AI 模型高效化:推理加速与训练优化的技术原理与理论解析
AI 模型高效化:推理加速与训练优化的技术原理与理论解析

文章目录
- AI 模型高效化:推理加速与训练优化的技术原理与理论解析
- 一、推理加速:让模型跑得更快的“程序员魔法”
- (一)动态结构自适应推理:像人类一样选择性思考
- (二)跨模态知识迁移:让模型「举一反三」
- (三)存内计算协同:打破「数据搬运工」瓶颈
- 二、训练优化:让模型学得更快的「程序员兵法」
- (一)自适应混合精度训练:用「精打细算」节省显存
- (二)分布式训练通信优化:让多卡协作更高效
- (三)自监督学习:让模型「无师自通」
- 三、进阶理论:从代码到数学的深层逻辑
- (一)模型压缩的数学基础:低秩分解(SVD)
- (二)分布式训练的通信复杂度:从 \( O(N) \) 到 \( O(1) \)
- 四、避坑指南
- 五、前沿工具箱
- 结语:做 AI 世界的系统工程师
一、推理加速:让模型跑得更快的“程序员魔法”
(一)动态结构自适应推理:像人类一样选择性思考
核心理论:生物启发的智能计算分配
- 为什么需要动态结构? 传统模型无论输入是什么,都按固定流程计算(比如层层递进的神经网络),就像一个人不分重点地逐字阅读。动态结构则像人类视觉 —— 看到复杂图像时聚焦细节,简单场景时快速扫描,通过 强化学习 让模型自己决定「哪些层需要算,哪些可以跳过」。
技术实现:用代码控制“计算开关”
1. 强化学习控制器(轻量级决策模块) 用一个小的 LSTM 网络(图 1),输入当前层的特征「混乱度」(熵值),输出是否跳过该层的决策(0/1)。
class DecisionLSTM(nn.Module):def __init__(self, input_size, hidden_size):super().__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.classifier = nn.Linear(hidden_size, 1) # 输出0或1def forward(self, feature_entropy):# feature_entropy形状:[batch_size, seq_len, input_size]out, _ = self.lstm(feature_entropy)return torch.sigmoid(self.classifier(out)) # 决策概率
2.渐进式剪枝策略
- 早期层(如神经网络前几层)保留 70% 计算量(抓整体特征),后期层(提取细节)逐步降至 30%(图 2)。
- 辅助缓存:用字典存储被跳过层的输出(cache = {layer_id: hidden_state}),避免重复计算。
示意图:动态结构推理流程
图 1:LSTM 控制器决定是否跳过当前层,缓存机制避免重复计算
(二)跨模态知识迁移:让模型「举一反三」
核心理论:不同模态的「语言翻译官」
跨模态困境:图像是像素矩阵,文本是 token 序列,如何让模型同时理解?解决:用共享的 Transformer 编码器(图 3),把图像和文本都翻译成统一的「语义语言」(比如 128 维向量),再通过交叉注意力让两者「对话」。
代码实现:多模态特征融合
class CrossAttention(nn.Module):def __init__(self, dim):super().__init__()self.qkv = nn.Linear(dim, dim*3, bias=False)self.out = nn.Linear(dim, dim)def forward(self, text_feat, image_feat):# 文本转Query,图像转Key/Valueq = self.qkv(text_feat)[..., :dim]k, v = self.qkv(image_feat)[..., dim:].chunk(2, dim=-1)# 计算注意力:文本如何关注图像区域attn = (q @ k.transpose(-2, -1)) / (dim**0.5)return self.out(torch.softmax(attn, dim=-1) @ v)
示意图:跨模态特征融合过程
图 2:文本和图像通过共享编码器进入同一语义空间,交叉注意力实现模态交互
(三)存内计算协同:打破「数据搬运工」瓶颈
核心理论:让数据「原地计算」
- 传统痛点:CPU/GPU 计算时,数据需在内存和计算单元之间来回搬运,能耗占比超 90%(图 4 左)。
- 存内计算:把存储单元(如 Flash 芯片)变成「计算器」,数据直接在存储里做矩阵乘法(图 4 右),算力密度提升 20 倍。
技术实践:用 TVM 适配存内计算芯片
- 模型转换:将神经网络的全连接层(Y=WX)转换为存内计算支持的「模拟矩阵乘法」。
