【NLP】 19. Tokenlisation 分词 BPE, WordPiece, Unigram/SentencePiece
1. 翻译系统性能评价方法
在机器翻译系统性能评估中,通常既有人工评价也有自动评价方法:
1.1 人工评价
人工评价主要关注以下几点:
- 流利度(Fluency): 判断翻译结果是否符合目标语言的语法和习惯。
- 充分性(Adequacy): 判断翻译是否传达了原文的全部信息。
- 评价方式: 可以通过打分(Rate)、排序(Rank)以及编辑比较(Edit & Compare)的方式进行人工评测。
1.2 自动评价指标
自动评价方法常用的包括基于字符 n-grams 的指标(如 chrF)和基于单词 n-grams 的指标(如 BLEU)。
chrF 指标
- 基本思想:
将翻译结果与参考译文在字符级别进行 n-gram 匹配,适合于捕捉词形变化(如“read”与“Reading”),适合处理小写、标点、甚至拼写错误等情况。 - 常用公式:
-
精确率(Precision):
precision = TP / (TP + FP) -
召回率(Recall):
recall = TP / (TP + FN) -
F-beita 分数(F_β-score):
F β = ( ( 1 + β 2 ) ⋅ T P ) / ( ( 1 + β 2 ) ⋅ T P + β 2 ⋅ F N + F P ) F_β = ((1+β^2)·TP) / ((1+β^2)·TP + β^2·FN + FP) Fβ=((1+β2)⋅TP)/((1+β2)⋅TP+β2⋅FN+FP)
其中,beita 参数控制精确率和召回率之间的权重。例如,F2-score中 β= 2(公式:F2 = 5TP/(5TP + 4FN + FP)),而 F0-score 则相当于Precision, 当β很大的时候,相当于Recall
-
当所评估句子数量较多时,chrF 能有效反映字符级匹配情况,但当匹配以单词为单位时,可能出现“没有4-gram匹配得分为0”的情况,因此常配合其他指标综合评估。
BLEU 指标
- 基本思想:
BLEU 通过对比翻译输出与参考译文的单词 n-grams(通常计算一元、二元、三元和四元 n-grams)精确率,并取几何平均后乘以一个惩罚因子(brevity penalty)来处理生成句子较短的问题。 - 局限性:
由于BLEU只计算精确率,不考虑单词的形态变化(例如“read”和“Reading”在严格匹配时视为不同)以及上下文语序,且几何平均在数据量不足时敏感,常常无法完全反映翻译的流利性和充分性。
对比
BLEU vs. chrF
| 特征 | BLEU | chrF |
|---|---|---|
| 全称 | Bilingual Evaluation Understudy | Character n-gram F-score |
| 单位 | 基于词级别(word-level) | 基于字符级别(character-level) |
| 匹配单位 | n-gram(如词组) | 字符n-gram(如连续的字符组合) |
| 语言适用性 | 英语/法语等空格分词语言效果较好 | 对形态复杂语言(如德语、芬兰语、中文)效果更好 |
| 对词形变化的鲁棒性 | 差(如“run”和“runs”会被认为不同) | 好(字符n-gram可以捕捉到词形变化) |
| 对词序敏感 | 非常敏感 | 不那么敏感 |
| 评价精度 | 偏向于流畅性(fluency) | 更能捕捉语义和词形匹配(adequacy) |
| 惩罚机制 | 有 Brevity Penalty 惩罚过短的句子 | 没有专门惩罚机制 |
| 实现工具 | NLTK、SacreBLEU | 官方工具:chrF++,也在 SacreBLEU 中支持 |
2. Tokenisation 的基本概念与问题
Tokenisation(分词或词元化)指的是将一段文本切分为基本单元(token),如单词、标点符号或子词单元。传统方法多采用基于空格分割,但存在以下问题:
2.1 基于空格分词的局限性
- 简单的空格分割:
通常将文本按照空格拆分出各个 token,此方法对于英文等基于空格分词的语言基本适用。但在实际情况中会遇到:- 缩写问题: 如 “won’t” 表示 “will not”,空格分词时可能作为一个整体或拆分为 “won” 和 “'t”。
- 标点处理: 如 “great!” 中的感叹号有可能被保留或删除,不同工具处理方式不一致。
- 罕见词或变体: 如 “taaaaaaasty” 可能有多种变体,直接按空格分割,无法解决拼写变化或冗余重复问题。
- 拼写错误或新词: 如 “laern” (原意 learn)和 “transformerify” 这样的新造词也会被简单拆分,而无法充分捕捉原有语义。
2.2 Tokenisation 帮助处理罕见词等问题
通过更细粒度的分词方法,可以减少由于拼写错误、变形或新词带来的问题。例如,将长词拆成子词单元,可以使得词形变化不至于使整个单词无法识别。
- 实例:
- “laern” 拆分为 “la##”, “ern”。
这样一来,即使遇到拼写错误或不常见的词,模型也能通过子词组合部分捕捉到词语的语义,从而提高整体泛化能力。
- “laern” 拆分为 “la##”, “ern”。
3. 子词分割策略与方法
为了更好地处理词形变化、罕见词及新词,现有许多基于子词单位的分词算法。主要包括以下三类:
3.1 Byte-Pair Encoding (BPE)
BPE 的基本算法步骤为:
- 初始化词汇表:
将词汇表设置为所有单独的字符。 - 查找频率最高的相邻字符对:
遍历语料,找出最常在一起出现的两个字符或子词。 - 合并:
将这一对合并,生成一个新的子词单位,并更新整个语料中的分词表示。 - 检查词汇表大小:
如果词汇表大小未达到预设目标(例如 100,000),则返回步骤2继续合并,直到达到要求。
这种方法简单高效,常用于许多现代 NLP 框架中。
假设我们现在的训练语料有以下 4 个词:
1. low
2. lower
3. newest
4. widest
