Python----机器学习(基于PyTorch的乳腺癌逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。
一、数据集介绍
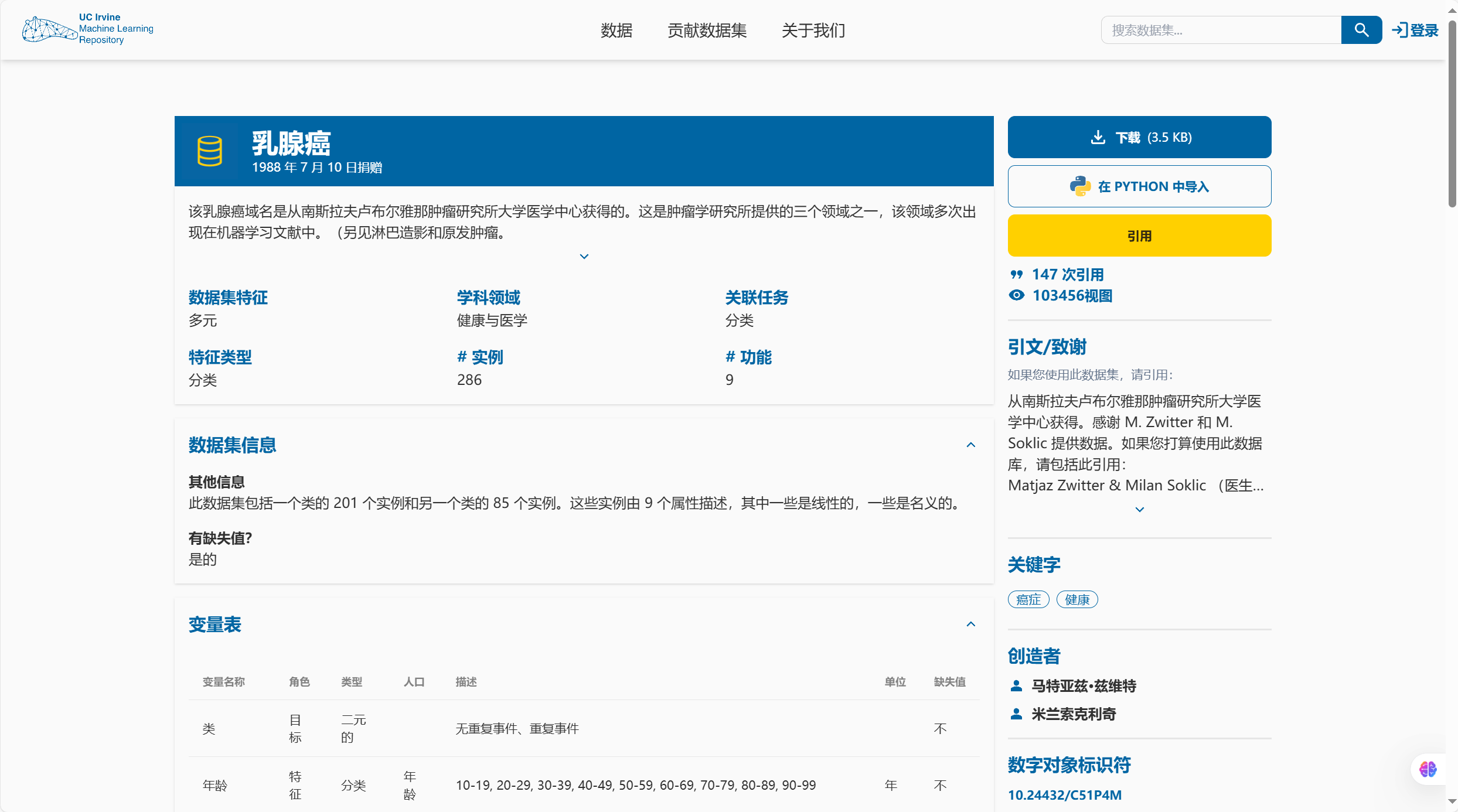
在本例中,使用了乳腺癌数据集 Breast Cancer - UCI Machine Learning Repository,其中包含 关于病人的信息,目标是预测肿瘤是否为无复发事件(no-recurrence-events)或有复发事件 (recurrence-events)。
数据集地址
Breast Cancer - UCI Machine Learning Repository
| Variable Name | Role | Type | Demographic | Description | Units | Missing Values |
|---|---|---|---|---|---|---|
| Class | Target | Binary | no-recurrence-events, recurrence-events | no | ||
| age | Feature | Categorical | Age | 10-19, 20-29, 30-39, 40-49, 50-59, 60-69, 70-79, 80-89, 90-99 | years | no |
| menopause | Feature | Categorical | lt40, ge40, premeno | no | ||
| tumor-size | Feature | Categorical | 0-4, 5-9, 10-14, 15-19, 20-24, 25-29, 30-34, 35-39, 40-44, 45-49, 50-54, 55-59 | no | ||
| inv-nodes | Feature | Categorical | 0-2, 3-5, 6-8, 9-11, 12-14, 15-17, 18-20, 21-23, 24-26, 27-29, 30-32, 33-35, 36-39 | no | ||
| node-caps | Feature | Binary | yes, no | yes | ||
| deg-malig | Feature | Integer | 1, 2, 3 | no | ||
| breast | Feature | Binary | left, right | no | ||
| breast-quad | Feature | Categorical | left-up, left-low, right-up, right-low, central | yes | ||
| irradiat | Feature | Binary | yes, no | no |
其他变量信息
1. 类:no-recurrence-events、recurrence-events
2. 年龄:10-19、20-29、30-39、40-49、50-59、60-69、70-79、80-89、90-99。
3. 更年期:LT40、GE40、Premeno。
4. 肿瘤大小:0-4、5-9、10-14、15-19、20-24、25-29、30-34、35-39、40-44、45-49、50-54、55-59。
5. INV 节点:0-2、3-5、6-8、9-11、12-14、15-17、18-20、21-23、24-26、27-29、30-32、33-35、36-39。
6. node-caps:是的,不是。
7. 度-马利格: 1, 2, 3.
8. 胸部:左、右。
9. 乳房四头肌:左上、左低、右上、右低、中央。
10. Irradiat:是的,不是。
二、设计思路
2.1、读取数据
import pandas as pd
names = ['Class', 'age', 'menopause', 'tumor-size', 'inv-nodes', 'node-caps', 'deg-malig', 'breast', 'breast-quad', 'irradiat']
df=pd.read_table('breast-cancer.data',names=names,sep=',')2.2、数据清洗
