Day08 【基于jieba分词实现词嵌入的文本多分类】
基于jieba分词的文本多分类
- 目标
- 数据准备
- 参数配置
- 数据处理
- 模型构建
- 主程序
- 测试与评估
- 测试结果
目标
本文基于给定的词表,将输入的文本基于jieba分词分割为若干个词,然后将词基于词表进行初步编码,之后经过网络层,输出在已知类别标签上的概率分布,从而实现一个简单文本的多分类。
数据准备
词表文件chars.txt
类别标签文件schema.json
{"停机保号": 0,"密码重置": 1,"宽泛业务问题": 2,"亲情号码设置与修改": 3,"固话密码修改": 4,"来电显示开通": 5,"亲情号码查询": 6,"密码修改": 7,"无线套餐变更": 8,"月返费查询": 9,"移动密码修改": 10,"固定宽带服务密码修改": 11,"UIM反查手机号": 12,"有限宽带障碍报修": 13,"畅聊套餐变更": 14,"呼叫转移设置": 15,"短信套餐取消": 16,"套餐余量查询": 17,"紧急停机": 18,"VIP密码修改": 19,"移动密码重置": 20,"彩信套餐变更": 21,"积分查询": 22,"话费查询": 23,"短信套餐开通立即生效": 24,"固话密码重置": 25,"解挂失": 26,"挂失": 27,"无线宽带密码修改": 28
}
训练集数据train.json训练集数据
验证集数据valid.json验证集数据
参数配置
config.py
# -*- coding: utf-8 -*-"""
配置参数信息
"""Config = {"model_path": "model_output","schema_path": "../data/schema.json","train_data_path": "../data/train.json","valid_data_path": "../data/valid.json","vocab_path":"../chars.txt","max_length": 20,"hidden_size": 128,"epoch": 10,"batch_size": 32,"optimizer": "adam","learning_rate": 1e-3,
}
数据处理
loader.py
# -*- coding: utf-8 -*-import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader"""
数据加载
"""class DataGenerator:def __init__(self, data_path, config):self.config = configself.path = data_pathself.vocab = load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.schema = load_schema(config["schema_path"])self.config["class_num"] = len(self.schema)self.load()def load(self):self.data = []with open(self.path, encoding="utf8") as f:for line in f:line = json.loads(line)#加载训练集if isinstance(line, dict):questions = line["questions"]label = line["target"]label_index = torch.LongTensor([self.schema[label]])for question in questions:input_id = self.encode_sentence(question)input_id = torch.LongTensor(input_id)self.data.append([input_id, label_index])else:assert isinstance(line, list)question, label = lineinput_id = self.encode_sentence(question)input_id = torch.LongTensor(input_id)label_index = torch.LongTensor([self.schema[label]])self.data.append([input_id, label_index])returndef encode_sentence(self, text):input_id = []if self.config["vocab_path"] == "words.txt":for word in jieba.cut(text):input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))else:for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))input_id = self.padding(input_id)return input_id#补齐或截断输入的序列,使其可以在一个batch内运算def padding(self, input_id):input_id = input_id[:self.config["max_length"]]input_id += [0] * (self.config["max_length"] - len(input_id))return input_iddef __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index]#加载字表或词表
def load_vocab(vocab_path):token_dict = {}with open(vocab_path, encoding="utf8") as f:for index, line in enumerate(f):token = line.strip()token_dict[token] = index + 1 #0留给padding位置,所以从1开始return token_dict#加载schema
def load_schema(schema_path):with open(schema_path, encoding="utf8") as f:return json.loads(f.read())#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):dg = DataGenerator(data_path, config)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dlif __name__ == "__main__":from config import Configdg = DataGenerator("valid_tag_news.json", Config)print(dg[1])主要实现一个自定义数据加载器 DataGenerator,用于加载和处理文本数据。它通过词汇表和标签映射将输入文本转化为索引序列,并进行补齐或截断。
模型构建
model.py
# -*- coding: utf-8 -*-import torch
import torch.nn as nn
from torch.optim import Adam, SGD
"""
建立网络模型结构
"""class TorchModel(nn.Module):def __init__(self, config):super(TorchModel, self).__init__()hidden_size = config["hidden_size"]vocab_size = config["vocab_size"] + 1max_length = config["max_length"]class_num = config["class_num"]self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)self.layer = nn.Linear(hidden_size, hidden_size)self.classify = nn.Linear(hidden_size, class_num)self.pool = nn.AvgPool1d(max_length)self.activation = torch.relu #relu做激活函数self.dropout = nn.Dropout(0.1)self.loss = nn.functional.cross_entropy #loss采用交叉熵损失#当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, target=None):x = self.embedding(x) #input shape:(batch_size, sen_len)x = self.layer(x) #input shape:(batch_size, sen_len, input_dim)x = self.pool(x.transpose(1,2)).squeeze() #input shape:(batch_size, sen_len, input_dim)predict = self.classify(x) #input shape:(batch_size, input_dim)if target is not None:return self.loss(predict, target.squeeze())else:return predictdef choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)定义了一个神经网络模型 TorchModel,继承自 nn.Module,用于文本分类任务。模型包括嵌入层、线性层、平均池化层和分类层,使用 ReLU 激活函数和 Dropout 防止过拟合。前向传播根据输入返回预测值或损失值(若提供标签)。choose_optimizer 函数根据配置选择 Adam 或 SGD 优化器,并设置学习率。模型通过交叉熵损失进行训练。
