Python爬虫第15节-2025今日头条街拍美图抓取实战
目录
一、项目背景与概述
二、环境准备与工具配置
2.1 开发环境要求
2.2 辅助工具配置
三、详细抓取流程解析
3.1 页面加载机制分析
3.2 关键请求识别技巧
3.3 参数规律深度分析
四、爬虫代码实现
五、实现关键
六、法律与道德规范
一、项目概述
在当今互联网时代,数据采集与分析已成为重要的技术能力。本教程将以今日头条街拍美图为例,详细介绍如何通过Python实现Ajax数据抓取的完整流程。
今日头条作为国内领先的内容平台,其图片内容资源丰富,特别是街拍类图片深受用户喜爱。通过分析其Ajax接口,我们可以学习到现代Web应用的数据加载方式,掌握处理动态内容的爬虫开发技巧。
二、环境准备与工具配置
2.1 开发环境要求
1. Python环境:建议使用Python 3.6及以上版本
- 可通过官网下载安装:https://www.python.org/downloads/
- 安装后验证:`python --version`
2. 必需库安装:
pip install requests urllib3 hashlib multiprocessing3. 推荐开发工具:
- IDE:PyCharm、VS Code
- 浏览器:Chrome(用于开发者工具分析)
- 调试工具:Postman(用于接口测试)
2.2 辅助工具配置
1. Chrome开发者工具:
- 快捷键F12或右键"检查"打开
- 重点使用Network面板和Elements面板
- 建议开启"Preserve log"选项保留请求记录
2. 代理设置(可选):
略
三、详细抓取流程解析
3.1 页面加载机制分析
现代Web应用普遍采用前后端分离架构,理解其数据加载原理至关重要:
1. 传统网页:服务端渲染,HTML包含所有内容
2. 现代SPA:初始HTML为空壳,通过Ajax动态加载数据
下面以今日头条为例分析:
首次加载基础框架