初始我们会把每个词都拆成字符 + 特殊结束符号 </w>来防止词和词连接在一起:
l o w </w>
l o w e r </w>
n e w e s t </w>
w i d e s t </w>
🔁 步骤 0:统计所有字符对频率
从上面所有词中,统计所有相邻字符对的频率(包括 </w>):
| Pair | Count |
|---|---|
| l o | 2 |
| o w | 2 |
| w | 1 |
| w e | 1 |
| e r | 1 |
| r | 1 |
| n e | 1 |
| e w | 1 |
| w e | 1 |
| e s | 2 |
| s t | 2 |
| t | 2 |
| w i | 1 |
| i d | 1 |
| d e | 1 |
注意:
w e出现了两次(一次是 “lower”,一次是 “newest”);e s、s t和t </w>是在 “newest” 和 “widest” 中反复出现的。
🔨 步骤 1:合并频率最高的字符对
我们假设 s t 是当前频率最高的(2 次)。那我们合并 s t → st。
现在变成:
l o w </w>
l o w e r </w>
n e w e st </w>
w i d e st </w>
🔁 步骤 2:重新统计字符对频率
重新统计所有字符对(只列几个):
| Pair | Count |
|---|---|
| l o | 2 |
| o w | 2 |
| e st | 2 |
| st | 2 |
| … | … |
我们发现 e st 和 st </w> 又很频繁 → 合并 e st → est
🔨 步骤 3:合并 e st → est
结果:
bashCopyEditl o w </w>
l o w e r </w>
n e w est </w>
w i d est </w>
你看,“newest” 和 “widest” 的后缀变成了统一的 est,这就是 BPE 的威力!
🔁 再来几轮(每次合并频率最高的)
假设继续合并:
| Round | 合并操作 | 影响 |
|---|---|---|
| 4 | l o → lo | 得到 lo w |
| 5 | lo w → low | 得到完整词 low |
| 6 | e r → er | 合并 “lower” 的尾部 |
| 7 | w e → we | 合并 “newest” 的 “we” 部分 |
| 8 | we + r → wer | 可得 “lower” 更完整 |
每合并一次,词汇表中就新增一个子词(如 low、est、er 等),最终我们就有一个子词词表,用于之后的分词。
✅ 最终效果(假设分词完成后):
| 原始词 | 分词结果 |
|---|---|
| low | low |
| lower | low + er |
| newest | new + est |
| widest | wid + est |
这样,即使将来出现一个从没见过的词,比如 bravest,我们也可以分成:
brav + est
🧠 总结亮点
- BPE 把频繁出现的字符组合合并成更长的单元;
- 最终词汇表里既有完整词(如
low),也有子词(如est,er); - 能处理拼写变化、形态变化、新词;
- 是 GPT、BERT、RoBERTa、T5 等模型使用的标准方法。
3.2 WordPiece
WordPiece 最早由 Google 提出,其主要步骤与 BPE 类似,但在合并步骤中使用更复杂的决策标准:
- 训练一个 n-gram 语言模型,
并考虑所有可能的词汇对,选择那个加入后能最大程度降低困惑度perplexity的组合; - HuggingFace 实现的 WordPiece 则有时选择使得合并后 token 的概率比例满足某个公式,例如选择使得
“|combined| / (|first symbol| * |second symbol|)” 最大的词对。
这种方法可在一定程度上更好地平衡子词与完整词的表达效果。
✂️ 分词示例(WordPiece)
以 playing 为例,假设词表中包含:
[ "play", "##ing", "##er", "##est", "##s" ]
那 playing 会被分为:
play + ##ing
再比如 unbelievable:
如果词表中有:
["un", "##believable", "##able", "##lievable", ...]
则可能被分为:
un + ##believable
(如果没有 “believable”,那就会继续拆成 ##believe + ##able)
🎯 WordPiece 构建流程(简要)
- 初始化词表:包含所有单字符 token(如 a, b, c,…);
- 基于最大似然概率计算所有可能合并的对;
- 每轮合并一对,使得整体训练语料的似然性最大;
- 直到词表达到预设大小(如 30,000 个 token)为止;
这比 BPE 更慢,但能得到更“语言合理”的子词。
🔍 分词过程总结
WordPiece 是一种贪心最长匹配算法,遵循以下原则:
- 从词首开始;
- 找到最长可匹配的 token(如 “unbelievable” → “un”);
- 然后从该点继续向右,查找
##前缀的匹配; - 直到整个词完成或无法继续拆分;
🧠 举个例子(完整流程)
假设词表里有:
["un", "##believe", "##able", "##believable"]
处理 unbelievable:
unbelievable→un+##believable
再处理 unbelievably:
如果 ##ly 也在词表中,就可以是:
un+##believable+##ly
如果 ##believable 不在词表中:
- 尝试
un+##believe+##able
✅ 总结
BPE 看频率,WordPiece 看语言模型概率。
WordPiece 更“聪明”,但 BPE 更“高效”。它们都用来解决“词太多”和“未知词”的问题。
WordPiece vs. BPE 的区别
| 特性 | BPE | WordPiece |
|---|---|---|
