目标检测与分割:深度学习在视觉中的应用

🔍 PART 1:目标检测(Object Detection)
1️⃣ 什么是目标检测?
目标检测是计算机视觉中的一个任务,目标是让模型“在图像中找到物体”,并且判断:
-
它是什么类别(classification)
-
它在哪里(localization)
输出通常是:一个或多个 bounding box + 对应类别
🧠 举例:看一张街景图,目标检测系统会输出:
[{"class": "car", "bbox": [50, 80, 200, 300]},{"class": "person", "bbox": [210, 100, 250, 300]}
]
2️⃣ 传统方法演变史
(1)R-CNN(Region-based CNN)
关键词:提候选区域 + 独立分类器
🛠️ 步骤:
-
使用 Selective Search 等方法,生成 2000+ 候选框(region proposals)
-
对每个框裁剪、resize,送入 CNN 提取特征(如 AlexNet)
-
用 SVM 对特征进行分类(猫狗车人等)
-
用边框回归器微调预测框的位置
✅ 优点:
-
检测准确率高,首次将 CNN 引入目标检测
-
引领了后续目标检测研究方向
❌ 缺点:
-
每张图像跑 2000 多次 CNN,速度慢如蜗牛
-
整个流程是分步骤训练,不能端到端训练
-
中间特征要保存,占用大量磁盘空间
(2)Fast R-CNN
关键词:共享特征图 + ROI Pooling + 单阶段训练
🔁 改进方法:
-
整张图只跑一次 CNN,生成特征图
-
使用 ROI Pooling 从特征图中裁剪候选框区域
-
在一个网络中同时做分类 + 边框回归
✅ 优点:
-
更快、更省内存
-
可端到端训练(使用 Softmax + Smooth L1 Loss)
❌ 缺点:
-
仍然依赖外部模块(如 Selective Search)来生成候选框
(3)Faster R-CNN
关键词:自带 RPN(Region Proposal Network)
Faster R-CNN 把“提候选框”的模块也变成一个神经网络,称为 RPN。
🚀 模型结构:
图像 → CNN → 特征图
↘→ RPN 生成候选框
↘→ ROI Pooling → 分类 + 回归
🧠 RPN 工作方式:
-
用卷积滑窗在特征图上滑动
-
每个滑窗预测:
-
是不是物体?(二分类)
-
如果是,框在哪里?(坐标回归)
-
✅ 总结优点:
-
全模型端到端训练(backprop 到最前面)
-
精度高,速度比前两者快
-
成为基准检测器(benchmark)
❌ 缺点:
-
实时性差(约 7 FPS)
-
对小物体不敏感(因层次深、特征粗)
3️⃣ YOLO(You Only Look Once)
关键词:单阶段、速度极快、端到端预测
YOLO 不再分“提框”和“分类”两步,而是一次性直接输出所有框和类别。
🧠 工作原理:
-
把输入图像划分为 S×S 网格
-
每个格子负责预测若干个 bounding box + 置信度 + 类别概率
-
最后筛选 + NMS(非极大值抑制)去掉重复框
✅ 优点:
-
快!(可达 45–155 FPS)
-
训练和预测都是端到端的
-
特别适合实时场景,如无人车、机器人
❌ 缺点:
-
精度不如 Faster R-CNN(特别是小物体)
-
对重叠目标不够敏感(因为格子限制)
4️⃣ SSD(Single Shot Detector)
关键词:多层多尺度预测、一次性输出
-
相比 YOLO,SSD 在不同尺度的 feature maps 上都进行预测
-
每个位置使用多个 aspect ratio 的 anchor box
✅ 特点:
-
保留 YOLO 的速度
-
提升对小物体、多物体的适应能力
-
应用广泛,如移动端部署
5️⃣ RetinaNet(高精度 + 快)
关键词:Focal Loss + Feature Pyramid Network
-
面对的问题:正负样本极度不平衡(99% 都是背景框)
-
引入 Focal Loss,使容易分类的样本损失变小,专注难样本
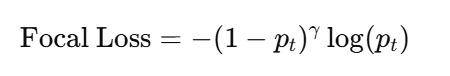
-
同时使用 FPN(从低层和高层抽取特征)
✅ 优势:
-
精度接近 Faster R-CNN,速度接近 SSD
-
成为很多工业检测系统的首选
✅ 小结对比表
| 方法 | 速度 | 精度 | 优势 |
|---|---|---|---|
| R-CNN | 慢 | 高 | 思想开创,流程复杂 |
| Fast R-CNN | 较慢 | 高 | 特征共享,训练简单 |
| Faster R-CNN | 中 | 非常高 | RPN 端到端 |
| YOLO | 非常快 | 一般 | 实时场景首选 |
| SSD | 非常快 | 中高 | 多尺度处理,小目标好 |
| RetinaNet | 快 + 准 | 很高 | 焦点损失 + 多层检测 |
🧠 Part 2:语义分割 & 实例分割
🔍 1️⃣ 什么是语义分割(Semantic Segmentation)?
就是要让模型对图像中的“每一个像素”做出分类。
换句话说,它不再是识别整张图里有没有狗,而是要把“狗的每个像素”标出来。
📷 举个例子:
一张图片里有:
-
天空
-
建筑
