大语言模型(LLMs)中的强化学习(Reinforcement Learning, RL)
第一部分:强化学习基础回顾
在深入探讨LLMs中的强化学习之前,我们先快速回顾一下强化学习的核心概念,确保基础扎实。
1. 强化学习是什么?
强化学习是一种机器学习范式,目标是让智能体(Agent)通过与环境(Environment)交互来学习最优策略,以最大化长期累积的奖励(Reward)。与监督学习(有明确的输入-输出对)不同,强化学习中没有直接的标签,智能体需要通过**试错(Trial-and-Error)**来发现哪些行为是好的。
强化学习的核心要素:
- 状态(State, S S S):描述环境或智能体所处的状况。
- 动作(Action, A A A):智能体可以采取的行为。
- 奖励(Reward, R R R):环境对智能体动作的反馈,通常是一个标量。
- 策略(Policy, π \pi π):智能体根据状态选择动作的规则,形式可以是确定性的( π ( s ) = a \pi(s) = a π(s)=a)或随机的( π ( a ∣ s ) \pi(a|s) π(a∣s))。
- 价值函数(Value Function):衡量某个状态或状态-动作对的长期期望回报,例如状态价值函数 V ( s ) V(s) V(s) 或动作价值函数 Q ( s , a ) Q(s, a) Q(s,a)。
- 折扣因子(Discount Factor, γ \gamma γ):用于平衡短期和长期奖励, 0 ≤ γ ≤ 1 0 \leq \gamma \leq 1 0≤γ≤1。
强化学习的数学目标是找到一个最优策略 π ∗ \pi^* π∗,使得期望累积奖励最大化:
J ( π ) = E [ ∑ t = 0 ∞ γ t R t ∣ π ] J(\pi) = \mathbb{E} \left[ \sum_{t=0}^\infty \gamma^t R_t \mid \pi \right] J(π)=E[∑t=0∞γtRt∣π]
2. 强化学习的典型算法
强化学习算法可以分为以下几类:
- 基于价值(Value-Based):如Q-Learning、SARSA,目标是学习动作价值函数 Q ( s , a ) Q(s, a) Q(s,a),然后选择最大化 Q Q Q 的动作。
- 基于策略(Policy-Based):如REINFORCE,直接优化策略 π ( a ∣ s ) \pi(a|s) π(a∣s),通常通过策略梯度方法。
- 演员-评论家(Actor-Critic):结合价值和策略方法,演员(Actor)负责选择动作,评论家(Critic)评估动作的好坏。
- 基于模型(Model-Based):学习环境的动态模型(状态转移概率),然后规划最优策略。
在LLMs中,基于策略和演员-评论家方法更为常见,因为语言生成任务通常涉及高维、离散的动作空间(如生成单词或句子)。
第二部分:LLMs中的强化学习背景
1. 为什么LLMs需要强化学习?
大语言模型(如GPT系列、LLaMA、BERT等)通常通过**预训练(Pre-training)和微调(Fine-tuning)**来学习。预训练阶段使用大规模语料进行自监督学习(如预测下一个单词),而微调阶段通常基于监督学习来适应特定任务。然而,监督学习有以下局限:
- 数据限制:高质量的监督数据(如人工标注的对话)往往稀缺且昂贵。
- 目标不一致:LLMs的预训练目标(如最大化似然)与实际应用目标(如生成有用、符合人类偏好的回答)可能不完全对齐。
- 复杂奖励:许多任务的评估指标(如回答的流畅性、相关性、道德性)难以通过简单的损失函数建模。
强化学习可以弥补这些不足,因为:
- RL允许模型通过与环境(例如用户或评估函数)交互来优化复杂、非可微的目标。
- RL可以直接优化基于人类反馈的奖励信号,而无需大量标注数据。
- RL适合处理语言生成中的序列决策问题(生成一个单词会影响后续单词)。
2. LLMs中强化学习的典型应用
在LLMs中,强化学习主要用于以下场景:
- 基于人类反馈的强化学习(RLHF):通过人类偏好数据微调模型,使其生成更符合人类期望的回答(如ChatGPT、Grok)。
- 对话系统优化:提高对话的连贯性、上下文相关性和用户满意度。
- 文本生成质量提升:优化生成文本的流畅性、创造性或特定风格。
- 任务特定优化:例如,优化机器翻译的BLEU分数、总结的ROUGE分数等。
第三部分:LLMs中强化学习的详细机制
现在我们深入探讨LLMs中强化学习的核心技术,以**基于人类反馈的强化学习(RLHF)**为例,因为这是目前LLMs中最广泛使用的RL方法。
1. RLHF的整体流程