| 合并策略 | 每次合并频率最高的 pair | 每次合并带来最大 语言模型概率提升 的 pair |
| 评分标准 | 纯粹基于频率 | 基于最大似然估计(MLE) |
| 分词方式 | 贪心从左到右合并 | 也使用贪心,但遵循“最大匹配”原则 |
| 应用例子 | GPT、RoBERTa、OpenNMT | BERT、ALBERT、DistilBERT 等 |
| 词边标记 | 可无(GPT类) | 用 ## 表示词中间部分(如 play ##ing) |
3.3 Unigram / SentencePiece
Unigram 模型(或称 SentencePiece)采取另一种策略,不是从最小单元不断合并,而是:
- 初始化:
从所有字符以及语料中频率较高的连续字符序列(甚至包括完整单词)构建一个较大的初始词汇表; - 精简:
通过一种复杂的概率模型和迭代过程,逐步删除贡献较小的词汇项,直到词汇表达到预期大小。
这种方法的优势在于能够同时考虑大单元和小单元的信息,从而得到更优的子词表示。
用 Unigram 分词 internationalization
假设词表中有:
["international", "##ization", "inter", "##national", "##ize", "##ation", "##al", "##i", "##zation"]
Unigram 会考虑所有可能组合:
- international + ization
- inter + national + ization
- inter + nation + al + ization
- …
对每个组合计算 概率乘积(P(a) × P(b) × P© …),然后选取概率 最大的组合方式。
比如:
international + ization → P1
inter + national + ization → P2
inter + nation + al + ization → P3
选取 max(P1, P2, P3) 那个组合。
3.4 各方法的比较
- BPE: 简单、直接,广泛应用,合并依据频率;
- WordPiece: 考虑对语言模型困惑度的影响,通常效果更好,但实现较复杂;
- Unigram/SentencePiece: 允许初始词汇同时包含较大和较小单元,通过概率模型精简词汇,具有更大的灵活性。
Unigram vs. BPE/WordPiece
| 特性 | Unigram(SentencePiece) | BPE | WordPiece |
|---|---|---|---|
| 分词方式 | 选择概率最高的子词组合(非贪心) | 左到右合并字符对(贪心) | 贪心最长匹配 |
| 词表生成方式 | 预设大词表 → EM算法删掉低概率的子词 | 每轮合并频率最高的 pair | 每轮合并最大增益的 pair |
| 分词结果是否唯一 | ❌ 可能多个组合概率差不多 | ✅ 唯一贪心路径 | ✅ 贪心最长匹配 |
| 优点 | 更灵活,能找到最优子词拆法 | 简单快速 | 精确但复杂 |
| 模型代表 | ALBERT, XLNet, T5, mBART, SentencePiece | RoBERTa, GPT, MarianMT | BERT, DistilBERT |
| 特殊符号 | 不需要空格、可直接处理未空格文本 | 需提前空格/处理标记 | 通常需要空格 |
4. 特殊常见词(例如“the”)的处理
在分词和词嵌入训练中,常见词(如 “the”、“is”、“and” 等)通常出现频率极高,这会带来两个问题:
- 模型训练时的影响:
高频词容易主导模型权重,导致训练过程中对低频实义词的信息关注不足。为此,许多方法会在训练时对这些高频词进行下采样(sub-sampling),降低它们在训练中的出现频率。 - 评价指标的匹配:
在翻译评价、自动摘要或其他生成任务中,通常不希望因为 “the” 这种功能词的不同写法(例如大小写问题)产生低分。在实际 tokenisation 中,往往会将所有单词统一小写,或者对停用词单独处理,从而确保这些高频但语义信息较弱的词对整体模型影响较小。
例如,在 BLEU 计算中,尽管 “read” 和 “Reading” 在大小写和形态上有所不同,但通常在预处理阶段会进行小写化;而在子词分割中,“the” 可能不再被拆分,因为它本身已经十分常见而且具有固定形式。因此,“the” 通常被保留为一个完整的 token,同时在训练和评价中通过下采样等方式控制其权重。
5. 实际案例补充
假设我们有一段英文文本作为翻译系统的输入与参考译文,并希望利用自动评价指标来评估翻译质量,同时考虑分词细节:
案例 1:翻译评价中 chrF 指标计算
- 参考译文: “I like to read too”
- 机器译文: “Reading, I too like”
- 处理流程:
-
分词:
利用子词分割策略处理标点和缩写,确保“Reading”可以与“read”在字符 n-gram 层面匹配。 -
计算字符 n-gram 匹配:
对机器译文和参考译文分别计算字符 n-grams,再计算精确率和召回率。 -
Fbeita 分数计算:
-
结果说明:
通过字符匹配,可以部分容忍由于词形变化(例如 “read” 与 “Reading”)而带来的微小差异。
-
案例 2:使用 BPE 处理新词
假设文本中出现一个新词 “transformerify”,传统的词汇表中可能未收录。通过 BPE 分词过程:
- 初始化:
将 “transformerify” 拆分为单个字符,即 [“t”, “r”, “a”, “n”, “s”, “f”, “o”, “r”, “m”, “e”, “r”, “i”, “f”, “y”]。 - 迭代合并:
统计在整个语料中最频繁出现的相邻字符对,如果 “er” 出现次数最多,则将“e”与“r”合并为 “er”。不断进行,直到达到预定词汇大小。 - 结果:
最终可能将 “transformerify” 分割为 “transforme” 和 “##ify”,使得即使新词未见过,也能利用已有的子词表示捕捉部分语义。
相关文章:

【NLP】 19. Tokenlisation 分词 BPE, WordPiece, Unigram/SentencePiece
1. 翻译系统性能评价方法 在机器翻译系统性能评估中,通常既有人工评价也有自动评价方法: 1.1 人工评价 人工评价主要关注以下几点: 流利度(Fluency): 判断翻译结果是否符合目标语言的语法和习惯。充分性…...
OpenAI发布GPT-4.1系列模型——开发者可免费使用
OpenAI刚刚推出GPT-4.1模型家族,包含GPT-4.1、GPT-4.1 Mini和GPT-4.1 Nano三款模型。重点是——现在全部免费开放! 虽然技术升级值得关注,但真正具有变革意义的是开发者能通过Cursor、Windsurf和GitHub Copilot等平台立即免费调用这些模型。…...
各地物价和生活成本 东欧篇
东欧地区的物价差异相对较大,一些国家的物价较高,而另一些国家则相对便宜。这些差异主要受当地经济发展水平、工资水平、旅游业发展以及国际关系等因素影响。以下是一些典型的东欧国家,按物价高低进行分类: 🌍 物价较高…...

Vue —— 实用的工具函数
目录 响应式数据管理1. toRef 和 torefs2. shallowRef 和 shallowReactive3. markRaw 依赖追踪与副作用1. computed2. watch 和 watchEffect 类型判断与优化1. unref2. isRef 、isReactive 和 isProxy 组件通信与生命周期1. provide 和 inject2. nextTick 高级工具1. useAttrs …...
flex布局(笔记)
弹性布局(Flex布局)是一种现代的CSS布局方式,通过使用display: flex属性来创建一个弹性容器,并在其中使用灵活的盒子模型来进行元素的排列和定位。 主轴与交叉轴:弹性容器具有主轴(main axis)和…...

