六、分布式嵌入
六、分布式嵌入
文章目录
- 六、分布式嵌入
- 前言
- 一、先要配置torch.distributed环境
- 二、Distributed Embeddings
- 2.1 EmbeddingBagCollectionSharder
- 2.2 ShardedEmbeddingBagCollection
- 三、Planner
- 总结
前言
- 我们已经使用了TorchRec的主模块:EmbeddedBagCollection。我们在上一节研究了它是如何工作的,以及数据在TorchRec中是如何表示的。然而,我们还没有探索TorchRec的主要部分之一,即分布式嵌入
一、先要配置torch.distributed环境
- EmbeddingBagCollectionSharder 依赖于 PyTorch 的分布式通信库(torch.distributed)来管理跨进程/GPU 的分片和通信。
首先初始化分布式环境
import torch.distributed as dist# 初始化进程组
dist.init_process_group(backend="nccl", # GPU 推荐 NCCL 后端, CPU就是 glooinit_method="env://", # 从环境变量读取节点信息rank=rank, # 当前进程的全局唯一标识(从 0 开始)world_size=world_size, # 总进程数(总 GPU 数)
)pg = dist.GroupMember.WORLD
设置环境变量(多节点训练时必须)
import torch.distributed as dist# 初始化进程组
# 在每个节点上设置以下环境变量
export MASTER_ADDR="主节点IP" # 如 "192.168.1.1"
export MASTER_PORT="66666" # 任意未占用端口
export WORLD_SIZE=4 # 总 GPU 数
export RANK=0 # 当前节点的全局 rank
二、Distributed Embeddings
- 先回顾一下我们上一节的EmbeddingBagCollection module
代码演示:
print(ebc)
"""
EmbeddingBagCollection((embedding_bags): ModuleDict((product_table): EmbeddingBag(4096, 64, mode='sum')(user_table): EmbeddingBag(4096, 64, mode='sum'))
)
"""
2.1 EmbeddingBagCollectionSharder
- 策略制定者 ,决定如何分片。
- 决定如何将 EmbeddingBagCollection 的嵌入表(Embedding Tables)分布到多个 GPU/节点。
核心功能 :根据配置(如 ShardingType)生成分片计划(Sharding Plan)
代码演示:
from torchrec.distributed.embedding_types import ShardingType
from torchrec.distributed.embeddingbag import EmbeddingBagCollectionSharder# 定义分片器:指定分片策略(如按表分片)
sharder = EmbeddingBagCollectionSharder(sharding_type=ShardingType.TABLE_WISE.value, # 每个表分配到一个 GPUkernel_type=EmbeddingComputeKernel.FUSED.value, # 使用 fused 优化
)
- 关键参数
- sharding_type:分片策略,如:
- TABLE_WISE:整个表放在一个 GPU。
- ROW_WISE:按行分片到多个 GPU。
- COLUMN_WISE:按列分片(适用于超大表)。
- kernel_type:计算内核类型(如 FUSED 优化显存)
- sharding_type:分片策略,如:
2.2 ShardedEmbeddingBagCollection
- 策略执行者 ,实际管理分片后的嵌入表
- 根据 EmbeddingBagCollectionSharder 生成的分片计划,实际管理分布在多设备上的嵌入表。
- 核心功能 :在分布式环境中执行前向传播、梯度聚合和参数更新
代码演示:
from torchrec.distributed.embeddingbag import ShardedEmbeddingBagCollection# 根据分片器生成分片后的模块
sharded_ebc = ShardedEmbeddingBagCollection(module=ebc, # 原始 EmbeddingBagCollectionsharder=sharder, # 分片策略device=device, # 目标设备(如 GPU:0)
)
三、Planner
- 它可以帮助我们确定最佳的分片配置。
- Planner能够根据嵌入表的数量和GPU的数量来确定最佳配置。事实证明,这很难手动完成,工程师必须考虑大量因素来确保最佳的分片计划。
- TorchRec在提供的这个Planner,可以帮助我们:
- 评估硬件的内存限制
- 将基于存储器获取的计算估计为嵌入查找
- 解决数据特定因素
- 考虑其他硬件细节,如带宽,以生成最佳分片计划
演示代码:
from torchrec.distributed.planner import EmbeddingShardingPlanner, Topology# 初始化Planner
planner = EmbeddingShardingPlanner(topology=Topology( # 硬件拓扑信息world_size=4, # 总 GPU 数compute_device="cuda",local_world_size=2, # 单机 GPU 数batch_size=1024, ),constraints={ # 可选约束(如强制某些表使用特定策略)"user_id": ParameterConstraints(sharding_types=[ShardingType.TABLE_WISE]),},
)# 生成分片计划
plan = planner.collective_plan(ebc, [sharder], pg)# 分片后的模型
from torchrec.distributed.embeddingbag import ShardedEmbeddingBagCollectionsharded_ebc = ShardedEmbeddingBagCollection(module=ebc,sharder=sharder,device=torch.device("cuda:0"),plan=plan, # 应用自动生成的分片计划
)
总结
- TorchRec中的分布式嵌入以及训练设置。
相关文章:

六、分布式嵌入
六、分布式嵌入 文章目录 六、分布式嵌入前言一、先要配置torch.distributed环境二、Distributed Embeddings2.1 EmbeddingBagCollectionSharder2.2 ShardedEmbeddingBagCollection 三、Planner总结 前言 我们已经使用了TorchRec的主模块:EmbeddedBagCollection。我…...
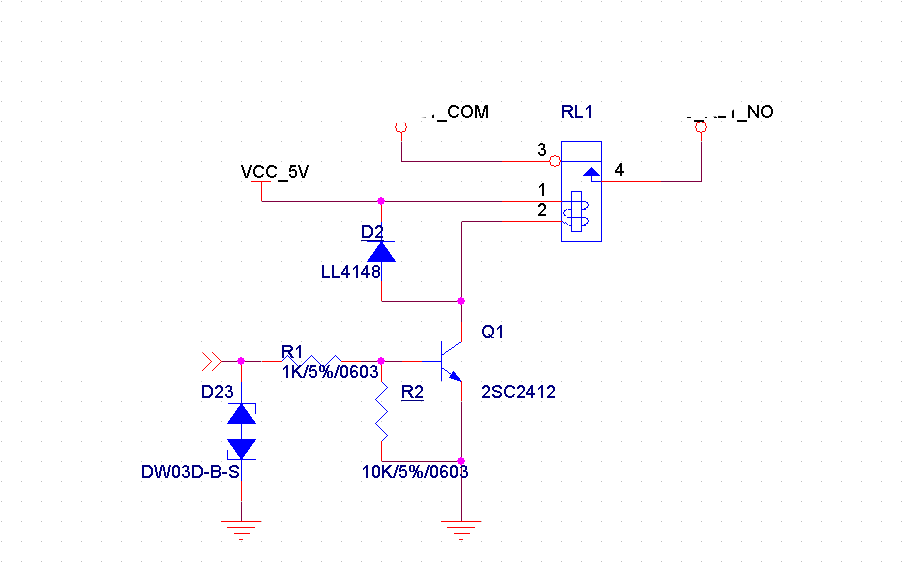
硬件知识积累 单片机+ 光耦 + 继电器需要注意的地方
1. 电路图 与其数值描述 1.1 单片机引脚信号为 OPtoCoupler_control_4 PC817SB 为 光耦 继电器 SRD-05VDC-SL-A 的线圈电压为 67Ω。 