GPT - 2 文本生成任务全流程
数据集下载
数据预处理
import json
import pandas as pdall_data = []with open("part-00018.jsonl",encoding="utf-8") as f:for line in f.readlines():data = json.loads(line)all_data.append(data["text"])batch_size = 10000for i in range(0,len(all_data),batch_size):begin = iend = i + batch_sizedf = pd.DataFrame({"content":all_data[begin:end]})df.to_csv(f"./data/{i}.csv",index=False)GPT-2 模型的配置
这部分代码的功能是初始化一个 GPT-2 模型的配置对象 GPT2Config,该对象将用于后续创建 GPT-2 模型实例。
方式一:在线配置
config = GPT2Config.from_pretrained("openai-community/gpt2",vocab_size=len(tokenizer),n_ctx=context_length,bos_token_id = tokenizer.bos_token_id,eos_token_id = tokenizer.eos_token_id,)
方式二:复制官网配置文件到本地
创建本地文件夹
复制官网配置文件到本地https://huggingface.co/openai-community/gpt2/blob/main/config.json
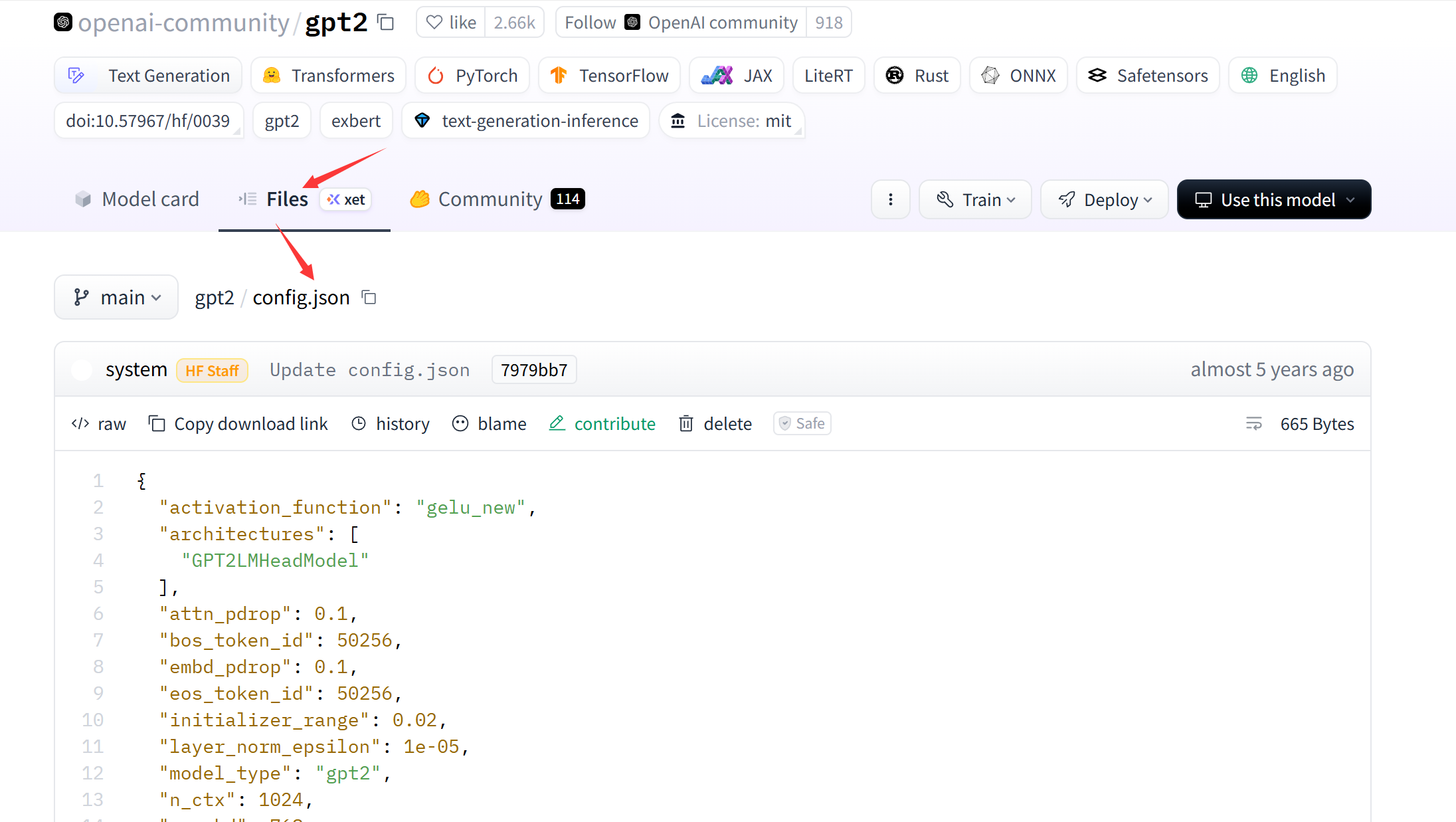
{"activation_function": "gelu_new","architectures": ["GPT2LMHeadModel"],"attn_pdrop": 0.1,"bos_token_id": 50256,"embd_pdrop": 0.1,"eos_token_id": 50256,"initializer_range": 0.02,"layer_norm_epsilon": 1e-05,"model_type": "gpt2","n_ctx": 1024,"n_embd": 768,"n_head": 12,"n_layer": 12,"n_positions": 1024,"resid_pdrop": 0.1,"summary_activation": null,"summary_first_dropout": 0.1,"summary_proj_to_labels": true,"summary_type": "cls_index","summary_use_proj": true,"task_specific_params": {"text-generation": {"do_sample": true,"max_length": 50}},"vocab_size": 50257
}config = GPT2Config.from_pretrained("config/gpt2.config",vocab_size=len(tokenizer),n_ctx=context_length,bos_token_id = tokenizer.bos_token_id,eos_token_id = tokenizer.eos_token_id,)
模型映射、模型训练
from glob import glob
import os
from torch.utils.data import Dataset
from datasets import load_dataset
import random
from transformers import BertTokenizerFast
from transformers import GPT2Config
from transformers import GPT2LMHeadModel
from transformers import DataCollatorForLanguageModeling
from transformers import Trainer,TrainingArgumentsdef tokenize(element):outputs = tokenizer(element["content"],truncation=True,max_length=context_length,return_overflowing_tokens=True,return_length=True)input_batch = []for length,input_ids in zip(outputs["length"],outputs["input_ids"]):if length == context_length:input_batch.append(input_ids)return {"input_ids":input_batch}if __name__ == "__main__":random.seed(1002)test_rate = 0.2context_length = 