Linux Kernel 6
clone 系统调用(The clone system call)
在 Linux 中,使用 clone() 系统调用来创建新的线程或进程。fork() 系统调用和 pthread_create() 函数都基于 clone() 的实现。
clone() 系统调用允许调用者决定哪些资源应该与父进程共享,哪些应该被复制或隔离。
📌 clone() 系统调用的标志
clone() 通过一组标志来控制父子进程或线程之间的资源共享。常见的标志包括:
- C L O N E _ F I L E S CLONE\_FILES CLONE_FILES:共享文件描述符表,意味着子进程或子线程将共享父进程的文件描述符(打开的文件)。
- C L O N E _ V M CLONE\_VM CLONE_VM:共享地址空间,意味着子进程或子线程将与父进程共享同一个虚拟内存地址空间。
- C L O N E _ F S CLONE\_FS CLONE_FS:共享文件系统信息,如根目录和当前目录。
- C L O N E _ N E W N S CLONE\_NEWNS CLONE_NEWNS:不共享挂载命名空间,意味着子进程或子线程将有自己的挂载点,不与父进程共享。
- C L O N E _ N E W I P C CLONE\_NEWIPC CLONE_NEWIPC:不共享 IPC 命名空间(例如,System V IPC 对象、POSIX 消息队列等)。
- C L O N E _ N E W N E T CLONE\_NEWNET CLONE_NEWNET:不共享网络命名空间(例如,网络接口、路由表等)。
🧠 重要概念解释
- f o r k ( ) fork() fork():系统调用,用于创建新进程,复制父进程的所有资源,形成父子进程。
- p t h r e a d _ c r e a t e ( ) pthread\_create() pthread_create():函数,用于在用户空间创建新线程。通常与线程库(如 POSIX 线程库)配合使用。
- 命名空间(Namespace):在 Linux 中,命名空间用于隔离系统资源。不同的命名空间提供进程间的隔离,例如文件系统、IPC、网络等命名空间。
✅ 创建线程与进程的区别
- 如果使用
CLONE_FILES | CLONE_VM | CLONE_FS组合标志,调用者会创建一个新线程,因为它共享父进程的文件描述符表、地址空间和文件系统信息。 - 如果不使用这些标志,调用者将创建一个新进程,因为新进程将拥有自己的资源,如地址空间、文件描述符表等。
命名空间与“容器”技术(Namespaces and “Containers”)
“容器”是一种轻量级的虚拟机形式,它们共享同一个内核实例,与传统的虚拟化技术不同,传统虚拟化技术通过虚拟机监视器(hypervisor)运行多个虚拟机(VM),每个虚拟机都有一个独立的内核实例。
📌 容器技术的例子
- LXC(Linux Containers):允许运行轻量级的“虚拟机”,并提供类似虚拟化的隔离功能。
- Docker:一种专门用于运行单一应用程序的容器技术,广泛用于开发和部署应用。
容器技术依赖于几个内核特性,其中之一就是命名空间(namespace)。命名空间通过隔离不同的资源,避免它们在全局范围内可见。
🔒 命名空间的作用
命名空间为容器提供了资源隔离,使得容器中的进程不会被其他容器的进程所干扰。比如:
- 没有容器时,系统中的所有进程都在
/proc中可见; - 有容器时,一个容器中的进程不会被其他容器看到(在
/proc中不可见,也无法被杀死)。
🧠 关键概念解释
-
命名空间(Namespace):命名空间用于隔离系统资源,使得在不同的命名空间中,资源(如进程、网络接口、挂载点等)是独立的,互不干扰。Linux 支持多种类型的命名空间,包括进程 ID(PID)命名空间、网络命名空间、文件系统命名空间等。
-
容器(Container):容器是一种通过利用命名空间和其他内核特性(如控制组cgroup)实现的轻量级虚拟化技术。容器共享主机的内核,但它们的资源(如进程、文件系统、网络等)是隔离的。
-
struct nsproxy结构体:用于管理和分组资源类型的内核数据结构。它是实现命名空间隔离的关键,支持的命名空间类型包括 IPC、网络、PID、挂载等。
📌 容器如何实现资源隔离