RLHF(Reinforcement Learning from Human Feedback)是将人类偏好融入LLMs微调的一种方法。其核心思想是:通过人类对模型输出的评分或比较,构建一个奖励模型(Reward Model),然后用强化学习优化LLMs以最大化该奖励。
RLHF的流程分为以下三个阶段:
阶段1:收集人类反馈数据
- 任务:让模型生成多个输出(如对话回答、文本摘要等),然后请人类评估者对这些输出进行评分或排序。
- 形式:
- 评分:人类给每个输出打分(如1到5分)。
- 成对比较:人类比较两个输出,指出哪个更好(更常见,因为排序比绝对评分更一致)。
- 输出:生成一个人类偏好数据集,例如:{(输入 x x x, 输出 y 1 y_1 y1, 输出 y 2 y_2 y2, 人类选择 y 1 > y 2 y_1 > y_2 y1>y2)}。
阶段2:训练奖励模型
- 目标:用人类反馈数据训练一个奖励模型 r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y),它能为任意输入 x x x 和输出 y y y 预测一个奖励分数,反映人类偏好。
- 方法:
- 奖励模型通常是一个神经网络(可以是独立的模型,也可以基于LLM微调)。
- 对于成对比较数据,常用的损失函数是Bradley-Terry模型,假设人类选择 y 1 > y 2 y_1 > y_2 y1>y2 的概率为:
P ( y 1 > y 2 ∣ x ) = exp ( r ϕ ( x , y 1 ) ) exp ( r ϕ ( x , y 1 ) ) + exp ( r ϕ ( x , y 2 ) ) P(y_1 > y_2 | x) = \frac{\exp(r_\phi(x, y_1))}{\exp(r_\phi(x, y_1)) + \exp(r_\phi(x, y_2))} P(y1>y2∣x)=exp(rϕ(x,y1))+exp(rϕ(x,y2))exp(rϕ(x,y1)) - 优化目标是最小化负对数似然:
L ( ϕ ) = − E ( x , y 1 , y 2 , y 1 > y 2 ) [ log σ ( r ϕ ( x , y 1 ) − r ϕ ( x , y 2 ) ) ] \mathcal{L}(\phi) = -\mathbb{E}_{(x, y_1, y_2, y_1 > y_2)} \left[ \log \sigma (r_\phi(x, y_1) - r_\phi(x, y_2)) \right] L(ϕ)=−E(x,y1,y2,y1>y2)[logσ(rϕ(x,y1)−rϕ(x,y2))]
其中 σ \sigma σ 是sigmoid函数。
- 输出:一个训练好的奖励模型 r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y),可以为任何生成输出提供奖励信号。
阶段3:用强化学习优化LLM
- 目标:利用奖励模型 r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y),通过强化学习优化LLM的策略 π θ ( y ∣ x ) \pi_\theta(y|x) πθ(y∣x),使其生成更高质量的输出。
- 环境设定:
- 状态:当前输入 x x x 和已生成的文本片段。
- 动作:生成下一个单词或token。
- 奖励:由奖励模型 r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y) 提供,通常在生成完整序列后计算。
- 算法:最常用的方法是近端策略优化(PPO, Proximal Policy Optimization),因为它在高维动作空间(如语言生成)中表现稳定。
- 优化目标:
- 最大化期望奖励:
J ( θ ) = E x ∼ D , y ∼ π θ [ r ϕ ( x , y ) ] J(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta} \left[ r_\phi(x, y) \right] J(θ)=Ex∼D,y∼πθ[rϕ(x,y)] - 为了防止模型偏离原始行为(例如生成不自然的文本),通常加入一个KL散度惩罚项,限制新策略 π θ \pi_\theta πθ 与初始策略 π ref \pi_{\text{ref}} πref(通常是监督微调后的模型)的差异:
J ( θ ) = E [ r ϕ ( x , y ) − β ⋅ KL ( π θ ( y ∣ x ) ∣ ∣ π ref ( y ∣ x ) ) ] J(\theta) = \mathbb{E} \left[ r_\phi(x, y) - \beta \cdot \text{KL}(\pi_\theta(y|x) || \pi_{\text{ref}}(y|x)) \right] J(θ)=E[rϕ(x,y)−β⋅KL(πθ(y∣x)∣∣πref(y∣x))]
