【消息队列kafka_中间件】三、Kafka 打造极致高效的消息处理系统
在当今数字化时代,数据量呈爆炸式增长,实时数据处理的需求变得愈发迫切。Kafka 作为一款高性能、分布式的消息队列系统,在众多企业级应用中得到了广泛应用。然而,要充分发挥 Kafka 的潜力,实现极致高效的消息处理,需要对其进行高级进阶和性能优化。
一、Kafka 高级特性深入剖析
1.1 分区再平衡
原理:
分区再平衡是 Kafka 中一个重要的机制,当消费者组中的消费者数量发生变化(如新增消费者、消费者崩溃等)或者主题的分区数量发生变化时,Kafka 会自动进行分区再平衡,以确保每个消费者能够均匀地消费主题的分区。
import org.apache.kafka.clients.consumer.*;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class RebalanceExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 订阅主题consumer.subscribe(Collections.singletonList("test-topic"), new ConsumerRebalanceListener() {@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> partitions) {System.out.println("Partitions revoked: " + partitions);}@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> partitions) {System.out.println("Partitions assigned: " + partitions);}});try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}}} finally {consumer.close();}}
}解释:
ConsumerRebalanceListener:用于监听分区再平衡事件。onPartitionsRevoked方法在分区被撤销时调用,onPartitionsAssigned方法在分区被分配时调用。consumer.subscribe:订阅主题,并注册分区再平衡监听器。
1.2 事务处理
原理:
Kafka 从 0.11.0 版本开始支持事务处理,允许生产者在一个事务中发送多条消息,确保这些消息要么全部成功发送,要么全部失败。事务处理可以保证消息的原子性,适用于对数据一致性要求较高的场景。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class TransactionExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("transactional.id", "my-transactional-id");KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 初始化事务producer.initTransactions();try {// 开始事务producer.beginTransaction();for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "key-" + i, "value-" + i);producer.send(record);}// 提交事务producer.commitTransaction();} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// 无法恢复的错误,关闭生产者producer.close();} catch (KafkaException e) {// 处理其他错误,回滚事务producer.abortTransaction();} finally {producer.close();}}
}解释:
transactional.id:为生产者指定一个唯一的事务 ID。initTransactions:初始化事务。beginTransaction:开始一个事务。commitTransaction:提交事务。abortTransaction:回滚事务。
1.3 幂等性生产者
原理:
幂等性生产者可以确保在消息发送过程中,即使发生重试,也不会导致消息的重复写入。Kafka 通过为每个生产者分配一个唯一的 PID(Producer ID),并为每条消息分配一个序列号,来实现幂等性。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class IdempotentProducerExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 启用幂等性props.put("enable.idempotence", "true");KafkaProducer<String, String> producer = new KafkaProducer<>(props);try {for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "key-" + i, "value-" + i);producer.send(record);}} finally {producer.close();}}
}
enable.idempotence:设置为true启用幂等性生产者。
二、Kafka 性能优化策略
2.1 生产者性能优化
批量发送:
生产者可以将多条消息批量发送到 Kafka,减少网络开销。可以通过设置batch.size和linger.ms参数来实现批量发送。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class BatchProducerExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 设置批量大小props.put("batch.size", 16384);// 设置等待时间props.put("linger.ms", 1);KafkaProducer<String, String> producer = new KafkaProducer<>(props);try {for (int i = 0; i < 100; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "key-" + i, "value-" + i);producer.send(record);}} finally {producer.close();}}
}解释:
batch.size:设置批量大小,单位为字节。当消息累积到这个大小后,生产者会将它们批量发送。linger.ms:设置生产者等待的时间,单位为毫秒。如果在这个时间内消息没有达到批量大小,也会将已有的消息发送出去。
2.2 消费者性能优化
并行消费:
消费者可以通过增加消费者组中的消费者数量,实现并行消费,提高消费效率。同时,合理设置fetch.max.bytes和fetch.min.bytes参数,控制每次拉取的消息量。
import org.apache.kafka.clients.consumer.*;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class ParallelConsumerExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 设置每次拉取的最大字节数props.put("fetch.max.bytes", 52428800);// 设置每次拉取的最小字节数props.put("fetch.min.bytes", 1024);KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList("test-topic"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}}} finally {consumer.close();}}
}解释:
fetch.max.bytes:设置每次拉取的最大字节数。fetch.min.bytes:设置每次拉取的最小字节数。如果 Kafka 中的消息量不足这个值,消费者会等待,直到满足条件。
2.3 集群性能优化
合理规划分区数量
分区数量的设置会影响 Kafka 的性能。分区数量过少会导致并发处理能力不足,分区数量过多会增加管理开销。需要根据实际的业务需求和硬件资源,合理规划分区数量。
硬件资源优化
为 Kafka 集群提供足够的 CPU、内存和磁盘 I/O 资源。可以使用高速磁盘(如 SSD)来提高磁盘读写性能,同时合理分配内存,避免内存不足导致的性能瓶颈。
网络优化
确保 Kafka 集群之间的网络带宽足够,减少网络延迟。可以采用分布式部署的方式,将 Kafka 节点分布在不同的物理机或虚拟机上,提高网络的可靠性和性能。
三、Kafka 监控与调优
3.1 监控指标
Kafka 提供了丰富的监控指标,如消息生产速率、消息消费速率、分区的水位(Log End Offset)等。可以使用 Kafka 自带的监控工具(如 JMX)或第三方监控工具(如 Prometheus、Grafana)来收集和展示这些指标。
3.2 性能调优实践
根据监控指标,对 Kafka 的配置参数进行调整。例如,如果发现消息生产速率较低,可以适当增大batch.size和linger.ms参数;如果发现消费者处理能力不足,可以增加消费者组中的消费者数量。
相关文章:

【消息队列kafka_中间件】三、Kafka 打造极致高效的消息处理系统
在当今数字化时代,数据量呈爆炸式增长,实时数据处理的需求变得愈发迫切。Kafka 作为一款高性能、分布式的消息队列系统,在众多企业级应用中得到了广泛应用。然而,要充分发挥 Kafka 的潜力,实现极致高效的消息处理&…...
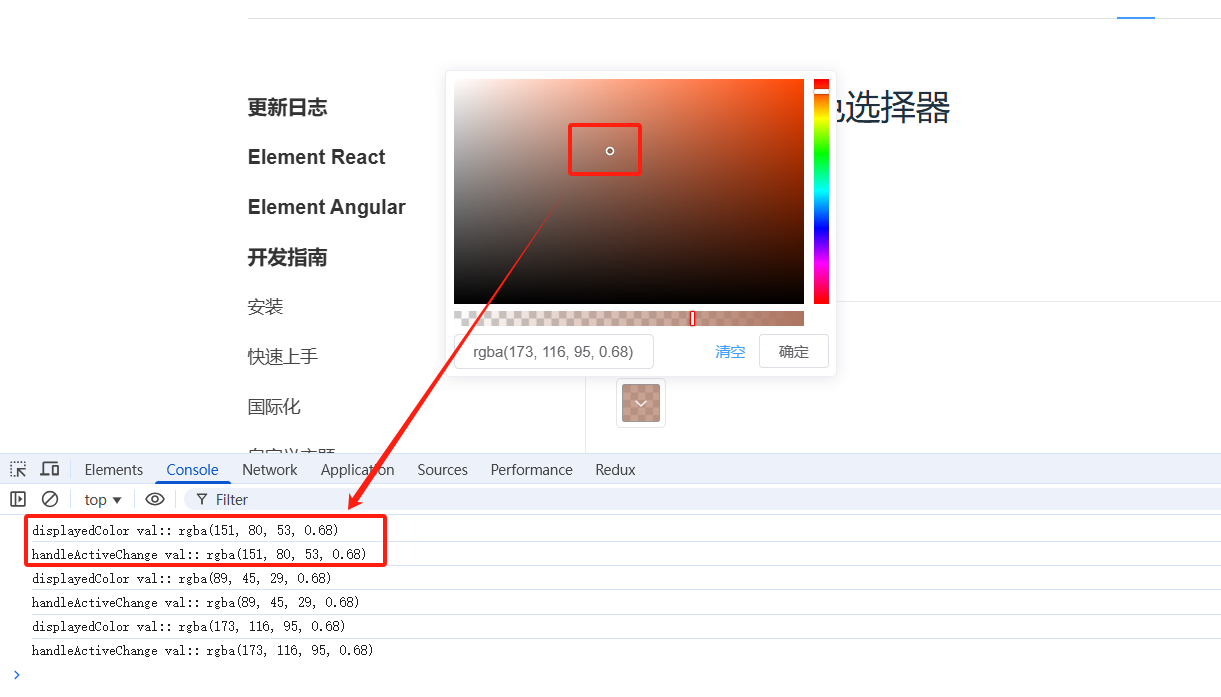
element-ui colorPicker 组件源码分享
简单分享 colorPicker 颜色选择器组件源码,主要从以下三个方面: 1、colorPicker 组件页面结构。 2、colorPicker 组件属性。 3、colorPicker 组件事件。 一、组件页面结构。 二、组件属性。 2.1 value/v-model 绑定值属性,类型为 string…...

