Elasticsearch 索引数据量激增的应对与优化:从原理到部署实践
Elasticsearch(ES)作为一款强大的分布式搜索和分析引擎,广泛应用于日志分析、全文搜索和实时数据处理等场景。然而,随着数据量激增,索引可能面临性能瓶颈,如写入变慢、查询延迟高或存储成本上升。如何有效应对数据量增长,并通过调优和部署优化确保系统高效运行,是 Java 开发者在使用 ES 时必须解决的难题。本文将深入探讨 Elasticsearch 索引数据量激增的应对策略,覆盖数据管理、性能调优和集群部署,并结合 Java 代码实现一个支持大数据量索引的日志系统。
一、索引数据量激增的挑战
1. 什么是索引数据量激增?
在 Elasticsearch 中,索引数据量激增指单个索引或集群存储的文档数量和体积显著增长,常见于:
- 日志系统:每天生成数百万日志。
- 电商搜索:商品数据随业务扩展快速累积。
- 监控平台:传感器或服务器产生高频数据。
典型场景下,索引可能从 GB 级增长到 TB 级,甚至 PB 级。
2. 数据量激增的影响
- 性能下降:
- 写入性能:批量索引变慢,刷新(refresh)开销增加。
- 查询性能:扫描更多分片和段,导致延迟升高。
- 存储压力:
- 磁盘占用激增,成本上升。
- 分片过多导致管理开销大。
- 集群稳定性:
- 节点过载,GC 频繁。
- 分片分配不均,热点问题。
- 资源瓶颈:
- CPU、内存和 IO 达到上限。
- 网络带宽受限,副本同步延迟。
3. 应对目标
- 高效写入:支持高吞吐索引。
- 快速查询:保持亚秒级响应。
- 存储优化:降低磁盘和成本。
- 集群扩展:动态适应数据增长。
二、应对索引数据量激增的策略
以下从数据管理、性能调优和集群部署三个维度分析应对手段。
1. 数据管理策略
原理
- 索引结构:
- 索引由分片组成,每个分片是 Lucene 索引。
- 分片过多增加管理开销,过少限制并行性。
- 数据生命周期:
- 数据有冷热阶段(如日志随时间变冷)。
- 过期数据无需实时查询。
- 瓶颈:
- 单索引过大导致查询慢。
- 冗余字段占用存储。
- 缺乏分区管理数据膨胀。
优化策略
- 时间分片索引:
- 按时间(如每天/每月)创建索引。
- 例:
logs-2025.04.12,便于滚动和删除。
- 索引生命周期管理(ILM):
- 定义阶段(Hot、Warm、Cold、Delete)。
- 自动滚动、压缩和删除。
- 精简映射:
- 禁用动态映射(
dynamic: strict)。 - 仅索引必要字段,禁用
_all和norms。
- 禁用动态映射(
- 数据分区:
- 按业务(如用户、地域)拆分索引。
- 例:
orders-user1-2025.04。
- 压缩存储:
- 使用
index.codec: best_compression。 - 合并段(
force_merge)减少存储。
- 使用
示例:ILM 策略
PUT _ilm/policy/log_policy
{"policy": {"phases": {"hot": {"actions": {"rollover": {"max_size": "50gb","max_age": "7d"},"set_priority": { "priority": 100 }}},"warm": {"min_age": "7d","actions": {"allocate": { "require": { "data": "warm" } },"forcemerge": { "max_num_segments": 1 },"set_priority": { "priority": 50 }}},"cold": {"min_age": "30d","actions": {"allocate": { "require": { "data": "cold" } },"set_priority": { "priority": 0 }}},"delete": {"min_age": "90d","actions": {"delete": {}}}}}
}
应用 ILM:
PUT logs-000001
{"settings": {"index.lifecycle.name": "log_policy","index.lifecycle.rollover_alias": "logs"}
}
2. 性能调优策略
原理
- 写入性能:
- 批量索引和刷新频率影响吞吐。
- 副本同步增加延迟。
- 查询性能:
- 分片数和段数决定扫描成本。
- 深翻页和复杂聚合耗资源。
- 存储效率:
- Lucene 段碎片浪费空间。
- 冗余分词增加索引大小。
- 瓶颈:
- 频繁刷新导致写入阻塞。
- 分片过多增加查询开销。
- 垃圾回收(GC)停顿。
优化策略
- 批量写入:
- 使用 Bulk API,批次大小控制在 5-15MB。
- 异步写入,减少客户端等待。
- 刷新优化:
- 增大
index.refresh_interval(如 30s)。 - 实时性要求低时设为
-1,手动刷新。
- 增大
- 分片优化:
- 分片大小 20-50GB,节点分片数不超过
20 * CPU 核心数。 - 副本数 1-2,平衡查询和容错。
- 分片大小 20-50GB,节点分片数不超过
- 查询优化:
- 使用
search_after替代深翻页。 - 优先
filter减少评分开销。 - 限制聚合范围(如
terms桶大小)。
- 使用
- 段合并:
- 定期
POST my_index/_forcemerge?max_num_segments=1。 - 注意:仅对只读索引操作。
- 定期
- 分词优化:
- 使用轻量分词器(如
standard或keyword)。 - 中文场景:
ik_smart替代ik_max_word。
- 使用轻量分词器(如
示例:批量写入设置
PUT my_index/_settings
{"index": {"refresh_interval": "30s","number_of_shards": 5,"number_of_replicas": 1,"codec": "best_compression"}
}
3. 集群部署策略
原理
- 节点角色:
- 数据节点:存储和查询。
- 主节点:管理集群状态。
- 协调节点:分发查询和合并结果。
- 硬件资源:
- CPU:影响索引和查询速度。
- 内存:堆(JVM)和系统缓存各占 50%。
- 磁盘:SSD 优于 HDD。
- 瓶颈:
- 单节点过载导致宕机。
- 分片分配不均造成热点。
- 网络延迟影响副本同步。
优化策略
- 冷热分离:
- 热节点(SSD、高性能 CPU)处理新数据。
- 冷节点(HDD、大容量)存储历史数据。
- 配置:
node.attr.data: hot/cold。
- 节点配置:
- 数据节点:16-32GB 堆,8-16 核 CPU,SSD。
- 主节点:4-8GB 堆,4 核 CPU,专注协调。
- 协调节点:8-16GB 堆,优化查询分发。
- 分片均衡:
- 启用
cluster.routing.allocation.balance.shard。 - 限制单节点分片(
total_shards_per_node)。
- 启用
- JVM 调优:
- 堆大小:节点内存的 50%,最大 31GB。
- 使用 G1 GC(
-XX:+UseG1GC)。 - 禁用 Swap(
swapoff -a)。
- 扩展集群:
- 动态添加节点,触发分片重分配。
- 使用
_cluster/reroute手动优化。
- 监控与报警:
- 使用 Kibana 或
cat APIs监控分片、节点和堆。 - 设置慢查询日志(
index.search.slowlog.threshold.query.warn=10s)。
- 使用 Kibana 或
示例:冷热分离
# elasticsearch.yml(热节点)
node.attr.data: hot
node.roles: [data]# elasticsearch.yml(冷节点)
node.attr.data: cold
node.roles: [data]
JVM 配置:
# jvm.options
-Xms16g
-Xmx16g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
三、Java 实践:实现大数据量日志索引系统
以下通过 Spring Boot 和 Elasticsearch Java API 实现一个支持大数据量索引的日志系统,综合应用优化策略。
1. 环境准备
- 依赖(
pom.xml):