- 容器通过将资源(如网络接口、进程 ID 等)分配到不同的命名空间来实现资源的隔离。
- 例如,网络命名空间会将网络接口列表存储在
struct net中,而不是使用全局的网络接口列表。
📊 默认命名空间与创建新命名空间
- 系统启动时会初始化一个默认的命名空间(如
init_net),所有进程默认共享该命名空间。 - 当创建新的命名空间时,系统会为新命名空间创建一个新的
net命名空间,并将新进程关联到这个新的命名空间,而不是默认的命名空间。
访问当前进程(Accessing the Current Process)
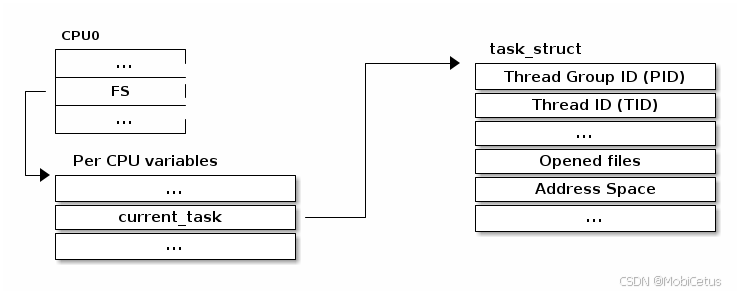
访问当前进程是一个常见的操作,很多系统调用都需要访问当前进程的相关信息:
- 打开文件时需要访问
struct\ task_struct中的file字段。 - 映射新文件时需要访问
struct\ task_struct中的mm字段。
📌 访问当前进程的宏
为了支持快速访问当前进程,尤其是在多处理器配置中,每个 CPU 都有一个变量来存储和获取指向当前 struct\ task_struct 的指针。
以前的实现方式
在以前,current 宏的实现方式如下:
/* 获取当前栈指针 */
register unsigned long current_stack_pointer asm("esp") __attribute_used__;/* 获取当前线程信息结构体 */
static inline struct thread_info *current_thread_info(void)
{return (struct thread_info *)(current_stack_pointer & ~(THREAD_SIZE – 1));
}#define current current_thread_info()->task
-
s t r u c t t a s k _ s t r u c t struct\ task\_struct struct task_struct:Linux 内核中用于表示进程(包括线程)的核心数据结构,包含了进程的调度信息、文件描述符、地址空间等。
-
c u r r e n t current current 宏:用于快速访问当前进程的 t a s k _ s t r u c t task\_struct task_struct 结构体。在多核处理器上,它通过每个 CPU 特有的变量来加速访问。
-
c u r r e n t _ s t a c k _ p o i n t e r current\_stack\_pointer current_stack_pointer:通过汇编指令直接获取当前栈指针,用于定位当前线程的信息。
-
t h r e a d _ i n f o thread\_info thread_info:存储与线程相关的信息,通常包含线程的状态、栈、进程 ID 等。通过 c u r r e n t _ s t a c k _ p o i n t e r current\_stack\_pointer current_stack_pointer`获取线程信息后,可以进一步访问线程的任务结构体。
-
THREAD_SIZE:定义了线程的栈大小,通常用于按位操作栈指针,确定当前线程的信息。
上下文切换(Context Switching)
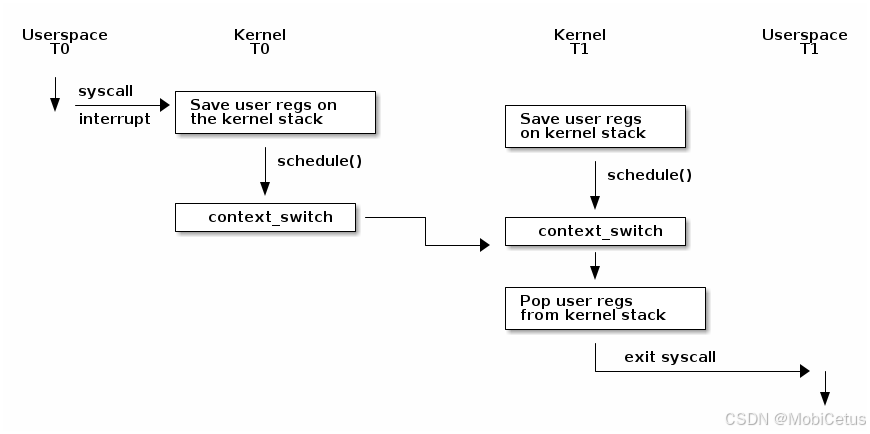
上图展示了 Linux 内核中上下文切换的整体流程:
- 触发内核态:上下文切换只能在内核态进行,通常由系统调用或中断引发。此时,用户空间寄存器会被保存到内核栈中。
- 调用
schedule():在某些时刻(如线程阻塞等待 I/O 或时间片用尽),内核会调用schedule(),决定从线程 T0 切换到线程 T1。 context_switch()函数:该函数执行与架构相关的操作,如更新地址空间(若从用户态切换到其他用户态)并维护 TLB(Translation Lookaside Buffer)。- 若
!next->mm(目标切换到内核线程),则共享prev->active_mm。 - 若
next->mm(目标切换到用户进程),则调用switch_mm_irqs_off()处理内存映射切换。
- 若