2. 需注意的地方 1. 单片机的推挽输出的电流最大为 25mA 2. 注意光耦的 CTR 参数 3. 注意继电器线圈的 内阻 4. 继电器的开启电压。 因为光耦…...
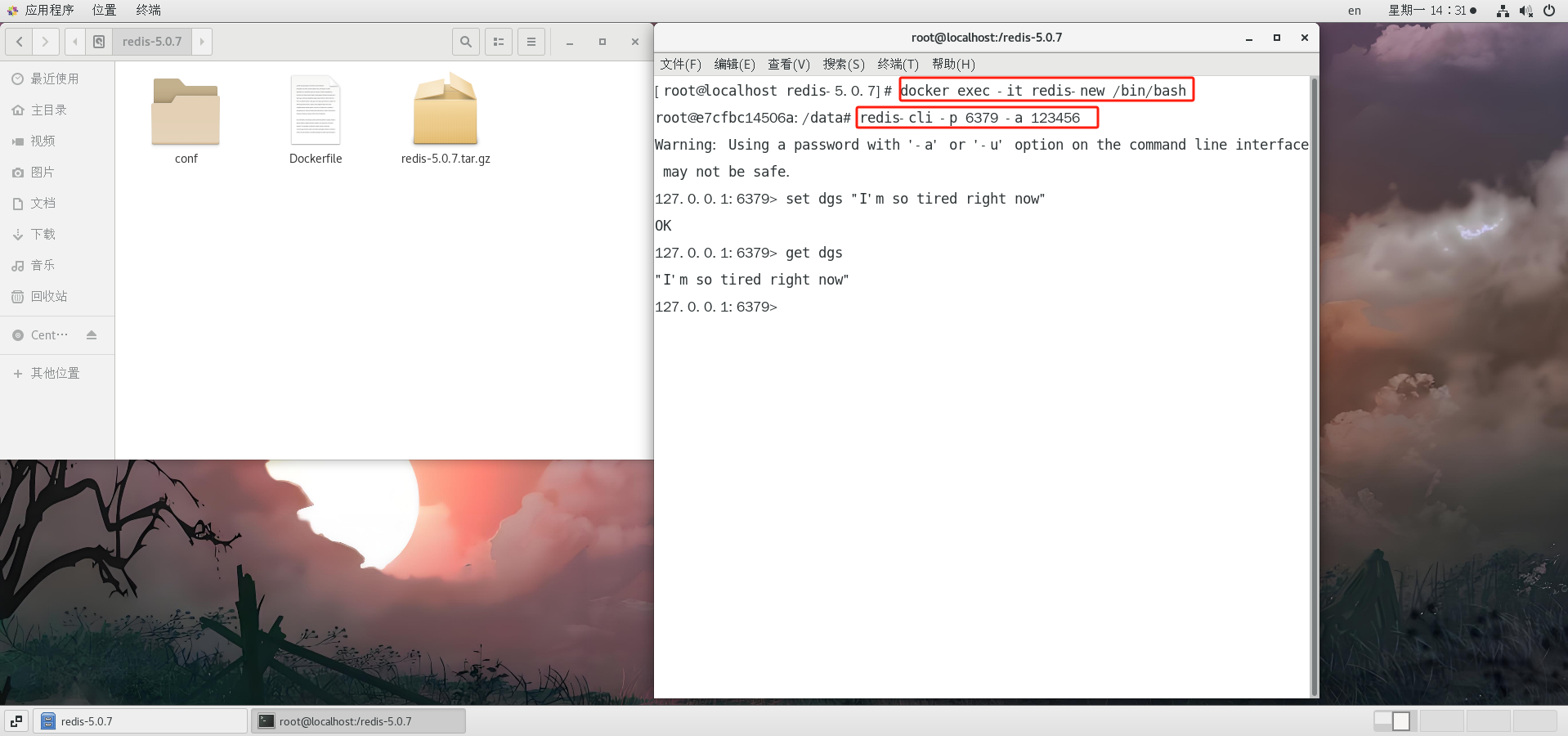
Dockerfile 学习指南和简单实战
引言 Dockerfile 是一种用于定义 Docker 镜像构建步骤的文本文件。它通过一系列指令描述了如何一步步构建一个镜像,包括安装依赖、设置环境变量、复制文件等。在现实生活中,Dockerfile 的主要用途是帮助开发者快速、一致地构建和部署应用。它确保了应用…...