其中 β \beta β 是惩罚系数。
- 最大化期望奖励:
- PPO的具体步骤:
- 采样:用当前策略 π θ \pi_\theta πθ 生成输出序列。
- 估计优势:用奖励模型计算奖励,并结合价值函数估计动作的优势(Advantage)。
- 更新策略:通过裁剪的损失函数(Clipped Objective)更新策略参数 θ \theta θ,避免更新幅度过大。
- 输出:一个优化后的LLM,生成结果更符合人类偏好。
2. PPO算法的细节
PPO是RLHF中最常用的强化学习算法,因为它简单、稳定且适合高维动作空间。以下是PPO的核心思想和技术细节:
- 策略梯度:PPO基于策略梯度方法,更新策略的参数 θ \theta θ 以最大化期望奖励。基本形式是:
∇ θ J ( θ ) = E [ ∇ θ log π θ ( a ∣ s ) ⋅ A ( s , a ) ] \nabla_\theta J(\theta) = \mathbb{E} \left[ \nabla_\theta \log \pi_\theta(a|s) \cdot A(s, a) \right] ∇θJ(θ)=E[∇θlogπθ(a∣s)⋅A(s,a)]
其中 A ( s , a ) A(s, a) A(s,a) 是优势函数,衡量动作 a a a 相对于平均水平的优劣。 - 裁剪目标:为了防止策略更新过于激进,PPO引入了裁剪的损失函数:
L CLIP ( θ ) = E [ min ( r t ( θ ) ⋅ A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) ⋅ A t ) ] L^{\text{CLIP}}(\theta) = \mathbb{E} \left[ \min \left( r_t(\theta) \cdot A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \cdot A_t \right) \right] LCLIP(θ)=E[min(rt(θ)⋅At,clip(rt(θ),1−ϵ,1+ϵ)⋅At)]
其中:- r t ( θ ) = π θ ( a t ∣ s t ) π old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\text{old}}(a_t|s_t)} rt(θ)=πold(at∣st)πθ(at∣st) 是新旧策略的概率比。
- ϵ \epsilon ϵ 是裁剪范围(通常为0.1~0.2)。
- 价值函数:PPO同时训练一个价值函数 V ψ ( s ) V_\psi(s) Vψ(s),用于估计状态的期望回报,损失函数为:
L VF ( ψ ) = E [ ( V ψ ( s t ) − R t ) 2 ] L^{\text{VF}}(\psi) = \mathbb{E} \left[ (V_\psi(s_t) - R_t)^2 \right] LVF(ψ)=E[(Vψ(st)−Rt)2]
其中 R t R_t Rt 是实际的折扣回报。
3. RLHF的挑战与解决方案
尽管RLHF非常强大,但也面临一些挑战:
- 奖励模型的不准确性:
- 问题:奖励模型可能过拟合人类反馈数据,或者无法泛化到未见过的输出。
- 解决方案:增加反馈数据的多样性;使用正则化技术;定期更新奖励模型。
- 策略退化:
- 问题:过度优化奖励可能导致模型生成不自然的文本(如过于冗长或重复)。
- 解决方案:引入KL散度惩罚;结合监督微调(SFT)作为初始化。
- 计算成本:
- 问题:RLHF需要大量计算资源,尤其是在PPO的采样和优化阶段。
- 解决方案:使用高效的实现(如DeepSpeed);探索更轻量级的RL算法(如DPO)。
- 奖励黑客(Reward Hacking):
- 问题:模型可能学会“欺骗”奖励模型,生成看似高分但实际上无意义的输出。
- 解决方案:设计更鲁棒的奖励函数;引入多样性约束。
第四部分:其他相关方法与前沿进展
除了RLHF,LLMs中还有一些与强化学习相关的方法和前沿进展,值得关注:
1. 直接偏好优化(DPO)
- 简介:DPO(Direct Preference Optimization)是一种替代RLHF的轻量级方法,直接利用人类偏好数据优化LLM,而无需显式训练奖励模型或运行强化学习。
- 原理:
- 将人类偏好建模为一个隐式奖励函数。
- 通过一个封闭形式的损失函数直接优化策略:
L DPO ( θ ) = − E ( x , y w , y l ) [ log σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) ) ] \mathcal{L}_{\text{DPO}}(\theta) = -\mathbb{E}_{(x, y_w, y_l)} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right) \right] LDPO(θ)=−E(x,yw,yl)[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
其中 y w y_w yw 是偏好的输出, y l y_l yl 是不偏好的输出。
- 优势:计算效率高;实现简单;效果接近RLHF。
- 局限:可能对复杂任务的优化能力不如RLHF。
2. 在线强化学习
- 简介:在线强化学习直接让LLM与真实用户交互,根据用户的实时反馈(如点赞、评论)更新模型。
- 挑战:需要高效的在线学习算法;用户反馈可能噪声较大。
- 应用:对话系统的动态优化;个性化推荐。
3. 多目标强化学习
- 简介:在LLMs中,优化目标往往是多维的(如流畅性、准确性、安全性)。多目标强化学习尝试平衡这些目标。
- 方法:
- 加权奖励:将多个奖励函数加权组合。
- Pareto优化:寻找满足多目标的折衷解。
- 应用:生成安全且有用的回答;优化多模态模型。
4. 自博弈与探索
- 简介:借鉴AlphaGo的思路,LLMs可以通过自博弈(Self-Play)或主动探索来提高性能。
- 方法:让模型与自身或其他模型交互,生成对抗样本或多样化输出,然后优化。
- 应用:提高模型的鲁棒性和创造性。
第五部分:学习建议与实践路径
1. 理论学习
- 书籍:
- 《Reinforcement Learning: An Introduction》(Sutton & Barto):强化学习经典教材,适合系统学习。
- 《Deep Reinforcement Learning Hands-On》(Maxim Lapan):结合代码讲解,适合实践导向。
- 论文:
- RLHF相关:
- “Learning to Summarize with Human Feedback”(Stiennon et al., 2020)
- “Fine-Tuning Language Models from Human Preferences”(Ziegler et al., 2019)
- “InstructGPT”(Ouyang et al., 2022)
- PPO:
- “Proximal Policy Optimization Algorithms”(Schulman et al., 2017)
- DPO:
- “Direct Preference Optimization: Your Language Model is Secretly a Reward Model”(Rafailov et al., 2023)
- RLHF相关:
- 课程:
- Coursera:DeepLearning.AI的“Reinforcement Learning Specialization”。
- Stanford CS234:Reinforcement Learning(YouTube上有公开课)。
- UC Berkeley CS285:Deep Reinforcement Learning。
2. 编程实践
- 工具与框架:
- PyTorch/TensorFlow:用于实现LLM和RL算法。
- Hugging Face Transformers:提供预训练LLM和微调工具。
- TRL(Transformer Reinforcement Learning):Hugging Face的一个库,专门用于RLHF和DPO。
- Gymnasium:强化学习环境库,适合练习基础RL算法。
- 项目建议:
- 基础项目:用PPO实现一个简单的对话优化任务(如优化生成文本的正面情感)。
- 进阶项目:实现一个小型RLHF流水线,包括:
- 用Hugging Face的模型生成输出。
- 模拟人类反馈(例如用规则生成偏好数据)。
- 训练奖励模型。
- 用TRL库实现PPO优化。
- 挑战项目:尝试复现DPO算法,比较其与RLHF的效果。
相关文章:
中的强化学习(Reinforcement Learning, RL))
大语言模型(LLMs)中的强化学习(Reinforcement Learning, RL)
第一部分:强化学习基础回顾 在深入探讨LLMs中的强化学习之前,我们先快速回顾一下强化学习的核心概念,确保基础扎实。 1. 强化学习是什么? 强化学习是一种机器学习范式,目标是让智能体(Agent)…...
