Kaggle-Disaster Tweets-(二分类+NLP+模型融合)
Disaster Tweets
题意:
就是给出一个dataframe包含text这一列代表着文本,文本会有一些词,问对于每条记录中的text是真关于灾难的还是假关于灾难的。
比如我们说今天作业真多,这真是一场灾难。实际上这个灾难只是我们调侃而言的。
数据处理:
1.首先要将文本转化为模型可以接受的数据。建立vectorizer将文本转换为词频矩阵,先fit训练数据,然后把这个vectorizer再应用到test数据上,这样才能保证测试数据和训练数据的一致性。
2.拆分训练集合和验证集合,对下面模型融合进行评估。
建立模型:
1.逻辑归回模型LogisticRegression,设置本模型的网格搜索参数,对lr进行超参数优化。
2.随机森林模型RandomForestClassifier,设置本模型的网格搜索参数,对rf进行超参数优化。
3.xgboost模型XGBClassifier,设置本模型的网格搜索参数,对xgb进行超参数优化。
4.投票模型融合,把三个算法的最佳参数下的模型进行融合训练,求出预测分数。只是把某个答案出现次数最多的作为答案。
5.加权模型融合,只是在投票模型的基础上,为每个模型分配一个权重。
6.堆叠模型融合,把三个模型输出答案作为次级模型的输入,再进行训练,预测出结果。逻辑回归模型会学习如何结合基模型的预测概率,以更准确地预测样本的类别。
例如,模型可能会学习到:
当基模型1和基模型3的预测概率较高时,样本更可能属于类别1。
当基模型2的预测概率较高时,样本更可能属于类别0。
代码:
import sys
import pandas as pd
from sklearn.ensemble import RandomForestClassifier, VotingClassifier, StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import feature_extraction, model_selection
from sklearn.model_selection import GridSearchCV
from xgboost import XGBClassifierif __name__ == '__main__':#数据处理data_train = pd.read_csv('/kaggle/input/nlp-getting-started/train.csv')data_test = pd.read_csv('/kaggle/input/nlp-getting-started/test.csv')vectorizer = feature_extraction.text.CountVectorizer()X_train = vectorizer.fit_transform(data_train['text'])Y_train = data_train['target']X_test = vectorizer.transform(data_test['text'])X_train,X_val,Y_train,Y_val = model_selection.train_test_split(X_train,Y_train,test_size=0.2,random_state=42)#lr模型lr_param_grid = {'penalty': ['l1', 'l2', 'elasticnet', None], #指定正则化类型,用于防止模型过拟合。# 'C': [0.001, 0.01, 0.1, 1, 10, 100], #正则化强度的倒数,值越小表示正则化越强。# 'solver': ['liblinear', 'saga'], #指定用于求解逻辑回归参数的优化算法。# 'class_weight': [None, 'balanced'] #指定类别权重,用于处理类别不平衡问题。}lr_model = GridSearchCV(estimator = LogisticRegression(random_state=42), #对什么模型进行搜索超参数param_grid = lr_param_grid, #超参数的候选值scoring = 'accuracy', #使用准确率作为评估指标cv = 3, #使用3折交叉验证n_jobs = -1, #使用所有cpu并行运算)lr_model.fit(X_train, Y_train)print('lr预测分数:' + str(lr_model.score(X_val, Y_val)))#rf模型rf_param_grid = {'n_estimators': [50, 100, 200], #树的数量# 'max_depth': [None, 10, 20, 30], #树的最大深度# 'min_samples_split': [2, 5, 10], #节点分裂所需的最小样本数# 'min_samples_leaf': [1, 2, 4], #叶节点所需的最小样本数# 'max_features': ['auto', 'sqrt', 'log2'], #找最佳分裂时考虑的最大特征数# 'bootstrap': [True, False] #否使用有放回抽样构建树}rf_model = GridSearchCV(estimator=RandomForestClassifier(random_state=42), # 