主程序
main.py
# -*- coding: utf-8 -*-import torch
import os
import random
import os
import numpy as np
import loggingfrom config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data, load_schemalogging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型训练主程序
"""def main(config):#创建保存模型的目录if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])#加载训练数据train_data = load_data(config["train_data_path"], config)#加载模型model = TorchModel(config)# 标识是否使用gpucuda_flag = torch.cuda.is_available()if cuda_flag:logger.info("gpu可以使用,迁移模型至gpu")model = model.cuda()#加载优化器optimizer = choose_optimizer(config, model)#加载效果测试类evaluator = Evaluator(config, model, logger)#训练for epoch in range(config["epoch"]):epoch += 1model.train()logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):optimizer.zero_grad()if cuda_flag:batch_data = [d.cuda() for d in batch_data]input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况loss = model(input_id, labels)train_loss.append(loss.item())if index % int(len(train_data) / 2) == 0:logger.info("batch loss %f" % loss)loss.backward()# print(loss.item())# print(model.classify.weight.grad)optimizer.step()logger.info("epoch average loss: %f" % np.mean(train_loss))evaluator.eval(epoch)model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)torch.save(model.state_dict(), model_path)return model, train_datadef ask(model, question):input_id = train_data.dataset.encode_sentence(question)model.eval()model = model.cpu()cls = torch.argmax(model(torch.LongTensor([input_id])))schemes = load_schema(Config["schema_path"])ans = ""for name, val in schemes.items():if val == cls:ans = namereturn ansif __name__ == "__main__":model, train_data = main(Config)print(ask(model, "积分是怎么积的"))while True:question = input("请输入问题:")res = ask(model, question)print("命中问题:", res)print("-----------")
实现一个基于 PyTorch 的文本分类模型的训练和推理过程。首先,通过 main 函数创建模型训练的主流程。代码首先检查是否有 GPU 可用,并将模型迁移至 GPU(如果可用)。然后加载训练数据、模型、优化器以及效果评估类。训练过程中,模型使用交叉熵损失函数计算训练误差并进行反向传播更新参数,每个 epoch 后记录并输出平均损失。同时,训练结束后,将模型保存至指定路径。
在训练完成后,ask 函数用于推理,输入问题并通过模型进行预测。它首先将输入问题转化为模型所需的格式,然后利用训练好的模型进行分类,最后返回匹配的答案。整个程序支持通过命令行输入问题,模型根据训练结果给出对应的答案。
在主程序中,首先进行一次初始化训练,之后进入循环,可以持续输入问题并得到模型的预测答案。
测试与评估
evaluate.py
# -*- coding: utf-8 -*-
import torch
from loader import load_data"""
模型效果测试
"""class Evaluator:def __init__(self, config, model, logger):self.config = configself.model = modelself.logger = loggerself.valid_data = load_data(config["valid_data_path"], config, shuffle=False)self.stats_dict = {"correct":0, "wrong":0} #用于存储测试结果def eval(self, epoch):self.logger.info("开始测试第%d轮模型效果:" % epoch)self.stats_dict = {"correct":0, "wrong":0} #清空前一轮的测试结果self.model.eval()for index, batch_data in enumerate(self.valid_data):if torch.cuda.is_available():batch_data = [d.cuda() for d in batch_data]input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况with torch.no_grad():pred_results = self.model(input_id) #不输入labels,使用模型当前参数进行预测self.write_stats(labels, pred_results)self.show_stats()returndef write_stats(self, labels, pred_results):assert len(labels) == len(pred_results)for true_label, pred_label in zip(labels, pred_results):pred_label = torch.argmax(pred_label)if int(true_label) == int(pred_label):self.stats_dict["correct"] += 1else:self.stats_dict["wrong"] += 1returndef show_stats(self):correct = self.stats_dict["correct"]wrong = self.stats_dict["wrong"]self.logger.info("预测集合条目总量:%d" % (correct +wrong))self.logger.info("预测正确条目:%d,预测错误条目:%d" % (correct, wrong))self.logger.info("预测准确率:%f" % (correct / (correct + wrong)))self.logger.info("--------------------")return定义一个 Evaluator 类,用于评估深度学习模型在验证集上的表现。Evaluator 初始化时接受配置文件、模型和日志记录器,并加载验证数据。eval 方法用于进行模型评估,在每轮评估开始时清空统计信息,设置模型为评估模式,然后通过遍历验证数据集进行预测。预测结果通过 write_stats 方法与真实标签进行比对,统计正确和错误的预测条目。最后,show_stats 方法输出总预测条目数、正确条目数、错误条目数以及准确率。该类的作用是帮助监控模型在验证集上的性能,便于调整和优化模型。
测试结果
请输入问题:在官网上如何修改移动密码
命中问题: 移动密码修改
-----------
请输入问题:我想多加一个号码作为亲情号
命中问题: 亲情号码设置与修改
-----------
请输入问题:我已经交足了话费请立即帮我开机
命中问题: 话费查询
-----------
请输入问题:密码想换一下
命中问题: 密码修改
相关文章:

Day08 【基于jieba分词实现词嵌入的文本多分类】
基于jieba分词的文本多分类 目标数据准备参数配置数据处理模型构建主程序测试与评估测试结果 目标 本文基于给定的词表,将输入的文本基于jieba分词分割为若干个词,然后将词基于词表进行初步编码,之后经过网络层,输出在已知类别标…...

BERT、T5、ViT 和 GPT-3 架构概述及代表性应用
BERT、T5、ViT 和 GPT-3 架构概述 1. BERT(Bidirectional Encoder Representations from Transformers) 架构特点 基于 Transformer 编码器:BERT 使用多层双向 Transformer 编码器,能够同时捕捉输入序列中每个词的左右上下文信息…...
倚光科技:以创新之光,雕琢全球领先光学设计公司
在光学技术飞速发展的当下,每一次突破都可能为众多领域带来变革性的影响。而倚光(深圳)科技有限公司,作为光学设计公司的一颗璀璨之星,正以其卓越的创新能力和深厚的技术底蕴,引领着光学设计行业的发展潮流…...

数据结构(六)——红黑树及模拟实现
目录 前言 红黑树的概念及性质 红黑树的效率 红黑树的结构 红黑树的插入 变色不旋转 单旋变色 双旋变色 插入代码如下所示: 红黑树的查找 红黑树的验证 红黑树代码如下所示: 小结 前言 在前面的文章我们介绍了AVL这一棵完全二叉搜索树&…...
】家政平台安全“攻防战”:渗透测试全解析)
【家政平台开发(48)】家政平台安全“攻防战”:渗透测试全解析
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化,测试阶段多维度保障平台质量,…...

