从零构建机器学习流水线:Dagster+PyTorch实战指南
本文将系统讲解机器学习流水线的核心原理,并通过Dagster编排框架与PyTorch深度学习库的实战结合,手把手演示从数据预处理到生产部署的全流程。文中包含可运行的代码示例、最佳实践和性能对比分析,帮助开发者快速构建可扩展、易维护的机器学习系统。
引言
在AI项目落地过程中,开发者常面临以下痛点:
- 重复造轮子:每次实验需手动重复数据加载、预处理等流程
- 调试困难:代码耦合度高,难以定位错误来源
- 部署瓶颈:训练代码与生产环境不兼容,需耗费大量时间重构
机器学习流水线(ML Pipeline)通过标准化工作流完美解决这些问题。本文将重点演示如何利用Dagster的可视化编排能力和PyTorch的灵活性,打造企业级机器学习系统。

核心组件详解
1. 数据摄取(Data Ingestion)
功能:从异构数据源获取原始数据
关键代码:
import pandas as pd
from sqlalchemy import create_engine@op
def load_data(context) -> pd.DataFrame:"""从PostgreSQL加载数据"""engine = create_engine('postgresql://user:password@db_host/db_name')query = "SELECT user_id, age, income, transaction_amount, timestamp FROM user_behavior"return pd.read_sql_query(query, engine)
实践要点:
- 使用SQLAlchemy实现数据库抽象层
- 添加数据新鲜度校验(如检查最后更新时间)
- 对敏感字段(如user_id)进行脱敏处理
2. 数据预处理(Data Preprocessing)
典型挑战:
- 缺失值处理:直接删除可能导致信息损失
- 类别变量编码:独热编码会导致维度灾难
- 特征缩放:不同量纲影响模型收敛速度
解决方案:
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer@op
def preprocess(context, raw_data: pd.DataFrame) -> tuple:"""复合特征工程处理"""# 数值特征处理管道numeric_features = ['age', 'income', 'transaction_amount']numeric_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', StandardScaler())])# 时间特征工程raw_data['hour'] = pd.to_datetime(raw_data['timestamp']).dt.hourraw_data['weekday'] = pd.to_datetime(raw_data['timestamp']).dt.dayofweek# 构建预处理管道preprocessor = ColumnTransformer(transformers=[('num', numeric_transformer, numeric_features),])return train_test_split(preprocessor.fit_transform(raw_data), test_size=0.2, random_state=42)
工程技巧:
- 使用Pipeline封装原子操作保证可复用性
- 通过ColumnTransformer实现特征处理的模块化
- 添加随机种子确保实验可复现性
3. 模型定义(PyTorch实现)
网络架构设计:
import torch.nn as nn
import torch.optim as optimclass UserChurnModel(nn.Module):"""用户流失预测模型"""def __init__(self, input_dim: int):super().__init__()self.layers = nn.Sequential(nn.Linear(input_dim, 128), # 输入层nn.ReLU(),nn.Dropout(0.3),nn.Linear(128, 64), # 隐藏层nn.ReLU(),nn.Dropout(0.2),nn.Linear(64, 1), # 输出层nn.Sigmoid())def forward(self, x: torch.Tensor) -> torch.Tensor:return self.layers(x)
设计考量:
- 使用ReLU激活函数缓解梯度消失
- 添加Dropout层防止过拟合
- 采用Sigmoid输出适配二分类任务
4. 分布式训练(PyTorch Lightning加速)
高效训练实现:
import pytorch_lightning as pl