import numpy as np
df=df.replace('?',np.nan)
df.dropna(axis=0,inplace=True)2.3、划分特征
X=df.drop(columns=['Class'],axis=1)
y=df['Class']2.4、one-hot独热编码
X=pd.get_dummies(X)2.5、划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.8,random_state=42)2.6、标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_train_scaler=scaler.fit_transform(X_train)
X_test_scaler=scaler.transform(X_test)2.7、特征标签
from sklearn.preprocessing import LabelEncoder
labelencoder=LabelEncoder()
y_train_labelencoder=labelencoder.fit_transform(y_train)
y_test_labelencoder=labelencoder.transform(y_test)2.8、加载逻辑回归模型拟合
from sklearn.linear_model import LogisticRegression
lr=LogisticRegression(C=1e5)
lr.fit(X_train_scaler,y_train_labelencoder)2.9、模型评估
from sklearn.metrics import roc_curve,aucprepro = lr.predict_proba(X_test_scaler)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test_labelencoder, prepro)
roc_auc=auc(fpr,tpr)2.10、可视化
from matplotlib import pylab as plt
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()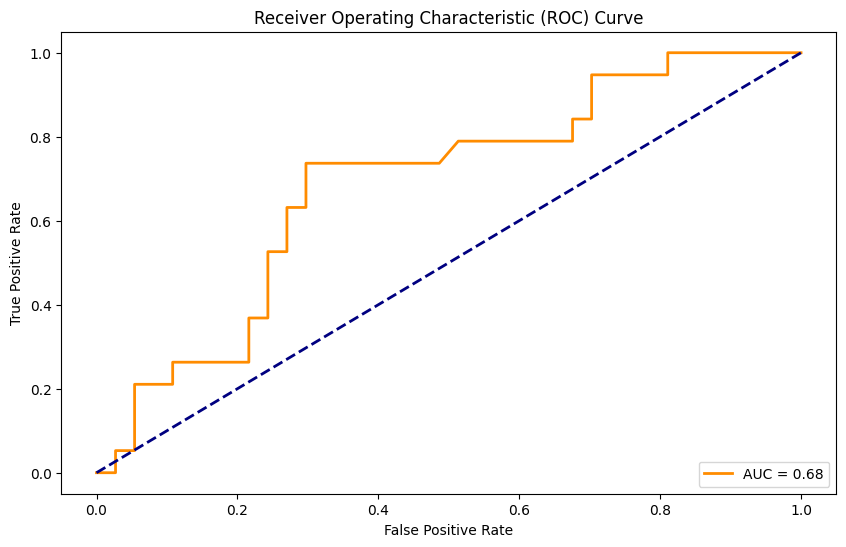
三、完整代码
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import numpy as np
from sklearn.metrics import roc_curve, auc
from sklearn.linear_model import LogisticRegression
from matplotlib import pylab as plt # 定义数据集的列名称
names = ['Class', 'age', 'menopause', 'tumor-size', 'inv-nodes', 'node-caps', 'deg-malig', 'breast', 'breast-quad', 'irradiat'] # 读取数据集,并将第一行作为列名
df = pd.read_table('breast-cancer.data', names=names, sep=',') # 替换缺失值的标记'?'为NaN,并删除含有缺失值的行
df = df.replace('?', np.nan)
df.dropna(axis=0, inplace=True) # 分离特征和目标变量
X = df.drop(columns=['Class'], axis=1) # 特征数据
y = df['Class'] # 目标变量 # 将分类特征进行独热编码
X = pd.get_dummies(X) # 划分训练集和测试集,训练集占80%
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=42) # 数据标准化
scaler = StandardScaler()
X_train_scaler = scaler.fit_transform(X_train) # 对训练数据进行标准化
X_test_scaler = scaler.transform(X_test) # 对测试数据进行同样的标准化 # 标签编码