第二阶段:数据结构与函数
模块4:常用数据结构 (Organizing Lots of Data) 在前面的模块中,我们学习了如何使用变量来存储单个数据,比如一个数字、一个名字或一个布尔值。但很多时候,我们需要处理一组相关的数据,比如班级里所有学生的名字、一本…...

云函数采集架构:Serverless模式下的动态IP与冷启动优化
在 Serverless 架构中使用云函数进行网页数据采集,不仅能大幅降低运维成本,还能根据任务负载动态扩展。然而,由于云函数的无状态特性及冷启动问题,加上目标网站对采集行为的反制措施(如 IP 限制、Cookie 校验等&#x…...
Linux笔记---动静态库(原理篇)
1. ELF文件格式 动静态库文件的构成是什么样的呢?或者说二者的内容是什么? 实际上,可执行文件,目标文件,静态库文件,动态库文件都是使用ELF文件格式进行组织的。 ELF(Executable and Linkable…...

string的模拟实现 (6)
目录 1.string.h 2.string.cpp 3.test.cpp 4.一些注意点 本篇博客就学习下如何模拟实现简易版的string类,学好string类后面学习其他容器也会更轻松些。 代码实现如下: 1.string.h #define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include <…...
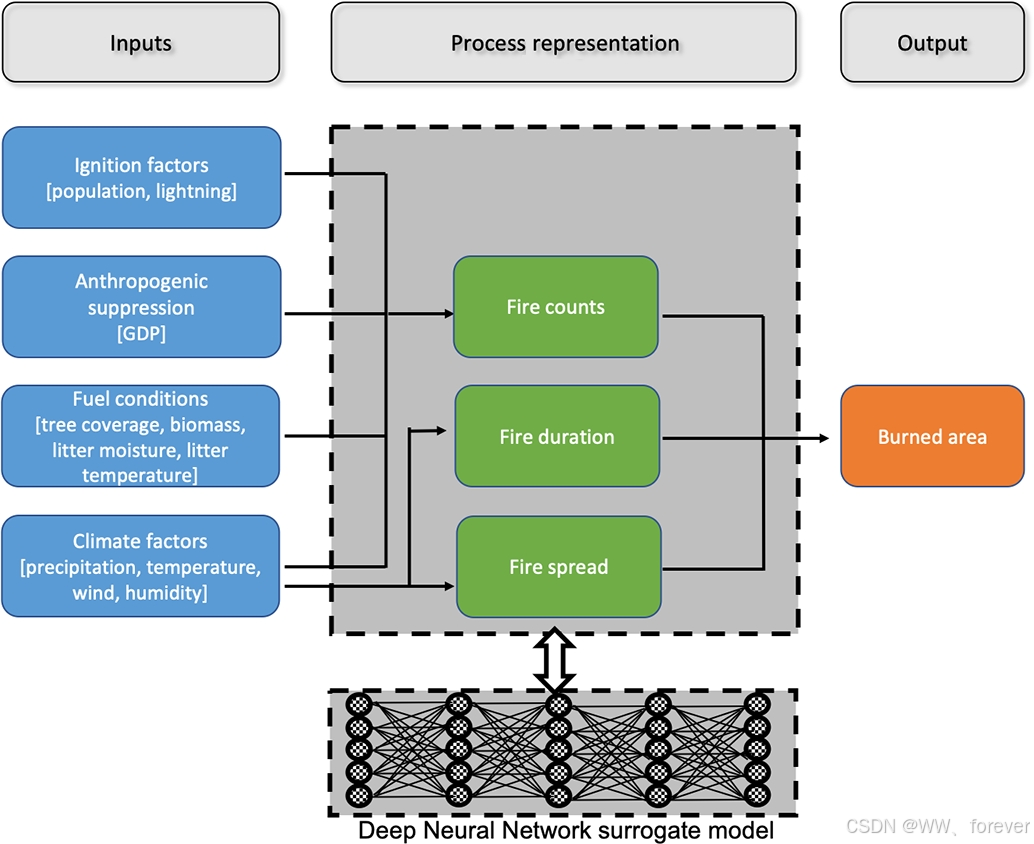
【野火模型】利用深度神经网络替代 ELMv1 野火参数化:机制、实现与性能评估
目录 一、ELMv1 野火过程表示法(BASE-Fire)关键机制野火模拟的核心过程 二、采用神经网络模拟野火过程三、总结参考 一、ELMv1 野火过程表示法(BASE-Fire) ELMv1 中的野火模型(称为 BASE-Fire)源自 Commun…...

红宝书第四十七讲:Node.js服务器框架解析:Express vs Koa 完全指南
红宝书第四十七讲:Node.js服务器框架解析:Express vs Koa 完全指南 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、框架定位:HTTP服务器的工具箱 共同功能: 快…...
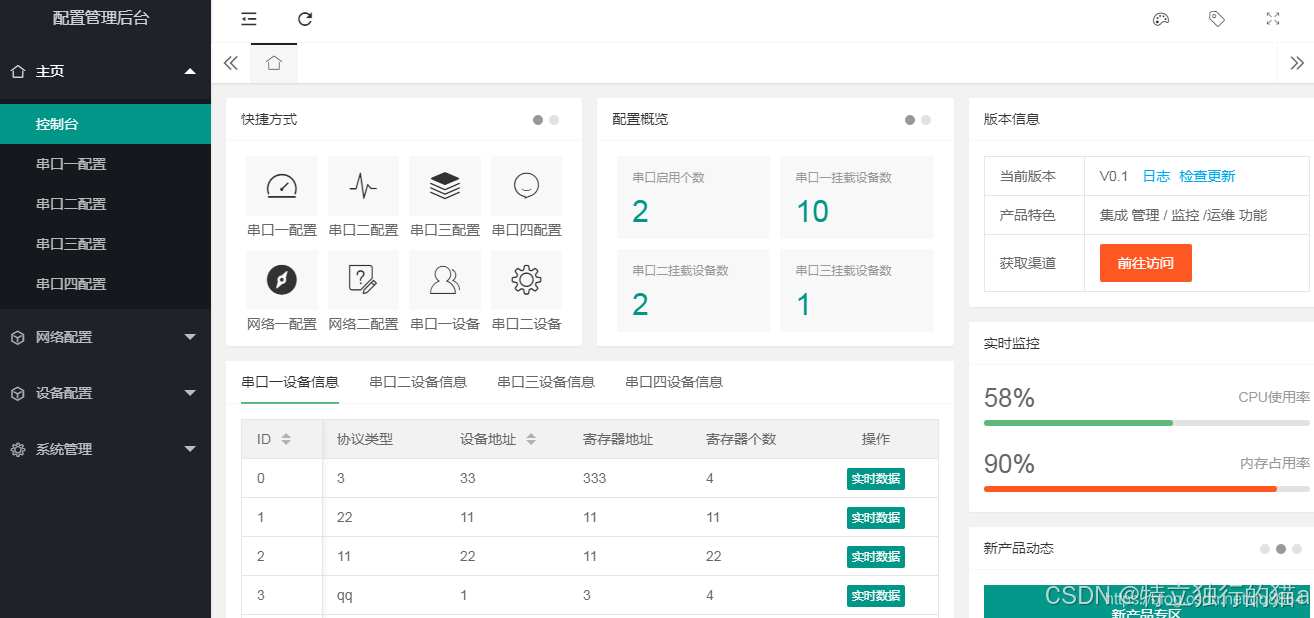
嵌入式Linux设备使用Go语言快速构建Web服务,实现设备参数配置管理方案探究
本文探讨,利用Go语言及gin框架在嵌入式Linux设备上高效搭建Web服务器,以实现设备参数的网页配置。通过gin框架,我们可以在几分钟内创建一个功能完善的管理界面,方便对诸如集中器,集线器等没有界面的嵌入式设备的管理。…...