Python爬虫-爬取全球股市涨跌幅和涨跌额数据
前言 本文是该专栏的第52篇,后面会持续分享python爬虫干货知识,记得关注。 本文中,笔者将基于Python爬虫,实现批量采集全球股市行情(亚洲,美洲,欧非,其他等)的各股市“涨跌幅”以及“涨跌额”数据。 具体实现思路和详细逻辑,笔者将在正文结合完整代码进行详细介绍。…...

解决 Vue 中 input 输入框被赋值后,无法再修改和编辑的问题
目录 需求: 出现 BUG: Bug 代码复现 解决问题: 解决方法1: 解决方法2 关于 $set() 的补充: 需求: 前段时间,接到了一个需求:在选择框中选中某个下拉菜单时,对应的…...
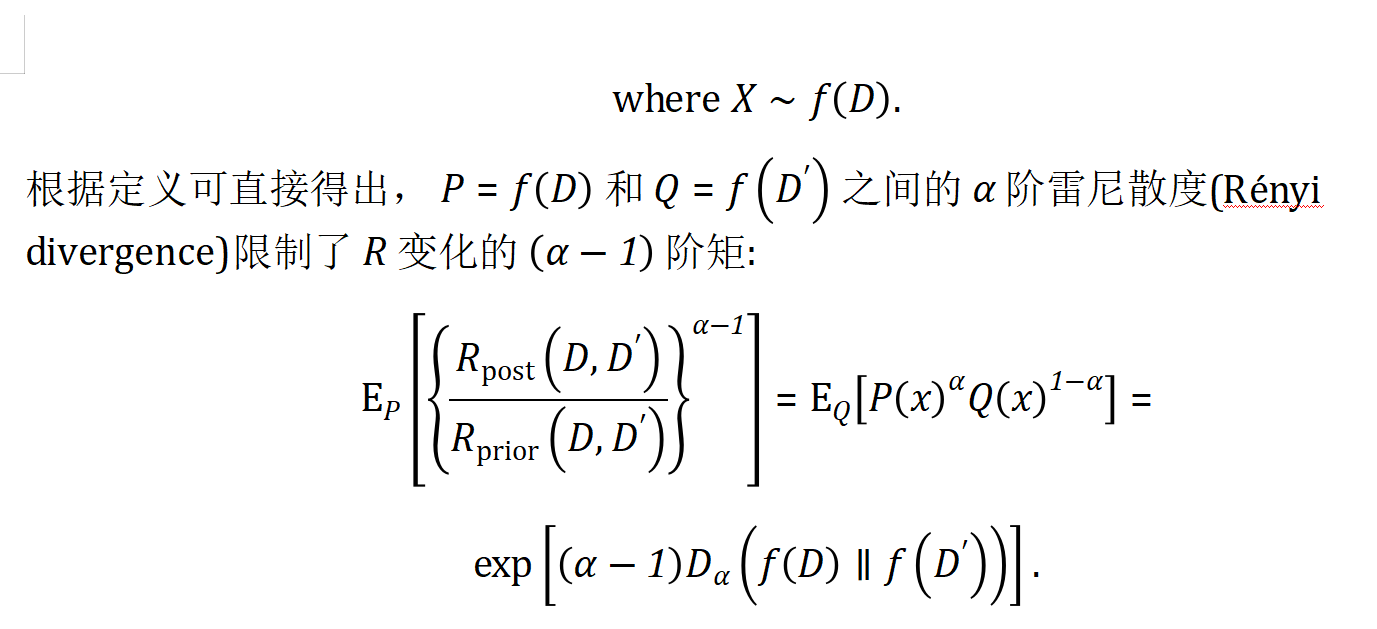
【差分隐私相关概念】瑞丽差分隐私(RDP)-瑞丽散度约束了贝叶斯因子后验变化
分步解释和答案: 在Rnyi差分隐私(RDP)框架中,通过贝叶斯因子和Rnyi散度的关系可以推导出关于后验变化的概率保证。以下是关键步骤的详细解释: 1. 贝叶斯因子的定义与分解 设相邻数据集 D D D 和 D ′ D D′&#x…...

vue3 onMounted 使用方法和注意事项
基础用法 / 语法糖写法 <script> import { onMounted } from vue;// 选项式 API 写法 export default {setup() {onMounted(() > {console.log(组件已挂载);});} } </script><script setup> onMounted(() > {console.log(组件已挂载); }); </scrip…...