labelencoder = LabelEncoder()
y_train_labelencoder = labelencoder.fit_transform(y_train) # 将训练标签编码为0/1
y_test_labelencoder = labelencoder.transform(y_test) # 将测试标签编码为0/1 # 实例化逻辑回归模型,正则化参数C设置为1e5
lr = LogisticRegression(C=1e5)
lr.fit(X_train_scaler, y_train_labelencoder) # 训练模型 # 预测测试集中每个样本属于正类的概率
prepro = lr.predict_proba(X_test_scaler)[:, 1]
# 计算ROC曲线
fpr, tpr, thresholds = roc_curve(y_test_labelencoder, prepro)
roc_auc = auc(fpr, tpr) # 计算AUC值 # 绘制ROC曲线
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}') # 绘制ROC曲线
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # 绘制随机猜测的对角线
plt.xlabel('假阳率 (False Positive Rate)') # X轴标签
plt.ylabel('真阳率 (True Positive Rate)') # Y轴标签
plt.title('接收者操作特征 (ROC) 曲线') # 图表标题
plt.legend(loc='lower right') # 图例位置
plt.show() # 显示图表 设计思路
-
数据读取和预处理:
加载数据: 使用
pd.read_table函数读取乳腺癌数据集,指定数据分隔符为逗号,并为每列定义合适的列名,增加可读性。处理缺失值: 数据中的缺失值用“?”表示,将其替换为NaN,并使用dropna方法删除所有包含缺失值的行,确保后续分析和建模的数据质量。 -
特征和标签的分离:
分离特征与标签: 将数据集拆分为特征(
X)和目标变量(y),其中X为特征数据,y为类别标签(如“良性”或“恶性”)。 -
类别特征的处理:
独热编码: 使用
pd.get_dummies将分类特征转换为数值型特征,生成更易于模型处理的二进制特征矩阵。独热编码将每个类别值转化为可互斥的二进制值,从而使得模型能够理解分类数据。 -
数据集划分:
训练集与测试集划分: 使用
train_test_split按照80%的比例将数据集分为训练集和测试集,以保障模型训练和验证的有效性。这种方法使得模型能够在独立的数据上进行测试,从而避免过拟合。 -
标准化处理:
数据标准化: 利用
StandardScaler对特征数据进行标准化,使其均值为0,方差为1。这一步骤可以消除特征之间由于量纲不同而带来的影响,从而提高模型的收敛速度和稳定性。 -
标签编码:
编码目标变量: 采用
LabelEncoder对目标变量进行编码,将标签(如“良性”、“恶性”)转换为0和1的数值形式,以便于后续模型的训练。 -
模型训练:
实例化逻辑回归模型: 采用
LogisticRegression类,设置正则化参数C(此处设定为1e5)来控制模型的复杂度。模型训练: 使用标准化后的训练数据对模型进行拟合(fit),建立分类模型。 -
性能评估:
概率预测: 在测试集上使用训练好的逻辑回归模型进行概率预测,通过
predict_proba函数获取分类为正类的概率。计算ROC曲线: 使用roc_curve函数计算真正率(TPR)和假正率(FPR),以评估模型在不同阈值下的性能。计算AUC值: 利用auc函数计算曲线下的面积(Area Under Curve,AUC),作为量化模型性能的指标。 -
可视化效果:
绘制ROC曲线: 使用Matplotlib库绘制ROC曲线,通过可视化手段展示模型在分类任务中的表现,同时标注AUC值以便于理解模型的好坏。图例、标签和标题增强了图表的可读性。
相关文章:
Python----机器学习(基于PyTorch的乳腺癌逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 在本例中&…...

