【NLP】24. spaCy 教程:自然语言处理核心操作指南(进阶)
spaCy 中文教程:自然语言处理核心操作指南(进阶)
1. 识别文本中带有“百分号”的数字
import spacy# 创建一个空的英文语言模型
nlp = spacy.blank("en")# 处理输入文本
doc = nlp("In 1990, more than 60% of people in East Asia were in extreme poverty. Now less than 4% are.")# 遍历文档中的每个词
for token in doc:if token.like_num: # 判断该词是否看起来像一个数字# 获取下一个词next_token = doc[token.i + 1]if next_token.text == "%":print("找到百分比:", token.text)
📌 2. 词性标注与依存关系分析
import spacy# 加载英文小模型
nlp = spacy.load("en_core_web_sm")# 输入文本
doc = nlp("She ate the pizza")# 打印每个词的词性标签
for token in doc:print(token.text, token.pos_, token.pos)# 输出依存结构信息(包括该词依赖于哪个词)
for token in doc:print(token.text, token.pos_, token.dep_, token.head.text)
📌 3. 命名实体识别(NER)
# 输出识别出来的命名实体及其类型
for ent in doc.ents:print(ent.text, ent.label_)
📌 4. 比较不同模型之间的差异(词性与依存关系)
# 假设 doc_small 和 doc_medium 是使用不同模型处理的结果
for i in range(len(doc_small)):print("词:", doc_small[i])if doc_small[i].pos_ != doc_medium[i].pos_:print("词性不同:", doc_small[i].pos_, doc_medium[i].pos_)if doc_small[i].dep_ != doc_medium[i].dep_:print("依存关系不同:", doc_small[i].dep_, doc_medium[i].dep_)
📌 5. 使用 Matcher 匹配自定义文本模式
示例一:识别“购买”某物的句子结构
from spacy.matcher import Matcher
import spacynlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)# 定义匹配“购买某物”的结构
pattern = [{"LEMMA": "buy"}, {"POS": "DET", "OP": "?"}, {"POS": "NOUN"}]
matcher.add("BUY_ITEM", [pattern])doc = nlp("I bought a smartphone. Now I'm buying apps.")
matches = matcher(doc)for match_id, start, end in matches:span = doc[start:end]print("匹配结果:", span.text)
示例二:识别“love + 名词”的组合
pattern = [{"LEMMA": "love", "POS": "VERB"}, {"POS": "NOUN"}]
matcher.add("LOVE_PATTERN", [pattern])doc = nlp("I loved vanilla but now I love chocolate more.")
matches = matcher(doc)for match_id, start, end in matches:span = doc[start:end]print("匹配:", span.text)
示例三:匹配 “COLORS10”, “COLORS11” 等结构
text = """After the iOS update you won’t notice big changes. Most of iOS 11's layout remains the same as iOS 10."""matcher = Matcher(nlp.vocab)
pattern = [{"TEXT": "COLORS"}, {"IS_DIGIT": True}]
matcher.add("IOS_VERSION", [pattern])doc = nlp(text)
matches = matcher(doc)for match_id, start, end in matches:span = doc[start:end]print("识别出的版本:", span.text)
示例四:识别“download + 专有名词”的结构
text = """I downloaded Fortnite on my laptop. Should I download WinZip too?"""pattern = [{"LEMMA": "download"}, {"POS": "PROPN"}]
matcher.add("DOWNLOAD_PATTERN", [pattern])doc = nlp(text)
matches = matcher(doc)for match_id, start, end in matches:print("下载内容:", doc[start:end].text)
示例五:匹配“形容词 + 名词”结构
text = "Features include a beautiful design, smart search, and voice responses."pattern = [{"POS": "ADJ"}, {"POS": "NOUN"}, {"POS": "NOUN", "OP": "?"}]
matcher.add("ADJ_NOUN", [pattern])doc = nlp(text)
matches = matcher(doc)for match_id, start, end in matches:print("形容词短语:", doc[start:end].text)
📌 6. 使用 Vocab 和 Lexeme 操作词汇表
nlp = spacy.blank("en")# 将字符串转换为 hash 值
word_hash = nlp.vocab.strings["hat"]
print("字符串 'hat' 的哈希值为:", word_hash)# 再将 hash 值反向转换为字符串
word_text = nlp.vocab.strings[word_hash]
print("哈希反查:", word_text)# 获取词汇的详细属性
lexeme = nlp.vocab["tea"]
print(lexeme.text, lexeme.orth, lexeme.is_alpha)