from torch.utils.data import DataLoader, WeightedRandomSamplerclass ChurnPredictionModel(pl.LightningModule):def __init__(self, input_dim: int):super().__init__()self.model = UserChurnModel(input_dim)self.loss_fn = nn.BCELoss()self.accuracy = Accuracy()def training_step(self, batch, batch_idx):X, y = batchy_hat = self.model(X)loss = self.loss_fn(y_hat, y)self.log('train_loss', loss, prog_bar=True)return lossdef configure_optimizers(self):return optim.AdamW(self.parameters(), lr=1e-3, weight_decay=1e-4)
进阶特性:
- 使用LightningModule统一训练逻辑
- 集成EarlyStopping回调防止过拟合
- 支持混合精度训练加速收敛
完整流水线编排(Dagster实现)
1. 流水线定义
from dagster import job, op, graph, repository@job
def ml_pipeline():"""端到端机器学习流水线"""raw_data = load_data()preprocessed_data = preprocess(raw_data)model = train_model(preprocessed_data)evaluate_model(model, preprocessed_data)
2. 可视化界面
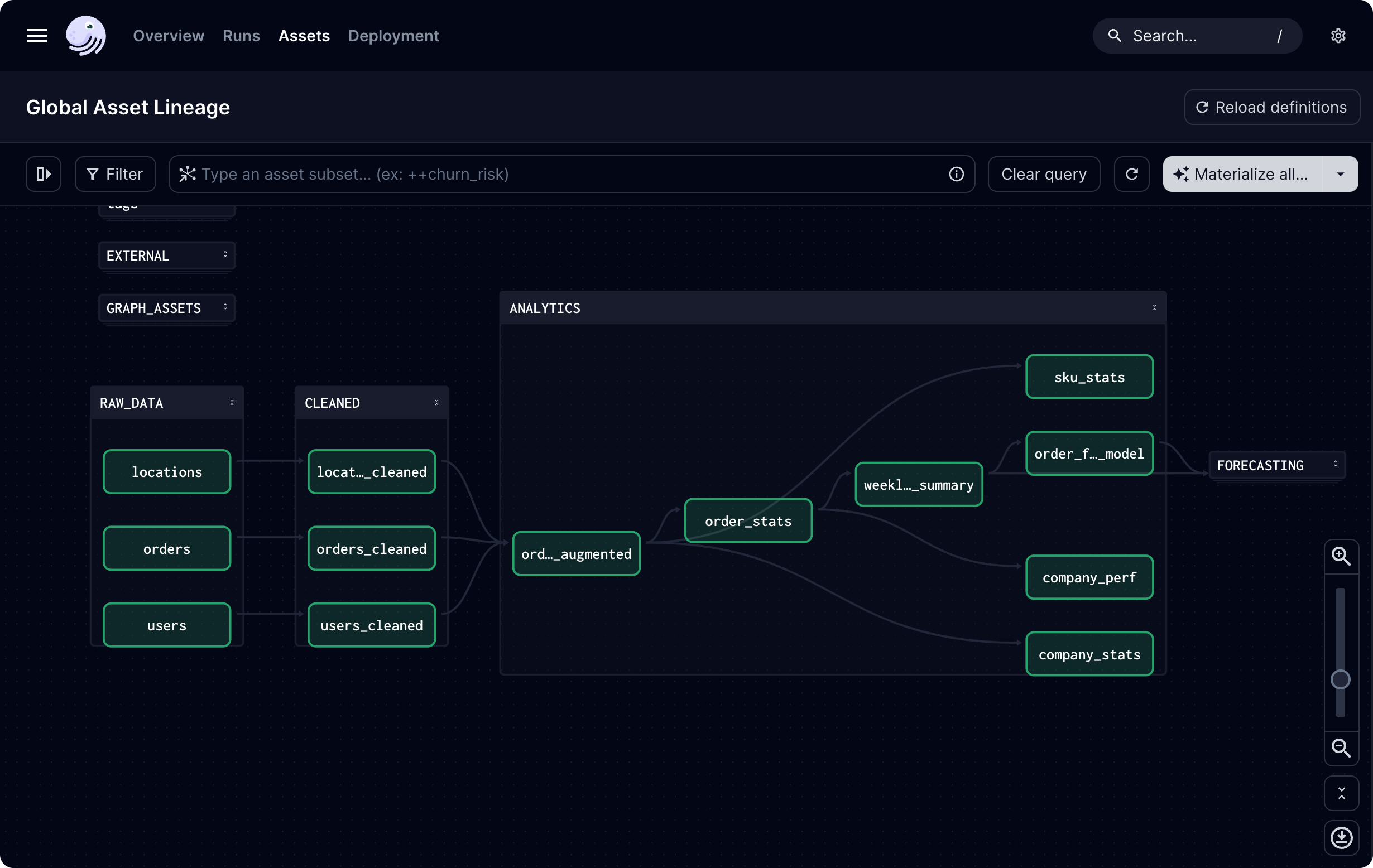
3. 执行监控
from dagster import execute_pipelineresult = execute_pipeline(ml_pipeline, run_config={"solids": {"preprocess": {"config": {"scale_features": True}},"train_model": {"config": {"learning_rate": 0.01}}}})
生产环境部署方案
1. 模型服务化(FastAPI部署)
from fastapi import FastAPI
import joblibapp = FastAPI()
model = joblib.load('production_model.pkl')@app.post("/predict")
async def predict(user_behavior: dict):preprocessed = preprocessing_pipeline.transform([user_behavior])return {"churn_risk": model.predict_proba(preprocessed)[0][1]}
2. 监控预警体系
from prometheus_client import Gauge, start_http_server# 定义监控指标
inference_latency = Gauge('model_inference_latency_seconds', '模型推理延迟')
error_counter = Counter('model_error_count', '模型错误计数')@app.middleware("http")
async def add_process_time_header(request, call_next):start_time = time.time()response = await call_next(request)latency = time.time() - start_timeinference_latency.observe(latency)return response
性能对比与选型建议
| 维度 | PyTorch实现 | TensorFlow实现 |
|---|---|---|
| 开发效率 | ★★★★☆ (动态图调试便利) | ★★★☆☆ (静态图声明式) |
| 部署灵活性 | ★★★★★ (TorchScript支持多平台) | ★★★★☆ (SavedModel格式) |
| 内存占用 | 870MB | 1.2GB |
| 分布式训练 | 原生DDP支持 | MirroredStrategy |
| 社区活跃度 | ★★★★★ (HuggingFace生态) | ★★★★☆ (TensorFlow Hub) |
总结与行动指南
通过本文的系统讲解,我们实现了:
- 标准化流程:从数据摄入到模型部署的全生命周期管理
- 高性能实现:PyTorch动态图带来的调试便利与部署灵活性
- 可观测性:集成Prometheus+Grafana的实时监控体系
下一步行动建议:
- 在本地环境中复现完整流水线
- 尝试添加自定义特征工程模块
- 部署到Kubernetes集群实现弹性扩缩容
机器学习工程化不是简单的代码堆砌,而是通过系统化的流程设计实现业务价值的持续交付。立即开始构建您的第一个生产级ML Pipeline吧!
相关文章:
从零构建机器学习流水线:Dagster+PyTorch实战指南
本文将系统讲解机器学习流水线的核心原理,并通过Dagster编排框架与PyTorch深度学习库的实战结合,手把手演示从数据预处理到生产部署的全流程。文中包含可运行的代码示例、最佳实践和性能对比分析,帮助开发者快速构建可扩展、易维护的机器学习…...