Git 学习笔记
这篇笔记记录了我在git学习中常常用到的指令,方便在未来进行查阅。此篇文章也会根据笔者的学习进度持续更新。 网站分享 Git 常用命令大全 Learn Git Branching 基础 $ git init //在当前位置配置一个git版本库 $ git add <file> //将文件添加至…...
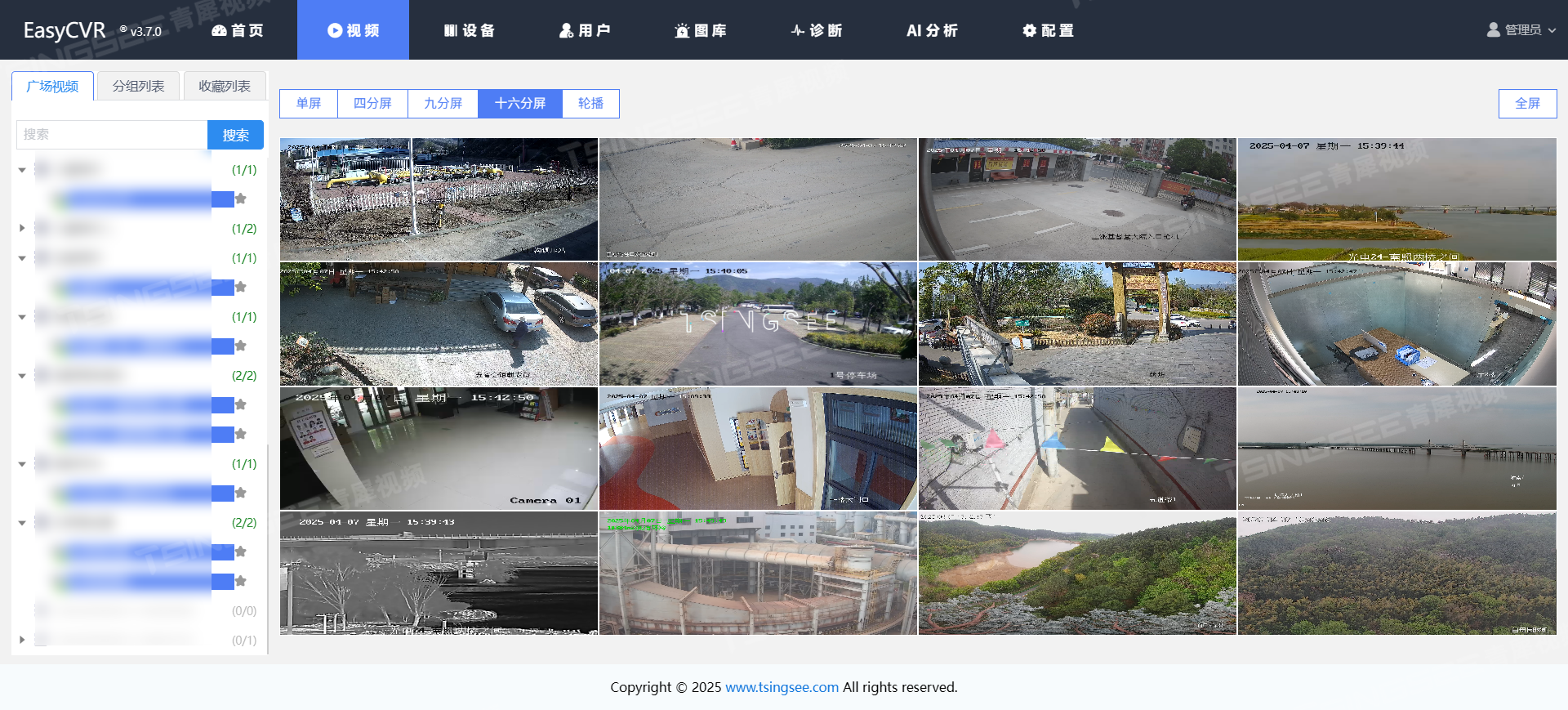
安防监控视频管理平台EasyCVR助力建筑工地施工4G/5G远程视频监管方案
一、项目背景 随着城市建设的快速发展,房地产建筑工地的数量、规模与施工复杂性都在增加,高空作业、机械操作频繁,人员流动大,交叉作业多,安全风险剧增。