算法复习(二分+离散化+快速排序+归并排序+树状数组)
一、二分算法
二分算法,堪称算法世界中的高效查找利器,其核心思想在于利用数据的有序性,通过不断将查找区间减半,快速定位目标元素或满足特定条件的位置。
1. 普通二分
普通二分适用于在有序数组中查找特定元素的位置。我们可以进一步细分需求,如查找满足条件的最左边的数的下标,或者最右边的数的下标。以代码中的 find1 和 find2 函数为例:
cpp
#include <bits/stdc++.h>
using namespace std;
const int N = 100010;
int a[N];
int n, m;int find1(int x) {int l = 0, r = n + 1;int ans = 0;while (l <= r) {int mid = (l + r) >> 1;if (a[mid] > x) {r = mid - 1;}else if (a[mid] == x) {ans = mid;r = mid - 1;}else if (a[mid] < x) {l = mid + 1;}}return ans;
}
int find2(int x) {int l = 0, r = n + 1;int ans = 0;while (l <= r) {int mid = (l + r) >> 1;if (a[mid] > x) {r = mid - 1;}else if (a[mid] == x) {ans = mid;l = mid + 1;}else if (a[mid] < x) {l = mid + 1;}}return ans;
}
int main() {cin >> n >> m;for (int i = 1; i <= n; i++) {cin >> a[i];}while (m--) {int tmp;cin >> tmp;cout << find1(tmp) - 1 << ' ' << find2(tmp) - 1 << endl;}return 0;
}
![]()
在 find1 函数中,当找到与 x 相等的元素时,我们继续将右边界 r 调整为 mid - 1,目的是持续向左查找,确保最终得到的是最左边的符合条件的下标。而 find2 函数在找到相等元素后,将左边界 l 调整为 mid + 1,以此向右查找最右边的符合条件的下标。这种技巧在处理重复元素较多的数组时,能够精准定位特定位置,为后续的数据处理提供极大便利。
2. 数值二分
数值二分则是将二分思想应用于数值求解领域。例如,在求一个浮点数的三次方根问题中,我们利用数值二分的方法可以高效且准确地得到结果。
cpp
#include<iostream>
#include<iomanip>
using namespace std;
double n, l, r, mid;
double q(double a) {return a * a * a;
}
int main() {cin >> n;l = -10000, r = 10000;while (r - l >= 1e-7) {mid = (l + r) / 2;if (q(mid) >= n) r = mid;else l = mid;}cout << fixed << setprecision(6) << l;return 0;
}
我们先确定一个可能包含三次方根的区间 [l, r],在这个例子中,由于任何实数的三次方根都在 -10000 到 10000 这个较大范围之内(对于一般竞赛和实际应用场景中的数值而言),我们以此作为初始区间。然后,通过不断缩小区间范围,当区间长度小于一定精度(这里是 1e-7)时,我们认为此时的左边界 l 就是所求三次方根的近似值。数值二分在处理这类数值逼近问题时,展现出了极高的效率和稳定性,相较于暴力枚举等方法,大大减少了计算量。
二、排序算法
排序算法是数据处理领域的核心算法之一,它能够将无序的数据整理成有序的序列,为后续的数据查找、统计、分析等操作奠定基础。
1. 快速排序
快速排序凭借其高效的性能,在众多排序算法中脱颖而出,广泛应用于各类场景。它基于分治策略,通过选择一个基准值,将数组划分为两部分,使得左边部分的元素都小于等于基准值,右边部分的元素都大于等于基准值,然后递归地对左右两部分进行排序。
cpp
#include<bits/stdc++.h>
using namespace std;const int N = 1000010;
int a[N];
int n;
void q(int l, int r) {if (l >= r) return;if (l + 1 == r) {if (a[l] > a[r]) swap(a[l], a[r]);return;}int i = l - 1, j = r + 1;int x = a[(i + j) >> 1];while (i <= j) {do i++; while (a[i] < x);do j--; while (a[j] > x);if (i < j) swap(a[i], a[j]);}q(l, j); q(j + 1, r); // 注意这里是j
}
int main() {cin >> n;for (int i = 0; i < n; i++) scanf("%d", &a[i]);q(0, n - 1);for (int i = 0; i < n; i++) printf("%d ", a[i]);
}
