【Python学习笔记】Pandas实现Excel质检记录表初审、复核及质检统计
背景:
我有这样一个需要审核的飞书题目表,按日期分成多个sheet,有初审——复核——质检三个环节,这三个环节是不同的同学在作业,并且领到同一个题目的人选是随机的,也就是说,完成一道题的三个人之间完全是没有任何联系。
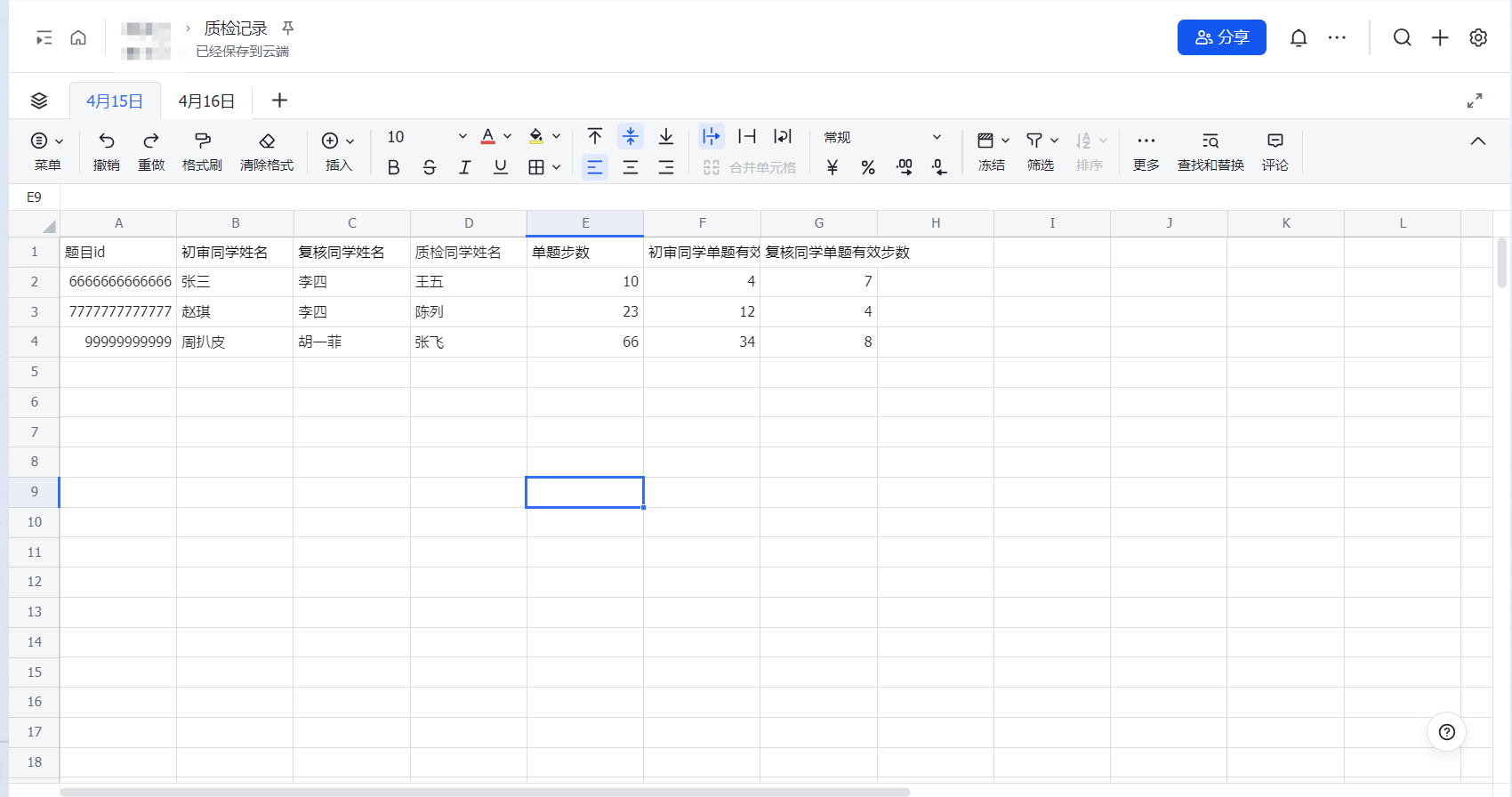
我现在需要指定sheet表的范围,统计一段时间内各环节的数据指标:
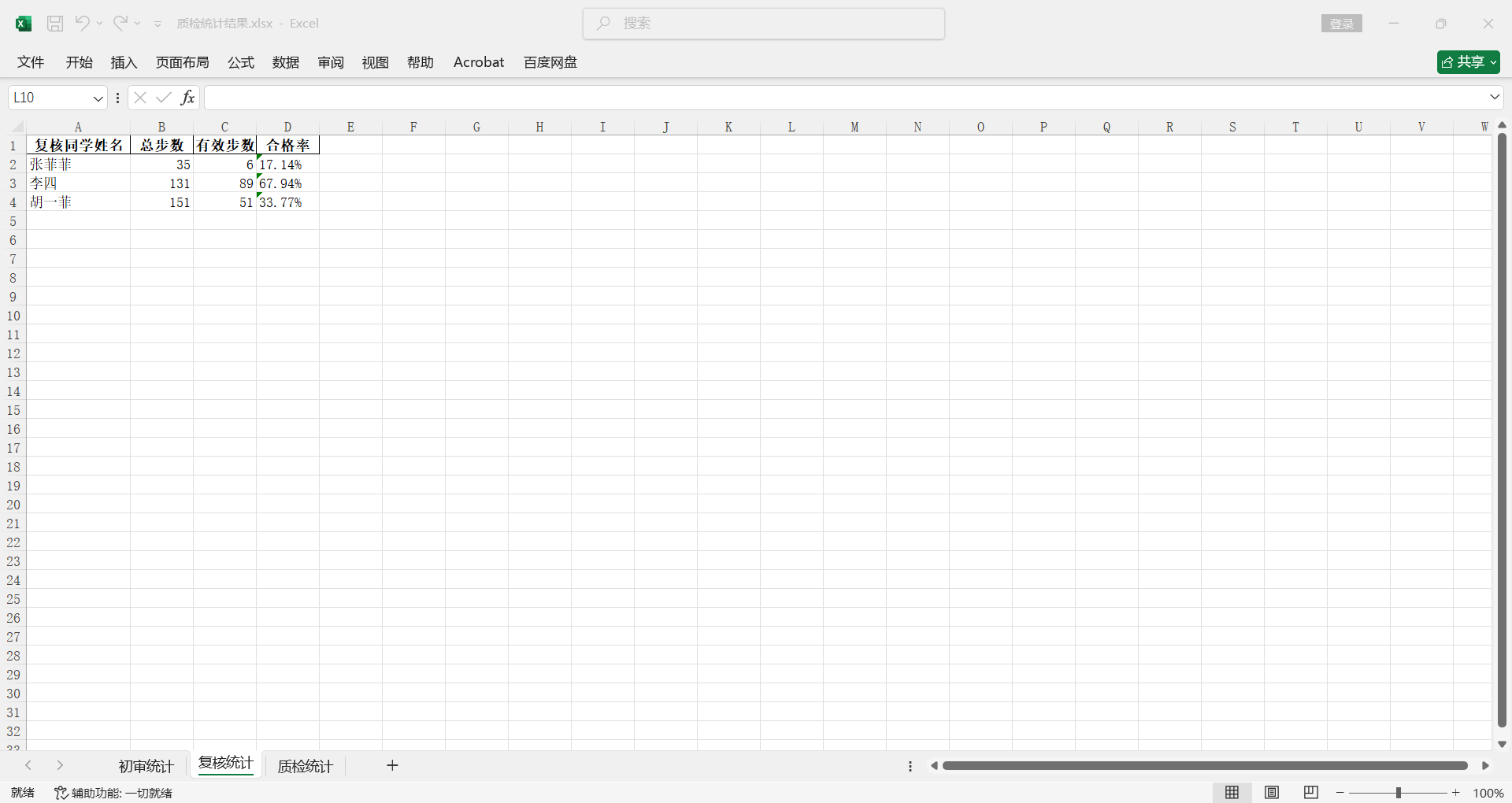
初审同学,需要统计每个同学的做题总步数,有效做题步数,还有合格率。
复核同学,需要统计每个同学的做题总步数,有效做题步数,还有合格率。
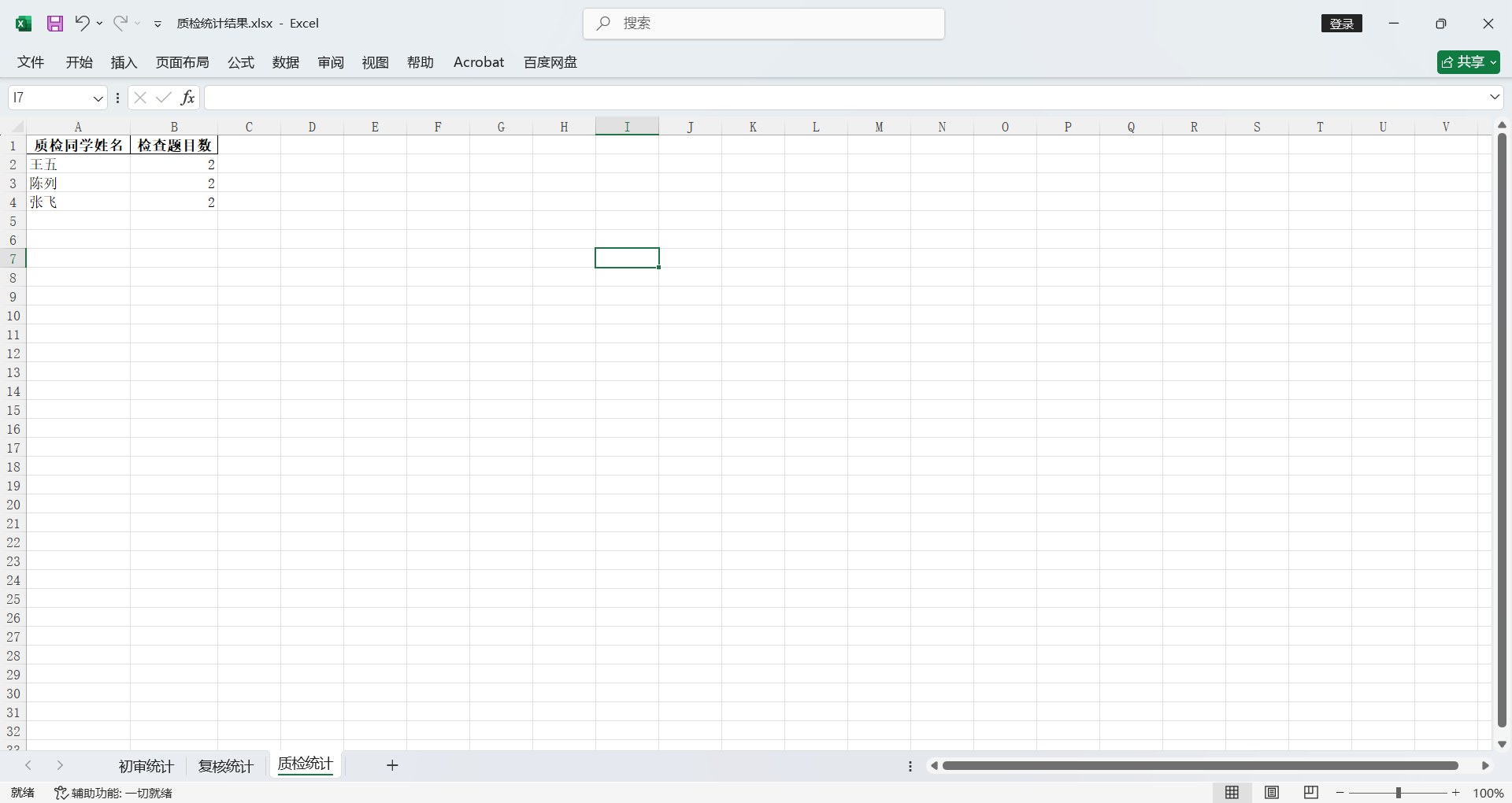
质检同学,需要统计每个质检同学的检查题目数量。一行就是一道题目,所以质检同学只需要看写着他名字的共有几行就可以。
其中,有效做题步数是指质检同学检查后判定为正确的步数,比如一道题共25步,如果质检认为初审同学做对15步,复核同学做对18步,那么初审有效步数 = 15,复核有效步数 = 18.
初审合格率 = 总初审有效步数 / 初审做题总步数;
复核合格率= 总复核有效步数 / 复核做题总步数;
编写代码:
理清上述逻辑之后,下面的工作直接交给GPT:
import pandas as pddef analyze_qc_records(file_path, sheet_names):initial_stats = {}relabel_stats = {}checker_counts = {}for sheet in sheet_names:df = pd.read_excel(file_path, sheet_name=sheet)for _, row in df.iterrows():# 初审init_name = row.get('初审同学姓名') # 取该行“初审同学姓名”,若是空值 (NaN) 则跳过。total_steps = row.get('单题步数', 0) or 0 # 当题目总步数(“单题步数”)缺失或为 NaN 时,设置为 0;否则读取数值。init_valid = row.get('初审同学单题有效步数', 0) or 0 # 读取该行“初审同学单题有效步数”if pd.notna(init_name):st = initial_stats.setdefault(init_name, {'总步数': 0, '有效步数': 0}) # 用 setdefault 保证 initial_stats[姓名] 一定存在,并初始化为 { '总步数':0, '有效步数':0 }st['总步数'] += total_steps # 每行累加“总步数”和“有效步数”st['有效步数'] += init_valid# 复核relabel_name = row.get('复核同学姓名')relabel_valid = row.get('复核同学单题有效步数', 0) or 0if pd.notna(relabel_name): # 如果不是缺失值st = relabel_stats.setdefault(relabel_name, {'总步数': 0, '有效步数': 0}) # 不管 relabel_name 之前在不在 relabel_stats 字典里,调用 setdefault 后,relabel_stats[relabel_name] 一定存在st['总步数'] += total_steps # 总步数依然用当行的 total_steps —— 即复核同学也「认定」原题的总步数与初审相同st['有效步数'] += relabel_valid# 质检checker = row.get('质检同学姓名')if pd.notna(checker): # 每遇到一行有“质检同学姓名”,就让对应姓名的计数 +1checker_counts[checker] = checker_counts.get(checker, 0) + 1# 构建 DataFrame(保留数值合格率)initial_df = pd.DataFrame([{'初审同学姓名': name,'总步数': stats['总步数'],'有效步数': stats['有效步数'],'合格率': stats['有效步数'] / stats['总步数'] if stats['总步数'] else 0} # 用“有效步数 ÷ 总步数” 得到一个 0–1 之间的小数;若总步数为 0 则直接赋 0,避免除零错误。for name, stats in initial_stats.items()])relabel_df = pd.DataFrame([{'复核同学姓名': name,'总步数': stats['总步数'],'有效步数': stats['有效步数'],'合格率': stats['有效步数'] / stats['总步数'] if stats['总步数'] else 0}for name, stats in relabel_stats.items()])checker_df = pd.DataFrame([{'质检同学姓名': name, '检查题目数': count}for name, count in checker_counts.items()])# 百分比格式化initial_df['合格率'] = initial_df['合格率'].map(lambda x: f"{x:.2%}")relabel_df['合格率'] = relabel_df['合格率'].map(lambda x: f"{x:.2%}")# 排序 初审/复核 按姓名字母序;质检按检查量从高到低。