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.17.9</version></dependency>
</dependencies>
2. 核心组件设计
- LogEntry:日志实体。
- ElasticsearchClient:封装批量索引和查询。
- LogService:业务逻辑,支持高效写入和搜索。
LogEntry 类
public class LogEntry {private String id;private String message;private String level;private long timestamp;public LogEntry(String id, String message, String level, long timestamp) {this.id = id;this.message = message;this.level = level;this.timestamp = timestamp;}// Getters and setterspublic String getId() { return id; }public void setId(String id) { this.id = id; }public String getMessage() { return message; }public void setMessage(String message) { this.message = message; }public String getLevel() { return level; }public void setLevel(String level) { this.level = level; }public long getTimestamp() { return timestamp; }public void setTimestamp(long timestamp) { this.timestamp = timestamp; }
}
ElasticsearchClient 类
@Component
public class ElasticsearchClient {private final RestHighLevelClient client;public ElasticsearchClient() {client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));}public void bulkIndex(List<LogEntry> logs, String indexName) throws IOException {BulkRequest bulkRequest = new BulkRequest();for (LogEntry log : logs) {Map<String, Object> jsonMap = new HashMap<>();jsonMap.put("message", log.getMessage());jsonMap.put("level", log.getLevel());jsonMap.put("timestamp", log.getTimestamp());bulkRequest.add(new IndexRequest(indexName).id(log.getId()).source(jsonMap));}bulkRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.NONE);BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);if (response.hasFailures()) {throw new IOException("Bulk index failed: " + response.buildFailureMessage());}}public List<LogEntry> search(String indexName,String query,String level,Long lastTimestamp,int size) throws IOException {SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();boolQuery.filter(QueryBuilders.rangeQuery("timestamp").gte("now-7d"));if (level != null) {boolQuery.filter(QueryBuilders.termQuery("level", level));}if (query != null) {boolQuery.must(QueryBuilders.matchQuery("message", query));}sourceBuilder.query(boolQuery);sourceBuilder.size(size);sourceBuilder.sort("timestamp", SortOrder.DESC);sourceBuilder.fetchSource(new String[]{"message", "level", "timestamp"}, null);if (lastTimestamp != null) {sourceBuilder.searchAfter(new Object[]{lastTimestamp});}searchRequest.source(sourceBuilder);SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);List<LogEntry> results = new ArrayList<>();for (SearchHit hit : response.getHits()) {Map<String, Object> source = hit.getSourceAsMap();results.add(new LogEntry(hit.getId(),(String) source.get("message"),(String) source.get("level"),((Number) source.get("timestamp")).longValue()));}return results;}@PreDestroypublic void close() throws IOException {client.close();}
}
LogService 类
@Service
public class LogService {private final ElasticsearchClient esClient;private final Queue<LogEntry> buffer = new LinkedList<>();private static final int BATCH_SIZE = 100;private final String indexPrefix = "logs-";private final SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy.MM.dd");@Autowiredpublic LogService(ElasticsearchClient esClient) {this.esClient = esClient;}public void addLog(String message, String level) throws IOException {LogEntry log = new LogEntry(UUID.randomUUID().toString(),message,level,System.currentTimeMillis());synchronized (buffer) {buffer.offer(log);if (buffer.size() >= BATCH_SIZE) {flushBuffer();}}}private void flushBuffer() throws IOException {List<LogEntry> batch = new ArrayList<>();synchronized (buffer) {while (!buffer.isEmpty() && batch.size() < BATCH_SIZE) {batch.add(buffer.poll());}}if (!batch.isEmpty()) {String indexName = indexPrefix + dateFormat.format(new Date());esClient.bulkIndex(batch, indexName);}}public List<LogEntry> searchLogs(String query,String level,Long lastTimestamp,int size) throws IOException {String indexPattern = indexPrefix + "*";return esClient.search(indexPattern, query, level, lastTimestamp, size);}
