Dify简介:从架构到部署与应用解析
Dify 是一个开源的生成式 AI 应用开发平台,融合了后端即服务(Backend as a Service, BaaS)和 LLMOps 的理念,旨在帮助开发者快速搭建生产级的生成式 AI 应用。本文将详细解析 Dify 的技术架构、部署流程以及实际应用场景,为开发者提供技术干货。

一、Dify 技术架构
Dify 就是一个集成了很多大模型 API 能力的工具。 可以自己配置工作流,整合很多第三方工具。
1.1 整体架构设计
Dify 的架构采用分层设计,自上而下分为四层:
- 数据层:包含数据集(Dataset)和提示词(Prompts),通过 ETL 进行数据处理,并由 RAG Pipeline 实现知识检索增强。
- 开发层:提供 Prompt IDE 和 Agent DSL,用于提示词的编写和智能代理的构建。
- 编排层:以 Orchestration Studio 为核心,协调组件运行,并通过审核系统和缓存系统保障应用质量。
- 基础层:包括存储系统和语言模型(LLMs),为上层提供支撑。

1.2 核心组件功能
- 低代码/无代码开发:Dify提供了可视化的界面,允许开发者通过拖拽、配置等方式定义Prompt(提示词)、上下文和插件,无需深入底层技术细节,降低了开发门槛。
- 模块化设计:采用模块化架构,每个模块都有清晰的功能和接口,开发者可以根据需求选择性地使用这些模块来构建自己的AI应用。
- 丰富的功能组件:
-
- AI工作流:通过可视化画布构建和测试强大的AI工作流。
- RAG管道:支持从文档摄入到检索的完整流程,可从PDF、PPT等常见格式中提取文本。
- Agent智能体:基于LLM的推理能力,可以自主规划任务、调用工具,完成复杂任务。
- 模型管理:支持数百种专有和开源的LLM,如GPT、Llama2等,并提供模型性能比较功能。
- 工具集成:提供了50多种内置工具(如谷歌搜索、DALL·E、Stable Diffusion)。
- 灵活的部署方式:支持云服务、私有部署以及Serverless部署。
- 企业级特性:提供私有化部署解决方案,确保数据和隐私安全。
二、Dify 部署流程
安装 Dify 之前, 请确保你的机器已满足最低安装要求:
- CPU >= 2 Core
- RAM >= 4 GiB
克隆 Dify 代码仓库
克隆 Dify 源代码至本地环境。
Copy
# 假设当前最新版本为 0.15.3
git clone https://github.com/langgenius/dify.git --branch 0.15.3启动 Dify
进入 Dify 源代码的 Docker 目录
- Copy
cd dify/docker复制环境配置文件
- Copy
cp .env.example .env启动 Docker 容器
根据你系统上的 Docker Compose 版本,选择合适的命令来启动容器。你可以通过 $ docker compose version 命令检查版本,详细说明请参考 Docker 官方文档:
- 如果版本是 Docker Compose V2,使用以下命令:
docker compose up -d- 如果版本是 Docker Compose V1,使用以下命令:
docker-compose up -d运行命令后,你应该会看到类似以下的输出,显示所有容器的状态和端口映射:
[+] Running 11/11✔ Network docker_ssrf_proxy_network Created 0.1s ✔ Network docker_default Created 0.0s ✔ Container docker-redis-1 Started 2.4s ✔ Container docker-ssrf_proxy-1 Started 2.8s ✔ Container docker-sandbox-1 Started 2.7s ✔ Container docker-web-1 Started 2.7s ✔ Container docker-weaviate-1 Started 2.4s ✔ Container docker-db-1 Started 2.7s ✔ Container docker-api-1 Started 6.5s ✔ Container docker-worker-1 Started 6.4s ✔ Container docker-nginx-1 Started 7.1s最后检查是否所有容器都正常运行:
docker compose ps在这个输出中,你应该可以看到包括 3 个业务服务 api / worker / web,以及 6 个基础组件 weaviate / db / redis / nginx / ssrf_proxy / sandbox 。
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
docker-api-1 langgenius/dify-api:0.6.13 "/bin/bash /entrypoi…" api About a minute ago Up About a minute 5001/tcp
docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db About a minute ago Up About a minute (healthy) 5432/tcp
docker-nginx-1 nginx:latest "sh -c 'cp /docker-e…" nginx About a minute ago Up About a minute 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp
docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis About a minute ago Up About a minute (healthy) 6379/tcp
docker-sandbox-1 langgenius/dify-sandbox:0.2.1 "/main" sandbox About a minute ago Up About a minute