initial_df = initial_df.sort_values(by='初审同学姓名').reset_index(drop=True)relabel_df = relabel_df.sort_values(by='复核同学姓名').reset_index(drop=True)checker_df = checker_df.sort_values(by='检查题目数', ascending=False).reset_index(drop=True)return initial_df, relabel_df, checker_dfif __name__ == '__main__':# 示例:读取文件并指定 sheet 范围file_path = '目录/质检记录.xlsx'xls = pd.ExcelFile(file_path)# 假如想统计第 1 到第 3 张 sheet(索引从 0 开始)selected_sheets = xls.sheet_names[0:3]init_df, relabel_df, checker_df = analyze_qc_records(file_path, selected_sheets)# 打印结果print("初审同学统计:")print(init_df)print("\n复核同学统计:")print(relabel_df)print("\n质检同学统计:")print(checker_df)# 如需导出到 Excel:with pd.ExcelWriter('目录/质检统计结果.xlsx') as writer:init_df.to_excel(writer, sheet_name='初审统计', index=False)relabel_df.to_excel(writer, sheet_name='复核统计', index=False)checker_df.to_excel(writer, sheet_name='质检统计', index=False)print("统计已导出到 质检统计结果.xlsx")输出结果:
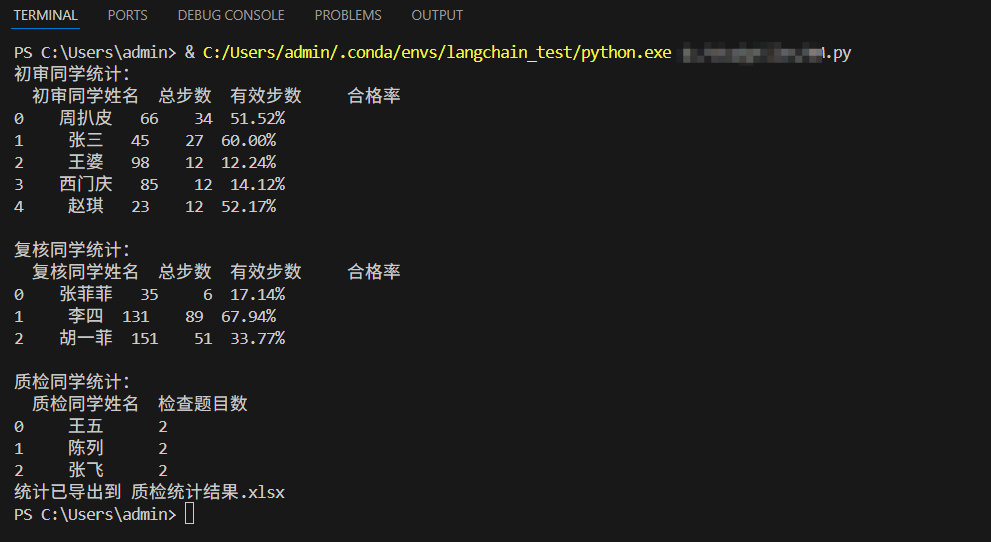
结果会直接写入XLSX文件保存。
并且初审/复核 按姓名字母序排列;质检按检查量从高到低排序。
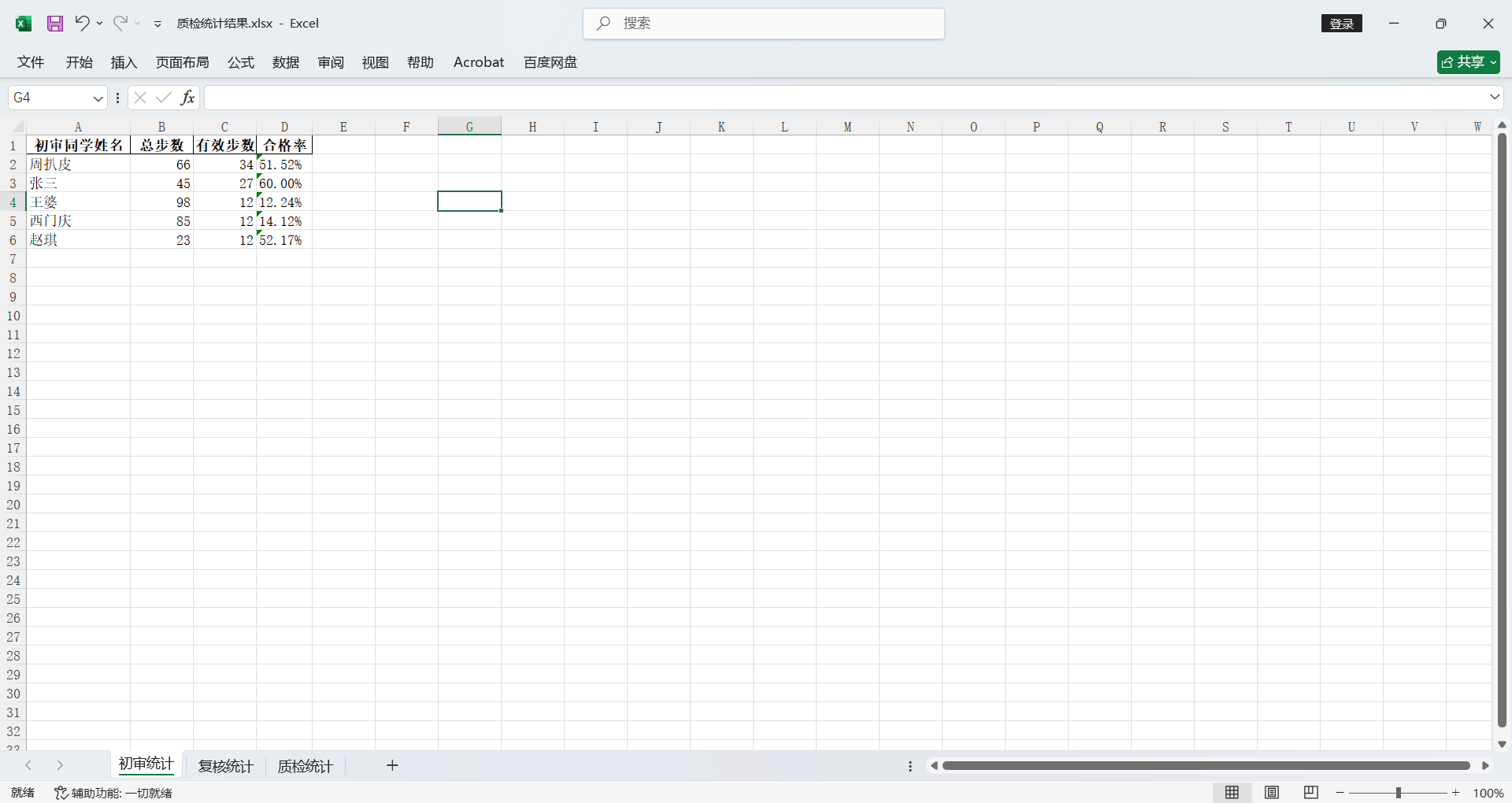
截至目前圆满实现了我的需求,完美!!