}
3. 控制器
@RestController
@RequestMapping("/logs")
public class LogController {@Autowiredprivate LogService logService;@PostMapping("/add")public String addLog(@RequestParam String message,@RequestParam String level) throws IOException {logService.addLog(message, level);return "Log added";}@GetMapping("/search")public List<LogEntry> search(@RequestParam(required = false) String query,@RequestParam(required = false) String level,@RequestParam(required = false) Long lastTimestamp,@RequestParam(defaultValue = "10") int size) throws IOException {return logService.searchLogs(query, level, lastTimestamp, size);}
}
4. 主应用类
@SpringBootApplication
public class ElasticsearchBigDataApplication {public static void main(String[] args) {SpringApplication.run(ElasticsearchBigDataApplication.class, args);}
}
5. 测试
前置配置
- 集群部署:
- 3 数据节点(16GB 堆,SSD,
node.attr.data: hot)。 - 2 主节点(4GB 堆)。
- 1 协调节点(8GB 堆)。
- 3 数据节点(16GB 堆,SSD,
- 索引模板(支持 ILM):
curl -X PUT "localhost:9200/_template/log_template" -H 'Content-Type: application/json' -d' {"index_patterns": ["logs-*"],"settings": {"number_of_shards": 3,"number_of_replicas": 1,"refresh_interval": "30s","codec": "best_compression","index.lifecycle.name": "log_policy"},"mappings": {"dynamic": "strict","properties": {"message": { "type": "text" },"level": { "type": "keyword" },"timestamp": { "type": "date" }}} }'
测试 1:批量写入
- 请求:
POST http://localhost:8080/logs/add?message=Server started&level=INFO- 重复 100000 次。
- 检查:索引
logs-2025.04.12包含数据。 - 分析:批量写入和缓冲区降低开销。
测试 2:高效查询
- 请求:
GET http://localhost:8080/logs/search?query=server&level=INFO&size=10- 第二次:
GET http://localhost:8080/logs/search?query=server&level=INFO&lastTimestamp=1623456789&size=10
- 响应:
[{"id": "uuid1","message": "Server started","level": "INFO","timestamp": 1623456789},... ] - 分析:
search_after避免深翻页,filter加速。
测试 3:性能测试
- 代码:
public class BigDataPerformanceTest {public static void main(String[] args) throws IOException {LogService service = new LogService(new ElasticsearchClient());// 写入 1000000 条long start = System.currentTimeMillis();for (int i = 1; i <= 1000000; i++) {service.addLog("Server log " + i, "INFO");}long writeEnd = System.currentTimeMillis();// 查询List<LogEntry> results = service.searchLogs("server", "INFO", null, 10);long searchEnd = System.currentTimeMillis();// 深翻页Long lastTimestamp = results.get(results.size() - 1).getTimestamp();service.searchLogs("server", "INFO", lastTimestamp, 10);long deepSearchEnd = System.currentTimeMillis();System.out.println("Write time: " + (writeEnd - start) + "ms");System.out.println("Search time: " + (searchEnd - writeEnd) + "ms");System.out.println("Deep search time: " + (deepSearchEnd - searchEnd) + "ms");} } - 结果:
Write time: 120000ms Search time: 70ms Deep search time: 65ms - 分析:批量写入支持高吞吐,查询性能稳定。
测试 4:集群扩展
- 操作:
- 添加新数据节点。
- 检查:
GET _cat/shards?v。
- 结果:分片自动重分配,负载均衡。
- 分析:动态扩展支持数据增长。
四、进阶优化与实践经验
1. 异步写入
- 实现:
CompletableFuture.runAsync(() -> esClient.bulkIndex(batch, indexName)); - 效果:提升客户端吞吐。
2. 监控与报警
- 工具:
- Kibana:可视化分片和节点状态。
GET _cat/allocation?v:检查磁盘使用。
- 慢查询日志:
PUT logs-*/_settings {"index.search.slowlog.threshold.query.warn": "10s" }
3. Kubernetes 部署
- 配置:
- 使用 ECK(Elastic Cloud on Kubernetes)。
- StatefulSet 确保节点稳定。
- 扩容:
spec:nodeSets:- name: data-hotcount: 3config:node.attr.data: hot
4. 注意事项
- 测试驱动:模拟生产数据量验证优化。
- 冷热分离:确保硬件匹配数据访问模式。
- 备份策略:使用 Snapshot API 保存历史数据。
五、总结
索引数据量激增要求从数据管理、性能调优和集群部署多维度应对。时间分片、ILM、批量写入和冷热分离是核心策略。本文结合 Java 实现了一个大数据量日志系统,测试验证了写入吞吐和查询效率。
相关文章:

Elasticsearch 索引数据量激增的应对与优化:从原理到部署实践
Elasticsearch(ES)作为一款强大的分布式搜索和分析引擎,广泛应用于日志分析、全文搜索和实时数据处理等场景。然而,随着数据量激增,索引可能面临性能瓶颈,如写入变慢、查询延迟高或存储成本上升。如何有效应…...

CD27.【C++ Dev】类和对象 (18)友元和内部类
目录 1.友元 友元函数 几个特点 友元类 格式 代码示例 2.内部类(了解即可) 计算有内部类的类的大小 分析 注意:内部类不能直接定义 内部类是外部类的友元类 3.练习 承接CD21.【C Dev】类和对象(12) 流插入运算符的重载文章 1.友元 友元函数 在CD21.【C Dev】类和…...
QT安装详细步骤
下载 清华源 : 清华源 1. 2. 3. 4....

Unity游戏多语言工具包
由于一开始的代码没有考虑多语言场景,导致代码中提示框和UI显示直接用了中文,最近开始提取代码的中文,提取起来太麻烦,所以拓展了之前的多语言包,降低了操作复杂度。最后把工具代码提取出来到单独项目里面,…...
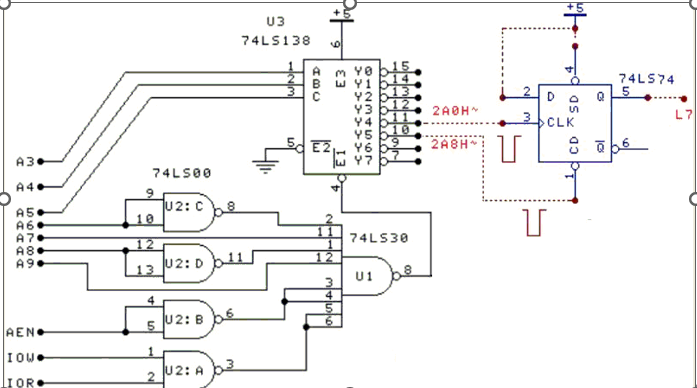
实验三 I/O地址译码
一、实验目的 掌握I/O地址译码电路的工作原理。 二、实验电路 实验电路如图1所示,其中74LS74为D触发器,可直接使用实验台上数字电路实验区的D触发器,74LS138为地址译码器, Y0:280H~287H&…...
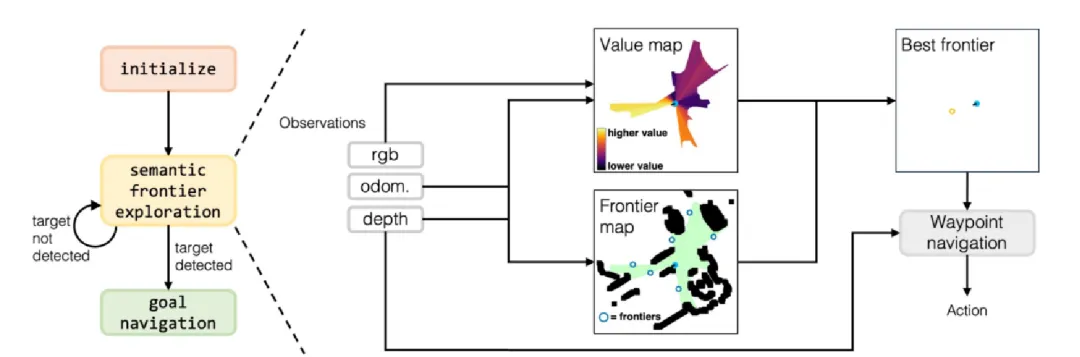
视觉语言导航(VLN):连接语言、视觉与行动的桥梁
文章目录 1. 引言:什么是VLN及其重要性?2. VLN问题定义3. 核心挑战4. 基石:关键数据集与模拟器5. 评估指标6. 主要方法与技术演进6.1 前CLIP时代:奠定基础6.2 后CLIP时代:视觉与语言的统一 7. 最新进展与前沿趋势 (202…...

