【NLP】 21. Transformer整体流程概述 Encoder 与 Decoder架构对比
1. Transformer 整体流程概述
Transformer 模型的整个处理流程可以概括为从自注意力(Self-Attention)到多头注意力,再加上残差连接、层归一化、堆叠多层的结构。其核心思想是利用注意力机制对输入进行并行计算,从而避免传统 RNN 逐步依赖导致的并行化困难问题。
在 Transformer 模型中,编码器(Encoder) 和 解码器(Decoder) 均由若干相同的层堆叠而成。模型的基本构成单元如下:
- 自注意力层(Self-Attention Layer):计算输入中各个 token 之间的相关性,为每个 token 提供上下文表示。
- 多头注意力机制(Multi-Head Attention):并行计算多个注意力头,每个头学习不同的特征(例如,有的关注实体信息,有的关注语法信息)。
- 前馈神经网络层(Feed-Forward Layer):在每个注意力模块后面添加一个全连接的前馈网络,引入非线性变换。
- 残差连接和层归一化(Residual Connection & Layer Normalization):通过加法将输入与输出相加,保证梯度能够高效传回,并利用层归一化稳定训练过程。
2. 多头注意力机制
2.1 为什么使用多头注意力
多头注意力机制将单一注意力分成多个“头”,每个头在不同的线性子空间中并行计算注意力,有以下优势:
- 捕获多种语义信息:例如,某一个注意力头可能专注于实体信息(entity focused),而另一个头可能捕捉句法结构(syntax focused)。
- 提高模型表达能力:通过并行多个注意力头,模型能够同时从多个角度学习输入数据的特征。
2.2 多头注意力公式
假设输入为查询 Q、键 K和值 V,单个注意力头的计算如下:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dkQK⊤)V
其中:
- dk 为键的维度,做缩放是为了缓解点积随维度增加过大带来的数值不稳定性;
- softmax 后得到的注意力权重用于对 V 进行加权平均。
多头注意力的计算为对多个独立注意力头计算后,将它们拼接,再通过一个输出矩阵 WO 得到最终的输出:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
其中 WiQ, WiK, WiV 为各头的线性变换矩阵。
3. 缩放点积注意力
3.1 为什么使用缩放
在高维空间下,如果直接用点积 计算注意力得分,因向量维度增加,点积值通常会变得很大,导致 softmax 函数会输出极端分布,进而使得梯度变小,不利于训练。因此,引入缩放因子,即除以 d k \sqrt{d_k} dk 来缓解这种情况。
3.2 缩放点积注意力公式
完整公式如下:
e x p ( e i j ′ ) α i j = exp ( e i j ) ∑ j ′ exp ( e i j ′ ) α i j = ∑ j ′ e x p ( e i j ′ ) exp(eij′)\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{j'} \exp(e_{ij'})}αij=∑j′exp(eij′) exp(eij′)αij=∑j′exp(eij′)exp(eij)αij=∑j′exp(eij′)
其中:
- eij 是未归一化的注意力得分;
- αij 是归一化后的权重;
- zi 是输出的向量表示。
4. 残差连接与层归一化
4.1 残差连接(Residual Connection)
残差连接用于缓解深层网络中的梯度消失问题,同时鼓励模型捕捉接近恒等映射的信息。其作用在于让输入信息能够直接流传至后续层,从而“学习”在原始表示上做出小的修改(即“学习小编辑”)。
公式表示为:
y = LayerNorm ( x + F ( x ) ) y = \text{LayerNorm}(x + F(x)) y=LayerNorm(x+F(x))
其中:
- x 为输入向量,
- F(x) 为经过注意力或前馈网络后的输出,
- LayerNorm 表示层归一化操作。
4.2 层归一化(Layer Normalization)
层归一化通过计算输入向量的均值和标准差,对向量进行归一化处理,从而稳定训练。具体步骤如下:
给定向量 x=[x1,x2,…,xd]
- 计算均值:
μ = 1 d ∑ i = 1 d x i \mu = \frac{1}{d} \sum_{i=1}^{d} x_i μ=d1i=1∑dxi
- 计算标准差(加上一个很小的 ϵ\epsilonϵ 防止除零):
σ = 1 d ∑ i = 1 d ( x i − μ ) 2 + ϵ \sigma = \sqrt{\frac{1}{d} \sum_{i=1}^{d} (x_i - \mu)^2 + \epsilon} σ=d1i=1∑d(xi−μ)2+ϵ
- 归一化和线性变换:
LayerNorm ( x ) i = γ i x i − μ σ + e + β i \text{LayerNorm}(x)_i = \gamma_i \frac{x_i - \mu}{\sigma+e} + \beta_i LayerNorm(x)i=γiσ+exi−μ+βi