128all_files = glob(pathname=os.path.join("data","*"))test_file_list = random.sample(all_files,int(len(all_files)*test_rate))train_file_list = [i for i in all_files if i not in test_file_list]raw_datasets = load_dataset("csv",data_files={"train":train_file_list,"vaild":test_file_list},cache_dir="cache_data")tokenizer = BertTokenizerFast.from_pretrained("D:/bert-base-chinese")tokenizer.add_special_tokens({"bos_token":"[begin]","eos_token":"[end]"})tokenize_datasets = raw_datasets.map(tokenize,batched=True,remove_columns=raw_datasets["train"].column_names)config = GPT2Config.from_pretrained("config/gpt2.config",vocab_size=len(tokenizer),n_ctx=context_length,bos_token_id = tokenizer.bos_token_id,eos_token_id = tokenizer.eos_token_id,)model = GPT2LMHeadModel(config)model_size = sum([ t.numel() for t in model.parameters()])print(f"model_size: {model_size/1000/1000} M")data_collator = DataCollatorForLanguageModeling(tokenizer,mlm=False)args = TrainingArguments(learning_rate=1e-5,num_train_epochs=100,per_device_train_batch_size=10,per_device_eval_batch_size=10,eval_steps=2000,logging_steps=2000,gradient_accumulation_steps=5,weight_decay=0.1,warmup_steps=1000,lr_scheduler_type="cosine",save_steps=100,output_dir="model_output",fp16=True,)trianer = Trainer(model=model,args=args,tokenizer=tokenizer,data_collator=data_collator,train_dataset=tokenize_datasets["train"],eval_dataset=tokenize_datasets["vaild"])trianer.train()文本生成交互界面
from transformers import GPT2LMHeadModel,BertTokenizerFast
import ostokenizer = BertTokenizerFast.from_pretrained("bert-base-chinese")
model_path = os.path.join("model_output","checkpoint-100")model = GPT2LMHeadModel.from_pretrained(model_path,pad_token_id=tokenizer.pad_token_id)
model = model.to("cuda")while True:input_text = input("请输入:")input_ids = tokenizer.encode(input_text,return_tensors="pt")input_ids = input_ids.to("cuda")output = model.generate(input_ids,max_length=400,num_beams=5,repetition_penalty=1,early_stopping=True)output_text = tokenizer.decode(output[0],skip_special_tokens=True)print(f"输出:{output_text}")
相关文章:
GPT - 2 文本生成任务全流程
数据集下载 数据预处理 import json import pandas as pdall_data []with open("part-00018.jsonl",encoding"utf-8") as f:for line in f.readlines():data json.loads(line)all_data.append(data["text"])batch_size 10000for i in ran…...