docker-ssrf_proxy-1 ubuntu/squid:latest "sh -c 'cp /docker-e…" ssrf_proxy About a minute ago Up About a minute 3128/tcp
docker-weaviate-1 semitechnologies/weaviate:1.19.0 "/bin/weaviate --hos…" weaviate About a minute ago Up About a minute
docker-web-1 langgenius/dify-web:0.6.13 "/bin/sh ./entrypoin…" web About a minute ago Up About a minute 3000/tcp
docker-worker-1 langgenius/dify-api:0.6.13 "/bin/bash /entrypoi…" worker About a minute ago Up About a minute 5001/tcp通过这些步骤,可以在本地成功安装 Dify。
更新 Dify
进入 dify 源代码的 docker 目录,按顺序执行以下命令:
cd dify/docker
docker compose down
git pull origin main
docker compose pull
docker compose up -d同步环境变量配置 (重要!)
- 如果
.env.example文件有更新,请务必同步修改你本地的.env文件。 - 检查
.env文件中的所有配置项,确保它们与你的实际运行环境相匹配。你可能需要将.env.example中的新变量添加到.env文件中,并更新已更改的任何值。
访问 Dify
你可以先前往管理员初始化页面设置设置管理员账户:
# 本地环境
http://localhost/install# 服务器环境
http://your_server_ip/installDify 主页面:
# 本地环境
http://localhost# 服务器环境
http://your_server_ip三、Dify 应用场景
3.1 微调模型优化工作流
通过可视化提示词编排和数据集嵌入,零代码构建对话机器人或 AI 助理,通过微调模型,优化对话策略。
1.前期准备
明确微调目标:确定希望模型在哪些方面进行优化,例如特定领域的知识掌握、特定语言风格的生成等。
准备数据:收集和整理与微调目标相关的高质量数据。数据通常需要以特定的格式呈现,如常见的JSONL格式,每条数据包含“messages”字段,其中有“role”为“system”“user”“assistant”的记录,分别对应系统提示、用户输入和模型的回答。
2.微调操作流程
1)创建工作流:在项目中创建一个新的工作流,工作流是一系列操作的流程化表示,用于构建微调的过程。
2)设置开始节点参数:在开始节点中新建输入参数,通常需要一个用于上传文件的参数,如“attachments”,用于接收用户上传的训练数据文件;还需要一个“触发词”参数,作为训练中的系统提示词。
3)添加文档提取器节点:在开始节点右边添加文档提取器节点,并将开始节点的“attachments”数组参数作为文档提取器的输入变量。文档提取器会对上传的文件进行处理,提取其中的文本内容。
4)添加代码执行节点:在文档提取器右边添加代码执行节点,并与文档提取器节点连接。在代码执行节点中,编写代码来进一步处理文档提取器输出的文本内容,如合并多个文档内容、截取一定长度的字符等。代码执行节点的输出变量通常为处理后的文本内容,参数名为“result”,类型为“string”。
5)连接LLM大语言模型节点:将代码执行节点连接一个LLM大语言模型节点。在LLM节点的配置中,选择合适的预训练模型,如SiliconCloud的Qwen/Qwen2.572binstruct128k模型等。同时,设置系统提示词和用户提示词,告诉大语言模型如何根据输入的文本内容转换为符合微调数据集格式要求的输出。系统提示词内容例如“【角色】你是一位LLM大语言模型科学家,参考用户提供的内容,帮助用户构造符合规范的finetune(微调)数据”等。
6)添加结束节点:从LLM大语言模型节点右边添加一个结束节点,将LLM的输出文本作为结束节点的输入参数,至此完成微调语料构造工作流的制作。
7)测试工作流:点击工作流上面的运行按钮,输入训练的预料文件和触发词,检查工作流是否能够正常运行并生成符合预期的微调数据集。
8)评估微调效果:使用测试集对微调后的模型进行评估,观察模型在特定任务上的性能表现,如准确率、召回率、F1值等指标是否有所提升,或者根据实际应用场景的需求进行主观评估,如生成的文本是否更符合要求、回答的准确性和合理性是否提高等。
3.2 应用方向
1. RAG(检索增强生成)
技术实现
文档解析(PDF/表格/扫描件)→ 向量化存储 → 多路召回(关键词+语义检索)→ 重排序优化 → LLM生成答案。
核心功能
- 可视化编排:通过拖拽节点(如LLM调用、条件分支、API请求)设计自动化流程,支持多轮交互与批处理。
- 优化策略:多路召回(向量+关键词检索)、融合重排序(基于相关性评分)。
应用场景
- 企业知识库问答:上传产品手册后,AI自动回答客户技术问题,准确率提升40%。
- 法律文档分析:解析合同条款,生成风险摘要,减少人工审核时间。
2. Workflow(工作流)
核心功能
通过拖拽节点(LLM调用、条件分支、API请求)设计自动化流程,支持单轮生成与多轮交互。
应用示例
- 工单处理自动化:用户提交工单→自动分类→调用知识库生成回复→邮件通知用户,耗时从20分钟缩短至3分钟。
- 电商促销生成:输入产品信息→生成多语言营销文案→同步至CMS系统,效率提升5倍。
3. Agent(智能体)
技术特性
基于ReAct框架的任务分解能力,支持调用外部工具(如WolframAlpha计算、Stable Diffusion绘图)。
应用示例
- 数据分析助手:用户提问“上月销售额趋势”→Agent自动查询数据库→生成可视化图表并解释关键指标。
- 多语言客服:识别用户语言→调用翻译工具→结合知识库生成本地化回复,支持全球客户服务。