-
一辆车
-
一只狗
那么语义分割模型就要把:
-
所有天空像素 → 标记为 class 0
-
所有建筑像素 → class 1
-
所有车的像素 → class 2
-
所有狗的像素 → class 3
结果输出是一张和原图一样大小的图片,每个像素是一个类别编号(mask)。
🎯 用处有哪些?
| 应用场景 | 解释 |
|---|---|
| 自动驾驶 | 车道线、人、车、障碍物像素级分割 |
| 医学图像分析 | 脑肿瘤、器官、血管等结构分割 |
| 卫星遥感 | 地表分类(农田、建筑、道路) |
🧱 2️⃣ 怎么实现语义分割?——FCN
🏗️ FCN:Fully Convolutional Network
🧠 思想:
我们不能再用全连接层(FC),因为它把图像“压成一维向量”了。
所以我们把原来分类网络的 FC 层去掉,全部换成卷积层!
✅ FCN 架构:
-
编码器部分(像 VGG、ResNet):提取图像高级语义特征(但大小变小)
-
上采样部分(Upsampling / Transposed Conv):把特征图“放大回原图大小”
-
像素级预测层:对每个像素输出分类结果(比如 softmax over 21 类)
📐 下采样 → 上采样:
-
原图输入:512×512
-
编码器卷积后:32×32(高层抽象)
-
上采样恢复回 512×512,每个像素分类!
🚧 问题:上采样后信息模糊
FCN 中的上采样有时候会“糊掉”细节,比如边缘不清晰、物体轮廓不完整。
🧬 3️⃣ U-Net:更强的语义分割网络
U-Net 是专为医学图像设计的分割网络,结构长得像字母 “U”。
🧱 U-Net 结构:
| 编码器部分(左边) | 解码器部分(右边) |
|---|---|
| 多层卷积 + Pooling | 多层转置卷积 + 上采样 |
| 把图像越压越小,提取特征 | 把特征图还原成原图尺寸 |
🌉 核心创新点:Skip Connections(跳跃连接)
-
将编码器中每层的特征图 直接连接到解码器的对应层
-
这样就把 低层的边缘细节 + 高层的语义信息融合起来了!
🔍 好处:
-
保留边界、轮廓信息
-
不会因为上采样而“糊”掉小物体
-
极其适合小样本学习,医学图像超常用!
👨👩👧 4️⃣ 什么是实例分割(Instance Segmentation)?
和语义分割的区别在于:
-
语义分割:你知道哪些像素是“人”,但不知道有几个“人”
-
实例分割:你不仅知道哪些像素是“人”,还知道是第1个人、第2个人…
比如:
-
语义分割 → 把 3 个苹果都标为 class=apple
-
实例分割 → 给 3 个苹果不同 mask(Apple1, Apple2, Apple3)
🧰 实例分割的代表:Mask R-CNN
Mask R-CNN 是在 Faster R-CNN 的基础上加了“像素级掩膜预测”的分支。
🧠 Mask R-CNN = Faster R-CNN + Mask head
架构如下:
输入图像 → → CNN backbone 提取特征 → → RPN 生成候选框 → → ROIAlign → 分类 & 回归(原来 Faster R-CNN 的输出) → + 额外的 Mask 分支 → 输出 28×28 的像素掩膜
💡 关键技术:ROIAlign
ROI Pooling 是把框中的区域裁剪为固定大小。但它会导致像素 misalignment(对不齐)。
ROIAlign 使用双线性插值方法保留空间对齐关系,大幅提升 mask 的像素级精度。
✅ 小结表:语义分割 vs 实例分割
| 特征 | 语义分割 | 实例分割 |
|---|---|---|
| 每个像素分类? | ✅ | ✅ |
| 能区分实例? | ❌ 所有人都一样 | ✅ 每个对象单独编号 |
| 适用模型 | FCN, U-Net | Mask R-CNN |
| 应用场景 | 自动驾驶、遥感、医学图 | 智能标注、COCO竞赛 |
🎓 PART 3:训练技巧与优化方法(Training & Regularization)
🎯 为什么要学习训练技巧?
在深度学习中,构建一个模型不是最难的,真正让它训练成功才是挑战!
常见训练中的“坑”包括:
| 问题 | 描述 |
|---|---|
| 过拟合 Overfitting | 在训练集表现很好,测试集效果很差 |
| 梯度爆炸/消失 | 网络太深或参数初始化不当 |
| 收敛慢、震荡大 | 学习率不合适、训练不稳定 |
| 数据不平衡 | 有些类别样本很多,有些很少 |
📌 我们将介绍的核心训练技巧:
| 技术名 | 用处 |
|---|---|
| ✅ 数据增强 | 让数据更多样,减少过拟合 |
| ✅ 正则化(L2) | 限制模型复杂度 |
| ✅ Dropout | 训练时随机“关掉”一部分神经元 |
| ✅ Batch Normalization | 训练更稳定,加快收敛 |
| ✅ Early Stopping | 验证集不再变好时就提前终止训练 |
| ✅ 迁移学习 | 用别人训练好的模型做自己任务 |
🧪 1️⃣ 正则化(Regularization)
📌 什么是正则化?
就是在损失函数中“惩罚”太复杂的模型,避免模型过拟合训练集。
🎯 目标:
-
想让模型在新数据上也表现好(泛化能力强)
-
而不是只会“记住”训练数据
✍️ 数学上怎么做?