需要注意的点&容易困惑的代码片段:
1.飞书必须导出为XLSX
因为CSV没有多个sheet,无法实现跨多张表统计。如果导出成了CSV,你会惊喜地发现只剩下第一张表,后面的数据全丢了。
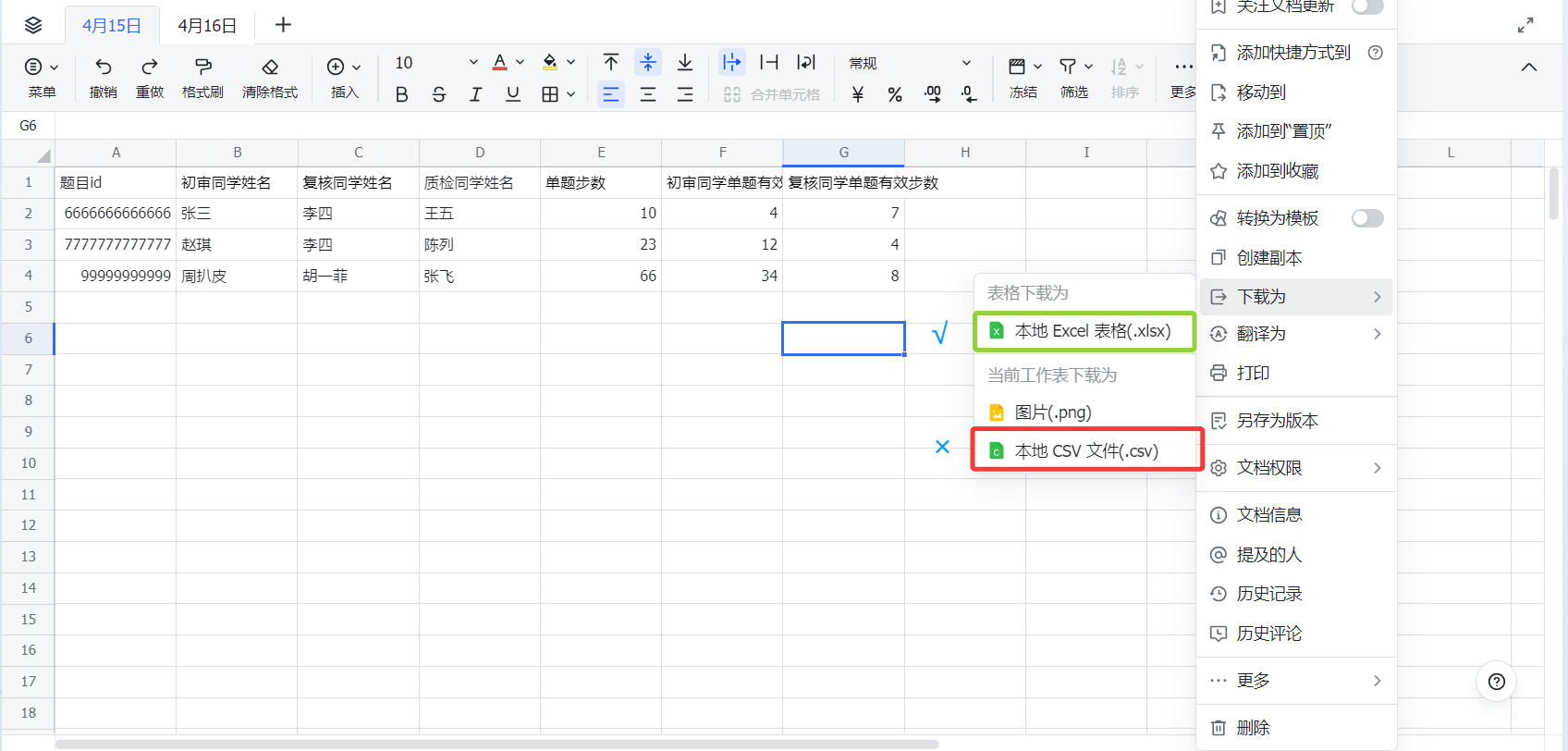
下载为CSV的后果…
2.if pd.notna(relabel_name),pd.notna是什么意思?
pd.notna(…) 的作用:
功能:判断一个值是否 不是 “缺失值”(NaN / None / NaT 等)。
返回:布尔值——如果传入的 relabel_name 既不是 NaN 也不是 None,则返回 True;否则返回 False。
为什么要用:在读取 Excel 时,空单元格会被 Pandas 识别为 NaN。只有当姓名字段确实有值时,才要执行后续的统计操作;如果是空的,就跳过这一行,避免在字典里注册一个空字符串或 NaN 作为键。
示例代码:
import pandas as pdprint(pd.notna("Alice")) # True,说明 "Alice" 是个有效字符串
print(pd.notna(None)) # False,说明 None 是缺失值
print(pd.notna(float('nan'))) # False,NaN 也是缺失值
这点确实很好用,有的同学填表容易漏项,没有把信息写全,留出一些空值在表里,会导致统计数据出现异常,非常的棘手。
3.dict.setdefault(key, default) 的用法?
所属类型:这是 Python 内置字典 (dict) 的一个方法。
功能:
如果字典中已经有了 key,就直接返回 dict[key];
如果没有 key,就先把 key: default 这对键值对插入字典,然后返回这个 default。
为什么要用:
这样写可以保证:不管 relabel_name 之前在不在 relabel_stats 字典里,调用 setdefault 后,relabel_stats[relabel_name] 一定存在,且是一个形如 {‘总步数’: 0, ‘有效步数’: 0} 的初始结构。
之后就可以安心地做 st[‘总步数’] += total_steps、st[‘有效步数’] += relabel_valid这样步数统计的操作,不用每次都写一大段 “如果 key 不在,就先赋值” 的逻辑。
示例代码:
d = {}
x = d.setdefault('张三', {'总步数': 0, '有效步数': 0})
# 这时 d == {'张三': {'总步数': 0, '有效步数': 0}}
# 变量 x 就是 {'总步数': 0, '有效步数': 0}# 再次调用
y = d.setdefault('张三', {'总步数': 100, '有效步数': 50})
# 因为 '张三' 已存在,d 不变,y 仍是原来的 {'总步数': 0, '有效步数': 0}print(d) # {'张三': {'总步数': 0, '有效步数': 0}}那么回到我们解决问题的代码:
结合第二点,这段代码的作用是:
先用 pd.notna 确保 relabel_name 真有值。
再用 setdefault 拿到或初始化统计结构,省去了手写“键不存在就先赋值”的繁琐。
最后在 st 上累加步数,就完成了该同学在“初审”或者”复核“环节的统计。
这样写既简洁又安全,不用担心 KeyError 或把空姓名也算进去。
4.for name, stats in initial_stats.items() ])这个stats是什么?
initial_stats 是你在前面遍历所有行时累积的一个字典,形如:
{"张三": {"总步数": 120, "有效步数": 110},"李四": {"总步数": 95, "有效步数": 90},...
}
initial_stats.items() 会返回一个由 (key, value) 对组成的可迭代对象,这里 key 就是每个同学的姓名,value 就是对应的那个小字典(包含 “总步数” 和 “有效步数” 两个字段)。
所以在列表推导里:
for name, stats in initial_stats.items()
name —— 对应同学姓名(例如 “张三”)
stats —— 对应该同学的那个子字典(例如 {“总步数”: 120, “有效步数”: 110})
接下来你就可以用 stats[‘总步数’]、stats[‘有效步数’] 来取出这两个值,计算合格率:
'合格率': stats['有效步数'] / stats['总步数'] if stats['总步数'] else 0
如果觉得 stats 这个名字不直观,也可以任意改成别的,比如 data、counts、vals,逻辑完全一样:它只是“每个同学对应的那份统计数据”的一个变量名。
相关文章:
【Python学习笔记】Pandas实现Excel质检记录表初审、复核及质检统计
背景: 我有这样一个需要审核的飞书题目表,按日期分成多个sheet,有初审——复核——质检三个环节,这三个环节是不同的同学在作业,并且领到同一个题目的人选是随机的,也就是说,完成一道题的三个人…...
)
药店药品管理系统(c语言版,使用链表)
一、声明后面所需要的结构体和函数 声明所需要的结构体、链表节点和函数部分 // 定义用户结构体 struct user {char username[20];char password[20]; };/*建立一个结构体储存商品信息*/ struct medicine {char name[20];int price;int number; };struct node {struct medi…...