施工企业和政府管理部门在施工现场管理上都面临难题。政府部门…...
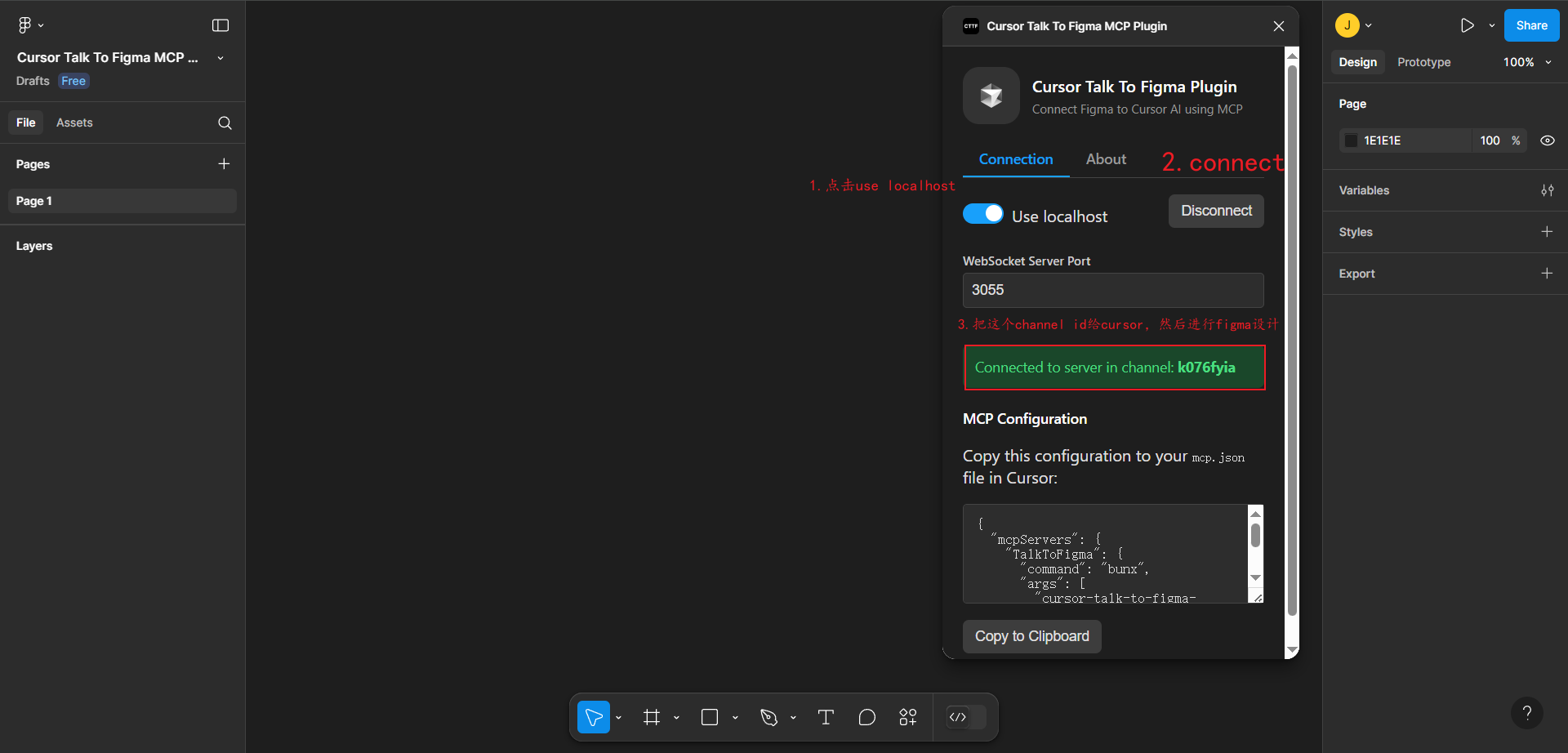
Cursor Talk To Figma MCP 安装与配置指南
Cursor Talk To Figma MCP 安装与配置指南 1.项目基础介绍 Cursor Talk To Figma MCP 是一个开源项目,它实现了 Cursor AI 与 Figma 之间的 Model Context Protocol(MCP)集成。通过这个集成,Cursor 能够与 Figma 进行通信&#…...