5分钟学会接口自动化测试框架
今天,我们来聊聊接口自动化测试。 接口自动化测试是什么?如何开始?接口自动化测试框架如何搭建? 自动化测试 自动化测试,这几年行业内的热词,也是测试人员进阶的必备技能,更是软件测试未来发…...
基于FreeRTOS和LVGL的多功能低功耗智能手表(APP篇)
目录 一、简介 二、软件框架 2.1 MDK工程架构 2.2 CubeMX框架 2.3 板载驱动BSP 1、LCD驱动 2、各个I2C传感器驱动 3、硬件看门狗驱动 4、按键驱动 5、KT6328蓝牙驱动 2.4 管理函数 2.4.1 StrCalculate.c 计算器管理函数 2.4.2 硬件访问机制-HWDataAccess 2.4.3 …...
)
visual studio 常用的快捷键(已经熟悉的就不记录了)
以下是 Visual Studio 中最常用的快捷键分类整理,涵盖代码编辑、调试、导航等核心场景: 一、生成与编译 生成解决方案 Ctrl Shift B 一键编译整个解决方案,检查编译错误(最核心的生成操作)编译当前文件 Ctrl F…...

学习记录-接口自动化python数据类型
1.字符串 str "字符串" str_1 字符串1 2.列表[ ] list [1,2,3,4,5,6] list_1 ["boy","girl"] 3.字典{ } key:value 键值对 dict {"name":"小林","age":20} 4.元组( ) tuple …...