在代码中,我们选取数组中间位置的元素作为基准值 x。通过两个指针 i 和 j 从数组两端向中间移动,将小于基准值的元素交换到左边,大于基准值的元素交换到右边。当 i 和 j 相遇时,数组就被划分成了符合条件的两部分。随后,递归地对这两部分继续进行快速排序,直至整个数组有序。快速排序的平均时间复杂度为 O(nlogn),在数据量较大时表现出色。
快排的延展:第 k 个数
基于快速排序的思想,我们可以进一步拓展其应用,快速找出数组中第 k 小的数。这在很多需要统计特定位置元素的场景中非常实用。
cpp
#include<bits/stdc++.h>
using namespace std;const int N = 1000010;
int a[N];
int n;int q(int l, int r, int k) {if (l >= r) return a[l];if (l + 1 == r) {if (a[l] > a[r]) swap(a[l], a[r]);if (k == 1) return a[l];return a[r];}int i = l - 1, j = r + 1;int x = a[(i + j) >> 1];while (i <= j) {do i++; while (a[i] < x);do j--; while (a[j] > x);if (i < j) swap(a[i], a[j]);}int len = j - l + 1;if (k <= len) // 注意这里的是k<=len,而不是k<=j+1return q(l, j, k);return q(j + 1, r, k - len);
}
int main() {int k;cin >> n >> k;for (int i = 0; i < n; i++) scanf("%d", &a[i]);cout << q(0, n - 1, k);}
在每次划分后,我们计算左半部分的长度 len。如果 k 小于等于 len,说明第 k 小的数在左半部分,我们递归在左半部分查找;否则,在右半部分查找,并且将 k 调整为 k - len,因为我们已经排除了左半部分的 len 个数。这种方法避免了对整个数组进行完全排序,大大提高了查找特定位置元素的效率。
2. 归并排序
归并排序同样是一种基于分治思想的排序算法,它将数组逐步分解为较小的子数组,分别进行排序后,再将这些有序的子数组合并成一个最终的有序数组。
cpp
#include <iostream>
using namespace std;
const int N = 100010;
int n;
int a[N];
int tmp[N];
void merge_sort(int l, int r) {if (l >= r) return;int mid = l + r >> 1;merge_sort(l, mid); merge_sort(mid + 1, r);int ls = l, rs = mid + 1; int tmpread = 0;while (ls <= mid && rs <= r) {if (a[ls] < a[rs]) tmp[tmpread++] = a[ls++];else tmp[tmpread++] = a[rs++];}while (ls <= mid) tmp[tmpread++] = a[ls++];while (rs <= r) tmp[tmpread++] = a[rs++];for (int i = l, j = 0; i <= r; j++, i++) a[i] = tmp[j];
}
int main() {cin >> n;for (int i = 0; i < n; i++) cin >> a[i];merge_sort(0, n - 1);for (int i = 0; i < n; i++) cout << a[i] << ' ';return 0;
}
在代码实现中,我们首先将数组递归地划分为左右两部分,直到子数组长度为 1(此时子数组自然有序)。然后,在合并阶段,通过两个指针 ls 和 rs 分别指向左右两个子数组的起始位置,比较并将较小的元素依次放入临时数组 tmp 中。当其中一个子数组遍历完后,将另一个子数组剩余的元素直接复制到 tmp 中。最后,将 tmp 数组中的元素复制回原数组 a,完成一次合并。归并排序的时间复杂度稳定在 O(nlogn),并且它是一种稳定的排序算法,即在排序过程中,相同元素的相对顺序保持不变。
归并排序的延伸:逆序对
归并排序的思想还可以巧妙地用于统计数组中的逆序对数量。逆序对在许多算法问题中有着重要的应用,比如计算数组的无序程度等。
cpp
#include <iostream>
using namespace std;const long long N = 1000010;
long long n;
long long a[N];
long long tmp[N];// 归并排序并统计逆序对数量