✨ 7. 手动创建 Doc 和 Span
在 spaCy 中,Doc 是处理文本的核心对象。我们可以使用 Doc 类手动创建文档,而不是通过 nlp() 处理字符串。
from spacy.tokens import Doc, Span
import spacynlp = spacy.blank("en") # 创建一个空的英文模型tokens = ["Hello", "world", "!"]
spaces = [True, False, False] # 单词之间是否有空格doc = Doc(nlp.vocab, words=tokens, spaces=spaces)
print("创建的文档:", doc)
接着我们可以用 Span 创建一个实体片段,并加上标签:
span = Span(doc, 0, 2, label="GREETING") # "Hello world"
doc.ents = [span] # 设置 doc 的实体
print("命名实体:", doc.ents)
🛠️ 8. 查看与修改 NLP 管道组件
spaCy 的 NLP 模型是一个管道(pipeline),包含多个组件(如分词、实体识别等)。
print("管道组件名称:", nlp.pipe_names)
print("组件详细信息:", nlp.pipeline)
你也可以向管道中添加自定义组件,例如:
from spacy.language import Language@Language.component("length_logger")
def log_doc_length(doc):print(f"文档长度:{len(doc)}")return docnlp.add_pipe("length_logger", first=True) # 插入为第一个组件
print("修改后的管道组件:", nlp.pipe_names)doc = nlp("A sample sentence.")
🐛 9. 自定义实体识别器(基于词性和词形)
我们用 Matcher 组件来匹配特定词汇(比如“moth”、“fly”、“mosquito”),并用 Span 标记为实体:
from spacy.matcher import Matchertext = "Qantas flies all sorts of cargo! That includes moths, mosquitos, and even the occasional fly."nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)# 添加匹配规则
for insect in ["moth", "fly", "mosquito"]:matcher.add("INSECT", [[{"LEMMA": insect, "POS": "NOUN"}]])@Language.component("insect_finder")
def mark_insects(doc):matches = matcher(doc)doc.ents = [Span(doc, start, end, label="INSECT") for _, start, end in matches]return docnlp.add_pipe("insect_finder", after="ner") # 放在命名实体识别之后doc = nlp(text)
print("识别到的昆虫实体:", [(ent.text, ent.label_) for ent in doc.ents])
🔍 10. 文本向量与相似度计算
spaCy 中的 en_core_web_md 或 en_core_web_lg 模型提供了词向量。我们可以比较词、句子的相似度:
nlp = spacy.load("en_core_web_md")doc1 = nlp("I like fast food")
doc2 = nlp("I like pizza")print("句子相似度:", doc1.similarity(doc2))doc = nlp("I like pizza and pasta")
print("词语相似度(pizza vs pasta):", doc[2].similarity(doc[4]))
📚 11. 使用 nlp.pipe 批量处理文本
如果你需要处理大量文本,nlp.pipe() 是更高效的选择:
texts = ["First example!", "Second example."]
for doc in nlp.pipe(texts):print("处理结果:", doc)
🧩 12. 给 Doc 添加自定义属性(Context 扩展)
使用 Doc.set_extension() 可以添加自定义字段,例如 id 或 page_number:
from spacy.tokens import Docdata = [("This is a text", {"id": 1, "page_number": 15}),("And another text", {"id": 2, "page_number": 16}),
]# 只设置一次,重复设置会报错
try:Doc.set_extension("id", default=None)Doc.set_extension("page_number", default=None)
except ValueError:pass# 给每个 doc 添加上下文属性
for doc, context in nlp.pipe(data, as_tuples=True):doc._.id = context["id"]doc._.page_number = context["page_number"]print(f"{doc.text} | ID: {doc._.id} | 页码: {doc._.page_number}")
🔧 13. 控制管道的运行组件(select_pipes)
你可以临时禁用某些组件,加快处理速度或避免不必要的分析:
text = """Chick-fil-A is an American fast food restaurant chain headquartered in
College Park, Georgia."""with nlp.select_pipes(disable=["tagger", "parser"]): # 临时关闭组件doc = nlp(text)print("命名实体:", doc.ents)print("词性标注(关闭 tagger 后):", [token.tag_ for token in doc])
相关文章:
)
【NLP】24. spaCy 教程:自然语言处理核心操作指南(进阶)
spaCy 中文教程:自然语言处理核心操作指南(进阶) 1. 识别文本中带有“百分号”的数字 import spacy# 创建一个空的英文语言模型 nlp spacy.blank("en")# 处理输入文本 doc nlp("In 1990, more than 60% of people in East…...

