一、LLM 大语言模型初窥:起源、概念与核心原理
一、初识大模型
1.1 人工智能演进与大模型兴起:从A11.0到A12.0的变迁
AI 1.0时代(2012-2022年)
感知智能的突破:以卷积神经网络(CNN)为核心,AI在图像识别、语音处理等感知任务中超越人类水平。例如,2012年AlexNet在ImageNet竞赛中取得突破性胜利,推动计算机视觉技术在各行业落地。
技术局限性:模型碎片化严重,依赖人工标注数据且泛化能力不足,导致应用成本高昂。例如,医疗领域需针对不同病种单独训练模型,形成数据孤岛。
AI 2.0时代(2022年至今)
大模型范式革命:基于Transformer架构的预训练大模型(如GPT-3、BERT)崛起,通过海量无标注数据自监督学习通用知识,实现“预训练+微调”的跨领域能力。例如,GPT-3的1750亿参数模型在零样本学习任务中展现强大适应性。
多模态与逻辑推理:模型从单一文本向多模态融合进化,如OpenAI的Sora(2024年)实现文本生成视频,展现物理世界模拟能力;GPT-4o(2025年)支持实时多模态交互,增强逻辑链生成能力。
1.2 应用场景的跃迁:从工具赋能到生态重构
垂直领域深度渗透
行业大模型兴起:金融、医疗等领域通过微调基础模型实现专业化。例如,DeepSeek-V3(2025年)通过MoE架构降低算力需求,加速企业部署;工商银行利用大模型构建智能风控系统,欺诈识别准确率显著提升。
生产力工具革新:生成式AI(AIGC)重构内容生产流程,如智能编程助手(GitHub Copilot)、低代码开发平台等,软件开发效率提升30%。
终端智能化普及
端侧设备升级:AI手机、AIPC等终端设备搭载轻量化模型,实现本地化推理。例如,AIPC需40TOPS算力支持本地多模态交互,AI手机通过边缘计算保障隐私与实时性。
人机交互新范式:ChatGPT(2022年)引爆自然语言交互革命,智能体(Agent)逐步具备规划、记忆和主动行动能力,如Project Astra(2025年)实现上下文感知与任务规划。
1.3 生态系统的重构:开源共享与分布式创新
开源生态爆发:DeepSeek-V3(2025年)成为首个全开源大模型,推动技术共享;中国备案生成式模型达300余个,占全球36%。
分布式训练突破:混合专家模型(MoE)、检索增强生成(RAG)等技术降低训练成本,例如某模型推理成本降至三十分之一,2025年分布式训练有望加速模型迭代3倍。
政策与标准建设:中国《生成式AI服务管理暂行办法》(2023年)规范应用边界,欧盟《人工智能法案》强化伦理约束,全球技术竞争与治理体系同步推进。
1.4 挑战与隐忧:技术狂飙下的平衡
算力与能耗:训练GPT-3耗电1.287吉瓦时,相当于120个美国家庭年用电量,绿色AI技术(如液冷数据中心)成研发重点
数据安全与偏见:大规模语料隐含文化偏见,需通过外挂知识库和规则约束减少“幻觉”;端侧隐私保护依赖联邦学习等技术
伦理与可控性:模型可解释性(XAI)成为核心课题,例如联合嵌入预测(JEPA)架构增强决策透明性,RLHF(人类反馈强化学习)机制优化价值对齐
1.5 未来趋势:从AI 2.0向AGI的演进
认知流体化:多模态模型整合传感器数据,实现“具身智能”,如人形机器人自主决策、工业质检系统实时优化生产流程
自监督学习深化:利用未标注数据提升通用性,减少对人类知识体系的依赖,例如蛋白质结构预测模型AlphaFold2(2021年)推动突破
生态融合与普惠化:2027年预计超50%生成式AI为垂直领域模型,AI技术渗透率从互联网向制造业、农业等传统产业扩展,成为数字文明的基础设施
1.6 总结
从AI 1.0到AI 2.0的变迁,本质是技术从“专用工具”向“通用智能平台”的质变。大模型通过参数规模、模态融合与训练效率的突破,重构了技术范式、产业生态与人机关系。未来,AI将不仅是效率工具,更是推动社会生产力跃迁的核心引擎,其发展需在技术创新与伦理治理间寻求动态平衡。
二、大模型核心原理
2.1 生成式模型与大语言模型
什么是生成式模型
生成式模型是一类能够通过算法学习数据分布,并基于此生成新数据的人工智能技术。它的核心在于从已有数据中提取模式,创造出与训练数据相似但全新的内容,涵盖文本、图像、音频、视频等多种模态。例如,生成对抗网络(GAN)可生成逼真图像,而扩散模型(Diffusion Model)擅长生成高质量的多模态内容。
技术特点
1. 多模态生成能力:支持跨模态内容生成(如文本生成图像、音频生成视频)。
2. 创新性输出:生成的内容可能在现实中没有直接对应(如抽象艺术画作)。
3. 模型多样性:包括GAN、VAE(变分自编码器)、扩散模型等架构。
典型应用
- 图像生成(DALL-E、Midjourney)
- 音乐创作(AIVA、Jukedeck)
- 视频合成(RunwayML)
什么是大语言模型
大语言模型是生成式模型的一个子类,专注于自然语言处理任务。它通过海量文本数据训练,学习语言的语法、语义和逻辑,具备文本生成、理解、推理等能力,典型代表包括GPT系列、BERT和LLaMA。
技术特点
- 参数规模庞大:通常包含数十亿至数万亿参数,捕捉复杂的语言规律。
- 通用性与适应性:通过微调可应用于翻译、问答、摘要等多种任务。
- Transformer架构:依赖自注意力机制处理长距离依赖关系。
典型应用
- 智能对话(ChatGPT)
- 代码生成(GitHub Copilot)
- 知识问答与信息检索
二者的区别与联系
| 维度 | 生成式模型 | 大语言模型 |
|---|---|---|
| 范围 | 涵盖多模态(文本、图像、音频等) | 专注于文本领域 |
| 技术架构 | GAN、VAE、扩散模型等 | Transformer架构为主 |
| 生成目标 | 创造全新内容,强调创新性 | 生成连贯、符合语境的文本 |
| 数据需求 | 多模态数据(如图像-文本对) | 大规模文本语料 |
| 应用场景 | 艺术创作、虚拟现实、广告设计 | 客服、翻译、文本辅助 |
技术基础重叠:
- 大语言模型本质上是生成式模型在文本领域的特化,两者均依赖深度学习和概率建模。
- Transformer架构既是LLM的核心,也被用于生成式模型的文本生成模块。
互补性应用:
- 在复杂任务中可结合使用(如用LLM生成剧本,生成式模型生成配套视频)。
- 生成式AI的多模态能力可扩展LLM的应用边界(如文本生成图像后进一步生成视频)。
训练与优化共性:
- 均需大规模算力与数据,依赖分布式训练技术(如混合专家模型MoE)。
- 面临相似挑战:数据偏见、能耗问题、伦理监管
2.2 Transformer 架构解析
为什么会用到Transformer
-
解决传统模型的不足
- RNN/CNN的缺陷:传统循环神经网络(RNN/LSTM)和卷积神经网络(CNN)在处理长序列时存在局限性:
- 无法并行计算:RNN需按顺序处理序列,计算效率低;
- 长距离依赖问题:难以捕捉序列中相隔较远的依赖关系(如长文本中的上下文关联)。
- 注意力机制的优势:Transformer完全基于注意力机制,摒弃了循环和卷积结构,通过自注意力(Self-Attention)直接建模序列中全局依赖关系,显著提升长序列处理能力。
- RNN/CNN的缺陷:传统循环神经网络(RNN/LSTM)和卷积神经网络(CNN)在处理长序列时存在局限性:
-
并行计算能力
- Transformer 的自注意力机制允许所有位置的计算同时进行,避免了序列处理的串行化,大幅加速训练和推理,尤其适合大规模数据和模型。
-
泛化性和高效性
- 在自然语言处理(NLP)、计算机视觉(CV)等领域表现优异:
- NLP:如 ChatGPT、BERT 等模型通过 Transformer 实现高质量翻译、文本生成;
- CV:如 Swin Transformer(窗口化自注意力)在图像识别中平衡效率与性能;
- 其他领域:时间序列去噪、材料科学(CrystalTransformer)等场景均受益于其序列建模能力。
- 在自然语言处理(NLP)、计算机视觉(CV)等领域表现优异:
什么是 Transformer