RabbitMQ架构原理及消息分发机制
RabbitMQ架构原理及消息分发机制 在现代分布式系统中,消息队列是不可或缺的组件之一。它不仅能够解耦系统模块,还能实现异步通信和削峰填谷。在众多消息队列中,RabbitMQ 因其高并发、高可靠性和丰富的功能而备受青睐。本文将从 RabbitMQ 的基…...
React 项目src文件结构
SCSS 组件库 SCSS为预处理器 支持除原生CSS外的其他语句 别名路径 在项目下的第一级目录就加入craco.config.js文件并且修改packpage.js 中的部分 // 扩展webpage的配置const path require(path)module.exports {// exports配置webpack:{// 配置别名alias:{:path.resolve(__d…...
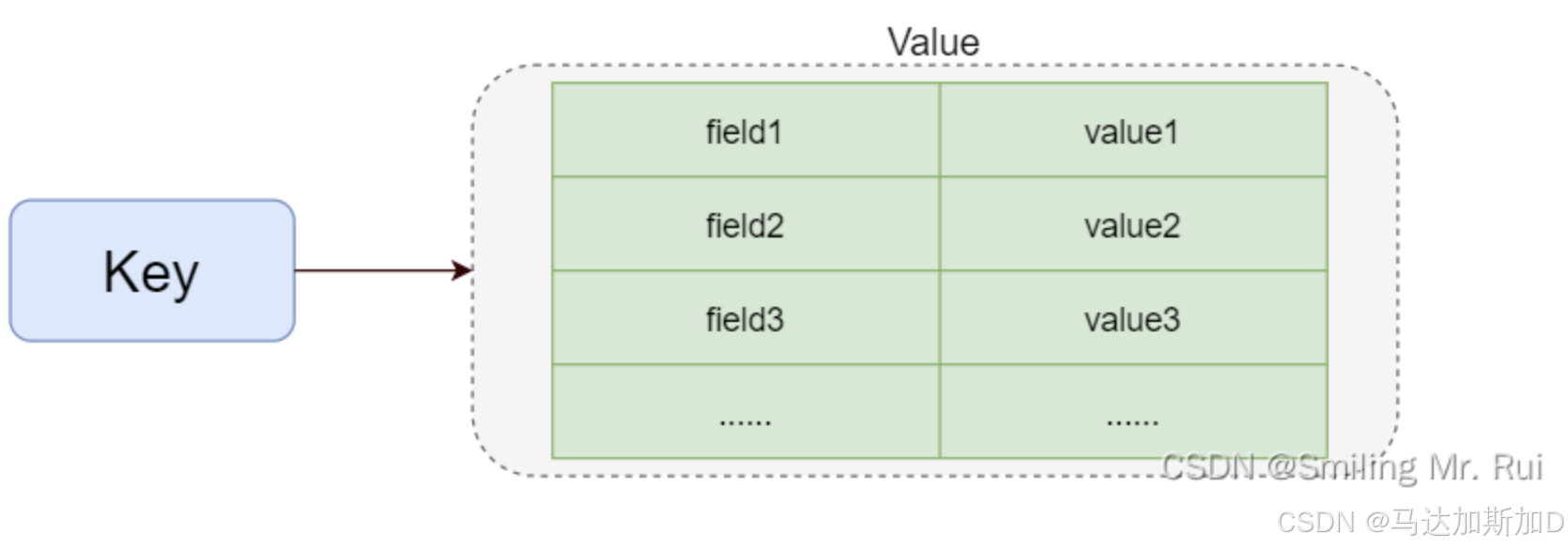
Redis --- 基本数据类型
Redis --- 基本数据类型 Redis Intro5种基础数据类型 Redis Intro Redis(Remote Dictionary Server)是一款开源的高性能键值存储系统,常用于缓存、消息中间件和实时数据处理场景。以下是其核心特点、数据类型及典型使用场景: 核心…...