红宝书第四十三讲:基于资料的数据可视化工具简单介绍:D3.js 与 Canvas绘图
红宝书第四十三讲:基于资料的数据可视化工具简单介绍:D3.js 与 Canvas绘图12 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、D3.js:数据驱动文档的王者 1 核心特性&#x…...
)
UI基础(1)
quit和close的区别: driver.close():关闭当前正在使用的窗口。 1、如果你的当前浏览器窗口只有一个情况下,它就会关闭窗口并且关闭浏览器 2、如果你的当前浏览器窗口有多个的情况下,它就会关闭driver驱动焦点所在的窗口 driver.quit():真正关闭浏览器(把所有的窗口都关闭…...

深入理解 Vue 的数据代理机制
何为数据代理? 通过一个对象代理对另一个对象中的属性的操作(读/写),就是数据代理。 要搞懂Vue数据代理这个概念,那我们就要从Object.defineProperty()入手 Object.defineProperty()是Vue中比较底层的一个方法&…...
)
封装,继承,多态(续)
在Java中,最基础的三原则无疑是封装,继承,多态 对于这三类,最基本同样最重要,我们是会经常遇到的,在编程中,会使用,但在考试中还有一定的不理解。 对于这点,我在这里进…...
Java excel导入/导出导致内存溢出问题,以及解决方案
excel导入/导出导致内存溢出问题,以及解决方案 1、内存溢出问题导入功能重新修正,采用SAX的流式解析数据。并结合业务流程。导出功能:由于精细化了业务流程,导致比较代码比较冗杂,就只放出最简单的案例。 1、内存溢出问…...

