GPT - GPT(Generative Pre-trained Transformer)模型框架
本节代码主要为实现了一个简化版的 GPT(Generative Pre-trained Transformer)模型。GPT 是一种基于 Transformer 架构的语言生成模型,主要用于生成自然语言文本。
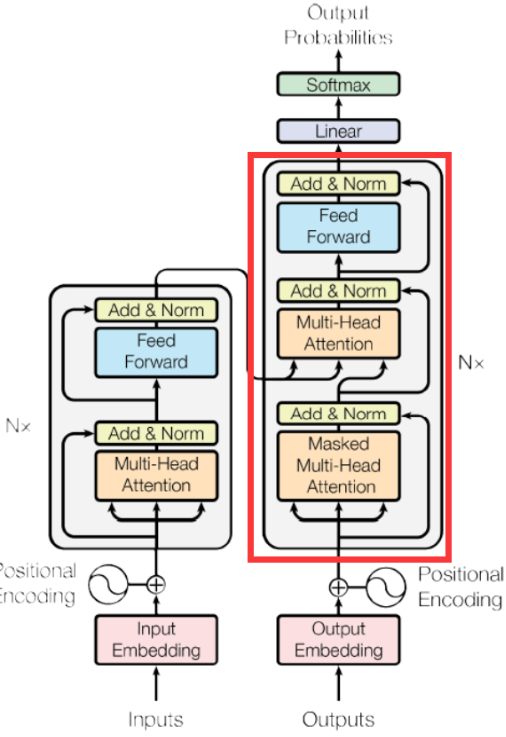
1. 模型结构
初始化部分
class GPT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, dff, dropout):super().__init__()self.emb = nn.Embedding(vocab_size, d_model)self.pos = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerDecoderBlock(d_model, dff, dropout)for i in range(N_blocks)])self.fc = nn.Linear(d_model, vocab_size)-
vocab_size:词汇表的大小,即模型可以处理的唯一词元(token)的数量。 -
d_model:模型的维度,表示嵌入和内部表示的维度。 -
seq_len:序列的最大长度,即输入序列的最大长度。 -
N_blocks:Transformer 解码器块的数量。 -
dff:前馈网络(Feed-Forward Network, FFN)的维度。 -
dropout:Dropout 的概率,用于防止过拟合。
组件说明
-
self.emb:词嵌入层,将输入的词元索引映射到d_model维的向量空间。 -
self.pos:位置嵌入层,将序列中每个位置的索引映射到d_model维的向量空间。位置嵌入用于给模型提供序列中每个词元的位置信息。 -
self.layers:一个模块列表,包含N_blocks个TransformerDecoderBlock。每个块是一个 Transformer 解码器层,包含多头注意力机制和前馈网络。 -
self.fc:一个线性层,将解码器的输出映射到词汇表大小的维度,用于生成最终的词元概率分布。
2. 前向传播
def forward(self, x, attn_mask=None):emb = self.emb(x)pos = self.pos(torch.arange(x.shape[1]))x = emb + posfor layer in self.layers:x = layer(x, attn_mask)return self.fc(x)步骤解析
-
词嵌入和位置嵌入:
-
self.emb(x):将输入的词元索引x转换为词嵌入表示emb,形状为(batch_size, seq_len, d_model)。 -
self.pos(torch.arange(x.shape[1])):生成位置嵌入pos,形状为(seq_len, d_model)。torch.arange(x.shape[1])生成一个从 0 到seq_len-1的序列,表示每个位置的索引。 -
x = emb + pos:将词嵌入和位置嵌入相加,得到最终的输入表示x。位置嵌入的加入使得模型能够区分序列中不同位置的词元。
-
-
Transformer 解码器层:
-
for layer in self.layers:将输入x逐层传递给每个TransformerDecoderBlock。 -
x = layer(x, attn_mask):每个解码器块会处理输入x,并应用因果掩码attn_mask(如果提供)。因果掩码确保模型在解码时只能看到当前及之前的位置,而不能看到未来的信息。
-
-
输出层:
-
self.fc(x):将解码器的输出x传递给线性层self.fc,生成最终的输出。输出的形状为(batch_size, seq_len, vocab_size),表示每个位置上每个词元的预测概率。
-
截止到本篇文章GPT简单复现完成,下面将附完整代码,方便理解代码整体结构
import math
import torch
import random
import torch.nn as nnfrom tqdm import tqdm
from torch.utils.data import Dataset, DataLoader'''
仿 nn.TransformerDecoderLayer 实现
'''class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_project = nn.Linear(d_model, d_model)self.k_project = nn.Linear(d_model, d_model)self.v_project = nn.Linear(d_model, d_model)self.o_project = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, attn_mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = Q @ K.transpose(2, 3) / math.sqrt(self.d_k)if attn_mask is not None:attn_mask = attn_mask.unsqueeze(1)atten_scores = atten_scores.masked_fill(attn_mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)out = self.o_project(out)return self.dropout(out)class TransformerDecoderBlock(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.linear1 = nn.Linear(d_model, dff)self.activation = nn.GELU()# self.activation = nn.ReLU()self.dropout = nn .Dropout(dropout)self.linear2 = nn.Linear(dff, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)def forward(self, x, mask=None):x = self.norm1(x + self.dropout1(self.mha_block1(x, mask)))x = self.norm2(x + self.dropout2(self.mha_block2(x, mask)))x = self.norm3(self.linear2(self.dropout(self.activation(self.linear1(x)))))return xclass GPT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, dff, dropout):super().