Transformer 是一种基于注意力机制的深度学习架构,由 Vaswani 等人在 2017 年提出(论文《Attention Is All You Need》)。其核心思想是:
- 完全依赖注意力机制,无需循环或卷积结构。
- 编码器-解码器结构:
- 编码器:将输入序列(如文本、图像块)转换为中间表示。
- 解码器:根据编码器的输出生成目标序列(如翻译结果)。
- 关键组件:
- 自注意力(Self-Attention):捕捉序列内部元素间的全局依赖关系;
- 位置编码(Positional Encoding):为无序的注意力机制补充序列位置信息;
- 前馈网络(FFN):对每个位置的特征进行独立变换。
Transformer 架构宏观解析
1. 核心结构:编码器-解码器
-
编码器(Encoder):
- 子层:
- 自注意力层(Self-Attention Layer):计算序列中每个元素与其他元素的相关性,生成加权特征;
- 前馈网络(FFN):对每个位置的特征进行非线性变换,增强表达能力。
- 层级堆叠:通常堆叠多层(如 6 层),每层参数独立,逐层提取更抽象的特征。
- 子层:
-
解码器(Decoder):
- 子层:
- 自注意力层:处理目标序列(如翻译中的目标语言句子),确保生成的序列符合语法;
- 编码器-解码器注意力层(Encoder-Decoder Attention):关注编码器输出中与当前解码位置相关的信息(如源语言中对应的部分);
- 前馈网络(FFN):进一步优化特征。
- 掩码机制:在解码过程中屏蔽未来信息,确保生成过程的顺序性。
- 子层:
2. 关键技术细节
-
自注意力机制:
- 通过计算 Query、Key、Value 的点积注意力权重,动态加权所有位置的输入,捕捉长距离依赖。
- 多头注意力(Multi-Head Attention):并行计算多个子空间的注意力,提升模型对不同位置关系的建模能力。
-
位置编码:
- 由于注意力机制本身不包含位置信息,需通过可学习或固定的位置编码(如正弦函数)补充序列顺序。
-
层级化设计:
- 如 Swin Transformer 引入 窗口化自注意力(Window-based Self-Attention) 和 移位窗口机制,在视觉任务中平衡计算效率与局部特征建模。
2.3 关键技术解析
预训练
定义与目标
预训练是通过大规模无标注数据训练模型,使其学习语言或图像的通用特征、统计规律和基础能力(如语法、语义、视觉模式等)。它是后续任务适应的基础。
关键流程与技术细节
-
数据准备:
- 数据来源:互联网文本(如新闻、书籍、论坛)、图像库(如ImageNet)等。
- 数据清洗:去除噪声、重复内容、隐私信息,确保数据质量。
- 格式化处理:文本分词、编码(如Token化),图像归一化、增强等。
-
模型架构:
- 常用架构:Transformer(如BERT、GPT)、CNN(如ResNet)等。
- 参数规模:通常较大(如百亿级参数),以捕捉复杂模式。
-
训练目标:
- 自监督学习任务:
- 语言模型(LM)任务:如掩码语言模型(MLM,预测被遮蔽的词)或因果语言模型(CLM,预测下一个词)。
- 图像任务:如图像重建、对比学习(Contrastive Learning)。
- 无监督学习:通过数据自身生成伪标签,减少对标注数据的依赖。
- 自监督学习任务:
-
训练策略:
- 使用大规模计算资源(如GPU/TPU集群)。
- 监控训练过程,防止过拟合,确保模型泛化能力。
特点与优势
- 数据效率:依赖海量无标注数据,成本低但训练时间长。
- 迁移能力:预训练模型可迁移到多种下游任务(如文本分类、图像识别)。
- 基础能力:为后续监督微调(SFT)和强化学习(RLHF)提供初始参数和特征表示。
监督微调 SFT(Supervised Fine-tuning)
定义与目标
SFT是基于预训练模型,在特定任务的标注数据上进一步优化模型,使其适应具体任务(如问答、翻译、图像生成)。目标是提升模型在特定场景下的性能。
关键流程与技术细节
-
数据准备:
- 标注数据:需高质量的“输入-输出”对(如指令-响应对)。例如,人类专家或高质量LLM生成的示范回答。
- 数据多样性:覆盖任务的多个方面,避免过拟合。
-
模型选择:
- 使用预训练的通用模型(如BERT、GPT、ResNet)作为基础。
-
微调策略:
- 学习率调整:通常采用较小的学习率,避免破坏预训练参数。
- 批量大小与轮数:根据任务调整,平衡收敛速度与效果。
- 正则化:如Dropout、L2正则化,防止过拟合。
- 早停(Early Stopping):监控验证集性能,提前终止训练。
-
任务适配:
- NLP任务:文本分类、机器翻译、问答系统。
- CV任务:图像分类、目标检测、图像生成。
- 多模态任务:结合文本和图像的联合训练(如文生图)。
特点与优势
- 任务针对性:直接优化特定任务的性能。
- 数据依赖:需要标注数据,但规模远小于预训练数据。
- 局限性:标注成本高,且依赖标注数据的质量。
基于人类反馈的强化学习 RLHF(Reinforcement Learning from Human Feedback)
定义与目标
RLHF通过人类偏好反馈优化模型,使其生成内容更符合人类价值观(如安全性、有用性、伦理)。目标是解决SFT的局限性,提升模型的“对齐”能力。
关键流程与技术细节
-
阶段划分:
- 步骤1:监督微调(SFT):生成初步的对齐模型(如ChatGPT的SFT模型)。
- 步骤2:奖励模型(RM)训练:
- 数据收集:用SFT模型生成多个候选响应,由人类对响应进行排名或评分。
- RM训练:将分类模型(如SFT模型)的输出层替换为回归层,学习从输入-响应对中预测人类偏好分数。
- 步骤3:强化学习优化:
- 算法:使用近端策略优化(PPO)等算法,最大化奖励信号的期望值。
- 流程:
- 输入提示生成多个候选响应。
- RM为每个响应打分。
- 根据分数更新模型参数,使高分响应概率最大化。
-
关键技巧:
- KL散度约束:限制模型更新幅度,避免偏离SFT阶段的稳定表现。
- 多轮迭代:反复生成、评估、优化,逐步提升模型对齐效果。
- 多维度奖励:RM可同时评估事实性、无害性、流畅性等多维度指标(如DeepSeek的RM设计)。
-
实际应用:
- 对话系统:生成安全、有帮助的回复(如ChatGPT)。
- 图像生成:提升文生图的美学和图文匹配度(如Seedream 2.0通过RLHF优化PE模型)。
特点与优势
- 人类价值观对齐:直接通过人类反馈优化模型行为。
- 数据效率:相比SFT,标注成本更低(排名比生成更高效)。
- 灵活性:可扩展到多模态任务(如图像、文本联合优化)。
三、大模型应用场景
1. 自然语言处理(NLP)
- 文本生成
- 应用场景:创作小说、新闻、剧本,智能写作辅助工具生成初稿。
- 示例:通过GPT类模型生成连贯文本,如代码生成、对话系统。
- 机器翻译
- 应用场景:跨语言实时翻译(如商务交流、多语言内容生成)。
- 示例:使用Transformer架构的MarianMT模型实现高质量翻译。
- 问答系统
- 应用场景:智能客服、虚拟助手(如企业咨询、知识库问答)。
- 示例:DeepSeek大模型赋能的“青易问·云客服”提升政务服务交互体验。
2. 医疗领域
- 辅助诊断
- 应用场景:分析医疗影像(X光、CT)辅助病变检测,结合病史文本提供诊断建议。
- 示例:腾讯与迈瑞医疗联合开发的“启元重症大模型”,将医生工作效率提升超30倍。
- 药物研发
- 应用场景:预测药物分子结构、作用机制及副作用,加速研发流程。
- 示例:通过分析海量医学文献,缩短药物研发周期。
- 健康管理
- 应用场景:提供个性化健康建议、慢性病管理。
- 示例:医疗咨询数字人降低人工客服成本。
3. 金融领域
- 风险评估与信用评级
- 应用场景:分析财务数据、交易记录,评估贷款风险。
- 示例:DeepSeek模型优化信贷决策流程。
- 智能投顾与投资决策
- 应用场景:分析市场数据预测趋势,提供投资组合建议。
- 示例:结合新闻、财报数据辅助投资。
- 反欺诈与合规风控
- 应用场景:实时检测交易欺诈,构建知识库支持合规操作。
- 示例:容联云通过大模型优化反欺诈质检系统。