💡 简单理解:
你给模型加了个“规则”:参数别乱搞太大,除非你真的很需要这么大。
🎛️ 2️⃣ Dropout(随机失活)
在训练过程中,随机让部分神经元“暂时消失”。
为什么这么做?
-
强迫模型不能依赖某个特定神经元
-
等于模拟多个不同的子网络 → 提高泛化能力
🧠 举例:
假设某一层有 100 个神经元,设置 Dropout rate = 0.5
-
每次前向传播,随机“屏蔽”掉 50 个神经元
在测试时:
-
不 Dropout,而是保留全部神经元,但乘以 0.5(期望值保持一致)
✅ 效果:
-
减少 co-adaptation(神经元之间互相依赖)
-
显著减轻过拟合
🧪 3️⃣ Batch Normalization(BN)
在每一层之后对输出进行标准化(均值为 0,方差为 1)
✨ 为什么 BN 有用?
-
深层网络中,分布会不断变动(叫 Internal Covariate Shift)
-
BN 让每一层的输入“保持稳定”,训练更快更稳
🎯 效果:
-
网络可以用更大学习率
-
收敛更快
-
训练更不容易陷入震荡
⏱️ 4️⃣ Early Stopping(早停)
如果验证集准确率不再提升,就提前停止训练
📌 为什么?
-
一般训练久了后,模型会开始过拟合
-
我们使用验证集判断模型什么时候“学得刚刚好”
怎么实现?
-
每训练一个 epoch,监控 validation loss
-
如果连续 N 次验证都没有变好,就停!
✅ 常见参数:
EarlyStopping(monitor='val_loss', patience=5)
📸 5️⃣ 数据增强(Data Augmentation)
用各种“微小变换”生成更多样的训练数据
🤸♀️ 举例:
| 方法 | 作用 |
|---|---|
| 翻转 | 让模型识别左右翻的图像 |
| 随机裁剪 | 学会注意局部信息 |
| 加噪声 | 增强鲁棒性 |
| 颜色扰动 | 提高模型对亮度/饱和度容忍 |
| Cutout/Mixup | 深度增强方法 |
📈 数据增强效果:
-
让模型看到“更多样的情况”
-
减少模型对背景、位置、颜色的依赖
-
显著提高模型在测试集的性能
🔄 6️⃣ 迁移学习(Transfer Learning)
利用别人已经训练好的模型来解决你的问题
💡 举例:
-
用别人训练好的 ResNet50(在 ImageNet 上)来做猫狗分类
-
你可以:
-
冻结原始网络参数,只训练最后几层(特征提取)
-
或 整体微调,重新训练所有层(fine-tune)
-
✅ 优点:
-
训练更快(因为预训练模型已经学了“通用特征”)
-
减少对大量标注数据的依赖
-
特别适合小样本任务!
🧠 总结:常见训练技巧一览表
| 技术 | 作用 | 是否减轻过拟合 |
|---|---|---|
| L2 正则化 | 限制权重增长 | ✅ |
| Dropout | 模拟多个子网络 | ✅ |
| Batch Norm | 稳定训练,提高效率 | ❌(但有辅助效果) |
| Early Stopping | 只训练到最优点 | ✅ |
| Data Augmentation | 提高泛化能力 | ✅ |
| Transfer Learning | 加速训练,提高性能 | ✅(尤其小数据) |
4.例题