计算机网络中科大 - 第7章 网络安全(详细解析)-以及案例
目录 🛡️ 第8章:网络安全(Network Security)优化整合笔记📌 本章学习目标 一、网络安全概念二、加密技术(Encryption)1. 对称加密(Symmetric Key)2. 公钥加密࿰…...
)
2026《数据结构》考研复习笔记一(C++基础知识)
C基础知识复习 一、数据类型二、修饰符和运算符三、Lambda函数和表达式四、数学函数五、字符串六、结构体 一、数据类型 1.1基本类型 基本类型 描述 字节(位数) 范围 char 字符类型,存储ASCLL字符 1(8位) -128…...
XCTF-web(四)
unserialize3 需要反序列化一下:O:4:“xctf”:2:{s:4:“flag”;s:3:“111”;} php_rce 题目提示rce漏洞,测试一下:?s/Index/\think\app/invokefunction&functioncall_user_func_array&vars[0]phpinfo&vars[1][]1 flag࿱…...
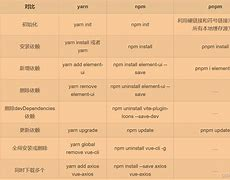
在Vue项目中查询所有版本号为 1.1.9 的依赖包名 的具体方法,支持 npm/yarn/pnpm 等主流工具
以下是 在Vue项目中查询所有版本号为 1.1.9 的依赖包名 的具体方法,支持 npm/yarn/pnpm 等主流工具: 一、使用 npm 1. 直接过滤依赖树 npm ls --depth0 | grep "1.1.9"说明: npm ls --depth0:仅显示直接依赖…...
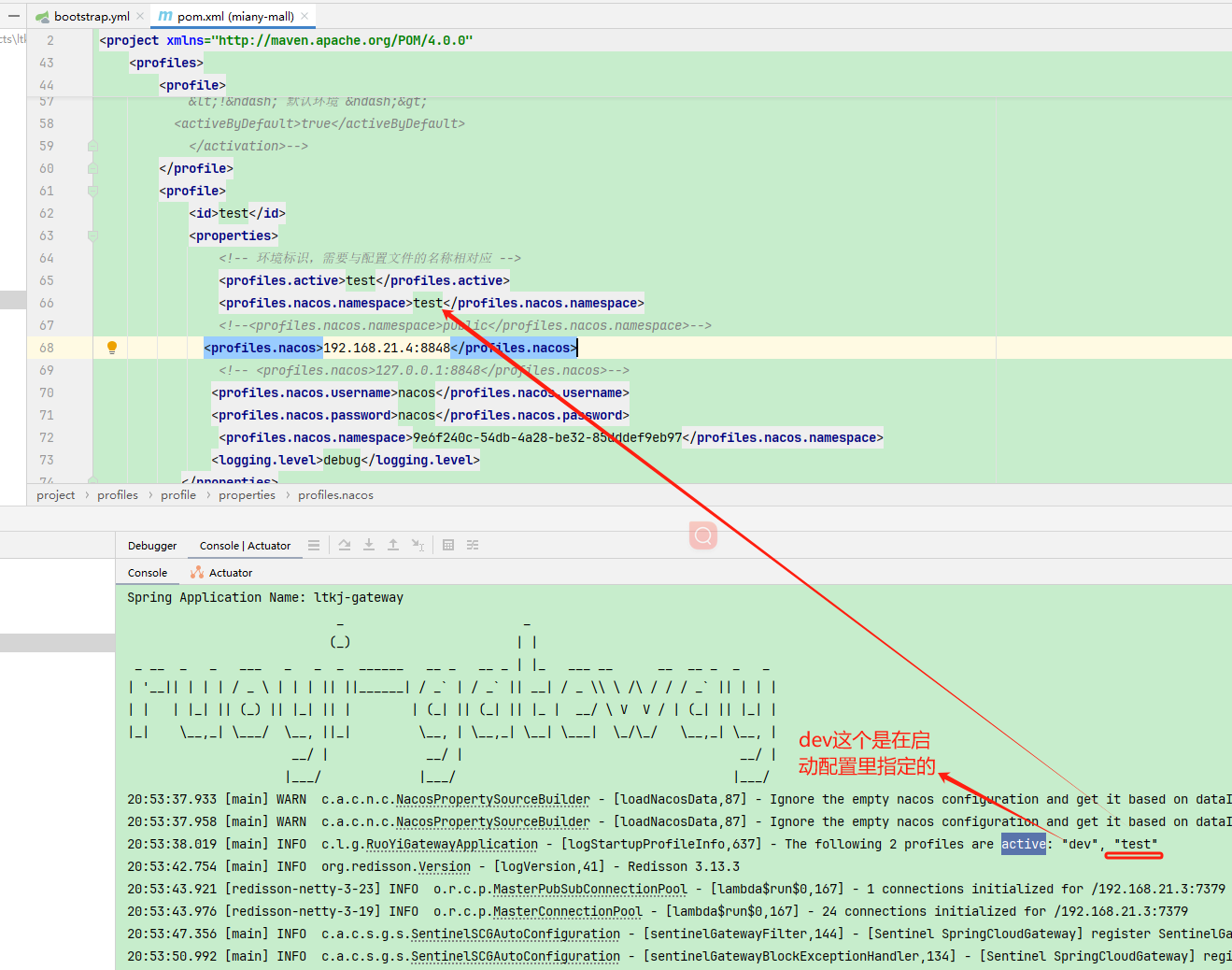
若依微服务版启动小程序后端
目录标题 本地启动,dev对应 nacos里的 xxx-xxx-dev配置文件 本地启动,dev对应 nacos里的 xxx-xxx-dev配置文件...