MCU屏和RGB屏
一、MCU屏 MCU屏:全称为单片机控制屏(Microcontroller Unit Screen),在显示屏背后集成了单片机控制器,因此,MCU屏里面有专用的驱动芯片。驱动芯片如:ILI9488、ILI9341、SSD1963等。驱动芯片里…...

Elasticsearch 向量数据库,原生支持 Google Cloud Vertex AI 平台
作者:来自 Elastic Valerio Arvizzigno Elasticsearch 将作为第一个第三方原生语义对齐引擎,支持 Google Cloud 的 Vertex AI 平台和 Google 的 Gemini 模型。这使得联合用户能够基于企业数据构建完全可定制的生成式 AI 体验,并借助 Elastics…...
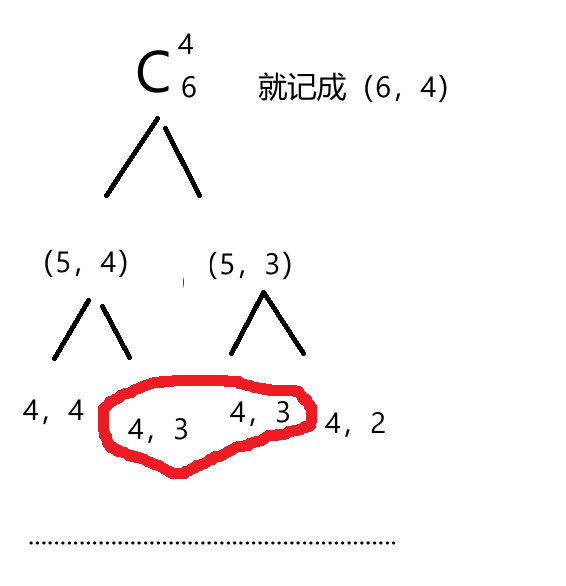
蓝桥杯基础数论入门
一.试除法 首先我们要了解,所有大于1的自然数都能进行质因数分解。试除法作用如下: 质数判断 试除法通过验证一个数是否能被小于它的数(一般是用2到用根号x)整除来判断其是否为质数。根据定义,质数只能被1和自身整除…...

Spring 事件机制与观察者模式的深度解析
一、引言 在软件设计中,观察者模式(Observer Pattern)是一种非常经典且实用的设计模式。它允许一个对象(Subject)在状态发生改变时通知所有依赖它的对象(Observers),从而实现对象之…...

【软考系统架构设计师】信息安全技术基础知识点
1、 信息安全包括5个基本要素:机密性、完整性、可用性、可控性与可审查性。 机密性:确保信息不暴露给未授权的实体或进程。(采取加密措施) 完整性:只有得到允许的人才能修改数据,并且能够判断出数据是否已…...

Python编程快速上手 让繁琐工作自动化笔记
编程基础 字符串使用单引号...

2025年第十六届蓝桥杯省赛真题解析 Java B组(简单经验分享)
之前一年拿了国二后,基本就没刷过题了,实力掉了好多,这次参赛只是为了学校的加分水水而已,希望能拿个省三吧 >_< 目录 1. 逃离高塔思路代码 2. 消失的蓝宝思路代码 3. 电池分组思路代码 4. 魔法科考试思路代码 5. 爆破思路…...

Java 设计模式:策略模式详解
Java 设计模式:策略模式详解 策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列算法,将每个算法封装起来,并使它们可以相互替换。策略模式让算法的变化独立于使用算法的客户端,从…...

什么是TensorFlow?
TensorFlow 是由 Google Brain 团队开发的开源机器学习框架,被广泛应用于深度学习和人工智能领域。它的基本概念包括: 1. 张量(Tensor):在 TensorFlow 中,数据以张量的形式进行处理。张量是多维数组的泛化…...

【3GPP核心网】【5G】精讲5G网络语音业务系统架构
1. 欢迎大家订阅和关注,精讲3GPP通信协议(2G/3G/4G/5G/IMS)知识点,专栏会持续更新中.....敬请期待! 目录 1. 音视频业务 2. 消息类业务 SMS over IMS SMS over NAS 3. 互联互通架构 3.1 音视频业务互通场景 3.2 5G 用户与 5G 用户互通 3.3 5G 用户与 4G 用户的互通…...
01-算法打卡-数组-二分查找-leetcode(704)-第一天
1 数组基础理论 数组是存放在连续内存空间上的相同数据结构的集合。数组可以通过下标索引快速获取数据,因为数组的存储空间是连续的所以在删除、更新数据的时候需要移动其他元素的地址。 下图是一个数组的案例图形:【内存连续、索引小标从0开始可…...
怎么看英文论文 pdf沉浸式翻译
https://arxiv.org/pdf/2105.09492 Immersive Translate Xournal打开...
:冯诺依曼结构)
Linux 进程基础(一):冯诺依曼结构
文章目录 一、冯诺依曼体系结构是什么?🧠二、冯诺依曼体系为何成为计算机组成的最终选择?(一)三大核心优势奠定主流地位(二)对比其他架构的不可替代性 三、存储分级:速度与容量的平衡…...