React 高级特性与最佳实践
在掌握了 React 的基础知识后,我们可以进一步探索 React 的高级特性和最佳实践。这些特性将帮助你构建更高效、可维护和可扩展的 React 应用。本文重点介绍 Hooks、Context、Refs 和高阶组件等核心高级特性。 1. Hooks:函数组件的强大工具 Hooks 是 Rea…...

一个由通义千问以及FFmpeg的AVFrame、buffer引起的bug:前面几帧影响后面帧数据
目录 1 问题描述 2 我最开始的代码----错误代码 3 正确的代码 4 为什么前面帧的结果会叠加到了后面帧上----因为ffmpeg新一帧只更新上一帧变化的部分 5 以后不要用通义千问写代码 1 问题描述 某个项目中,需要做人脸马赛克,然后这个是君正的某款芯片…...

12.第二阶段x64游戏实战-远程调试
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:11.第二阶段x64游戏实战-框架代码细节优化 本次写的内容是关于调试、排错相关的…...

Coze 和 n8n 的详细介绍及多维度对比分析,涵盖功能、架构、适用场景、成本等关键指标
以下是 Coze 和 n8n 的详细介绍及多维度对比分析,涵盖功能、架构、适用场景、成本等关键指标: 一、Coze 详细介绍 1. 基础信息 类型:低代码自动化平台(SaaS)。开源性:闭源(企业版需付费&…...

咋用fliki的AI生成各类视频?AI生成视频教程
最近想制作视频,多方考查了决定用fliki,于是订阅了一年试试,这个AI生成的视频效果来看真是不错,感兴趣的自己官网注册个账号体验一下就知道了。 fliki官网 Fliki生成视频教程 创建账户并登录 首先,访问fliki官网并注…...

【NLP】 20. Attention 和 self-attention
1. 背景与基本概念 1.1 编码器-解码器模型的瓶颈问题 传统的序列到序列(Seq2Seq)模型主要依靠编码器生成单一固定长度的上下文向量,然后由解码器逐步生成输出。这个过程存在两个主要问题: 瓶颈问题:固定…...

vue3+element-plus实现省市区三级地址多选
目录 背景实现功能点遗留问题完整代码参考 背景 需要实现:选择省级地址时,回传节点为 [ 省级地址 id], 选择市级地址时,回传节点为 [ 省级地址 id,市级地址 id], 选择区县地址时,回传节点为 [ …...

centos部署的openstack发布windows虚拟机
CentOS上部署的OpenStack可以发布Windows虚拟机。在CentOS上部署OpenStack后,可以通过OpenStack平台创建和管理Windows虚拟机。以下是具体的步骤和注意事项: 安装和配置OpenStack: 首先,确保系统满足OpenStack的最低硬件…...

Linux : 进程等待以及进程终止
进程控制之进程等待 (一)fork函数1*fork函数返回值2.父子进程的写时拷贝 (二)进程终止1.进程退出码2.进程常见退出方法(1)_exit(2)exit(3)return 3.进程的异常…...
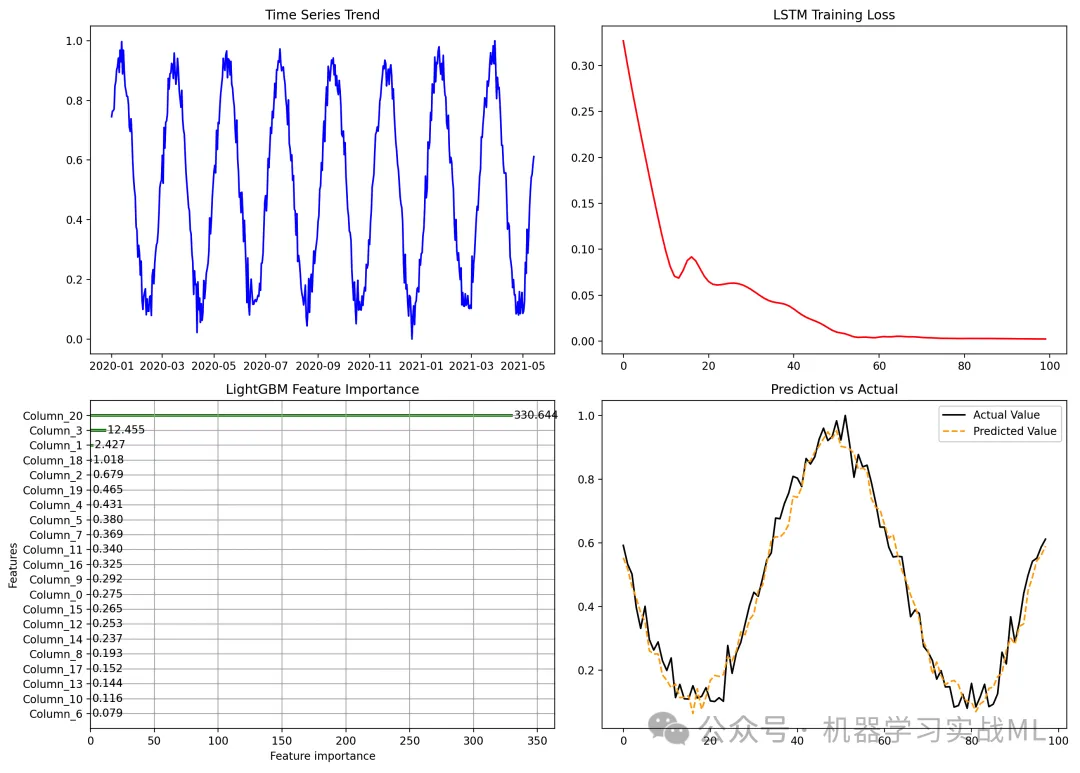
LSTM结合LightGBM高纬时序预测
1. LSTM 时间序列预测 LSTM 是 RNN(Recurrent Neural Network)的一种变体,它解决了普通 RNN 训练时的梯度消失和梯度爆炸问题,适用于长期依赖的时间序列建模。 LSTM 结构 LSTM 由 输入门(Input Gate)、遗…...