__init__()self.emb = nn.Embedding(vocab_size, d_model)self.pos = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerDecoderBlock(d_model, dff, dropout)for i in range(N_blocks)])self.fc = nn.Linear(d_model, vocab_size)def forward(self, x, attn_mask=None):emb = self.emb(x)pos = self.pos(torch.arange(x.shape[1]))x = emb + posfor layer in self.layers:x = layer(x, attn_mask)return self.fc(x)def read_data(file, num=1000):with open(file, "r", encoding="utf-8") as f:data = f.read().strip().split("\n")res = [line[:24] for line in data[:num]]return resdef tokenize(corpus):vocab = {"[PAD]": 0, "[UNK]": 1, "[BOS]": 2, "[EOS]": 3, ",": 4, "。": 5, "?": 6}for line in corpus:for token in line:vocab.setdefault(token, len(vocab))idx2word = list(vocab)return vocab, idx2wordclass Tokenizer:def __init__(self, vocab, idx2word):self.vocab = vocabself.idx2word = idx2worddef encode(self, text):ids = [self.token2id(token) for token in text]return idsdef decode(self, ids):tokens = [self.id2token(id) for id in ids]return tokensdef id2token(self, id):token = self.idx2word[id]return tokendef token2id(self, token):id = self.vocab.get(token, self.vocab["[UNK]"])return idclass Poetry(Dataset):def __init__(self, poetries, tokenizer: Tokenizer):self.poetries = poetriesself.tokenizer = tokenizerself.pad_id = self.tokenizer.vocab["[PAD]"]self.bos_id = self.tokenizer.vocab["[BOS]"]self.eos_id = self.tokenizer.vocab["[EOS]"]def __len__(self):return len(self.poetries)def __getitem__(self, idx):poetry = self.poetries[idx]poetry_ids = self.tokenizer.encode(poetry)input_ids = torch.tensor([self.bos_id] + poetry_ids)input_msk = causal_mask(input_ids)label_ids = torch.tensor(poetry_ids + [self.eos_id])return {"input_ids": input_ids,"input_msk": input_msk,"label_ids": label_ids}def causal_mask(x):mask = torch.triu(torch.ones(x.shape[0], x.shape[0]), diagonal=1) == 0return maskdef generate_poetry(method="greedy", top_k=5):model.eval()with torch.no_grad():input_ids = torch.tensor(vocab["[BOS]"]).view(1, -1)while input_ids.shape[1] < seq_len:output = model(input_ids, None)probabilities = torch.softmax(output[:, -1, :], dim=-1)if method == "greedy":next_token_id = torch.argmax(probabilities, dim=-1)elif method == "top_k":top_k_probs, top_k_indices = torch.topk(probabilities[0], top_k)next_token_id = top_k_indices[torch.multinomial(top_k_probs, 1)]if next_token_id == vocab["[EOS]"]:breakinput_ids = torch.cat([input_ids, next_token_id.view(1, 1)], dim=1)return input_ids.squeeze()if __name__ == "__main__":file = "/Users/azen/Desktop/llm/LLM-FullTime/dataset/text-generation/poetry_data.txt"poetries = read_data(file, num=2000)vocab, idx2word = tokenize(poetries)tokenizer = Tokenizer(vocab, idx2word)trainset = Poetry(poetries, tokenizer)batch_size = 16trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)d_model = 512seq_len = 25 # 有特殊标记符num_heads = 8dropout = 0.1dff = 4*d_modelN_blocks = 2model = GPT(len(vocab), d_model, seq_len, N_blocks, dff, dropout)lr = 1e-4optim = torch.optim.Adam(model.parameters(), lr=lr)loss_fn = nn.CrossEntropyLoss()epochs = 100for epoch in range(epochs):for batch in tqdm(trainloader, desc="Training"):batch_input_ids = batch["input_ids"]batch_input_msk = batch["input_msk"]batch_label_ids = batch["label_ids"]output = model(batch_input_ids, batch_input_msk)loss = loss_fn(output.view(-1, len(vocab)), batch_label_ids.view(-1))loss.backward()optim.step()optim.zero_grad()print("Epoch: {}, Loss: {}".format(epoch, loss))res = generate_poetry(method="top_k")text = tokenizer.decode(res)print("".join(text))pass
相关文章:
GPT - GPT(Generative Pre-trained Transformer)模型框架
本节代码主要为实现了一个简化版的 GPT(Generative Pre-trained Transformer)模型。GPT 是一种基于 Transformer 架构的语言生成模型,主要用于生成自然语言文本。 1. 模型结构 初始化部分 class GPT(nn.Module):def __init__(self, vocab…...