🧠 通俗+专业解释如下:
✅ 什么是 Transfer Learning?
迁移学习(Transfer Learning) 是指:我们不从头开始训练模型,而是使用别人已经训练好的模型来解决我们的新任务。
💡 举个现实例子:
比如你要训练一个识别“古代陶瓷”的模型,但你没有几千张图,也没有 GPU 跑几天:
你可以下载一个别人训练好的模型(如 ResNet50)
然后用它来“提取图像特征”
最后只在最后一两层训练自己的分类任务
这就叫 迁移学习
✅ 为什么要这样做?
训练 CNN 非常耗资源(数据 + 时间 + 算力)
很多低层卷积层学到的特征是“通用”的(比如边缘、角、纹理)
复用别人的模型能:
节省时间
提升小样本任务效果
加快收敛速度
📌 回到选项分析:
选项 内容 正确与否 理由 A 从零开始训练每个新任务 ❌ 正好是迁移学习的反面 B 使用预训练模型 + 微调 ✅ ✅ 完整迁移学习流程 C 把图像转文字再学 ❌ 不相关,混淆概念 D 合并多个 CNN 提升性能 ❌ 那叫集成学习,不是迁移学习
相关文章:
目标检测与分割:深度学习在视觉中的应用
🔍 PART 1:目标检测(Object Detection) 1️⃣ 什么是目标检测? 目标检测是计算机视觉中的一个任务,目标是让模型“在图像中找到物体”,并且判断: 它是什么类别(classif…...

SpringBoot 与 Vue3 实现前后端互联全解析
在当前的互联网时代,前后端分离架构已经成为构建高效、可维护且易于扩展应用系统的主流方式。本文将详细介绍如何利用 SpringBoot 与 Vue3 构建一个前后端分离的项目,展示两者如何通过 RESTful API 实现无缝通信,让读者了解从环境搭建、代码实…...

HEIF、HEIC、JPG 和 PNG是什么?
1. HEIF (High Efficiency Image Format) 定义:HEIF 是一种用于存储单张图像和图像序列(如连拍照片)的图像文件格式。优势:相比传统的图像格式,HEIF 提供了更高的压缩效率和更好的图像质量。压缩算法:HEI…...

第一层、第二层与第三层隧道协议
(本文由deepseek生成,特此声明) 隧道协议是网络通信中用于在不同网络间安全传输数据的关键技术,其工作层次决定了封装方式、功能特性及应用场景。本文将详细介绍物理层(第一层)、数据链路层(第…...

部署qwen2.5-VL-7B
简单串行执行 from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor from qwen_vl_utils import process_vision_info import torch, time, threadingdef llm(model_path,promptNone,imageNone,videoNone,imagesNone,videosNone,max_new_tokens2048,t…...

记录jdk8->jdk17 遇到的坑和解决方案
最近项目在升级jdk8->jdk17 springboot2->springboot3 顺序先升级业务服务,后升级组件服务。跟随迭代开发一起验证功能。 1. 使用parent pom 版本管理 spring相关组件的版本。 组件依赖低版本parent不变。 业务服务依赖高版本parent。 2. 修改maven jdk…...

vue3 uniapp vite 配置之定义指令
动态引入指令 // src/directives/index.js import trim from ./trim;const directives {trim, };export default {install(app) {console.log([✔] 自定义指令插件 install 触发了!);Object.entries(directives).forEach(([key, directive]) > {app.directive(…...

杰弗里·辛顿:深度学习教父
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 杰弗里辛顿:当坚持遇见突破,AI迎来新纪元 一、人物简介 杰弗…...
STM32蓝牙连接Android实现云端数据通信(电机控制-开源)
引言 基于 STM32F103C8T6 最小系统板完成电机控制。这个小项目采用 HAL 库方法实现,通过 CubeMAX 配置相关引脚,步进电机使用 28BYJ-48 (四相五线式步进电机),程序通过蓝牙连接手机 APP 端进行数据收发, OL…...

第一个Qt开发的OpenCV程序
OpenCV计算机视觉开发实践:基于Qt C - 商品搜索 - 京东 下载安装Qt:https://download.qt.io/archive/qt/5.14/5.14.2/qt-opensource-windows-x86-5.14.2.exe 下载安装OpenCV:https://opencv.org/releases/ 下载安装CMake:Downl…...