四、Dify 技术优势
全平台兼容:
- Dify支持本地(如NAS/服务器)和云端(如Docker/Kubernetes)部署,确保数据完全自主可控,满足金融、医疗等行业的严格合规需求。
大模型优先设计:
- Dify内置了OpenAI、DeepSeek、LLama等主流模型接口,兼容多种大语言模型,实现业务层和模型层解耦。支持RAG(检索增强生成)框架,一键接入企业文档生成智能知识库,实现灵活扩展和定制。
低代码工作流:
- 可视化编排支持条件分支、循环、子流程,搭配API节点实现“模型调用+外部工具”联动,如“用户提问→模型生成回答→触发工单系统”。
- 通过“模型调用节点+工具节点”拖拽组合,快速实现“用户输入→模型处理→数据库操作→消息通知”闭环,无需编写复杂胶水代码。
- 业务人员可以通过拖拽节点快速搭建基础流程,而开发者可以通过代码节点实现深度定制,兼顾易用性与扩展性,适合不同技术背景的开发者。
生产级能力:
- 提供Backend-as-a-Service(BAAS),集成流量监控、日志分析、权限管理,适合高并发场景下的企业级部署。
- 支持多模型热切换,提供API网关、操作审计、数据加密,满足GDPR、等保三级等合规要求,适合政府、金融机构部署智能客服、风险控制等系统。

总结
Dify凭借其多模型支持、企业级LLMOps能力和灵活部署选项,成为开发者构建生产级AI应用的首选平台。与Coze、Langflow等工具相比,Dify在复杂任务处理与生态整合上更具优势,但在易用性和垂直领域检索精度上仍有优化空间。对于需要快速落地的企业场景,Dify+RAG/Workflow/Agent的组合能显著提升自动化水平与决策效率。
相关文章:
Dify简介:从架构到部署与应用解析
Dify 是一个开源的生成式 AI 应用开发平台,融合了后端即服务(Backend as a Service, BaaS)和 LLMOps 的理念,旨在帮助开发者快速搭建生产级的生成式 AI 应用。本文将详细解析 Dify 的技术架构、部署流程以及实际应用场景ÿ…...

构建高可靠C++服务框架:从日志系统到任务调度器的完整实现
构建高可靠C服务框架:从日志系统到任务调度器的完整实现 一、深度解析示例代码技术体系 1.1 日志系统的进阶应用 示例代码中的ZRY_LOG_XXX宏展示了基础日志功能,但在生产环境中我们需要更完善的日志系统: 推荐技术栈组合: sp…...

碳化硅(SiC)功率模块方案对工商业储能变流器PCS市场格局的重构
碳化硅(SiC)模块方案(如BMF240R12E2G3)对工商业储能变流器PCS市场格局产生颠覆性的重构: 2025年,SiC模块方案(如BMF240R12E2G3)凭借效率、成本和政策支持的三重优势,将重…...
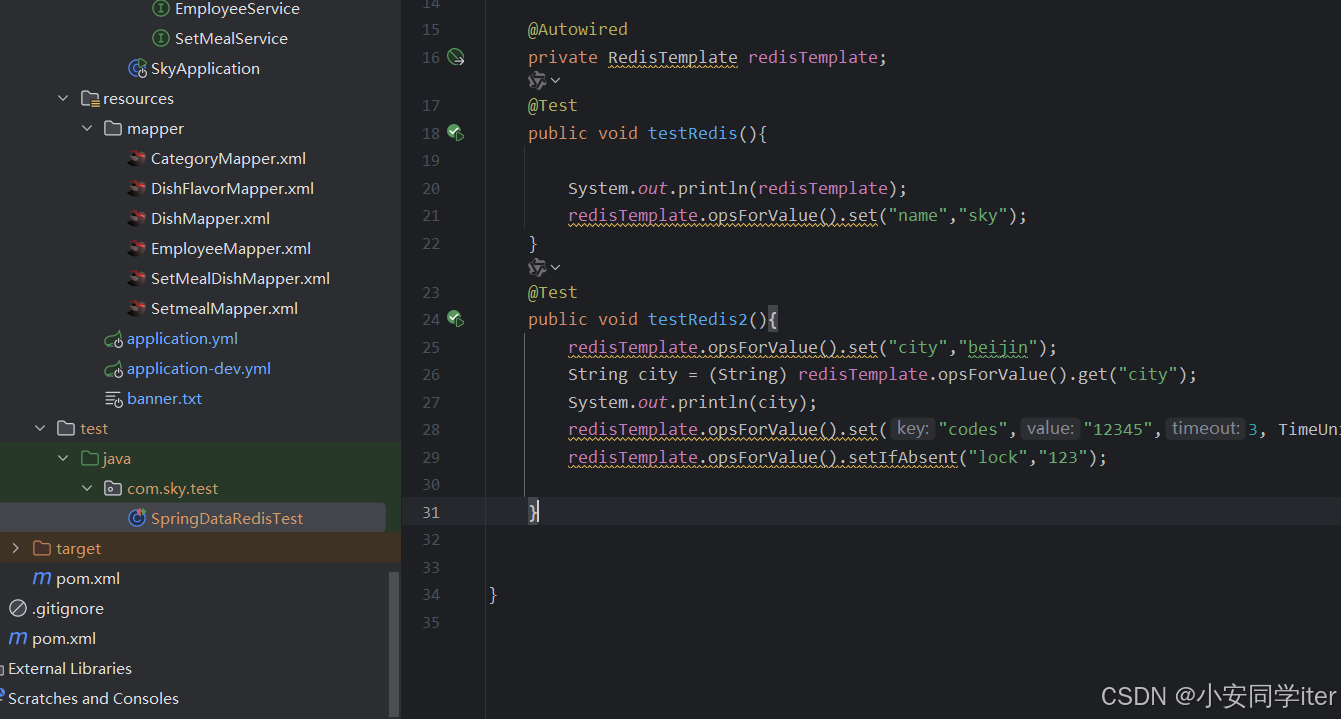
Redis入门(Java中操作Redis)
目录 一 基础概念 1. Redis 核心特点 2. Redis 与 MySQL 的对比 3. Redis的开启与使用 二 Redis的常用数据类型 1 基础概念 2 数据结构的特点 三 Redis基础操作命令 1 字符串操作命令 2 哈希操作命令 3 列表操作命令 4 集合操作命令 5 有序集合操作命令 6 通用命令…...
论文阅读)
DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY(分布式优先级体验回放)论文阅读
标题:DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY(分布式优先级体验回放) 作者:John Quan, Dan Horgan,David Budden,Gabriel Barth-Maron 单位: DeepMind 发表期刊:Machine Learning 发表时…...