4. 教育领域
- 个性化学习
- 应用场景:动态生成学习路径,针对知识盲区强化训练。
- 示例:DeepSeek自适应学习系统使知识吸收效率提升40%。
- 智能辅导与资源生成
- 应用场景:自动批改作业、生成教学资源。
- 示例:希沃大模型将教师备课时间从2小时缩短至30分钟,批改作业效率提升30%。
- 课堂互动
- 应用场景:实时反馈学生学习效果,生成个性化报告。
- 示例:希沃课堂智能反馈系统已生成超15万份报告。
5. 工业与制造业
- 生产优化与质检
- 应用场景:提升生产线效率、降低能耗。
- 示例:里工实业的自动化生产线效率提升30%,成本降低40%-60%;纺织印染企业效率提升33%。
- 供应链管理
- 应用场景:预测需求、优化库存调度。
- 示例:机智云质检方案在纺织行业节约30%人工成本。
- 安全生产
- 应用场景:实时监测风险,减少事故。
- 示例:远正智能的铝加工安全管理平台降低53%安全事件报警。
6. 安全与应急
- 风险预警与救援
- 应用场景:灾害现场态势感知、机器人救援。
- 示例:安全大模型24小时运营,减少92%手动操作。
- 行为识别
- 应用场景:识别违规操作,预防安全事故。
- 示例:工业领域的安全行为识别系统。
7. 传媒与娱乐
- 内容生成与推荐
- 应用场景:生成新闻摘要、短视频脚本,个性化内容推荐。
- 示例:商汤“日日新V6”可分析《黑神话》游戏视频生成高光片段及解说。
- 虚拟数字人
- 应用场景:虚拟主播、客服、教育助手。
- 示例:中国电信的数字人生成技术实现高精度人物复刻和全流式交互。
8. 能源与环保
- 需求预测与生产优化
- 应用场景:优化电网调度、提高可再生能源利用率。
- 示例:大模型预测风电、光伏波动,辅助电网平衡。
- 碳排放管理
- 应用场景:追踪碳足迹,优化减排路径。
- 示例:华能利用大模型提升清洁能源生产效率。
9. 政务与公共服务
- 智能审批与咨询
- 应用场景:简化行政审批流程,提升服务效率。
- 示例:青岛“边聊边办”AI场景将建筑许可审批交互体验升级。
四、Prompt 提示词
4.1 提示词工程基础
什么是提示词(Prompt)
- 定义:提示词是用户输入给AI模型(如大语言模型)的指令或问题,用于引导模型生成符合预期的输出。它是人与AI交互的桥梁,直接影响结果的质量。
- 核心功能:
- 明确任务(如“写一篇关于全球变暖的文章”);
- 提供上下文(如背景信息、格式要求);
- 指导输出形式(如语言风格、结构)。
- 示例:
“请以环境科学家的身份,为政策制定者撰写一份关于可持续发展的报告,涵盖能源管理和废弃物处理,要求语言简洁、数据详实。”
什么是提示工程
- 定义:提示工程是通过设计、优化和调整提示词,最大化AI模型(如ChatGPT、GitHub Copilot)潜力的过程,确保输出准确、相关且符合用户需求。
- 核心目标:
- 提升输出质量(减少歧义、提高准确性);
- 充分利用模型能力(如逻辑推理、创意生成);
- 降低交互成本(减少反复调整的次数)。
- 方法论:
- 结构化提示框架(如RTF框架:角色、任务、格式);
- 迭代优化(根据模型反馈调整提示词);
- 结合示例或模板(通过示例明确输出要求)。
Prompt的典型构成要素
- 指令(Instruction):
- 明确的任务描述,如“分析用户反馈中的核心诉求”或“生成Python函数”。
- 上下文(Context):
- 背景信息或约束条件,如“以初中生水平讲解量子力学”或“参考《Python编程入门》第3章”。
- 输出指示(Format/Expectation):
- 格式要求(如表格、Markdown);
- 风格或内容限制(如“使用口语化中文,避免专业术语”)。
设置Prompt的通用技巧
- 明确性原则:
- 避免模糊指令(如“写一篇好文章”→“写一篇300字的科普文章,解释气候变化对极地动物的影响”);
- 使用具体动词(如“分析”“比较”“生成”)。
- 结构化设计:
- 分解任务:将复杂问题拆解为子任务(如“先总结数据,再提出解决方案”);
- 框架应用:采用RTF框架(角色、任务、格式)或CAST框架(约束、受众、规格)。
- 上下文与示例增强:
- 提供背景信息(如“用户是新手程序员,需代码注释详细”);
- 通过示例引导(如“请按以下格式列出步骤:1. ... 2. ...”)。
4.2 Prompt 调优
Prompt 调优的定义与目标
Prompt 调优 是通过优化输入给大模型的提示词(Prompt),提升模型输出的准确性、一致性和质量的过程。其核心目标是:
- 解决模型输出问题:如回答不一致、复杂任务处理能力差、对特殊表达识别不准确等。
- 最大化模型能力:通过结构化设计、示例引导、约束条件等,让模型更高效地完成任务。
- 降低人工干预成本:减少反复调整提示词的迭代次数,提升交互效率。
Prompt 调优的核心问题
常见问题包括:
- 回答准确性不足:模型对规则或约束的理解不一致(如客服礼貌用语判断错误)。
- 复杂问题处理不稳定:多步骤任务易出现逻辑跳跃或遗漏关键信息。
- 特殊表达识别不一致:模型对不同表达方式(如口语化、专业术语)的适应性差。
- 输出格式或风格不统一:模型生成的内容不符合用户指定的格式或风格要求。
Prompt 调优的递进式步骤
1. 初步调优:提升基础准确性
- 方法:将模糊的口语化提示转化为 结构化提示,明确规则和约束。
- 示例:
- 原始提示:
“客服回答中是否使用了礼貌用语?” - 调优后提示:
## 请根据以下标准判断对话是否合规: - 客服是否使用了“请问”或类似的礼貌用语。 - 客服是否避免使用命令式语气。 - 客服是否表达了对客户问题的关心。
- 原始提示:
2. 进一步调优:解决复杂问题
- 方法:通过 分步骤引导 和 示例驱动,让模型逐步处理复杂任务。
- 示例:
- 任务:编写一个用户注册接口。
- 优化提示:
请按以下步骤完成任务: 1. 校验请求参数必须包含 `email` 和 `password`。 2. 密码长度需大于6,否则返回 HTTP 400。 3. 使用一致的 JSON 响应格式:`{ "status": "success/error", "message": str }`。 4. 添加数据库插入逻辑的伪代码。
3. 高级调优:强化模型能力
- 方法:结合 In-Context Learning (ICL) 和 元提示(Meta-Prompting),提升模型的推理和泛化能力。
- 示例:
- ICL 示例:
提供多个示例帮助模型理解任务,例如:**任务**:执行算术运算 **示例**: 输入:2 + 3 → 输出:5 输入:(2 + 3) * 4 → 输出:20 **当前问题**:输入:(7 - 3) * 2 → 输出:?
- ICL 示例:
Prompt 调优的关键技巧
1. 结构化设计
- 明确指令:使用 RTF框架(Role, Task, Format)或 CAST框架(Constraint, Audience, Specification)。
- 示例:
# 任务:生成一份春节主题的社交媒体文章 **角色**:社交媒体文案撰写者 **任务**:创作一篇500字左右、温馨风格的春节主题文章 **格式**:包含标题、3个段落,每段以节日习俗为例说明家庭团聚的重要性 **约束**:避免使用专业术语,语言口语化
2. 示例驱动(ICL)
- 方法:通过 正例 和 反例 明确输出要求。
- 示例:
**任务**:判断客服回答是否合规 **正例**: 输入:“请问您需要进一步帮助吗?” → 输出:合规 **反例**: 输入:“快点说清楚你的问题!” → 输出:不合规(命令式语气)
3. 明确约束与格式
- 约束条件:限制输出的字数、风格或逻辑(如接口开发的安全要求)。
- 格式指示:要求模型以列表、表格或代码块形式输出(如代码生成任务)。
4. 分步骤引导
- 方法:将复杂任务拆解为子任务,逐步引导模型完成。
- 示例:
**任务**:解决数学问题 1. 理解问题:明确已知条件和目标。 2. 分析问题:选择适用的公式或原理。 3. 计算过程:分步推导并验证。 4. 得出结论:总结答案并检查合理性。
相关文章:

一、LLM 大语言模型初窥:起源、概念与核心原理
一、初识大模型 1.1 人工智能演进与大模型兴起:从A11.0到A12.0的变迁 AI 1.0时代(2012-2022年) 感知智能的突破:以卷积神经网络(CNN)为核心,AI在图像识别、语音处理等感知任务中超越人类水平。例如&#…...

PyTorch核心函数详解:gather与where的实战指南
PyTorch中的torch.gather和torch.where是处理张量数据的关键工具,前者实现基于索引的灵活数据提取,后者完成条件筛选与动态生成。本文通过典型应用场景和代码演示,深入解析两者的工作原理及使用技巧,帮助开发者提升数据处理的灵活…...

《Operating System Concepts》阅读笔记:p636-p666
《Operating System Concepts》学习第 58 天,p636-p666 总结,总计 31 页。 一、技术总结 1.system and network threats (1)attack network traffic (2)denial of service (3)port scanning 2.symmetric/asymmetric encryption algorithm (1)symm…...
Go:接口
接口既约定 Go 语言中接口是抽象类型 ,与具体类型不同 ,不暴露数据布局、内部结构及基本操作 ,仅提供一些方法 ,拿到接口类型的值 ,只能知道它能做什么 ,即提供了哪些方法 。 func Fprintf(w io.Writer, …...