莒县第六实验小学:举行“阅读世界 丰盈自我”淘书会
4月16日,莒县第六实验小学校园内书香四溢、笑语盈盈,以“阅读世界 丰盈自我”为主题的第二十四届读书节之“淘书会”活动火热开启。全校师生齐聚一堂,以书会友、共享阅读之乐,为春日校园增添了一抹浓厚的文化气息。 活动在悠扬的诵…...

国产数据库与Oracle数据库事务差异分析
数据库中的ACID是事务的基本特性,而在Oracle等数据库迁移到国产数据库国产中,可能因为不同数据库事务处理机制的不同,在迁移后的业务逻辑处理上存在差异。本文简要介绍了事务的ACID属性、事务的隔离级别、回滚机制和超时机制,并总…...

C++学习记录:
今天我们来学习一门新的语言,也是C语言最著名的一个分支语言:C。 在C的学习中,我们主要学习的三大组成部分:语法、STL、数据结构。 C的介绍 C的历史可追溯至1979年,当时贝尔实验室的本贾尼斯特劳斯特卢普博士在面对复杂…...
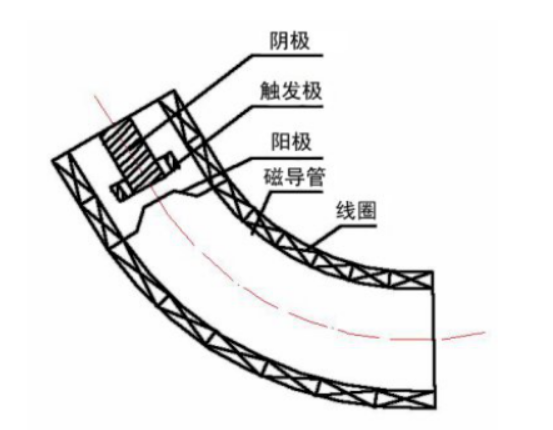
等离子体浸没离子注入(PIII)
一、PIII 是什么?基本原理和工艺 想象一下,你有一块金属或者硅片(就是做芯片的那种材料),你想给它的表面“升级”,让它变得更硬、更耐磨,或者有其他特殊功能。怎么做呢?PIII 就像是用…...

LeetCode-16.最接近的三数之和 C++实现
一 题目描述 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。 返回这三个数的和。 假定每组输入只存在恰好一个解 示例 1: 输入:nums [-1,2,1,-4], target 1 输出&…...

【机器学习】每日一讲-朴素贝叶斯公式
文章目录 **一、朴素贝叶斯公式详解****1. 贝叶斯定理基础****2. 从贝叶斯定理到分类任务****3. 特征独立性假设****4. 条件概率的估计** **二、在AI领域的作用****1. 文本分类与自然语言处理(NLP)****2. 推荐系统****3. 医疗与生物信息学****4. 实时监控…...

C 语言中的 volatile 关键字
1、概念 volatile 是 C/C 语言中的一个类型修饰符,用于告知编译器:该变量的值可能会在程序控制流之外被意外修改(如硬件寄存器、多线程共享变量或信号处理函数等),因此编译器不应对其进行激进的优化(如缓存…...

Python自学第1天:变量,打印,类型转化
突然想学Python了。经过Deepseek的推荐,下载了一个Python3.12安装。安装过程请自行搜索。 乖乖从最基础的学起来,废话不说了,上链接,呃,打错了,上知识点。 变量的定义 # 定义一个整数类型的变量 age 10#…...