每天学一个 Linux 命令(15):man
可访问网站查看,视觉品味拉满:http://www.616vip.cn/15/index.html 每天学一个 Linux 命令(15):man 命令简介 man(Manual)是 Linux 中最核心的命令之一,用于查看命令、系统调用、库函数等的手册文档。它是用户和开发者获取帮助的核心工具,几乎覆盖了系统中的所有功…...
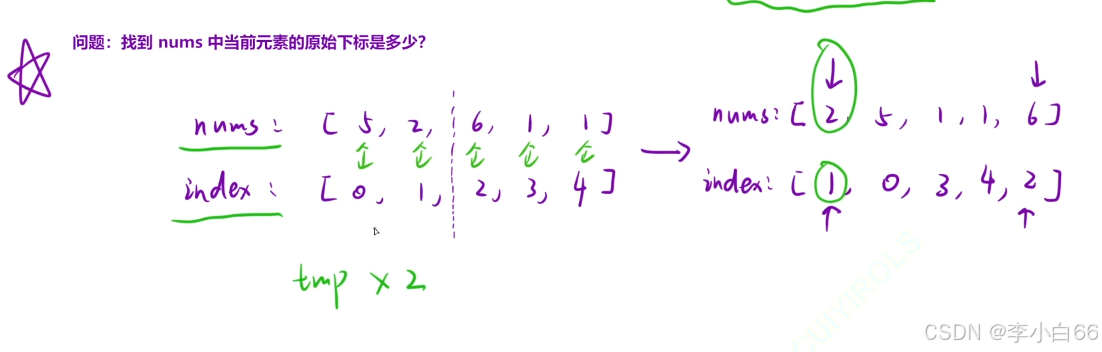
必刷算法100题之计算右侧小于当前元素的个数
题目链接 315. 计算右侧小于当前元素的个数 - 力扣(LeetCode) 题目解析 计算数组里面所有元素右侧比它小的数的个数, 并且组成一个数组,进行返回 算法原理 归并解法(分治) 当前元素的后面, 有多少个比我小(降序) 我们要找到第一比左边小的元素, 这样…...