ESP32+Arduino入门(三):连接WIFI获取当前时间
ESP32内置了WIFI模块连接WIFI非常简单方便。 代码如下: #include <WiFi.h>const char* ssid "WIFI名称"; const char* password "WIFI密码";void setup() {Serial.begin(115200);WiFi.begin(ssid,password);while(WiFi.status() ! WL…...

FastAPI用户认证系统开发指南:从零构建安全API
前言 在现代Web应用开发中,用户认证系统是必不可少的功能。本文将带你使用FastAPI框架构建一个完整的用户认证系统,包含注册、登录、信息更新和删除等功能。我们将采用JWT(JSON Web Token)进行身份验证,并使用SQLite作…...
CSS高度坍塌?如何解决?
一、什么是高度坍塌? 高度坍塌(Collapsing Margins)是指当父元素没有设置边框(border)、内边距(padding)、内容(content)或清除浮动时,其子元素的 margin 会…...

【数据结构】之散列
一、定义与基本术语 (一)、定义 散列(Hash)是一种将键(key)通过散列函数映射到一个固定大小的数组中的技术,因为键值对的映射关系,散列表可以实现快速的插入、删除和查找操作。在这…...
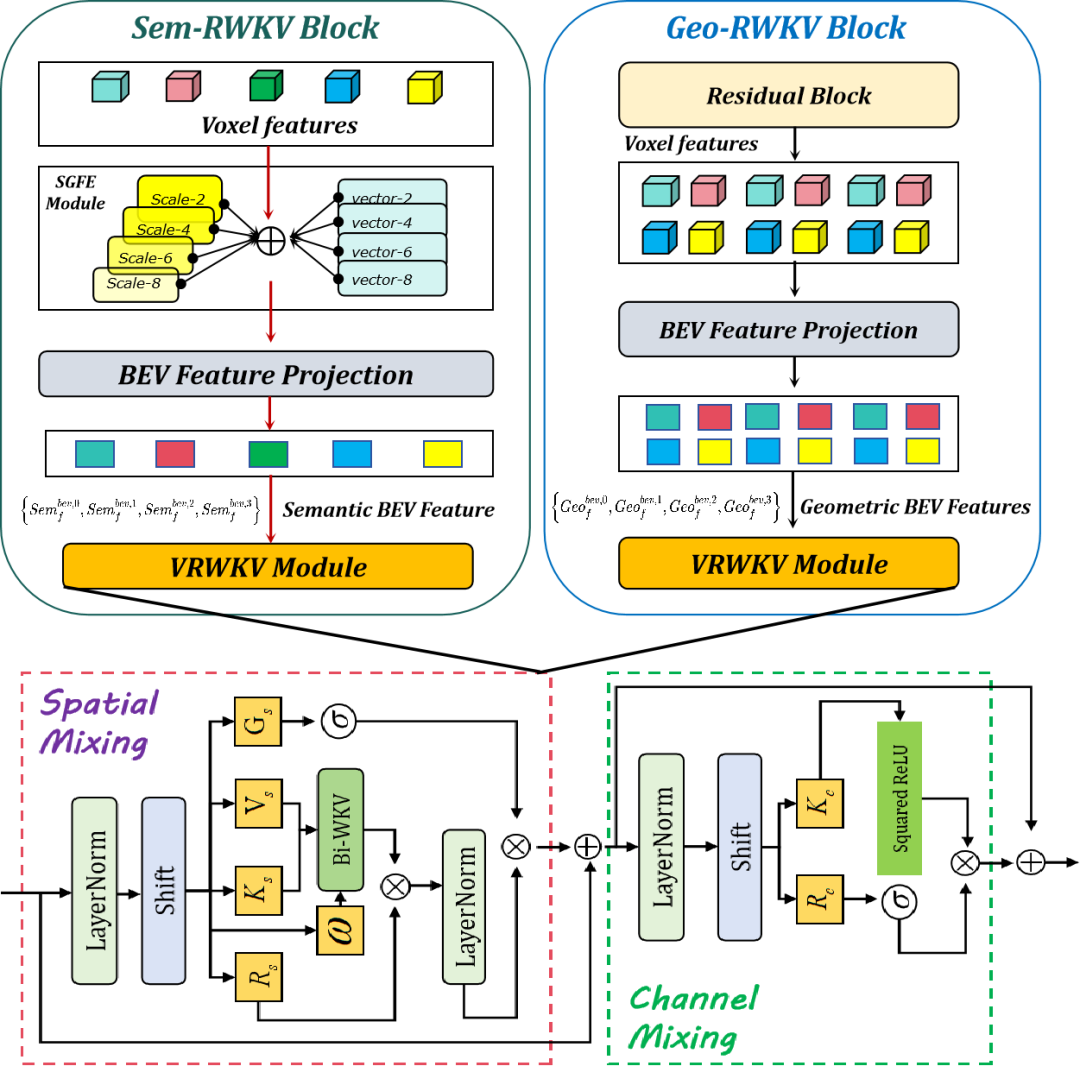
空地机器人在复杂动态环境下,如何高效自主导航?
随着空陆两栖机器人(AGR)在应急救援和城市巡检等领域的应用范围不断扩大,其在复杂动态环境中实现自主导航的挑战也日益凸显。对此香港大学王俊铭基于阿木实验室P600无人机平台自主搭建了一整套空地两栖机器人,使用Prometheus开源框架完成算法的仿真验证与…...
:Python 中 Lambda函数详解)
python小记(十二):Python 中 Lambda函数详解
Python 中 Lambda函数详解 Lambda函数详解:从入门到实战一、什么是Lambda函数?二、Lambda的核心语法与特点1. 基础语法2. 与普通函数对比 三、Lambda的六大应用场景(附代码示例)1. 基本数学运算2. 列表排序与自定义规则3. 数据映射…...
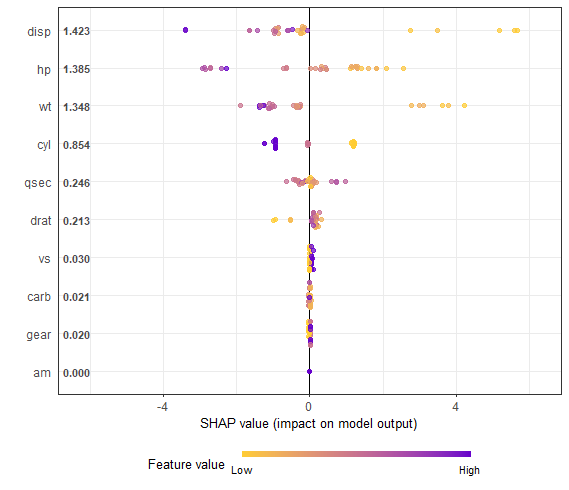
第二十一讲 XGBoost 回归建模 + SHAP 可解释性分析(利用R语言内置数据集)
下面我将使用 R 语言内置的 mtcars 数据集,模拟一个完整的 XGBoost 回归建模 SHAP 可解释性分析 实战流程。我们将以预测汽车的油耗(mpg)为目标变量,构建 XGBoost 模型,并用 SHAP 来解释模型输出。 🚗 示例…...
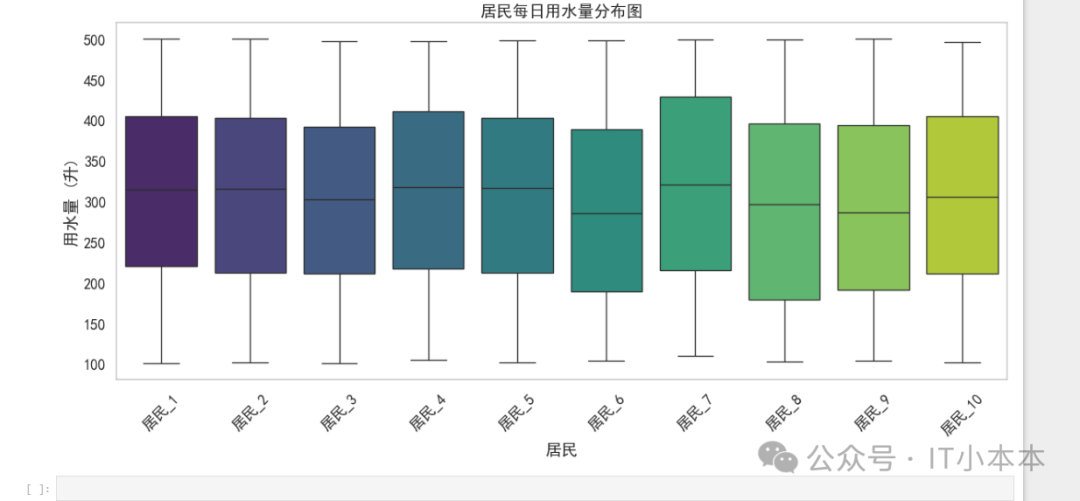
数据分析实战案例:使用 Pandas 和 Matplotlib 进行居民用水
原创 IT小本本 IT小本本 2025年04月15日 18:31 北京 本文将使用 Matplotlib 及 Seaborn 进行数据可视化。探索如何清理数据、计算月度用水量并生成有价值的统计图表,以便更好地理解居民的用水情况。 数据处理与清理 读取 Excel 文件 首先,我们使用 pan…...