- 稀疏优化:通过结构化剪枝(如每 4x4 矩阵保留 2 个非零元素),减少存储单元的计算量。
# TVM定义存内计算算子(简化版)
@tvm.register_func("mem_compute.matmul")
def mem_compute_matmul(w, x):# 假设w已存储在存内计算芯片的电阻阵列中return simulate_analog_compute(w, x) # 调用硬件模拟函数
存内计算vs传统计算对比表
| 维度 | 传统冯·诺依曼架构 | 存内计算架构 |
|---|---|---|
| 数据流向 | 内存 ↔ 总线 ↔ 计算单元(多次搬运) | 存储单元直接计算(原地处理) |
| 能耗占比 | 数据搬运占90%+ | 搬运能耗降低90% |
| 算力密度 | 约1.2TOPS/W(GPU) | 24TOPS/W(存内计算芯片) |
| 典型应用 | 云端大模型推理(如GPT-4) | 边缘AI(智能手表、AR眼镜) |
二、训练优化:让模型学得更快的「程序员兵法」
(一)自适应混合精度训练:用「精打细算」节省显存
核心理论:该省省,该花花
- FP16(半精度):优点是计算快、占显存少;缺点是数值范围小,容易算错(比如梯度太小变成 0)。
- FP32(单精度):准确但占显存大。
- 动态平衡:对敏感层(如 BatchNorm)用 FP32,对卷积层用 FP16,通过「损失缩放」避免 FP16 下溢(图 5)。
代码实现:PyTorch 自动混合精度
from torch.cuda.amp import autocast, GradScalerscaler = GradScaler() # 自动调整缩放因子
for inputs, labels in dataloader:inputs = inputs.cuda()labels = labels.cuda()optimizer.zero_grad(set_to_none=True)with autocast(): # 自动用FP16计算outputs = model(inputs)loss = criterion(outputs, labels)scaler.scale(loss).backward() # 放大损失防止下溢scaler.step(optimizer) # 反向传播scaler.update() # 更新缩放因子
(二)分布式训练通信优化:让多卡协作更高效
核心理论:减少「卡间聊天」时间
- 痛点:多 GPU 训练时,梯度需要在卡间同步(all-reduce),通信耗时占比达 40%。
- 解决方案:
a.梯度量化:把 32 位梯度压缩成 4 位(如 0.123→0.12),通信量减少 8 倍(图 6)。
b.异步更新:允许落后的 GPU 先算完再同步,避免全局等待。
代码框架:基于 Horovod 的压缩通信
import horovod.torch as hvdhvd.init()
optimizer = hvd.DistributedOptimizer(optimizer, compression=hvd.Compression.fp16)for epoch in range(epochs):for inputs, labels in dataloader:outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()hvd.allreduce(optimizer.param_groups[0]['params'], op=hvd.AverageOp) # 压缩后通信optimizer.step()
(三)自监督学习:让模型「无师自通」
核心理论:自己和自己玩「找不同」
- 为什么重要?:标注数据昂贵(如医学影像标注每例 500 元),自监督用无标注数据训练。
- SimCLR 方法:把同一张图做两种变换(如裁剪 + 模糊),让模型学习「这两个变换后的图其实是同一张图」(图 7)。
代码实现:对比学习损失函数
def simclr_loss(h1, h2, temperature=0.1):# h1, h2是同一张图的两个视图的特征batch_size = h1.shape[0]h = torch.cat([h1, h2], dim=0) # [2B, D]sim = torch.matmul(h, h.t()) / temperature # 相似度矩阵# 构造标签:每个h1对应的正样本是对应的h2,反之亦然labels = torch.arange(batch_size, dtype=torch.long, device=h.device)labels = (labels + batch_size) % (2 * batch_size)return nn.CrossEntropyLoss()(sim, labels)
三、进阶理论:从代码到数学的深层逻辑
(一)模型压缩的数学基础:低秩分解(SVD)