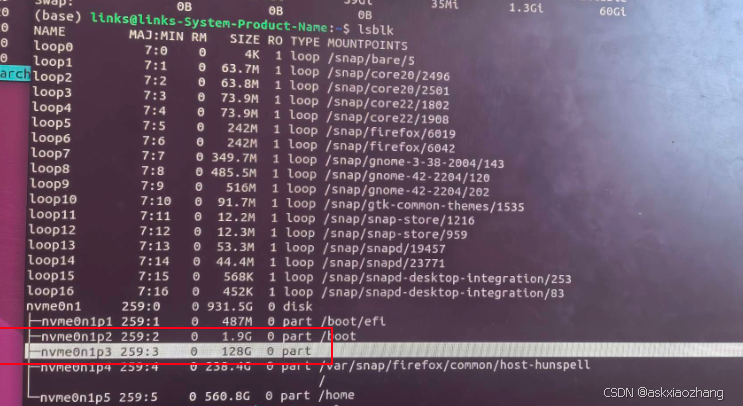
Gparted重新分配swap空间之后,linux电脑读不到swap空间
问题背景 lsblk 显示存在物理设备(如 /dev/nvme0n1),但 swapon --show 无输出 说明 系统未启用任何 Swap 设备 问题原因分析 /etc/fstab 中 Swap 的 UUID 配置错误 从图片中看到执行 sudo swapon -a 时报错: swapoff: cannot fin…...

Paramiko 使用教程
目录 简介安装 Paramiko连接到远程服务器执行远程命令文件传输示例 简介 Paramiko 是一个基于 Python 的 SSH 客户端库,它提供了在网络上安全传输文件和执行远程命令的功能。本教程将介绍 Paramiko 的基本用法,包括连接到远程服务器、执行命令、文件传输…...
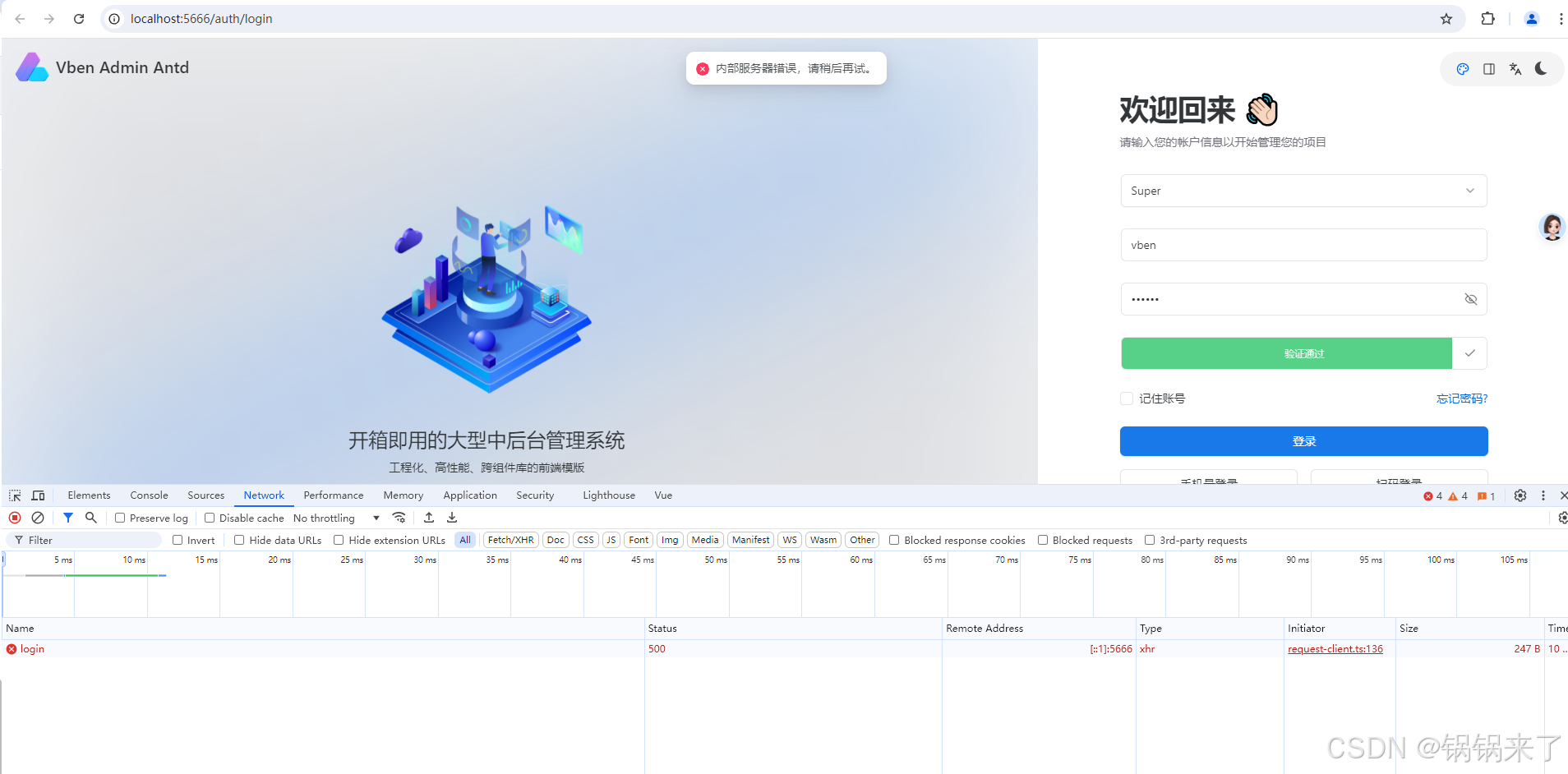
第一节:Vben Admin 最新 v5.0初体验
系列文章目录 基础篇 第一节:Vben Admin介绍和初次运行 第二节:Vben Admin 登录逻辑梳理和对接后端准备 第三节:Vben Admin登录对接后端login接口 第四节:Vben Admin登录对接后端getUserInfo接口 第五节:Vben Admin权…...
ARCGIS国土超级工具集1.5更新说明
ARCGIS国土超级工具集V1.5版本更新说明:因作者近段时间工作比较忙及正在编写ARCGISPro国土超级工具集(截图附后)的原因,故本次更新为小更新(没有增加新功能,只更新了已有的工具)。本次更新主要修…...
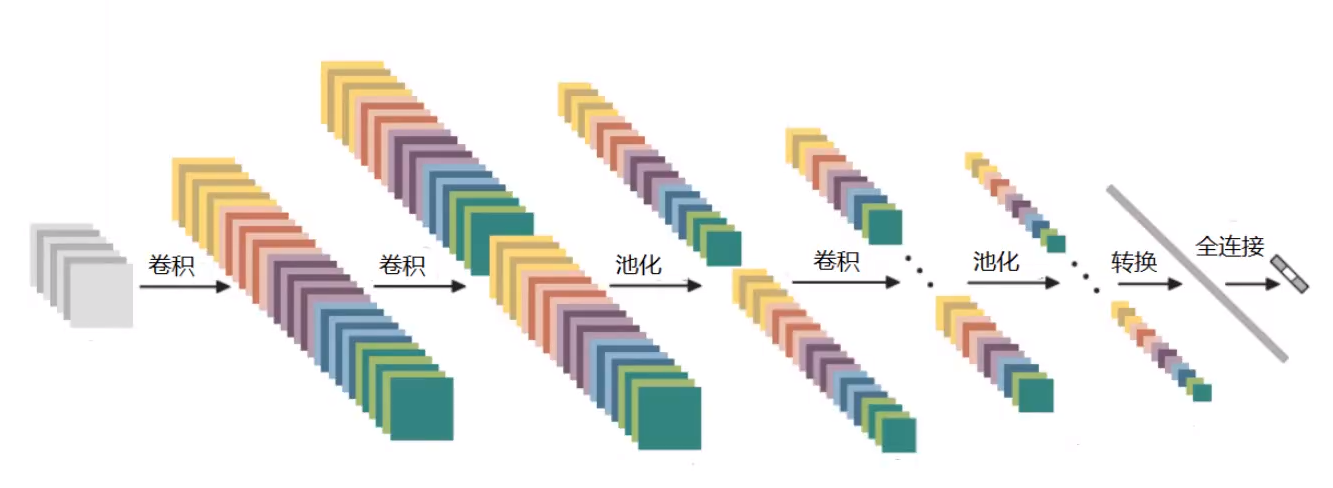
CNN:卷积到底做了什么?
卷积神经网络(Convolutional Neural Network, CNN) 是一种深度学习模型,专门用于处理具有网格结构的数据(如图像、视频等)。它在计算机视觉领域表现卓越,广泛应用于图像分类、目标检测、图像分割等任务。CN…...