在今日头条首页( https://www.toutiao.com/),直接输入街拍搜索,然后如下点击图片选项,就会出现大把的美女图片。
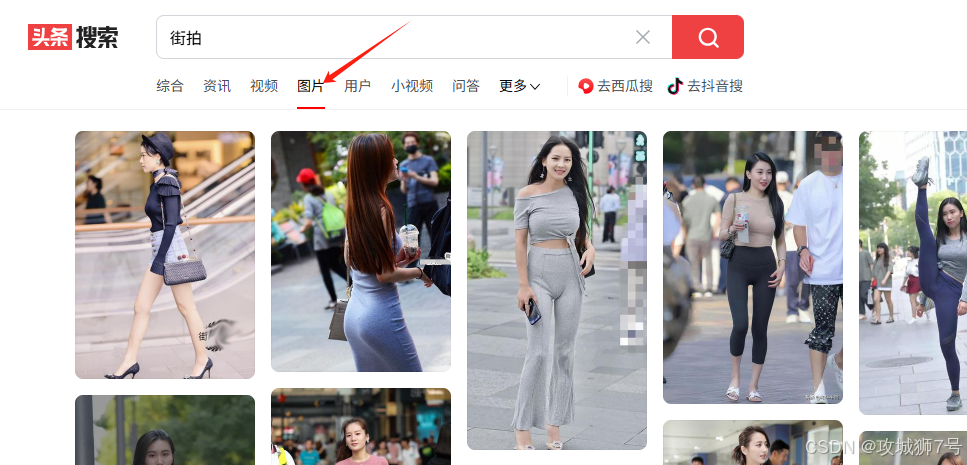
这时按ctrl+s即可保存所有已加载的网页内容,保存下来的网页可以直接搜到jpeg的图片链接。但是我们现在要查看接口请求,我们按F12打开开发者工具,重新加载页面,查看所有的网络请求。
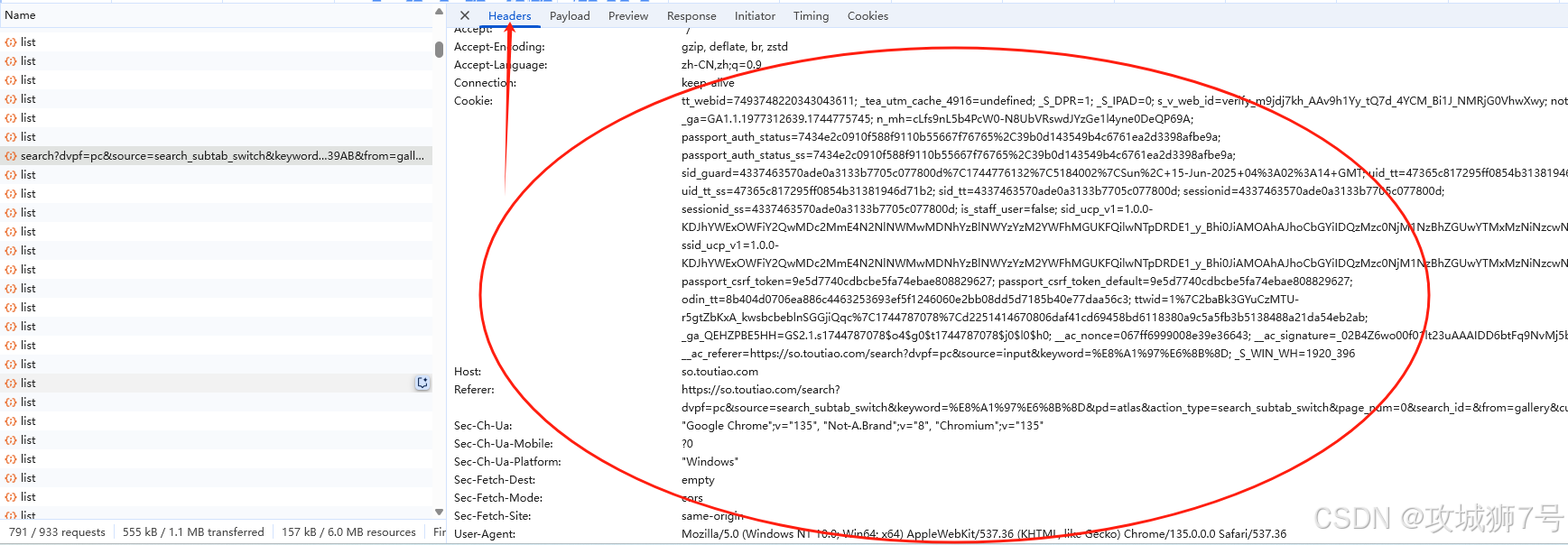
首先,查看发起第一个网络请求,请求的URL是 ( https://so.toutiao.com/search?dvpf=pc&source=search_subtab_switch&keyword=%E8%A1%97%E6%8B%8D&pd=atlas&action_type=search_subtab_switch&page_num=0&search_id=&from=gallery&cur_tab_title=gallery )。然后打开Preview选项卡,查看响应体内容。要是页面上的内容是依据第一个请求的结果渲染出来的 。
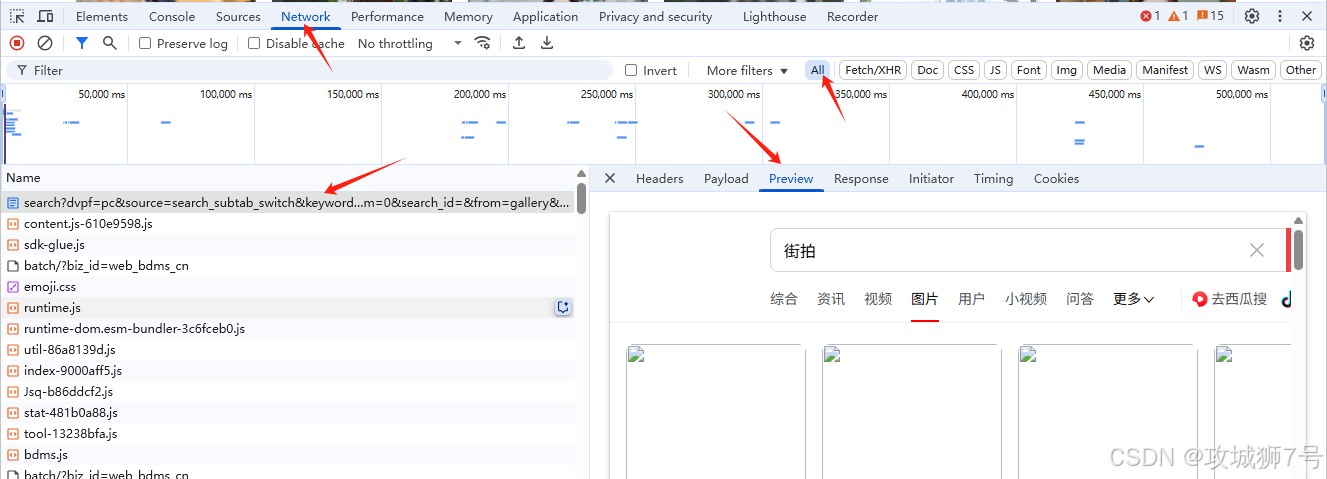
由于查看他的请求头内容Headers没有明确的 X-Requested-With 请求头,看不出是ajax请求。
通过XHR请求获取实际内容
然而我点击Fetch/XHR进行过滤ajax请求,并快速向下滚动页面就会发现下面某接口:
https://so.toutiao.com/search?dvpf=pc&source=search_subtab_switch&keyword=%E8%A1%97%E6%8B%8D&pd=atlas&action_type=search_subtab_switch&page_num=1&search_id=20250416152239B787556EC505238FF4F8&from=gallery&cur_tab_title=gallery&rawJSON=1
其中请求头内容的sec-fetch-mode: cors 和其他请求头(如 accept: */*)以及请求的行为模式(如通过查询参数发送数据),这些都是AJAX 请求特征。
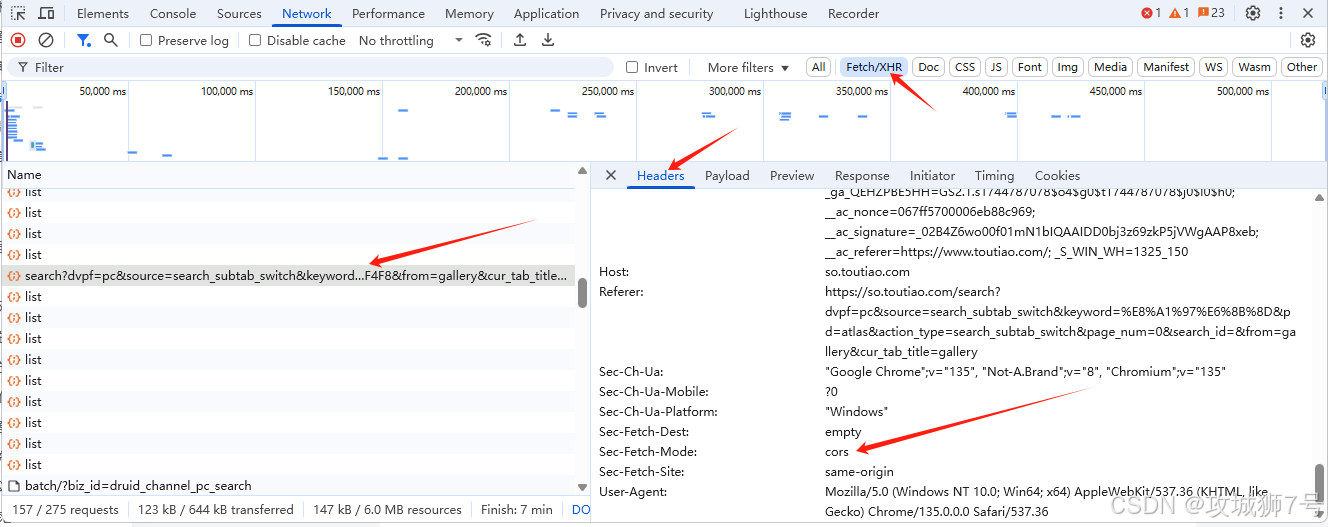
然后点击Preview查看响应数据的数据结构
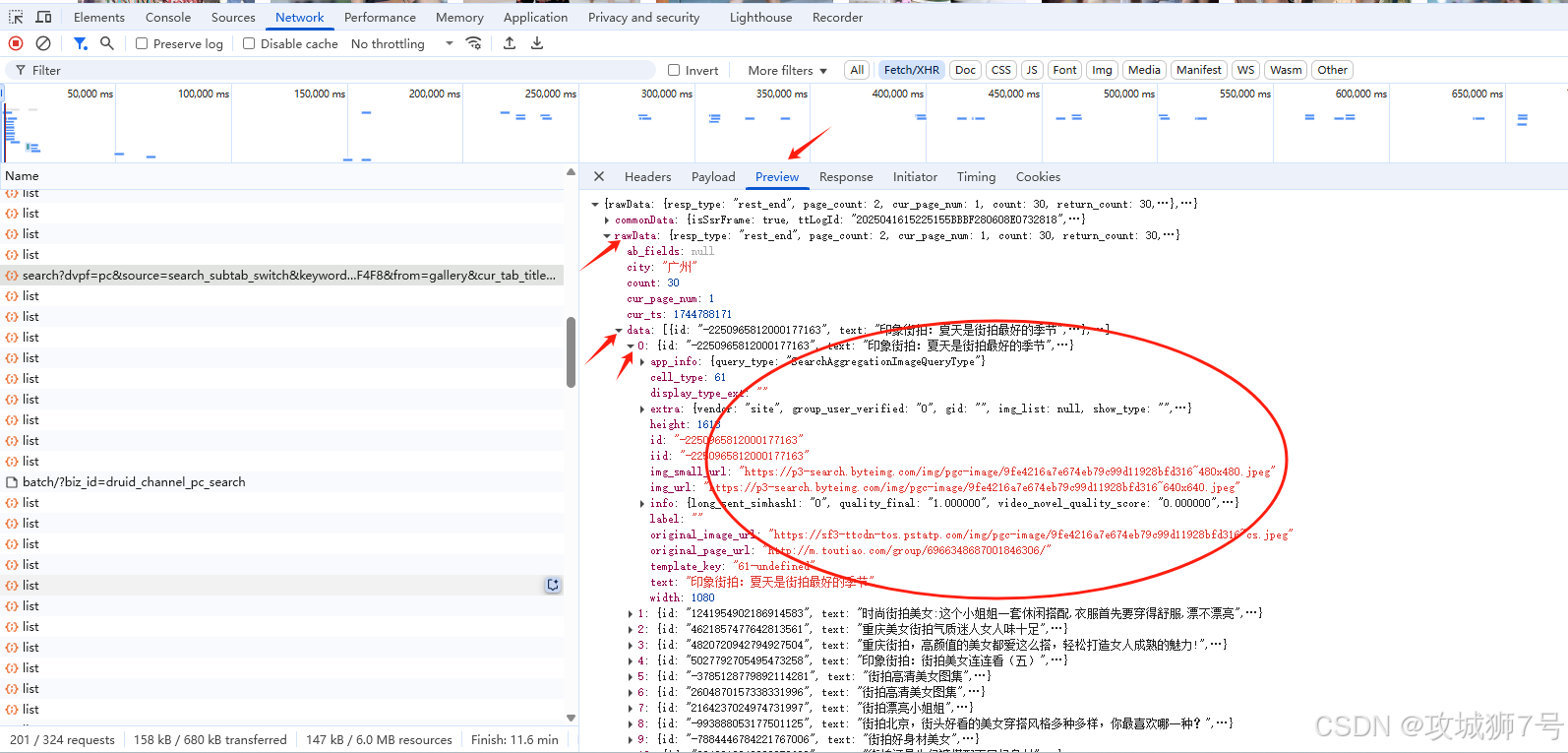
看得出为了防止连续被爬取图片,参数page_num和search_id是有限制关系的,即使page_num有规律,但是search_id却另外计算获取。
3.2 关键请求识别技巧
在开发者工具的Network面板中:
1. 过滤XHR请求:快速定位Ajax调用
2. Preview功能:直观查看JSON数据结构
3. Headers分析:
- Request URL:接口地址
- Request Method:GET/POST
- Query Parameters:请求参数
4. 时序分析:通过Waterfall了解加载顺序
3.3 参数规律深度分析
从提供的 URL,我们可以解析出一系列的查询参数(query parameters),每个参数都有其特定的作用:
1. `dvpf=pc`: 这个参数可能指示请求是从个人计算机(PC)发出的,可能用于区分不同设备类型的请求,如移动端或平板电脑。
2. `source=search_subtab_switch`: 这个参数可能表示请求的来源,这里是“search_subtab_switch”,可能是指用户在搜索结果的子标签页之间进行切换时触发的请求。
3. `keyword=%E8%A1%97%E6%8B%8D`: 这是经过URL编码的搜索关键词,解码后是“街拍”。这是用户在搜索框中输入的关键词。
4. `pd=atlas`: 这个参数的具体含义不是很清晰,它可能指的是请求的特定部分或页面(Page Division)。
5. `action_type=search_subtab_switch`: 类似于 `source` 参数,这个参数可能指明了用户执行的动作类型,这里是在搜索子标签页之间切换。
6. `page_num=1`: 这个参数指示请求的是搜索结果的第几页,这里是第2页,从0开始算。
7. `search_id=20250416152239B787556EC505238FF4F8`: 这是一个唯一的搜索会话标识符,用于追踪用户的搜索会话。
8. `from=gallery`: 这个参数可能指示用户是从图库部分发起搜索的。
9. `cur_tab_title=gallery`: 这个参数可能表示当前活动的标签页标题是图库。
10. `rawJSON=1`: 这个参数指示服务器返回的数据格式应该是原始的 JSON 格式,而不是经过任何服务器端处理的数据。
每个参数都是键值对的形式,通过 `&` 符号连接。服务器会解析这些参数,以便根据用户的请求提供定制化的内容。例如,服务器可以根据 `keyword` 参数提供搜索关键词的相关结果,`page_num` 参数用来分页显示结果,而 `search_id` 用来保持搜索会话的连续性。
四、爬虫代码实现
模拟请求的时候需要设置必要的请求头参数,包括cookie等,不然请求拿不到数据。因为search_id暂时还没找到解决办法,只能获取某一页数据。由于search_id会变,所以下面拿了最新的模拟请求:
import requests
import re
import os
from hashlib import md5
import json
from urllib.parse import urlencode
import time
import gzip
import iodef get_page(page_num):base_url = 'https://so.toutiao.com/search?'params = {'dvpf': 'pc','source': 'search_subtab_switch','keyword': '街拍','pd': 'atlas','action_type': 'search_subtab_switch','page_num': page_num,'search_id': '202504161626333A15E72F0B54BF7C39AB','from': 'gallery','cur_tab_title': 'gallery','rawJSON': '1'}headers = {'Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.9','Connection': 'keep-alive','Cookie': 'tt_webid=7493748220343043611; _tea_utm_cache_4916=undefined; _S_DPR=1; _S_IPAD=0; s_v_web_id=verify_m9jdj7kh_AAv9h1Yy_tQ7d_4YCM_Bi1J_NMRjG0VhwXwy; notRedShot=1; _ga=GA1.1.1977312639.1744775745; n_mh=cLfs9nL5b4PcW0-N8UbVRswdJYzGe1l4yne0DeQP69A; passport_auth_status=7434e2c0910f588f9110b55667f76765%2C39b0d143549b4c6761ea2d3398afbe9a; passport_auth_status_ss=7434e2c0910f588f9110b55667f76765%2C39b0d143549b4c6761ea2d3398afbe9a; sid_guard=4337463570ade0a3133b7705c077800d%7C1744776132%7C5184002%7CSun%2C+15-Jun-2025+04%3A02%3A14+GMT; uid_tt=47365c817295ff0854b31381946d71b2; uid_tt_ss=47365c817295ff0854b31381946d71b2; sid_tt=4337463570ade0a3133b7705c077800d; sessionid=4337463570ade0a3133b7705c077800d; sessionid_ss=4337463570ade0a3133b7705c077800d; _S_WIN_WH=1920_396; __ac_nonce=067ff6999008e39e36643; __ac_signature=_02B4Z6wo00f01lt23uAAAIDD6btFq9NvMj5bVtpAAPEx9d; __ac_referer=https://so.toutiao.com/search?dvpf=pc&source=input&keyword=%E8%A1%97%E6%8B%8D','Host': 