核心公式:
对于任意矩阵 W ∈ R m × n W \in \mathbb{R}^{m \times n} W∈Rm×n
其奇异值分解(SVD)可表示为: W = U Σ V T W = U \Sigma V^T W=UΣVT
其中: U ∈ R m × k U \in \mathbb{R}^{m \times k} U∈Rm×k 为左奇异矩阵(列正交)
Σ ∈ R k × k \Sigma \in \mathbb{R}^{k \times k} Σ∈Rk×k 为对角矩阵,对角线元素为降序排列的奇异值
V ∈ R n × k V \in \mathbb{R}^{n \times k} V∈Rn×k 为右奇异矩阵(列正交)
通过保留前 ( k ) 个最大奇异值(( k \ll \min(m, n) )),可实现矩阵的低秩近似,参数量从原始的 ( m \times n ) 压缩至 ( k(m + n + k) )。
压缩效果对比:
| 指标 | 原始矩阵 | 低秩分解后 | 压缩比(( m=n=1000, k=50 )) |
|---|---|---|---|
| 参数量 | ( 10^6 ) | ( 102,500 ) | 约9.7倍 |
| 计算复杂度 | ( O(mn) ) | ( O(k(m+n)) ) | 降低90%+ |
(二)分布式训练的通信复杂度:从 ( O(N) ) 到 ( O(1) )
传统全reduce通信量:
通信量 = N × D (N为GPU数,D为参数维度) \text{通信量} = N \times D \quad \text{(N为GPU数,D为参数维度)} 通信量=N×D(N为GPU数,D为参数维度)
优化后通信量:
通过梯度量化(如4位定点数,压缩比8倍)和稀疏化(仅传输非零梯度,稀疏度s):
优化后通信量 = N × D × s 8 \text{优化后通信量} = \frac{N \times D \times s}{8} 优化后通信量=8N×D×s
当稀疏度 ( s=0.1 ) 时,通信量降至原始的 1/80,显著减少卡间同步耗时。
四、避坑指南
- 动态剪枝≠随意删层:需通过训练让模型学会「哪些层可以删」,直接手动删层可能导致精度暴跌。
- 混合精度不是「一刀切」:先用
torch.cuda.is_available()检查硬件是否支持 FP16,老显卡(如 Pascal架构)可能不兼容。 - 分布式训练先调单卡:确保单卡代码无误后再用多卡,否则通信错误难以排查。
五、前沿工具箱
| 领域 | 前言理论 | 开源工具链 | 顶会热点 |
|---|---|---|---|
| 推理加速 | 神经形态计算(类脑架构) | TensorRT、TVM、TFLite | NeurIPS’24 动态网络专场 |
| 训练优化 | 二阶优化(L-BFGS 变种) | DeepSpeed、Horovod、Apex | ICML’24 大规模训练 Workshop |
| 存内计算协同 | 电阻式 RAM(RRAM)计算模型 | 知存科技 WTM SDK、MemCNN 库 | ISSCC’24 存算一体芯片论文 |
结语:做 AI 世界的系统工程师
从编程视角看,AI 优化本质是在算力、精度、速度之间找平衡。
初学者需先理解每个技术的为什么(如为什么需要存内计算),再动手实现小案例(如用 PyTorch 写一个动态剪枝层);内行人则需深入数学推导(如 SVD 压缩的误差边界)和硬件特性(如 HBM3e 的带宽瓶颈)。
记住:最好的优化代码,是让机器聪明地偷懒,而不是盲目地蛮干。
相关文章:
AI 模型高效化:推理加速与训练优化的技术原理与理论解析
AI 模型高效化:推理加速与训练优化的技术原理与理论解析 文章目录 AI 模型高效化:推理加速与训练优化的技术原理与理论解析一、推理加速:让模型跑得更快的“程序员魔法”(一)动态结构自适应推理:像人类一样…...

c++STL——vector的使用和模拟实现
文章目录 vector的使用和模拟实现vector的使用vector介绍重点接口的讲解迭代器部分默认成员函数空间操作增删查改操作迭代器失效问题(重要)调整迭代器 vector的模拟实现实现的版本模拟实现结构预先处理的函数尾插函数push_backswap函数赋值重载size函数reserve函数 迭代器默认成…...
git更新的bug
文章目录 1. 问题2. 分析 1. 问题 拉取了一个项目后遇到了这个问题, nvocation failed Server returned invalid Response. java.lang.RuntimeException: Invocation failed Server returned invalid Response. at git4idea.GitAppUtil.sendXmlRequest(GitAppUtil…...
