C++ 线程间通信开发从入门到精通实战

C++ 线程间通信开发从入门到精通实战
在现代软件开发中,多线程程序已成为提升应用性能、实现并行处理的重要手段。随着多核处理器的普及和复杂应用需求的增加,C++作为一门高性能的编程语言,在多线程开发中扮演着不可或缺的角色。然而,多线程编程的复杂性也随之增加,其中最具挑战性的部分之一便是线程间通信。本文将深入探讨C++中线程间通信的基本概念、实现方法及优化技巧,并通过详实的实战案例,帮助开发者从入门到精通,构建高效、稳定的多线程应用。
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,qt,python等,具备多种混合语言开发能力。撰写博客分享知识,致力于帮助编程爱好者共同进步。欢迎关注、交流及合作,提供技术支持与解决方案。
技术合作请加本人wx(注明来自csdn):xt20160813

目录
- 线程间通信基础概念
- 什么是线程间通信
- 线程间通信的重要性
- C++中的线程间通信方法
- 互斥锁(Mutex)
- 条件变量(Condition Variable)
- 原子操作(Atomic Operations)
- 读写锁(Read-Write Locks)
- 信号量(Semaphores)
- 线程安全队列(Thread-safe Queues)
- 高效使用线程间通信的技巧
- 避免死锁
- 最小化锁的粒度
- 使用RAII管理锁
- 减少锁竞争
- 实战案例:生产者-消费者模型
- 案例背景
- 初始实现:使用互斥锁和条件变量
- 优化步骤一:使用线程安全队列
- 优化步骤二:减少锁的持有时间
- 优化步骤三:使用移动语义
- 优化后的实现代码
- 性能对比与分析
- 高级技巧与并发模式
- 无锁编程
- 使用C++并发库(如Intel TBB)
- 事件驱动与回调机制
- 线程间通信的调试与性能优化
- 常见问题及解决方案
- 性能分析工具
- 总结
- 参考资料
线程间通信基础概念
什么是线程间通信
**线程间通信(Inter-Thread Communication,简称ITC)**是指在多线程程序中,一个线程与另一个线程之间交换信息或数据的过程。由于多个线程共享同一进程的地址空间,线程间通信需要协调访问共享资源,确保数据的一致性和完整性。
线程间通信的重要性
多线程程序通过并行执行多个任务,显著提升了应用的响应速度和资源利用率。然而,当多个线程需要共享数据或资源时,如何有效地进行通信和同步,成为确保程序正确性和高效性的关键。良好的线程间通信机制不仅能避免数据竞争、死锁等问题,还能提升程序的整体性能和可维护性。
C++中的线程间通信方法
C++11引入了标准线程库(<thread>、<mutex>、<condition_variable>等),极大地简化了多线程编程。然而,线程间通信的实现依然需要开发者深入理解同步原语及其应用场景。以下将详细介绍C++中常用的线程间通信方法。
互斥锁(Mutex)
**互斥锁(Mutex)**是用于保护共享资源,防止多个线程同时访问而导致数据不一致的同步原语。在C++中,std::mutex是最常用的互斥锁类型。
示例代码:
#include <iostream>
#include <thread>
#include <mutex>using namespace std;int counter = 0;
mutex mtx;void increment(int id) {for(int i = 0; i < 1000; ++i) {// 加锁保护共享资源mtx.lock();++counter;mtx.unlock();}cout << "Thread " << id << " finished.\n";
}int main() {thread t1(increment, 1);thread t2(increment, 2);t1.join();t2.join();cout << "Final counter value: " << counter << endl;return 0;
}
输出:
Thread 1 finished.
Thread 2 finished.
Final counter value: 2000
说明:
mtx.lock()和mtx.unlock()分别用于加锁和解锁。- 这种手动管理锁的方式容易导致忘记解锁或异常情况下未能解锁,进而引发死锁。
改进:使用std::lock_guard:
std::lock_guard是RAII风格的互斥锁管理器,可以自动管理锁的加锁和解锁,大大提高代码的安全性。
#include <iostream>
#include <thread>
#include <mutex>using namespace std;int counter = 0;
mutex mtx;void increment(int id) {for(int i = 0; i < 1000; ++i) {// 使用lock_guard自动管理锁lock_guard<mutex> lock(mtx);++counter;}cout << "Thread " << id << " finished.\n";
}int main() {thread t1(increment, 1);thread t2(increment, 2);t1.join();t2.join();cout << "Final counter value: " << counter << endl;return 0;
}
输出:
Thread 1 finished.
Thread 2 finished.
Final counter value: 2000
优点:
- 自动管理锁的生命周期,确保锁被正确释放。
- 减少手动加锁和解锁的错误。
条件变量(Condition Variable)
**条件变量(Condition Variable)**用于实现线程之间的等待与通知机制。当某个条件满足时,线程可以被唤醒继续执行。std::condition_variable是C++标准库中提供的条件变量实现。
示例代码:生产者-消费者模型中的条件变量
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <chrono>using namespace std;queue<int> dataQueue;
mutex mtx;
condition_variable cv;
bool done = false;void producer(int numItems) {for(int i = 1; i <= numItems; ++i) {{lock_guard<mutex> lock(mtx);dataQueue.push(i);cout << "Producer produced: " << i << endl;}cv.notify_one(); // 通知消费者this_thread::sleep_for(chrono::milliseconds(100)); // 模拟生产时间}{lock_guard<mutex> lock(mtx);done = true;}cv.notify_all(); // 通知所有消费者工作完成
}void consumer(int id) {while(true) {unique_lock<mutex> lock(mtx);cv.wait(lock, []{ return !dataQueue.empty() || done; }); // 等待条件满足if(!dataQueue.empty()) {int data = dataQueue.front();dataQueue.pop();lock.unlock();cout << "Consumer " << id << " consumed: " << data << endl;}else if(done) {break; // 生产完成,退出循环}}cout << "Consumer " << id << " finished.\n";
}int main() {thread prod(producer, 10);thread cons1(consumer, 1);thread cons2(consumer, 2);prod.join();cons1.join();cons2.join();cout << "All threads finished.\n";return 0;
}
输出:
Producer produced: 1
Consumer 1 consumed: 1
Producer produced: 2
Consumer 2 consumed: 2
...
Producer produced: 10
Consumer 1 consumed: 10
Consumer 1 finished.
Consumer 2 finished.
All threads finished.
说明:
- 生产者线程向队列中插入数据,并使用
cv.notify_one()通知一个消费者线程。 - 消费者线程使用
cv.wait()等待生产者生产数据,当队列不为空或生产完成时被唤醒。 - 当生产完成后,生产者设置
done = true并通知所有消费者,消费者在发现done为true且队列为空时退出。
优点:
- 有效协调多线程之间的等待与通知,避免忙等(busy-wait)。
- 确保消费者在有数据时被唤醒,提升资源利用率。
原子操作(Atomic Operations)
**原子操作(Atomic Operations)**提供了一种无锁的同步机制,适用于简单的同步需求,如计数器累加。C++11中的std::atomic模板类用于实现原子操作。
示例代码:使用原子变量实现线程安全计数器
#include <iostream>
#include <thread>
#include <atomic>using namespace std;atomic<int> counter(0);void increment(int id) {for(int i = 0; i < 1000; ++i) {++counter; // 原子操作,线程安全}cout << "Thread " << id << " finished.\n";
}int main() {thread t1(increment, 1);thread t2(increment, 2);t1.join();t2.join();cout << "Final counter value: " << counter.load() << endl;return 0;
}
输出:
Thread 1 finished.
Thread 2 finished.
Final counter value: 2000
说明:
std::atomic提供了原子性,确保多个线程对同一变量的操作不会造成数据竞争。- 适用于简单的同步需求,如计数器、标志位等,不需要使用互斥锁。
优点:
- 无锁同步,减少了线程阻塞和上下文切换的开销。
- 提供了简单、高效的线程安全操作。
缺点:
- 仅适用于简单的同步场景,复杂的数据结构和操作仍需使用互斥锁或其他同步原语。
- 需要开发者理解内存模型,避免因内存顺序不当引发的潜在问题。
读写锁(Read-Write Locks)
**读写锁(Read-Write Locks)**允许多个线程同时读取共享资源,但在写入时独占资源。std::shared_mutex(C++17引入)是C++标准库中提供的读写锁实现。
示例代码:使用读写锁优化多读少写场景
#include <iostream>
#include <thread>
#include <shared_mutex>
#include <vector>
#include <chrono>using namespace std;vector<int> data;
shared_mutex rw_mtx;void reader(int id) {for(int i = 0; i < 5; ++i) {{shared_lock<shared_mutex> lock(rw_mtx);cout << "Reader " << id << " read data size: " << data.size() << endl;}this_thread::sleep_for(chrono::milliseconds(100));}
}void writer(int id, int numItems) {for(int i = 0; i < numItems; ++i) {{unique_lock<shared_mutex> lock(rw_mtx);data.push_back(i);cout << "Writer " << id << " added: " << i << endl;}this_thread::sleep_for(chrono::milliseconds(150));}
}int main() {thread r1(reader, 1);thread r2(reader, 2);thread w1(writer, 1, 5);r1.join();r2.join();w1.join();cout << "Final data size: " << data.size() << endl;return 0;
}
输出:
Reader 1 read data size: 0
Reader 2 read data size: 0
Writer 1 added: 0
Reader 1 read data size: 1
Reader 2 read data size: 1
Writer 1 added: 1
...
Final data size: 5
说明:
- 使用
shared_lock允许多个读者同时持有锁,提高读取性能。 - 使用
unique_lock确保写者独占锁,防止数据竞争。 - 适用于多读少写的场景,显著优化了程序的并发性能。
优点:
- 提高了多读的并发性能,避免了读操作的阻塞。
- 确保写操作的独占性,维护了数据的一致性。
缺点:
- 在多写或多读写交替频繁的场景下,性能提升有限。
- 增加了代码的复杂性,需要合理管理锁的获取和释放。
信号量(Semaphores)
**信号量(Semaphores)**是一种用于控制多个线程同时访问有限资源的同步原语。虽然C++20引入了std::counting_semaphore,但在C++11/14/17中需要使用第三方库或自行实现。
示例代码:使用C++20的信号量实现简单同步
#include <iostream>
#include <thread>
#include <semaphore>using namespace std;counting_semaphore<1> semaphore(1); // 二元信号量,相当于互斥锁int sharedResource = 0;void task(int id) {cout << "Thread " << id << " waiting to access shared resource.\n";semaphore.acquire(); // 获取信号量cout << "Thread " << id << " acquired shared resource.\n";// 访问共享资源sharedResource += id;cout << "Thread " << id << " updated shared resource to " << sharedResource << ".\n";semaphore.release(); // 释放信号量cout << "Thread " << id << " released shared resource.\n";
}int main() {thread t1(task, 1);thread t2(task, 2);t1.join();t2.join();cout << "Final shared resource value: " << sharedResource << endl;return 0;
}
输出:
Thread 1 waiting to access shared resource.
Thread 1 acquired shared resource.
Thread 1 updated shared resource to 1.
Thread 1 released shared resource.
Thread 2 waiting to access shared resource.
Thread 2 acquired shared resource.
Thread 2 updated shared resource to 3.
Thread 2 released shared resource.
Final shared resource value: 3
说明:
counting_semaphore用于控制对共享资源的访问,确保同一时间只有一个线程可以访问。- 适用于需要控制同时访问数量的场景,如限流、资源池等。
注意:
- 在C++11/14/17中,需要自行实现信号量或使用第三方库,如Boost.Semaphore。
线程安全队列(Thread-safe Queues)
线程安全队列是一种将生产者与消费者线程连接起来的高效数据结构。它内部管理同步机制,确保多线程环境下的安全操作。
示例代码:实现一个简单的线程安全队列
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>using namespace std;// 线程安全队列模板类
template<typename T>
class ThreadSafeQueue {
public:ThreadSafeQueue() {}// 禁止拷贝ThreadSafeQueue(const ThreadSafeQueue&) = delete;ThreadSafeQueue& operator=(const ThreadSafeQueue&) = delete;// 入队void enqueue(T value) {{lock_guard<mutex> lock(mtx);q.push(move(value));}cv.notify_one();}// 出队,返回是否成功bool dequeue(T& value) {unique_lock<mutex> lock(mtx);cv.wait(lock, [this]{ return !q.empty() || done; });if(q.empty()) return false;value = move(q.front());q.pop();return true;}// 标记完成void setDone() {{lock_guard<mutex> lock(mtx);done = true;}cv.notify_all();}private:queue<T> q;mutable mutex mtx;condition_variable cv;bool done = false;
};// 生产者函数
void producer(ThreadSafeQueue<int>& tsq, int numItems) {for(int i = 1; i <= numItems; ++i) {tsq.enqueue(i);cout << "Producer enqueued: " << i << endl;this_thread::sleep_for(chrono::milliseconds(100));}tsq.setDone();
}// 消费者函数
void consumer(ThreadSafeQueue<int>& tsq, int id) {int data;while(tsq.dequeue(data)) {cout << "Consumer " << id << " processed: " << data << endl;}cout << "Consumer " << id << " finished.\n";
}int main() {ThreadSafeQueue<int> tsq;int numItems = 10;thread prod(producer, ref(tsq), numItems);thread cons1(consumer, ref(tsq), 1);thread cons2(consumer, ref(tsq), 2);prod.join();cons1.join();cons2.join();cout << "All threads finished.\n";return 0;
}
输出:
Producer enqueued: 1
Consumer 1 processed: 1
Producer enqueued: 2
Consumer 2 processed: 2
...
Producer enqueued: 10
Consumer 1 processed: 10
Consumer 1 finished.
Consumer 2 finished.
All threads finished.
说明:
- 使用
ThreadSafeQueue将生产者与多个消费者连接起来,确保数据在多线程环境下的安全传递。 - 生产者在完成生产后调用
setDone()通知消费者无需等待更多数据,消费者在队列为空且done为true时退出循环。
优点:
- 简化了生产者-消费者之间的同步逻辑。
- 提高了数据传递的效率和安全性。
高效使用线程间通信的技巧
在多线程编程中,正确、高效地使用线程间通信原语,能够显著提升程序的性能和稳定性。以下是一些关键的优化技巧。
避免死锁
**死锁(Deadlock)**发生在两个或多个线程互相等待对方释放资源,导致程序无法继续执行。避免死锁是多线程编程中的重要课题。
避免策略:
- 固定锁的获取顺序:确保所有线程以相同的顺序获取多个锁,防止循环等待。
- 使用
std::lock:同时获取多个互斥锁,以防止死锁。 - 设定锁的超时时间:如果无法在规定时间内获取锁,可以选择放弃或重试,避免永久阻塞。
示例代码:避免死锁的固定锁顺序
#include <iostream>
#include <thread>
#include <mutex>using namespace std;mutex mtx1, mtx2;void threadA() {lock_guard<mutex> lock1(mtx1);this_thread::sleep_for(chrono::milliseconds(100));lock_guard<mutex> lock2(mtx2);cout << "Thread A acquired both locks.\n";
}void threadB() {lock_guard<mutex> lock1(mtx1);this_thread::sleep_for(chrono::milliseconds(100));lock_guard<mutex> lock2(mtx2);cout << "Thread B acquired both locks.\n";
}int main() {thread t1(threadA);thread t2(threadB);t1.join();t2.join();cout << "No deadlock occurred.\n";return 0;
}
说明:
- 线程A和线程B都按照相同的顺序获取
mtx1和mtx2,避免了循环等待,防止死锁。
最小化锁的粒度
锁的粒度指的是锁所保护的代码范围和资源范围。较小的锁粒度可以减少锁的持有时间和等待时间,提高并发性能。
优化方法:
- 细化锁的保护范围:仅对必要的共享资源进行保护,避免不必要的锁定。
- 分段锁(Sharding Locks):将资源分成多个独立部分,每部分使用单独的锁,提高并发度。
示例代码:细化锁的保护范围
#include <iostream>
#include <thread>
#include <mutex>
#include <vector>using namespace std;vector<int> data;
mutex mtx;void pushData(int id) {for(int i = 0; i < 100; ++i) {// 仅对写操作加锁{lock_guard<mutex> lock(mtx);data.push_back(id * 100 + i);}// 读操作不需要锁// cout << "Thread " << id << " pushed: " << id * 100 + i << endl;}
}int main() {thread t1(pushData, 1);thread t2(pushData, 2);thread t3(pushData, 3);t1.join();t2.join();t3.join();cout << "Data size: " << data.size() << endl;return 0;
}
说明:
- 仅在执行写操作时加锁,读操作不涉及共享资源的修改,因此无需加锁,减少了锁的持有时间。
- 提高了程序的并发性能。
使用RAII管理锁
**RAII(Resource Acquisition Is Initialization)**是一种编程习惯,通过对象的构造和析构自动管理资源(如互斥锁的加锁与解锁),避免资源泄漏和管理错误。
示例代码:使用std::lock_guard管理锁
#include <iostream>
#include <thread>
#include <mutex>using namespace std;int counter = 0;
mutex mtx;void increment(int id) {for(int i = 0; i < 1000; ++i) {// lock_guard自动管理锁lock_guard<mutex> lock(mtx);++counter;}cout << "Thread " << id << " finished.\n";
}int main() {thread t1(increment, 1);thread t2(increment, 2);t1.join();t2.join();cout << "Final counter value: " << counter << endl;return 0;
}
说明:
- 使用
lock_guard对象的生命周期自动管理锁的加锁和解锁,确保即使在异常情况下锁也能被正确释放。 - 提高了代码的安全性和可读性。
减少锁竞争
**锁竞争(Lock Contention)**指的是多个线程同时尝试获取同一个锁,导致等待和性能下降。减少锁竞争是提升多线程程序性能的重要策略。
优化方法:
- 减少锁的持有时间:尽量在锁内执行少量必要的操作,缩短锁的持有时间。
- 分离读写操作:使用读写锁,允许多线程并行读取资源。
- 使用无锁数据结构:通过原子操作和内存屏障,避免使用互斥锁。
示例代码:使用读写锁减少锁竞争
#include <iostream>
#include <thread>
#include <shared_mutex>
#include <vector>
#include <chrono>using namespace std;vector<int> data;
shared_mutex rw_mtx;void reader(int id) {for(int i = 0; i < 5; ++i) {shared_lock<shared_mutex> lock(rw_mtx);cout << "Reader " << id << " sees data size: " << data.size() << endl;this_thread::sleep_for(chrono::milliseconds(100));}