其中 γ 和 β 是可学习的参数,分别用于重新缩放和平移归一化后的输出。e是一个小的值,以防止被零除
5. Transformer 中的解码器(Decoder)
5.1 解码器与编码器的相似性
解码器与编码器的基本构建块相似,都包含自注意力、多头注意力、前馈网络、残差连接与层归一化。然而,解码器有两个关键的区别:
-
因果(Masked)自注意力:
为防止未来信息泄露,解码器中计算自注意力时对未来的位置做屏蔽。e i j = { q i ⊤ k j d k , j ≤ i − ∞ , j > i e_{ij} = \begin{cases} \frac{q_i^\top k_j}{\sqrt{d_k}}, & j \leq i \\ -\infty, & j > i \end{cases} eij={dkqi⊤kj,−∞,j≤ij>i
然后软化为:
α i j = exp ( e i j ) ∑ j ′ = 1 i exp ( e i j ′ ) \alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{j'=1}^{i} \exp(e_{ij'})} αij=∑j′=1iexp(eij′)exp(eij)
-
跨注意力(Cross-Attention):
除了自注意力外,解码器还包含跨注意力层,用于结合编码器的输出信息。在跨注意力中:- 查询(Query, Q) 来自解码器当前的隐藏状态;
- 键(Key, K) 和 值(Value, V) 来自编码器的隐藏状态;
相应公式与前述缩放点积注意力类似:
CrossAttention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{CrossAttention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V CrossAttention(Q,K,V)=softmax(dkQK⊤)V
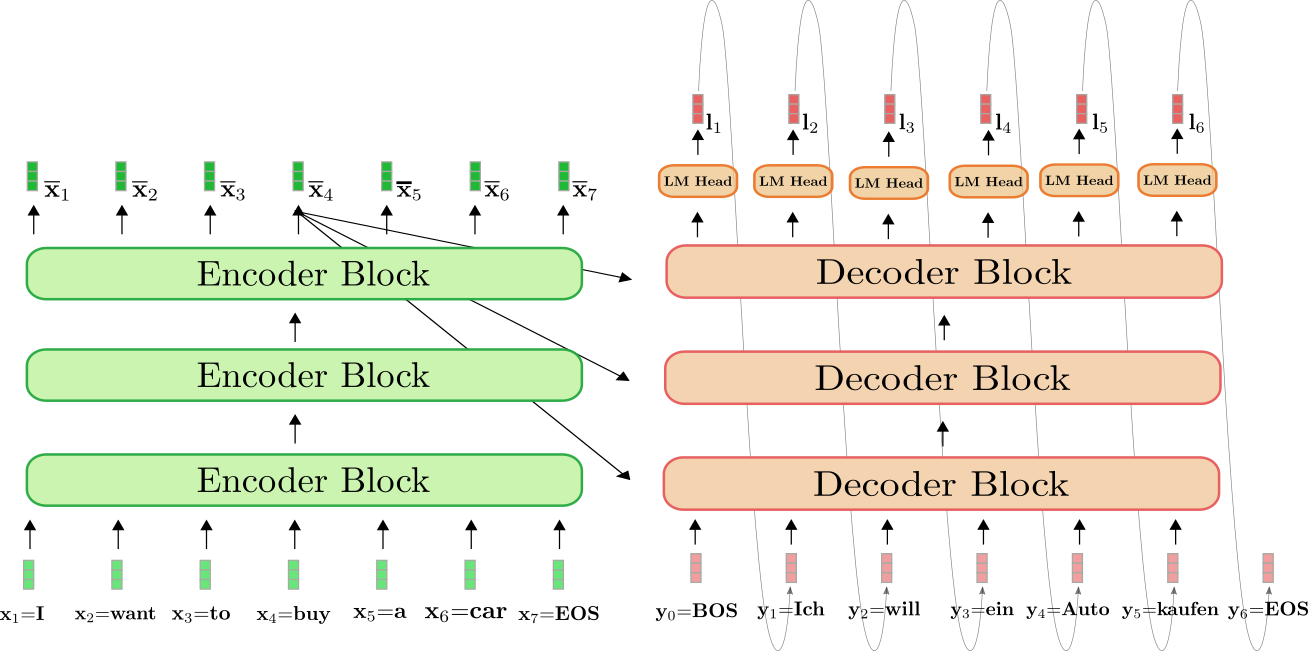
5.2 解码器的结构总结
解码器的一个典型层可以总结为:
- Masked Self-Attention:计算当前解码器输入的自注意力并屏蔽未来信息;
- 跨注意力(Encoder-Decoder Attention):利用编码器输出为解码器生成当前输出提供上下文信息;
- 前馈网络(Feed-Forward Network):对注意力输出进行非线性变换;
- 残差连接与层归一化:确保训练中梯度稳定并促进模型学习细微调整。
6. Transformer 总结及残差视角
从整体角度看,Transformer 模型的核心操作可以概括为:
- 多次并行注意力计算:通过多头注意力,模型同时关注不同角度的信息。
- 添加残差连接:让每一层学习输入上的小修正(“编辑”),从而保留原始信息。
- 加入层归一化:使各层输入分布保持稳定,提高训练效率。
- 堆叠多层结构:重复上述模块,多层堆叠能捕捉到更加抽象的特征。
从残差视角来观察,Transformer 的核心是词嵌入,随后每一层做的是在原始表示上学习微小的调整,从而“编辑”出更符合任务需求的表示。
核心区别总结表:
| 模块 | Encoder Layer | Decoder Layer |
|---|---|---|
| Attention 1 | Multi-Head Self-Attention | Masked Multi-Head Self-Attention |
| Attention 2 | 无 | Cross-Attention(Query 来自 Decoder,Key/Value 来自 Encoder) |
| FFN | 有(相同) | 有(相同) |
| 残差&归一化 | 有 | 有 |
📌 为什么 Decoder 需要 Masked Self-Attention?
为了保证**自回归(Autoregressive)**生成,只能看到前面的词,不能偷看将来的词。
举例:
- 当前生成到位置 3,不能让 Decoder 看到位置 4 的词。
- 所以在 Attention 的 softmax 权重矩阵中,强行 mask 掉未来位置。
🤯 记忆小技巧:
| Encoder | Decoder |
|---|---|
| 自我理解 | 自我生成 + 看懂输入 |
| “我看整句,理解上下文” | “我边生成边回看 Encoder 给的提示” |
相关文章:
【NLP】 21. Transformer整体流程概述 Encoder 与 Decoder架构对比
1. Transformer 整体流程概述 Transformer 模型的整个处理流程可以概括为从自注意力(Self-Attention)到多头注意力,再加上残差连接、层归一化、堆叠多层的结构。其核心思想是利用注意力机制对输入进行并行计算,从而避免传统 RNN …...
《Vue Router实战教程》21.扩展 RouterLink
欢迎观看《Vue Router 实战(第4版)》视频课程 扩展 RouterLink RouterLink 组件提供了足够的 props 来满足大多数基本应用程序的需求,但它并未尝试涵盖所有可能的用例,在某些高级情况下,你可能会发现自己使用了 v-sl…...