对什么模型进行搜索超参数param_grid=rf_param_grid, # 超参数的候选值scoring='accuracy', # 使用准确率作为评估指标cv=3, # 使用3折交叉验证n_jobs=-1, # 使用所有cpu并行运算)rf_model.fit(X_train, Y_train)print('rf预测分数:' + str(rf_model.score(X_val, Y_val)))#xgb模型xgb_param_grid = {'n_estimators': [50, 100, 200], #树的数量# 'max_depth': [3, 4, 5, 6], #树的最大深度# 'learning_rate': [0.01, 0.1, 0.2], #学习速率# 'subsample': [0.8, 1.0], #指定每次迭代中用于训练每棵树的数据比例# 'colsample_bytree': [0.8, 1.0], #指定每次迭代中用于训练每棵树的特征比例# 'gamma': [0, 0.1, 0.2], #最小损失减少值# 'min_child_weight': [1, 3, 5], #子节点所需的最小样本权重和# 'reg_alpha': [0, 0.1, 1], #控制模型的正则化强度# 'reg_lambda': [0, 0.1, 1] #控制模型的正则化强度}xgb_model = GridSearchCV(estimator = XGBClassifier(random_state=42), #对什么模型进行搜索超参数param_grid = xgb_param_grid, #超参数的候选值scoring = 'accuracy', #使用准确率作为评估指标cv = 3, #使用3折交叉验证n_jobs = -1, #使用所有cpu并行运算)xgb_model.fit(X_train,Y_train)print('xgb预测分数:' + str(xgb_model.score(X_val, Y_val)))lr_best = lr_model.best_estimator_rf_best = rf_model.best_estimator_xgb_best = xgb_model.best_estimator_#投票模型融合voting_model = VotingClassifier(estimators=[('lr', lr_best), ('rf', rf_best), ('xgb', xgb_best)],voting='soft' # 使用预测概率的平均值)voting_model.fit(X_train, Y_train)print('投票模型融合预测分数:' + str(voting_model.score(X_val, Y_val)))#加权投票模型融合lr_score = lr_model.score(X_val,Y_val)rf_score = rf_model.score(X_val,Y_val)xgb_score = xgb_model.score(X_val,Y_val)total_score = lr_score + rf_score + xgb_scoreweights = [lr_score / total_score, rf_score / total_score, xgb_score / total_score]weighted_voting_model = VotingClassifier(estimators=[('lr', lr_best), ('rf', rf_best), ('xgb', xgb_best)],voting='soft',weights=weights)weighted_voting_model.fit(X_train, Y_train)print('加权模型融合预测分数:' + str(weighted_voting_model.score(X_val, Y_val)))#堆叠模型融合stacking_model = StackingClassifier(estimators = [('lr', lr_best), ('rf', rf_best), ('xgb', xgb_best)],final_estimator=LogisticRegression(),cv=3 # 使用3折交叉验证生成元模型的训练数据)stacking_model.fit(X_train, Y_train)print('堆叠模型融合预测分数:' + str(stacking_model.score(X_val, Y_val)))Submission = pd.DataFrame({'id': data_test['id'],'target': stacking_model.predict(X_test)})Submission.to_csv('/kaggle/working/Submission.csv', index=False)
相关文章:
)
Kaggle-Disaster Tweets-(二分类+NLP+模型融合)
Disaster Tweets 题意: 就是给出一个dataframe包含text这一列代表着文本,文本会有一些词,问对于每条记录中的text是真关于灾难的还是假关于灾难的。 比如我们说今天作业真多,这真是一场灾难。实际上这个灾难只是我们调侃而言的。…...