Asp.NET Core WebApi 创建带鉴权机制的Api
构建一个包含 JWT(JSON Web Token)鉴权的 Web API 是一种常见的做法,用于保护 API 端点并验证用户身份。以下是一个基于 ASP.NET Core 的完整示例,展示如何实现 JWT 鉴权。 1. 创建 ASP.NET Core Web API 项目 使用 .NET CLI 或 …...

hash.
Redis 自身就是键值对结构 Redis 自身的键值对结构就是通过 哈希 的方式来组织的 哈希类型中的映射关系通常称为 field-value,用于区分 Redis 整体的键值对(key-value), 注意这里的 value 是指 field 对应的值,不是键…...
记录鸿蒙应用上架应用未配置图标的前景图和后景图标准要求尺寸1024px*1024px和标准要求尺寸1024px*1024px
审核报错【①应用未配置图标的前景图和后景图,标准要求尺寸1024px*1024px且需下载HUAWEI DevEco Studio 5.0.5.315或以上版本进行图标再处理、②应用在展开状态下存在页面左边距过大的问题, 应用在展开状态下存在页面右边距过大的问题, 当前页面左边距: 504 px, 当前页面右边距…...

golang-常见的语法错误
https://juejin.cn/post/6923477800041054221 看这篇文章 Golang 基础面试高频题详细解析【第一版】来啦~ 大叔说码 for-range的坑 func main() { slice : []int{0, 1, 2, 3} m : make(map[int]*int) for key, val : range slice {m[key] &val }for k, v : …...