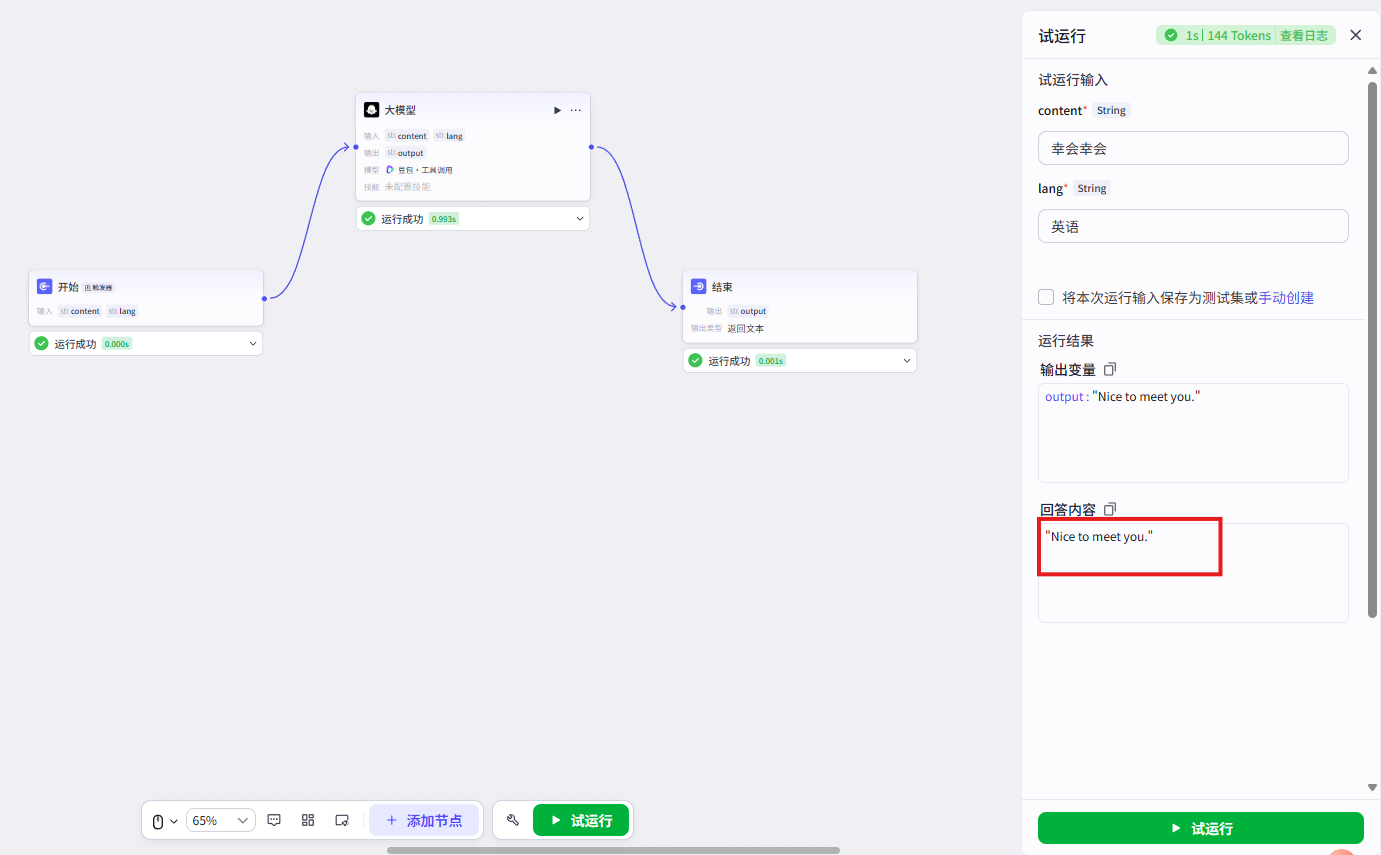
AI应用开发之扣子第二课-AI翻译(第1节/共2节)
简介 共分为两节介绍,内容简单易懂,步骤详细,可以避免很多坑,建议直接上手操作(预估30分钟)。 AI应用开发之扣子第二课学习-AI翻译(第1节/共2节):业务逻辑实现 AI应用…...

linux学习 3.用户的操作
用户 建议在系统操作的时候不要一直使用root用户,因为root用户具有最高权限,你可能因为某些操作影响了你的系统,采用子用户则可以避免这一点 这里的学习不用太深入,掌握如何创建删除切换即可(除非你要做详细的用户管理࿰…...

leetcode 139. Word Break
这道题用动态规划解决。 class Solution { public:bool wordBreak(string s, vector<string>& wordDict) {unordered_set<string> wordSet;for(string& word:wordDict){wordSet.insert(word);}int s_len s.size();//s的下标从1开始起算,dp[j]…...

Vue与React组件化设计对比
组件化是现代前端开发的核心思想之一,而Vue和React作为两大主流框架,在组件化设计上既有相似之处,也存在显著差异。本文将从语法设计、数据管理、组件通信、性能优化、生态系统等多个方向,结合实例详细对比两者的特点。 一、模板…...
Leetcode刷题 由浅入深之哈希表——242. 有效的字母异位词
目录 (一)字母异位词的C实现 写法一(辅助数组) (二)复杂度分析 时间复杂度 空间复杂度 (三)总结 【题目链接】242.有效的字母异位词 - 力扣(LeetCode) …...

自动化构建工具:makemakefile
在Windows中,我们写C代码或者C代码都需要用先找到一款合适的编译器,用来方便我们更好的完成代码,比如说vs2019,这些工具的特点是集成了多种开发所需的功能,如代码编辑、编译、调试、版本控制等,无需在不同的…...

刷题 | 牛客 - js中等10题(更ing)1/54知识点解答
知识点汇总: Array.from(要转换的对象, [mapFn], [thisArg ]):将类数组对象(Array-like)/可迭代对象(Iterable)转为真正的数组。 第二参 mapFn 是 类似 Array.prototype.map 的回调函数,加工…...

Ubuntu 20.04.6编译安装COMFAST CF-AX90无线网卡驱动
目录 0 前言 1 CF-AX90无线网卡驱动 1.1 驱动下载 1.2 驱动准备 2 编译安装驱动 2.1 拷贝驱动依赖到系统 2.2 驱动安装编译 3 重启 0 前言 COMFAST CF-AX90或者说AIC8800D80的Linux版本驱动不支持高版本的linux内核,实测目前仅支持最高5.15的内核。Ubuntu2…...

将python项目打包成Windows后台服务
前文,我开发了一个基于windows11与本地deepseek实现的语音助手,之前是通过CMD直接执行项目的main.py文件。但是这样不适合移植,现在想将其生成一个exe文件,以及部署成windows的后台服务。 关于语音助手的开发与发布,可以看的CSDN文章:一个基于windows11与本地deepseek实…...
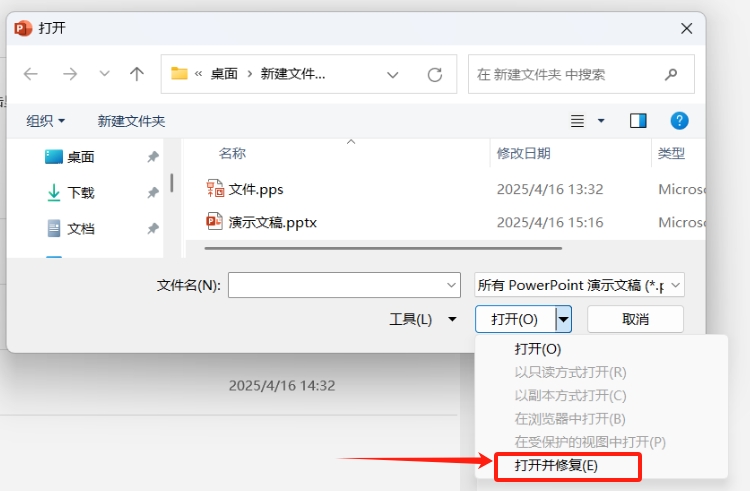
PPT无法编辑怎么办?原因及解决方法全解析
在日常办公中,我们经常会遇到需要编辑PPT的情况。然而,有时我们会发现PPT文件无法编辑,这可能由多种原因引起。今天我们来看看PPT无法编辑的几种常见原因,并提供实用的解决方法,帮助你轻松应对。 原因1:文…...