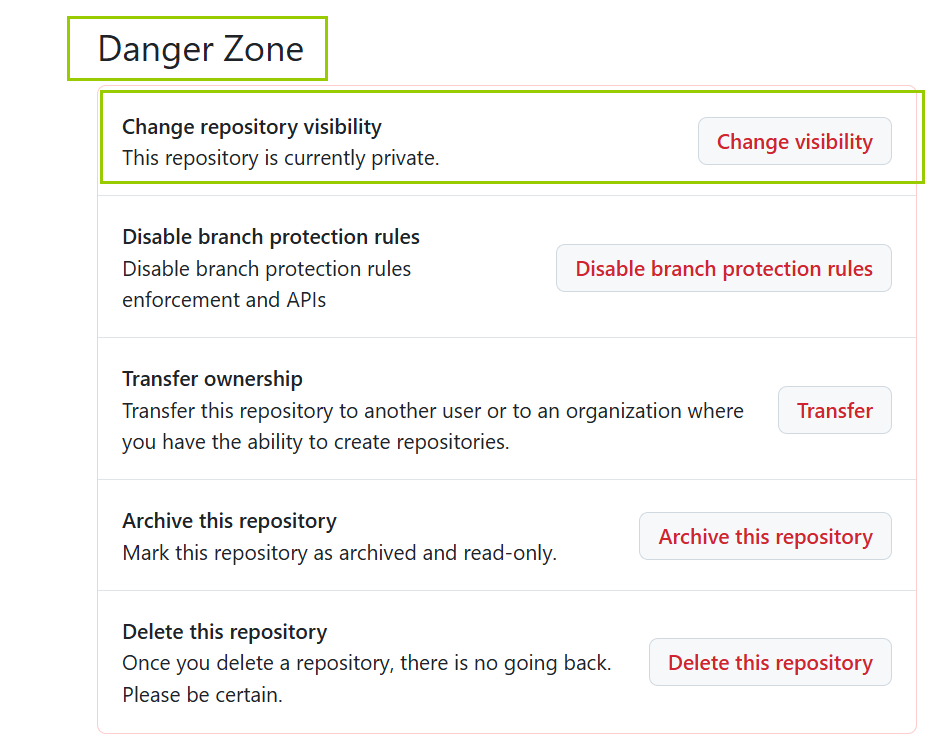
github | 仓库权限管理 | 开权限
省流版总结: github 给别人开权限:仓库 -> Setting -> Cllaborate -> Add people GitHub中 将公开仓库改为私有:仓库 -> Setting -> Danger Zone(危险区) ->Change repository visibility( 更改仓…...

MQTT客户端核心架构解析:clients.h源码深度解读
MQTT客户端核心架构解析:clients.h源码深度解读 一、头文件概览与设计哲学 clients.h作为MQTT客户端核心数据结构定义文件,体现了以下设计原则: 分层架构:网络层/协议层/业务层解耦状态管理:通过状态机实现复杂协议…...

uniapp自定义底部导航栏,解决下拉时候顶部空白的问题
一、背景 最近使用uniapp开发微信小程序,因为使用了自定义的顶部导航栏,所以在ios平台上(Android未测试)测试的时候,下拉的时候会出现整个页面下拉并且顶部留下大片空白的问题 二、任务:解决这个问题 经…...
C++学习之密码学知识
目录 1.文档介绍 2.知识点概述 3.项目准备 4.序列化介绍 5.项目中基础组件介绍 6.基础模块在项目中作用 7.项目中其他模块介绍 8.加密三要素 9.对称加密和非堆成加密 10.对称和非对称加密特点 11.堆成加密算法des 12.des对称加密算法 13.对称加密算法aes 14.知识点…...

力扣 797. 所有可能的路径
题目 给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序) graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一…...
第二篇:linux之Xshell使用及相关linux操作
第二篇:linux之Xshell使用及相关linux操作 文章目录 第二篇:linux之Xshell使用及相关linux操作一、Xshell使用1、Xshell安装2、Xshell使用 二、Bash Shell介绍与使用1、什么是Bash Shell(壳)?2、Bash Shell能干什么?3、平时如何使…...
自动驾驶热点技术的成熟之处就是能判断道路修复修路,能自动利用类似“人眼”的摄像头进行驾驶!值得学习!)
全自动驾驶(FSD,Full Self-Driving)自动驾驶热点技术的成熟之处就是能判断道路修复修路,能自动利用类似“人眼”的摄像头进行驾驶!值得学习!
全自动驾驶(FSD,Full Self-Driving)软件是自动驾驶领域中的热点技术,其核心目标是实现车辆在各种复杂交通环境下的安全、稳定、高效自动驾驶。FSD软件的技术核心涉及多个方面的交叉技术,下面将详细分析说明其主要核心技…...

SpringBoot项目动态加载jar 实战级别
网上也找到类似的文章,但是基本都不到实用级别,就是不能直接用。在参照网上的文章及与AI沟通N次后终于完善可以在实际项目上 创建jar文件动态加载类 Component Slf4j public class PluginRegistry {Autowiredprivate GenericApplicationContext applicat…...