Prometheus架构组件
Prometheus 是一个开源的监控与告警系统,专为动态的云原生环境(如 Kubernetes)设计。其架构基于主动拉取(Pull)模型,支持多维数据模型和灵活的查询语言(PromQL)。以下是 Prometheus …...
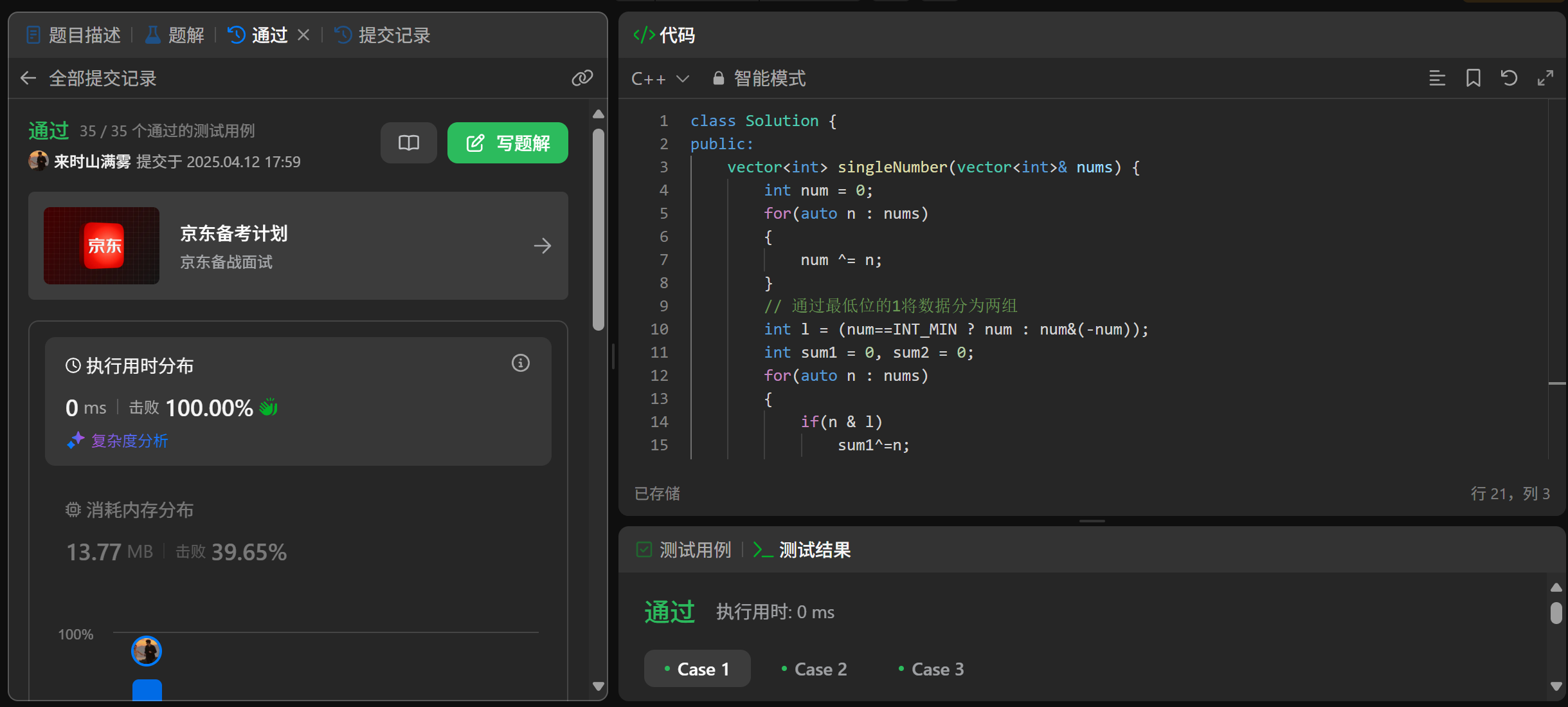
算法思想之位运算(一)
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之位运算(一) 发布时间:2025.4.12 隶属专栏:算法 目录 算法介绍六大基础位运算符常用模板总结 例题位1的个数题目链接题目描述算法思路代码实现 比特位计数题目链接题目描述算法思路…...
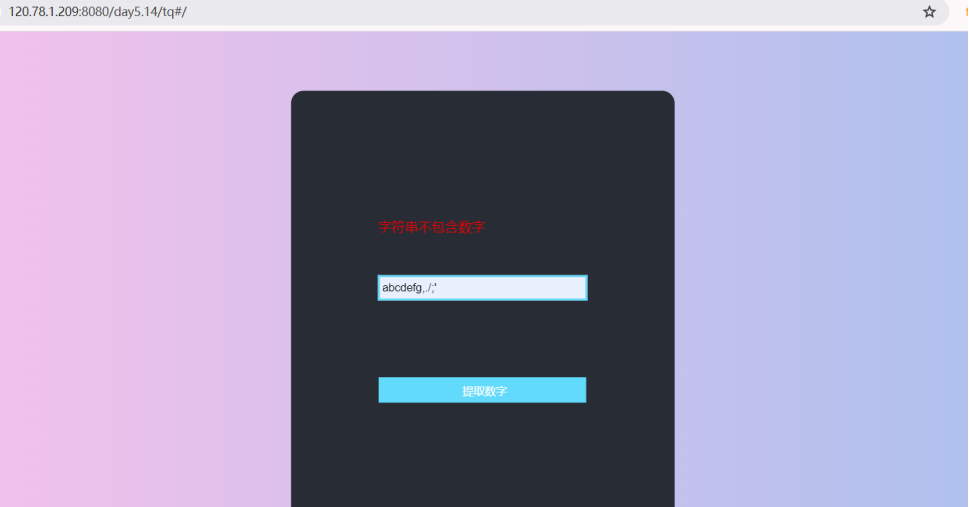