详细解释MCP项目中安装命令 bunx 和 npx区别
详细解释 bunx 和 npx 1. bunx bunx 是 Bun 的一个命令行工具,用于自动安装和运行来自 npm 的包。它是 Bun 生态系统中类似于 npx 或 yarn dlx 的工具。以下是 bunx 的主要特点和使用方法: 自动安装和运行: bunx 会自动从 npm 安装所需的包…...
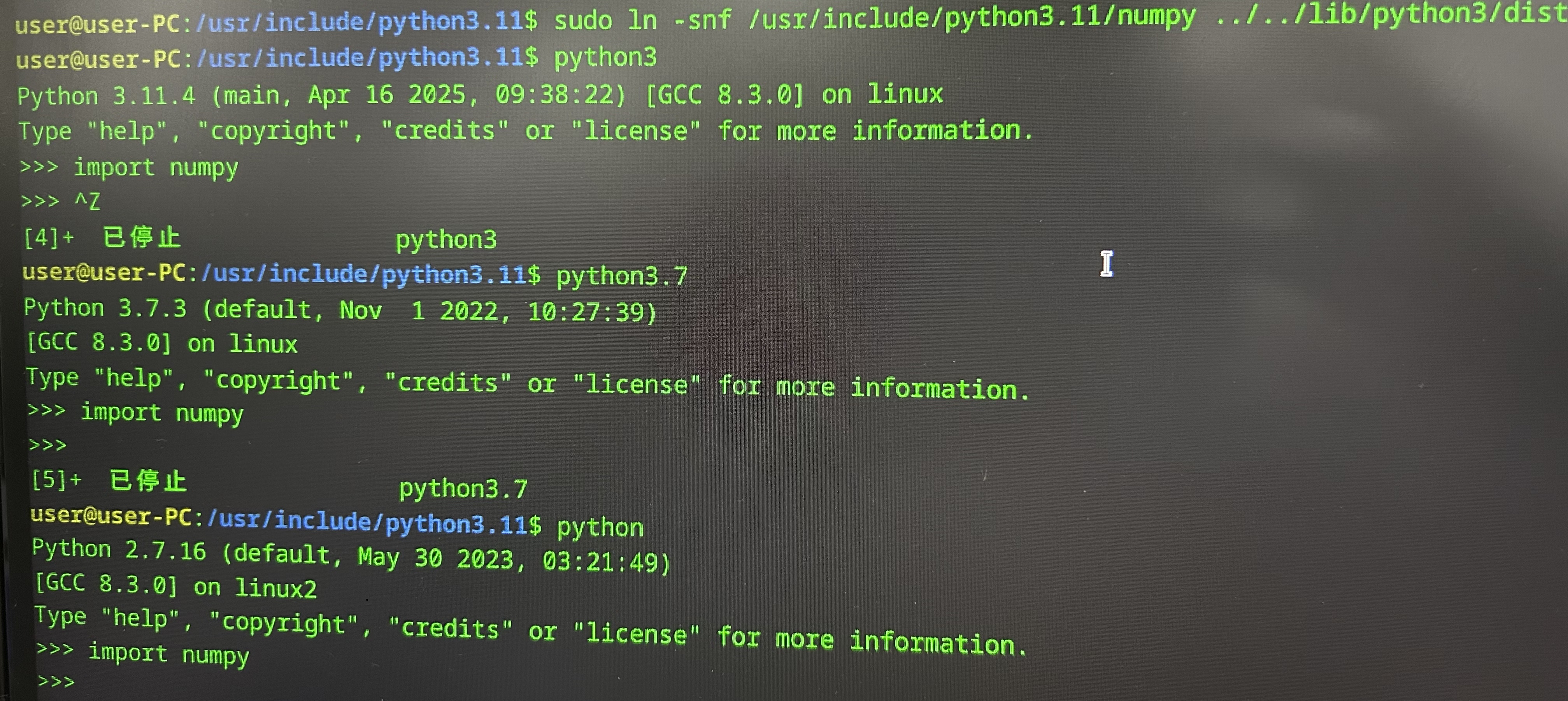
【统信UOS操作系统】python3.11安装numpy库及导入问题解决
一、安装Python3.11.4 首先来安装Python3.11.4。所用操作系统:统信UOS 前提是准备好Python3.11.4的安装包(可从官网下载(链接)),并解压到本地: 右键,选择“在终端中打开”ÿ…...

