 的区别:部署环境:构建:构建产物构建和打包的性能优化页面加载优化构建速度优化 DevOps原则反馈的技术实践 encode-bundlepackage.json解读src/cli-default.tssrc/cli-node.tssrc/cl…...

3.2.2.1 Spring Boot配置静态资源映射
在Spring Boot中配置静态资源映射,可以通过默认路径或自定义配置实现。默认情况下,Spring Boot会在classpath:/static/等目录下查找静态资源。若需自定义映射,可通过实现WebMvcConfigurer接口的addResourceHandlers方法或在全局配置文件中设置…...
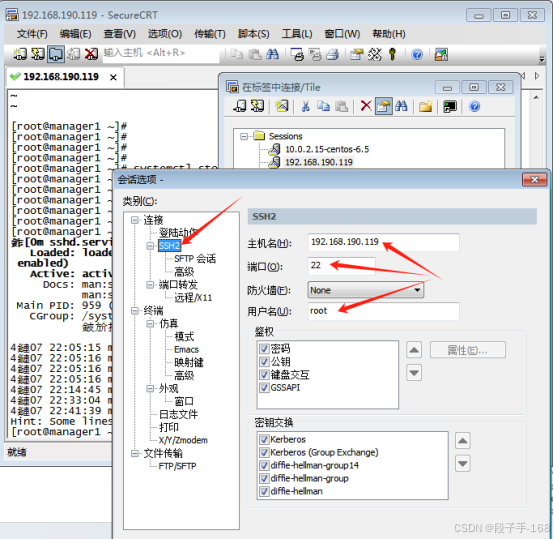
# 更换手机热点后secureCRT无法连接centOS7系统
更换手机热点后secureCRT无法连接centOS7系统 一、问题描述 某些情况下,我们可能使用手机共享热点而给电脑联网。本来用一个手机热点共享网络时,SecureCRT可以正常连接到CentOS 7虚拟机,当更换一个手机热点时,突然发现SecureCR…...

【高性能缓存Redis_中间件】三、redis 精通:性能优化与生产实践
一、引言 在前两篇 Redis 消息队列的文章中,我们掌握了基础使用和高级特性。本文作为系列终篇,将聚焦生产环境的性能优化与全流程实践,请各位跟随小编的步伐一起构建高可靠、高性能的消息处理系统(文章中的演示均为Centos7的背…...

jupyter notebook 无法启动- markupsafe导致
一、运行jupyter notebook和Spyder报错:(已安装了Anaconda,以前可打开) 1.背景:为了部署机器学习模型,按教程直接安装了flask 和markupsafe,导致jupyter notebook,Spyder 打不开。 pip install flas…...

Kotlin作用域函数
在 Kotlin 中,.apply 是一个 作用域函数(Scope Function),它允许你在一个对象的上下文中执行代码块,并返回该对象本身。它的设计目的是为了 对象初始化 或 链式调用 时保持代码的简洁性和可读性。 // 不使用 apply va…...

设计模式:工厂方法模式 - 高扩展性与低耦合的设计之道
一、为什么需要工厂方法模式? 在软件开发中,对象创建与使用耦合会影响系统的灵活性和扩展性。以通知系统(支持邮件通知、短信通知和推送通知)为例 :直接实例化。 Notification email new EmailNotification(); Noti…...
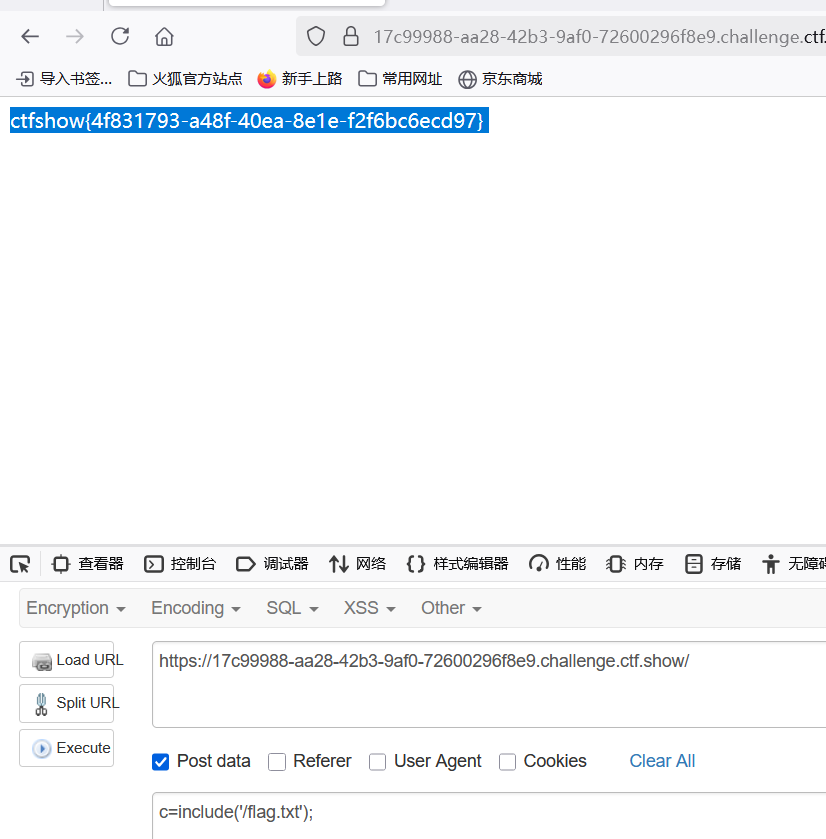
CTF web入门之命令执行 完整版
web29 文件名过滤 由于flag被过滤,需要进行文件名绕过,有以下几种方法: 1.通配符绕过 fla?.* 2.反斜杠绕过 fl\ag.php 3.双引号绕过 fl’‘ag’.php 还有特殊变量$1、内联执行等 此外 读取文件利用cat函数,输出利用system、passthru 、echo echo `nl flag.php`; ec…...