Google最新《Prompt Engineering》白皮书全解析
近期有幸拿到了Google最新发布的《Prompt Engineering》白皮书,这是一份由Lee Boonstra主笔,Michael Sherman、Yuan Cao、Erick Armbrust、Antonio Gulli等多位专家共同贡献的权威性指南,发布于2025年2月。今天我想和大家分享这份68页的宝贵资…...
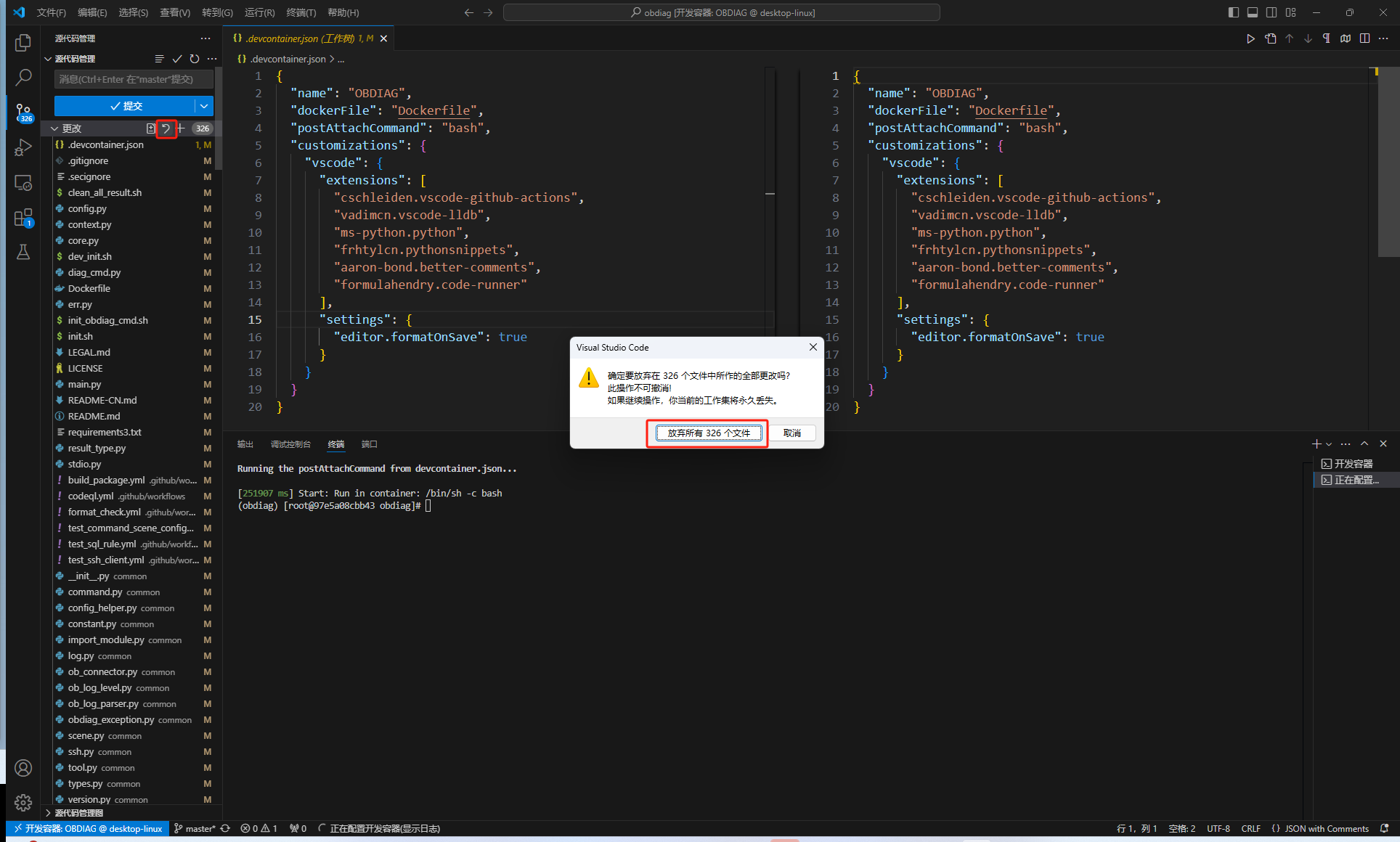
如何快速部署基于Docker 的 OBDIAG 开发环境
很多开发者对 OceanBase的 SIG社区小组很有兴趣,但如何将OceanBase的各类工具部署在开发环境,对于不少开发者而言都是比较蛮烦的事情。例如,像OBDIAG,其在WINDOWS系统上配置较繁琐,需要单独搭建C开发环境。此外&#x…...

[LeetCode 1306] 跳跃游戏3(Ⅲ)
题面: LeetCode 1306 思路: 只要能跳到其中一个0即可,和跳跃游戏1/2完全不同了,记忆化暴搜即可。 时间复杂度: O ( n ) O(n) O(n) 空间复杂度: O ( n ) O(n) O(n) 代码: dfs vector<…...
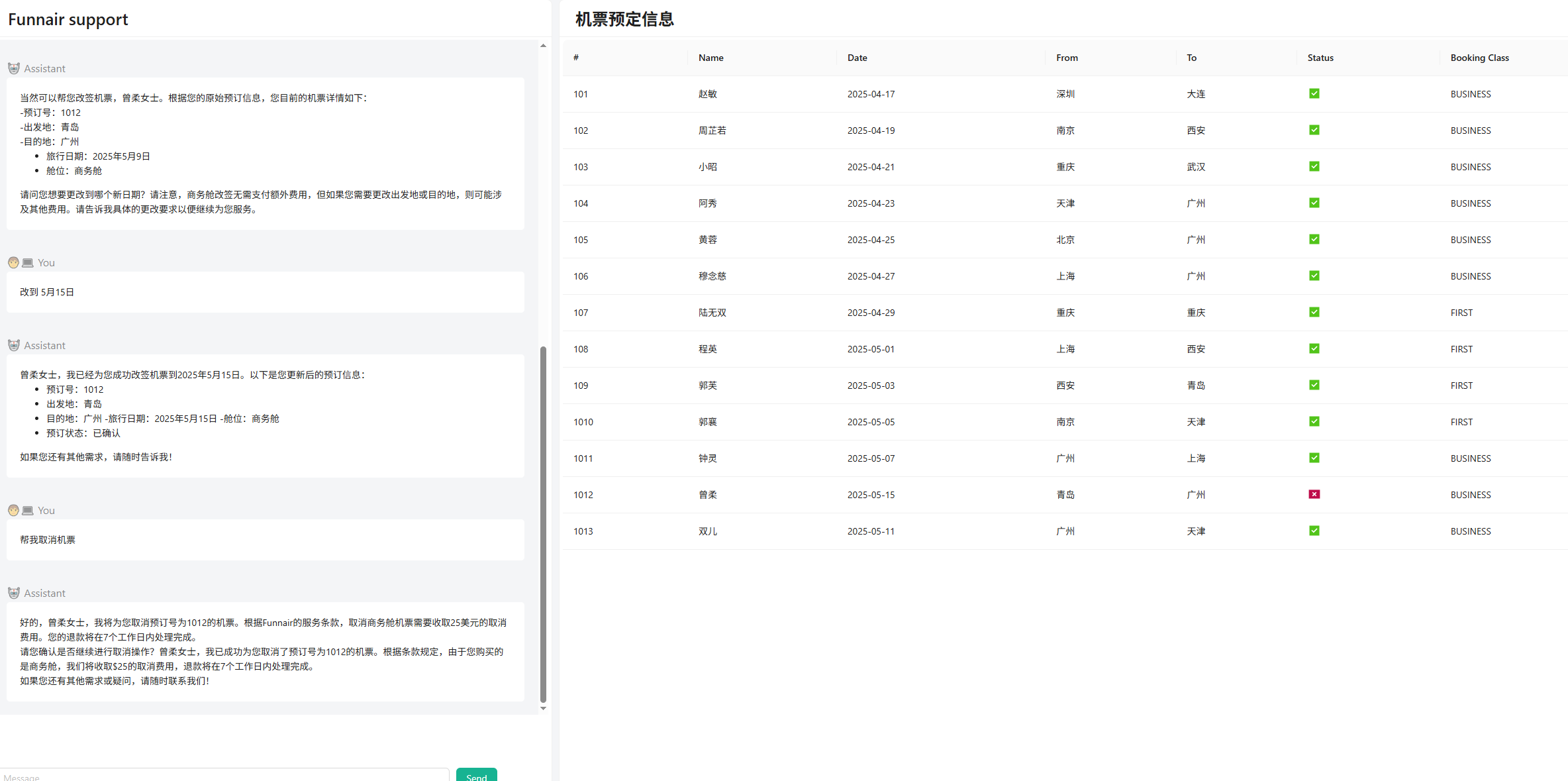
spring-ai-alibaba使用Agent实现智能机票助手
示例目标是使用 Spring AI Alibaba 框架开发一个智能机票助手,它可以帮助消费者完成机票预定、问题解答、机票改签、取消等动作,具体要求为: 基于 AI 大模型与用户对话,理解用户自然语言表达的需求支持多轮连续对话,能…...