switch_to():context_switch()最终调用switch_to()进行真正的寄存器状态和内核栈切换。其实现包含以下关键步骤:- 保存被调度出线程的寄存器到当前栈:如
ebp, ebx, edi, esi等“调用者保存的寄存器”; - 更新
esp(栈指针),切换到新线程的内核栈; - 恢复新线程的寄存器,然后跳转到
__switch_to继续执行。
- 保存被调度出线程的寄存器到当前栈:如
首先要注意的是,上下文切换之前必须完成一次从用户空间到内核空间的过渡(如通过系统调用或中断)。在这一点上,用户空间的寄存器状态会被保存到内核栈上。当调度器调用 schedule() 函数后,可能判定当前线程(如 T0)需要切换到另一个线程(如 T1),原因可能包括当前线程等待I/O操作完成而阻塞,或其时间片耗尽。
此时,context_switch() 会执行特定于体系结构的操作,并在需要时切换地址空间:
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,struct task_struct *next, struct rq_flags *rf)
{prepare_task_switch(rq, prev, next);arch_start_context_switch(prev);if (!next->mm) { // 若目标线程为内核线程(无用户地址空间)enter_lazy_tlb(prev->active_mm, next);next->active_mm = prev->active_mm;if (prev->mm)mmgrab(prev->active_mm);elseprev->active_mm = NULL;} else { // 若目标线程为用户线程membarrier_switch_mm(rq, prev->active_mm, next->mm);switch_mm_irqs_off(prev->active_mm, next->mm, next);if (!prev->mm) { // 如果来源线程是内核线程rq->prev_mm = prev->active_mm;prev->active_mm = NULL;}}rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);prepare_lock_switch(rq, next, rf);switch_to(prev, next, prev); // 执行寄存器状态和内核栈切换barrier();return finish_task_switch(prev);
}
接下来调用特定于体系结构的函数 s w i t c h _ t o switch\_to switch_to,它负责切换寄存器状态和内核栈指针。寄存器状态保存在栈中,而栈指针被保存在任务结构体中:
#define switch_to(prev, next, last) \
do { \((last) = __switch_to_asm((prev), (next))); \
} while (0)
下面是 x86 架构上 _ _ s w i t c h _ t o _ a s m \_\_switch\_to\_asm __switch_to_asm 的汇编实现:
SYM_CODE_START(__switch_to_asm)pushl %ebppushl %ebxpushl %edipushl %esipushflmovl %esp, TASK_threadsp(%eax)movl TASK_threadsp(%edx), %esp#ifdef CONFIG_STACKPROTECTORmovl TASK_stack_canary(%edx), %ebxmovl %ebx, PER_CPU_VAR(stack_canary)+stack_canary_offset
#endif#ifdef CONFIG_RETPOLINEFILL_RETURN_BUFFER %ebx, RSB_CLEAR_LOOPS, X86_FEATURE_RSB_CTXSW
#endifpopflpopl %esipopl %edipopl %ebxpopl %ebpjmp __switch_to
SYM_CODE_END(__switch_to_asm)