如何编写爬取网络上的视频文件
网络爬虫程序,可以爬取某些网站上的视频,音频,图片或其它文件,然后保存到本地电脑上; 有时在工作中非常有用,那在技术上如何进行爬取文件和保存到本地呢?下面以python语言为例,讲解p…...
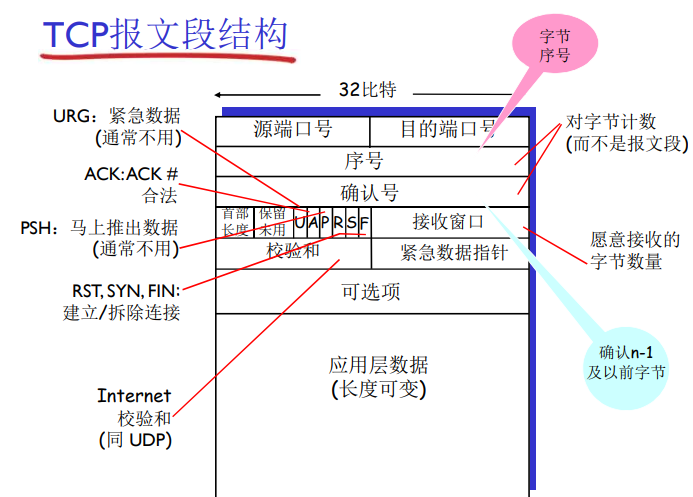
TCP 如何在网络 “江湖” 立威建交?
一、特点: (一)面向连接 在进行数据传输之前,TCP 需要在发送方和接收方之间建立一条逻辑连接。这一过程类似于打电话,双方在通话前需要先拨号建立连接。建立连接的过程通过三次握手来完成,确保通信双方都…...
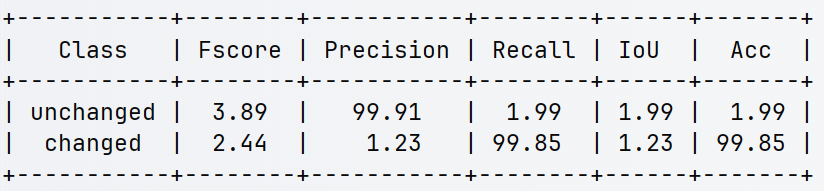
【小白训练日记——2025/4/15】
变化检测常用的性能指标 变化检测(Change Detection)的性能评估依赖于多种指标,每种指标从不同角度衡量模型的准确性。以下是常用的性能指标及其含义: 1. 混淆矩阵(Confusion Matrix) 定义:统…...

交叉熵在机器学习中的应用解析
文章目录 核心概念香农信息量(自信息)熵(Entropy)KL散度(Kullback-Leibler Divergence)交叉熵 在机器学习中的应用作为损失函数对于二分类(Binary Classification):对于多…...

ARM Cortex汇编指令
在ARM架构的MCU开发中,汇编指令集是底层编程的核心。以下是针对Cortex-M系列(如M0/M3/M4/M7/M85)的指令集体系、分类及查询方法的详细说明: 一、指令集体系与核心差异 1. 架构版本与指令集特性 处理器架构指令集特点典型应用场…...
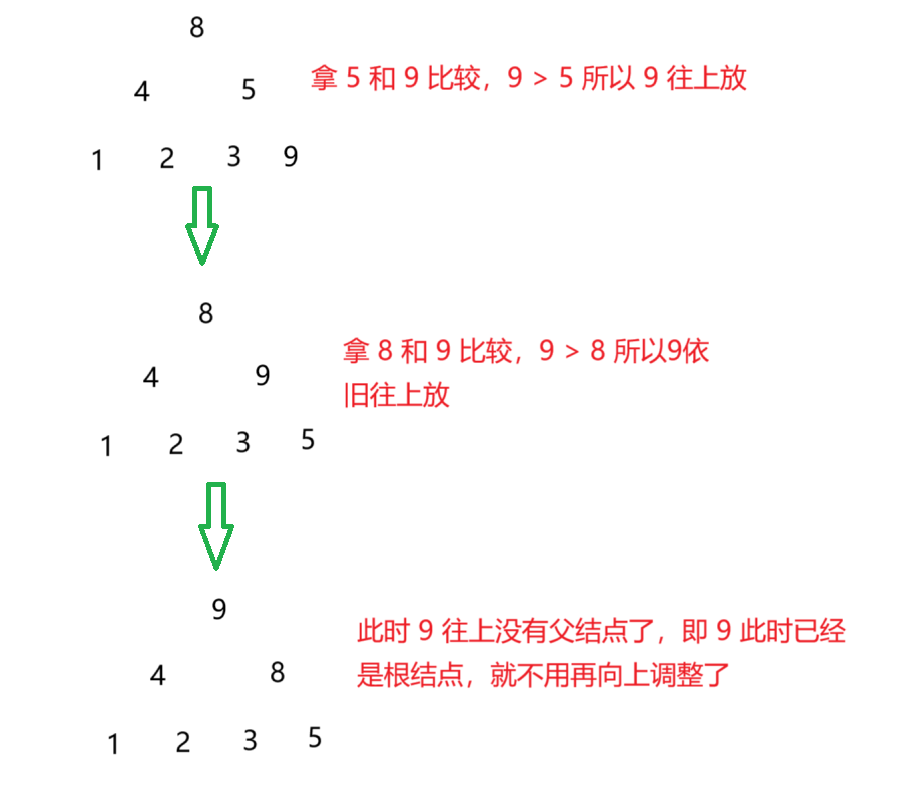
数据结构——二叉树(中)
接上一篇,上一篇主要讲解了关于二叉树的基本知识,也是为了接下来讲解关于堆结构和链式二叉树结构打基础,其实无论是堆结构还是链式二叉树结构,都是二叉树的存储结构,那么今天这一篇主要讲解关于堆结构的实现与应用 堆…...