设计模式之状态模式:优雅管理对象行为变化
引言 状态模式(State Pattern)是一种行为型设计模式,它允许对象在其内部状态改变时改变它的行为,使对象看起来似乎修改了它的类。状态模式将状态转移逻辑和状态相关行为封装在独立的状态类中,完美解决了复杂条件判断问…...
高性能内存kv数据库Redis
目录 引言 一.Redis相关命令详解及其原理 1.redis是什么? 2.redis中存储数据的数据结构都有哪些? 3.redis的存储结构(KV) 4.reidis中value编码 5.string的基本原理和相关命令 5.1基本原理 5.2基础命令 5.3string存储结构 …...

C 语言宏定义的新用法
// power on/off #define SPK_POWER_ON() {GPIO_SET_OUT(PT_SPK_EN, PB_SPK_EN);GPIO_SET_HIGH(PT_SPK_EN, PB_SPK_EN);} #define SPK_POWER_OFF() {GPIO_SET_OUT(PT_SPK_EN, PB_SPK_EN);GPIO_SET_LOW(PT_SPK_EN, PB_SPK_EN);}在 C 语言中,宏定义可以…...

性能优化实践
4.1 大规模量子态处理的性能优化 背景与问题分析 量子计算中的大规模量子态处理(如量子模拟、量子态可视化)需要高效计算和实时渲染能力。传统图形API(如WebGL)在处理高维度量子态时可能面临性能瓶颈,甚至崩溃(如表格中14量子比特时WebGL的崩溃)。而现代API(如WebGPU…...
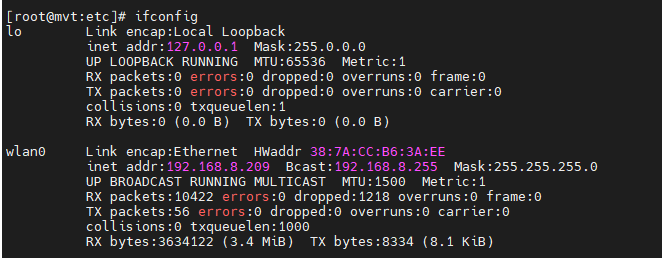
使用wpa_cli和wpa_supplicant配置Liunx开发板的wlan0无线网
目录 1 简单介绍下wpa_cli和wpa_supplicant 1.1 wpa_supplicant 简介 1.2 wpa_cli 简介 1.3 它们之间的关系 2 启动wpa_supplicant 3 使用rz工具把wpa_cli命令上传到开发板 4 用wpa_cli配置网络 参考文献: 1 简单介绍下wpa_cli和wpa_supplicant 1.1 wpa_su…...
C++Cherno 学习笔记day19 [76]-[80] std::optional、variant、any、如何让C++及字符串运行得更快
b站Cherno的课[76]-[80] 一、如何处理OPTIONAL数据 std::optional二、单一变量存放多类型的数据 std::variant三、如何存储任意类型的数据 std::any四、如何让C运行得更快五、如何让C字符串更快 一、如何处理OPTIONAL数据 std::optional std::optional C17 数据是否存在是可选…...
)
【信息系统项目管理师】高分论文:论信息系统项目的整合管理(旅游景区导游管理平台)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文一、制定项目章程二、制订项目管理计划三、指导和管理项目工作四、管理项目知识五、监控项目工作六、实施整体变更控制七、结束项目或阶段论文 在国家《中国旅游“十三五”发展规划信息化专项规划的背景下…...
【项目日记(一)】-仿mudou库one thread oneloop式并发服务器实现
1、模型框架 客户端处理思想:事件驱动模式 事件驱动处理模式:谁触发了我就去处理谁。 ( 如何知道触发了)技术支撑点:I/O的多路复用 (多路转接技术) 1、单Reactor单线程:在单个线程…...