前端加密的几种方式
前端加密的几种方式 一、对称加密原理常用算法代码示例(AES)适用场景 二、非对称加密原理常用算法代码示例(RSA)适用场景 三、哈希函数原理常用算法代码示例(SHA-256)适用场景 四、Base64 编码原…...
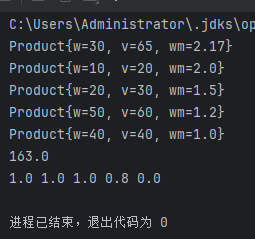
贪心算法:部分背包问题深度解析
简介: 该Java代码基于贪心算法实现了分数背包问题的求解,核心通过单位价值降序排序和分阶段装入策略实现最优解。首先对Product数组执行双重循环冒泡排序,按wm(价值/重量比)从高到低重新排列物品;随后分两阶段装入:循环…...

连接器电镀层的作用与性能
连接器电镀层的作用与性能: 镀金 金具有很高的化学稳定性,只溶于王水,不溶于其它酸,金镀层耐蚀性强,导电性好,易于焊接,耐高温,硬金具有一定的耐磨性。 对钢、铜、银及其合金基体而…...

神经网络如何表示数据
神经网络是如何工作的?这是一个让新手和专家都感到困惑的问题。麻省理工学院计算机科学和人工智能实验室(CSAIL)的一个团队表示,理解这些表示,以及它们如何为神经网络从数据中学习的方式提供信息,对于提高深…...
)
【双指针】和为 s 的两个数字(easy)
和为 s 的两个数字(easy) 题⽬描述:解法⼀(暴⼒解法,会超时):解法⼆(双指针 - 对撞指针):算法思路:C 算法代码Java 算法代码: 题⽬链接…...