}void writer(int id) {for(int i = 0; i < 5; ++i) {unique_lock<shared_mutex> lock(rw_mtx);data.push_back(id * 100 + i);cout << "Writer " << id << " added: " << id * 100 + i << endl;this_thread::sleep_for(chrono::milliseconds(150));}
}int main() {thread r1(reader, 1);thread r2(reader, 2);thread w1(writer, 1);thread w2(writer, 2);r1.join();r2.join();w1.join();w2.join();cout << "Final data size: " << data.size() << endl;return 0;
}
说明:
- 使用
std::shared_mutex,允许多个读者同时持有共享锁,而写者需要独占锁,减少了锁竞争。 - 提升了程序的并发性能,读操作可以并行执行,只有在写操作需要独占时才阻塞。
实战案例:生产者-消费者模型
生产者-消费者模型是多线程编程中经典的同步问题,广泛应用于数据流处理、任务调度等场景。以下将通过一个具体的C++实战案例,详细讲解如何实现高效的生产者-消费者模型,并逐步优化其性能。
案例背景
假设我们需要处理大量的数据生产和消费任务。生产者线程负责生成数据,消费者线程负责处理数据。为了保证数据的安全传递和高效处理,我们需要实现一个线程间通信机制,确保生产者和消费者能够协同工作。
初始实现:使用互斥锁和条件变量
在初始实现中,我们使用std::mutex和std::condition_variable来管理生产者和消费者之间的数据传递。
实现代码:
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <chrono>using namespace std;queue<int> dataQueue;
mutex mtx;
condition_variable cv;
bool done = false;// 生产者函数
void producer(int numItems) {for(int i = 1; i <= numItems; ++i) {// 加锁并入队{lock_guard<mutex> lock(mtx);dataQueue.push(i);cout << "Producer produced: " << i << endl;}cv.notify_one(); // 通知消费者this_thread::sleep_for(chrono::milliseconds(100)); // 模拟生产时间}// 标记生产完成{lock_guard<mutex> lock(mtx);done = true;}cv.notify_all(); // 通知所有消费者
}// 消费者函数
void consumer(int id) {while(true) {unique_lock<mutex> lock(mtx);// 等待条件满足(队列非空或生产完成)cv.wait(lock, []{ return !dataQueue.empty() || done; });if(!dataQueue.empty()) {int data = dataQueue.front();dataQueue.pop();lock.unlock(); // 解锁后处理数据cout << "Consumer " << id << " consumed: " << data << endl;}else if(done) {break; // 生产完成,退出循环}}cout << "Consumer " << id << " finished.\n";
}int main() {int numItems = 10;thread prod(producer, numItems);thread cons1(consumer, 1);thread cons2(consumer, 2);prod.join();cons1.join();cons2.join();cout << "All threads finished.\n";return 0;
}
输出示例:
Producer produced: 1
Consumer 1 consumed: 1
Producer produced: 2
Consumer 2 consumed: 2
...
Producer produced: 10
Consumer 1 consumed: 10
Consumer 1 finished.
Consumer 2 finished.
All threads finished.
说明:
- 生产者:生成数据并放入共享队列,通知消费者线程新数据的到来。
- 消费者:等待数据的到来,消费数据,直到生产完成。
- 使用
std::mutex保护共享队列,使用std::condition_variable实现线程间的等待与通知。
潜在问题:
- 每次生产一个数据后,都需要加锁和通知,导致锁的频繁获取和释放,影响性能。
- 使用原子变量
done和标志位,增加了代码的复杂性。 - 当生产者和消费者数量增多时,性能可能成为瓶颈。
优化步骤一:使用线程安全队列
为了减少锁的管理复杂性和提高代码的可复用性,我们可以实现一个封装好的线程安全队列。
实现代码:线程安全队列模板类
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <chrono>using namespace std;// 线程安全队列模板类
template<typename T>
class ThreadSafeQueue {
public:ThreadSafeQueue() {}// 禁止拷贝构造和赋值ThreadSafeQueue(const ThreadSafeQueue&) = delete;ThreadSafeQueue& operator=(const ThreadSafeQueue&) = delete;// 入队void enqueue(T value) {{lock_guard<mutex> lock(mtx_);q_.push(move(value));}cv_.notify_one();}// 出队,返回是否成功bool dequeue(T& value) {unique_lock<mutex> lock(mtx_);cv_.wait(lock, [this]{ return !q_.empty() || done_; });if(q_.empty()) return false;value = move(q_.front());q_.pop();return true;}// 标记完成void setDone() {{lock_guard<mutex> lock(mtx_);done_ = true;}cv_.notify_all();}private:queue<T> q_;mutable mutex mtx_;condition_variable cv_;bool done_ = false;
};// 生产者函数
void producer(ThreadSafeQueue<int>& tsq, int numItems) {for(int i = 1; i <= numItems; ++i) {tsq.enqueue(i);cout << "Producer enqueued: " << i << endl;this_thread::sleep_for(chrono::milliseconds(100)); // 模拟生产时间}tsq.setDone();
}// 消费者函数
void consumer(ThreadSafeQueue<int>& tsq, int id) {int data;while(tsq.dequeue(data)) {cout << "Consumer " << id << " consumed: " << data << endl;}cout << "Consumer " << id << " finished.\n";
}int main() {ThreadSafeQueue<int> tsq;int numItems = 10;thread prodThread(producer, ref(tsq), numItems);thread consThread1(consumer, ref(tsq), 1);thread consThread2(consumer, ref(tsq), 2);prodThread.join();consThread1.join();consThread2.join();cout << "All threads finished.\n";return 0;
}
输出示例:
Producer enqueued: 1
Consumer 1 consumed: 1
Producer enqueued: 2
Consumer 2 consumed: 2
...
Producer enqueued: 10
Consumer 1 consumed: 10
Consumer 1 finished.
Consumer 2 finished.
All threads finished.
说明:
- 线程安全队列
ThreadSafeQueue:封装了锁和条件变量,实现了安全的入队和出队操作。 - 生产者与消费者:不再直接操作共享资源,依赖于线程安全队列进行数据传递,提高了代码的可复用性和可维护性。
优点:
- 简化了生产者和消费者的实现逻辑。
- 减少了锁管理的复杂性,降低了出错概率。
- 提高了代码的模块化和可复用性。
优化步骤二:减少锁的持有时间
通过进一步优化,我们可以减少锁的持有时间,提高程序整体性能。具体方法包括在获取锁前进行必要的检查,尽量在锁内只执行必要的操作。
优化方法:
- 提前检查:在获取锁前,通过原子变量或其他机制进行快速检查,决定是否需要进入加锁区。
- 批量处理:生产者可以一次生产多个数据,减少锁的频繁获取。
实现代码:批量入队
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <vector>
#include <chrono>using namespace std;// 线程安全队列模板类
template<typename T>
class ThreadSafeQueue {
public:ThreadSafeQueue() {}// 禁止拷贝构造和赋值ThreadSafeQueue(const ThreadSafeQueue&) = delete;ThreadSafeQueue& operator=(const ThreadSafeQueue&) = delete;// 批量入队void enqueueBatch(vector<T> values) {{lock_guard<mutex> lock(mtx_);for(auto& val : values) {q_.push(move(val));}}cv_.notify_all();}// 批量出队,返回实际出队的数量int dequeueBatch(vector<T>& values, int maxItems) {unique_lock<mutex> lock(mtx_);cv_.wait(lock, [this]{ return !q_.empty() || done_; });if(q_.empty()) return 0;int count = 0;while(!q_.empty() && count < maxItems) {values.push_back(move(q_.front()));q_.pop();++count;}return count;}// 标记完成void setDone() {{lock_guard<mutex> lock(mtx_);done_ = true;}cv_.notify_all();}private:queue<T> q_;mutable mutex mtx_;condition_variable cv_;bool done_ = false;
};// 生产者函数,批量入队
void producer(ThreadSafeQueue<int>& tsq, int numItems, int batchSize) {int current = 1;while(current <= numItems) {vector<int> batch;for(int i = 0; i < batchSize && current <= numItems; ++i, ++current) {batch.push_back(current);}tsq.enqueueBatch(move(batch));cout << "Producer enqueued batch up to: " << current - 1 << endl;this_thread::sleep_for(chrono::milliseconds(200)); // 模拟生产时间}tsq.setDone();
}// 消费者函数,批量出队
void consumer(ThreadSafeQueue<int>& tsq, int id, int batchSize) {vector<int> batch;while(tsq.dequeueBatch(batch, batchSize)) {for(auto& data : batch) {cout << "Consumer " << id << " consumed: " << data << endl;}batch.clear();}cout << "Consumer " << id << " finished.\n";