[特殊字符] LoRA微调大模型实践:从MAC到Web的全流程指南
🚀 实践步骤概览 今天我们要在MAC上完成一个完整的AI项目闭环: 微调一个大模型 → 2. 导出模型并部署 → 3. 暴露API给web后端 → 4. 前端展示 🛠️ 微调模型准备 核心配置 框架:LLama-Factory 🏭 算法:…...

关于 Spring Boot 监控方式的详细对比说明及总结表格
以下是关于 Spring Boot 监控方式的详细对比说明及总结表格: 1. 监控方式概述 1.1 Actuator(内置核心监控) 功能: Spring Boot 内置的监控模块,提供健康检查、指标收集、环境信息、HTTP 追踪等端点。 适用场景&#…...

OpenCV 图形API(35)图像滤波-----中值模糊函数medianBlur()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 使用中值滤波器模糊图像。 该函数使用带有 ksizeksize 开口的中值滤波器来平滑图像。多通道图像的每个通道都是独立处理的。输出图像必须与输入…...

【嵌入式八股5】C++:多线程相关
1. 线程创建与管理 1.1 pthread_create 功能: 创建一个新的线程,并指定该线程的执行函数。参数: pthread_t *thread: 指向线程标识符的指针。const pthread_attr_t *attr: 线程属性,通常为 NULL。void *(*start_routine)(void *): 线程执行的函数指针。…...

视觉slam框架从理论到实践-第一节绪论
从opencv的基础实现学习完毕后,接下来依照视觉slam框架从理论到实践(第二版)的路线进行学习,主要以学习笔记的形式进行要点记录。 目录 1.数据里程计 2.后端优化 3.回环检测 4.建图 在视觉SLAM 中整体作业流程可分为࿱…...
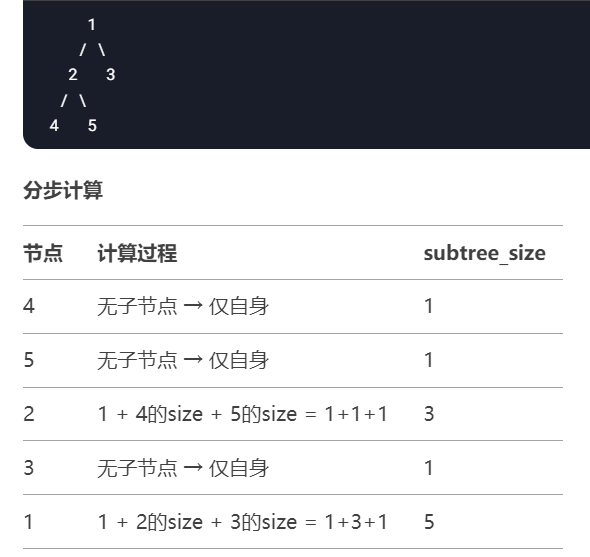
图论--DFS搜索图/树
目录 一、图的存储结构 二、题目练习 846. 树的重心 - AcWing题 dfs,之前学习的回溯算法好多都是用dfs实现搜索的(把题目抽象成树形结构来搜索),其实 回溯算法就是 深搜,只不过针对某一搜索场景 我们给他一个更细分…...