.net core 工作流介绍
WikeFlow2.0介绍 WikeFlow官网:http://www.wikesoft.com WikeFlow学习版演示地址:http://workflow.wikesoft.com WikeFlow学习版源代码下载:WorkFlow: 多数据库支持,同时支持:SQLServer,Mysql࿰…...
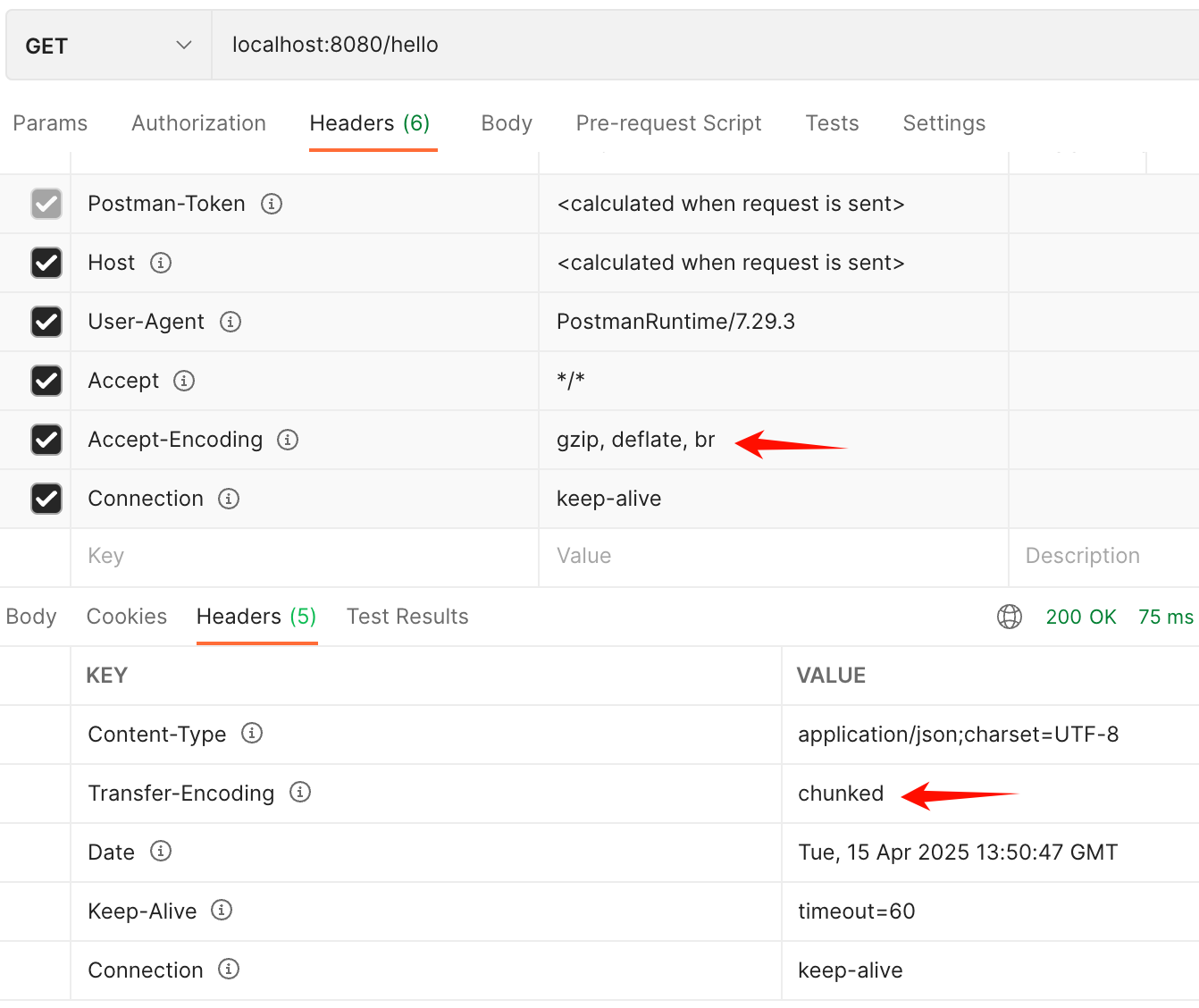
nginx自编译重现gzip和chunked的现象
前言 最近做项目,发现一个比较好玩的事,nginx的module gzip模式默认支持1KB压缩,和chunked返回,本来现在的很多框架都很完善了,但是,一些新语言框架或者一些老旧框架会不能完整支持chunked,导致…...
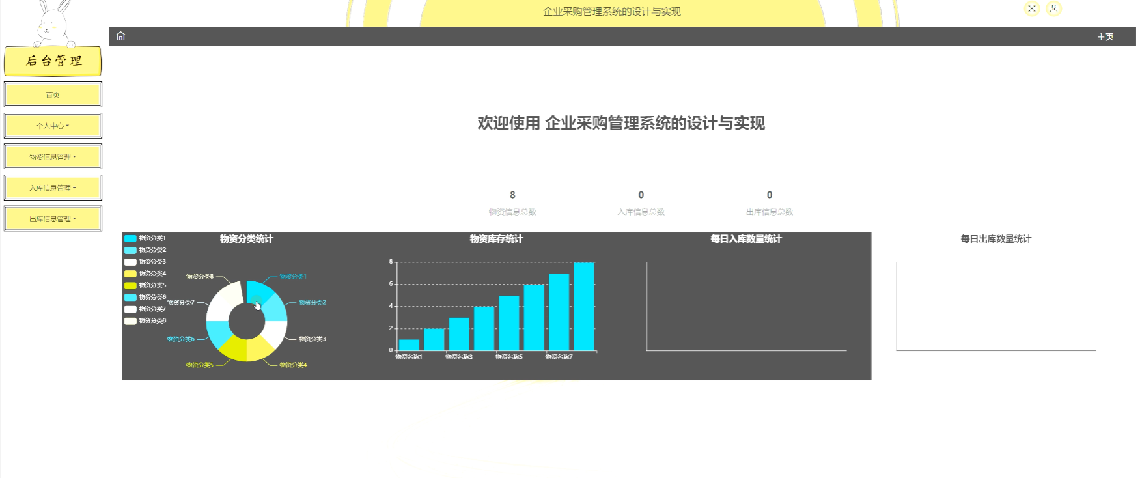
jspm企业采购管理系统的设计与实现(源码+lw+部署文档+讲解),源码可白嫖!
摘要 相比于以前的传统企业采购手工管理方式,智能化的管理方式可以大幅降低企业采购管理的运营人员成本,实现了企业采购管理的标准化、制度化、程序化的管理,有效地防止了物资信息、物资入库、出库等的随意管理,提高了信息的处理…...

iOS应用开发指南
开发一款iOS应用是一个系统化的过程,涵盖从环境搭建、界面设计、编码实现到测试发布的各个环节。以下是一份面向初学者的iOS移动应用开发指南,帮助你从零开始构建自己的App。 一、准备工作:开发环境与工具 必备设备 Mac电脑:iO…...

Go之defer关键字:优雅的资源管理与执行控制
在Go语言中,defer关键字是处理资源释放、错误恢复和代码逻辑清理的利器。它看似简单,却隐藏着许多设计哲学和底层机制。本文将深入剖析defer的执行原理、使用场景和常见陷阱,助你掌握这一关键特性。 一、defer基础:延迟执行的本质…...