Dockerfile 文件常见命令及其作用
Dockerfile 文件包含一系列命令语句,用于定义 Docker 镜像的内容、配置和构建过程。以下是一些常见的命令及其作用: FROM:指定基础镜像,后续的操作都将基于该镜像进行。例如,FROM python:3.9-slim-buster 表示使用 Pyt…...
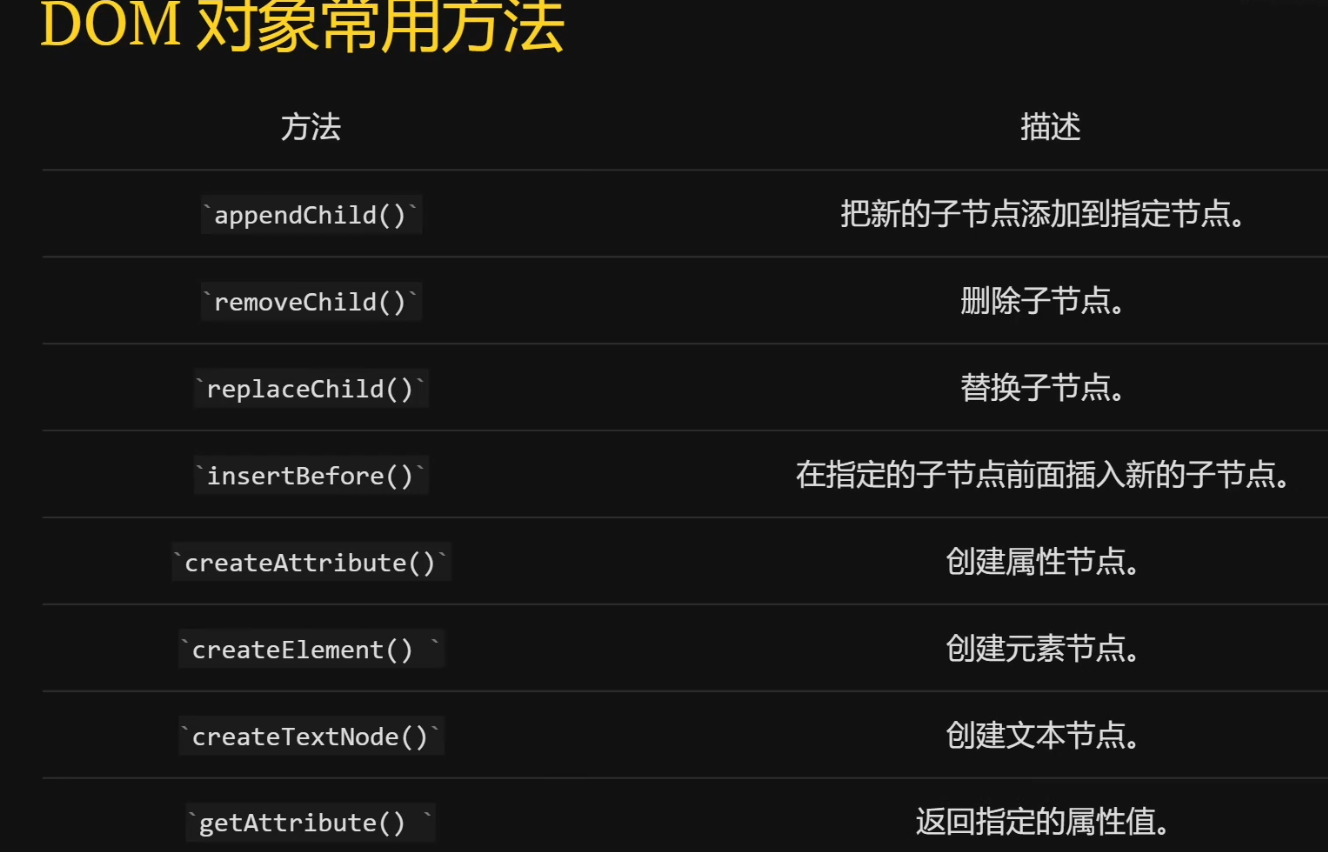
前端快速入门——JavaScript函数、DOM
1.JavaScript函数 函数是一段可重复使用的代码块,它接受输入(参数)、执行特定任务,并返回输出。 <scricpt>function add(a,b){return ab;}let cadd(5,10);console.log(c); </script>2.JavaScript事件 JavaScript绑定事件的方法࿱…...