在上下文切换过程中,你会发现指令指针(IP / EIP / RIP)并没有被显式保存。之所以不需要额外保存,有以下几个原因:
-
总是在同一个函数中恢复执行
当任务恢复时,它会回到同一个函数内继续执行,从而不必担心额外的指令指针保存。 -
schedule()(或context_switch()内联)的调用者返回地址已保存在内核栈中
schedule()所在函数(或直接调用context_switch()的地方)的返回地址会保存在栈中。当切换回来时,CPU 会自动从栈中取出这个返回地址。 -
使用
jmp执行__switch_to()函数
当__switch_to()函数执行完毕并返回时,它会从栈中弹出原先(下一个任务)的返回地址,因而无需我们显式地保存 IP。
🧠 关键概念解释
-
指令指针(Instruction Pointer)
指示 CPU 正在执行的下一条指令的地址。在 x86 上通常被称为 EIP(32 位)或 RIP(64 位)。 -
内核栈(Kernel Stack)
每个任务都有自己的内核栈,用于在内核态保存函数调用、寄存器以及返回地址等信息。 -
schedule()和context_switch()
Linux 内核调度的重要函数,它们在切换任务时会内联或调用一系列的汇编/内核逻辑来完成上下文切换。
阻塞与唤醒任务(Blocking and Waking Up Tasks)
任务状态(Task States)
下图展示了任务(线程)的各种状态以及它们之间的可能转换路径:
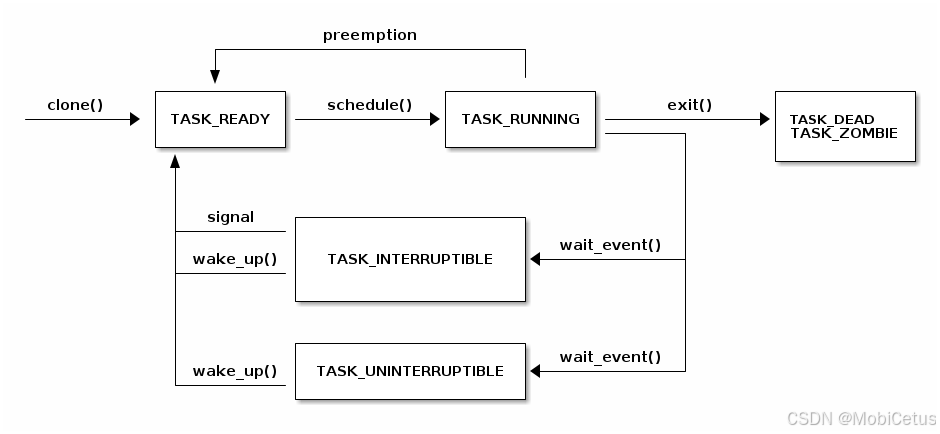
- 从
clone()创建新任务,初始状态为TASK_READY。 - 当调度器调用
schedule()后,任务变为TASK_RUNNING。 - 如果任务调用
exit(),它会变为TASK_DEAD或TASK_ZOMBIE。 - 运行中的任务可以因为 I/O 或其他事件调用
wait_event()进入阻塞状态:TASK_INTERRUPTIBLE:可中断的睡眠状态,可以被信号唤醒;TASK_UNINTERRUPTIBLE:不可中断的睡眠状态,只有事件发生才唤醒。
- 被阻塞的任务可通过
wake_up()被重新唤醒并返回TASK_READY状态,等待再次被调度执行。
阻塞当前线程(Blocking the Current Thread)
阻塞当前线程是操作系统中一个关键操作,它的意义在于当当前线程无法继续运行(例如等待 I/O 完成)时,让出 CPU,让其他线程得以运行,从而实现高效调度。
实现线程阻塞的操作步骤如下:
- 将当前线程的状态设置为
TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE; - 将该线程添加到等待队列中;
- 调用调度器
schedule(),选择另一个READY队列中的任务; - 执行上下文切换,将 CPU 控制权交给新的任务。
等待队列是一个链表,每个元素包含一些额外的信息,如指向任务结构体的指针。
💡 关于 wait_event 的重要说明
wait_event和wake_up之间的时序非常关键。为了防止死锁,在检查条件前,任务必须先加入等待队列;- 唤醒操作
wake_up会检查条件是否满足,并在满足时唤醒线程; - 唤醒前还会检查是否有信号(如果线程为可中断状态);
- 唤醒后,调度器会重新安排任务执行,通过
schedule()完成实际的上下文切换。
TASK_RUNNING:线程正在 CPU 上执行;TASK_READY:线程就绪,等待调度;TASK_INTERRUPTIBLE:线程在等待某事件,可被信号中断;TASK_UNINTERRUPTIBLE:线程在等待某事件,不能被信号中断;wait_event:内核机制,用于让线程等待某个条件;wake_up:当条件满足时,唤醒被阻塞的线程;schedule():内核调度函数,选择下一个要运行的线程。
唤醒任务(Waking up a Task)
我们可以使用内核提供的 wake_up 原语来唤醒被阻塞的任务。当某个事件(如 I/O 完成)发生时,内核会调用 wake_up 将等待中的线程重新置为可运行状态。其主要操作流程如下:
🧱 唤醒流程(高层操作步骤)
- 从等待队列中选择一个任务
找到在特定等待队列中阻塞的任务,通常这些任务正在等待某个条件或事件完成。 - 将任务状态设置为
TASK_READY