【基于Servlet技术处理表单】
文章目录 一、实验背景与目的二、实验设计与实现思路1. 功能架构2. 核心代码实现3. 测试用例 总结 一、实验背景与目的 本次实验旨在深入理解Servlet工作原理,掌握JSP与Servlet的协同开发,实现前端表单与后端数据处理的交互。具体目标包括:设…...
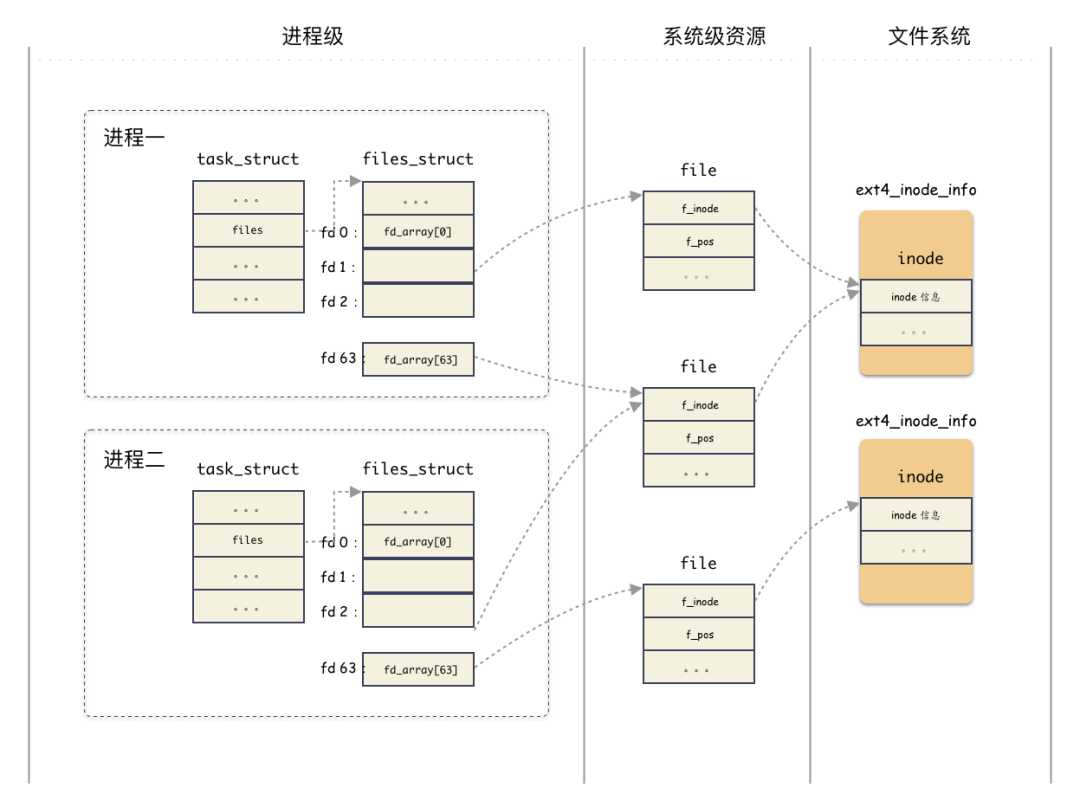
[OS] mmap | fd是什么 | inode机制 | vfs封装
Linux 下一切皆文件 * 统统抽象为文件,系统封装一层结构体之后,通过指针来访问 * 文章后面的 几个思考题都挺好的 * 后面涉及到的inode 机制,去年暑假的这篇文章,有详细的记录到过 【Linux】(26) 详解磁盘与文件系统:从…...