开发一个答题pk小程序的大致成本是多少
答题 PK 小程序通常指的是一种允许用户之间进行实时或异步答题竞赛的应用程序,可能结合PK答题、积分系统、排行榜等功能。 一、首先,确定答题 PK 小程序的基本功能模块。这可能包括用户注册登录、题库管理、题目类型(单选、多选、判断等&am…...

Android 应用蓝牙连接通信实现
Android 应用蓝牙连接通信实现,主要包括如下步骤: 一.打开蓝牙 // 获取蓝牙适配器 BluetoothAdapter bluetoothAdapter BluetoothAdapter.getDefaultAdapter() 1.判断蓝牙是否打开, bluetoothAdapter.isEnabled() 2. 如果未打开,执行打开蓝牙…...

GPT-2 语言模型 - 模型训练
本节代码是一个完整的机器学习工作流程,用于训练一个基于GPT-2的语言模型。下面是对这段代码的详细解释: 文件目录如下 1. 初始化和数据准备 设置随机种子 random.seed(1002) 确保结果的可重复性。 定义参数 test_rate 0.2 context_length 128 tes…...

科技项目验收测试包括哪些内容?有什么作用?
在现代科技快速发展的背景下,科技项目的验收测试已成为项目管理中的重要环节。科技项目验收测试是一种系统性的方法,旨在评估一个科技项目是否达到预定的技术指标和要求,确认项目的完成质量。该测试通常在项目实施完成后进行,通过…...