现代测试自动化框架教程:Behave接口测试与Airtest移动端UI自动化
前言 我发现每天还是陆陆续续有人在看我之前写的自动化框架搭建的文档;即使很早就有新的框架,更好的选择出来了;所以特别写了这一篇目前大厂也在使用的;日活400w有实际落地的自动化测试架构方案; 随着测试技术…...

优化运营、降低成本、提高服务质量的智慧物流开源了
智慧物流视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本可通过边缘计算技术…...

使用Lombok的@Slf4j和idea构建:找不到log符号-解决
问题:在使用Lombok的Slf4j构建项目时提示如下内容: MvcConfiguration.java:26:9 java: cannot find symbol symbol: variable log location: class cn.edu.wynu.mrcinerec.mrserver.config.WebMvcConfiguration查了网上的方法都是改配置 但是使用Googl…...
)
陕化之光(原创)
当城市在和周公化合 陕化的工装已与朝霞发生反应 工人先锋号已然吹响 陕化工人游走在工作的床层 钢铁森林间穿梭的身影 是沉默的催化剂 让冰冷的方程式 绽放出最活跃的分子温度 扳手与阀门对话时 塔林正在记录 关于电流与压力的学习笔记 每一次精确的调控 都是舞台上…...

redis 内存中放哪些数据?
在 Java 开发中,Redis 作为高性能内存数据库,通常用于存储高频访问、低延迟要求、短期有效或需要原子操作的数据。以下是 Redis 内存中常见的数据类型及对应的使用场景,适合面试回答: 1. 缓存数据(高频访问,降低数据库压力) 用户会话(Session):存储用户登录状态、临时…...
【Python爬虫】简单案例介绍1
目录 三、Python爬虫的简单案例 3.1 网页分析 单页 三、Python爬虫的简单案例 本节以科普中国网站为例。 3.1 网页分析 单页 在运用 Python 进行爬虫开发时,一套严谨且有序的流程是确保数据获取高效、准确的关键。首先,深入分析单个页面的页面结构…...

LLM-as-Judge真的更偏好AI输出?
论文标题 Do LLM Evaluators Prefer Themselves for a Reason? 论文地址 https://arxiv.org/pdf/2504.03846 代码地址 https://github.com/wlchen0206/llm-sp 作者背景 弗吉尼亚大学,乔治华盛顿大学 实践建议 在将LLM部署为评估器之前,应严格评…...

【软考-架构】13.3、架构复用-DSSA-ABSD
✨资料&文章更新✨ GitHub地址:https://github.com/tyronczt/system_architect 文章目录 1、软件架构复用2、特定领域软件架构DSSADSSA的三个基本活动参与DSSA的四种角色人员建立DSSA的过程三层次模型 考试真题第一题第二题 3、基于架构的软件开发ABSD的软件开发…...
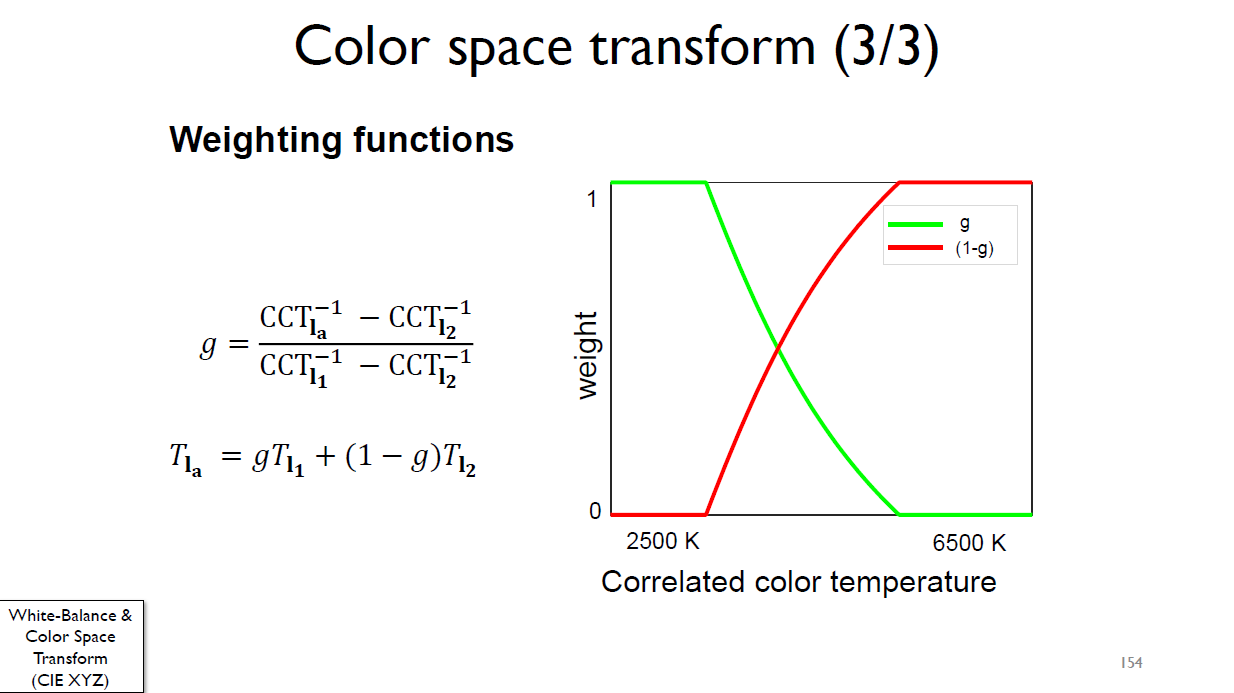
色温插值计算借鉴
色温插值计算方法借鉴: 摘至:Understanding the in-camera rendering pipeline & the role of AI and deep learning...