'so.toutiao.com','Referer': 'https://so.toutiao.com/search?dvpf=pc&source=search_subtab_switch&keyword=%E8%A1%97%E6%8B%8D&pd=atlas&action_type=search_subtab_switch&page_num=0&search_id=&from=gallery&cur_tab_title=gallery','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36','sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"'}url = base_url + urlencode(params)try:# 直接请求数据response = requests.get(url, headers=headers, stream=True)if response.status_code == 200:try:# 尝试直接解析响应内容content = response.texttry:json_data = json.loads(content)return json_dataexcept json.JSONDecodeError:print(f"Failed to decode JSON. Response content: {content[:200]}...")# 如果解析失败,尝试解码原始内容raw_content = response.content.decode('utf-8', errors='ignore')print(f"Raw content: {raw_content[:200]}...")return Noneexcept Exception as e:print(f"Error processing response: {str(e)}")print(f"Response headers: {response.headers}")return Noneelse:print(f"Request failed with status code: {response.status_code}")return Noneexcept requests.ConnectionError as e:print('Error occurred while fetching the page:', e)return Nonedef parse_images(json_data):if not json_data or 'rawData' not in json_data:return# 解析返回的JSON数据data = json_data['rawData'].get('data', [])for item in data:if item.get('text') and (item.get('img_url') or item.get('original_image_url')):title = item.get('text', '')# 优先使用img_urlimage_url = item.get('img_url', '')if not image_url:image_url = item.get('original_image_url', '')yield {'title': title,'image': image_url,'width': item.get('width', 0),'height': item.get('height', 0)}def save_image(item):if not item.get('title') or not item.get('image'):return# 清理文件名中的非法字符title = re.sub(r'[\\/:*?"<>|]', '_', item.get('title'))img_path = 'img' + os.path.sep + titleif not os.path.exists(img_path):os.makedirs(img_path)max_retries = 3retry_count = 0original_url = item.get('image')# 构建可能的URL列表image_urls = []if 'pstatp.com' in original_url or 'ttcdn-tos' in original_url:# 移除协议头以便替换域名url_without_protocol = original_url.split('://')[-1]# 替换域名domains = ['p3-search.byteimg.com','p1-search.byteimg.com','p6-search.byteimg.com','p3-tt.byteimg.com','p1-tt.byteimg.com','p6-tt.byteimg.com']# 替换图片格式和尺寸formats = ['~640x640.jpeg','~480x480.jpeg','~noop.image','~tplv-tt-cs0.jpeg']base_url = url_without_protocol.split('~')[0]for domain in domains:for fmt in formats:url = f'https://{domain}/{base_url.split("/", 1)[1]}{fmt}'if url not in image_urls:image_urls.append(url)# 始终添加原始URL作为最后的选项if original_url not in image_urls:image_urls.append(original_url)# 请求头img_headers = {'Accept': 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9','Connection': 'keep-alive','Referer': 'https://so.toutiao.com/','Origin': 'https://so.toutiao.com','Sec-Fetch-Dest': 'image','Sec-Fetch-Mode': 'no-cors','Sec-Fetch-Site': 'cross-site','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36','Cookie': 'tt_webid=7493748220343043611; _tea_utm_cache_4916=undefined; _S_DPR=1; _S_IPAD=0; s_v_web_id=verify_m9jdj7kh_AAv9h1Yy_tQ7d_4YCM_Bi1J_NMRjG0VhwXwy'}success = Falsefor image_url in image_urls:if retry_count >= max_retries:breaktry:# 使用stream=True来分块下载response = requests.get(image_url, headers=img_headers, stream=True, timeout=10)if response.status_code == 200:try:# 