安全用电基础知识及隐患排查重点
安全用电是电气安全的一个重要方面,作为普通人员,必须学会基础的用电知识和技巧,才能保障自己和家庭的安全。 以下是安全用电的基础知识及隐患排查重点: 一、基础知识 1.电压:单位为伏特(V)&a…...
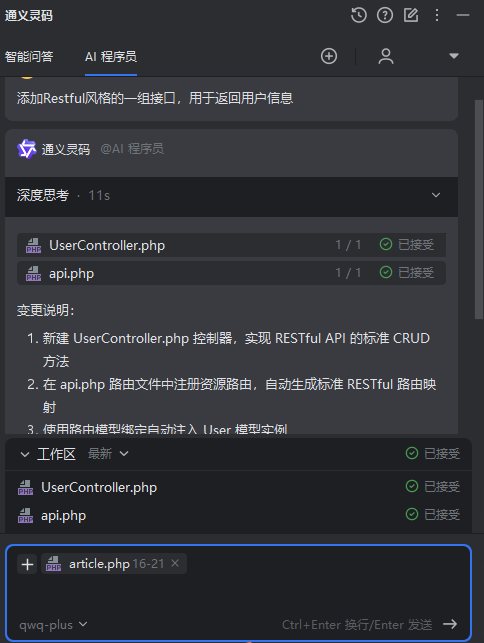
Laravel 使用通义灵码 - AI 辅助开发提升效率
一、引言 Laravel 是 PHP 常用的一种后端开发框架,遵循 MVC(模型 - 视图 - 控制器)架构,以简洁、优雅的语法和强大的功能著称,旨在提升开发效率并简化复杂任务的实现。然而,它的开发习惯可能与传统的 PHP …...

签到功能---实现签到接口
文章目录 概要整体架构流程技术细节小结 概要 需求分析以及接口设计 由KEY的结构可知,要签到,就必须知道是谁在哪一天签到,也就是两个信息: 当前用户 当前时间 这两个信息我们都可以自己获取,因此签到时ÿ…...

JavaScript爬虫基础篇:HTTP 请求与响应
在互联网的世界里,数据无处不在。无论是新闻资讯、商品信息,还是社交媒体动态,这些数据都以各种形式存储在服务器上。而爬虫,就是我们获取这些数据的得力助手。今天,我们就来聊聊爬虫的基础——HTTP 请求与响应&#x…...
方法)
Python中的count()方法
文章目录 Python中的count()方法基本语法在不同数据类型中的使用1. 列表(List)中的count()2. 元组(Tuple)中的count()3. 字符串(String)中的count() 高级用法1. 指定搜索范围2. 统计复杂元素 注意事项 Python中的count()方法 前言:count()是Python中用于序列类型&a…...
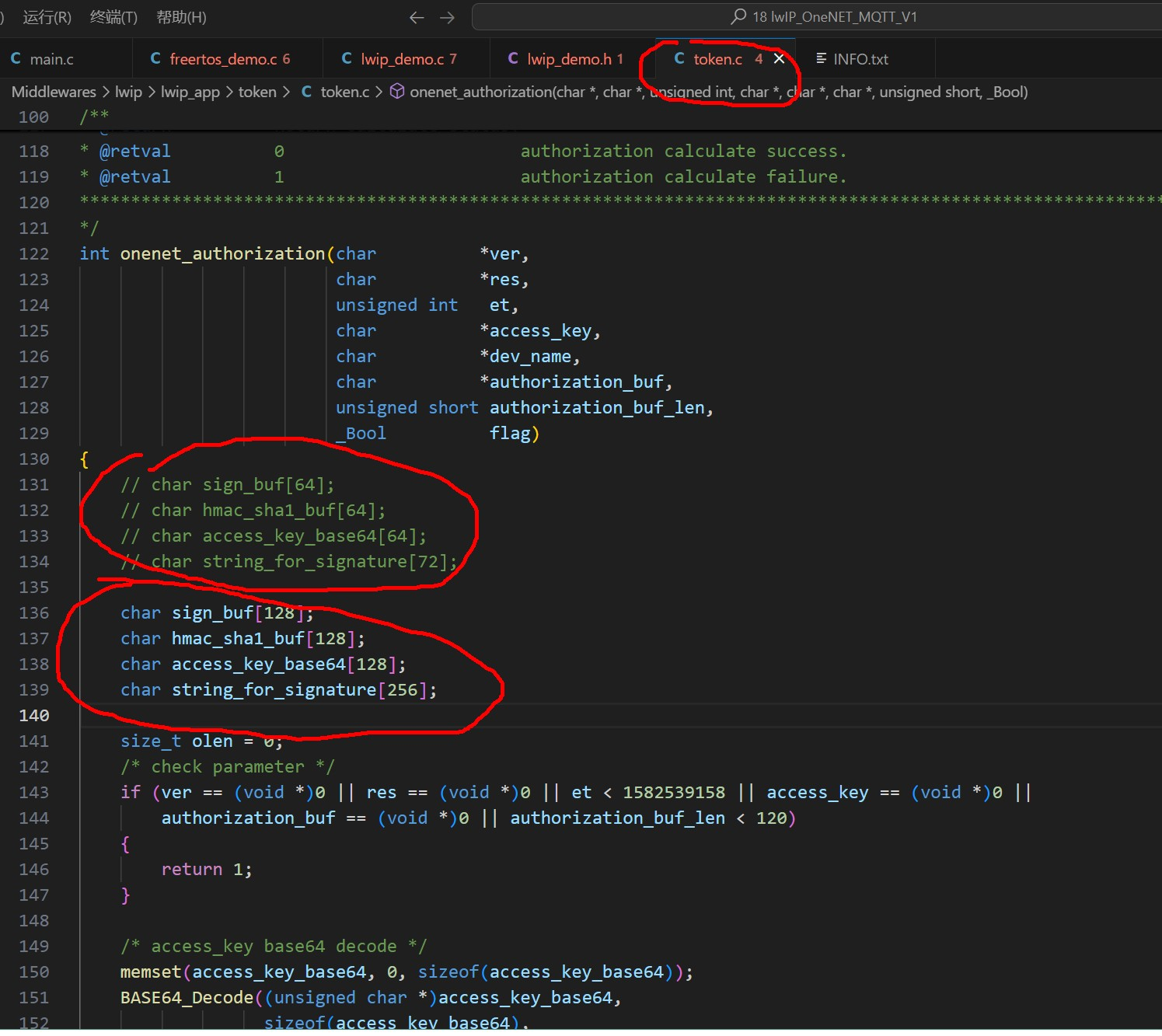
LWIP_MQTT连接ONENET
前言: 使用正点原子STM32F407, LWIP,MQTT demo,验证LwIP的MQTT连接ONENET物联网平台,测试整个链路是否畅通,后面再详细分析LWIP移植和MQTT协议的使用。 26 基于 MQTT 协议连接 OneNET 服务器 本章主要介绍 lwIP 如何通过 MQTT 协议将设备连接到 OneNET…...