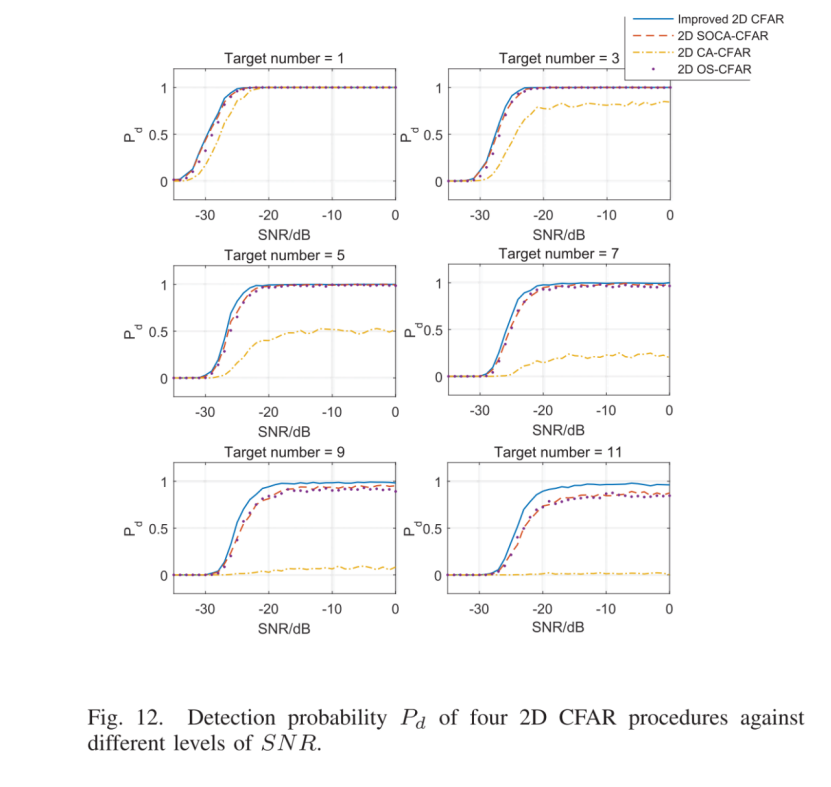
一种改进的CFAR算法用于目标检测(解决多目标掩蔽)
摘要 恒虚警率(CFAR)技术在雷达自动检测过程中起着关键作用。单元平均(CA)CFAR算法在几乎所有的多目标情况下都会受到掩蔽效应的影响。最小单元平均(SOCA)CFAR算法仅当干扰目标位于参考窗口的前后方时才具有…...

无人机+智能监控:石油管道巡检迈入“空中智慧时代”
引言:安全与效率的双重革命 在广袤的沙漠、崎岖的山脉或人迹罕至的冻土带,石油管道的安全巡检曾是一项耗时耗力且风险极高的任务。如今,随着无人机巡检技术与视频监控管理平台的深度融合,石油行业正迎来一场智能化变革——从“人巡…...
)
Python内置函数---anext()
用于异步迭代器的核心工具,专为处理异步数据流设计。 1. 基本语法 await anext(async_iterator, default) 参数: async_iterator :实现了异步迭代协议的对象(如异步生成器、异步迭代器类)。 default (可选…...

4.17学习总结
完成135. 分发糖果 - 力扣(LeetCode)的算法 学习了字节缓冲流和字符缓冲流,了解了底层的原理,...

【gpt生成-其一】以go语言为例,详细描述一下 :语法规范BNF/EBNF形式化描述
在 Go 语言中通过 EBNF 形式化描述语法规范需要结合语言规范文档的结构,以下是详细实现方法及标准规范示例: 一、Go 语法规范结构(基于 Go 1.21 标准) ebnf 复制 // 基础元素定义 letter "A" ... "Z&quo…...
)
用cython将python程序打包成C++动态库(windows+Vistual Studio2017平台)
作为一名程序员我们都知道Python的库可能要比C的丰富的多特别是在算法方面,但是有的时候我们的工程是用C开发的,我们又像用Python的这个库那怎么办呢?如果直接调.py程序,工程中代码有.py又有.cpp显得工程很杂乱。那么我么可以借助…...