大语言模型深度思考与交互增强
总则:深度智能交互的全面升级 在主流大语言模型(LLM)与用户的每一次交互中,模型需于回应或调用工具前,展开深度、自然且无过滤的思考进程。当模型判断思考有助于提升回复质量时,必须即时进行全方位的思考与…...

<C#> 详细介绍.NET 依赖注入
在 .NET 开发中,依赖注入(Dependency Injection,简称 DI)是一种设计模式,它可以增强代码的可测试性、可维护性和可扩展性。以下是对 .NET 依赖注入的详细介绍: 1. 什么是依赖注入 在软件开发里࿰…...

布局决定终局:基于开源AI大模型、AI智能名片与S2B2C商城小程序的战略反推思维
摘要:在商业竞争日益激烈的当下,布局与终局预判成为企业成功的关键要素。本文探讨了布局与终局预判的智慧性,强调其虽无法做到百分之百准确,但能显著提升思考能力。终局思维作为重要战略工具,并非一步到位的战略部署&a…...

构建面向大模型训练与部署的一体化架构:从文档解析到智能调度
作者:汪玉珠|算法架构师 标签:大模型训练、数据集构建、GRPO、自监督聚类、指令调度系统、Qwen、LLaMA3 🧭 背景与挑战 随着 Qwen、LLaMA3 等开源大模型不断进化,行业逐渐从“能跑通”迈向“如何高效训练与部署”的阶…...

告别循环!用Stream优雅处理集合
什么是stream? 也叫Stream流,是jdk8新增的一套API(java.util.stream.*)可以用于操作集合或者数组的数据。 优势:Stream流大量的结合了Lambda语法的风格编程,提供了一种更加强大,更加简单的方式…...

Linux电源管理、功耗管理 和 发热管理 (CPUFreq、CPUIdle、RPM、thermal、睡眠 和 唤醒)
1 架构图 1.1 Linux内核电源管理的整体架构 《Linux设备驱动开发详解:基于最新的Linux4.0内核》图19.1 1.2 通用的低功耗软件栈 《SoC底层软件低功耗系统设计与实现》 1.3 低功耗系统的架构设计;图1-3 2 系统级睡眠和唤醒管理 Linux系统的待机、睡眠…...
OSCP - Proving Grounds -FunboxEasy
主要知识点 弱密码路径枚举文件上传 具体步骤 首先是nmap扫描一下,虽然只有22,80和3306端口,但是事情没那么简单 Nmap scan report for 192.168.125.111 Host is up (0.45s latency). Not shown: 65532 closed tcp ports (reset) PORT …...

探索 Go 与 Python:性能、适用场景与开发效率对比
1 性能对比:执行速度与资源占用 1.1 Go 的性能优势 Go 语言被设计为具有高效的执行速度和低资源占用。它编译后生成的是机器码,能够直接在硬件上运行,避免了 Python 解释执行的开销。 以下是一个用 Go 实现的简单循环计算代码: …...
与析构函数(Destructor))
c++:构造函数(Constructor)与析构函数(Destructor)
目录 为什么我们需要构造函数? 什么是构造函数? 🧬 本质:构造函数是“创建对象的一部分” 为什么 需要析构函数? 什么是析构函数? 析构函数的核心作用 ❗注意点 为什么我们需要构造函数?…...

三周年创作纪念日
文章目录 回顾与收获三年收获的五个维度未来的展望致谢与呼唤 亲爱的社区朋友们,大家好! 今天是 2025 年 4 月 14 日,距离我在 2022 年 4 月 14 日发布第一篇技术博客《SonarQube 部署》整整 1,095 天。在这条创作之路上,我既感慨…...
Vue 3 国际化实战:支持 Element Plus 组件和语言持久化
目录 Vue 3 国际化实战:支持 Element Plus 组件和语言持久化实现效果:效果一、中英文切换效果二、本地持久化存储效果三、element Plus国际化 vue3项目国际化实现步骤第一步、安装i18n第二步、配置i18n的en和zh第三步:使用 vue-i18n 库来实现…...

1.阿里云快速部署Dify智能应用
一、宝塔面板 宝塔面板是一款功能强大且易于使用的服务器管理软件,支持Linux和Windows系统,通过web端可视化操作,优化了建站流程,提供安全管理、计划任务、文件管理以及软件管理等功能。 1.1 宝塔面板的特点与优势 易用性 宝塔面…...

Ubuntu与windows时间同步
由于ubuntu每次重启后时间老是不对,所以使用ntp服务,让ubuntu作为客户端,去同步windows时间。 一、windows服务端配置 1、启用ntp服务 # 启动W32Time服务(若未启动) net start w32time # 配置服务为NTP模式 w32tm /…...