cout和printf的区别
在C编程中,printf和cout都是用于输出的,但它们之间存在一些关键的区别。printf是C语言中的标准输出函数,而cout是C中引入的一个对象,它是iostream库的一部分。 printf的特点 printf是一个函数,需要明确指定输出的格式…...
STL详解 - vector的模拟实现
目录 一、整体设计 1.1 核心结构 1.2 迭代器实现 二、核心接口实现 2.1 构造函数系列 🌴默认构造 🌴迭代器范围构造 🌴元素填充构造 2.2 拷贝控制 🌵拷贝构造函数 🌵赋值运算符(现代写法…...

C++第三方库【JSON】nlohman/json
文章目录 优势使用API从文件中读取json从json文本创建json对象直接创建并操作json对象字符串 <> json对象文件流 <> json对象从迭代器读取像使用STL一样的访问STL容器转化为 json数组STL容器 转 json对象自定义类型转化为 json对象 限制 优势 直观的语法ÿ…...
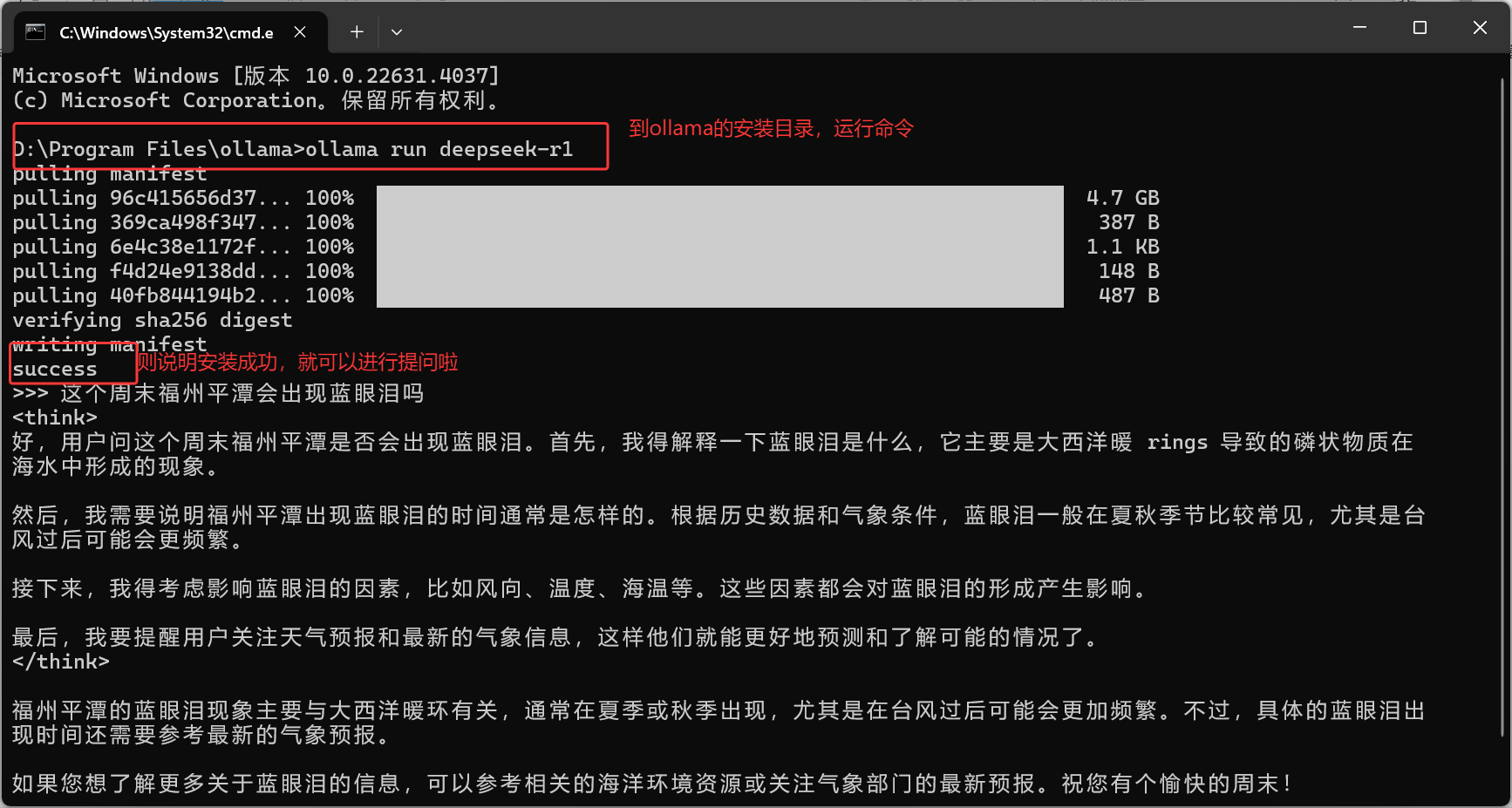
超细的ollama下载以及本地部署deepseek项目
Ollama 是一个开源的本地化大语言模型(LLM)运行和部署工具,专注于让开发者能够快速、高效地在本地运行和管理各种开源大语言模型(如 LLaMA、Mistral、GPT 系列等)。它提供了一个统一的接口,简化了模型下载、…...
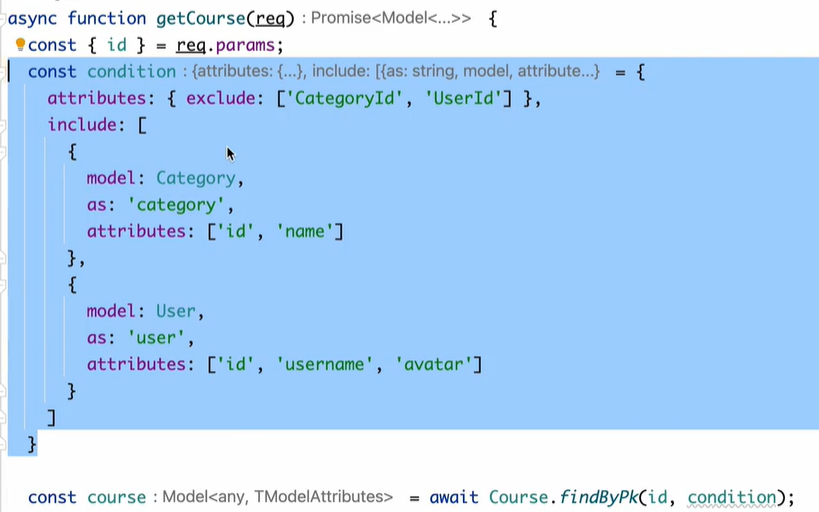
【Sequelize】关联模型和孤儿记录
一、关联模型的核心机制 1. 关联类型与组合规则 • 基础四类型: • hasOne:外键存储于目标模型(如用户档案表存储用户ID) • belongsTo:外键存储于源模型(如订单表存储用户ID) • hasMany&…...
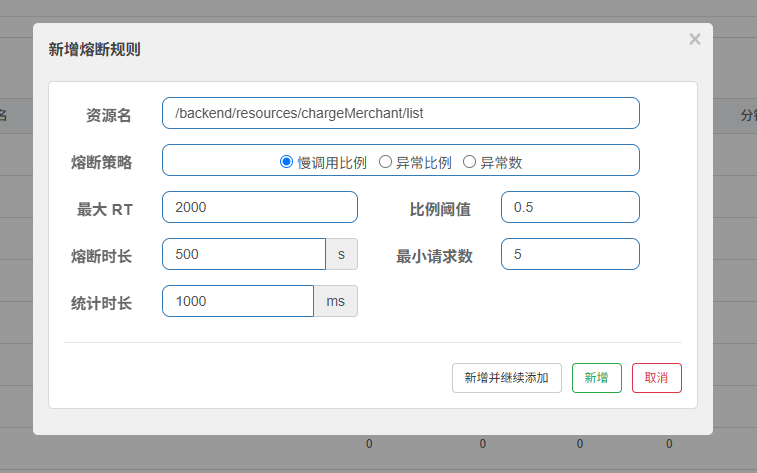
Sentinel实战教程:流量控制与Spring Boot集成
Sentinel实战教程:流量控制与Spring Boot集成 1. Sentinel简介与核心概念 1.1 什么是Sentinel? Sentinel是阿里巴巴开源的流量控制组件,主要用于微服务架构中的流量防护。它通过限流、熔断、热点防护等机制,帮助系统在高并发场景下保持稳定运行。 1.2 核心功能与术语 流…...