}int main() {ThreadSafeQueue<int> tsq;int numItems = 20;int producerBatchSize = 5;int consumerBatchSize = 4;thread prodThread(producer, ref(tsq), numItems, producerBatchSize);thread consThread1(consumer, ref(tsq), 1, consumerBatchSize);thread consThread2(consumer, ref(tsq), 2, consumerBatchSize);prodThread.join();consThread1.join();consThread2.join();cout << "All threads finished.\n";return 0;
}
输出示例:
Producer enqueued batch up to: 5
Consumer 1 consumed: 1
Consumer 1 consumed: 2
Consumer 1 consumed: 3
Consumer 1 consumed: 4
Consumer 2 consumed: 5
Producer enqueued batch up to: 10
...
Producer enqueued batch up to: 20
Consumer 1 consumed: 17
Consumer 1 consumed: 18
Consumer 1 consumed: 19
Consumer 1 consumed: 20
Consumer 1 finished.
Consumer 2 finished.
All threads finished.
说明:
- 生产者通过批量入队减少了锁的获取次数,提升了生产效率。
- 消费者通过批量出队提高了数据处理的连贯性,减少了锁的持有时间。
优化步骤三:使用移动语义
在现代C++中,**移动语义(Move Semantics)**可以显著提升性能,特别是在处理大对象或需要进行资源所有权转移时。通过使用std::move,可以避免不必要的拷贝操作,优化程序的执行效率。
实现代码:在队列中使用移动语义
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <vector>
#include <chrono>using namespace std;// 线程安全队列模板类,支持移动语义
template<typename T>
class ThreadSafeQueue {
public:ThreadSafeQueue() {}// 禁止拷贝构造和赋值ThreadSafeQueue(const ThreadSafeQueue&) = delete;ThreadSafeQueue& operator=(const ThreadSafeQueue&) = delete;// 入队,支持移动语义void enqueue(T value) {{lock_guard<mutex> lock(mtx_);q_.push(move(value));}cv_.notify_one();}// 出队,返回是否成功bool dequeue(T& value) {unique_lock<mutex> lock(mtx_);cv_.wait(lock, [this]{ return !q_.empty() || done_; });if(q_.empty()) return false;value = move(q_.front());q_.pop();return true;}// 标记完成void setDone() {{lock_guard<mutex> lock(mtx_);done_ = true;}cv_.notify_all();}private:queue<T> q_;mutable mutex mtx_;condition_variable cv_;bool done_ = false;
};// 生产者函数,使用移动语义入队
void producer(ThreadSafeQueue<string>& tsq, int numItems) {for(int i = 1; i <= numItems; ++i) {string data = "Data_" + to_string(i);tsq.enqueue(move(data));cout << "Producer enqueued: " << data << endl;this_thread::sleep_for(chrono::milliseconds(100)); // 模拟生产时间}tsq.setDone();
}// 消费者函数,使用移动语义出队
void consumer(ThreadSafeQueue<string>& tsq, int id) {string data;while(tsq.dequeue(data)) {cout << "Consumer " << id << " processed: " << data << endl;}cout << "Consumer " << id << " finished.\n";
}int main() {ThreadSafeQueue<string> tsq;int numItems = 10;thread prodThread(producer, ref(tsq), numItems);thread consThread1(consumer, ref(tsq), 1);thread consThread2(consumer, ref(tsq), 2);prodThread.join();consThread1.join();consThread2.join();cout << "All threads finished.\n";return 0;
}
输出示例:
Producer enqueued: Data_1
Consumer 1 processed: Data_1
Producer enqueued: Data_2
Consumer 2 processed: Data_2
...
Producer enqueued: Data_10
Consumer 1 processed: Data_10
Consumer 1 finished.
Consumer 2 finished.
All threads finished.
说明:
- 通过在入队和出队操作中使用
std::move,避免了不必要的字符串副本,优化了内存使用和执行效率。 - 特别适用于处理大对象或需要资源所有权转移的场景。
优化后的实现代码
结合上述优化策略,我们可以进一步优化生产者-消费者模型,实现高效的多线程通信。
优化后的完整代码:
#include <iostream>
#include <thread>
#include <shared_mutex>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <vector>
#include <chrono>
#include <string>
#include <atomic>
#include <functional>using namespace std;// 线程安全队列模板类,支持批量操作和移动语义
template<typename T>
class ThreadSafeQueue {
public:ThreadSafeQueue() {}// 禁止拷贝构造和赋值ThreadSafeQueue(const ThreadSafeQueue&) = delete;ThreadSafeQueue& operator=(const ThreadSafeQueue&) = delete;// 批量入队,使用移动语义void enqueueBatch(vector<T> values) {{lock_guard<mutex> lock(mtx_);for(auto& val : values) {q_.push(move(val));}}cv_.notify_all();}// 单个入队,使用移动语义void enqueue(T value) {{lock_guard<mutex> lock(mtx_);q_.push(move(value));}cv_.notify_one();}// 批量出队,返回实际出队的数量int dequeueBatch(vector<T>& values, int maxItems) {unique_lock<mutex> lock(mtx_);// 等待条件满足(队列非空或生产完成)cv_.wait(lock, [this]{ return !q_.empty() || done_; });if(q_.empty()) return 0;int count = 0;while(!q_.empty() && count < maxItems) {values.push_back(move(q_.front()));q_.pop();++count;}return count;}// 出队,返回是否成功bool dequeue(T& value) {unique_lock<mutex> lock(mtx_);cv_.wait(lock, [this]{ return !q_.empty() || done_; });if(q_.empty()) return false;value = move(q_.front());q_.pop();return true;}// 标记完成void setDone() {{lock_guard<mutex> lock(mtx_);done_ = true;}cv_.notify_all();}private:queue<T> q_;mutable mutex mtx_;condition_variable cv_;bool done_ = false;
};// 生产者函数,支持批量入队和移动语义
void producer(ThreadSafeQueue<string>& tsq, int numItems, int batchSize) {int current = 1;while(current <= numItems) {vector<string> batch;for(int i = 0; i < batchSize && current <= numItems; ++i, ++current) {string data = "Data_" + to_string(current);batch.push_back(move(data));}tsq.enqueueBatch(move(batch));cout << "Producer enqueued batch up to: " << current - 1 << endl;this_thread::sleep_for(chrono::milliseconds(200)); // 模拟生产时间}tsq.setDone();
}// 消费者函数,支持批量出队和移动语义
void consumer(ThreadSafeQueue<string>& tsq, int id, int batchSize) {while(true) {vector<string> batch;int count = tsq.dequeueBatch(batch, batchSize);if(count == 0) break; // 生产完成且队列为空for(auto& data : batch) {// 处理数据cout << "Consumer " << id << " processed: " << data << endl;}}cout << "Consumer " << id << " finished.\n";
}int main() {ThreadSafeQueue<string> tsq;int numItems = 20;int producerBatchSize = 5;int consumerBatchSize = 4;// 启动生产者线程thread prodThread(producer, ref(tsq), numItems, producerBatchSize);// 启动多个消费者线程thread consThread1(consumer, ref(tsq), 1, consumerBatchSize);thread consThread2(consumer, ref(tsq), 2, consumerBatchSize);prodThread.join();consThread1.join();consThread2.join();cout << "All threads finished.\n";return 0;
}
输出示例:
Producer enqueued batch up to: 5
Consumer 1 processed: Data_1
Consumer 1 processed: Data_2
Consumer 1 processed: Data_3
Consumer 1 processed: Data_4
Consumer 2 processed: Data_5
Producer enqueued batch up to: 10
Consumer 1 processed: Data_6
Consumer 1 processed: Data_7
Consumer 1 processed: Data_8
Consumer 1 processed: Data_9
Consumer 2 processed: Data_10
...
Producer enqueued batch up to: 20
Consumer 1 processed: Data_17