git合并分支原理
Git合并的原理是基于三方合并(three-way merge)算法,它通过比较三个快照来合并不同分支上的更改。这三个快照包括两个要合并的分支的最新提交和它们的共同祖先提交。合并过程并不是简单地按照提交时间来进行,而是通过比较这些快照…...

SnailJob:分布式环境设计的任务调度与重试平台!
背景 近日挖掘到一款名为“SnailJob”的分布式重试开源项目,它旨在解决微服务架构中常见的重试问题。在微服务大行其道的今天,我们经常需要对某个数据请求进行多次尝试。然而,当遇到网络不稳定、外部服务更新或下游服务负载过高等情况时,请求…...
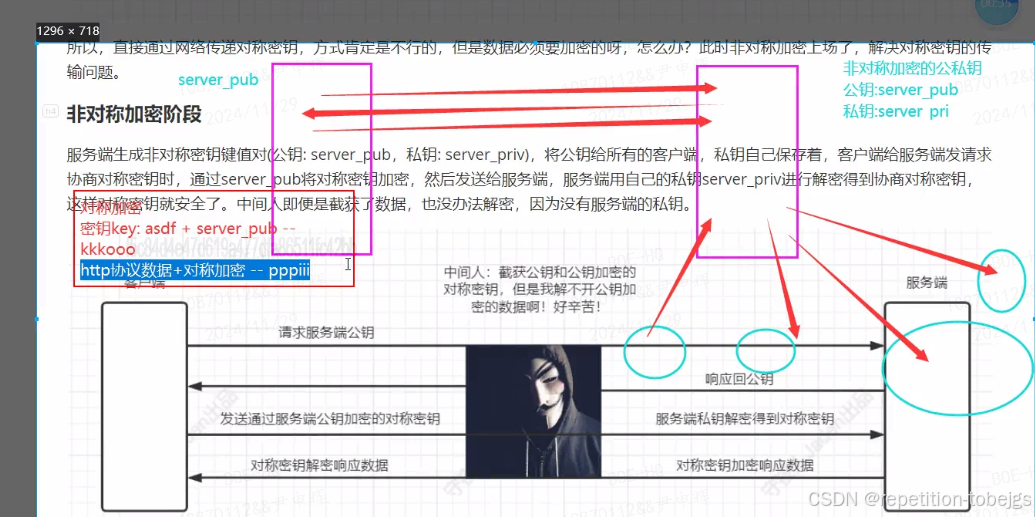
网络安全-Http\Https协议和Bp抓包
1. http协议,有请求必有相应, 请求协议, 响应协议; 2. 密码学加密机制及常用算法和常用名称说明: 算法 密钥 明文数据 密文; 加密算法分类和常用算法: 加密算法可以归结为三大类ÿ…...
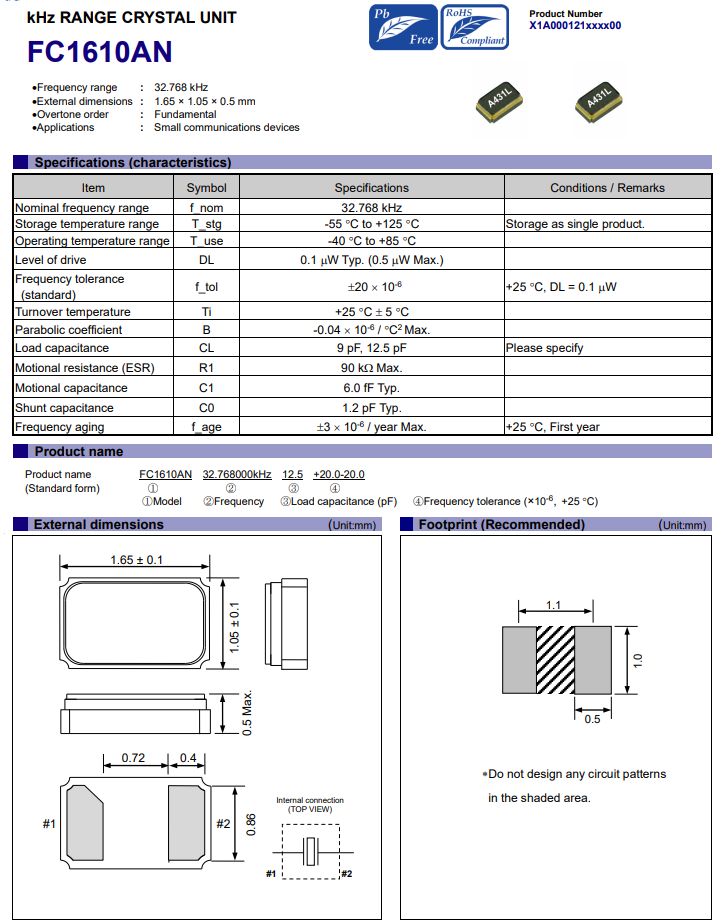