10 个最新 CSS 功能已在所有主流浏览器中得到支持
前言 CSS 不断发展,新功能使我们的工作更快、更简洁、更强大。得益于最新的浏览器改进(Baseline 2024),许多新功能现在可在所有主要引擎上使用。以下是您可以立即开始使用的10 CSS新功能。 1. Scrollbar-Gutter 和 Scrollbar-Co…...
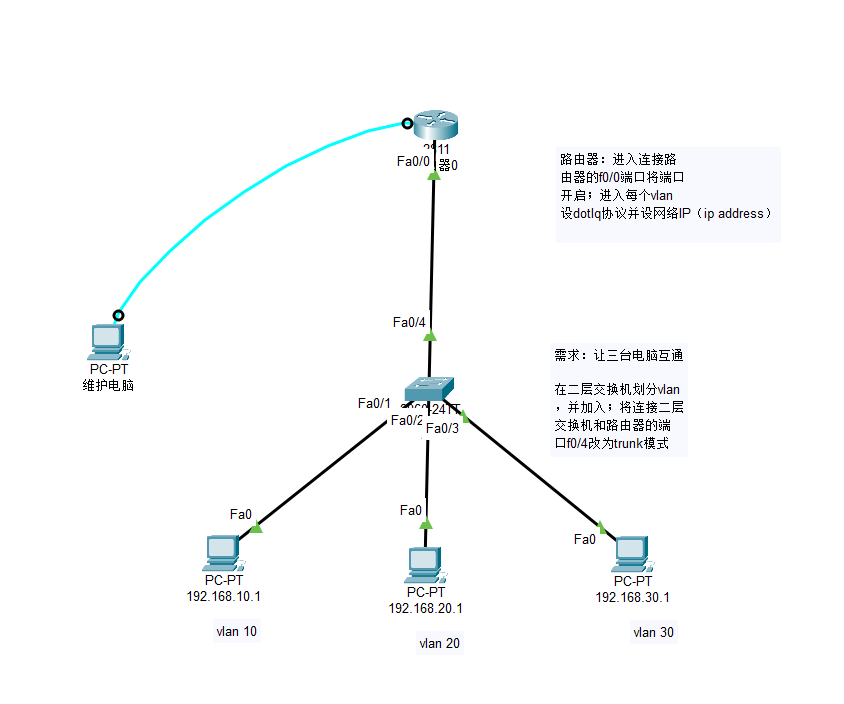
思科模拟器的单臂路由,交换机,路由器,路由器只要两个端口的话,连接三台电脑该怎么办,划分VLAN,dotlq协议
单臂路由 1. 需求:让三台电脑互通 2. 在二层交换机划分vlan,并加入; 3. 将连接二层交换机和路由器的端口f0/4改为trunk模式 4. 路由器:进入连接路由器的f0/0端口将端口开启 5. 进入每个vlan设dotlq协议并设网络IP(…...
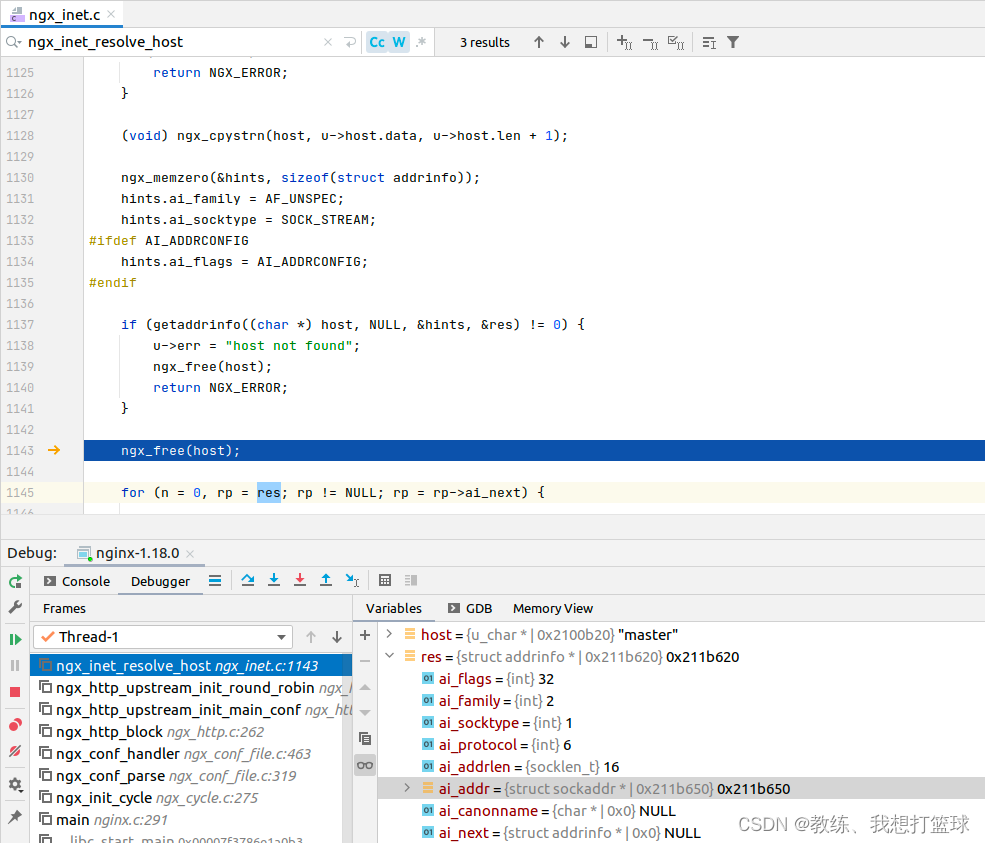
14 nginx 的 dns 缓存的流程
前言 这个是 2020年11月 记录的这个关于 nginx 的 dns 缓存的问题 docker 环境下面 前端A连到后端B 前端B连到后端A 最近从草稿箱发布这个问题的时候, 重新看了一下 发现该问题的记录中仅仅是 定位到了 nginx 这边的 dns 缓存的问题, 但是 并没有到细节, 没有到 具体的 n种…...
实战教程:使用JetBrians Rider快速部署与调试PS5和Xbox上的UE项目
面向主机游戏开发者的重大新闻!在2024.3版本中,JetBrains Rider 增加了对 PlayStation5 和 Xbox 游戏主机的支持,您可以直接在您喜欢的游戏主机上构建、部署和调试 Unreal Engine 和自定义游戏引擎。 JetBrains Rider现在支持主机游戏开发&am…...