InnoDB的MVCC实现原理?MVCC如何实现不同事务隔离级别?MVCC优缺点?
概念 InnoDB的MVCC(Multi-Version Concurrency Control)即多版本并发控制,是一种用于处理并发事务的机制。它通过保存数据在不同时间点的多个版本,让不同事务在同一时刻可以看到不同版本的数据,以此来减少锁竞争&…...

UDP目标IP不存在时的发送行为分析
当网络程序使用UDP协议发送数据时,如果目标IP不存在,发送程序的行为取决于网络环境和操作系统的处理机制。以下是详细分析: 1. UDP的无连接特性 UDP是无连接的传输协议,发送方不会预先建立连接,也不会收到对方是否存在…...

WHAT - 动态导入模块遇到版本更新解决方案
文章目录 一、动态导入模块二、常见原因与解决方案1. 模块 URL 错误2. 开发人员发版用户停留在旧页面问题背景解决方案思路1. 监听错误,提示用户刷新2. 使用缓存控制策略:强制刷新3. 动态模块加载失败时兜底4. 使用 import.meta.glob() 或 webpack 的 __…...
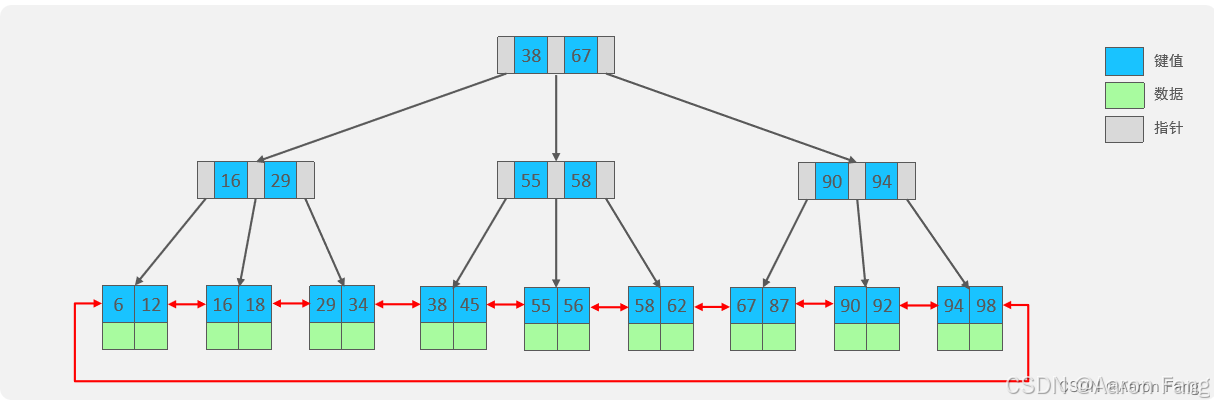
02-MySQL 面试题-mk
文章目录 1.mysql 有哪些存储引擎、区别是什么?1.如何定位慢查询?2.SQL语句执行很慢,如何分析?3.索引概念以及索引底层的数据结构4.什么是聚簇索引什么是非聚簇索引?5.知道什么叫覆盖索引嘛 ?6.索引创建原则有哪些?7.什么情况下索引会失效 ?8.谈一谈你对sql的优化的经验…...

#include<bits/stdc++.h>
#include<bits/stdc.h> 是 C 中一个特殊的头文件,其作用如下: 核心作用 包含所有标准库头文件 该头文件会自动引入 C 标准库中的几乎全部头文件(如 <iostream>、<vector>、<algorithm> 等)&…...

PostgreSQL:逻辑复制与物理复制
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c=1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编程,高并发设计,Springboot和微服务,熟悉Linux,ESXI虚拟化以及云原生Docker和K8s,热衷于探…...
在企业级部署中如何优化NVIDIA GPU和容器环境配置:最佳实践与常见误区20250414
在企业级部署中如何优化NVIDIA GPU和容器环境配置:最佳实践与常见误区 引言 随着AI和深度学习技术的迅速发展,企业对GPU加速计算的需求愈加迫切。在此过程中,如何高效地配置宿主机与容器化环境,特别是利用NVIDIA GPU和相关工具&…...

iphone各个机型尺寸
以下是苹果(Apple)历代 iPhone 机型 的屏幕尺寸、分辨率及其他关键参数汇总(截至 2023年10月,数据基于官方发布信息): 一、标准屏 iPhone(非Pro系列) 机型屏幕尺寸(英寸…...