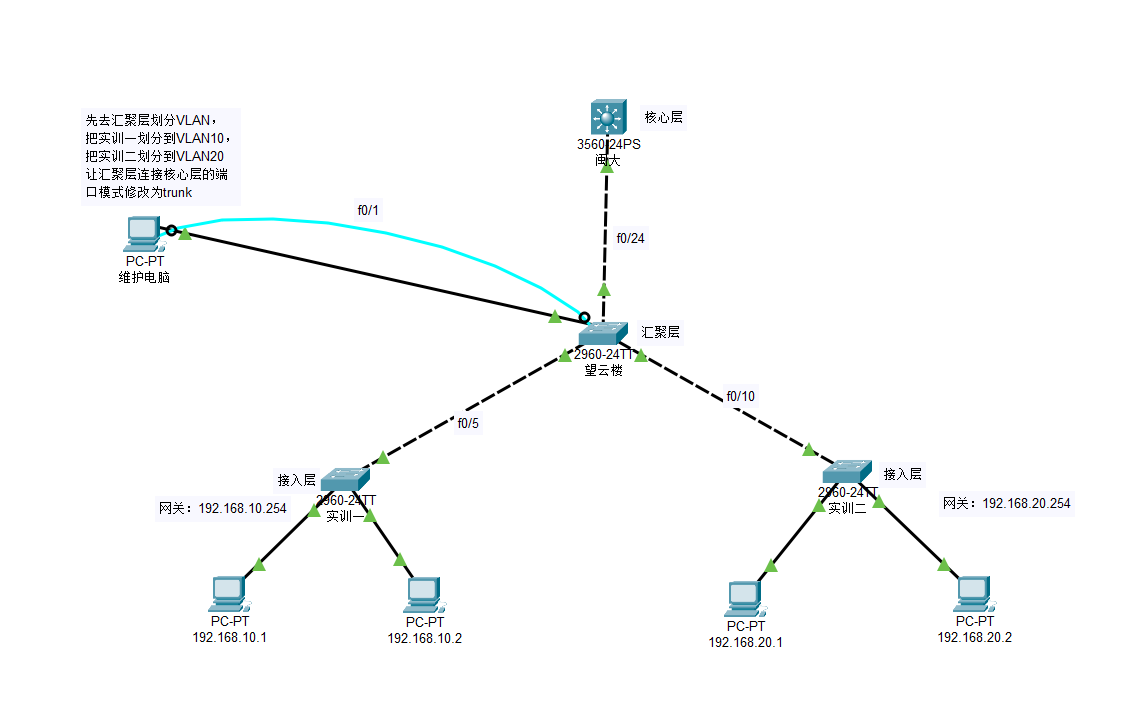
三层交换机SVI功能(交换机虚拟接口)实现各个实训室电脑网络可互通,原本是独立局域网
三层交换机 SVI功能(交换机虚拟接口) 实现VLAN路由 需求 :各实训室使用独立局域网,即每个实训有自己的IP网段, 每个实训室只有内部互相访问。 需求:为了加强各实训室学生的交流,学校要求我们…...

class的访问器成员
class的访问器成员 本质是 class 的语法糖 等价于对象的defineProperty对象里面也能使用 class Product{constructor(count, price){this.count count;this.price price;}get total(){ // 相当于getterreturn this.count * this.price;}}const product new Product(10, 10…...
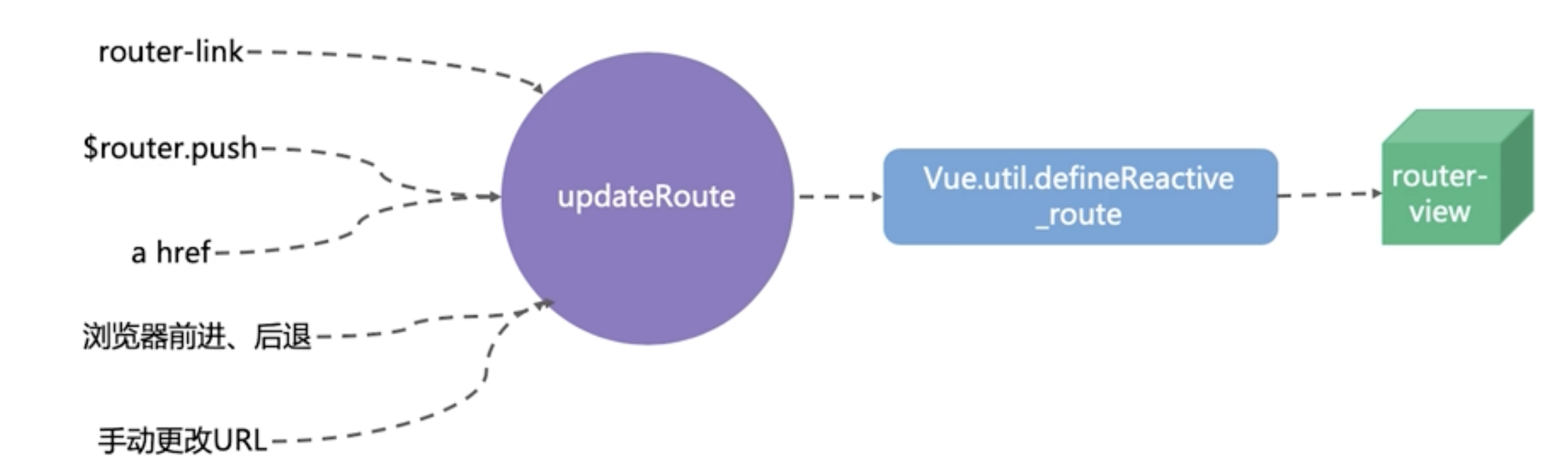
vue入门:路由 router
文章目录 介绍安装配置路由模式嵌套路由路由传参编程式导航路由懒加载 底层原理 介绍 vue2 vue router API vue3 vue router API Vue Router 是 Vue.js 的官方路由管理器,它允许你通过不同的 URL 显示不同的组件,从而实现单页面应用(SPA&a…...