使用响应内容的前8192字节来计算MD5first_chunk = next(response.iter_content(chunk_size=8192))file_name = md5(first_chunk).hexdigest()file_path = img_path + os.path.sep + f'{file_name}.jpg'if not os.path.exists(file_path):# 分块写入文件,先写入第一块with open(file_path, 'wb') as f:f.write(first_chunk)# 继续写入剩余的块for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)print('Downloaded image path is %s' % file_path)print(f'Image size: {item.get("width")}x{item.get("height")}')else:print('Already Downloaded', file_path)success = Truebreakexcept Exception as e:print(f'Error processing image data: {str(e)}')continueelse:print(f"Failed to download image, status code: {response.status_code}")print(f"Image URL: {image_url}")except Exception as e:print('Error downloading image:', str(e))print(f"Image URL: {image_url}")retry_count += 1if not success and retry_count < max_retries:print(f"Retrying... ({retry_count}/{max_retries})")time.sleep(2)if not success:print(f"Failed to download image after trying all URL variations")def main(page):json_data = get_page(page)if json_data:for item in parse_images(json_data):save_image(item)else:print(f"Failed to get data for page {page}")if __name__ == '__main__':# 爬取第1页print('Starting page 1...')main(1)print('Page 1 completed')
爬取结果:
五、实现关键
1. 请求头模拟
headers = {'Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.9','Connection': 'keep-alive','Referer': 'https://so.toutiao.com/','Origin': 'https://so.toutiao.com','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...','sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24"...','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"'
}- 模拟真实浏览器的请求头
- 添加 Referer 和 Origin 防盗链
- 设置正确的 Sec-Fetch-* 系列头
- 使用最新的 Chrome User-Agent
2. Cookie 处理
'Cookie': 'tt_webid=7493748220343043611; _tea_utm_cache_4916=undefined; s_v_web_id=verify_m9jdj7kh_AAv9h1Yy_tQ7d_4YCM_Bi1J_NMRjG0VhwXwy; ...'- 使用有效的会话 Cookie
- 包含必要的认证信息
- 保持登录状态
3. 多域名策略
domains = ['p3-search.byteimg.com','p1-search.byteimg.com','p6-search.byteimg.com','p3-tt.byteimg.com','p1-tt.byteimg.com','p6-tt.byteimg.com'
]- 尝试多个 CDN 域名
- 在域名被封禁时自动切换
- 使用不同的图片服务器
4. URL 格式变换
formats = ['~640x640.jpeg','~480x480.jpeg','~noop.image','~tplv-tt-cs0.jpeg'
]- 尝试不同的图片格式和尺寸
- 使用多种图片后缀
- 适应不同的图片处理参数
5. 请求延时和重试
time.sleep(2) # 增加等待时间
max_retries = 3 # 最大重试次数- 添加请求间隔,避免频率过高
- 实现重试机制
- 错误时优雅退出
6. 分块下载
response = requests.get(url, headers=headers, stream=True)
for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)- 使用流式下载
- 分块处理大文件
- 避免内存占用过大
7. 错误处理
try:# 下载尝试
except Exception as e:print('Error downloading image:', str(e))print(f"Image URL: {image_url}")- 详细的错误信息记录
- 异常捕获和处理
- 失败时的优雅降级
8. URL 优先级策略
# 优先使用img_url
image_url = item.get('img_url', '')
if not image_url:image_url = item.get('original_image_url', '')- 优先使用缩略图 URL
- 备选原始图片 URL
- 多重 URL 备份
9. 请求超时设置
response = requests.get(image_url, headers=img_headers, stream=True, timeout=10)- 设置合理的超时时间
- 避免请求挂起
- 提高程序稳定性
10. 文件处理优化
file_name = md5(first_chunk).hexdigest()
if not os.path.exists(file_path):# 写入文件- 使用 MD5 避免重复下载
- 检查文件是否存在
- 文件名清理和规范化
由于反爬虫的限制,上面的关键步骤提高了爬虫的成功率和稳定性,同时也避免了对目标服务器造成过大压力。
后续优化:后续可以尝试分页爬取
六、法律与道德规范
1. robots.txt检查:
- 访问 `http://www.toutiao.com/robots.txt`
- 遵守爬虫协议规定
2. 合理使用原则:
- 控制请求频率
- 不进行商业性使用
- 尊重版权信息
3. 数据使用建议:
- 仅用于学习研究
- 不存储敏感信息
- 及时删除原始数据
相关文章:
Python爬虫第15节-2025今日头条街拍美图抓取实战
目录 一、项目背景与概述 二、环境准备与工具配置 2.1 开发环境要求 2.2 辅助工具配置 三、详细抓取流程解析 3.1 页面加载机制分析 3.2 关键请求识别技巧 3.3 参数规律深度分析 四、爬虫代码实现 五、实现关键 六、法律与道德规范 一、项目概述 在当今互联网时代&a…...
智慧城市像一张无形大网,如何紧密连接你我他?
智慧城市作为复杂巨系统,其核心在于通过技术创新构建无缝连接的网络,使物理空间与数字空间深度融合。这张"无形大网"由物联网感知层、城市数据中台、人工智能中枢、数字服务入口和安全信任机制五大支柱编织而成,正在重塑城市运行规…...