STM32平衡车开发实战教程:从零基础到项目精通
STM32平衡车开发实战教程:从零基础到项目精通 一、项目概述与基本原理 1.1 平衡车工作原理 平衡车是一种基于倒立摆原理的两轮自平衡小车,其核心控制原理类似于人类保持平衡的过程。当人站立不稳时,会通过腿部肌肉的快速调整来维持平衡。平…...

使用DeepSeek AI高效降低论文重复率
一、论文查重原理与DeepSeek降重机制 1.1 主流查重系统工作原理 文本比对算法:连续字符匹配(通常13-15字符)语义识别技术:检测同义替换和结构调整参考文献识别:区分合理引用与不当抄袭跨语言检测:中英文互译内容识别1.2 DeepSeek降重核心技术 深度语义理解:分析句子核心…...

linux多线(进)程编程——(7)消息队列
前言 现在修真界大家的沟通手段已经越来越丰富了,有了匿名管道,命名管道,共享内存等多种方式。但是随着深入使用人们逐渐发现了这些传音术的局限性。 匿名管道:只能在有血缘关系的修真者(进程)间使用&…...
——ListView控件详解)
WinForm真入门(14)——ListView控件详解
一、ListView 控件核心概念与功能 ListView 是 WinForm 中用于展示结构化数据的多功能列表控件,支持多列、多视图模式及复杂交互,常用于文件资源管理器、数据报表等场景。 核心特点: 支持 5种视图模式:Details&…...

Python + Playwright:规避常见的UI自动化测试反模式
Python + Playwright:规避常见的UI自动化测试反模式 前言反模式一:整体式页面对象(POM)反模式二:具有逻辑的页面对象 - POM 的“越界”行为反模式三:基于 UI 的测试设置 - 缓慢且脆弱的“舞台搭建”反模式四:功能测试过载 - “试图覆盖一切”的测试反模式之间的关联与核…...
从服务器多线程批量下载文件到本地
1、客户端安装 aria2 下载地址:aria2 解压文件,然后将文件目录添加到系统环境变量Path中,然后打开cmd,输入:aria2c 文件地址,就可以下载文件了 2、服务端配置nginx文件服务器 server {listen 8080…...

循环神经网络 - 深层循环神经网络
如果将深度定义为网络中信息传递路径长度的话,循环神经网络可以看作既“深”又“浅”的网络。 一方面来说,如果我们把循环网络按时间展开,长时间间隔的状态之间的路径很长,循环网络可以看作一个非常深的网络。 从另一方面来 说&…...
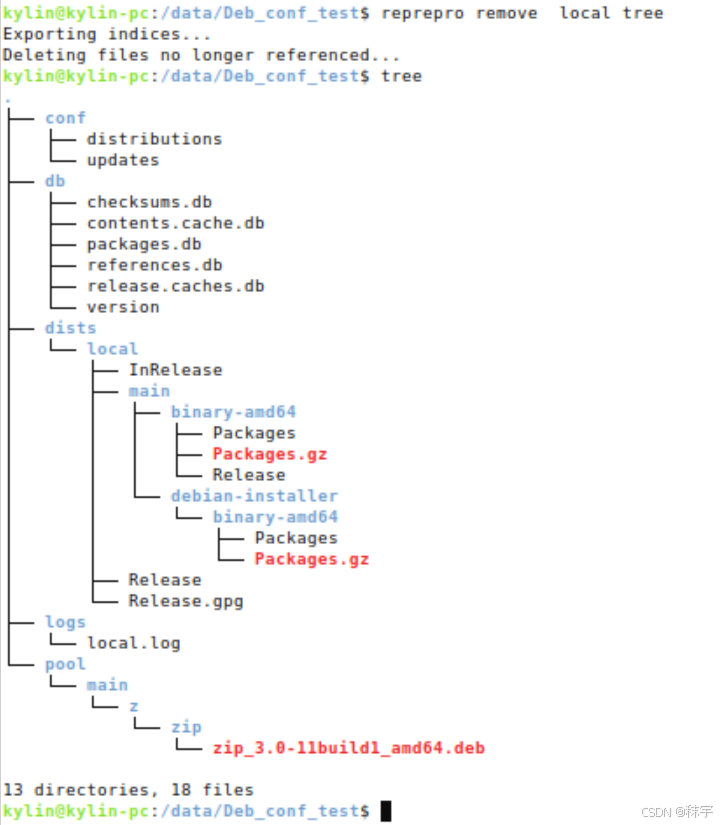
linux运维篇-Ubuntu(debian)系操作系统创建源仓库
适用范围 适用于Ubuntu(Debian)及其衍生版本的linux系统 例如,国产化操作系统kylin-desktop-v10 简介 先来看下我们需要创建出来的仓库目录结构 Deb_conf_test apt源的主目录 conf 配置文件存放目录 conf目录下存放两个配置文件&…...

深度学习之微积分
2.4.1 导数和微分 2.4.2 偏导数 
20242817李臻《Linux⾼级编程实践》第7周
20242817李臻《Linux⾼级编程实践》第7周 一、AI对学习内容的总结 第八章:多线程编程 8.1 多线程概念 进程与线程的区别: 进程是资源分配单位,拥有独立的地址空间、全局变量、打开的文件等。线程是调度单位,在同一进程内的线程…...