Java 设计模式:组合模式详解
Java 设计模式:组合模式详解 组合模式(Composite Pattern)是一种结构型设计模式,它允许将对象组织成树形结构,以统一的方式处理单个对象和对象集合。组合模式适用于需要表示“部分-整体”层次结构的场景,例…...

java实现加密解密
AES加密/解密核心步骤 参考 https://flying-fish.blog.csdn.net/article/details/142688630?fromshareblogdetail&sharetypeblogdetail&sharerId142688630&sharereferPC&sharesourceweixin_48616345&sharefromfrom_link工具类 import javax.crypto.Cip…...
websoket 学习笔记
目录 基本概念 工作原理 优势 应用场景 HTTP协议与 webSoket协议之间的对比 消息推送场景 1. 轮询(Polling) 2. 长轮询(Long Polling) 3. 服务器发送事件(Server-Sent Events, SSE) 4. WebSocket…...
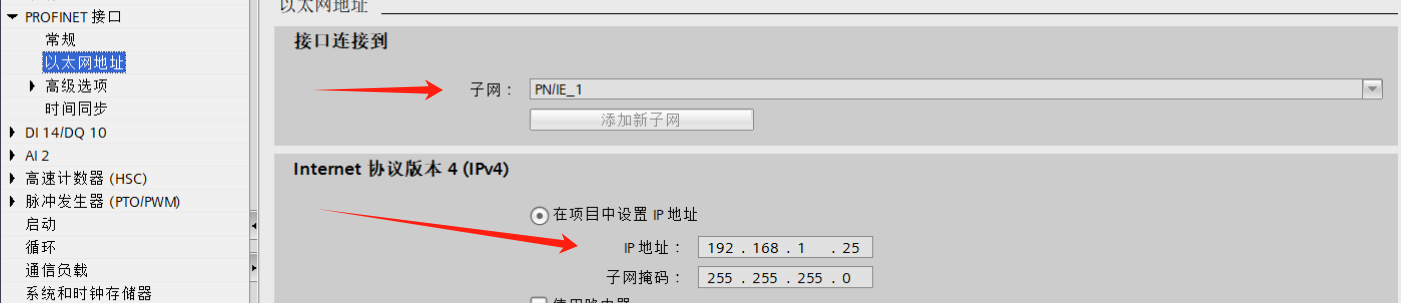
博途 TIA Portal之1200做从站与汇川EASY的TCP通讯
上篇我们写到了博途做主站与汇川EASY的通讯。通讯操作起来很简单,当然所谓的简单,也是相对的,如果操作成功一次,那么后面就很容易了, 如果操作不成功,就会很遭心。本篇我们将1200做从站,与汇川EASY做主站进行TCP的通讯。 1、硬件准备 1200PLC一台,带调试助手的PC机一…...
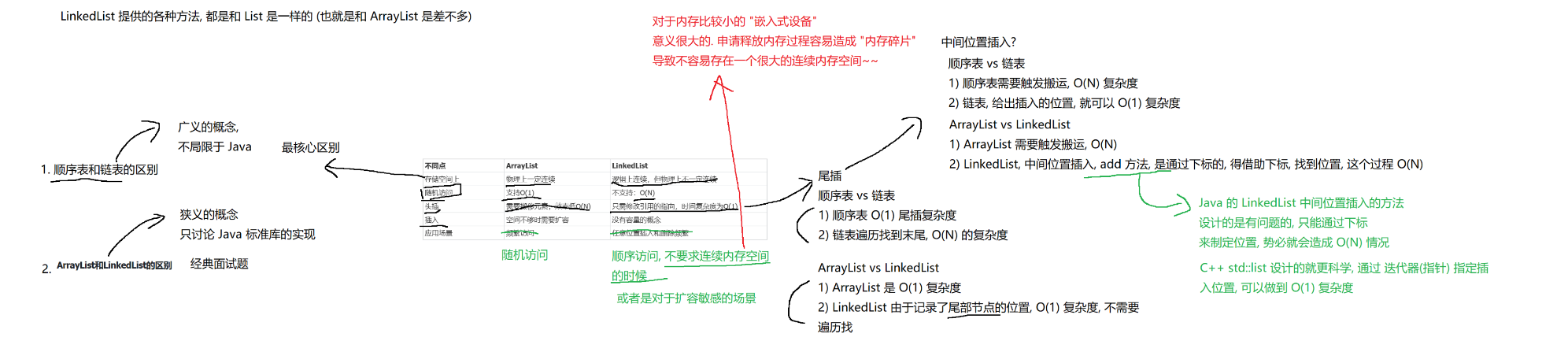
【数据结构_6下篇】有关链表的oj题
思路: 1.分别求出这两个链表的长度 2.创建两个引用,指向两个链表的头节点;找到长度长的链表,让她的引用先走差值步数 3.让这两个引用,同时往后走,每个循环各自走一步 然后再判定两个引用是否指向同一个…...
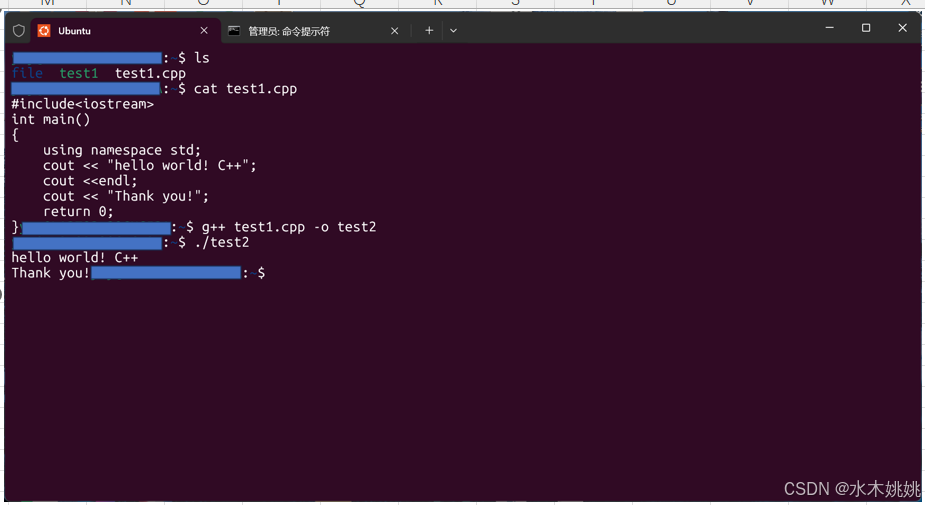
vscode+wsl 运行编译 c++
linux 的 windows 子系统(wsl)是 windows 的一项功能,可以安装 Linux 的发行版,例如(Ubuntu,Kali,Arch Linux)等,从而可以直接在 windows 下使用 Linux 应用程序…...
)
快速幂(蓝桥杯)
1. 递归实现 递归方法通过将问题分解为更小的子问题来实现。具体步骤如下: 如果指数 b 为 0,返回 1。 如果 b 是偶数,则递归计算 (a^2)b/2。 如果 b 是奇数,则递归计算 a⋅(a^2)(b−1)/2。 伪代码: function fas…...