long long merge_sort(long long l, long long r) {if (l >= r) return 0;if (l + 1 == r) {if (a[l] > a[r]) {swap(a[l], a[r]);return 1;}return 0;}long long mid = l + r >> 1;long long res = merge_sort(l, mid) + merge_sort(mid + 1, r);long long ls = l, rs = mid + 1, tmpread = 0;while (ls <= mid && rs <= r) {if (a[ls] <= a[rs]) {tmp[tmpread++] = a[ls++];}else {// 当 a[ls] > a[rs] 时,a[ls...mid] 都与 a[rs] 构成逆序对res += mid - ls + 1;tmp[tmpread++] = a[rs++];}}while (ls <= mid) tmp[tmpread++] = a[ls++];while (rs <= r) tmp[tmpread++] = a[rs++];for (long long i = l, j = 0; i <= r; j++, i++) a[i] = tmp[j];return res;
}int main() {cin >> n;for (long long i = 0; i < n; i++) cin >> a[i];cout << merge_sort(0, n - 1);return 0;
}
在合并过程中,当我们发现 a[ls] > a[rs] 时,这意味着 a[ls] 到 a[mid] 这 mid - ls + 1 个元素都与 a[rs] 构成逆序对,因此将这个数量累加到结果 res 中。通过递归地进行归并排序和逆序对统计,我们能够高效地得到整个数组的逆序对数量。
三、区间和
在处理区间和相关问题时,离散化与树状数组的组合是一种非常强大的解决方案。当我们面对无限长数轴上的区间操作,或者数据范围过大导致直接存储和处理困难时,离散化可以将实际用到的数据映射到一个较小的连续空间中,大大减少内存占用和计算量。而树状数组则为快速更新和查询区间和提供了便利。
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;// 树状数组类
class FenwickTree {
private:vector<int> tree;int n;// 计算最低位的 1 所代表的值int lowbit(int x) {return x & -x;}public:FenwickTree(int size) : n(size), tree(size + 1, 0) {}// 单点更新操作void update(int idx, int val) {while (idx <= n) {tree[idx] += val;idx += lowbit(idx);}}// 前缀和查询操作int query(int idx) {int res = 0;while (idx > 0) {res += tree[idx];idx -= lowbit(idx);}return res;}
};// 二分查找数值对应的下标
int find(int x, const vector<int>& a) {int l = 0, r = a.size() - 1;while (l < r) {int mid = l + r >> 1;if (a[mid] >= x) r = mid;else l = mid + 1;}// 如果 x 小于最小的位置,返回 0if (a[l] > x) return 0;return l + 1; // 下标从 1 开始
}int main() {int n, m;cin >> n >> m;vector<pair<int, int>> operations(n);vector<pair<int, int>> queries(m);vector<int> all_positions;// 读取操作并记录所有位置for (int i = 0; i < n; ++i) {cin >> operations[i].first >> operations[i].second;all_positions.push_back(operations[i].first);}// 读取查询并记录所有位置for (int i = 0; i < m; ++i) {cin >> queries[i].first >> queries[i].second;all_positions.push_back(queries[i].first);all_positions.push_back(queries[i].second);}// 离散化处理sort(all_positions.begin(), all_positions.end());all_positions.erase(unique(all_positions.begin(), all_positions.end()), all_positions.end());// 创建树状数组FenwickTree fenwickTree(all_positions.size());// 执行操作for (const auto& op : operations) {int idx = find(op.first, all_positions);fenwickTree.update(idx, op.second);}// 处理查询for (const auto& query : queries) {int l = find(query.first, all_positions);int r = find(query.second, all_positions);int result = fenwickTree.query(r) - fenwickTree.query(l - 1);cout << result << endl;}return 0;
}相关文章:

算法复习(二分+离散化+快速排序+归并排序+树状数组)
一、二分算法 二分算法,堪称算法世界中的高效查找利器,其核心思想在于利用数据的有序性,通过不断将查找区间减半,快速定位目标元素或满足特定条件的位置。 1. 普通二分 普通二分适用于在有序数组中查找特定元素的位置。我们可以…...

VSCode写java时常用的快捷键
首先得先安好java插件 1、获取返回值 这里是和idea一样的快捷键的,都是xxxx.var 比如现在我new一个对象 就输入 new MbDo().var // 点击回车即可变成下面的// MbDo mbDo new MbDo()//以此类推get方法也可获取 mbDo.getMc().var // 点击回车即可变成下面的 // St…...

【Code】《代码整洁之道》笔记-Chapter16-重构SerialDate
第16章 重构SerialDate 如果你找到JCommon类库,深入该类库,其中有个名为org.jfree.date的程序包。在该程序包中,有个名为SerialDate的类,我们即将剖析这个类。 SerialDate的作者是David Gilbert。David显然是一位经验丰富、能力…...

使用 Node.js、Express 和 React 构建强大的 API
了解如何使用 Node.js、Express 和 React 创建一个强大且动态的 API。这个综合指南将引导你从设置开发环境开始,到集成 React 前端,并利用 APIPost 进行高效的 API 测试。无论你是初学者还是经验丰富的开发者,这篇文章都适合你。 今天&#…...

深度学习入门:神经网络的学习
目录 1 从数据中学习1.1 数据驱动1.2 训练数据和测试数据 2损失函数2.1 均方误差2.2 交叉熵误差2.3 mini-batch学习2.4 mini-batch版交叉熵误差的实现2.5 为何要设定损失函数 3 数值微分3.1 数值微分3.3 偏导数 4 梯度4.1 梯度法4.2 神经网络的梯度 5 学习算法的实现5.1 2层神经…...

OSI参考模型和TCP/IP模型
1.OSI参考模型 OSI模型: OSI参考模型有7层,自下而上依次为物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。(记忆口诀:物联网叔会用)。低…...

人工智能中的卷积神经网络(CNN)综述
文章目录 前言 1. CNN的基本原理 1.1 卷积层 1.2 池化层 1.3 全连接层 2. CNN的发展历程 2.1 LeNet-5 2.2 AlexNet 2.3 VGGNet 2.4 ResNet 3. CNN的主要应用 3.1 图像分类 3.2 目标检测 3.3 语义分割 3.4 自然语言处理 4. 未来研究方向 4.1 模型压缩与加速 4.2 自监督学习 4.3 …...
WordPress - 此站点出现严重错误
本篇讲 当WordPress出现 此站点出现严重错误 时,该如何解决。 目录 1,现象 2, FAQ 3,管理Menu无法打开 下面是详细内容。 1,现象 此站点出现严重错误(このサイトで重大なエラーが発生しました&#x…...
)
力扣每日打卡 1534. 统计好三元组 (简单)
力扣 1534. 统计好三元组 简单 前言一、题目内容二、解题方法1. 暴力解法2.官方题解2.1 方法一:枚举2.2 方法二:枚举优化 前言 这是刷算法题的第十二天,用到的语言是JS 题目:力扣 1534. 统计好三元组 (简单) 一、题目内容 给你一…...

《Vue3学习手记2》
今天主要学习Vue3中的数据监视: ps: 代码中的注释写的很详细,这样更有利于理解 watch 作用: 监视数据的变化(和Vue2中watch作用一致) 特点: Vue3中的watch只能监视以下四种数据: ref创建定义的数据(基本类型、对象类型)reactiv…...
在pycharm中搭建yolo11分类检测系统1--PyQt5学习(一)
实验条件:pycharm24.3autodlyolov11环境PyQt5 如果pycharm还没有配PyQt5的话就先去看我原先写的这篇博文: PyQT5安装搭配QT DesignerPycharm)-CSDN博客 跟练参考文章: 目标检测系列(四)利用pyqt5实现yo…...
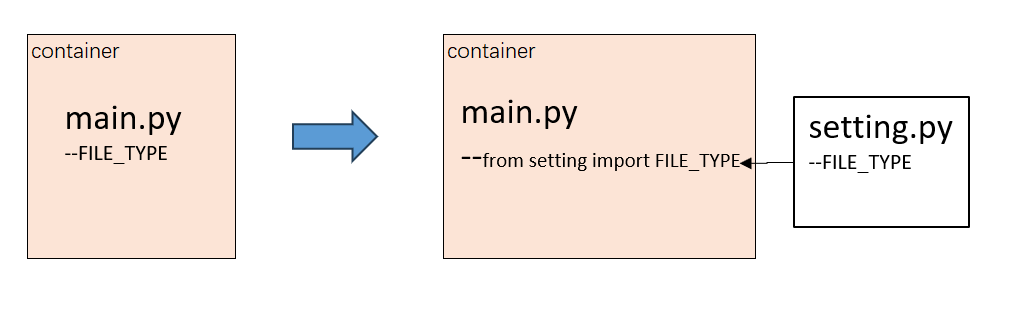
【经验记录贴】使用配置文件提高项目的可维护性
mark一下。 整体修改前后如下: 课题: 在项目中有一个支持的文件类型的FILE_TYPE的定义, 这个是写死在主程序中,每次增加可以支持的文件类型的时候,都需要去修改主程序中这个FILGE_TYPE的定义。 主程序修改其实不太花时…...