shell 编程之循环语句
目录 一、for 循环语句 二、while 循环语句 三、until 循环语句 四、总结扩展 1. 循环对比 2. 调试技巧 3. 易混淆点解析 4. 进阶技巧 一、for 循环语句 1. 基础概念 含义: 用于 遍历一个已知的列表,逐个执行同一组命令 核心作用:…...

10【模块学习】LCD1602(二):6路温度显示+实时时钟
项目:6路温度显示实时时钟 1、6路温度显示①TempMenu.c文件的代码②TempMenu.h文件的代码③main.c文件的代码④Timer.c文件的代码⑤Delay.c文件的代码⑥Key.c文件的代码 2、实时时钟显示①BeiJingTime.c文件的代码②BeiJingTime.h文件的代码③main.c文件的代码如下④…...

Linux基础14
一、搭建LAMP平台 安装包:mariadb-server、php、php-mysqlnd、php-xml、php-json 搭建平台步骤: php步骤: 创建网页:index.php 网页内编写php语言: > eg:<?p…...

PDF处理控件Aspose.PDF指南:使用 C# 从 PDF 文档中删除页面
需要从 PDF 文档中删除特定页面?本快速指南将向您展示如何仅用几行代码删除不需要的页面。无论您是清理报告、跳过空白页,还是在共享前自定义文档,C# 都能让 PDF 操作变得简单高效。学习如何以编程方式从 PDF 文档中选择和删除特定页面&#…...

如何在不同版本的 Elasticsearch 之间以及集群之间迁移数据
作者:来自 Elastic Kofi Bartlett 当你想要升级一个 Elasticsearch 集群时,有时候创建一个新的独立集群并将数据从旧集群迁移到新集群会更容易一些。这让用户能够在不冒任何停机或数据丢失风险的情况下,在新集群上使用所有应用程序测试其所有…...

Vue3生命周期钩子详解
Vue 3 的生命周期钩子函数允许开发者在组件不同阶段执行特定逻辑。与 Vue 2 相比,Vue 3 在 Composition API 中引入了新名称,并废弃了部分钩子。以下是详细说明: 一、Vue 3 生命周期阶段与钩子函数 1. 组件创建阶段 setup() 替代 Vue 2 的 b…...

Day08【基于预训练模型分词器实现交互型文本匹配】
基于预训练模型分词器实现交互型文本匹配 目标数据准备参数配置数据处理模型构建主程序测试与评估总结 目标 本文基于预训练模型bert分词器BertTokenizer,将输入的文本以文本对的形式,送入到分词器中得到文本对的词嵌入向量,之后经过若干网络…...

npm和npx的作用和区别
npx 和 npm 是 Node.js 生态系统中两个常用的工具,它们有不同的作用和使用场景。 1. npm(Node Package Manager) 作用: npm 是 Node.js 的包管理工具,主要用于: 安装、卸载、更新项目依赖(包&a…...

mysql按条件三表并联查询
下面为你呈现一个 MySQL 按条件三表并联查询的示例。假定有三个表:students、courses 和 enrollments,它们的结构和关联如下: students 表:包含学生的基本信息,有 student_id 和 student_name 等字段。courses 表&…...
C++学习之金融类安全传输平台项目git
目录 1.知识点概述 2.版本控制工具作用 3.git和SVN 4.git介绍 5.git安装 6.工作区 暂存区 版本库概念 7.本地文件添加到暂存区和提交到版本库 8.文件的修改和还原 9.查看提交的历史版本信息 10.版本差异比较 11.删除文件 12.本地版本管理设置忽略目录 13.远程git仓…...