【中间件】nginx反向代理实操
一、说明 nginx用于做反向代理,其目标是将浏览器中的请求进行转发,应用场景如下: 说明: 1、用户在浏览器中发送请求 2、nginx监听到浏览器中的请求时,将该请求转发到网关 3、网关再将请求转发至对应服务 二、具体操作…...

嵌入式硬件篇---加法减法积分微分器
文章目录 前言1. 加法器(Summing Amplifier)结构反相加法器同相加法器 特点反相输出虚地特性 应用 2. 减法器(差分放大器)结构特点差分放大共模抑制比 应用 3. 积分器结构特点直流漂移问题应用 4. 微分器结构特点应用关键注意事项…...

Spring Cloud Gateway 的执行链路详解
Spring Cloud Gateway 的执行链路详解 🎯 核心目标 明确 Spring Cloud Gateway 的请求处理全过程(从接收到请求 → 到转发 → 到返回响应),方便你在合适的生命周期节点插入你的逻辑。 🧱 核心执行链路图(执…...
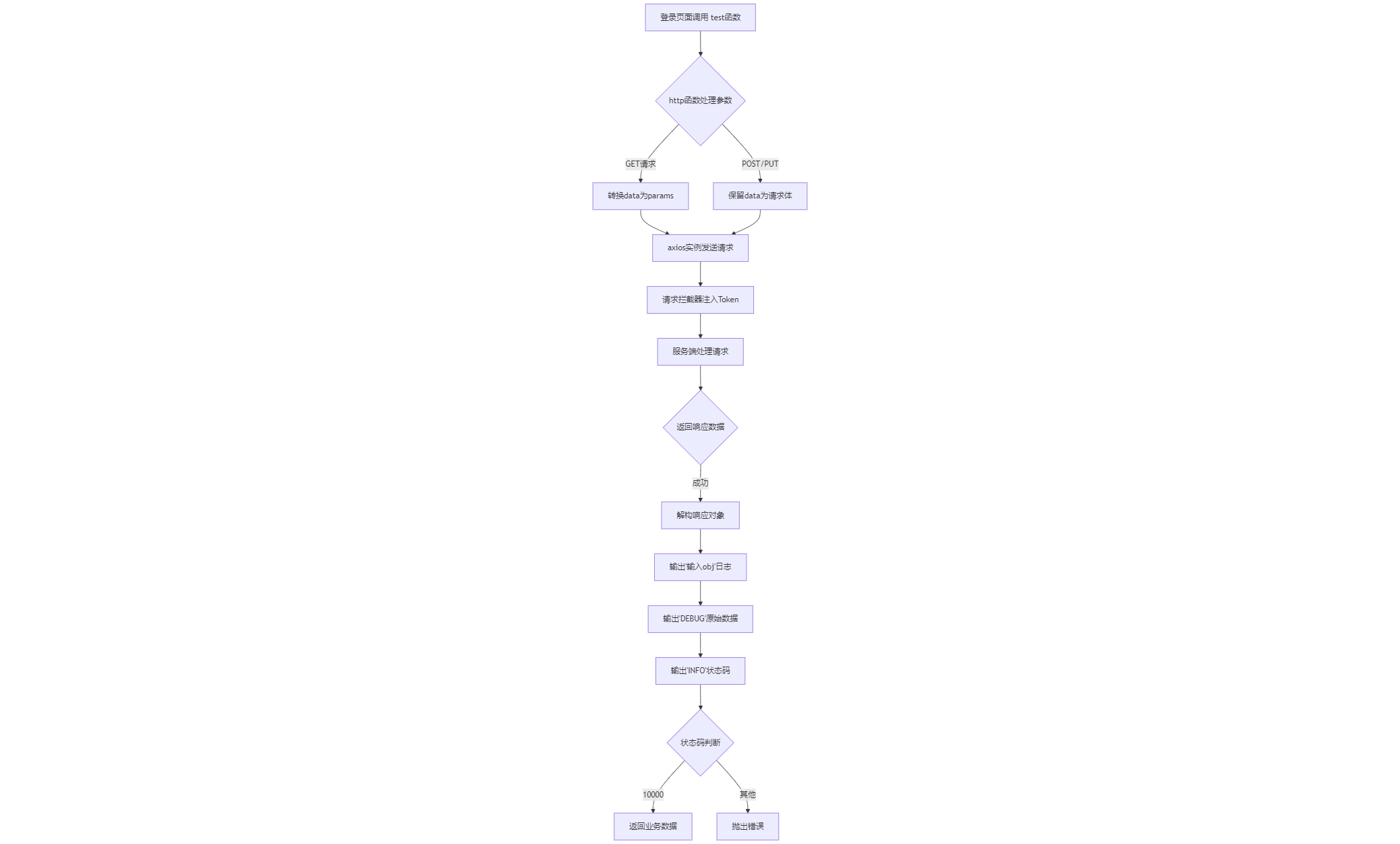
鸿蒙应用(医院诊疗系统)开发篇2·Axios网络请求封装全流程解析
一、项目初始化与环境准备 1. 创建鸿蒙工程 src/main/ets/ ├── api/ │ ├── api.ets # 接口聚合入口 │ ├── login.ets # 登录模块接口 │ └── request.ets # 网络请求核心封装 └── pages/ └── login.ets # 登录页面逻辑…...
突发重磅消息!!!CVE项目将被取消?
突发重磅消息!!!CVE项目将被取消?突发!来自可靠消息来源。MITRE 对 CVE 项目的支持将于明天到期。附件信件已发送给 CVE 董事会成员。https://mp.weixin.qq.com/s/N3qkiHaDfzDuBMK3JbBCjw...
详解与FTP服务器相关操作
目录 什么是FTP服务器 搭建FTP服务器相关 编辑 Unity中与FTP相关的类 上传文件到FTP服务器 使用FTP服务器上传文件的关键点 开始上传 从FTP服务器下载文件到客户端 使用FTP下载文件的关键点 开始下载 关于FTP服务器的其他操作 将文件的上传,下载&…...