这意味着该任务已经可以继续执行,不再处于TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE阻塞状态。 - 将任务插入调度器的就绪队列(READY queue)中
被唤醒的任务将重新加入调度器的就绪队列,等待系统调度器下一次调度。
🧠 多核系统中的复杂性(SMP 系统)
在 SMP(对称多处理)系统中,唤醒任务的过程更为复杂,原因如下:
- 每个 CPU 核心有自己的就绪队列
为了避免锁竞争与提升并行性,Linux 在每个 CPU 上维护独立的调度队列。 - 任务队列之间需要负载均衡
如果唤醒的任务在不同的 CPU 上被调度,系统需要确保多个队列负载平衡,防止有的 CPU 空闲而有的 CPU 拥堵。 - 唤醒其他 CPU 可能需要发信号
如果目标任务位于非当前 CPU 的就绪队列中,需要通过 IPI(中断)唤醒对应的处理器,以便它能及时调度该任务。
相关文章:
Linux Kernel 6
clone 系统调用(The clone system call) 在 Linux 中,使用 clone() 系统调用来创建新的线程或进程。fork() 系统调用和 pthread_create() 函数都基于 clone() 的实现。 clone() 系统调用允许调用者决定哪些资源应该与父进程共享,…...
【开源项目】Excel手撕AI算法深入理解(四):AlphaFold、Autoencoder
项目源码地址:https://github.com/ImagineAILab/ai-by-hand-excel.git 一、AlphaFold AlphaFold 是 DeepMind 开发的突破性 AI 算法,用于预测蛋白质的三维结构。它的出现解决了生物学领域长达 50 年的“蛋白质折叠问题”,被《科学》杂志评为…...
第IV部分有效应用程序的设计模式
第IV部分有效应用程序的设计模式 第IV部分有效应用程序的设计模式第23章:应用程序用户界面的架构设计23.1设计考量23.2示例1:用于非分布式有界上下文的一个基于HTMLAF的、服务器端的UI23.3示例2:用于分布式有界上下文的一个基于数据API的客户端UI23.4要点第24章:CQRS:一种…...

如何编制实施项目管理章程
本文档概述了一个项目管理系统的实施计划,旨在通过统一的业务规范和技术架构,加强集团公司的业务管控,并规范业务管理。系统建设将遵循集团统一模板,确保各单位项目系统建设的标准化和一致性。 实施范围涵盖投资管理、立项管理、设计管理、进度管理等多个方面,支持项目全生…...
排序(java)
一.概念 排序:对一组数据进行从小到大/从大到小的排序 稳定性:即使进行排序相对位置也不受影响如: 如果再排序后 L 在 i 的前面则稳定性差,像图中这样就是稳定性好。 二.常见的排序 三.常见算法的实现 1.插入排序 1.1 直…...
内存管理补充版)
嵌入式C语言进阶(二+)内存管理补充版
C语言内存管理:从小白到大神的完全指南 前言:为什么需要理解内存管理 C语言以其高效性和灵活性著称,但这也意味着程序员需要手动管理内存。与Java、Python等高级语言不同,C语言没有自动垃圾回收机制,内存管理的重担完全落在开发者肩上。理解C语言的内存管理机制不仅能帮…...
【HDFS入门】HDFS副本策略:深入浅出副本机制
目录 1 HDFS副本机制概述 2 HDFS副本放置策略 3 副本策略的优势 4 副本因子配置 5 副本管理流程 6 最佳实践与调优 7 总结 1 HDFS副本机制概述 Hadoop分布式文件系统(HDFS)的核心设计原则之一就是通过数据冗余来保证可靠性,而这一功能正是通过副本策略实现的…...

Excel自定义函数取拼音首字母
1.启动Excel 2003(其它版本请仿照操作),打开相应的工作表; 2.执行“工具 > 宏 > Visual Basic编辑器”命令(或者直接按“AltF11”组合键),进入Visual Basic编辑状态; 3.执行“…...
智能 GitHub Copilot 副驾驶® 更新升级!
智能 GitHub Copilot 副驾驶 迎来重大升级!现在,所有 VS Code 用户都能体验支持 Multi-Context Protocol(MCP)的全新 Agent Mode。此外,微软还推出了智能 GitHub Copilot 副驾驶 Pro 订阅计划,提供更强大的…...

