【实战手册】8000w数据迁移实践:MySQL到MongoDB的完整解决方案
🔥 本文将带你深入解析大规模数据迁移的实践方案,从架构设计到代码实现,手把手教你解决数据迁移过程中的各种挑战。
📚博主其他匠心之作,强推专栏:
- 小游戏开发【博主强推 匠心之作 拿来即用无门槛】

文章目录
- 一、场景引入
- 1. 问题背景
- 2. 场景分析
- 为什么需要消息队列?
- 为什么选择Redis?
- 技术选型对比
- 二、技术方案设计
- 1. 整体架构
- 2. 核心组件设计
- 2.1 任务管理模块
- 2.1.1 MigrationStarter
- 2.1.2 MigrationTaskManager
- 2.2 数据读取模块
- 2.2.1 DataReader
- 2.2.2 OrderMapper
- 2.3 Redis队列模块
- 2.3.1 RedisQueue
- 2.4 消费者模块
- 2.4.1 ConsumerManager
- 2.4.2 ConsumerWorker
- 2.4.3 MongoWriter
- 2.4.4 MongoDBMonitor
- 2.4.5 ConsumerProgressManager
- 写在最后
一、场景引入
场景:需要将8000w条历史订单数据从原有MySQL数据库迁移到新的MongoDB集群中,你有什么好的解决方案? 大家可以先暂停,自己思考一下。
1. 问题背景
需要将8000w条历史订单数据从原有MySQL数据库迁移到新的MongoDB集群中,主要面临以下挑战:
- 源库压力:直接读取大量数据会影响线上业务
- 目标库压力:直接写入大量数据可能导致MongoDB性能下降
- 数据一致性:确保迁移过程中数据不丢失、不重复
- 迁移效率:需要在规定时间窗口内完成迁移
- 异常处理:支持断点续传,避免异常导致全量重试
2. 场景分析
为什么需要消息队列?
- 源库保护:
- 通过消息队列控制读取速度
- 避免大量查询影响线上业务
- 任务解耦:
- 将数据读取和写入解耦
- 支持独立扩展读写能力
- 流量控制:
- 控制写入MongoDB的速度
- 避免瞬时高并发
为什么选择Redis?
- 性能考虑:
- Redis的list结构天然支持队列操作
- 单机QPS可达10w级别
- 可靠性:
- 支持持久化,防止数据丢失
- 主从架构保证高可用
- 成本因素:
- 无需额外引入消息队列组件
- 降低系统复杂度
- 实现简单:
- 开发成本低
- 维护成本低
技术选型对比
| 方案 | 优势 | 劣势 | 是否采用 |
|---|---|---|---|
| 直接迁移 | 实现简单 | 压力大,风险高 | 否 |
| Redis队列 | 实现简单,成本低 | 单机容量有限 | 是 |
| Kafka | 吞吐量大,持久化好 | 部署复杂,成本高 | 否 |
| RabbitMQ | 功能完善 | 过重,维护成本高 | 否 |
二、技术方案设计
1. 整体架构
MySQL(Source) -> Data Reader -> Redis Queue -> Consumer Workers -> MongoDB(Target)↑ ↑ ↑ ↑限流控制 队列监控告警 消费进度监控 写入状态监控
整个迁移过程说起来很简单:从MySQL读数据,写到Redis队列,消费者从Redis读取后写入MongoDB。但魔鬼藏在细节里,让我们一步步看看要注意什么:
MySQL数据读取
首先是MySQL这块,我们不能无脑读取。想象一下,如果不控制读取速度,直接大量读取数据,很可能会影响到线上正常业务。所以这里有两个关键点:
- 选择合适的时间。建议在业务低峰期,比如凌晨,这时候可以适当提高读取速率。
- 控制读取速度。通过监控MySQL的负载情况,动态调整读取速率。
读取方式
读取数据时要格外注意顺序问题。我们一般用创建时间和ID来排序:
- 先按创建时间排序
- 如果时间相同,再按ID排序
- 每次读取都记录当前的时间点和ID
- 下次继续读取时,就从这个位置开始
Redis队列控制
数据读出来了,不能直接往Redis里写。Redis也是有容量限制的,需要合理控制:
- 假设一条订单数据1KB(实际可能2-3KB)
- 单实例Redis一般4-8G,按8G算
- 建议只用30%给这个任务,也就是2.4GB
- 差不多能放2400万条数据,超过就要告警
- 如果队列积压严重,要停止写入,等消费者消费一些后再继续
数据写入流程
整个写入过程要严格保证可靠性:
- 读取数据
- 记录任务进度
- 写入Redis