Python依赖注入完全指南:高效解耦、技术深析与实践落地
Python依赖注入完全指南:高效解耦、技术深析与实践落地 摘要 依赖注入(DI)不仅是一种设计技术,更是一种解耦的艺术。它通过削减模块间的强耦合性,为系统提供了更高的灵活性和可测试性,特别是在 FastAPI 等…...
)
android弱网环境数据丢失解决方案(3万字长文)
在移动互联网时代,Android 应用已经成为人们日常生活中不可或缺的一部分。从社交媒体到在线购物,从移动办公到娱乐游戏,用户对应用的依赖程度与日俱增。然而,尽管网络基础设施在全球范围内得到了显著改善,弱网环境依然是一个普遍存在且难以完全避免的现实。特别是在一些发…...

答案之书和源代码
答案之书是一个神秘而神奇的工具,它可以帮助你在遇到问题或犹豫不决的时候找到答案或暗示。这个程序模拟了答案之书的功能,让你随机生成一个简短而有启发性的答案,让你在困境中找到一丝希望。 在这个程序中,你会看到一个画布上显…...

Spring Cloud主要组件介绍
一、Spring Cloud 1、Spring Cloud技术概览 分为:服务治理,链路追踪,消息组件,配置中心,安全控制,分布式任务管理、调度,Cluster工具,Spring Cloud CLI,测试 2、注册中心:常用注册中心(Euerka[AP]、Zookeeper[CP]) 1)Euerka Client(服务提供者)=》注册=》Eue…...
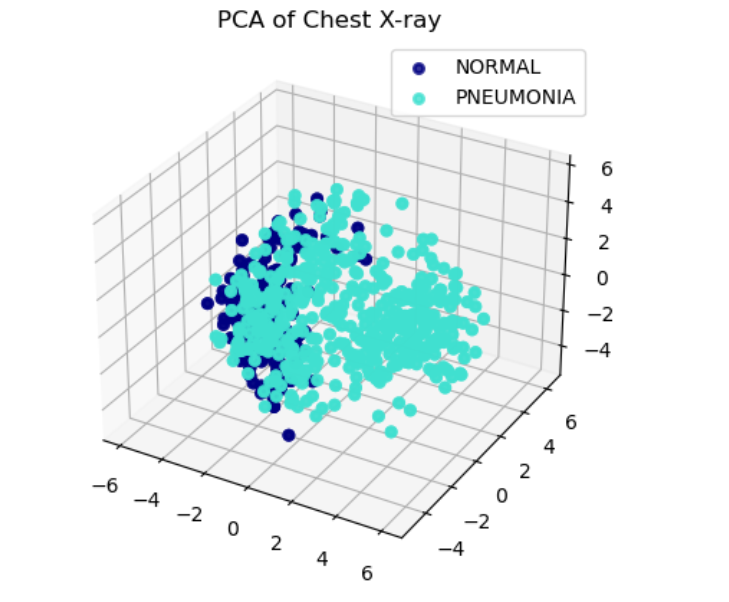
深度学习ResNet模型提取影响特征
大家好,我是带我去滑雪! 影像组学作为近年来医学影像分析领域的重要研究方向,致力于通过从医学图像中高通量提取大量定量特征,以辅助疾病诊断、分型、预后评估及治疗反应预测。这些影像特征涵盖了形状、纹理、灰度统计及波形变换等…...

【Qt】Qt Creator开发基础:项目创建、界面解析与核心概念入门
🍑个人主页:Jupiter. 🚀 所属专栏:QT 欢迎大家点赞收藏评论😊 目录 Qt Creator 新建项⽬认识 Qt Creator 界⾯项⽬⽂件解析Qt 编程注意事项认识对象模型(对象树)Qt 窗⼝坐标体系 Qt Creator 新…...
 中查看 DICOM 文件的像素位深(8位或16位))
SimpleITK (sitk) 中查看 DICOM 文件的像素位深(8位或16位)
在 SimpleITK (sitk) 中查看 DICOM 文件的像素位深(8位或16位),可以通过以下方法实现: 方法一:通过 图像像素数组的数据类型 判断 读取 DICOM 文件: 使用 sitk.ReadImage() 加载文件,生成图像对…...
技术详解)
Unity IL2CPP内存泄漏追踪方案(基于Memory Profiler)技术详解
一、IL2CPP内存管理特性与泄漏根源 1. IL2CPP内存架构特点 内存区域管理方式常见泄漏类型托管堆(Managed)GC自动回收静态引用/事件订阅未取消原生堆(Native)手动管理非托管资源未释放桥接层GCHandle/PInvoke跨语言引用未正确释放 对惹,这里有一个游戏开发交流小组…...
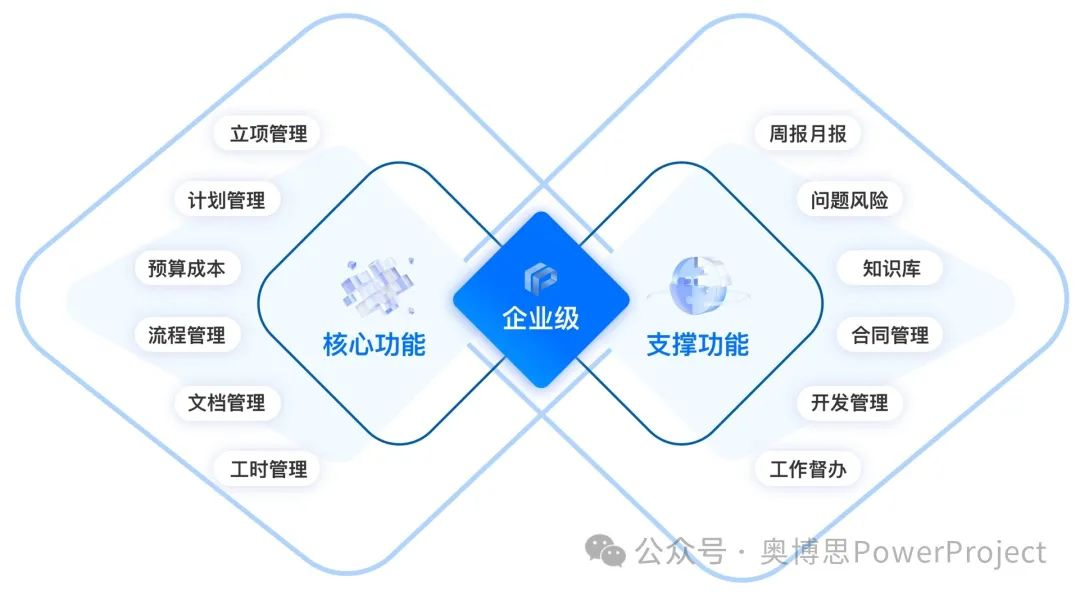
制造业项目管理如何做才能更高效?制造企业如何选择适配的数字化项目管理系统工具?
一、制造企业项目管理过程中面临的痛点有哪些? 制造企业在项目管理过程中面临的痛点通常涉及跨部门协作、资源调配、数据整合、风险控制等多个维度,且与行业特性(如离散制造vs流程制造)紧密相关。 进度失控多项目资源冲突信息孤…...