Android ViewPager使用预加载机制导致出现页面穿透问题
缘由 在应用中使用ViewPager,并且设置预加载页面。结果出现了一些异常的现象。 我们有4个页面,分别是4个Fragment,暂且称为FragmentA、FragmentB、FragmentC、FragmentD,ViewPager在MainActivity中,切换时&#x…...

【今日三题】添加字符(暴力枚举) / 数组变换(位运算) / 装箱问题(01背包)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 添加字符(暴力枚举)数组变换(位运算)装箱问题(01背包) 添加字符(暴力枚举) 添加字符 当在A的开头或结尾添加字符直到和B长度…...
)
【AIoT】智能硬件GPIO通信详解(二)
前言 上一篇我们深入解析了智能硬件GPIO通信原理(传送门:【AIoT】智能硬件GPIO通信详解(一))。接下来,我们将结合无人售货机控制场景,通过具体案例进一步剖析物联网底层通信机制的实际应用。 在智能零售领域,无人售货机通过AI技术升级为智能柜,其设备控制的底层通信…...
Python中JSON的妙用:详解序列化与反序列化原理及实战案例)
Python(18)Python中JSON的妙用:详解序列化与反序列化原理及实战案例
目录 一、背景:为什么Python需要JSON?二、核心技术解析:序列化与反序列化2.1 核心概念2.2 类型映射对照表 三、Python操作JSON的四大核心方法3.1 基础方法库3.2 方法详解1. json.dumps()2. json.loads()3. json.dump()4. json.load() 四、实战…...

【Python进阶】字典:高效键值存储的十大核心应用
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现(10个案例)案例1:基础操作案例2:字典推导式…...
的轨迹仿真,主要用于模拟升力体在不同飞行阶段(初始滑翔段、滑翔段、下压段)的运动轨迹)
MATLAB脚本实现了一个三自由度的通用航空运载器(CAV-H)的轨迹仿真,主要用于模拟升力体在不同飞行阶段(初始滑翔段、滑翔段、下压段)的运动轨迹
%升力体:通用航空运载器CAV-H %读取数据1 升力系数 alpha = [10 15 20]; Ma = [3.5 5 8 10 15 20 23]; alpha1 = 10:0.1:20; Ma1 = 3.5:0.1:23; [Ma1, alpha1] = meshgrid(Ma1, alpha1); CL = readmatrix(simulation.xlsx, Sheet, Sheet1, Range, B2:H4); CL1 = interp2(…...
 函数)
多角度分析Vue3 nextTick() 函数
nextTick() 是 Vue 3 中的一个核心函数,它的作用是延迟执行某些操作,直到下一次 DOM 更新循环结束之后再执行。这个函数常用于在 Vue 更新 DOM 后立即获取更新后的 DOM 状态,或者在组件渲染完成后执行某些操作。 官方的解释是,当…...

Linux——消息队列
目录 一、消息队列的定义 二、相关函数 2.1 msgget 函数 2.2 msgsnd 函数 2.3 msgrcv 函数 2.4 msgctl 函数 三、消息队列的操作 3.1 创建消息队列 3.2 获取消息队列并发送消息 3.3 从消息队列接收消息recv 四、 删除消息队列 4.1 ipcrm 4.2 msgctl函数 一、消息…...
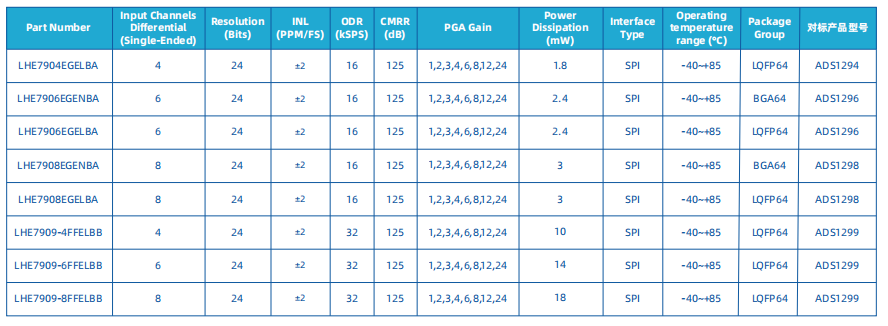
领慧立芯LHE7909可兼容替代TI的ADS1299
LHE7909是一款由领慧立芯(Legendsemi)推出的24位高精度Δ-Σ模数转换器(ADC),主要面向医疗电子和生物电势测量应用,如脑电图(EEG)、心电图(ECG)等设备。以下是…...