- 这几步要在一个事务里完成
- 如果失败了要记录下来,方便重试
消费者处理
消费这块要特别注意几个问题:
- 从Redis读取数据
- 写入MongoDB
- 确认消费完成
- 记录消费进度
- 失败要支持重试
- 整个过程要保证幂等性,防止重复消费
MongoDB写入控制
最后写MongoDB时也要注意控制速度:
- 监控MongoDB的负载情况
- 根据负载动态调整写入速度
- 避免写入太快导致MongoDB压力过大
通过这样的设计,我们就能实现一个相对可靠的数据迁移方案。当然,实际实现时还需要考虑更多细节,比如异常处理、监控告警等。
2. 核心组件设计
在开始具体的代码实现之前,让我们先理解每个组件的职责和实现思路。
2.1 任务管理模块
首先来看任务管理相关的代码实现。这部分主要包含两个核心类:MigrationStarter和MigrationTaskManager。
2.1.1 MigrationStarter
这是整个迁移任务的入口类,负责创建任务并提交给任务管理器。它的主要职责是:
- 生成唯一的任务ID
- 创建迁移任务实例
- 提交任务到管理器
/*** 数据迁移启动器* 作为整个迁移任务的入口*/
@Slf4j
@Component
public class MigrationStarter {@Autowiredprivate MigrationTaskManager taskManager; // 迁移任务管理器/*** 启动迁移任务* @param startTime 开始时间* @param endTime 结束时间*/public void startMigration(LocalDateTime startTime, LocalDateTime endTime) {// 1. 创建迁移任务String taskId = UUID.randomUUID().toString(); // 生成任务IDMigrationTask task = new MigrationTask(taskId, startTime, endTime); // 创建迁移任务// 2. 提交任务taskManager.submitTask(task); // 提交任务log.info("迁移任务已提交,taskId={}", taskId); // 日志记录 }
}
2.1.2 MigrationTaskManager
任务管理器负责任务的具体执行和生命周期管理。它实现了:
- 线程池管理
- 任务执行流程控制
- 异常处理和重试机制
/*** 迁移任务管理器* 负责任务的调度和管理*/
@Slf4j
@Component
public class MigrationTaskManager {@Autowiredprivate DataReader dataReader;@Autowiredprivate MongoWriter mongoWriter;@Autowiredprivate RedisQueue redisQueue;// 线程池配置private final ExecutorService executorService = new ThreadPoolExecutor(5, 10, 60L, TimeUnit.SECONDS,new LinkedBlockingQueue<>(1000),new ThreadFactoryBuilder().setNameFormat("migration-pool-%d").build());/*** 提交迁移任务*/@Transactional(rollbackFor = Exception.class)public void submitTask(MigrationTask task) {executorService.submit(() -> {try {// 1. 初始化任务task.init();// 2. 执行数据读取while (task.hasNext()) {// 读取数据List<Order> orders = dataReader.readNextBatch(task);// 在事务中执行更新进度和写入Redis队列transactionTemplate.execute(status -> {try {// 先更新任务进度(持久化)task.updateProgress(orders);// 原子性写入Redis队列redisQueue.pushBatchAtomic(orders);return true;} catch (Exception e) {status.setRollbackOnly();throw new RuntimeException("处理批次数据失败", e);}});}// 3. 完成任务task.complete();} catch (Exception e) {log.error("任务执行异常", e);task.fail(e);}});}