大型语言模型中中医知识的多模态基准数据集
下载链接: https://github.com/pariskang/ZhongJing-OMNI https://github.com/pariskang/ZhongJing-OMNI 下载链接 https://github.com/pariskang/ZhongJing-OMNI.git 链接失效反馈 资源简介: ZhongJing-OMNI是第一个用于评估大型语言模型中中医知…...
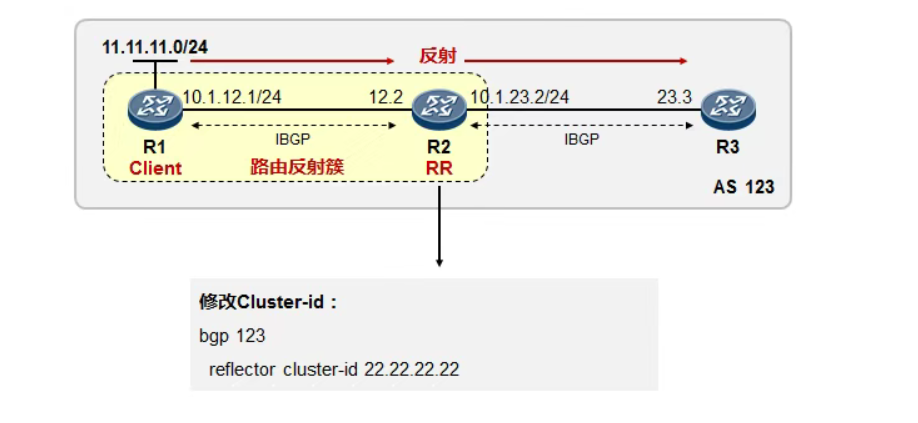
专题十五:动态路由——BGP
一、BGP的基本概念 BGP(Border Gateway Protocol,边界网关协议)是一种用于在不同自治系统(AS)之间交换路由信息的外部网关协议(EGP)。通过TCP179端口建立连接。目前采用BGP4版本,IP…...

Linux命令-vim编辑
用vi或vim命令进入vim编辑器。 基础: u 撤销上一次操作。x剪切当前光标所在处的字符。yy复制当前行。dd剪切当前行。p粘贴剪贴板内容到光标下方。i切换到输入模式,在光标当前位置开始输入文本。:wq保存并退出Vim 编辑器。:q!不保存强制退出Vim 编辑器。 拓展: w光…...
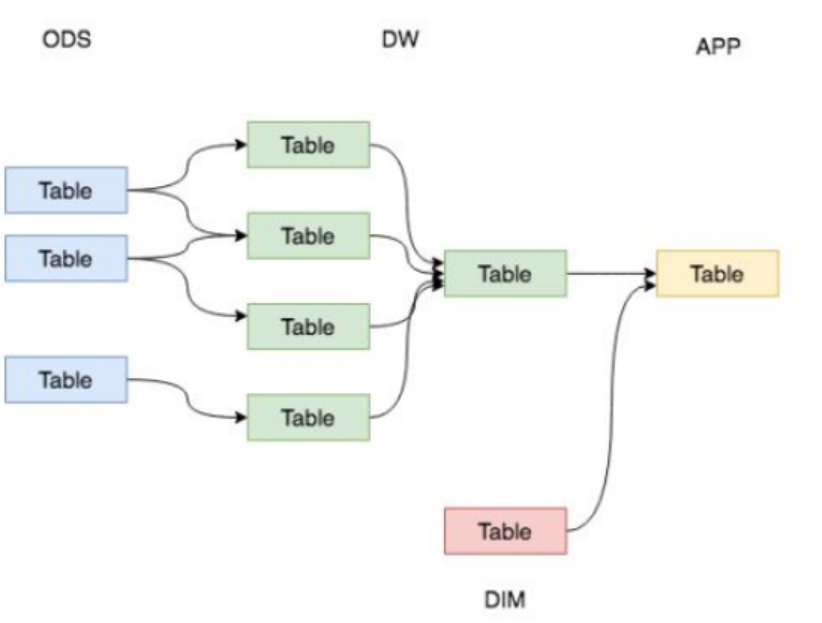
hive数仓要点总结
1.OLTP和OLAP区别 OLTP(On-Line Transaction Processing)即联机事务处理,也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用…...