2025最新版微软GraphRAG 2.0.0本地部署教程:基于Ollama快速构建知识图谱
一、前言 微软近期发布了知识图谱工具 GraphRAG 2.0.0,支持基于本地大模型(Ollama)快速构建知识图谱,显著提升了RAG(检索增强生成)的效果。本文手把手教你如何从零部署,并附踩坑记录和性能实测…...
)
泛型算法——只读算法(一)
在 C 标准库中,泛型算法的“只读算法”指那些 不会改变它们所操作的容器中的元素,仅用于访问或获取信息的算法,例如查找、计数、遍历等操作。 accumulate std::accumulate()是 C 标准库**numeric**头文件中提供的算法,用于对序列…...

Redis的常见数据类型
Redis 提供了多种数据类型,以满足不同的应用场景。以下是 Redis 的主要数据类型及其应用场景: 字符串(String): 描述:最基本的数据类型,存储单个键值对,值可以是字符串、整数或浮点数…...
层几种传参方式)
Mybatis中dao(mapper)层几种传参方式
一、SQL语句中接收参数的方式有两种: 1、 #{}预编译 (可防止sql注入) 2、${}非预编译(直接拼接sql,不能防止sql注入) #{}和${}的区别是什么? #{} 占位符,相当于?,sql预编译&…...

网络安全知识点2
1.虚拟专用网VPN:VPN用户在此虚拟网络中传输私网流量,在不改变网络现状的情况下实现安全,可靠的连接 2.VPN技术的基本原理是利用隧道技术,对传输报文进行封装,利用VPN骨干网建立专用数据传输通道,实现报文…...

libevent服务器附带qt界面开发(附带源码)