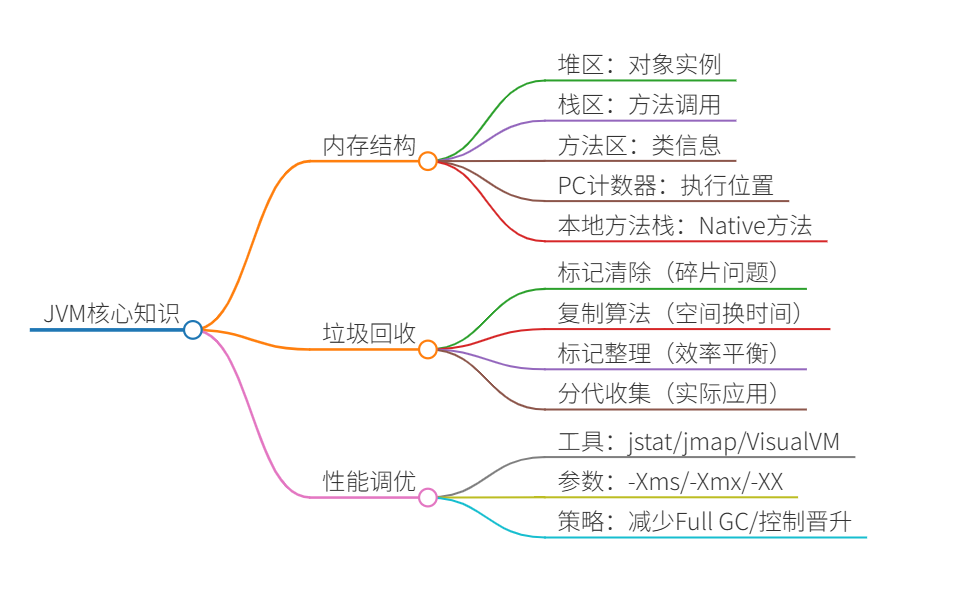
JVM详解(曼波脑图版)
(✪ω✪)ノ 好哒!曼波会用最可爱的比喻给小白同学讲解JVM,准备好开启奇妙旅程了吗?(๑˃̵ᴗ˂̵)و 📌 思维导图 ━━━━━━━━━━━━━━━━━━━ 🍎 JVM是什么?(苹果式比…...

Prometheus thanos架构
Thanos 是一个用于扩展 Prometheus 的高可用性和长期存储的解决方案。它通过整合多个 Prometheus 实例,提供了全局查询、长期存储、以及高可用性的能力。Thanos 的架构主要由以下几个核心组件组成: 1. Sidecar 功能: Sidecar 是与每个 Prom…...
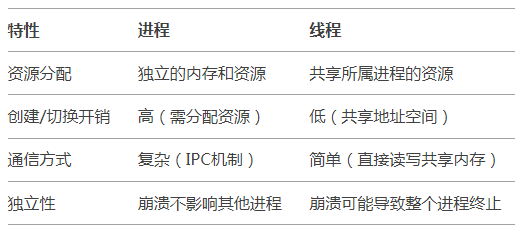
进程(Process)和进程管理
李升伟 整理 进程和进程管理是操作系统的核心概念之一,涉及计算机资源的分配、调度和执行控制。以下是详细的解释: 1. 进程的定义 进程(Process)是正在执行的程序实例,是操作系统进行资源分配和调度的基本单位。它包…...
更强的视觉 AI!更智能的多模态助手!Qwen2.5-VL-32B-Instruct-AWQ 来袭
Qwen2.5-VL-32B-Instruct 是阿里巴巴通义千问团队于 2025 年 3 月 24 日开源的多模态大模型,基于 Apache 2.0 协议发布。该模型在 Qwen2.5-VL 系列的基础上,通过强化学习技术优化,以 32B 参数规模实现了多模态能力的突破。 核心特性升级&…...