狂神SQL学习笔记一:初识MySQL、关系型数据库和非关系型数据库
菜鸟教程学习一半了,但是已经疲倦了,所以换一个课程学习,来提升学习质量,可能会有很多已经学习到的地方,就当是复习巩固了。 按照SQL学习课程来划分,分为45集,所以可能也会写45篇文章ÿ…...

关于 Spring Boot 微服务解决方案的对比,并以 Spring Cloud Alibaba 为例,详细说明其核心组件的使用方式、配置及代码示例
以下是关于 Spring Boot 微服务解决方案的对比,并以 Spring Cloud Alibaba 为例,详细说明其核心组件的使用方式、配置及代码示例: 关于 Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案! https://sca.aliyun.com/?spm7145af80…...
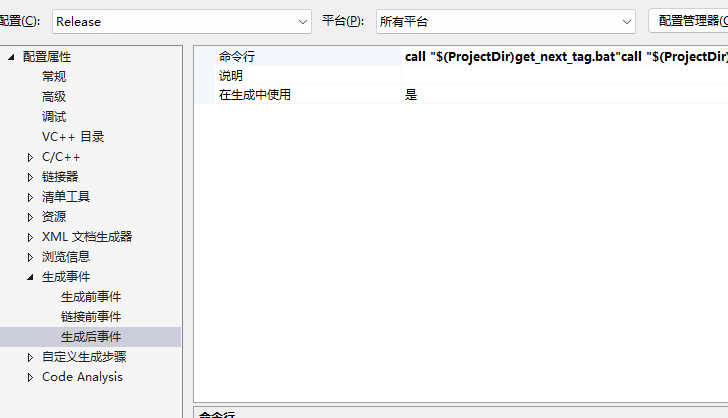
VS 基于git工程编译版本自动添加版本号
目录 概要 实现方案 概要 最近在用visual Studio 开发MFC项目时,需要在release版本编译后的exe文件自动追加版本信息。 由于我们用的git工程管理,即需要基于最新的git 提交来打版本。 比如: MFCApplication_V1.0.2_9.exe 由于git 提交信…...