}
2.2 数据读取模块
数据读取是整个迁移过程的起点,需要特别注意读取性能和源库压力控制。这部分包含两个关键类:
2.2.1 DataReader
数据读取器负责从MySQL中批量读取数据,实现了:
- 动态批次大小调整
- 读取速率控制
- 异常处理机制
/*** 数据读取器*/
@Slf4j
@Component
public class DataReader {private final RateLimiter rateLimiter;@Autowiredprivate MySQLMonitor mysqlMonitor;private int currentBatchSize = 1000; // 初始批次大小private static final int MIN_BATCH_SIZE = 100;private static final int MAX_BATCH_SIZE = 5000;public DataReader() {// 初始速率设置this.rateLimiter = RateLimiter.create(100); // 每秒100个请求}/*** 动态调整读取速率*/private void adjustReadingRate() {if (!mysqlMonitor.checkMySQLStatus()) {// 降低速率和批次大小rateLimiter.setRate(rateLimiter.getRate() * 0.8);currentBatchSize = Math.</相关文章:
【实战手册】8000w数据迁移实践:MySQL到MongoDB的完整解决方案
🔥 本文将带你深入解析大规模数据迁移的实践方案,从架构设计到代码实现,手把手教你解决数据迁移过程中的各种挑战。 📚博主其他匠心之作,强推专栏: 小游戏开发【博主强推 匠心之作 拿来即用无门槛】文章目录 一、场景引入1. 问题背景2. 场景分析为什么需要消息队列?为…...

麒麟高级服务器操作系统内核升级
1. 确认系统及内核版本 使用uname -r命令查看当前系统内核版本 ,使用cat /etc/.productinfo等命令确认操作系统版本,以便后续操作适配。 2. 查看可用内核版本 运行sudo yum list kernel* ,该命令会列出当前 yum 源中可用的内核相关包及版本信息&#…...

OpenAI为抢跑AI,安全底线成牺牲品?
几年前,如果你问任何一个AI从业者,安全测试需要多长时间,他们可能会淡定地告诉你:“至少几个月吧,毕竟这玩意儿可能改变世界,也可能毁了它。”而现在,OpenAI用实际行动给出了一个新答案——几天…...

OpenCV 图形API(25)图像滤波-----均值滤波(模糊处理)函数blur()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 使用归一化的方框滤波器模糊图像。 该函数使用以下核来平滑图像: K 1 k s i z e . w i d t h k s i z e . h e i g h t [ 1 1 ⋯ …...

大模型——Crawl4AI入门指南
大模型——Crawl4AI入门指南 本快速入门指南介绍了Crawl4AI,涵盖了基本用法、先进功能(例如分块和提取策略)以及异步编程。用户将学习如何实现各种爬虫技术,包括截图、JSON提取和动态内容爬取。 1. 什么是Crawl4AI? Crawl4AI 是一个强大的异步网络爬虫库,旨在简化信息…...
轻量级开源文件共享系统PicoShare本地部署并实现公网环境文件共享
## 前言 本篇文章介绍,如何在 Linux 系统本地部署轻量级文件共享系统 PicoShare,并结合 Cpolar 内网穿透实现公网环境远程传输文件至本地局域网内文件共享系统。 PicoShare 是一个由 Go 开发的轻量级开源共享文件系统,它没有文…...
UE5蓝图之间的通信------接口
一、创建蓝图接口 二、双击创建的蓝图接口,添加函数,并重命名新函数。 三、在一个蓝图(如玩家角色蓝图)中实现接口,如下图: 步骤一:点击类设置 步骤二:在细节面板已经实现的接口中…...