Consumer 1 processed: Data_18
Consumer 1 processed: Data_19
Consumer 1 processed: Data_20
Consumer 1 finished.
Consumer 2 finished.
All threads finished.
分析:
- 批量处理:生产者一次生产多个数据,消费者一次处理多个数据,减少了锁的获取和释放次数,提高了性能。
- 移动语义:使用
std::move避免了字符串的拷贝,优化了内存使用。 - 线程安全队列:简化了生产者和消费者的通信逻辑,提高了代码的可维护性和可扩展性。
性能对比与分析
通过初始实现和优化后的实现,可以观察到锁的管理和通信机制的优化对程序性能的影响。
初始实现:
- 生产者每生产一个数据就加锁一次,消费者每消费一个数据也需要加锁和解锁。
- 锁的频繁获取和释放导致了较高的锁管理开销,限制了程序的性能。
优化后实现:
- 生产者采用批量入队,降低了锁的获取次数。
- 消费者采用批量出队,提升了数据处理的连贯性。
- 使用移动语义减少了数据的拷贝开销。
- 线程安全队列封装了同步机制,简化了代码结构,减少了错误发生的可能。
性能提升:
- 锁管理的优化降低了程序的同步开销,提高了多线程并发的效率。
- 批量处理和移动语义的使用显著提升了数据传输和处理的性能。
高级技巧与并发模式
随着多线程编程需求的增长,C++提供了更多高级技巧和并发模式,帮助开发者构建高效、复杂的多线程应用。
无锁编程
**无锁编程(Lock-Free Programming)**旨在通过原子操作和内存屏障,避免使用互斥锁来实现线程间的同步,从而减少锁的开销和避免死锁。
示例代码:无锁栈的实现
#include <iostream>
#include <atomic>
#include <thread>
#include <vector>using namespace std;template<typename T>
class LockFreeStack {
public:LockFreeStack() : head(nullptr) {}void push(T value) {Node* newNode = new Node(move(value));newNode->next = head.load();while(!head.compare_exchange_weak(newNode->next, newNode));}bool pop(T& result) {Node* oldHead = head.load();while(oldHead && !head.compare_exchange_weak(oldHead, oldHead->next));if(oldHead) {result = move(oldHead->data);delete oldHead;return true;}return false;}private:struct Node {T data;Node* next;Node(T val) : data(move(val)), next(nullptr) {}};atomic<Node*> head;
};LockFreeStack<int> stack;void producer(int id, int numItems) {for(int i = 1; i <= numItems; ++i) {stack.push(id * 100 + i);cout << "Producer " << id << " pushed: " << id * 100 + i << endl;}
}void consumer(int id, int numItems) {int value;for(int i = 0; i < numItems; ++i) {if(stack.pop(value)) {cout << "Consumer " << id << " popped: " << value << endl;}}
}int main() {int numItems = 10;thread prod1(producer, 1, numItems);thread prod2(producer, 2, numItems);thread cons1(consumer, 1, numItems);thread cons2(consumer, 2, numItems);prod1.join();prod2.join();cons1.join();cons2.join();cout << "All threads finished.\n";return 0;
}
说明:
- 原子指针:使用
std::atomic<Node*>实现无锁操作。 - CAS操作:通过
compare_exchange_weak实现原子更改,确保多线程环境下的安全性。 - 优点:避免了锁的开销和死锁风险,适合高并发场景。
- 缺点:实现复杂,需要开发者深入理解原子操作和内存模型。
使用C++并发库(如Intel TBB)
**Intel Threading Building Blocks(TBB)**是一个高性能的C++模板库,提供了丰富的并发算法和数据结构,简化了多线程编程。
示例代码:使用TBB实现并行for
#include <iostream>
#include <vector>
#include <tbb/tbb.h>using namespace std;
using namespace tbb;int main() {const int N = 1000000;vector<int> data(N, 1);atomic<int> sum(0);// 使用TBB的parallel_for并行计算总和parallel_for(blocked_range<size_t>(0, data.size()),[&](const blocked_range<size_t>& r) {int localSum = 0;for(size_t i = r.begin(); i != r.end(); ++i) {localSum += data[i];}sum += localSum;});cout << "Total sum: " << sum.load() << endl;return 0;
}
说明:
- 并行算法:
parallel_for允许将循环迭代分配到多个线程,自动管理线程的创建和调度。 - 原子变量:使用
std::atomic<int>避免数据竞争。 - 优点:简化并行计算的实现,提升程序的性能和可扩展性。
- 缺点:需要引入第三方库,增加项目的依赖性。
事件驱动与回调机制
事件驱动编程通过回调机制处理异步事件,如用户输入、网络消息等。C++通过std::function和Lambda表达式提供了简洁的回调实现方式。
示例代码:事件驱动系统
#include <iostream>
#include <functional>
#include <vector>
#include <thread>
#include <chrono>using namespace std;// 事件类
class Event {
public:// 注册回调函数void registerCallback(function<void(string)> cb) {callbacks_.push_back(cb);}// 触发事件void trigger(string message) {cout << "Event triggered with message: " << message << endl;for(auto& cb : callbacks_) {cb(message);}}private:vector<function<void(string)>> callbacks_;
};// 回调函数A
void callbackA(string msg) {cout << "Callback A received: " << msg << endl;
}// 回调函数B,使用Lambda表达式
int main() {Event event;// 注册回调函数Aevent.registerCallback(callbackA);// 注册Lambda回调函数event.registerCallback([](string msg) {cout << "Lambda Callback received: " << msg << endl;});// 模拟触发事件this_thread::sleep_for(chrono::seconds(1));event.trigger("Hello, Event!");return 0;
}
输出示例:
Event triggered with message: Hello, Event!
Callback A received: Hello, Event!
Lambda Callback received: Hello, Event!
说明:
- 事件注册:通过
registerCallback方法注册多个回调函数,实现多个观察者模式。 - 事件触发:通过
trigger方法触发事件,调用所有注册的回调函数。 - 灵活性高:支持任意类型的回调函数,如自由函数、Lambda表达式、成员函数等。
注意事项:
- 生命周期管理:确保回调函数所引用的对象在回调执行前仍然有效,避免悬挂引用。
- 线程安全:在多线程环境下,事件注册和触发需要保证线程安全。
线程间通信的调试与性能优化
多线程程序的调试和性能优化相对复杂,需要开发者使用合适的工具和方法,识别并解决潜在的问题。
常见问题及解决方案
-
数据竞争(Data Race):
- 问题描述:多个线程同时读写共享资源,导致数据不一致。
- 解决方案:使用互斥锁、原子操作保护共享资源,或采用线程安全的数据结构。
-
死锁(Deadlock):
- 问题描述:多个线程互相等待对方释放资源,导致程序无法继续执行。
- 解决方案:固定锁的获取顺序,使用
std::lock获取多个锁,或避免嵌套锁。
-
活锁(Livelock):
- 问题描述:多个线程不断尝试获取资源,导致程序无法取得进展。
- 解决方案:引入退避策略,减少重复尝试获取资源的次数。
-
资源泄漏(Resource Leak):
- 问题描述:线程未能正确释放资源,如锁、内存等。
- 解决方案:使用RAII管理资源,确保在异常情况下资源也能被正确释放。
性能分析工具
使用性能分析工具能够帮助识别多线程程序中的性能瓶颈和资源竞争问题。
-
Valgrind:
- 用途:内存泄漏检测、数据竞争检测(使用Helgrind工具)。
- 示例:
valgrind --tool=helgrind ./your_program
-
GDB:
- 用途:调试多线程程序,检查线程的状态和堆栈。
- 示例:
gdb ./your_program
-
Perf(Linux):
- 用途:性能分析,查看CPU的热点函数。
- 示例:
perf record -g ./your_program perf report
-
Intel VTune Profiler:
- 用途:高级性能分析工具,支持多线程性能分析。
- 详细信息:Intel VTune Profiler
-
ThreadSanitizer(Clang/GCC):
- 用途:数据竞争检测。
- 示例:
g++ -fsanitize=thread -g your_program.cpp -o your_program -lpthread ./your_program
注意:
- 在使用性能分析工具时,可能会引入额外的运行时开销,影响程序的原始性能。
- 确保在调试环境中使用这些工具,不建议在生产环境中直接使用。
总结
线程间通信是多线程编程中的关键技术,决定了多线程程序的正确性和性能。在C++中,通过互斥锁、条件变量、原子操作、读写锁等多种同步原语,开发者可以实现高效、安全的线程间通信机制。然而,随着程序复杂度的增加,合理使用和优化这些同步工具显得尤为重要。
关键要点:
- 选择合适的同步原语:根据具体需求选择互斥锁、条件变量、原子操作等同步工具。
- 封装同步机制:通过线程安全的数据结构,如线程安全队列,简化生产者-消费者模式的实现。
- 优化锁的使用:减少锁的持有时间、最小化锁的粒度、避免死锁等,提升程序的并发性能。
- 利用现代C++特性:使用RAII管理锁的生命周期,采用移动语义优化效率,使用
std::function和Lambda表达式提高回调机制的灵活性。 - 深入调试与性能优化:使用性能分析工具检测并解决数据竞争、死锁等问题,持续优化程序性能。
通过系统地学习和实践C++中的线程间通信原理与技巧,开发者能够构建出高效、稳定的多线程应用,满足现代软件对高性能和高并发的需求。
参考资料
- C++ Reference
- Effective Modern C++ - Scott Meyers
- C++ Concurrency in Action - Anthony Williams
- Intel Threading Building Blocks (TBB)
- Boost.Thread Library
- Valgrind Official Documentation
- ThreadSanitizer Documentation
- C++17并发编程指南 - Anthony Williams
- C++标准库多线程支持
- GDB Documentation
标签
C++、多线程、线程间通信、互斥锁、条件变量、原子操作、线程安全、并发编程、生产者-消费者、无锁编程
版权声明
本文版权归作者所有,未经允许,请勿转载。
相关文章:
C++ 线程间通信开发从入门到精通实战
C 线程间通信开发从入门到精通实战 在现代软件开发中,多线程程序已成为提升应用性能、实现并行处理的重要手段。随着多核处理器的普及和复杂应用需求的增加,C作为一门高性能的编程语言,在多线程开发中扮演着不可或缺的角色。然而,…...