小程序开发指南
小程序开发指南 目录 1. 小程序开发概述 1.1 什么是小程序1.2 小程序的优势1.3 小程序的发展历程 2. 开发准备工作 2.1 选择开发平台2.2 开发环境搭建2.3 开发模式选择 3. 小程序开发流程 3.1 项目规划3.2 界面设计3.3 代码开发3.4 基本开发示例3.5 数据存储3.6 网络请求3.7 …...

MySQL 超详细安装教程与常见问题解决方案
一、MySQL 安装教程 1. Windows 系统安装(以 MySQL 8.0 为例) 步骤 1:下载 MySQL Installer 访问 MySQL 官网下载页面。 选择 Windows (x86, 64-bit), MSI Installer(推荐使用完整版 mysql-installer-web-community-8.0.xx.xx.…...
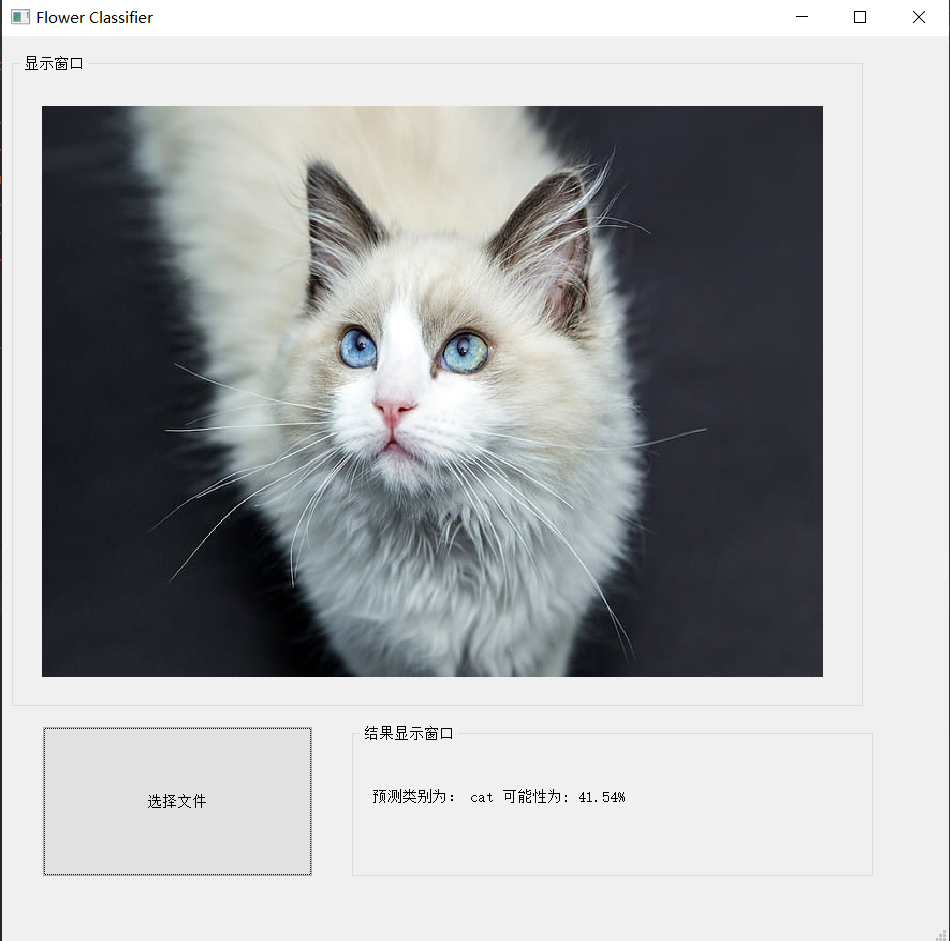
pytorch软件封装
封装代码,通过传入文件名,即可输出类别信息 上一章节,我们做了关于动物图像的分类,接下来我们把程序封装,然后进行预测。 单张图片的predict文件 predict.py 按着路径,导入单张图片做预测from torchvis…...