银河麒麟服务器操作系统V10安装Nvidia显卡驱动和CUDA(L40)并安装ollama运行DeepSeek【开荒存档版】
前期说明 麒麟官方适配列表查找没有L40,只有海光和兆芯适配麒麟V10,不适配Intel芯片 但是我在英伟达驱动列表查到是适配的! 反正都算是X86,我就直接开始干了,按照上面安装系统版本为:银河麒麟kylinos V10 sp3 2403 输入nkvers可以查看麒麟系统具体版本: 安装Nvid…...
学习八股的随机思考
随时有八股思考都更新一下,理解的学一下八股。谢谢大家的阅读,有错请大家指出。 bean的生命周期 实际上只有四步 实例化 ----> 属性赋值 ---> 初始化 ---> 销毁 但是在实例化前后 初始化前后 会存在一些前置后置的处理,目的是增…...
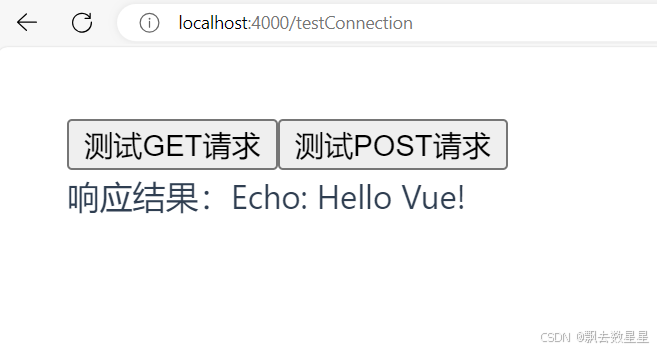
山东大学软件学院创新项目实训开发日志(10)之测试前后端连接
在正式开始前后端功能开发前,在队友的帮助下,成功完成了前后端测试连接: 首先在后端编写一个测试相应程序: 然后在前端创建vue 并且在index.js中添加一下元素: 然后进行测试,测试成功: 后续可…...
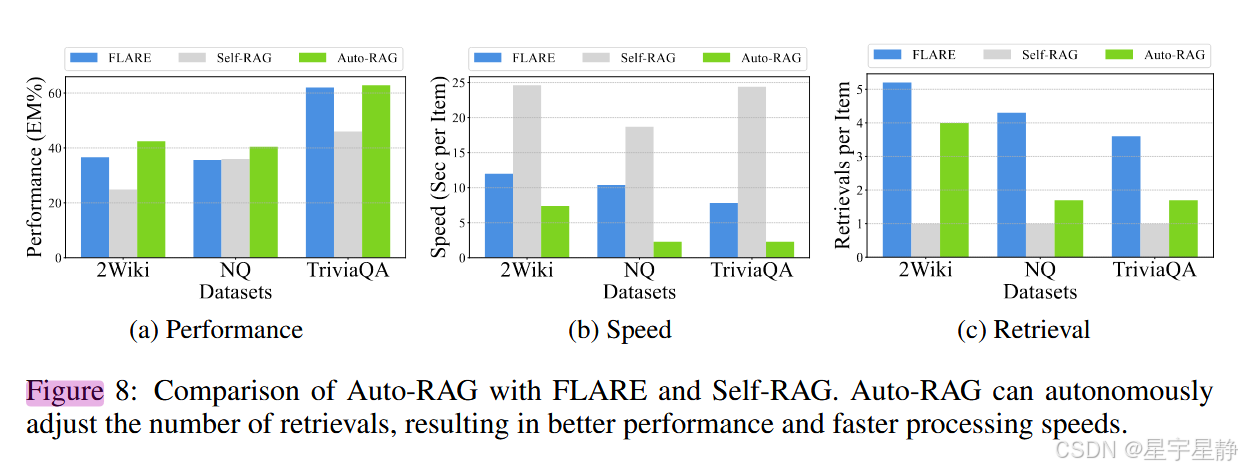
AUTO-RAG: AUTONOMOUS RETRIEVAL-AUGMENTED GENERATION FOR LARGE LANGUAGE MODELS
Auto-RAG:用于大型语言模型的自主检索增强生成 单位:中科院计算所 代码: https://github.com/ictnlp/Auto-RAG 拟解决问题:通过手动构建规则或者few-shot prompting产生的额外推理开销。 贡献:提出一种以LLM决策为中…...