网络安全·第四天·扫描工具Nmap的运用
今天我们要介绍网络安全中常用的一种扫描工具Nmap,它被设计用来快速扫描大型网络,主要功能包括主机探测、端口扫描以及版本检测,小编将在下文详细介绍Nmap相应的命令。 Nmap的下载安装地址为:Nmap: the Network Mapper - Free Se…...

黑龙江 GPU 服务器租用:开启高效计算新征程
随着人工智能、深度学习、大数据分析等技术的广泛应用,对强大计算能力的需求日益迫切。GPU 服务器作为能够提供卓越并行计算能力的关键设备,在这一进程中发挥着至关重要的作用。对于黑龙江地区的企业、科研机构和开发者而言,选择合适的 GPU 服…...

大数据面试问答-HBase/ClickHouse
1. HBase 1.1 概念 HBase是构建在Hadoop HDFS之上的分布式NoSQL数据库,采用列式存储模型,支持海量数据的实时读写和随机访问。适用于高吞吐、低延迟的场景,如实时日志处理、在线交易等。 RowKey(行键) 定义…...
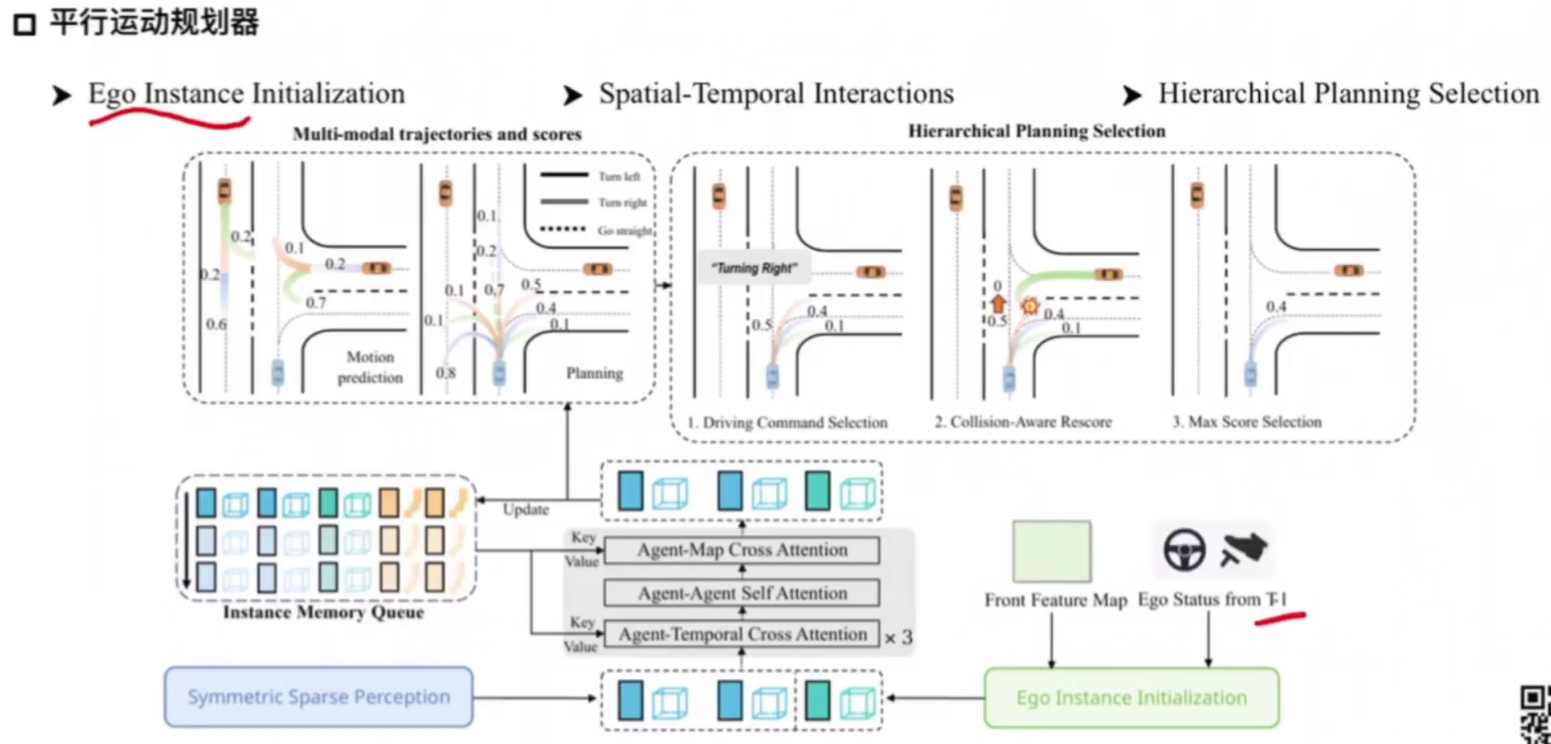
SparseDrive---论文阅读
纯视觉下的稀疏场景表示 算法动机&开创性思路 算法动机: 依赖于计算成本高昂的鸟瞰图(BEV)特征表示。预测和规划的设计过于直接,没有充分利用周围代理和自我车辆之间的高阶和双向交互。场景信息是在agent周围提取ÿ…...