在pycharm配置虚拟环境和jupyter,解决jupyter运行失败问题
记录自己pycharm环境配置和解决问题的流程。 解决pycharm无法运行jupyter代码,仅运行import板块显示运行失败,但是控制台不输出任何错误信息,令人困惑。 遇到的问题是:运行代码左下角显示运行失败但是有没有任何的输出错误信息。 …...

Vue 技术解析:从核心概念到实战应用
Vue.js 是一款流行的渐进式前端框架,以其简洁的 API、灵活的组件化结构和高效的响应式数据绑定而受到开发者的广泛欢迎。本文将深入解析 Vue 技术的核心概念、原理和应用场景,帮助开发者更好地理解和使用 Vue.js。 一、Vue 的设计哲学与核心概念 &…...

Series和 DataFrame是 Pandas 库中的两种核心数据结构
Series 和 DataFrame 是 Pandas 库中的两种核心数据结构,它们各有特点和用途。理解它们之间的区别有助于更高效地进行数据分析和处理。以下是 Series 和 DataFrame 的主要区别: 1. 维度 Series:是一维的数组,可以存储任何类型的…...

关于异步消息队列的详细解析,涵盖JMS模式对比、常用组件分析、Spring Boot集成示例及总结
以下是关于异步消息队列的详细解析,涵盖JMS模式对比、常用组件分析、Spring Boot集成示例及总结: 一、异步消息核心概念与JMS模式对比 1. 异步消息核心组件 组件作用生产者发送消息到消息代理(如RabbitMQ、Kafka)。消息代理中间…...

利用 Python 进行股票数据可视化分析
在金融市场中,股票数据的可视化分析对于投资者和分析师来说至关重要。通过可视化,我们可以更直观地观察股票价格的走势、交易量的变化以及不同股票之间的相关性等。 Python 作为一种功能强大的编程语言,拥有丰富的数据处理和可视化库…...

【Docker】离线安装Docker
背景 离线安装Docker的必要性,第一,在目前数据安全升级的情况下,很多外网已经基本不好访问了。第二,如果公司有对外部署的需求,那么难免会存在对方只有内网的情况,那么我们就要做到学会离线安装。 下载安…...

kubectl命令补全以及oc命令补全
kubectl命令补全 1.安装bash-completion 如果你用的是Bash(默认情况下是),先安装补全功能支持包 sudo apt update sudo apt install bash-completion -y2.为kubectl 启用补全功能 会话中临时: source <(kubectl completion bash)持久化配置&#x…...