远程登录一个Linux系统,如何用命令快速知道该系统属于Linux的哪个发行版,以及该服务器的各种配置参数,运行状态?
远程登录一个Linux系统,如何用命令快速知道该系统属于Linux的哪个发行版,以及该服务器的各种配置参数,运行状态? 查看Linux发行版信息 查看发行版名称和版本: cat /etc/*-release或 lsb_release -a查看内核版本&#…...

解决 .Net 6.0 项目发布到IIS报错:HTTP Error 500.30
今天在将自己开发许久的项目上线的时候,发现 IIS 发布后请求后端老是报一个 HTTP Error 500.30 的异常,如下图所示。 后来仔细调查了一下发现是自己的程序中写了 UseStaticFiles 的依赖注入,这个的主要作用就是发布后端后,想…...

STM32F103_HAL库+寄存器学习笔记16 - 监控CAN发送失败(轮询方式)
导言 《STM32F103_HAL库寄存器学习笔记15 - 梳理CAN发送失败时,涉及哪些寄存器》从上一章节看到,当CAN消息发送失败时,CAN错误状态寄存器ESR的TEC会持续累加,LEC等于0x03(ACK错误)。本次实验的目的是编写一…...

Java并发-AQS框架原理解析与实现类详解
什么是AQS? AQS(AbstractQueuedSynchronizer)是Java并发包(JUC)的核心基础框架,它为构建锁和同步器提供了高效、灵活的底层支持。本文将从设计原理、核心机制及典型实现类三个维度展开,帮助读者…...