基础贪心算法集合2(10题)
目录 1.单调递增的数字 2.坏了的计算器 3.合并区间 4.无重叠区间 5. 用最少数量的箭引爆气球 6.整数替换 解法1:模拟记忆化搜索 解法2位运算贪心 7.俄罗斯套娃信封问题 补充.堆箱子 8.可被3整除的最大和 9.距离相等的条形码 10.重构字符串 1.单调递增的数字…...
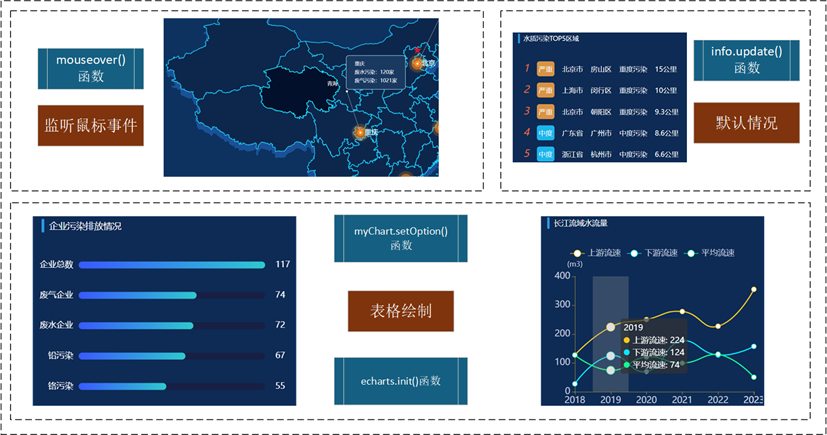
空间信息可视化——WebGIS前端实例(二)
技术栈:原生HTML 源代码:CUGLin/WebGIS: This is a project of Spatial information visualization 5 水质情况实时监测预警系统 5.1 系统设计思想 水安全是涉及国家长治久安的大事。多年来,为相应国家战略,诸多地理信息领域的…...

Vue3微前端架构全景解析:模块联邦与渐进式集成
一、微前端核心模式 1.1 主应用与微应用通讯机制 1.2 架构模式对比 维度iFrame方案Web Components模块联邦组合式微前端样式隔离完全隔离Shadow DOM构建时CSS作用域动态样式表通信复杂度困难(postMessage)自定义事件依赖共享Props传递依赖共享不共享按需加载自动共享显式声明…...

多模态大语言模型arxiv论文略读(十九)
MLLMs-Augmented Visual-Language Representation Learning ➡️ 论文标题:MLLMs-Augmented Visual-Language Representation Learning ➡️ 论文作者:Yanqing Liu, Kai Wang, Wenqi Shao, Ping Luo, Yu Qiao, Mike Zheng Shou, Kaipeng Zhang, Yang Yo…...

【蓝桥杯选拔赛真题101】Scratch吐丝的蜘蛛 第十五届蓝桥杯scratch图形化编程 少儿编程创意编程选拔赛真题解析
目录 scratch吐丝的蜘蛛 一、题目要求 1、准备工作 2、功能实现 二、案例分析 1、角色分析 2、背景分析 3、前期准备 三、解题思路 四、程序编写 五、考点分析 六、推荐资料 1、scratch资料 2、python资料 3、C++资料 scratch吐丝的蜘蛛 第十五届青少年蓝桥杯s…...

springboot集成spring-cloud-context手动刷新并读取更新后的配置文件
背景 springboot单体项目在运行过程需要刷新springboot配置文件值,比如某个接口限流阈值,新增某个账户等场景。分布式设计的可以直接引入一些持久化中间件比如redis等,也可以用相关配置中心中间件如nacos等。处于成本等场景单体项目可以考虑①…...