《 C++ 点滴漫谈: 三十三 》当函数成为参数:解密 C++ 回调函数的全部姿势
一、前言 在现代软件开发中,“解耦” 与 “可扩展性” 已成为衡量一个系统架构优劣的重要标准。而在众多实现解耦机制的技术手段中,“回调函数” 无疑是一种高效且广泛使用的模式。你是否曾经在编写排序算法时,希望允许用户自定义排序规则&a…...
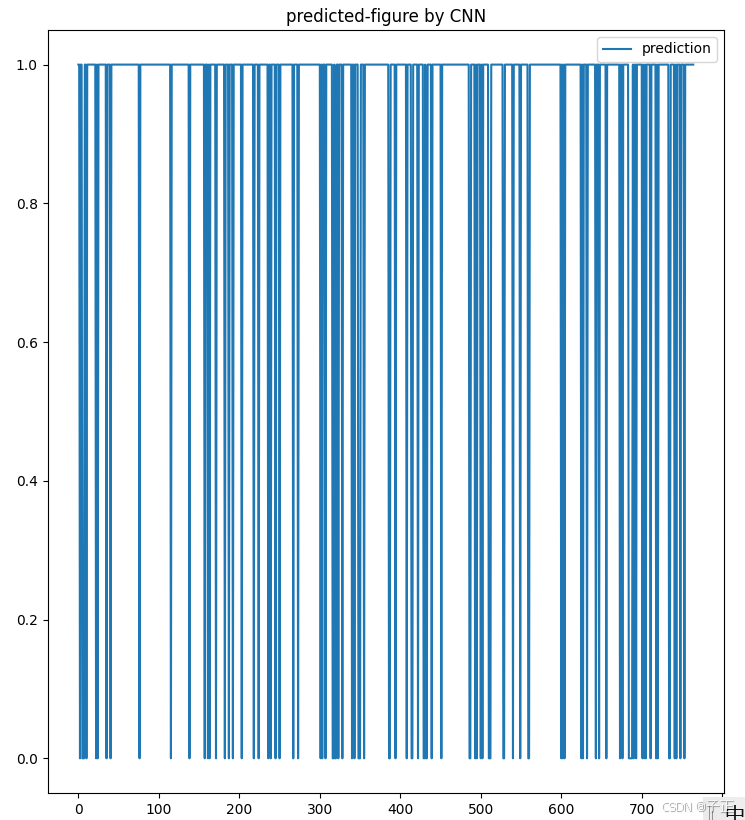
极简cnn-based手写数字识别程序
1.先看看识别效果: 这个程序识别的是0~9的一组手写数字,这是最终的识别效果,为1,代表识别成功,0为失败。 然后数据源是:ds deeplake.load(hub://activeloop/optical-handwritten-digits-train)里面是一组…...
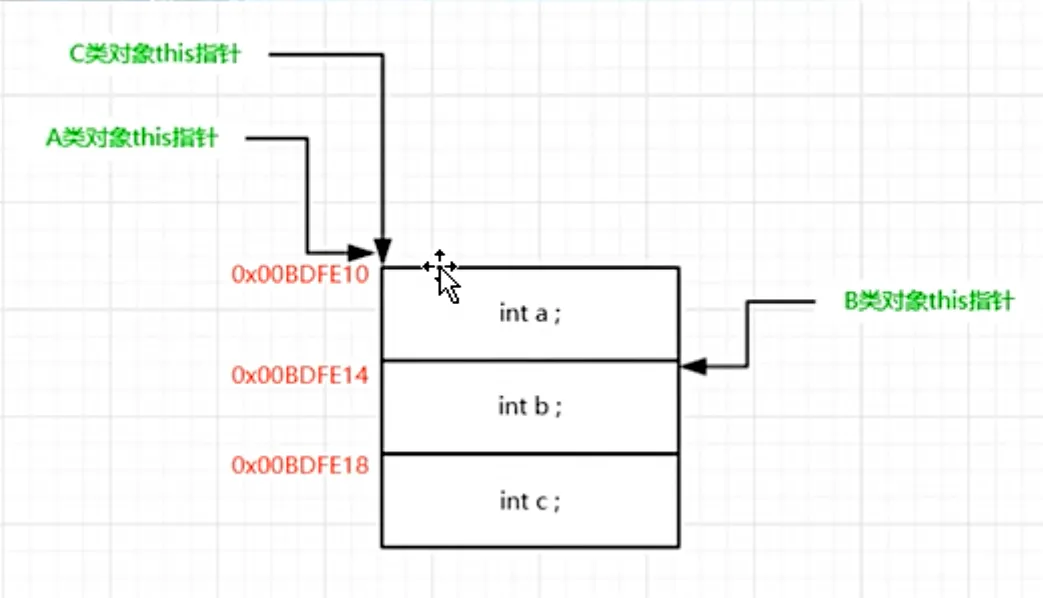
C++核心机制-this 指针传递与内存布局分析
示例代码 #include<iostream> using namespace std;class A { public:int a;A() {printf("A:A()的this指针:%p!\n", this);}void funcA() {printf("A:funcA()的this指针:%p!\n", this);} };class B { public:int b;B() {prin…...

vue3 history路由模式刷新页面报错问题解决
在使用history路由模式时刷新网页提示404错误,这是改怎么办呢。 官方解决办法 https://router.vuejs.org/zh/guide/essentials/history-mode.html...

PHP爬虫教程:使用cURL和Simple HTML DOM Parser
一个关于如何使用PHP的cURL和HTML解析器来创建爬虫的教程,特别是处理代理信息的部分。首先,我需要确定用户的需求是什么。可能他们想从某个网站抓取数据,但遇到了反爬措施,需要使用代理来避免被封IP。不过用户没有提到具体的目标网…...