一款安全好用的企业即时通讯平台,支持统一门户
在数字化转型的浪潮中,企业面临着信息孤岛、系统分散、协作低效等诸多挑战。BeeWorks作为一款专为企业打造的数字化底座平台,凭借其强大的企业内部应用集成能力和单点登录功能,正在成为企业数字化转型的有力推手。 数字化底座平台࿱…...
git安装(windows)
通过网盘分享的文件:资料(1) 链接: https://pan.baidu.com/s/1MAenYzcQ436MlKbIYQidoQ 提取码: evu6 点击next 可修改安装路径 默认就行 一般从命令行调用,所以不用创建。 用vscode,所以这么选择。...
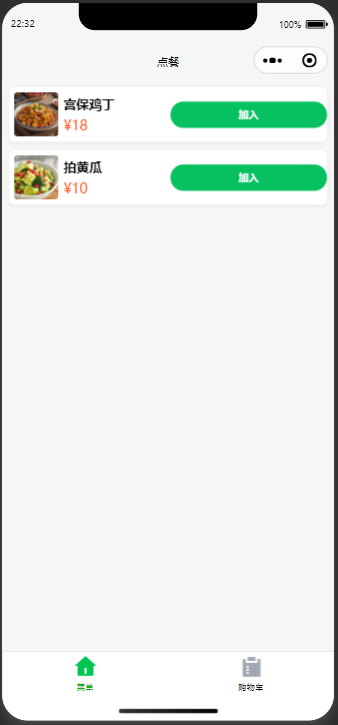
微信小程序实战案例 - 餐馆点餐系统 阶段1 - 菜单浏览
阶段 1 – 菜单浏览(超详细版) 目标:完成「首页=菜品卡片列表」 打好 UI 地基会从 云数据库 拉取 categories / dishes 并渲染打 Git Tag v1.0‑menu 1. 技术/知识点速览 知识点关键词说明云数据库db.collection().where().…...

Dashboard的安装和基本使用
1.Dashboard简介: Dashboard是Kubernetes的Web图形用户界面(GUI),它为用户提供了一个直观的方式来管理和监控Kubernetes集群。 2.实验基础和前置条件: 本实验以Kubernetes集群环境搭建与初始化-CSDN博客为基础和前置…...