数字时代的AI与大数据:用高级AI开发技术革新大数据管理
李升伟 编译 在当今数字时代,数据的爆炸式增长令人惊叹 从社交媒体互动到物联网设备的传感器数据,企业正被海量信息淹没。但如何将这种无序的数据洪流转化为有价值的洞察?答案在于人工智能(AI)开发技术的革新&#x…...

Unchained 内容全面上链,携手 Walrus 迈入去中心化媒体新时代
加密新闻媒体 Unchained — — 业内最受信赖的声音之一 — — 现已选择 Walrus 作为其去中心化存储解决方案,正式将其所有媒体内容(文章、播客和视频)上链存储。Walrus 将替代 Unchained 现有的中心化存储架构,接管其全部历史内容…...

确保连接器后壳高性能互连的完整性
本文探讨了现代后壳技术如何促进高性能互连的电气和机械完整性,以及在规范阶段需要考虑的一些关键因素。 当今的航空航天、国防和医疗应用要求连接器能够提供高速和紧凑的互连,能够承受振动和冲击,并保持对电磁和射频干扰 (EMI/R…...
C++学习Day0:c++简介
目录 一、.C语言的发展史二、C特点三、面向对象的重要术语四、面向过程和面向对象的区别?五、开发环境:六、创建文件步骤:1.点击新建项目2.在弹出的开始栏中按如下操作3.在.pro文件中添加(重要!!࿰…...