Python批量处理PDF图片详解(插入、压缩、提取、替换、分页、旋转、删除)
目录 一、概述 二、 使用工具 三、Python 在 PDF 中插入图片 3.1 插入图片到现有PDF 3.2 插入图片到新建PDF 3.3 批量插入多张图片到PDF 四、Python 提取 PDF 图片及其元数据 五、Python 替换 PDF 图片 5.1 使用图片替换图片 5.2 使用文字替换图片 六、Python 实现 …...

让 Python 脚本在后台持续运行:架构级解决方案与工业级实践指南
让 Python 脚本在后台持续运行:架构级解决方案与工业级实践指南 一、生产环境需求全景分析 1.1 后台进程的工业级要求矩阵 维度开发环境要求生产环境要求容灾要求可靠性单点运行集群部署跨机房容灾可观测性控制台输出集中式日志分布式追踪资源管理无限制CPU/Memo…...

【后端开发】Spring配置文件
文章目录 配置文件properties配置文件基本语法读取配置文件 yml配置文件基本语法读取配置文件配置空字符串及null单双引号配置对象配置集合配置Map 优缺点优点缺点 配置文件 硬编码是将数据直接嵌入到程序或其他可执行对象的源代码中,也就是常说的"代码写死&q…...
七种驱动器综合对比——《器件手册--驱动器》
九、驱动器 名称 功能与作用 工作原理 优势 应用 隔离式栅极驱动器 隔离式栅极驱动器用于控制功率晶体管(如MOSFET、IGBT、SiC或GaN等)的开关,其核心功能是将控制信号从低压侧传输到高压侧的功率器件栅极,同时在输入和输出之…...

996引擎-源码学习:PureMVC Lua 中的系统启动,初始化并注册 Mediator
996引擎-源码学习:PureMVC Lua 中的系统启动,初始化并注册 Mediator 一、PureMVC 核心架构二、系统启动流程系统启动注册 StartUp 通知发送 StartUp 通知,开始初始化三、Mediator 初始化1. gameStateInit.lua2. LoadingBeginCommand.lua3. RegisterWorldMediatorCommand.lua…...

redis系列--1.redis是什么
国际惯例,想了解一个东西,首先就要看看官方提供了什么。redis的官网是https://redis.io 。以下这段话就是redis的简介了: Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message…...

CSS 过渡与变形:让交互更丝滑
在网页设计中,动效能让用户交互更自然、流畅,提升使用体验。本文将通过 CSS 的 transition(过渡)和 transform(变形)属性,带你入门基础动效设计,结合案例演示如何实现颜色渐变、元素…...

linuxbash原理
3417 1647 0 04:17 ? 00:00:21 /usr/libexec/gnome-terminal-server yangang 3425 3417 0 04:17 pts/0 00:00:00 bash yangang 4524 3417 0 04:26 pts/1 00:00:00 bash 控制台创建是通过/usr/libexec/gnome-terminal-server 进行创建 rea…...