英语单词 list 11
前言 这一个 list 是一些简单的单词。感觉这个浏览单词的方法比较低效,所以准备每天最多看一个 list ,真要提升英语水平,感觉还是得直接做阅读理解题。就像我们接触中文阅读材料一样,当然光知道这个表面意思还不够,还…...

JAVA基础 - 高效管理线程隔离数据结构ThreadLocalMap
欢迎光临小站:致橡树 ThreadLocalMap 是 ThreadLocal 的核心底层数据结构,负责在每个线程中存储与 ThreadLocal 实例绑定的数据。它的设计目标是高效管理线程隔离数据,同时尽量减少内存泄漏风险。以下是其核心实现细节。 数据结构与设计目标…...

DeepSeek 接入 Word 完整教程
一、前期准备 1.1 注册并获取 API 密钥 访问 DeepSeek 平台: 打开浏览器,访问 DeepSeek 官方网站(或您使用的相应平台)。注册并登录您的账户。 创建 API 密钥: 在用户控制面板中,找到“API Keys”或“API…...
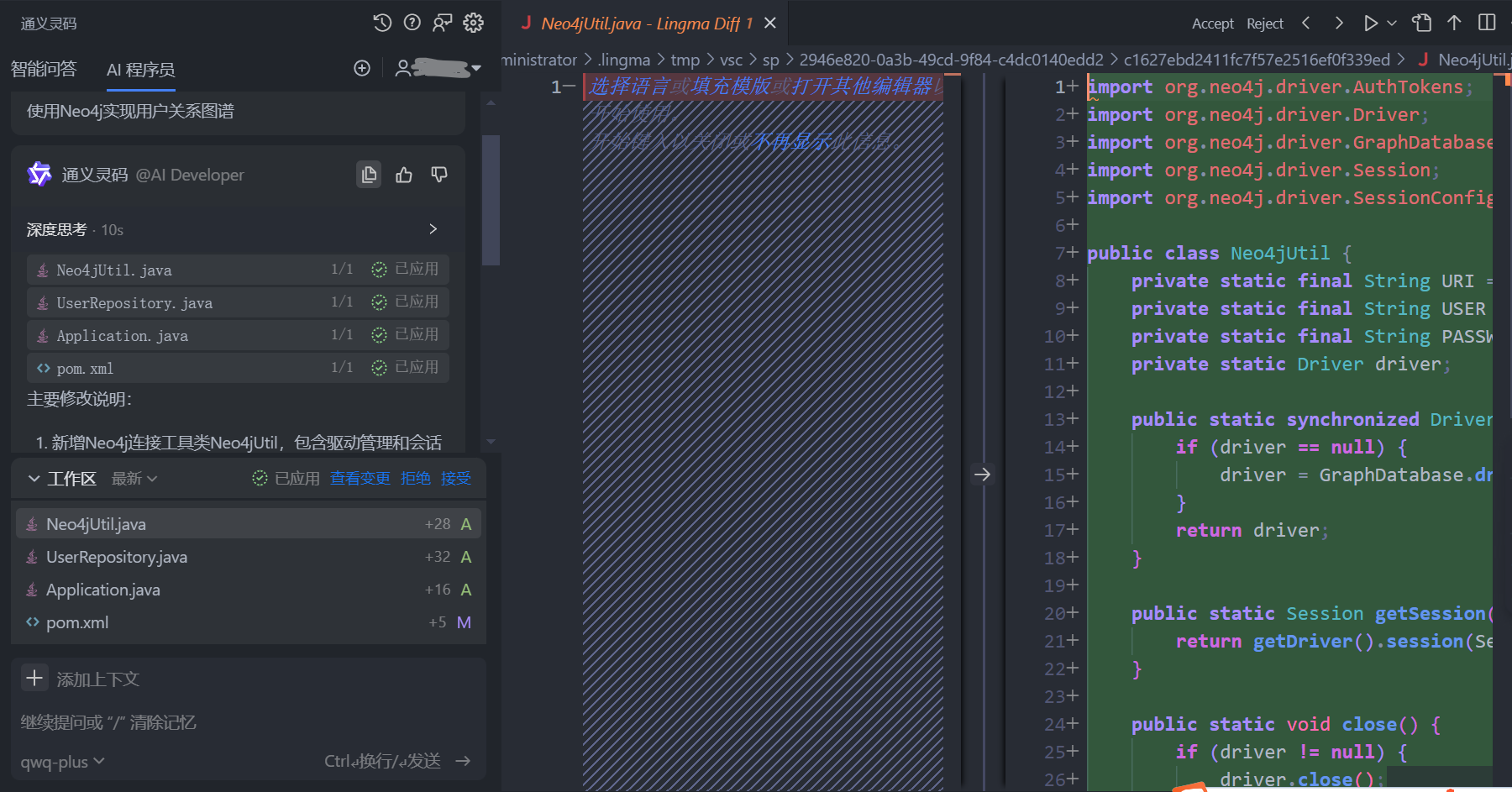
通义灵码助力Neo4J开发:快速上手与智能编码技巧
在 Web 应用开发中,Neo4J 作为一种图数据库,用于存储节点及节点间的关系。当图结构复杂化时,关系型数据库的查找效率会显著降低,甚至无法有效查找,这时 Neo4J 的优势便凸显出来。然而,由于其独特的应用场景…...