【NLP 59、大模型应用 —— 字节对编码 bpe 算法】
目录 一、词表的构造问题 二、bpe(byte pair encoding) 压缩算法 算法步骤 示例: 步骤 1:初始化符号表和频率统计 步骤 2:统计相邻符号对的频率 步骤 3:合并最高频的符号对 步骤 4:重复合并直至终止条件 三、bpe在NLP中…...
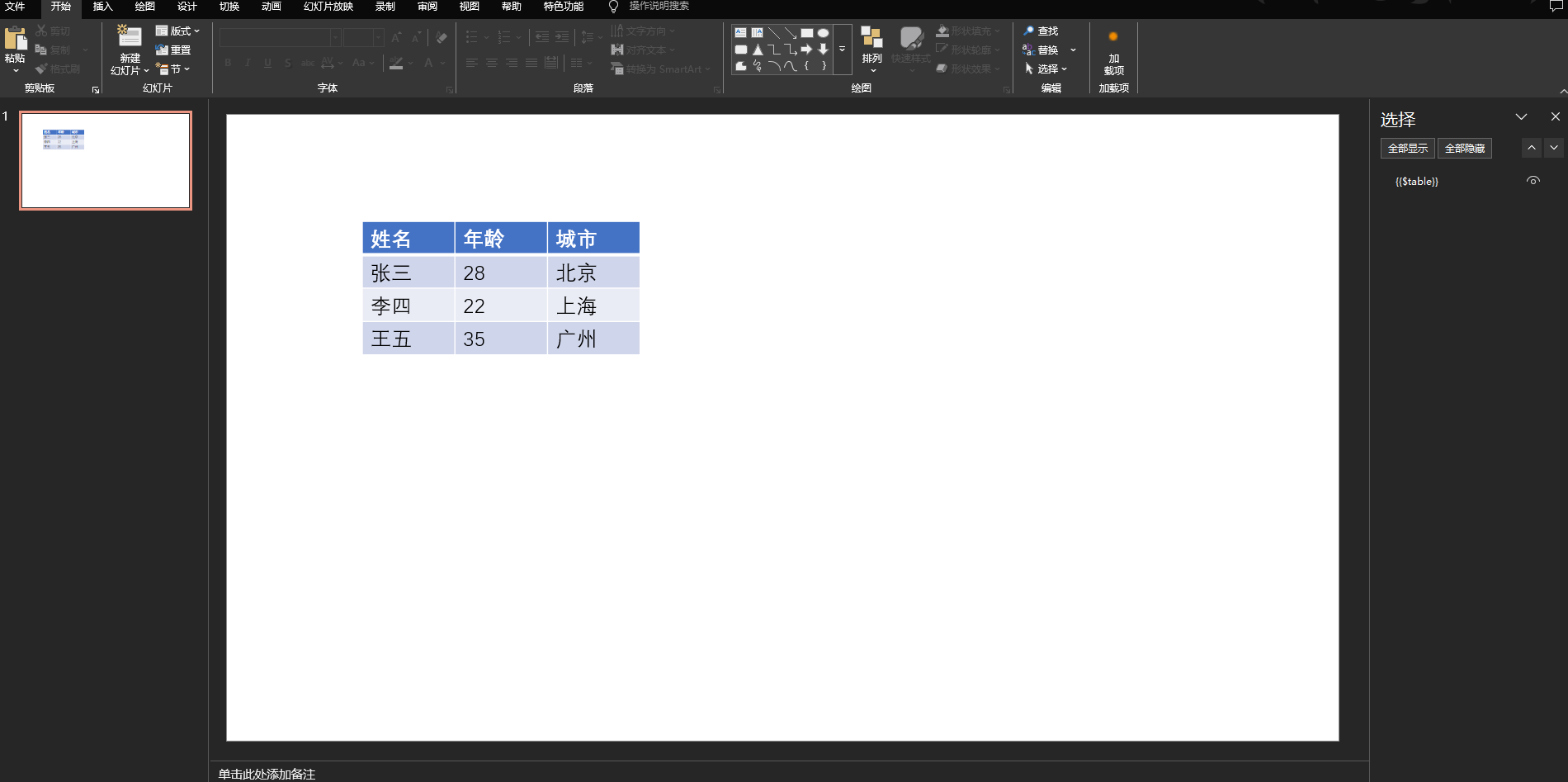
Python对ppt进行文本替换、插入图片、生成表格
目录 1. 安装pptx2. 文本替换和插入图片3. 生成表格 1. 安装pptx pip install python-pptx2. 文本替换和插入图片 文本通过占位符例如{{$xxx}}进行标记,然后进行替换;图片通过ppt中的图形和图片中的占位符进行标记ppt如下 具体实现 from pptx import …...
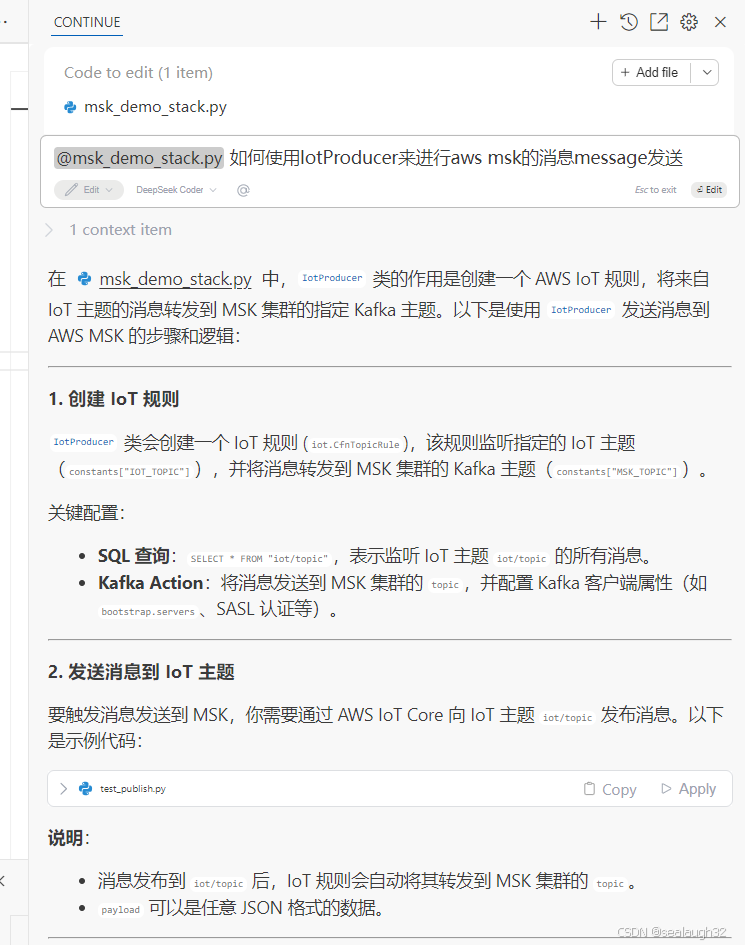
AI(学习笔记第一课) 在vscode中配置continue
文章目录 AI(学习笔记第一课) 在vscode中配置continue学习内容:1. 使用背景2. 在vscode中配置continue2.1 vscode版本2.2 在vscode中下载continue插件2.2.1 直接进行安装2.2.2 在左下角就会有continue的按钮2.2.3 可以移动到右上角2.2.3 使用的时候需要login 2.3 配…...