游戏引擎学习第221天:(实现多层次过场动画)
资产: intro_art.hha 已发布 在下载页面,你会看到一个新的艺术包。你将需要这个艺术包来进行接下来的开发工作。这个艺术包是由一位艺术家精心制作并打包成我们设计的格式,旨在将这些艺术资源直接应用到游戏中。它包含了许多我们会在接下来的直播中使用…...
(java)重构字符串)
贪心算法(19)(java)重构字符串
题目:给定一个字符串 s ,检查是否能重新排布其中的字母,使得两相邻的字符不同。 返回 s 的任意可能的重新排列。若不可行,返回空字符串 "" 。 示例 1: 输入: s "aab" 输出: "aba"示例 2: 输入:…...
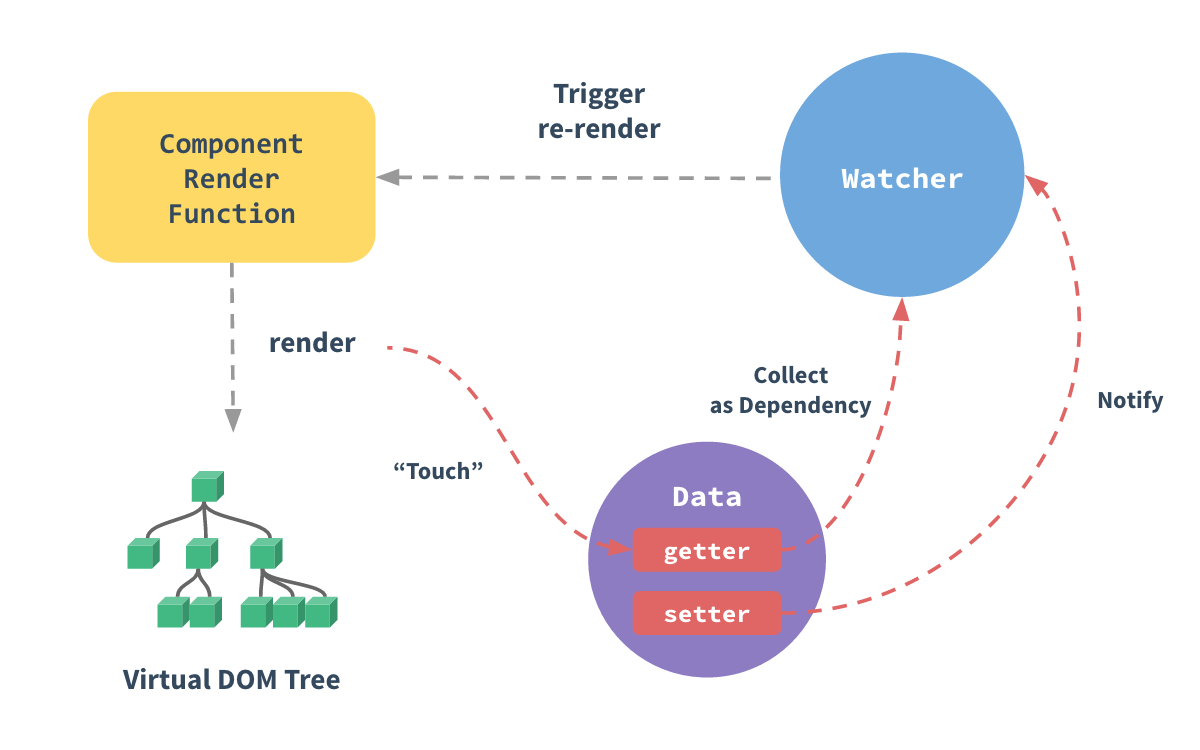
前端基础之《Vue(4)—响应式原理》
一、什么是响应式 1、响应式英文reactive 当你get/set一个变量时,你有办法可以“捕获到”这种行为。 2、一个普通对象和一个响应式对象对比 (1)普通对象 <script>// 这种普通对象不具备响应式var obj1 {a: 1,b: 2} </script>…...