RabbitMQ 深度解析:从基础到高级应用的全面指南
🐰 RabbitMQ 深度解析:从基础到高级应用的全面指南 前言📘 一、RabbitMQ 简介⚙️ 二、核心特性可靠性 🔒灵活路由 🔄高可用性 🌐多协议支持 🌍多语言客户端 💻插件机制 ὐ…...

【图灵Python爬虫逆向】题七:千山鸟飞绝
题目背景 题目地址:https://stu.tulingpyton.cn/problem-detail/7/ 这一题为中等难度 打开控制台时会发现进入无限debug,可以通过右键点击"一律不在此处暂停"来绕过这个障碍。 一、请求与响应分析 1. 请求参数分析 首先观察网络请求&…...
ubuntu 2404 安装 vcs 2018
参考ubuntu 2204 安装 vcs 2018 系统信息 Ubuntu 24.04.2 LTS ubuntu和 安装后的 vcs 花费了 22G , 其中 "安装后的 vcs" 占13G预先配置 过程 和 2204 安装 vcs 2018 不同, 其他相同 // vm-tools 的安装, 不是虚拟机不需要 sudo apt-get update sudo apt-get inst…...
潇洒浪: Dify 上传自定义文件去除内容校验 File validation failed for file: re.json
Dify上传文件 添加其他文件类型如 my.myselfsuffix 上传成功 执行报错 File validation failed for file: re.json 解决办法 Notepad++ 搜索dify源码...
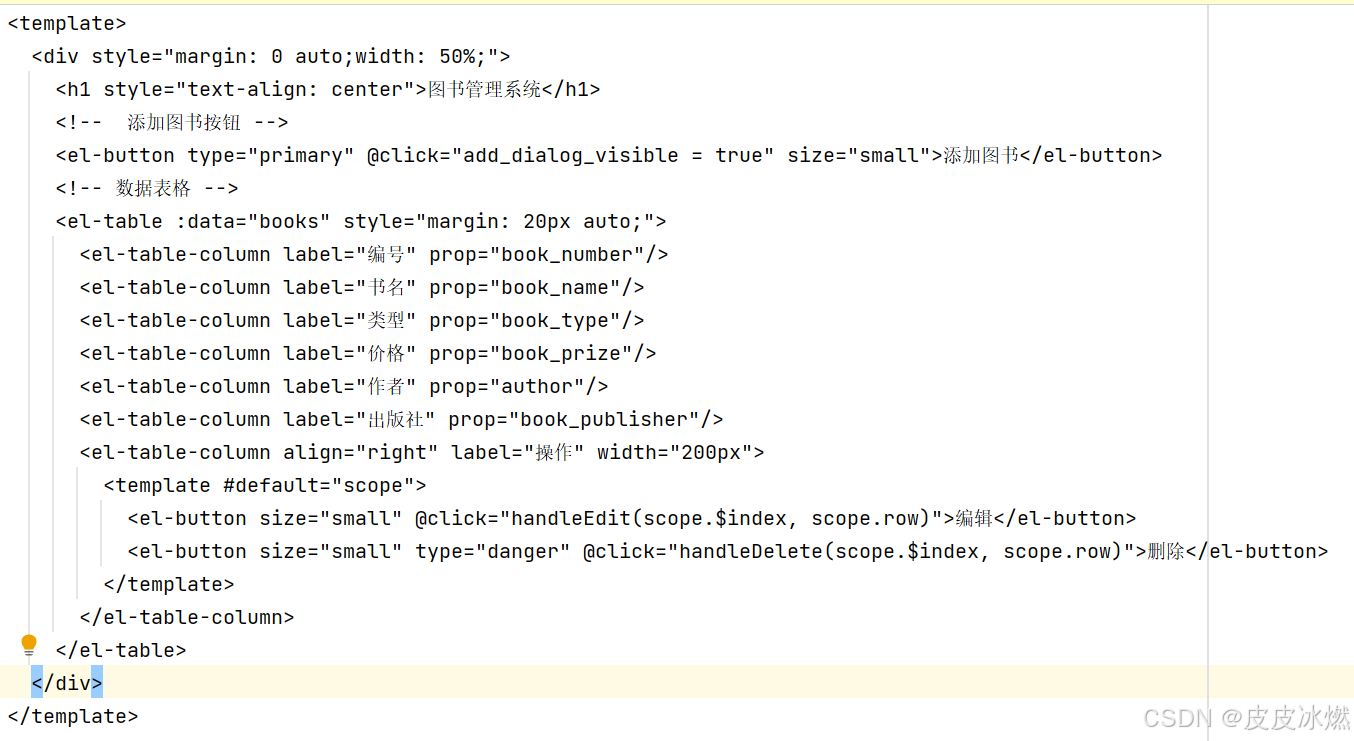
python-66-前后端分离之图书管理系统的Vue前端项目逐行分析
文章目录 1 App.vue的数据表格1.1 template部分1.1.1 div标签1.1.2 h1标签1.1.3 el-button标签1.1.4 el-table标签1.1.5 el-table-column标签1.1.6 表格中放置按钮1.2 script部分1.2.1 加载库和函数1.2.2 创建响应式数组1.2.3 创建getBooks函数1.2.4 onMounted函数1.2.5 创建ha…...