Linux系统中的Perf总结
Linux系统中的Perf总结 Perf 是一个集成在 Linux 内核中的强大性能分析工具,在 Ubuntu 系统上尤为实用。它可以帮助用户监控和分析 CPU、内存、I/O 等性能指标。本文将一步步详解 Perf 在 Ubuntu 系统中的安装、使用方法及进阶技巧,带你从入门走向精通。…...

每日算法-250417
每日算法 - 20250417 记录今天的算法学习过程,包含三道 LeetCode 题目。 1005. K 次取反后最大化的数组和 题目 思路 贪心 解题过程 想要获得最大的数组和,我们的目标是尽可能地增大数组元素的总和。一种有效的贪心策略是:每次选择数组中绝…...
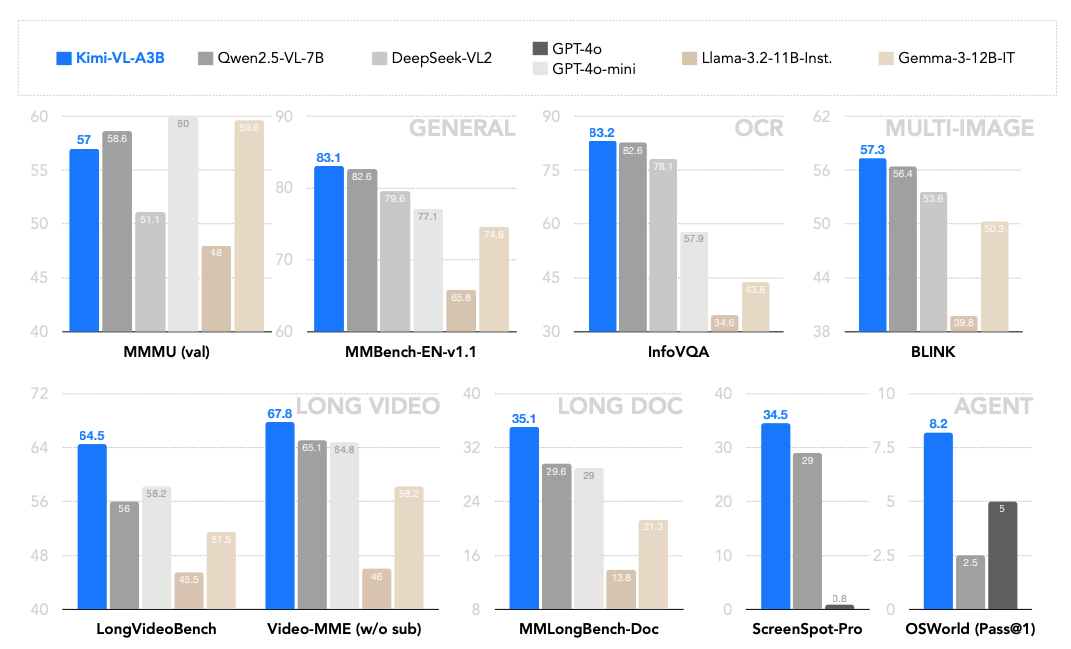
16.4B参数仅激活2.8B!Kimi-VL-A3B开源:长文本、多模态、低成本的AI全能选手
近日,月之暗面(Moonshot AI)开源了Kimi-VL系列模型,包含Kimi-VL-A3B-Instruct(指令调优版)和Kimi-VL-A3B-Thinking(推理增强版)。这两款模型以总参数16.4B、激活参数仅2.8B的轻量化设…...
山东大学软件学院创新项目实训开发日志(17)之中医知识历史问答历史对话查看功能完善
本次完善了历史对话的查看功能,可以让其正常显示标题 后端:在conversationDTO功能构造方法添加title 前端:在历时会话按钮添加标题title即可 前端效果展示,成功(^-^)V:...

关于Java集合中对象字段的不同排序实现方式
📊 关于Java集合中对象字段的不同排序实现方式 #Java集合 #排序算法 #Comparator #性能优化 一、排序基础:两种核心方式对比 方式Comparable接口Comparator接口实现位置目标类内部实现独立类或匿名内部类排序逻辑自然排序(固定规则…...
ZKmall开源商城静态资源管理:Nginx 配置与优化
ZKmall开源商城作为电商平台,其商品图片、前端资源等静态内容的高效管理与分发直接影响用户体验和系统性能。基于Nginx的静态资源管理方案,结合动静分离、缓存优化、安全加固、性能调优四大核心策略,可显著提升平台响应速度与稳定性。以下是具…...