从JSON到SQL:基于业务场景的SQL生成器实战
引言 在数据驱动的业务场景中,将业务需求快速转化为SQL查询是常见需求。本文将通过一个轻量级的sql_json_to_sql函数,展示如何将JSON格式的查询描述转换为标准SQL语句,并结合实际业务场景验证其功能。 核心代码解析 1. 代码实现 def sql_j…...

空格键会提交表单吗?HTML与JavaScript中的行为解析
在网页开发中,理解用户交互细节对于提供流畅的用户体验至关重要。一个常见的问题是:空格键是否会触发表单提交?本文将通过一个简单的示例解释这一行为,并探讨如何使用HTML和JavaScript来定制这种交互。 示例概览 考虑以下HTML代…...
)
06 - 多线程-JUC并发编程-原子类(二)
上一章,讲解java (java.util.concurrent.atomic) 包中的 支持基本数据类型的原子类,以及支持数组类型的原子类,这一章继续讲解支持对实体类的原子类,以及原子类型的修改器。 还有最后java (java…...

vue3 实现谷歌登录
很多人都是直接在 index.html 文件中引入的,刚开始我也那样写但是谷歌的api只能调起一次后续就不会生效了 我的登录是个弹窗,写在app.vue 文件中 const isGoogleLoaded ref(true);onMounted(async () > {initialize(); }); // 初始化 const initi…...
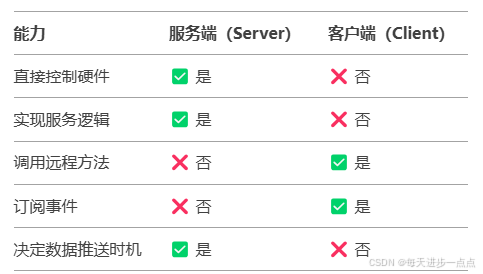
SOME/IP中”客户端消费“及”服务端提供”的解析
先上结论 AREthAddConsumedEventGroup-->客户端的函数-->谁调用 Consumed函数,谁就是消费者 AREthAddProvidedEventGroup-->服务端的函数-->谁调用 Provided函数,谁就是服务端 Server 端:AREthAddProvidedEventGroup → 声明 &…...
)
GO语言入门:字符串处理1(打印与格式化输出)