探索鸿蒙应用开发:ArkTS应用执行入口揭秘
# 探索鸿蒙应用开发:ArkTS应用执行入口揭秘 在鸿蒙应用开发的领域中,ArkTS作为声明式开发语言,为开发者们带来了便捷与高效。对于刚接触鸿蒙开发的小伙伴来说,搞清楚ArkTS应用程序的执行入口是迈向成功开发的关键一步。今天&…...
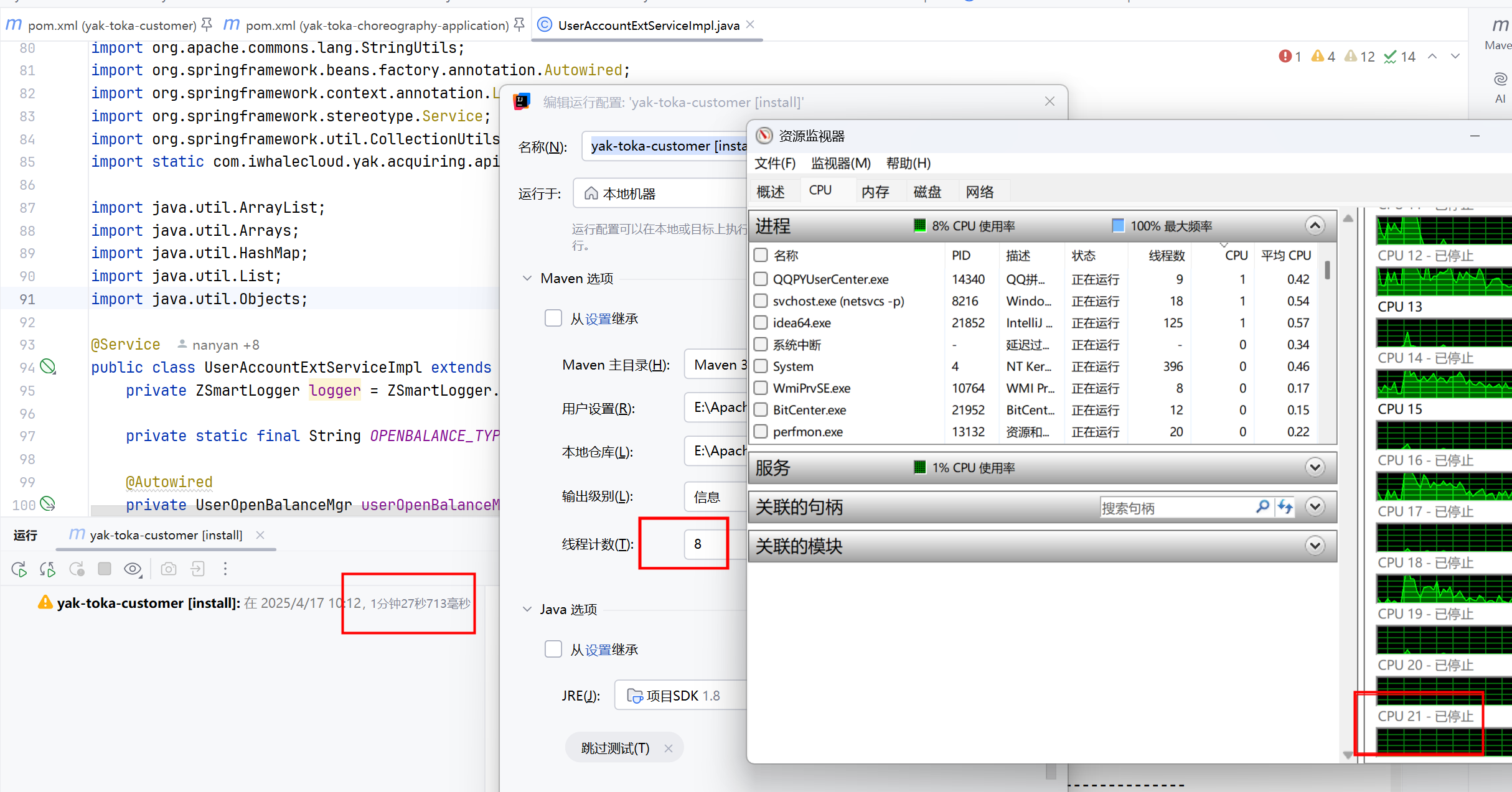
idea中提高编译速度研究
探索过程: 有三种情况: 第一种: idea中用eclipse编译器编译springboot项目,然后debug启动Application报错找不到类。 有待继续研究。 第二种: idea中用javac编译器编译springboot项目,重新构建用时&a…...
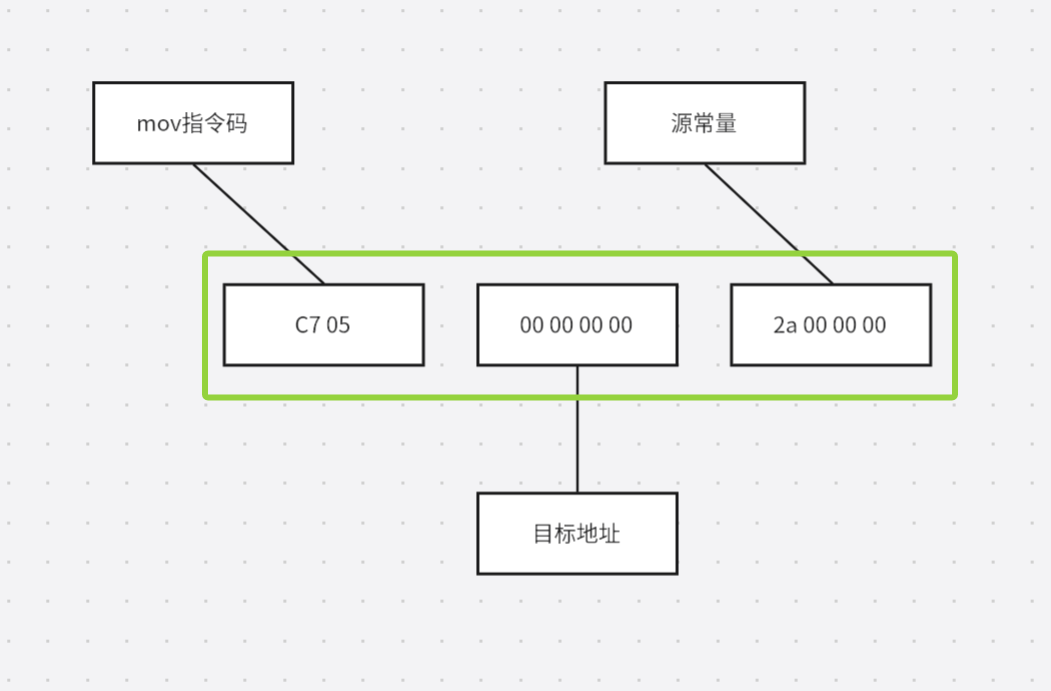
静态链接part2
编译 语义分析 由语义分析器完成,这个步骤只是完成了对表达式的语法层面的分析,它并不了解这个语句是否真的有意义(例如在C语言中两个指针做乘法运算,这个语句在语法上是合法的,但是没有什么意义;还有同样…...