编程技能:调试01,调试介绍
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程基础:位运算07,右移 回到目录 下一…...
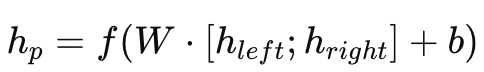
循环神经网络 - 扩展到图结构之递归神经网络
本文我们来学习递归神经网络(Recursive Neural Network,RecNN),其是循环神经网络在有向无循环图上的扩展 。 递归神经网络是一类专门设计来处理具有层次结构或树形结构的数据的神经网络模型。它与更常见的循环神经网络(Recurrent Neural Net…...

【Kubernetes基础--Pod深入理解】--查阅笔记2
深入理解Pod 为什么要有个Pod1. 容器协作与资源共享2. 简化调度和资源管理3. 设计模式支持 Pod 基本用法Pod 容器共享 VolumePod 的配置管理ConfigMap 概述创建 ConfigMap 资源对象在 Pod 中使用 ConfigMap使用 ConfigMap 的限制条件 为什么要有个Pod Pod 的引入并非技术冗余&…...
【euclid】10.3 2D变换模块(transform2d.rs)bytemuck trait
这段代码是一个 Rust 的 unsafe trait 实现,用于标记 Transform2D 类型在特定条件下可以安全地被视为由全零字节组成的有效实例。让我们详细解释每个部分: 代码分解: #[cfg(feature "bytemuck")] unsafe impl<T: Zeroable, S…...
Maven超级详细安装部署
1.到底什么是Maven?搞清楚这个 Maven 是一个项目管理工具,主要用于 Java 项目的构建、依赖管理和文档生成。 它基于项目对象模型(POM),通过 pom.xml 文件定义项目的配置。 (简单说破:就是工程…...