【多线程-第四天-自己模拟SDWebImage的下载图片功能-看SDWebImage的Demo Objective-C语言】
一、我们打开之前我们写的异步下载网络图片的项目,把刚刚我们写好的分类拖进来 1.我们这个分类包含哪些文件: 1)HMDownloaderOperation类, 2)HMDownloaderOperationManager类, 3)NSString+Sandbox分类, 4)UIImageView+WebCache分类, 这四个文件吧,把它们拖过来…...

电脑提示“找不到mfc140u.dll“的完整解决方案:从原因分析到彻底修复
当你启动某个软件或游戏时,突然遭遇"无法启动程序,因为计算机中丢失mfc140u.dll"的错误提示,这确实令人沮丧。mfc140u.dll是Microsoft Foundation Classes(MFC)库的重要组成部分,属于Visual C Re…...
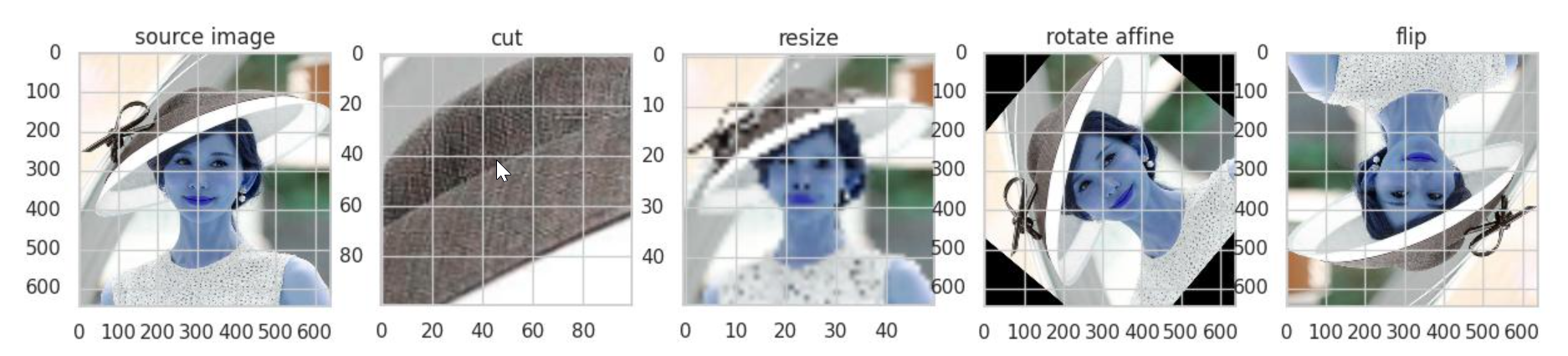
图像变换方式区别对比(Opencv)
1. 变换示例 import cv2 import matplotlib.pyplot as plotimg cv2.imread(url) img_cut img[100:200, 200:300] img_rsize cv2.resize(img, (50, 50)) (hight,width) img.shape[:2] rotate_matrix cv2.getRotationMatrix2D((hight//2, width//2), 50, 1) img_wa cv2.wa…...
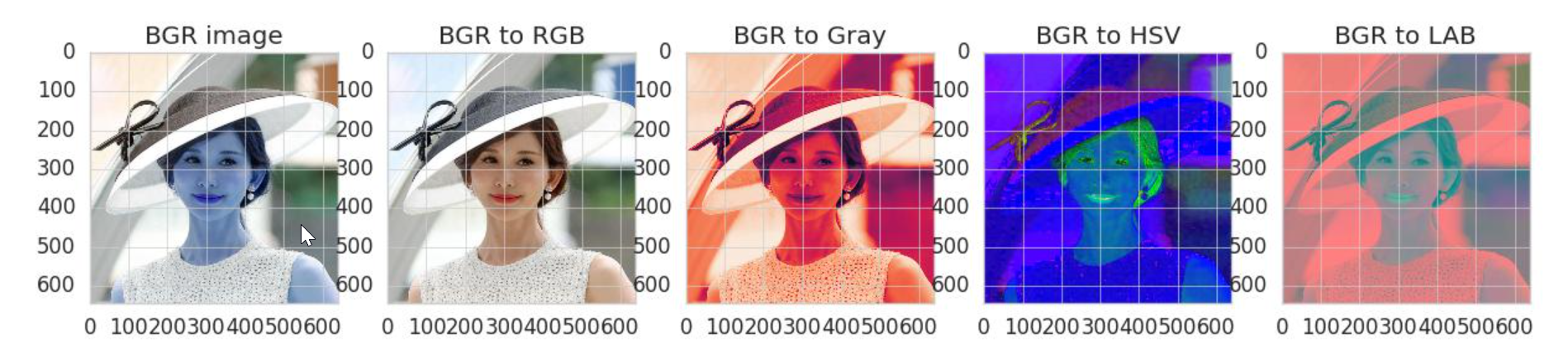
图像颜色空间对比(Opencv)
1. 颜色转换 import cv2 import matplotlib.pyplot as plotimg cv2.imread("tmp.jpg") img_r cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img_g cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img_h cv2.cvtColor(img, cv2.COLOR_BGR2HSV) img_l cv2.cvtColor(img, cv2.C…...
)
【NLP】24. spaCy 教程:自然语言处理核心操作指南(进阶)
spaCy 中文教程:自然语言处理核心操作指南(进阶) 1. 识别文本中带有“百分号”的数字 import spacy# 创建一个空的英文语言模型 nlp spacy.blank("en")# 处理输入文本 doc nlp("In 1990, more than 60% of people in East…...