在PyTorch中,使用不同模型的参数进行模型预热
在PyTorch中,使用不同模型的参数进行模型预热(Warmstarting)是一种常见的迁移学习和加速训练的策略。以下是结合多个参考资料总结的实现方法和注意事项: 1. 核心机制:load_state_dict()与strict参数 • 部分参数加载&…...

conda 创建、激活、退出、删除环境命令
参考博客:Anaconda创建环境、删除环境、激活环境、退出环境 使用起来觉得有些不方便可以改进,故写此文。 1. 创建环境 使用 -y 跳过确认 conda create -n 你的环境名 -y 也可以直接选择特定版本 python 安装,以 3.10 为例: co…...

Redis核心数据类型在实际项目中的典型应用场景解析
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Redis作为高性能的键值存储系统,在现代软件开发中扮演着重要角色。其多样化的数据结构为开发者提供了灵活的解决方案,本文将通过真实项…...
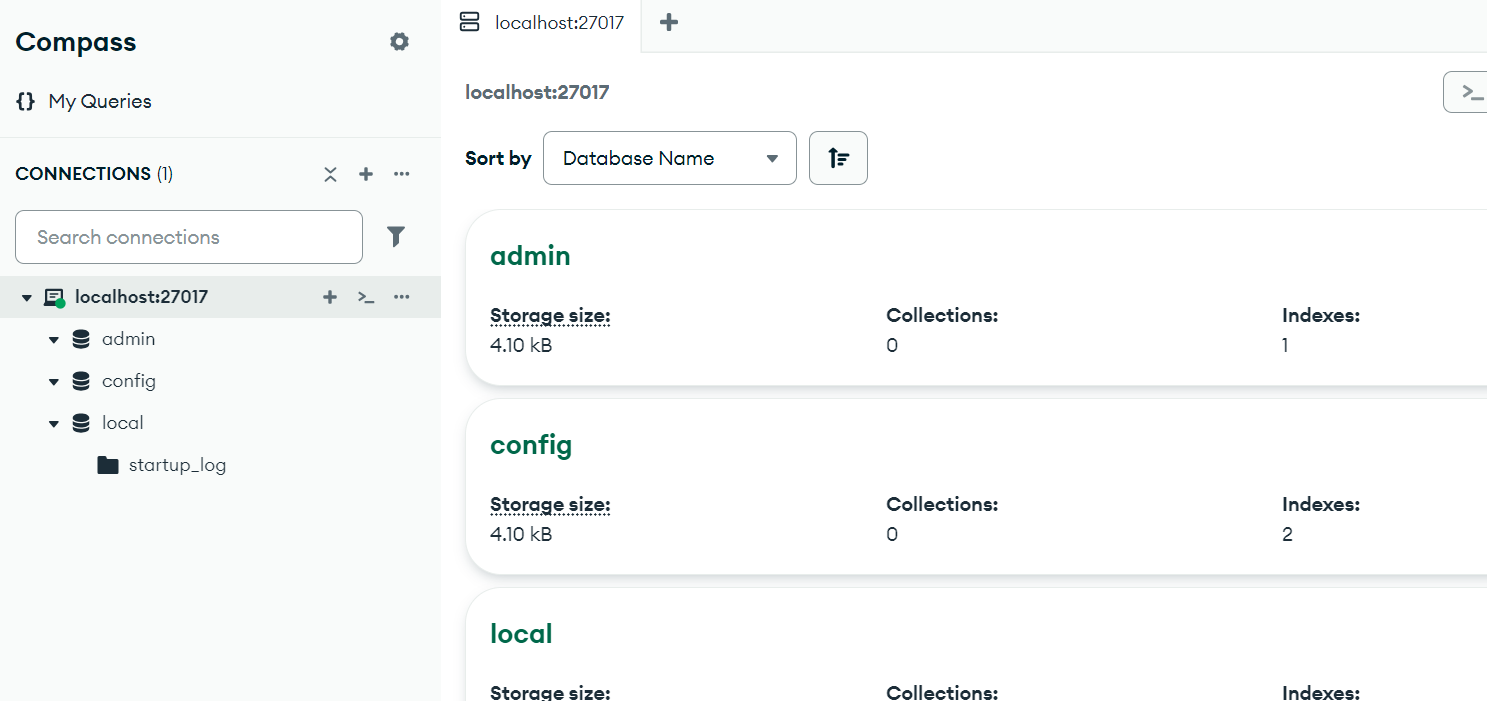
MongoDB简单用法
图片中 MongoDB Compass 中显示了默认的三个数据库: adminconfiglocal 如果在 .env 文件中配置的是: MONGODB_URImongodb://admin:passwordlocalhost:27017/ MONGODB_NAMERAGSAAS💡 一、为什么 Compass 里没有 RAGSAAS 数据库?…...