C# + Python混合开发实战:优势互补构建高效应用
文章目录 前言🥏一、典型应用场景1. 桌面应用智能化2. 服务端性能优化3. 自动化运维工具 二、四大技术实现方案方案1:进程调用(推荐指数:★★★★☆)方案2:嵌入Python解释器(推荐指数࿱…...

云服务模式全知道:IaaS、PaaS、SaaS与DaaS深度解析
云服务模式详解:IaaS、PaaS、SaaS与DaaS 在当今数字化快速发展的时代,云计算已经成为企业和开发者不可或缺的一部分。它提供了灵活的资源和服务,使得用户可以根据自己的需求选择最合适的解决方案。本文将详细介绍四种主要的云服务模式&#…...
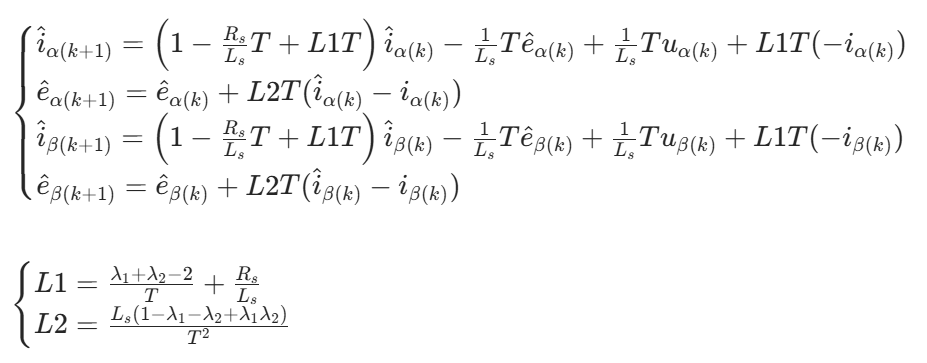
电机控制-隆博戈观测器(Luenberger state observer)
本文围绕基于无传感器控制策略的状态观测器展开,介绍其在电机领域的应用、原理、性能表现及无传感器驱动的优劣: 应用场景:适用于燃油泵、风扇等大量固定转速和低成本应用场景。工作原理:状态观测器利用完整的电机微分模型&#…...
RK3506+net9+VS2022跨平台调试C#程序
下载GetVsDbg.sh ,这脚本会下载一个压缩包,然后解压缩,设置x权限等等。但是目标板子连不上,就想办法获取到下载路径,修改这个脚本,显示这个下载链接后,复制一下,用电脑下下来 修改好…...

【16】数据结构之基于树的排序算法篇章
目录标题 选择排序简单选择排序树形选择排序 堆排序堆的定义Heap小跟堆大根堆堆的存储堆的代码设计堆排序的代码设计 排序算法综合比较 选择排序 基本思想:从待排序的序列中选出最大值或最小值,交换该元素与待排序序列的头部元素,对剩下的元…...

华熙生物亮相消博会,这次又带来了什么样的变化?
首先,从展示层面来看,华熙生物在消博会上构建科技桥梁,展台主视觉展示糖生物学发展历程与自身发展交织历程,这象征着中国生物科技企业从产业突围到定义全球标准的蜕变。这一展示不仅提升了华熙生物的品牌形象,更向外界…...

python自动化浏览器标签页的切换
#获取全部标签页的句柄返回句柄的列表 handleswebdriver.window_handles#获取全部标签页的句柄返回句柄的列表 print(len(handles)) 切换标签页 handleswebdriver.window_handles webdriver.switch_to.window(handles[index])#切换到第几个标签页就写几 关闭标签页 关闭标…...
大象机器人推出myCobot 280 RDK X5,携手地瓜机器人共建智能教育机
摘要 大象机器人全新推出轻量级高性能教育机械臂 myCobot 280 RDK X5,该产品集成地瓜机器人 RDK X5 开发者套件,深度整合双方在硬件研发与智能计算领域的技术优势,实现芯片架构、软件算法、硬件结构的全栈自主研发。作为国内教育机器人生态合…...

Redis 数据类型全解析:从基础到实战应用
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Redis 作为高性能的键值对存储系统,其丰富的数据类型是实现复杂业务逻辑的核心优势。本文将深入解析 Redis 六大核心数据类型及扩展类型ÿ…...

第一天 unity3D 引擎入门
一、为什么选择Unity进行3D开发? Unity作为全球使用最广泛的游戏引擎,在2022年的开发者调查中占据了62%的市场份额。它不仅支持3D/2D游戏开发,更在VR/AR、工业仿真、影视动画等领域大放异彩。对于初学者而言,Unity的独特优势在于…...