Go学习系列文章声明
本次学习是基于B站的视频,【Udemy高分热门付费课程】Golang:完整开发者指南(基础知识和高级特性)中英文字幕_哔哩哔哩_bilibili 本人会尝试输出视频中的内容,如有错误欢迎指出 next page: Go installation process...
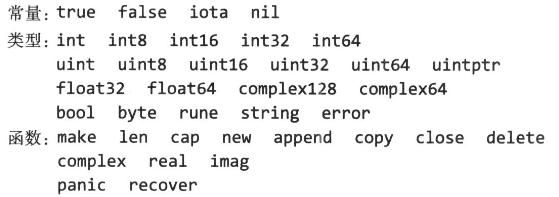
Go:程序结构
文章目录 名称声明变量短变量声明指针new 函数变量的生命周期 赋值多重赋值可赋值性 类型声明包和文件导入包初始化 作用域 名称 命名规则: 通用规则:函数、变量、常量、类型、语句标签和包的名称,开头须是字母(Unicode 字符 &a…...

【GitHub探索】mcp-go,MCP协议的Golang-SDK
近期大模型Agent应用开发方面,MCP的概念比较流行,基于MCP的ToolServer能力开发也逐渐成为主流趋势。由于笔者工作原因,主力是Go语言,为了调研大模型应用开发,也接触到了mcp-go这套MCP的SDK实现。 对于企业内部而言&am…...
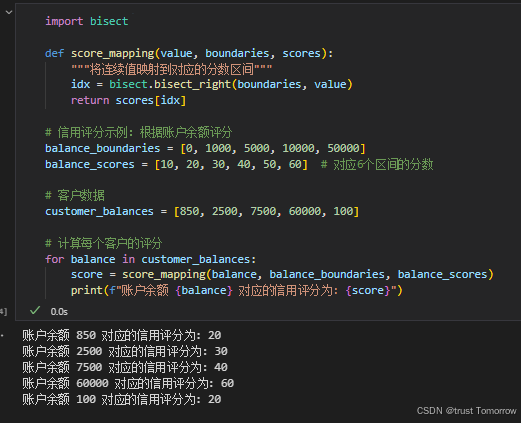
Python 二分查找(bisect):排序数据的高效检索
二分查找:排序数据的高效检索 第二天清晨,李明早早来到了图书馆。今天他的研究目标是bisect模块,特别是其中的bisect_left和bisect_right函数。这些函数实现了二分查找算法,用于在已排序的序列中高效地查找元素或确定插入位置。 …...

【数据结构】堆排序详细图解
堆排序目录 1、什么是堆?1.1、什么是大顶堆1.2、什么是小顶堆 2、堆排序的过程3、堆排序的图解3.1、将数组映射成一个完全二叉树3.2、将数组转变为一个大顶堆3.3、开始进行堆排序 4、堆排序代码 1、什么是堆? 堆的定义:在一棵完全二叉树中&a…...
如何排查Dubbo的序列化问题?)
Dubbo(45)如何排查Dubbo的序列化问题?
排查Dubbo的序列化问题需要从多个角度进行分析,包括序列化协议的配置、序列化对象的定义、序列化框架的兼容性等。以下是详细的排查步骤及相关代码示例: 1. 检查序列化协议配置 Dubbo支持多种序列化协议(如Hessian、Kryo、FST等)…...

有哪些基于solidity的应用
🔥 Solidity 常见应用分类(附例子) 🏦 1. DeFi(去中心化金融) Solidity 的最大应用场景之一。 项目功能示例合约逻辑Uniswap去中心化交易所(AMM)流动性池、定价算法、swap函数Aave /…...

CST1016.基于Spring Boot+Vue高校竞赛管理系统
计算机/JAVA毕业设计 【CST1016.基于Spring BootVue高校竞赛管理系统】 【项目介绍】 高校竞赛管理系统,基于 DeepSeek Spring AI Spring Boot Vue 实现,功能丰富、界面精美 【业务模块】 系统共有两类用户,分别是学生用户和管理员用户&a…...