如何学习嵌入式
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.16 请各位前辈能否给我提点建议,或者学习路线指导一下 STM32单片机学习总…...

【AI】IDEA 集成 AI 工具的背景与意义
一、IDEA 集成 AI 工具的背景与意义 随着人工智能技术的迅猛发展,尤其是大语言模型的不断演进,软件开发行业也迎来了智能化变革的浪潮。对于开发者而言,日常工作中面临着诸多挑战,如代码编写的重复性劳动、复杂逻辑的实现、代码质…...
uniapp-商城-26-vuex 使用流程
为了能在所有的页面都实现状态管理,我们按照前面讲的页面进行状态获取,然后再进行页面设置和布局,那就是重复工作,vuex 就会解决这样的问题,如同类、高度提炼的接口来帮助我们实现这些重复工作的管理。避免一直在造一样的轮子。 https://vuex.vuejs.org/zh/#%E4%BB%80%E4…...
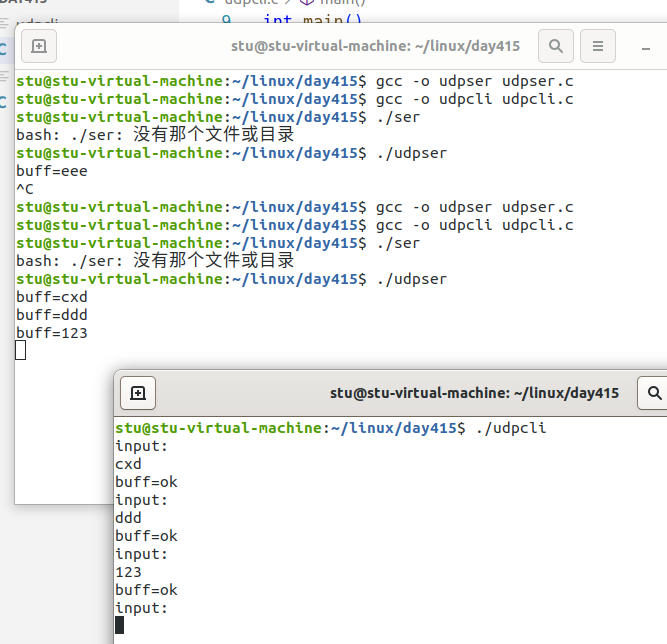
UDP概念特点+编程流程
UDP概念编程流程 目录 一、UDP基本概念 1.1 概念 1.2 特点 1.2.1 无连接性: 1.2.2 不可靠性 1.2.3 面向报文 二、UDP编程流程 2.1 客户端 cli.c 2.2 服务端ser.c 一、UDP基本概念 1.1 概念 UDP 即用户数据报协议(User Datagram Protocol &…...

celery rabbitmq 配置 broker和backend
在使用Celery和RabbitMQ作为消息代理和结果后端时,你需要正确配置Celery以便它们可以有效地通信。以下是如何配置Celery以使用RabbitMQ作为broker(消息代理)和backend(结果后端)的步骤: 安装必要的库 首先…...
)
vue+electron ipc+sql相关开发(三)
在 Electron 中使用 IPC(Inter-Process Communication)与 SQLite 数据库进行通信是一个常见的模式,特别是在需要将数据库操作从渲染进程(Vue.js)移到主进程(Electron)的情况下。这样可以更好地管理数据库连接和提高安全性。下一篇介绍结合axios写成通用接口形式,虽然没…...

[特殊字符] PostgreSQL MCP 开发指南
简介 🚀 PostgreSQL MCP 是一个基于 FastMCP 框架的 PostgreSQL 数据库交互服务。它提供了一套简单易用的工具函数,让你能够通过 API 方式与 PostgreSQL 数据库进行交互。 功能特点 ✨ 🔄 数据库连接管理与重试机制🔍 执行 SQL…...

GD32裸机程序-SFUD接口文件记录
SFUD gitee地址 SFUD spi初始化 /********************************************************************************* file : bsp_spi.c* author : shchl* brief : None* version : 1.0* attention : None* date : 25-…...