自然语言处理spaCy
spaCy 是一个流行的开源 自然语言处理(NLP) 库,专注于 高效、易用和工业化应用。它由 Explosion AI 开发,广泛应用于文本处理、信息提取、机器翻译等领域。 zh_core_web_sm 是 spaCy 提供的一个小型中文预训练语言模型࿰…...

在spark中,窄依赖算子map和filter会组合为一个stage,这种情况下,map和filter是在一个task内进行的吗?
在 Spark 中,当 map 和 filter 这类窄依赖(Narrow Dependency)的算子连续应用时,它们会被合并到同一个 Stage 中,并且在同一个 Task 内按顺序执行。这种优化称为 流水线(Pipeline)执行ÿ…...

MySQL切换PolarDB-X方案
一、DTS 增量同步完成后的流量切换策略 1. 切换期间的数据写入处理 • 场景:DTS 增量同步完成(Lag0)后,业务流量切换到 PolarDB-X 的瞬间可能产生 2-3 秒延迟,导致部分订单仍写入 MySQL。 • 解决方案: ◦…...

Java 开发工具:从 Eclipse 到 IntelliJ IDEA 的进化之路
Java 开发工具:从 Eclipse 到 IntelliJ IDEA 的进化之路 在 Java 开发的历史长河中,开发工具的演变不仅改变了程序员的编码方式,也深刻影响了整个行业的开发效率和代码质量。从 Eclipse 到 IntelliJ IDEA,这不仅是工具的更替&…...
GPT - 2 文本生成任务全流程
数据集下载 数据预处理 import json import pandas as pdall_data []with open("part-00018.jsonl",encoding"utf-8") as f:for line in f.readlines():data json.loads(line)all_data.append(data["text"])batch_size 10000for i in ran…...

红宝书第四十三讲:基于资料的数据可视化工具简单介绍:D3.js 与 Canvas绘图
红宝书第四十三讲:基于资料的数据可视化工具简单介绍:D3.js 与 Canvas绘图12 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、D3.js:数据驱动文档的王者 1 核心特性&#x…...
)
UI基础(1)
quit和close的区别: driver.close():关闭当前正在使用的窗口。 1、如果你的当前浏览器窗口只有一个情况下,它就会关闭窗口并且关闭浏览器 2、如果你的当前浏览器窗口有多个的情况下,它就会关闭driver驱动焦点所在的窗口 driver.quit():真正关闭浏览器(把所有的窗口都关闭…...

深入理解 Vue 的数据代理机制
何为数据代理? 通过一个对象代理对另一个对象中的属性的操作(读/写),就是数据代理。 要搞懂Vue数据代理这个概念,那我们就要从Object.defineProperty()入手 Object.defineProperty()是Vue中比较底层的一个方法&…...
)
封装,继承,多态(续)
在Java中,最基础的三原则无疑是封装,继承,多态 对于这三类,最基本同样最重要,我们是会经常遇到的,在编程中,会使用,但在考试中还有一定的不理解。 对于这点,我在这里进…...
Java excel导入/导出导致内存溢出问题,以及解决方案
excel导入/导出导致内存溢出问题,以及解决方案 1、内存溢出问题导入功能重新修正,采用SAX的流式解析数据。并结合业务流程。导出功能:由于精细化了业务流程,导致比较代码比较冗杂,就只放出最简单的案例。 1、内存溢出问…...