13.1 打印文本 在 fmt 包中,Print 函数用于打印(输出)文本信息。依据输出目标的不同,Print 函数可以划分为三组,详见下表。 按应用目标分组函数说明将文本信息输出到标准输出流,一般是输出到屏幕上Print将…...
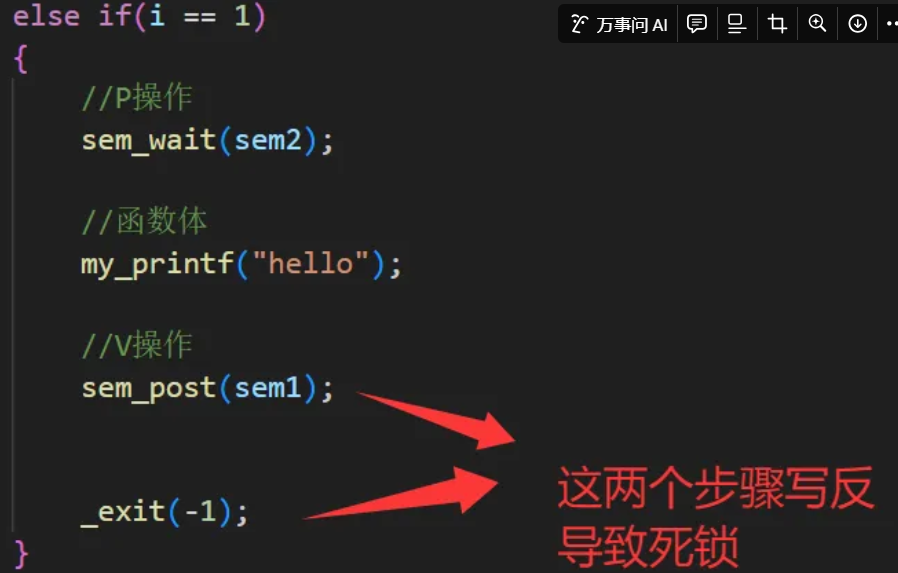
Linux 深入浅出信号量:从线程到进程的同步与互斥实战指南
知识点1【信号量概述】 信号量是广泛用于进程和线程间的同步和互斥。信号量的本质 是一个非负的整数计数器,它被用来控制对公共资源的访问 当信号量值大于0的时候,可以访问,否则将阻塞。 PV原语对信号量的操作,一次P操作使信号…...
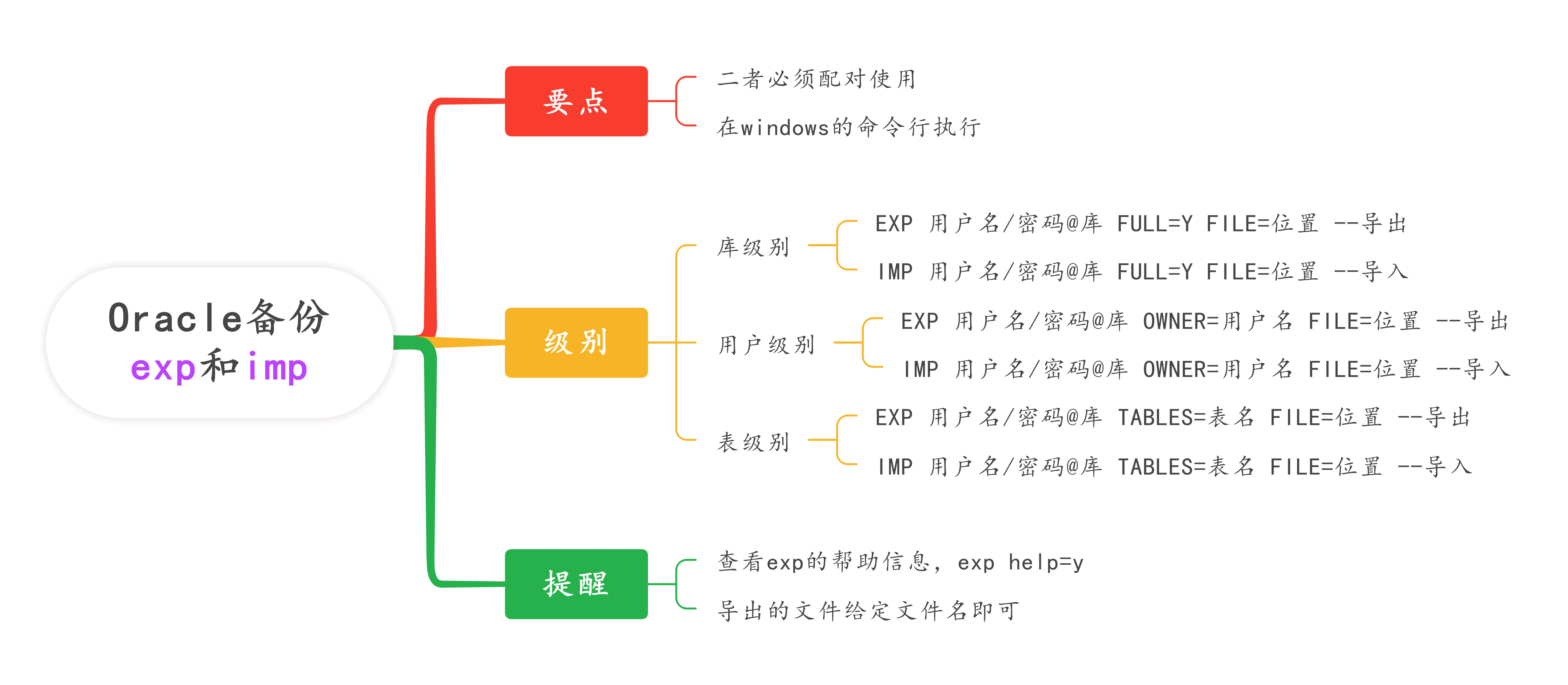
Oracle数据库数据编程SQL<9.1 数据库逻辑备份和迁移exp和imp之导出、导入>
EXP (Export) 和 IMP (Import) 是 Oracle 提供的传统数据导出导入工具,用于数据库逻辑备份和迁移。尽管在较新版本中已被 Data Pump (EXPDP/IMPDP) 取代,但在某些场景下仍然有用。 目录 一、EXP 导出工具 1. 基本语法 2. 常用参数说明 3. 导出模式 3.1 表模式导出 3.2 用…...
DotnetCore开源库SampleAdmin源码编译
1.报错: System.Net.Sockets.SocketException HResult0x80004005 Message由于目标计算机积极拒绝,无法连接。 SourceSystem.Net.Sockets StackTrace: 在 System.Net.Sockets.Socket.AwaitableSocketAsyncEventArgs.ThrowException(SocketError error, C…...
)
Kaggle-Disaster Tweets-(二分类+NLP+模型融合)
Disaster Tweets 题意: 就是给出一个dataframe包含text这一列代表着文本,文本会有一些词,问对于每条记录中的text是真关于灾难的还是假关于灾难的。 比如我们说今天作业真多,这真是一场灾难。实际上这个灾难只是我们调侃而言的。…...