本章是入门章节,讲解如何实现一个附带界面的服务器,后续会完善与优化 使用qt编译libevent源码演示视频qt的一些知识 1.主要功能有登录界面 2.基于libevent实现的服务器的业务功能 使用qt编译libevent 下载这个,其他版本也可以 主要是github上…...
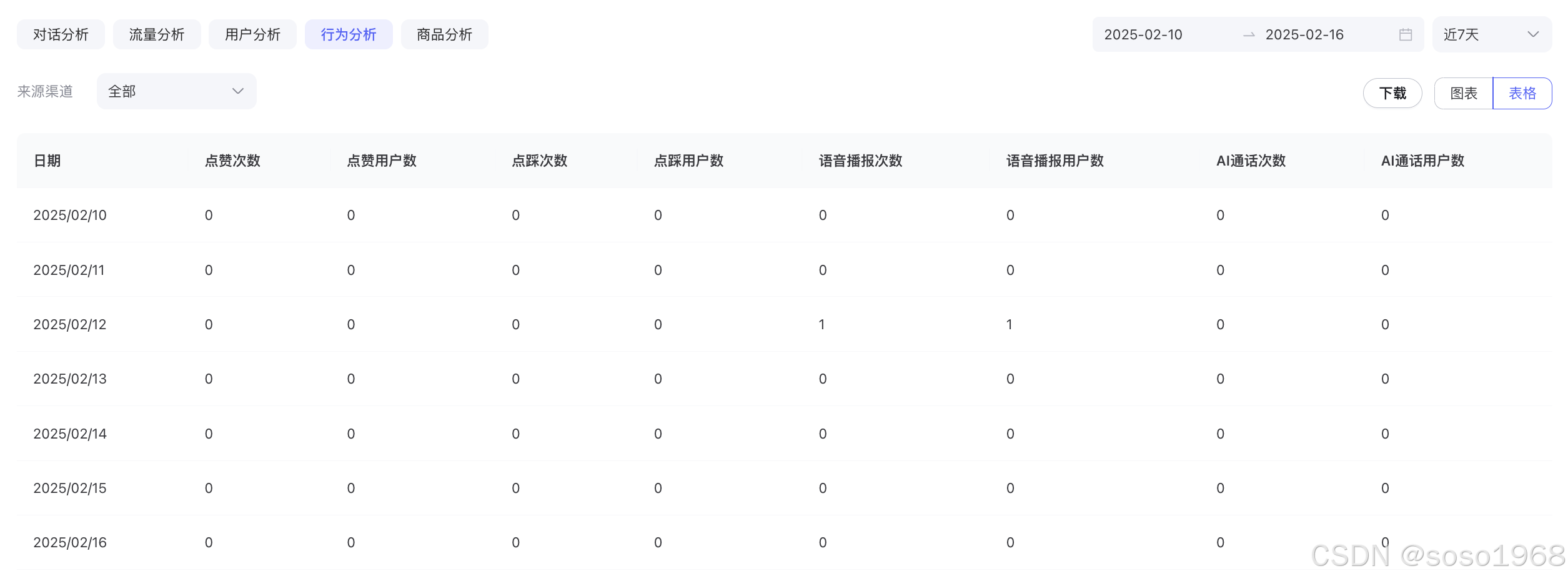
智能体数据分析
数据概览: 展示智能体的累计对话次数、累计对话用户数、对话满意度、累计曝光次数。数据分析: 统计对话分析、流量分析、用户分析、行为分析数据指标,帮助开发者完成精准的全面分析。 ps:数据T1更新,当日12点更新前一天…...
原理解析:容器背后的存储技术)
[特殊字符] UnionFS(联合文件系统)原理解析:容器背后的存储技术
🔍 UnionFS(联合文件系统)原理解析:容器背后的存储技术 💡 什么是 UnionFS? UnionFS(联合文件系统) 是一种可以将多个不同来源的文件系统“合并”在一起的技术。它的核心思想是&am…...
STM32(M4)入门: 概述、keil5安装与模板建立(价值 3w + 的嵌入式开发指南)
前言:本教程内容源自信盈达教培资料,价值3w,使用的是信盈达的405开发版,涵盖面很广,流程清晰,学完保证能从新手入门到小高手,软件方面可以无基础学习,硬件学习支持两种模式ÿ…...

采用若依vue 快速开发系统功能模块
文章目录 运行若依项目 科室管理科室查询-后端代码实现科室查询-前端代码实现科室名称状态搜索科室删除-后端代码实现科室删除-前端代码实现科室新增-后端代码实现科室新增-前端代码实现科室修改-后端代码实现前端代码实现角色权限实现 运行若依项目 运行redis 创建数据库 修改…...
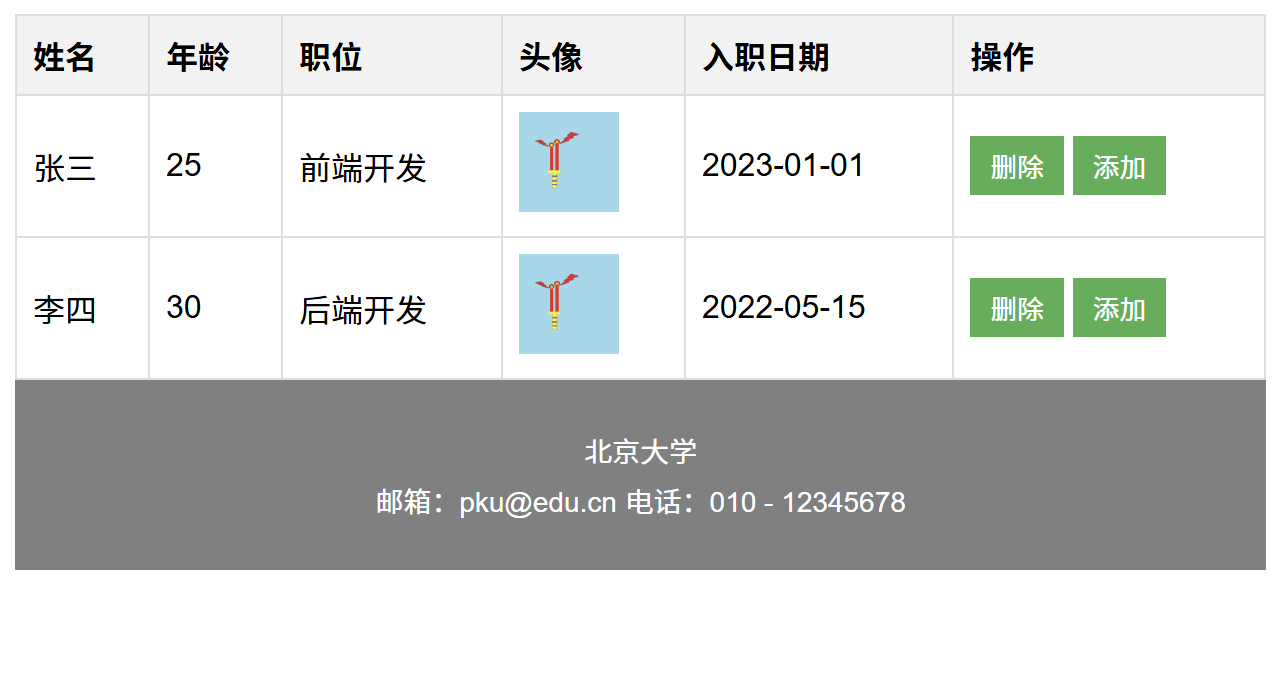
HTML:表格数据展示区