Visual Studio + OpenCV C++ 安装与配置教程
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,广泛用于图像处理、视频分析、模式识别和机器学习等领域。它由Intel公司于1999年发起,并在2000年由Willow Garage(一个机器人研究机构)进一步开发和维护。OpenCV支持多种编程语言,包括C++、Python…...
)
Java核心知识点的系统整理(一)
目录 一、数据类型与运算符秘籍 1. 四类八种数据类型 2. 自增运算符的暗战 3. 位运算与逻辑运算对决 二、流程控制三剑客 1. 分支结构抉择 2. 循环控制四骑士 三、面向对象核心机制 1. final的三重封印 2. 静态成员生存法则 四、进阶特性解密 1. 多态的三重境界 2…...

在Android Studio中,`Settings`里的Gradle路径、环境变量以及`gradle - wrapper.properties`文件关联
在Android Studio中,Settings里的Gradle路径、环境变量以及gradle - wrapper.properties文件关联 Android Studio中Settings里的Gradle路径 在Android Studio的Settings(Preferences ) -> Build, Execution, Deployment -> Build Tools -> Gradle 中: Use defau…...

算法复习(二分+离散化+快速排序+归并排序+树状数组)
一、二分算法 二分算法,堪称算法世界中的高效查找利器,其核心思想在于利用数据的有序性,通过不断将查找区间减半,快速定位目标元素或满足特定条件的位置。 1. 普通二分 普通二分适用于在有序数组中查找特定元素的位置。我们可以…...

VSCode写java时常用的快捷键
首先得先安好java插件 1、获取返回值 这里是和idea一样的快捷键的,都是xxxx.var 比如现在我new一个对象 就输入 new MbDo().var // 点击回车即可变成下面的// MbDo mbDo new MbDo()//以此类推get方法也可获取 mbDo.getMc().var // 点击回车即可变成下面的 // St…...

【Code】《代码整洁之道》笔记-Chapter16-重构SerialDate
第16章 重构SerialDate 如果你找到JCommon类库,深入该类库,其中有个名为org.jfree.date的程序包。在该程序包中,有个名为SerialDate的类,我们即将剖析这个类。 SerialDate的作者是David Gilbert。David显然是一位经验丰富、能力…...

使用 Node.js、Express 和 React 构建强大的 API
了解如何使用 Node.js、Express 和 React 创建一个强大且动态的 API。这个综合指南将引导你从设置开发环境开始,到集成 React 前端,并利用 APIPost 进行高效的 API 测试。无论你是初学者还是经验丰富的开发者,这篇文章都适合你。 今天&#…...

深度学习入门:神经网络的学习
目录 1 从数据中学习1.1 数据驱动1.2 训练数据和测试数据 2损失函数2.1 均方误差2.2 交叉熵误差2.3 mini-batch学习2.4 mini-batch版交叉熵误差的实现2.5 为何要设定损失函数 3 数值微分3.1 数值微分3.3 偏导数 4 梯度4.1 梯度法4.2 神经网络的梯度 5 学习算法的实现5.1 2层神经…...

OSI参考模型和TCP/IP模型
1.OSI参考模型 OSI模型: OSI参考模型有7层,自下而上依次为物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。(记忆口诀:物联网叔会用)。低…...

人工智能中的卷积神经网络(CNN)综述
文章目录 前言 1. CNN的基本原理 1.1 卷积层 1.2 池化层 1.3 全连接层 2. CNN的发展历程 2.1 LeNet-5 2.2 AlexNet 2.3 VGGNet 2.4 ResNet 3. CNN的主要应用 3.1 图像分类 3.2 目标检测 3.3 语义分割 3.4 自然语言处理 4. 未来研究方向 4.1 模型压缩与加速 4.2 自监督学习 4.3 …...
WordPress - 此站点出现严重错误
本篇讲 当WordPress出现 此站点出现严重错误 时,该如何解决。 目录 1,现象 2, FAQ 3,管理Menu无法打开 下面是详细内容。 1,现象 此站点出现严重错误(このサイトで重大なエラーが発生しました&#x…...