搭建一个网站需要选择什么配置的服务器?
一般要考虑网站规模、技术需求等因素来进行选择。 小型网站:个人博客、小型企业官网等日均量在 1000 以内的网站,一般推荐2 核 CPU、4GB 内存、50GB 硬盘,带宽 1 - 5M。如果是纯文字内容且图片较少的小型网站,初始阶段 1 核 CPU、…...

idea如何使用git
在 IntelliJ IDEA 中使用 Git 的详细步骤如下,分为配置、基础操作和高级功能,适合新手快速上手: 一、配置 Git 安装 Git 下载并安装 Git,安装时勾选“Add to PATH”。验证安装:终端输入 git --version 显示版本…...

webpack vite
1、webpack webpack打包工具(重点在于配置和使用,原理并不高优。只在开发环境应用,不在线上环境运行),压缩整合代码,让网页加载更快。 前端代码为什么要进行构建和打包? 体积更好&#x…...
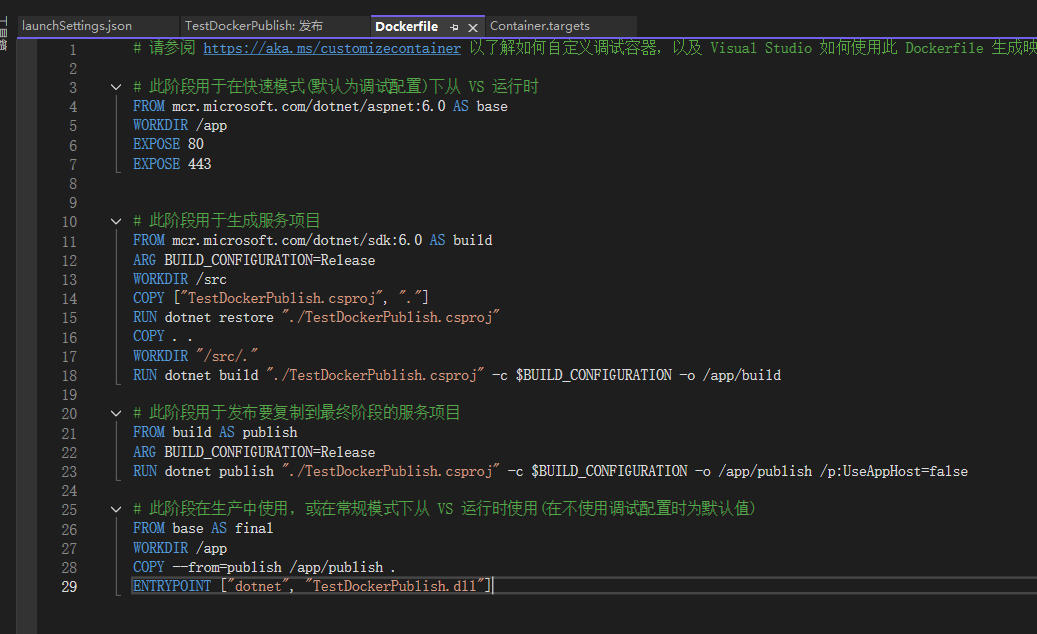
.Net 9 webapi使用Docker部署到Linux
参考文章连接: https://www.cnblogs.com/kong-ming/p/16278109.html .Net 6.0 WebApi 使用Docker部署到Linux系统CentOS 7 - 长白山 - 博客园 项目需要跨平台部署,所以就研究了一下菜鸟如何入门Net跨平台部署,演示使用的是Net 9 webAPi Li…...
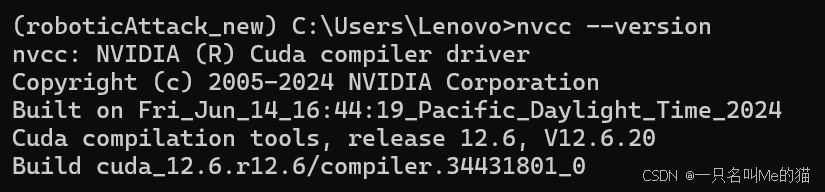
PyTorch 根据官网命令行无法安装 GPU 版本 解决办法
最近遇到一个问题,PyTorch 官网给出了 GPU 版本的安装命令,但安装成功后查看版本,仍然是 torch 2.6.0cpu 1. 清理现有 PyTorch 安装 经过探索发现,需要同时卸载 conda 和 pip 安装的 torch。 conda remove pytorch torchvision …...