MecAgent Copilot:机械设计师的AI助手,开启“氛围建模”新时代
MecAgent Copilot作为机械设计师的AI助手,正通过多项核心技术推动机械设计进入“氛围建模”新时代。以下从功能特性、技术支撑和应用场景三方面解析其创新价值: 一、核心功能特性 智能草图生成与参数化建模 支持自然语言输入生成设计草图和3D模型,如输入“剖面透视…...

[Python基础速成]2-模块与包与OOP
上篇➡️[Python基础速成]1-Python规范与核心语法 目录 Python模块创建模块与导入属性__name__dir()函数标准模块 Python包类类的专有方法 对象继承多态拷贝 Python模块 Python 中的模块(Module)是一个包含 Python 定义和语句的文件,文件名就…...
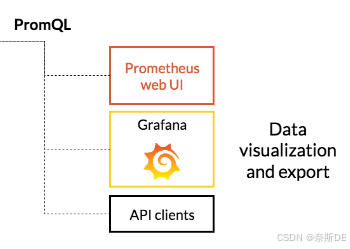
【prometheus+Grafana篇】Prometheus与Grafana:深入了解监控架构与数据可视化分析平台
💫《博主主页》:奈斯DB-CSDN博客 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了解 💖如果觉得文章对你有所帮…...
)
Web前端开发——超链接与浮动框架(下)
本节说明: 上一节,我们了解了超链接概述与超链接的语法、路径及分类两大部分内容,本节我们将了解超链接的应用与浮动框架。 三、超链接的应用 在网络上能够通过链接访问不同的资源或网页。链接对象多种多样,可分为文件、FTP站点…...

【后端开发】初识Spring IoC与SpringDI、图书管理系统
文章目录 图书管理系统用户登录需求分析接口定义前端页面代码服务器代码 图书列表展示需求分析接口定义前端页面部分代码服务器代码Controller层service层Dao层modle层 Spring IoC定义传统程序开发解决方案IoC优势 Spring DIIoC &DI使用主要注解 Spring IoC详解bean的存储五…...