搭建一个网站需要选择什么配置的服务器?
一般要考虑网站规模、技术需求等因素来进行选择。 小型网站:个人博客、小型企业官网等日均量在 1000 以内的网站,一般推荐2 核 CPU、4GB 内存、50GB 硬盘,带宽 1 - 5M。如果是纯文字内容且图片较少的小型网站,初始阶段 1 核 CPU、…...

idea如何使用git
在 IntelliJ IDEA 中使用 Git 的详细步骤如下,分为配置、基础操作和高级功能,适合新手快速上手: 一、配置 Git 安装 Git 下载并安装 Git,安装时勾选“Add to PATH”。验证安装:终端输入 git --version 显示版本…...

webpack vite
1、webpack webpack打包工具(重点在于配置和使用,原理并不高优。只在开发环境应用,不在线上环境运行),压缩整合代码,让网页加载更快。 前端代码为什么要进行构建和打包? 体积更好&#x…...
.Net 9 webapi使用Docker部署到Linux
参考文章连接: https://www.cnblogs.com/kong-ming/p/16278109.html .Net 6.0 WebApi 使用Docker部署到Linux系统CentOS 7 - 长白山 - 博客园 项目需要跨平台部署,所以就研究了一下菜鸟如何入门Net跨平台部署,演示使用的是Net 9 webAPi Li…...
PyTorch 根据官网命令行无法安装 GPU 版本 解决办法
最近遇到一个问题,PyTorch 官网给出了 GPU 版本的安装命令,但安装成功后查看版本,仍然是 torch 2.6.0cpu 1. 清理现有 PyTorch 安装 经过探索发现,需要同时卸载 conda 和 pip 安装的 torch。 conda remove pytorch torchvision …...

PHP防火墙代码,防火墙,网站防火墙,WAF防火墙,PHP防火墙大全
PHP防火墙代码,防火墙,网站防火墙,WAF防火墙,PHP防火墙大全 资源宝整理分享:https://www.htple.net PHP防火墙(作者:悠悠楠杉) 验证测试,链接后面加上?verify_cs1后可以自行测试 <?php //复制保存zzwaf.php$we…...
使用 Vitis Model Composer 生成 FPGA IP 核
本文将逐步介绍如何使用 Vitis Model Composer 生成 FPGA IP 核,从建模到部署。 在当今快节奏的世界里,技术正以前所未有的速度发展,FPGA 设计也不例外。高级工具层出不穷,加速着开发进程。传统上,FPGA 设计需要使用硬…...

Day08 【基于jieba分词实现词嵌入的文本多分类】
基于jieba分词的文本多分类 目标数据准备参数配置数据处理模型构建主程序测试与评估测试结果 目标 本文基于给定的词表,将输入的文本基于jieba分词分割为若干个词,然后将词基于词表进行初步编码,之后经过网络层,输出在已知类别标…...