PHP防火墙代码,防火墙,网站防火墙,WAF防火墙,PHP防火墙大全
PHP防火墙代码,防火墙,网站防火墙,WAF防火墙,PHP防火墙大全 资源宝整理分享:https://www.htple.net PHP防火墙(作者:悠悠楠杉) 验证测试,链接后面加上?verify_cs1后可以自行测试 <?php //复制保存zzwaf.php$we…...
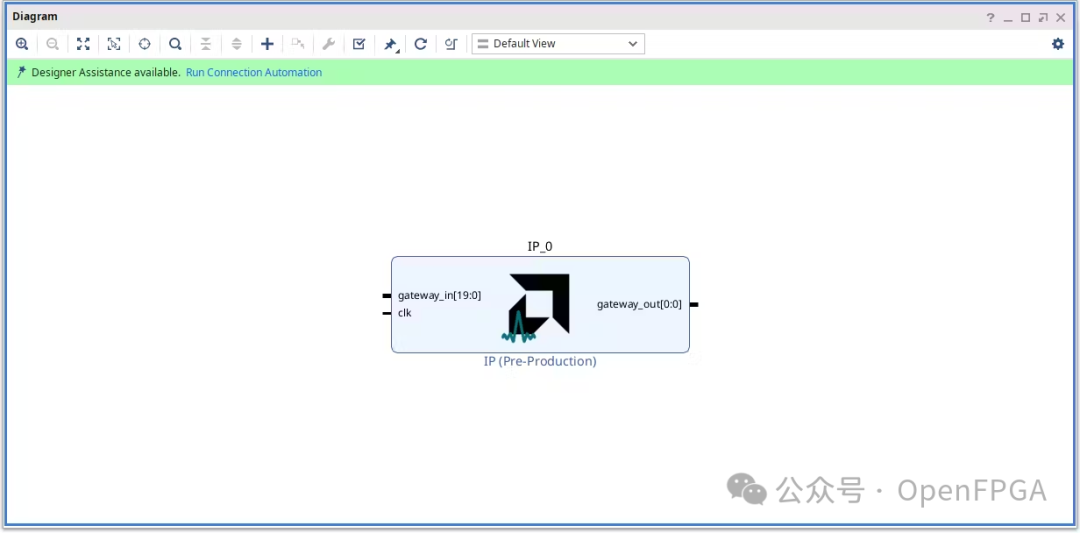
使用 Vitis Model Composer 生成 FPGA IP 核
本文将逐步介绍如何使用 Vitis Model Composer 生成 FPGA IP 核,从建模到部署。 在当今快节奏的世界里,技术正以前所未有的速度发展,FPGA 设计也不例外。高级工具层出不穷,加速着开发进程。传统上,FPGA 设计需要使用硬…...

Day08 【基于jieba分词实现词嵌入的文本多分类】
基于jieba分词的文本多分类 目标数据准备参数配置数据处理模型构建主程序测试与评估测试结果 目标 本文基于给定的词表,将输入的文本基于jieba分词分割为若干个词,然后将词基于词表进行初步编码,之后经过网络层,输出在已知类别标…...

BERT、T5、ViT 和 GPT-3 架构概述及代表性应用
BERT、T5、ViT 和 GPT-3 架构概述 1. BERT(Bidirectional Encoder Representations from Transformers) 架构特点 基于 Transformer 编码器:BERT 使用多层双向 Transformer 编码器,能够同时捕捉输入序列中每个词的左右上下文信息…...
倚光科技:以创新之光,雕琢全球领先光学设计公司
在光学技术飞速发展的当下,每一次突破都可能为众多领域带来变革性的影响。而倚光(深圳)科技有限公司,作为光学设计公司的一颗璀璨之星,正以其卓越的创新能力和深厚的技术底蕴,引领着光学设计行业的发展潮流…...

数据结构(六)——红黑树及模拟实现
目录 前言 红黑树的概念及性质 红黑树的效率 红黑树的结构 红黑树的插入 变色不旋转 单旋变色 双旋变色 插入代码如下所示: 红黑树的查找 红黑树的验证 红黑树代码如下所示: 小结 前言 在前面的文章我们介绍了AVL这一棵完全二叉搜索树&…...
】家政平台安全“攻防战”:渗透测试全解析)
【家政平台开发(48)】家政平台安全“攻防战”:渗透测试全解析
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化,测试阶段多维度保障平台质量,…...

Python爬虫-爬取全球股市涨跌幅和涨跌额数据
前言 本文是该专栏的第52篇,后面会持续分享python爬虫干货知识,记得关注。 本文中,笔者将基于Python爬虫,实现批量采集全球股市行情(亚洲,美洲,欧非,其他等)的各股市“涨跌幅”以及“涨跌额”数据。 具体实现思路和详细逻辑,笔者将在正文结合完整代码进行详细介绍。…...