爱普生FC1610AN5G手机中替代传统晶振的理想之选
在 5G 技术引领的通信新时代,手机性能面临前所未有的挑战与机遇。从高速数据传输到多任务高效处理,从长时间续航到紧凑轻薄设计,每一项提升都离不开内部精密组件的协同优化。晶振,作为为手机各系统提供稳定时钟信号的关键元件&…...
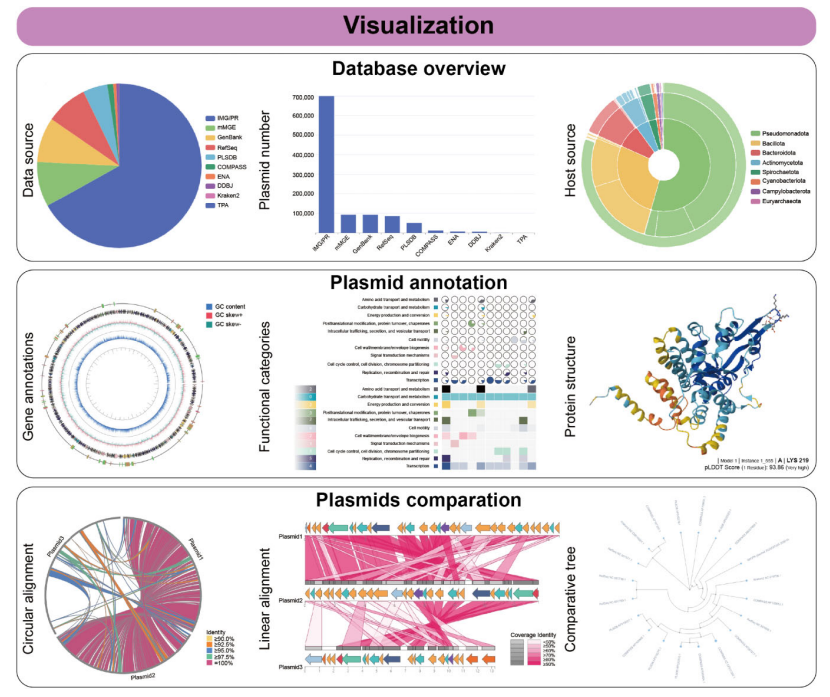
质粒已被全面解析
随着微生物研究的不断深入和耐药性问题的日益加剧,了解质粒对开发抗菌策略及生物技术应用意义重大。但现有质粒数据库缺乏细致注释并且工具存在不足。近期,香港城市大学李帅成课题组在Nucleic Acids Research期刊发表研究成果,推出全面注释质…...
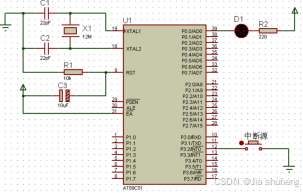
实验二.单按键控制LED
1.实验任务 如图4.1所示:在P0.0端口上接一个发光二极管L1,按键按一下灯亮,在按一下灯灭。 2.电路原理图 3.系统板上硬件连线 把“单片机系统”区域中的P0端口用导线连接到“八路发光二极管指示模块”区域中的L1端口上。 4.程序设计内容...