【实战手册】8000w数据迁移实践:MySQL到MongoDB的完整解决方案
🔥 本文将带你深入解析大规模数据迁移的实践方案,从架构设计到代码实现,手把手教你解决数据迁移过程中的各种挑战。 📚博主其他匠心之作,强推专栏: 小游戏开发【博主强推 匠心之作 拿来即用无门槛】文章目录 一、场景引入1. 问题背景2. 场景分析为什么需要消息队列?为…...

麒麟高级服务器操作系统内核升级
1. 确认系统及内核版本 使用uname -r命令查看当前系统内核版本 ,使用cat /etc/.productinfo等命令确认操作系统版本,以便后续操作适配。 2. 查看可用内核版本 运行sudo yum list kernel* ,该命令会列出当前 yum 源中可用的内核相关包及版本信息&#…...

OpenAI为抢跑AI,安全底线成牺牲品?
几年前,如果你问任何一个AI从业者,安全测试需要多长时间,他们可能会淡定地告诉你:“至少几个月吧,毕竟这玩意儿可能改变世界,也可能毁了它。”而现在,OpenAI用实际行动给出了一个新答案——几天…...

OpenCV 图形API(25)图像滤波-----均值滤波(模糊处理)函数blur()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 使用归一化的方框滤波器模糊图像。 该函数使用以下核来平滑图像: K 1 k s i z e . w i d t h k s i z e . h e i g h t [ 1 1 ⋯ …...