栈的学习笔记
使用数组实现一个栈 #include <stdio.h>#define MAX_SIZE 101int A[MAX_SIZE]; int top -1; //栈顶指针,初始为-1,表示栈为空 void push(int x) {if (top MAX_SIZE - 1){printf("栈已满,无法入栈\n");return;}A[top] x;…...
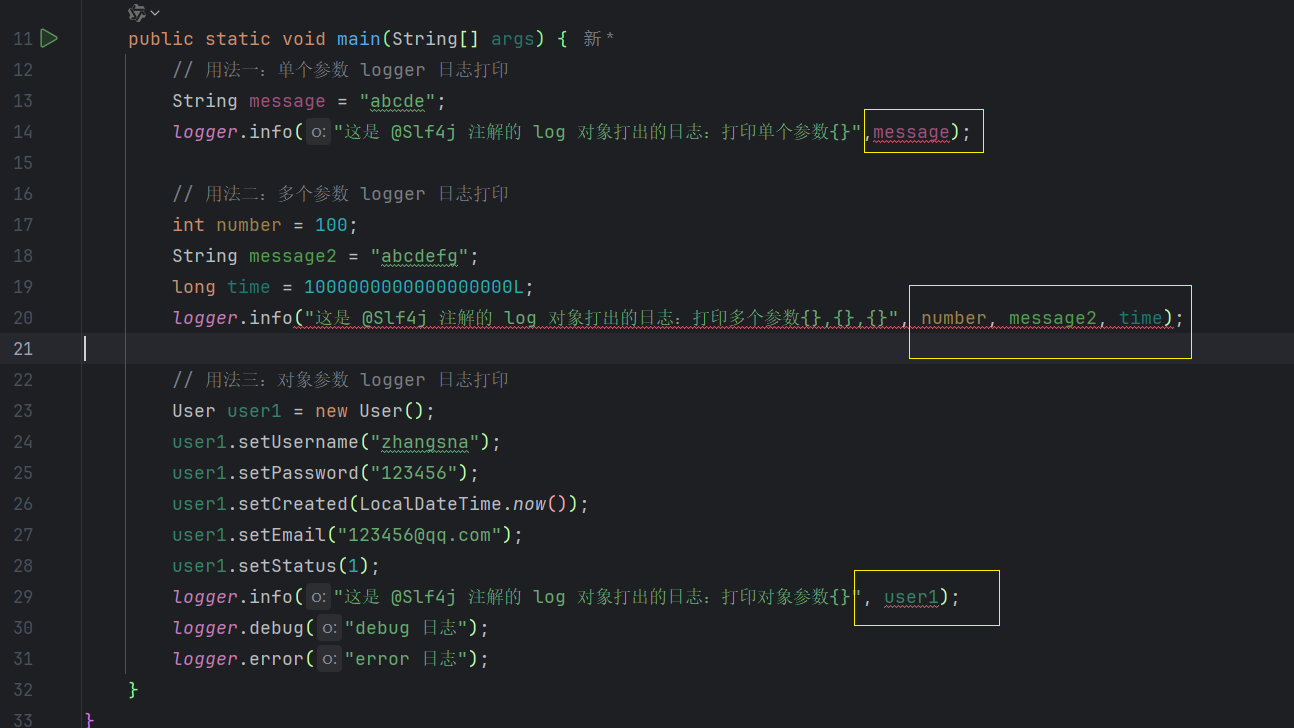
Spring Boot 项目三种打印日志的方法详解。Logger,log,logger 解读。
目录 一. 打印日志的常见三种方法? 1.1 手动创建 Logger 对象(基于SLF4J API) 1.2 使用 Lombok 插件的 Slf4j 注解 1.3 使用 Spring 的 Log 接口(使用频率较低) 二. 常见的 Logger,logger,…...

按键精灵安卓/ios脚本辅助工具开发教程:如何把界面配置保存到服务器
在使用按键精灵工具辅助的时候,多配置的情况下,如果保存现有的配置,并且读取,尤其是游戏中多种任务并行情况下,更是需要界面进行保存,简单分享来自紫猫插件的配置保存服务器写法。 界面例子: …...