CCF CSP 第36次(2024.12)(1_移动_C++)
CCF CSP 第36次(2024.12)(1_移动_C) 解题思路:思路一: 代码实现代码实现(思路一): 时间限制: 1.0 秒 空间限制: 512 MiB 原题链接 解题思路&…...
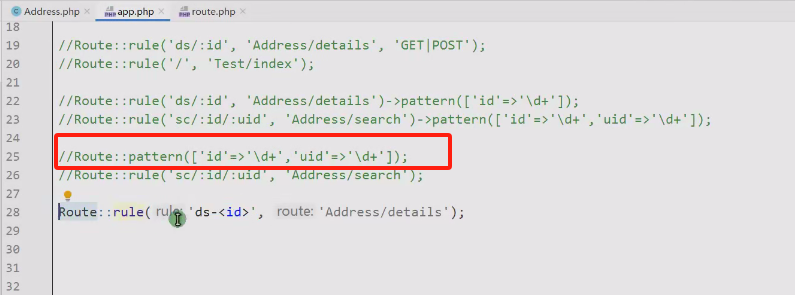
7.thinkphp的路由
一.路由简介 1. 路由的作用就是让URL地址更加的规范和优雅,或者说更加简洁; 2. 设置路由对URL的检测、验证等一系列操作提供了极大的便利性; 3. 路由是默认开启的,如果想要关闭路由,在config/app.php配置…...

Browser-use 是连接你的AI代理与浏览器的最简单方式
AI MCP 系列 AgentGPT-01-入门介绍 Browser-use 是连接你的AI代理与浏览器的最简单方式 AI MCP(大模型上下文)-01-入门介绍 AI MCP(大模型上下文)-02-awesome-mcp-servers 精选的 MCP 服务器 AI MCP(大模型上下文)-03-open webui 介绍 是一个可扩展、功能丰富且用户友好的…...

(五)机器学习---决策树和随机森林
在分类问题中还有一个常用算法:就是决策树。本文将会对决策树和随机森林进行介绍。 目录 一.决策树的基本原理 (1)决策树 (2)决策树的构建过程 (3)决策树特征选择 (4࿰…...

【项目管理】第16章 项目采购管理-- 知识点整理
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应&…...

2025年4月15日 百度一面 面经
目录 1. 代理相关 从静态代理到动态代理 2. cglib可以代理被final修饰的类吗,为什么 3. JVM 体系结构 4. 垃圾回收算法 5. 什么是注解 如何使用 底层原理 6. synchronized和reentrantlock 7. 讲一下你项目中 redis的分布式锁 与java自带的锁有啥区别 8. post 请求和 ge…...
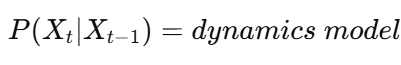
从图像“看出动作”
📘 第一部分:运动估计(Motion Estimation) 🧠 什么是运动估计? 简单说: 👉 给你一段视频,计算机要“看懂”里面什么东西动了、往哪动了、有多快。 比如: 一…...

鸿蒙案例---生肖抽卡
案例源码: Zodiac_cards: 鸿蒙生肖抽奖卡片 效果演示 初始布局 1. Badge 角标组件 此处为语雀内容卡片,点击链接查看:https://www.yuque.com/kevin-nzthp/lvl039/rccg0o4pkp3v6nua 2. Grid 布局 // 定义接口 interface ImageCount {url:…...
)
达梦数据库-学习-18-ODBC数据源配置(Linux)
一、环境信息 名称值CPU12th Gen Intel(R) Core(TM) i7-12700H操作系统CentOS Linux release 7.9.2009 (Core)内存4G逻辑核数2DM版本1 DM Database Server 64 V8 2 DB Version: 0x7000c 3 03134284194-20240703-234060-20108 4 Msg Versi…...