实现定长的内存池
池化技术 所谓的池化技术,就是程序预先向系统申请过量的资源,然后自己管理起来,以备不时之需。这个操作的价值就是,如果申请与释放资源的开销较大,提前申请资源并在使用后并不释放而是重复利用,能够提高程序…...
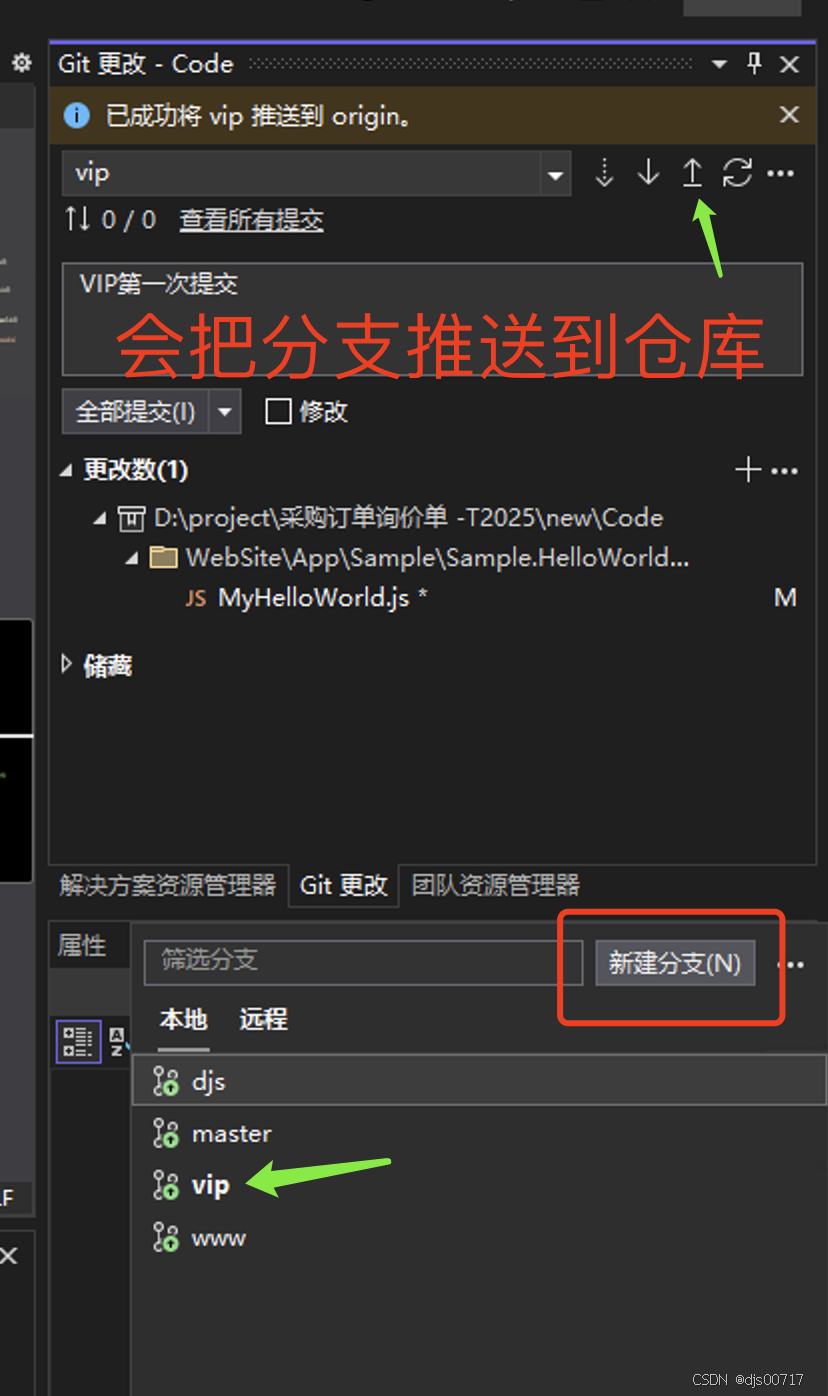
vs2022使用git方法
1、创建git 2、在cmd下执行 git push -f origin master ,会把本地代码全部推送到远程,同时会覆盖远程代码。 3、需要设置【Git全局设置】,修改的代码才会显示可以提交,否则是灰色的不能提交。 4、创建的分支,只要点击…...

Mysql中表的使用(3)
目录 1.updata的使用 2.delete(删除表中数据)drop(删除表) 数据库的约束 1.NOT NULL 指定列不能为空 2.UNIQUE指定列唯一 3.DEFAULT(默认值) 4.PRIMARY KEY 5.自增主键 1.updata的使用 1.0update 表名 set 列名x where 列名y; 2.0update 表名 s…...
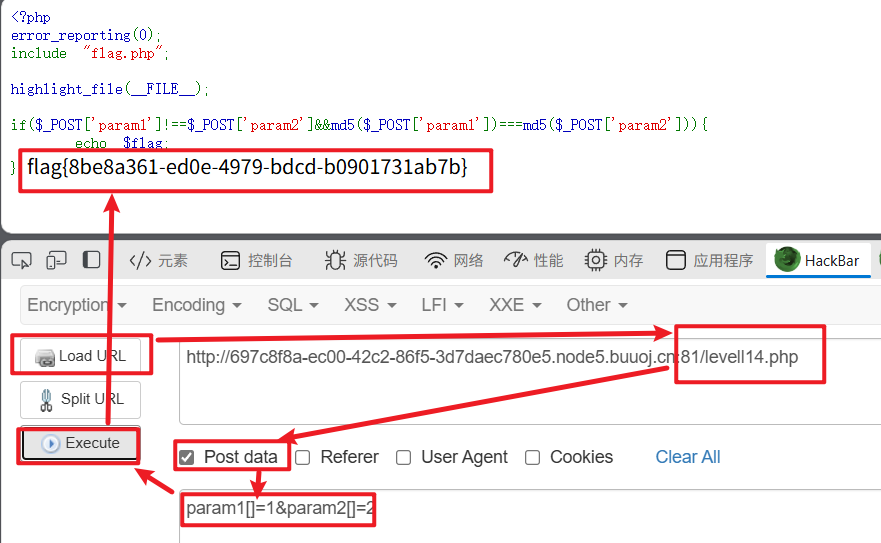
BUUCTF-Web(1-20)
目录 一.SQL注入 (1)[极客大挑战 2019]EasySQL 万能密码 (7)[SUCTF 2019]EasySQL 堆叠注入 解一: 解二: (10)[强网杯 2019]随便注 堆叠注入 解一: 解二: 解三: (8)[极客大挑战 2019]LoveSQL 联…...