每天学一个 Linux 命令(15):man
可访问网站查看,视觉品味拉满:http://www.616vip.cn/15/index.html 每天学一个 Linux 命令(15):man 命令简介 man(Manual)是 Linux 中最核心的命令之一,用于查看命令、系统调用、库函数等的手册文档。它是用户和开发者获取帮助的核心工具,几乎覆盖了系统中的所有功…...
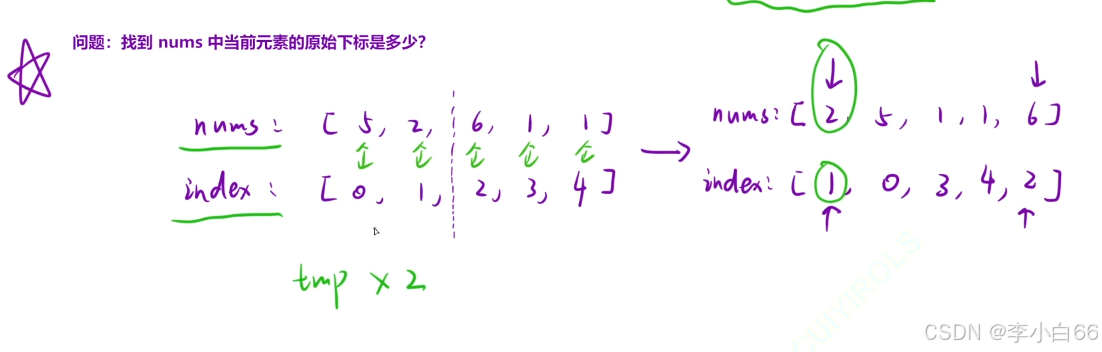
必刷算法100题之计算右侧小于当前元素的个数
题目链接 315. 计算右侧小于当前元素的个数 - 力扣(LeetCode) 题目解析 计算数组里面所有元素右侧比它小的数的个数, 并且组成一个数组,进行返回 算法原理 归并解法(分治) 当前元素的后面, 有多少个比我小(降序) 我们要找到第一比左边小的元素, 这样…...

Python依赖注入完全指南:高效解耦、技术深析与实践落地
Python依赖注入完全指南:高效解耦、技术深析与实践落地 摘要 依赖注入(DI)不仅是一种设计技术,更是一种解耦的艺术。它通过削减模块间的强耦合性,为系统提供了更高的灵活性和可测试性,特别是在 FastAPI 等…...
)
android弱网环境数据丢失解决方案(3万字长文)
在移动互联网时代,Android 应用已经成为人们日常生活中不可或缺的一部分。从社交媒体到在线购物,从移动办公到娱乐游戏,用户对应用的依赖程度与日俱增。然而,尽管网络基础设施在全球范围内得到了显著改善,弱网环境依然是一个普遍存在且难以完全避免的现实。特别是在一些发…...

答案之书和源代码
答案之书是一个神秘而神奇的工具,它可以帮助你在遇到问题或犹豫不决的时候找到答案或暗示。这个程序模拟了答案之书的功能,让你随机生成一个简短而有启发性的答案,让你在困境中找到一丝希望。 在这个程序中,你会看到一个画布上显…...

Spring Cloud主要组件介绍
一、Spring Cloud 1、Spring Cloud技术概览 分为:服务治理,链路追踪,消息组件,配置中心,安全控制,分布式任务管理、调度,Cluster工具,Spring Cloud CLI,测试 2、注册中心:常用注册中心(Euerka[AP]、Zookeeper[CP]) 1)Euerka Client(服务提供者)=》注册=》Eue…...