[react]Next.js之自适应布局和高清屏幕适配解决方案
序言 阅读前首先了解即将要用到的两个包的作用 1.postcss-pxtorem 自动将 CSS 中的 px 单位转换为 rem 单位按照设计稿尺寸直接写 px 值,由插件自动计算 rem 值 2.amfe-flexible 动态设置根元素的 font-size(即 1rem 的值)根据设备屏幕宽度和…...
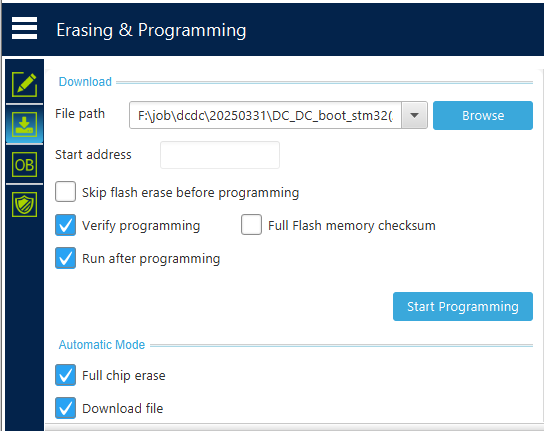
STM32H503CB升级BootLoader
首先,使用SWD接口,ST-LINK连接电脑和板子。 安装SetupSTM32CubeProgrammer_win64 版本2.19。 以下是接线和软件操作截图。...
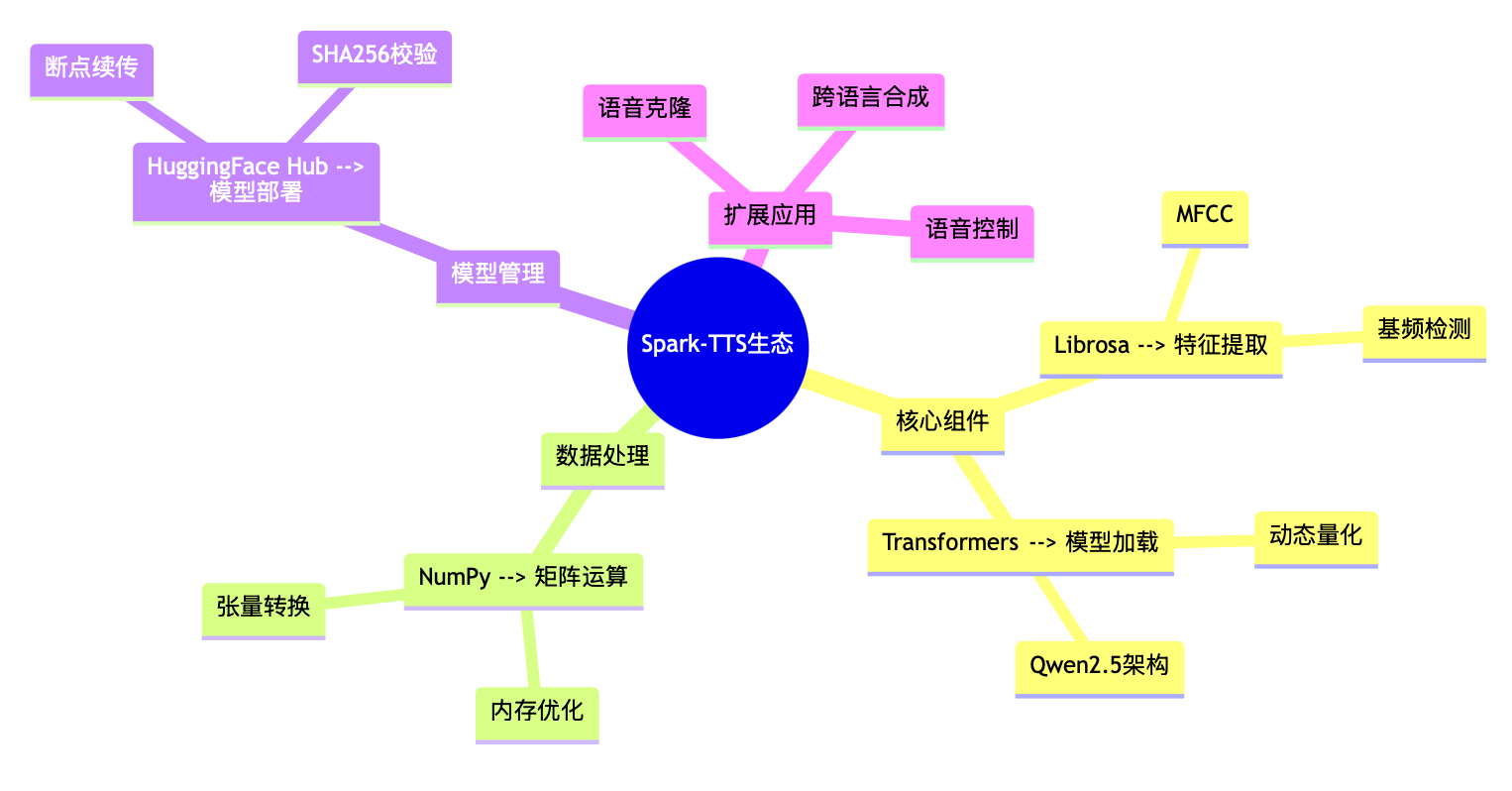
在Apple Silicon上部署Spark-TTS:四大核心库的技术魔法解析!!!
在Apple Silicon上部署Spark-TTS:四大核心库的技术魔法解析 🚀 (M2芯片实测|Python 3.12.9PyTorch 2.6.0全流程解析) 一、核心库功能全景图 🔍 在Spark-TTS的部署过程中,pip install numpy li…...