解决 Vue 中 input 输入框被赋值后,无法再修改和编辑的问题
目录 需求: 出现 BUG: Bug 代码复现 解决问题: 解决方法1: 解决方法2 关于 $set() 的补充: 需求: 前段时间,接到了一个需求:在选择框中选中某个下拉菜单时,对应的…...
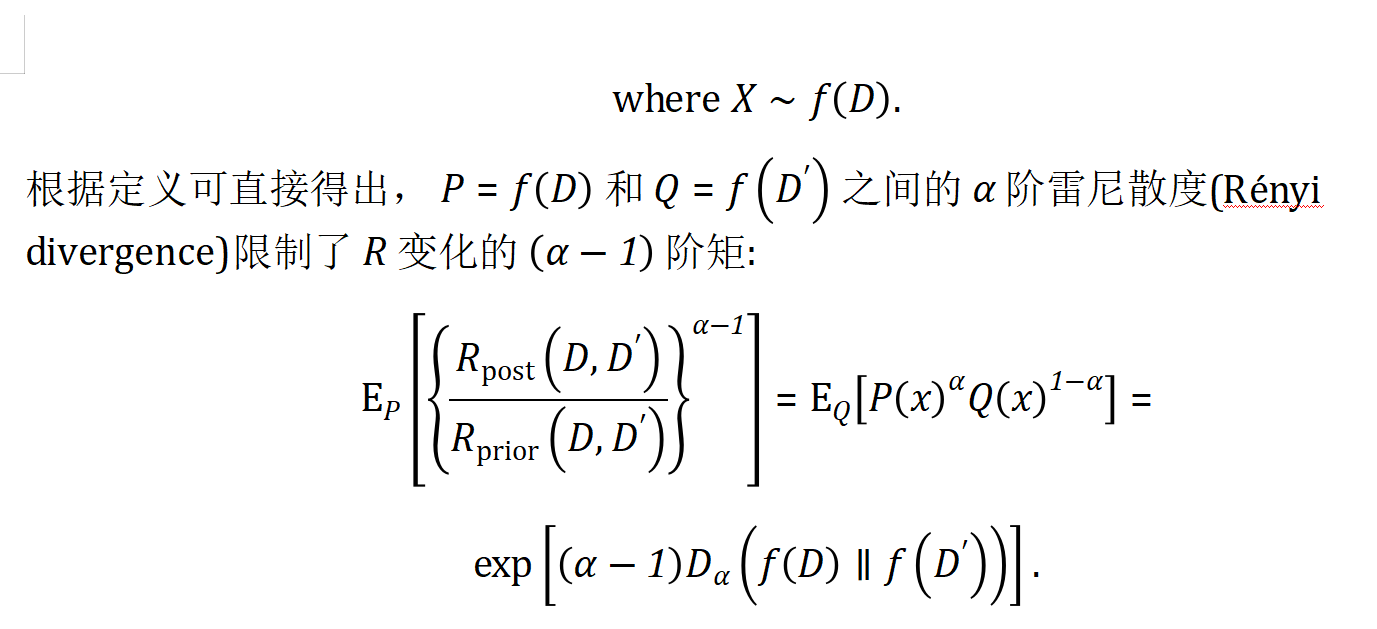
【差分隐私相关概念】瑞丽差分隐私(RDP)-瑞丽散度约束了贝叶斯因子后验变化
分步解释和答案: 在Rnyi差分隐私(RDP)框架中,通过贝叶斯因子和Rnyi散度的关系可以推导出关于后验变化的概率保证。以下是关键步骤的详细解释: 1. 贝叶斯因子的定义与分解 设相邻数据集 D D D 和 D ′ D D′&#x…...

vue3 onMounted 使用方法和注意事项
基础用法 / 语法糖写法 <script> import { onMounted } from vue;// 选项式 API 写法 export default {setup() {onMounted(() > {console.log(组件已挂载);});} } </script><script setup> onMounted(() > {console.log(组件已挂载); }); </scrip…...