大模型——Crawl4AI入门指南
大模型——Crawl4AI入门指南 本快速入门指南介绍了Crawl4AI,涵盖了基本用法、先进功能(例如分块和提取策略)以及异步编程。用户将学习如何实现各种爬虫技术,包括截图、JSON提取和动态内容爬取。 1. 什么是Crawl4AI? Crawl4AI 是一个强大的异步网络爬虫库,旨在简化信息…...
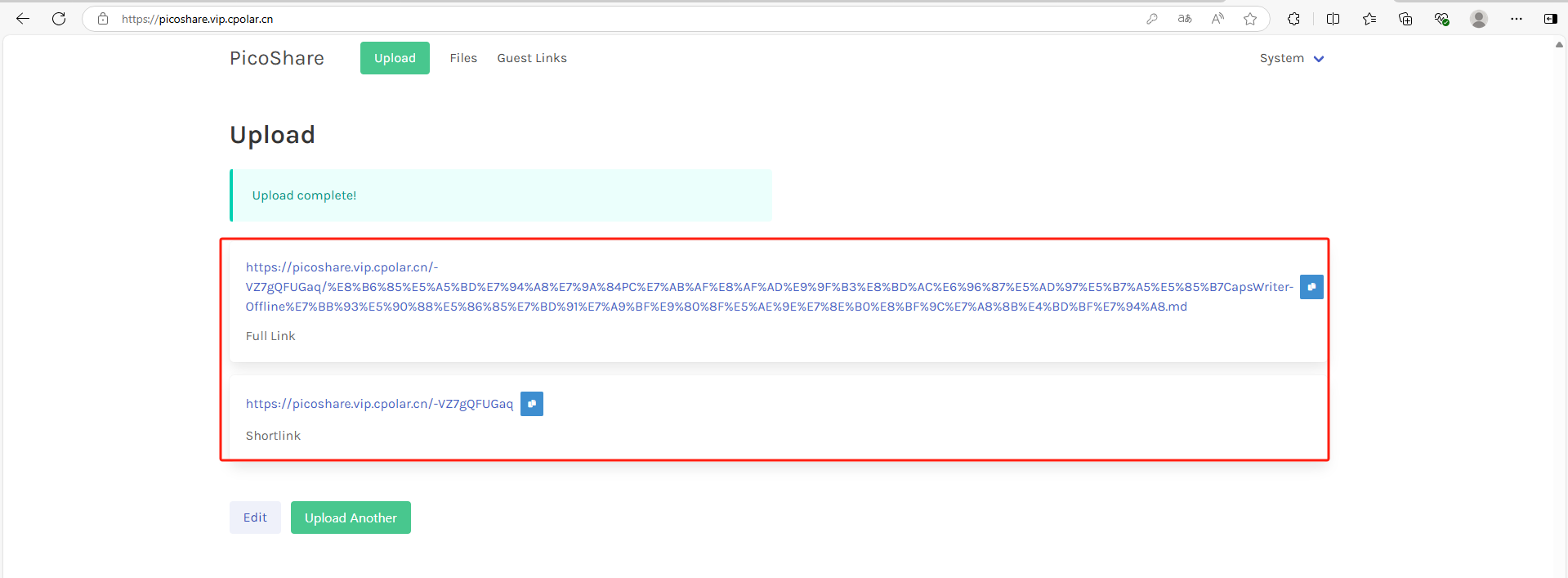
轻量级开源文件共享系统PicoShare本地部署并实现公网环境文件共享
## 前言 本篇文章介绍,如何在 Linux 系统本地部署轻量级文件共享系统 PicoShare,并结合 Cpolar 内网穿透实现公网环境远程传输文件至本地局域网内文件共享系统。 PicoShare 是一个由 Go 开发的轻量级开源共享文件系统,它没有文…...
UE5蓝图之间的通信------接口
一、创建蓝图接口 二、双击创建的蓝图接口,添加函数,并重命名新函数。 三、在一个蓝图(如玩家角色蓝图)中实现接口,如下图: 步骤一:点击类设置 步骤二:在细节面板已经实现的接口中…...
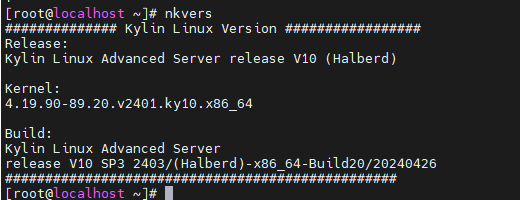
银河麒麟服务器操作系统V10安装Nvidia显卡驱动和CUDA(L40)并安装ollama运行DeepSeek【开荒存档版】
前期说明 麒麟官方适配列表查找没有L40,只有海光和兆芯适配麒麟V10,不适配Intel芯片 但是我在英伟达驱动列表查到是适配的! 反正都算是X86,我就直接开始干了,按照上面安装系统版本为:银河麒麟kylinos V10 sp3 2403 输入nkvers可以查看麒麟系统具体版本: 安装Nvid…...
学习八股的随机思考
随时有八股思考都更新一下,理解的学一下八股。谢谢大家的阅读,有错请大家指出。 bean的生命周期 实际上只有四步 实例化 ----> 属性赋值 ---> 初始化 ---> 销毁 但是在实例化前后 初始化前后 会存在一些前置后置的处理,目的是增…...