Vue3 SSR 工程化实践:日常工作中的性能优化与实战技巧
一、流式渲染与分块传输(面向性能的关键优化) 1.1 流式响应基础实现 // Node.js Express 示例(Vite SSR同理)import { renderToWebStream } from vue/server-rendererapp.get(/, async (req, res) > { res.setHeader(Conten…...
——生成项目站点)
Maven工具学习使用(十)——生成项目站点
maven2中站点生成是Maven核心的一部分,Maven3中这部分内容已经移除。maven3必须使用3.x版本的maven-site-plugin,maven2则使用最新的2.x的版本,执行mvn site命令,可以在项目的target/site/目录下找到Maven生成的站点文件。例如dependencies.h…...
Redis原理与Windows环境部署实战指南:助力测试工程师优化Celery调试
引言 在分布式系统测试中,Celery作为异步任务队列常被用于模拟高并发场景。而Redis作为其核心消息代理,其性能和稳定性直接影响测试结果。本文将深入解析Redis的核心原理,主要讲解Windows环境部署redis,为测试工程师提供一套完整…...

Go语言入门到入土——一、安装和Hello World
Go语言入门到精通——安装和Hello World 文章目录 Go语言入门到精通——安装和Hello World下载并安装让Go跑起来为你的代码启动依赖跟踪调用外部包总结 下载并安装 下载地址:https://go.dev/dl/ 下载后傻瓜式安装 查看是否安装完成 go version让Go跑起来 创建一个…...