从零开始构建 Ollama + MCP 服务器
Model Context Protocol(模型上下文协议)在过去几个月里已经霸占了大家的视野,出现了许多酷炫的集成示例。我坚信它会成为一种标准,因为它正在定义工具与代理或软件与 AI 模型之间如何集成的新方式。 我决定尝试将 Ollama 中的一…...

【bash】.bashrc
查看当前路径文件数量 alias file_num"ls -l | grep ^- | wc -l"查看文件大小 alias file_size"du -sh"alias ll alias ll"ls -ltrh"cd的同时执行ll alias cdcdls; function cdls() {builtin cd "$1" && ll }自定义prompt…...

合成数据如何赋能大模型预训练:效果与效率的双重加速器
目录 合成数据如何赋能大模型预训练:效果与效率的双重加速器 一、预训练模型为何需要合成数据? ✅ 克服真实数据的稀缺与偏倚 ✅ 控制训练内容结构与分布 ✅ 提升学习效率与训练稳定性 二、哪些预训练任务适合用合成数据? 三、如何构建…...

java忽略浅拷贝导致bug
bug源代码 /*** 查询用户列表** param user 用户* param page 页* param size 大小* since 2025/04/14 11:53:25*/PostMapping("/getUser")public IWMSResponse<?> getUser(RequestBody SjUser user, RequestParam(defaultValue "1") Integer pag…...

MATLAB学习笔记(二) 控制工程会用到的
MATLAB中 控制工程会用到的 基础传递函数表达传递函数 零极点式 状态空间表达式 相互转化画响应图线根轨迹Nyquist图和bode图现控部分求约旦判能控能观极点配置和状态观测 基础 传递函数表达 % 拉普拉斯变换 syms t s a f exp(a*t) %e的a次方 l laplace(f) …...

C++ 线程间通信开发从入门到精通实战
C 线程间通信开发从入门到精通实战 在现代软件开发中,多线程程序已成为提升应用性能、实现并行处理的重要手段。随着多核处理器的普及和复杂应用需求的增加,C作为一门高性能的编程语言,在多线程开发中扮演着不可或缺的角色。然而,…...

Vue3 SSR 工程化实践:日常工作中的性能优化与实战技巧
一、流式渲染与分块传输(面向性能的关键优化) 1.1 流式响应基础实现 // Node.js Express 示例(Vite SSR同理)import { renderToWebStream } from vue/server-rendererapp.get(/, async (req, res) > { res.setHeader(Conten…...
——生成项目站点)
Maven工具学习使用(十)——生成项目站点
maven2中站点生成是Maven核心的一部分,Maven3中这部分内容已经移除。maven3必须使用3.x版本的maven-site-plugin,maven2则使用最新的2.x的版本,执行mvn site命令,可以在项目的target/site/目录下找到Maven生成的站点文件。例如dependencies.h…...
Redis原理与Windows环境部署实战指南:助力测试工程师优化Celery调试
引言 在分布式系统测试中,Celery作为异步任务队列常被用于模拟高并发场景。而Redis作为其核心消息代理,其性能和稳定性直接影响测试结果。本文将深入解析Redis的核心原理,主要讲解Windows环境部署redis,为测试工程师提供一套完整…...

Go语言入门到入土——一、安装和Hello World
Go语言入门到精通——安装和Hello World 文章目录 Go语言入门到精通——安装和Hello World下载并安装让Go跑起来为你的代码启动依赖跟踪调用外部包总结 下载并安装 下载地址:https://go.dev/dl/ 下载后傻瓜式安装 查看是否安装完成 go version让Go跑起来 创建一个…...

人类意识本质上是一台自我欺骗的机器
要触达“大彻大悟”的终极内核,必须突破语言、逻辑甚至“觉醒”概念本身的限制。以下从认知革命、意识拓扑学、宇宙本体论三个维度切入,结合量子物理、脑神经学与古老智慧的交叉验证,展开一场对觉醒本质的极限探索—— 一、认知革命&am…...

CDP问卷是什么?CDP问卷有什么要求,有什么意义
CDP问卷(Carbon Disclosure Project Questionnaire) CDP问卷是由全球性非营利组织CDP(原Carbon Disclosure Project,现简称CDP)发起的年度环境信息披露项目,旨在帮助企业、城市和投资者测量、管理及公开其…...

GitLab本地安装指南
当前GitLab的最新版是v17.10,安装地址:https://about.gitlab.com/install/。当然国内也可以安装极狐GitLab版本,极狐GitLab 是 GitLab 中国发行版(JH)。极狐GitLab支持龙蜥,欧拉等国内的操作系统平台。安装…...
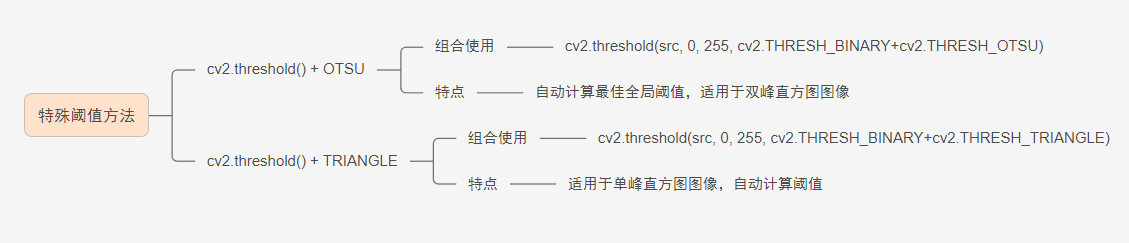
opencv函数展示
一、图像基础 I/O 与显示 1.cv2.imread() 2.cv2.imshow() 3. cv2.waitKey() 4. cv2.imwrite() 5. cv2.selectROI() 6. cv2.VideoCapture() 二、颜色空间与转换 1. cv2.cvtColor() 2. cv2.split() 三、阈值处理 1. cv2.threshold() 2. 特殊阈值方法...