C++ (初始面向对象之继承,实现继承,组合,修饰权限)
初始面向对象之继承 根据面向对象的编程思路,我们可以把共性抽象出来封装成类,然后让不同的角色去继承这些类,从而避免大量重复代码的编写 实现继承 继承机制是面向对象程序设计中使代码可以复用的最重要的手段,它允许程序员在保…...
)
vmcore分析锁问题实例(x86-64)
问题描述:系统出现panic,dmesg有如下打印: [122061.197311] task:irq/181-ice-enp state:D stack:0 pid:3134 ppid:2 flags:0x00004000 [122061.197315] Call Trace: [122061.197317] <TASK> [122061.197318] __schedule0…...

21、c#中“?”的用途
在C#中,? 是一个多用途的符号,具有多种不同的用途,具体取决于上下文。以下是一些常见的用法: 1、可空类型(Nullable Types) ? 可以用于将值类型(如 int、bool 等)变为可空类型。…...
每日搜索--12月
12.1 1. urlencode是一种编码方式,用于将字符串以URL编码的形式进行转换。 urlencode也称为百分号编码(Percent-encoding),是特定上下文的统一资源定位符(URL)的编码机制。它适用于统一资源标识符(URI)的编码,也用于为application/x-www-form-urlencoded MIME准备数…...
一天一个java知识点----Tomcat与Servlet
认识BS架构 静态资源:服务器上存储的不会改变的数据,通常不会根据用户的请求而变化。比如:HTML、CSS、JS、图片、视频等(负责页面展示) 动态资源:服务器端根据用户请求和其他数据动态生成的,内容可能会在每次请求时都…...

游戏报错?MFC140.dll怎么安装才能解决问题?提供多种MFC140.dll丢失修复方案
MFC140.dll 是 Microsoft Visual C 2015 运行库的重要组成部分,许多软件和游戏依赖它才能正常运行。如果你的电脑提示 "MFC140.dll 丢失" 或 "MFC140.dll 未找到",说明系统缺少该文件,导致程序无法启动。本文将详细介绍 …...

TDengine 3.3.6.3 虚拟表简单验证
涛思新出的版本提供虚拟表功能,完美解决了多值窄表查询时需要写程序把窄表变成宽表的处理过程,更加优雅。 超级表定义如下: CREATE STABLE st01 (ts TIMESTAMP,v0 INT,v1 BIGINT,v2 FLOAT,v3 BOOL) TAGS (device VARCHAR(32),vtype VARCHAR(…...

小白如何从0学习php
学习 PHP 可以从零开始逐步深入,以下是针对小白的系统学习路径和建议: 1. 了解 PHP 是什么 定义:PHP 是一种开源的服务器端脚本语言,主要用于 Web 开发(如动态网页、API、后台系统)。 用途:构建…...
常见的 14 个 HTTP 状态码详解
文章目录 一、2xx 成功1、200 OK2、204 No Content3、206 Partial Content 二、3xx 重定向1、301 Moved Permanently2、302 Found3、303 See Other注意4、Not Modified5、307 Temporary Redirect 三、4xx 客户端错误1、400 Bad Request2、401 Unauthorized3、403 Forbidden4、4…...

【Java学习笔记】DOS基本指令
DOS 基本指令 基本原理 接受指令 解析指令 执行指令 常用命令 查看当前目录有什么:dir 使用绝对路径查看特定目录下文件:dir 绝对路径 切换到其他盘:直接输入C: 或 D:直接切换到根目录 返回上一级目录:cd.. 切换到根目录…...
Linux Kernel 8
可编程中断控制器(Programmable Interrupt Controller,PIC) 支持中断(interrupt)的设备通常会有一个专门用于发出中断请求Interrupt ReQuest,IRQ的输出引脚(IRQ pin)。这些IRQ引脚连…...
原子操作CAS(Compare-And-Swap)和锁
目录 原子操作 优缺点 锁 互斥锁(Mutex) 自旋锁(Spin Lock) 原子性 单核单CPU 多核多CPU 存储体系结构 缓存一致性 写传播(Write Propagation) 事务串行化(Transaction Serialization&#…...

MySQL安装实战分享
一、在 Windows 上安装 MySQL 1. 下载 MySQL 安装包 访问 MySQL 官方下载页面。选择适合你操作系统的版本。一般推荐下载 MySQL Installer。 2. 运行安装程序 双击下载的安装文件(例如 mysql-installer-community-<version>.msi)。如果出现安全…...

C++ 编程指南35 - 为保持ABI稳定,应避免模板接口
一:概述 模板在 C 中是编译期展开的,不同模板参数会生成不同的代码,这使得模板类/函数天然不具备 ABI 稳定性。为了保持ABI稳定,接口不要直接用模板,先用普通类打个底,模板只是“外壳”,这样 AB…...
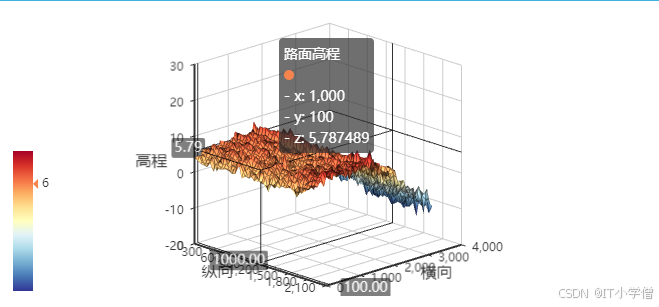
【WPF】 在WebView2使用echart显示数据
文章目录 前言一、NuGet安装WebView2二、代码部分1.xaml中引入webview22.编写html3.在WebView2中加载html4.调用js方法为Echarts赋值 总结 前言 为了实现数据的三维效果,所以需要使用Echarts,但如何在WPF中使用Echarts呢? 一、NuGet安装WebV…...