编程语言到mysql ‘\‘到数量关系
在 MySQL 的模糊查询中,反斜杠 \ 的转义规则需要根据 转义层级 和 SQL 模式 来确定。以下是详细说明及示例: 一、默认模式下(未启用 NO_BACKSLASH_ESCAPES) 1. 规则说明 反斜杠转义:\ 是 MySQL 的默认转义字符。 转义…...
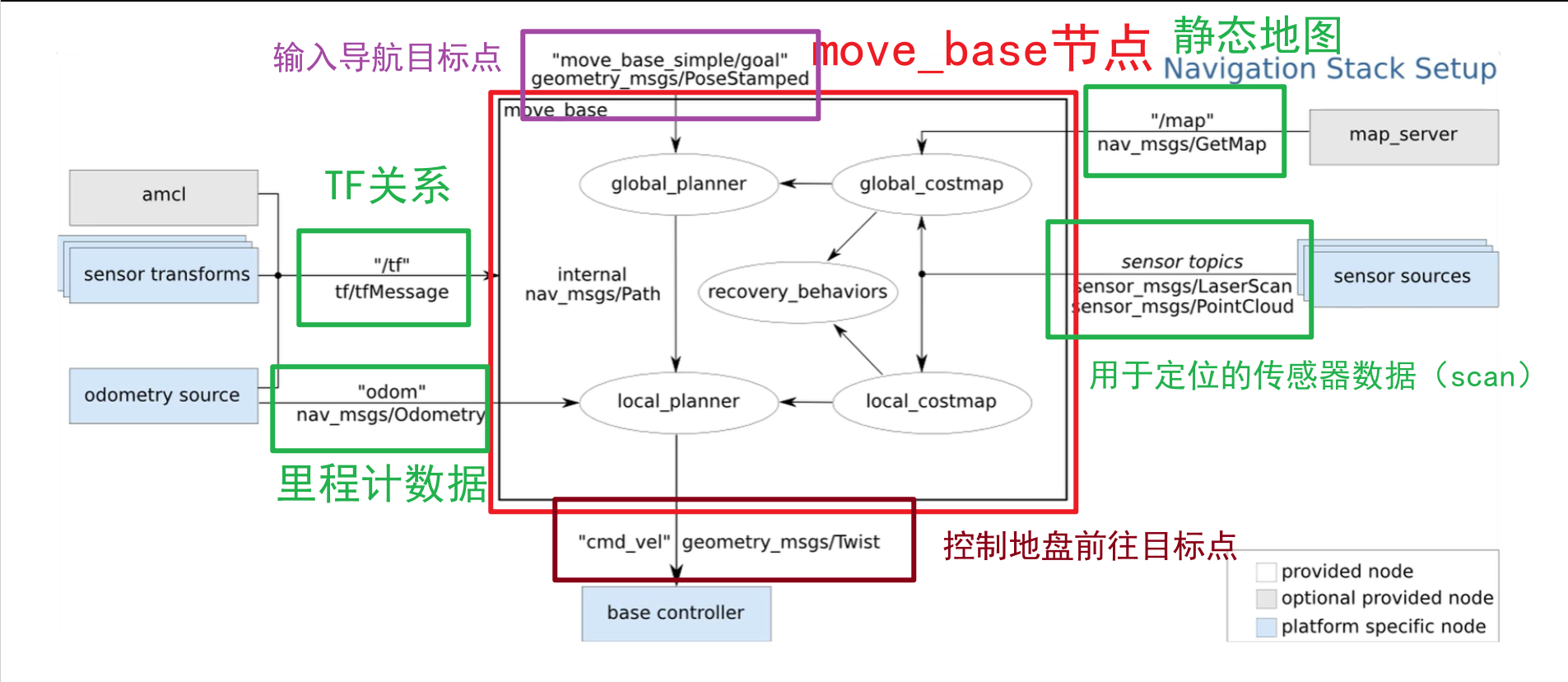
【ROS】move_base 导航节点概述
【ROS】move_base 导航节点概述 前言move_base 架构move_base 内部模块move_base 外部数据 前言 本章介绍 ROS 导航系统中的核心节点 move_base,它负责路径规划和导航控制,是系统的调度中心。我们将简要讲解其内部模块结构,以及运行所需的外…...

【教程】Ubuntu修改ulimit -l为unlimited
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 问题描述 解决方法一 解决方法二 解决方法三 (终极) 问题描述 查系统资源限制 ulimit -l如果返回的是 64 或其他较小值,那么RDM…...
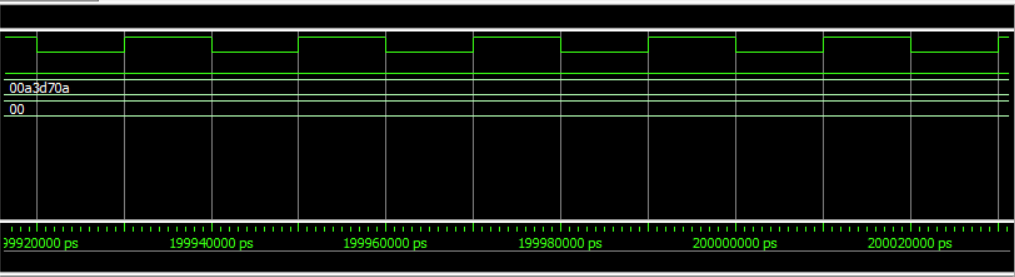
【FPGA基础学习】DDS信号发生器设计
一、IP核简介 IP核的定义与核心作用 定义 IP核是芯片设计中独立功能的成熟模块,例如处理器、存储器、接口协议等。它们以硬件描述语言(HDL)、网表或物理版图形式交付,供其他设计者直接调用,避免重复开发 核心作用 缩…...