编写一个写字楼类似抖音剪映的管理系统Demo
编写一个写字楼类似抖音剪映的管理系统Demo。用户可能想要一个简化版的系统,用于管理视频素材、模板和项目,类似于抖音剪映的功能,但针对办公场景。首先,我得明确用户的需求是什么。用户提到的“写字楼类似抖音剪映管理系统”可能…...

前端面试-自动化部署
基础概念 什么是CI/CD?在前端项目中如何应用?自动化部署相比手动部署有哪些优势?常见的自动化部署工具有哪些?举例说明它们的区别(如Jenkins vs GitHub Actions)。如何通过Git Hook实现自动化部署…...
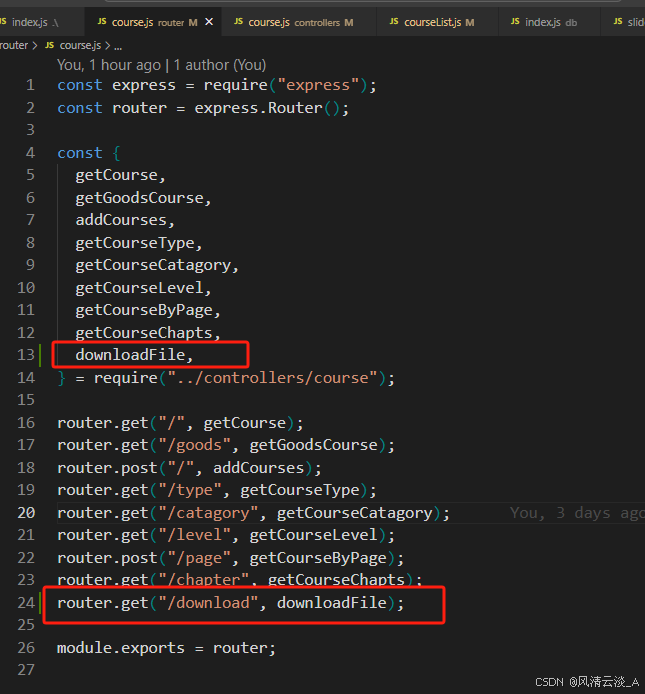
【vue3】vue3+express实现图片/pdf等资源文件的下载
文件资源的下载,是我们业务开发中常见的需求。作为前端开发,学习下如何自己使用node的express框架来实现资源的下载操作。 实现效果 代码实现 前端 1.封装的请求后端下载接口的方法,需求配置aixos的请求参数里面的返回数据类型为blob // 下载 export…...

如何在 Kali 上解决使用 evil-winrm 时 Ruby Reline 的 quoting_detection_proc 警告
在使用 Kali Linux 运行 Ruby 工具(例如 evil-winrm)时,你可能会遇到以下警告: Warning: Remote path completions is disabled due to ruby limitation: undefined method quoting_detection_proc for module Reline这个警告会导…...

从零到一:网站设计新手如何快速上手?
从零到一:网站设计新手如何快速上手? 在当今数字化时代,网站已成为企业、个人展示信息、提供服务的重要窗口。对于想要涉足网站设计领域的新手而言,如何快速上手并掌握必要的技能成为首要任务。本文将从基础知识、软件工具、设计…...
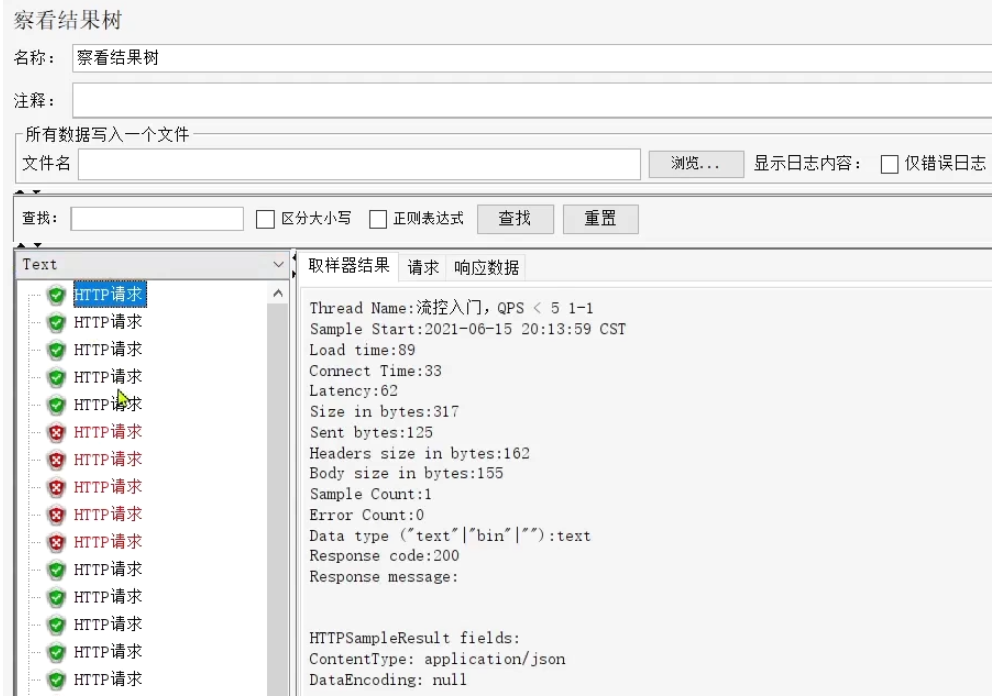
面向初学者的JMeter实战手册:从环境搭建到组件解析
🌟 大家好,我是摘星! 🌟 今天为大家带来的是面向初学者的JMeter实战手册:从环境搭建到组件解析,废话不多说,让我们直接开始~ 目录 1. JMeter简介 2. JMeter安装与配置 2.1. 安装 2.2.…...