Vim 编辑器的常用快捷键介绍
以下是 Vim 编辑器的常用快捷键分类介绍,帮助你快速掌握高效编辑技巧: 一、基础模式切换 Vim 的核心是 模式化操作,常用模式包括: 普通模式(默认):导航、命令输入。插入模式:输入/…...
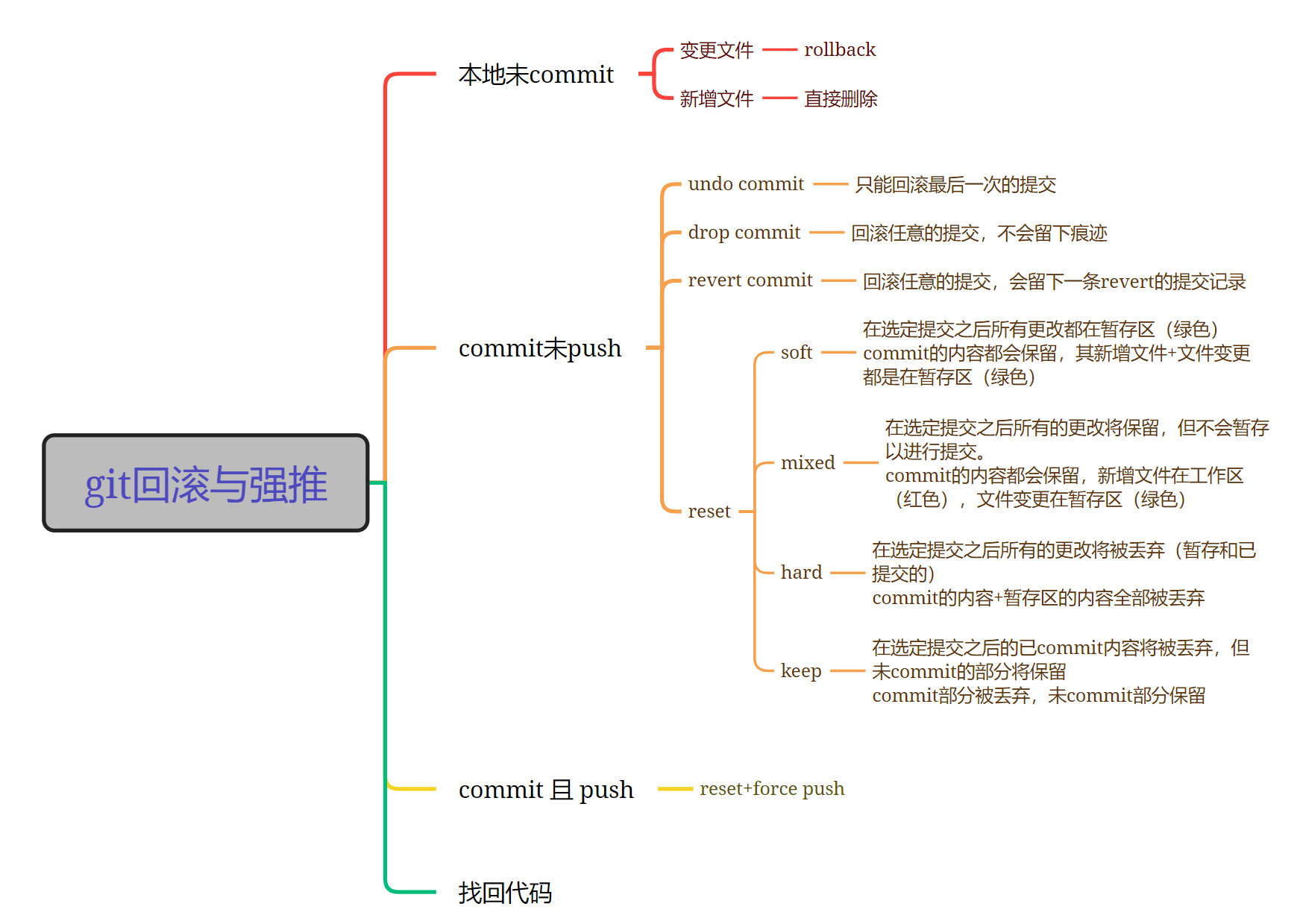
git在IDEA中使用技巧
git在IDEA中使用技巧 merge和rebase 参考:IDEA小技巧-Git的使用 git回滚、强推、代码找回 参考:https://www.bilibili.com/video/BV1Wa411a7Ek?spm_id_from333.788.videopod.sections&vd_source2f73252e51731cad48853e9c70337d8e cherry pick …...

榕壹云无人共享系统:基于SpringBoot+MySQL+UniApp的物联网共享解决方案
无人共享经济下的技术革新 随着无人值守经济模式的快速发展,传统共享设备面临管理成本高、效率低下等问题。榕壹云无人共享系统依托SpringBootMySQLUniApp技术栈,结合物联网与移动互联网技术,为商家提供低成本、高可用的无人化运营解决方案。…...
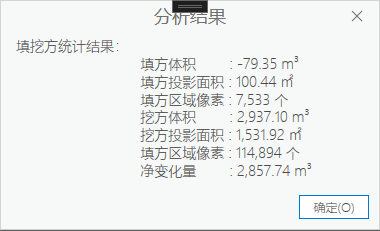
ARCGIS PRO DSK 利用两期地表DEM数据计算工程土方量
利用两期地表DEM数据计算工程土方量需要准许以下数据: 当前地图有3个图层,两个栅格图层和一个矢量图层 两个栅格图层:beforeDem为工程施工前的地表DEM模型 afterDem为工程施工后的地表DEM模型 一个矢量图层…...

考研408参考用书:计算机组成原理(唐朔飞)介绍,附pdf
我用夸克网盘分享了「《计算机组成原理》第2,3版 唐朔飞」, 链接:https://pan.quark.cn/s/6a87d10274a3 1. 书籍定位与适用对象 定位:计算机组成原理是计算机科学与技术、软件工程等专业的核心基础课程,涉及计算机硬件的底层工作原…...