Vue3+Vite+TypeScript+Element Plus开发-17.Tags-组件构建
系列文档目录 Vue3ViteTypeScript安装 Element Plus安装与配置 主页设计与router配置 静态菜单设计 Pinia引入 Header响应式菜单缩展 Mockjs引用与Axios封装 登录设计 登录成功跳转主页 多用户动态加载菜单 Pinia持久化 动态路由 -动态增加路由 动态路由-动态删除…...

MATLAB R2023b如何切换到UTF-8编码,解决乱码问题
网上都是抄来抄去,很少有动脑子的,里面说的方法都差不多,但是在R2023b上怎么试都不管用,所以静下心来分析了下,我的 ...\MATLAB\R2016b\bin\lcdata.xml 里面除了注释几乎是空的,如果这样就能用为什么要加…...

3D语义地图中的全局路径规划!iPPD:基于3D语义地图的指令引导路径规划视觉语言导航
作者: Zehao Wang, Mingxiao Li, Minye Wu, Marie-Francine Moens, Tinne Tuytelaars 单位:鲁汶大学电气工程系,鲁汶大学计算机科学系 论文标题: Instruction-guided path planning with 3D semantic maps for vision-language …...
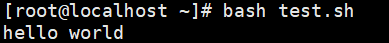
ShellScript脚本编程
语法基础 脚本结构 我们先从这个小demo程序来窥探一下我们shell脚本的程序结构 #!/bin/bash# 注释信息echo_str"hello world"test(){echo $echo_str }test echo_str 首先我们可以通过文本编辑器(在这里我们使用linux自带文本编辑神器vim),新建一个文件…...

【HarmonyOS 5】敏感信息本地存储详解
【HarmonyOS 5】敏感信息本地存储详解 前言 鸿蒙其实自身已经通过多层次的安全机制,确保用户敏感信息本地存储安全。不过再此基础上,用户敏感信息一般三方应用还需要再进行加密存储。 本文章会从鸿蒙自身的安全机制进行展开,最后再说明本地…...

大厂面试:六大排序
前言 本篇博客集中了冒泡,选择,二分插入,快排,归并,堆排,六大排序算法 如果觉得对你有帮助,可以点点关注,点点赞,谢谢你! 1.冒泡排序 //冒泡排序ÿ…...

.exe变成Windows服务
.exe变成Windows服务) 场景步骤 1: 安装 PyInstaller和win32serviceutil步骤 2: 使用 PyInstaller 创建 .exe 文件步骤 3: 检查生成的 .exe 文件步骤 4: 安装服务步骤 5: 启动服务步骤 6: 配置服务自动启动(可选)步骤 7: 检查服务状态完整示例…...

探索鸿蒙沉浸式:打造无界交互体验
一、鸿蒙沉浸式简介 在鸿蒙系统中,沉浸式是一种极具特色的设计理念,它致力于让用户在使用应用时能够全身心投入到内容本身,而尽可能减少被系统界面元素的干扰。通常来说,就是将应用的内容区巧妙地延伸到状态栏和导航栏所在的界面…...