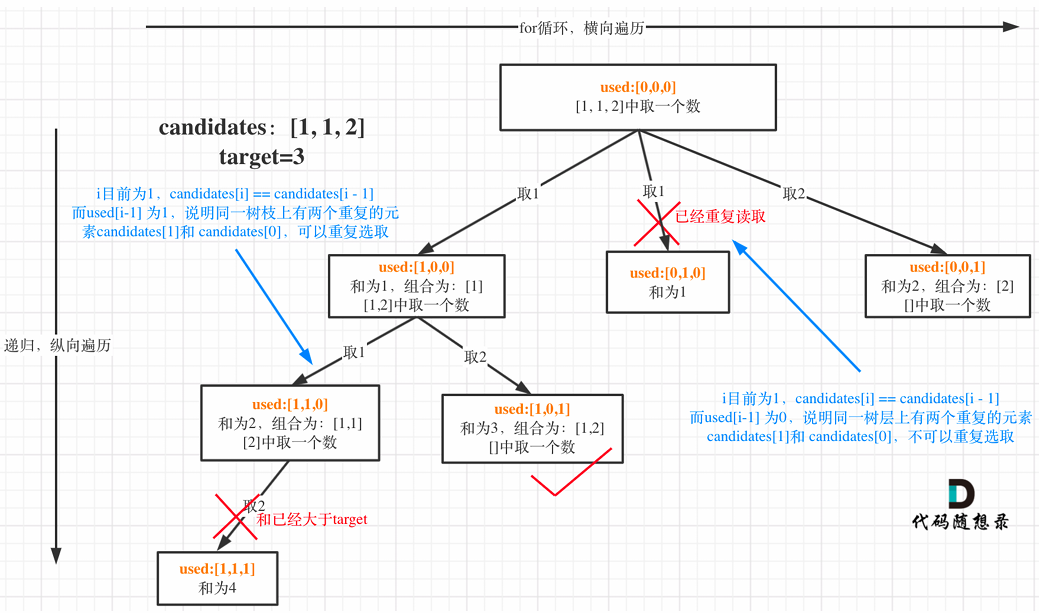
代码随想录刷题|Day20(组合总数,组合总数2、分割回文串)
回溯算法 Part02 组合总数 力扣题目链接 代码随想录链接 视频讲解 题目描述: 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你…...
详解及利用方法)
文件描述符(File Descriptor, FD)详解及利用方法
文件描述符(FD)是 Linux/Unix 系统中用于访问文件、管道、套接字等 I/O 资源的整数标识符。每个进程默认打开 3 个标准文件描述符: FD名称默认绑定设备用途0stdin键盘标准输入(读取数据)1stdout终端屏幕标准输出&…...
)
Minecraft盔甲机制详解(1.9之后)
Minecraft的盔甲有很多种,但是评判盔甲的好坏,通常玩家会使用一个变量来评判——护甲值 护甲值的机制很简单,一格护甲值 (半个灰色的衣服图标)最多能提供4%的防御 护甲值在不开作弊的生存模式理论上限是20点…...

ArcGIS Desktop使用入门(四)——9版本与10版本区别
系列文章目录 ArcGIS Desktop使用入门(一)软件初认识 ArcGIS Desktop使用入门(二)常用工具条——标准工具 ArcGIS Desktop使用入门(二)常用工具条——编辑器 ArcGIS Desktop使用入门(二&#x…...

R语言之环境清理
有时候 R 环境中残留的变量可能会导致警告,可以尝试清理工作空间并重新加载数据。 警告信息: In mget(objectNames, envir ns, inherits TRUE) : 重新评估被中断的许诺 # 观察前6行 head(iris)# 观察数据结构 str(iris)# 探知数据的极值和分位数,以及…...
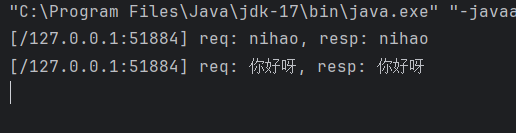
javaSE————网络编程套接字
网络编程套接字~~~~~ 好久没更新啦,蓝桥杯爆掉了,从今天开始爆更嗷; 1,网络编程基础 为啥要有网络编程呢,我们进行网络通信就是为了获取丰富的网络资源,说实话真的很神奇,想想我们躺在床上&a…...
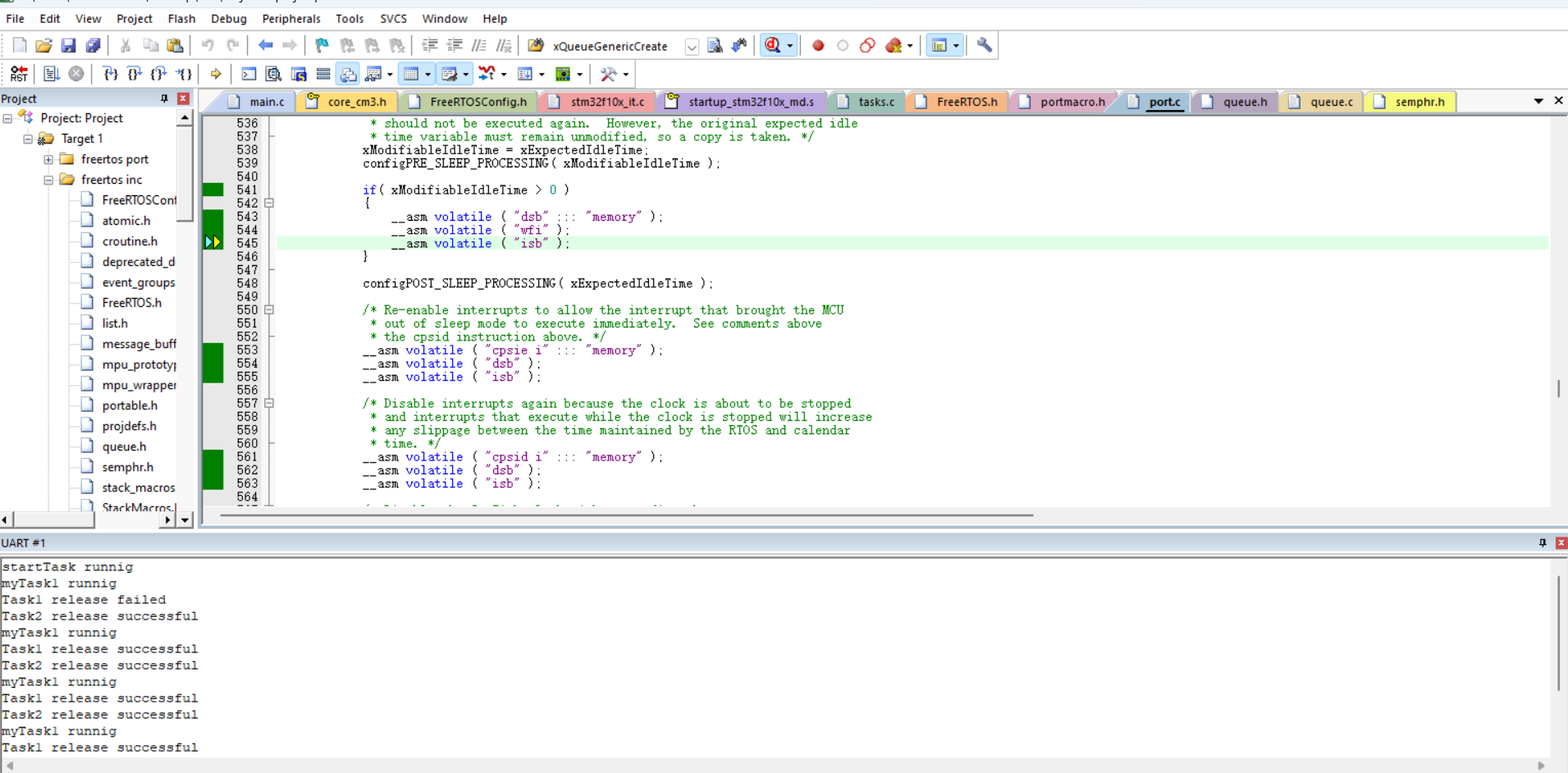
FreeRTOS二值信号量详解与实战教程
FreeRTOS二值信号量详解与实战教程 📚 作者推荐:想系统学习FreeRTOS嵌入式开发?请访问我的FreeRTOS开源学习库,内含从入门到精通的完整教程和实例代码! 1. 二值信号量核心概念解析 二值信号量(Binary Semaphore)是Fre…...