高性能文件上传服务
高性能文件上传服务 —— 您业务升级的不二选择 在当今互联网数据量激增、文件体积日益庞大的背景下,高效、稳定的文件上传方案显得尤为重要。我们的文件分块上传服务端采用业界领先的 Rust HTTP 框架 Hyperlane 开发,凭借其轻量级、低延时和高并发的特…...

p2p的发展
PCDN(P2P内容分发网络)行业目前处于快速发展阶段,面临机遇与挑战并存的局面。 一、发展机遇 技术融合推动 边缘计算与5G普及:5G的高带宽、低延迟特性与边缘计算技术结合,显著提升PCDN性能,降低延迟&#x…...

Java Lambda 表达式详解:发展史、语法、使用场景及代码示例
Java Lambda 表达式详解:发展史、语法、使用场景及代码示例 1. Lambda 表达式的发展史 背景与动机 JDK 7 前:Java的匿名内部类虽强大,但代码冗余(如事件监听器、集合遍历)。JDK 8(2014)&#…...
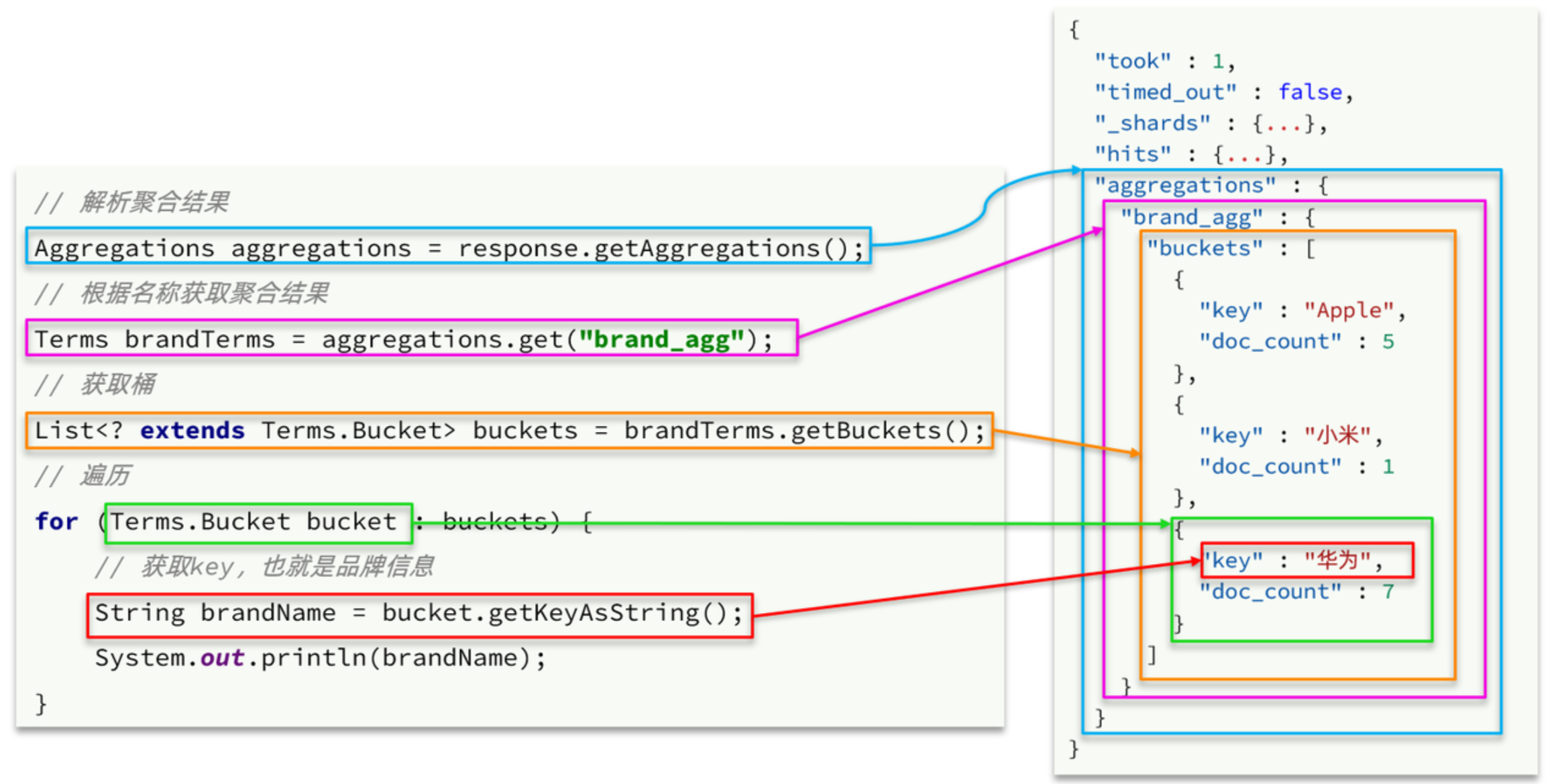
【从0到1学Elasticsearch】Elasticsearch从入门到精通(下)
我们在【从0到1学Elasticsearch】Elasticsearch从入门到精通(上)这边文章详细讲解了如何创建索引库和文档及javaAPI操作,但是在实战当中,我们还需要根据一些特殊字段对文档进行查找搜索,仅仅靠id查找文档是显然不够的。…...
Python实现贪吃蛇二
上篇文章Python实现贪吃蛇一,实现了一个贪吃蛇的基础版本,但存在一些不足,也缺乏一些乐趣。本篇文章将对其进行一些改进,主要修改/实现以下几点: 1、解决食物随机生成的位置与蛇身重合问题 2、蛇身移动加速/减速功能 3…...

使用pybind11开发c++扩展模块输出到控制台的中文信息显示乱码的问题
使用pybind11开发供Python项目使用的C++扩展模块时,如果在扩展模块的C++代码中向控制台输出的信息中包含中文,python程序的控制台很容易出现乱码。以如下C++扩展框架代码为例(这是对上一篇文章简明使用pybind11开发pythonc+扩展模块教程-CSDN博客中的C++扩展框架代码进行少量…...

基于51单片机的正负5V数字电压表( proteus仿真+程序+设计报告+讲解视频)
基于51单片机的正负5V数字电压表( proteus仿真程序设计报告讲解视频) 仿真图proteus7.8及以上 程序编译器:keil 4/keil 5 编程语言:C语言 设计编号:S0101 1. 主要功能: 设计一个基于51单片机数字电压表 1、能够…...

Java雪花算法
以下是用Java实现的雪花算法代码示例,包含详细注释和异常处理: 代码下面有解析 public class SnowflakeIdGenerator {// 起始时间戳(2020-01-01 00:00:00)private static final long START_TIMESTAMP 1577836800000L;// 各部分…...