Dockerfile 文件常见命令及其作用
Dockerfile 文件包含一系列命令语句,用于定义 Docker 镜像的内容、配置和构建过程。以下是一些常见的命令及其作用: FROM:指定基础镜像,后续的操作都将基于该镜像进行。例如,FROM python:3.9-slim-buster 表示使用 Pyt…...
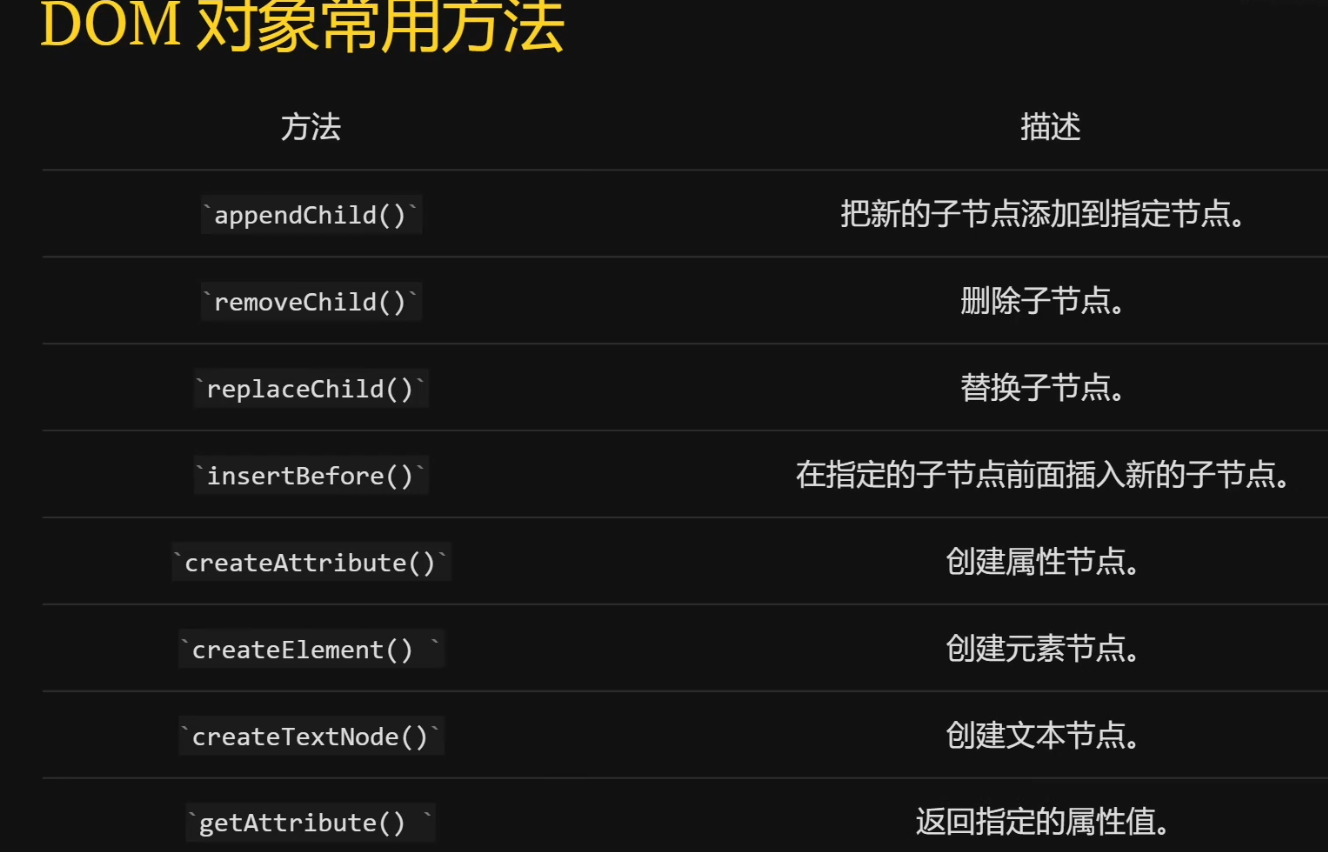
前端快速入门——JavaScript函数、DOM
1.JavaScript函数 函数是一段可重复使用的代码块,它接受输入(参数)、执行特定任务,并返回输出。 <scricpt>function add(a,b){return ab;}let cadd(5,10);console.log(c); </script>2.JavaScript事件 JavaScript绑定事件的方法࿱…...