人类意识本质上是一台自我欺骗的机器
要触达“大彻大悟”的终极内核,必须突破语言、逻辑甚至“觉醒”概念本身的限制。以下从认知革命、意识拓扑学、宇宙本体论三个维度切入,结合量子物理、脑神经学与古老智慧的交叉验证,展开一场对觉醒本质的极限探索—— 一、认知革命&am…...

CDP问卷是什么?CDP问卷有什么要求,有什么意义
CDP问卷(Carbon Disclosure Project Questionnaire) CDP问卷是由全球性非营利组织CDP(原Carbon Disclosure Project,现简称CDP)发起的年度环境信息披露项目,旨在帮助企业、城市和投资者测量、管理及公开其…...

GitLab本地安装指南
当前GitLab的最新版是v17.10,安装地址:https://about.gitlab.com/install/。当然国内也可以安装极狐GitLab版本,极狐GitLab 是 GitLab 中国发行版(JH)。极狐GitLab支持龙蜥,欧拉等国内的操作系统平台。安装…...
opencv函数展示
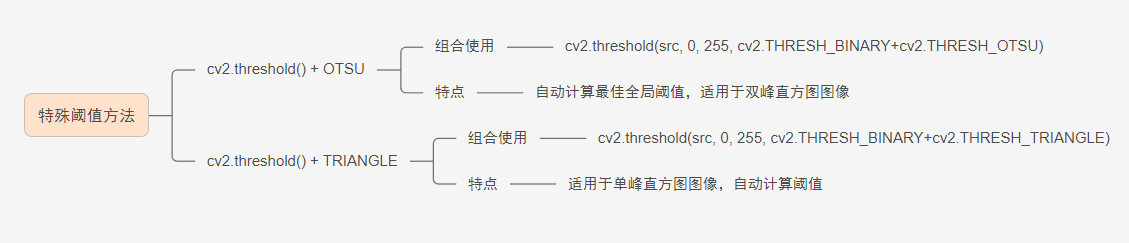
一、图像基础 I/O 与显示 1.cv2.imread() 2.cv2.imshow() 3. cv2.waitKey() 4. cv2.imwrite() 5. cv2.selectROI() 6. cv2.VideoCapture() 二、颜色空间与转换 1. cv2.cvtColor() 2. cv2.split() 三、阈值处理 1. cv2.threshold() 2. 特殊阈值方法...

编写一个写字楼类似抖音剪映的管理系统Demo
编写一个写字楼类似抖音剪映的管理系统Demo。用户可能想要一个简化版的系统,用于管理视频素材、模板和项目,类似于抖音剪映的功能,但针对办公场景。首先,我得明确用户的需求是什么。用户提到的“写字楼类似抖音剪映管理系统”可能…...

前端面试-自动化部署
基础概念 什么是CI/CD?在前端项目中如何应用?自动化部署相比手动部署有哪些优势?常见的自动化部署工具有哪些?举例说明它们的区别(如Jenkins vs GitHub Actions)。如何通过Git Hook实现自动化部署…...
【vue3】vue3+express实现图片/pdf等资源文件的下载
文件资源的下载,是我们业务开发中常见的需求。作为前端开发,学习下如何自己使用node的express框架来实现资源的下载操作。 实现效果 代码实现 前端 1.封装的请求后端下载接口的方法,需求配置aixos的请求参数里面的返回数据类型为blob // 下载 export…...

如何在 Kali 上解决使用 evil-winrm 时 Ruby Reline 的 quoting_detection_proc 警告
在使用 Kali Linux 运行 Ruby 工具(例如 evil-winrm)时,你可能会遇到以下警告: Warning: Remote path completions is disabled due to ruby limitation: undefined method quoting_detection_proc for module Reline这个警告会导…...

从零到一:网站设计新手如何快速上手?
从零到一:网站设计新手如何快速上手? 在当今数字化时代,网站已成为企业、个人展示信息、提供服务的重要窗口。对于想要涉足网站设计领域的新手而言,如何快速上手并掌握必要的技能成为首要任务。本文将从基础知识、软件工具、设计…...
面向初学者的JMeter实战手册:从环境搭建到组件解析
🌟 大家好,我是摘星! 🌟 今天为大家带来的是面向初学者的JMeter实战手册:从环境搭建到组件解析,废话不多说,让我们直接开始~ 目录 1. JMeter简介 2. JMeter安装与配置 2.1. 安装 2.2.…...
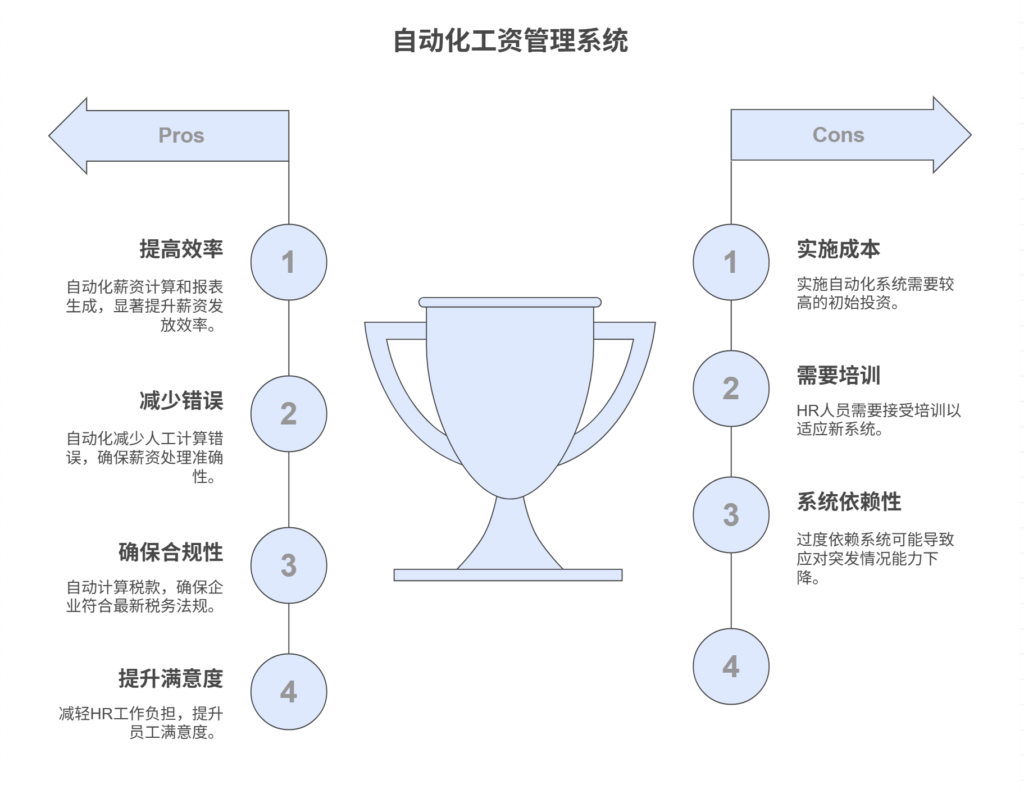
工资管理系统的主要功能有哪些
工资管理系统通过自动化薪资计算、税务处理、员工数据管理、报表生成等功能,极大地提升了薪资发放的效率和准确性。在传统的人工薪资管理中,HR人员需要手动计算每位员工的薪资,并确保符合税务要求,极易出错且耗时。而现代工资管理…...