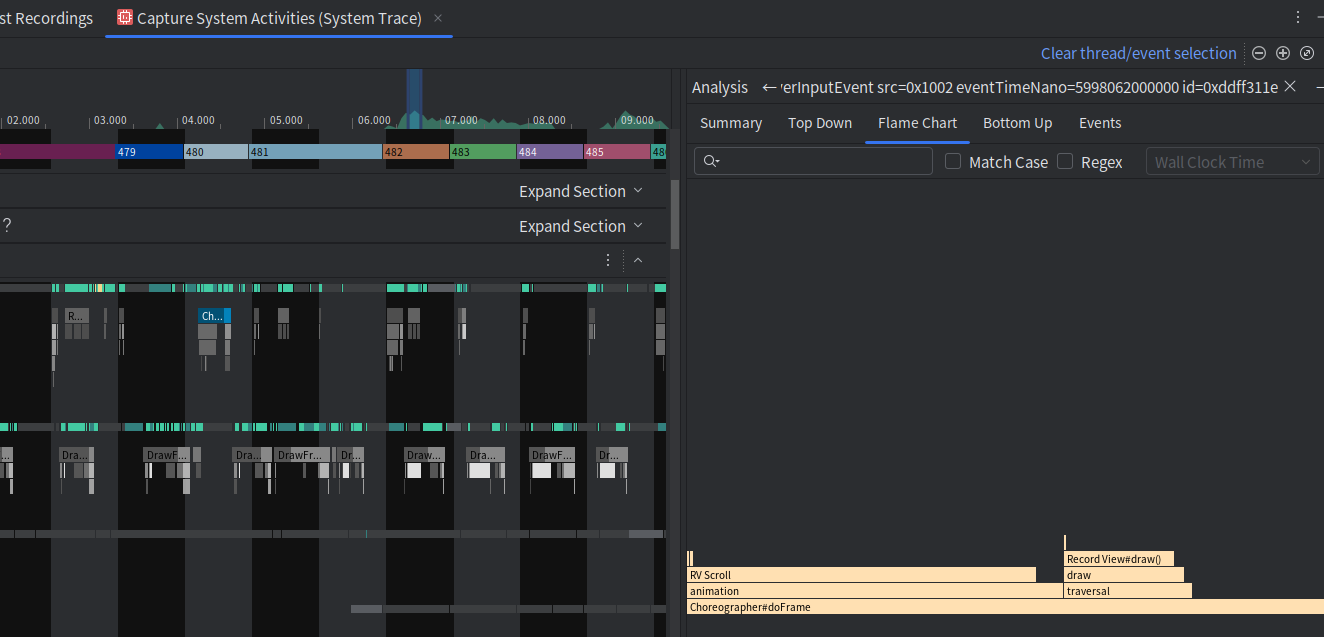
安卓性能调优之-掉帧测试
掉帧指的是某一帧没有在规定时间内完成渲染,导致 UI 画面不流畅,产生视觉上的卡顿、跳帧现象。 Android目标帧率: 一般情况下,Android设备的屏幕刷新率是60Hz,即每秒需要渲染60帧(Frame Per Second, FPS&a…...
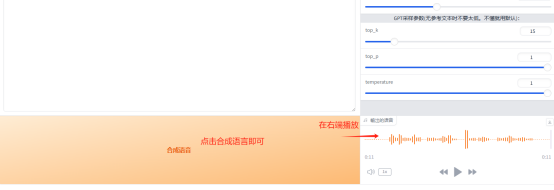
GPT-SoVITS:5 步实现 AI 语音克隆
在 AI 技术高速迭代的今天,语音合成早已突破”机械朗读“的局限 —— 从短视频创作者的虚拟配音、游戏角色的个性化声线,到智能客服的自然交互,GPT-SoVITS正凭借其强大的多模态融合能力,成为实现”AI 声音克隆“与“情感化语音生成…...