shell 编程之循环语句
目录 一、for 循环语句 二、while 循环语句 三、until 循环语句 四、总结扩展 1. 循环对比 2. 调试技巧 3. 易混淆点解析 4. 进阶技巧 一、for 循环语句 1. 基础概念 含义: 用于 遍历一个已知的列表,逐个执行同一组命令 核心作用:…...

10【模块学习】LCD1602(二):6路温度显示+实时时钟
项目:6路温度显示实时时钟 1、6路温度显示①TempMenu.c文件的代码②TempMenu.h文件的代码③main.c文件的代码④Timer.c文件的代码⑤Delay.c文件的代码⑥Key.c文件的代码 2、实时时钟显示①BeiJingTime.c文件的代码②BeiJingTime.h文件的代码③main.c文件的代码如下④…...

Linux基础14
一、搭建LAMP平台 安装包:mariadb-server、php、php-mysqlnd、php-xml、php-json 搭建平台步骤: php步骤: 创建网页:index.php 网页内编写php语言: > eg:<?p…...

PDF处理控件Aspose.PDF指南:使用 C# 从 PDF 文档中删除页面
需要从 PDF 文档中删除特定页面?本快速指南将向您展示如何仅用几行代码删除不需要的页面。无论您是清理报告、跳过空白页,还是在共享前自定义文档,C# 都能让 PDF 操作变得简单高效。学习如何以编程方式从 PDF 文档中选择和删除特定页面&#…...

如何在不同版本的 Elasticsearch 之间以及集群之间迁移数据
作者:来自 Elastic Kofi Bartlett 当你想要升级一个 Elasticsearch 集群时,有时候创建一个新的独立集群并将数据从旧集群迁移到新集群会更容易一些。这让用户能够在不冒任何停机或数据丢失风险的情况下,在新集群上使用所有应用程序测试其所有…...

Vue3生命周期钩子详解
Vue 3 的生命周期钩子函数允许开发者在组件不同阶段执行特定逻辑。与 Vue 2 相比,Vue 3 在 Composition API 中引入了新名称,并废弃了部分钩子。以下是详细说明: 一、Vue 3 生命周期阶段与钩子函数 1. 组件创建阶段 setup() 替代 Vue 2 的 b…...

Day08【基于预训练模型分词器实现交互型文本匹配】
基于预训练模型分词器实现交互型文本匹配 目标数据准备参数配置数据处理模型构建主程序测试与评估总结 目标 本文基于预训练模型bert分词器BertTokenizer,将输入的文本以文本对的形式,送入到分词器中得到文本对的词嵌入向量,之后经过若干网络…...

npm和npx的作用和区别
npx 和 npm 是 Node.js 生态系统中两个常用的工具,它们有不同的作用和使用场景。 1. npm(Node Package Manager) 作用: npm 是 Node.js 的包管理工具,主要用于: 安装、卸载、更新项目依赖(包&a…...

mysql按条件三表并联查询
下面为你呈现一个 MySQL 按条件三表并联查询的示例。假定有三个表:students、courses 和 enrollments,它们的结构和关联如下: students 表:包含学生的基本信息,有 student_id 和 student_name 等字段。courses 表&…...
C++学习之金融类安全传输平台项目git
目录 1.知识点概述 2.版本控制工具作用 3.git和SVN 4.git介绍 5.git安装 6.工作区 暂存区 版本库概念 7.本地文件添加到暂存区和提交到版本库 8.文件的修改和还原 9.查看提交的历史版本信息 10.版本差异比较 11.删除文件 12.本地版本管理设置忽略目录 13.远程git仓…...

CCF CSP 第36次(2024.12)(1_移动_C++)
CCF CSP 第36次(2024.12)(1_移动_C) 解题思路:思路一: 代码实现代码实现(思路一): 时间限制: 1.0 秒 空间限制: 512 MiB 原题链接 解题思路&…...