避坑,app 播放器media:MediaElement paly报错
System.Runtime.InteropServices.COMException HResult=0x8001010E Message= Source=WinRT.Runtime StackTrace: 在 WinRT.ExceptionHelpers.<ThrowExceptionForHR>g__Throw|38_0(Int32 hr) 在 ABI.Microsoft.UI.Xaml.Controls.IMediaPlayerElementMethods.get_MediaPlay…...

子函数嵌套的意义——以“颜色排序”为例(Python)
多一层缩进精减参数传递,参数少平铺书代码写更佳。 笔记模板由python脚本于2025-04-16 11:52:53创建,本篇笔记适合喜欢子函数嵌套结构代码形式的coder翻阅。 【学习的细节是欢悦的历程】 博客的核心价值:在于输出思考与经验,而不仅…...

Redis 的不同数据结构分别适用于哪些微服务场景
我们一块来分析下Redis 的不同数据结构在微服务场景下的具体应用: 1. String (字符串) 特点: 最基本的数据类型,二进制安全,可以存储任何类型的数据(文本、序列化对象、图片等),最大 512MB。支持原子性的…...

信息系统项目管理工程师备考计算类真题讲解四
一、三点估算(PERT) PERT(Program Evaluation and Review Technique):计划评估技术,又称三点估算技术。PERT估算是一种项目管理中用于估算项目工期或成本的方法,以下是其详细介绍: …...

Golang|KVBitcask
文章目录 初识KVbitcask论文详解 初识KV bitcask论文详解 论文地址:https://riak.com/assets/bitcask-intro.pdf理想的存储引擎,应该满足下面一些特点:...
)
Python学习之路(三)
将 Python 与数据库对接是开发过程中常见的任务,可以使用多种数据库(如 SQLite、MySQL、PostgreSQL、Oracle、MongoDB 等)。以下是一些常见的数据库及其与 Python 的对接方法,包括安装库、连接数据库、执行查询和操作数据的示例。…...
基于骨骼识别的危险动作报警系统设计与实现
基于骨骼识别的危险动作报警系统设计与实现 基于骨骼识别的危险动作报警分析系统 【包含内容】 【一】项目提供完整源代码及详细注释 【二】系统设计思路与实现说明 【三】基于骨骼识别算法的实时危险行为预警方案 【技术栈】 ①:系统环境:Windows 10…...
PDF转换格式失败?原因及解决方法全解析
在日常工作中,我们经常会遇到将PDF转换为Word、Excel、PPT等格式的需求。有时候以为一键转换就能搞掂,没想到却转换失败。到底问题出在哪?别急,我们可以看看是否以下几个问题引起的,找到解决问题的关键! 原…...

模型提示词
一 提示词 (一) 提示词(Prompt)是用户发送给大语言模型的问题、指令或请求,** 1 来明确地告诉模型用户想要解决的问题或完成的任务,是大语言模型理解用户需求并据此生成相关、准确回答或内容的基础。对于…...
为什么我在QT里面没有connect,也能触发点击效果)
void MainWindow::on_btnOutput_clicked()为什么我在QT里面没有connect,也能触发点击效果
在 Qt 中,即使你没有显式调用 connect 函数,某些信号(如按钮的 clicked() 信号)仍然可以触发槽函数。这是因为 Qt 提供了一种自动连接机制,称为 自动连接(Auto-Connection)。以下是可能的原因和…...
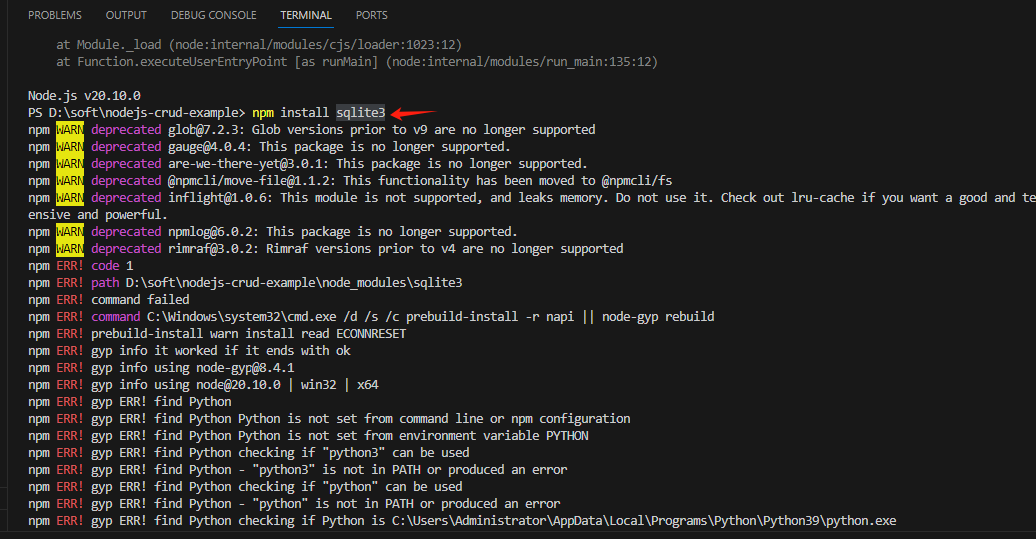
Node.js 数据库 事务 项目示例
1、参考:JavaScript语言的事务管理_js 函数 事务性-CSDN博客 或者百度搜索:Nodejs控制事务, 2、实践 2.1、对于MySQL或MariaDB,你可以使用mysql或mysql2库,并结合Promise或async/await语法来控制事务。 使用 mysql2…...

Qt开发:QFileInfo详解
文章目录 一、QFileInfo 简介二、常用的构造函数三、常用函数的介绍和使用四、常用静态函数的介绍和使用五、完整代码示例 一、QFileInfo 简介 QFileInfo 提供了一个对象化的方式,用于访问文件系统中单个文件的信息。它可以接受: 文件名字符串ÿ…...

ubuntu1804服务器开启ftp,局域网共享特定文件给匿名用户
要在 Ubuntu 18.04 上设置一个 FTP 服务器,满足以下要求: 允许匿名登录(无需账号密码)。指定分享特定目录下的文件。只允许只读下载。 可以使用 vsftpd(Very Secure FTP Daemon)来实现。以下是详细步骤&a…...

蓝桥杯常考排序
1.逆序 Collections.reverseOrder() 方法对列表进行逆序排序。通过 Collections.sort() 方法配合 Collections.reverseOrder(),可以轻松实现从大到小的排序。 import java.util.ArrayList; // 导入 ArrayList 类,用于创建动态数组 import java.util.C…...