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>人员信息表</title><link rel"styl…...

WIN11运行游戏时出现“ms-gamingoverlay”弹框的问题
针对WIN11运行游戏时出现“ms-gamingoverlay”弹框的问题,以下是经过验证的多种解决方法,结合不同场景需求提供对应方案: 一、关闭系统内置的游戏录制功能 禁用Xbox Game Bar及游戏录制 • 进入系统设置(WinI)→ 左侧选…...
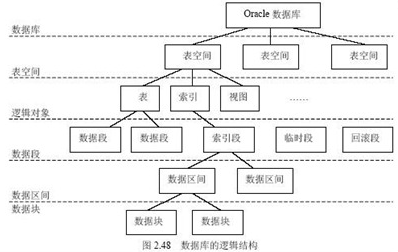
Oracle测试题目及笔记(单选)
所有题目来自于互联网搜索 当 Oracle 服务器启动时,下列哪种文件不是必须的(D)。 A.数据文件 B.控制文件 C.日志文件 D.归档日志文件 数据文件、日志文件-在数据库的打开阶段使用 控制文件-在数…...

Jmeter创建使用变量——能够递增递减的计数器
Jmeter创建使用变量——能够递增递减的计数器 如下图所示,创建一个 取值需限定为0 2 4这三个值内的变量。 Increment:每次迭代后 递增的值,给计数器增加的值 Maximum value:计数器的最大值,如果超过最大值࿰…...

【LeetCode基础算法】滑动窗口与双指针
定长滑动窗口 总结:入-更新-出。 入:下标为 i 的元素进入窗口,更新相关统计量。如果 i<k−1 则重复第一步。 更新:更新答案。一般是更新最大值/最小值。 出:下标为 i−k1 的元素离开窗口,更新相关统计量…...
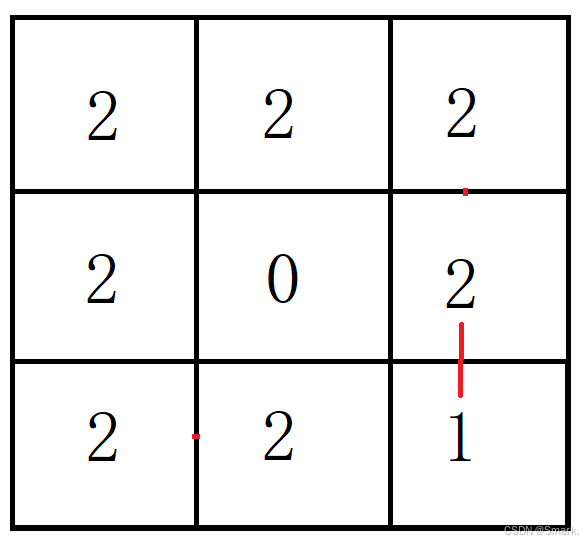
数据结构之BFS广度优先算法(腐烂的苹果)
队列这个数据结构在很多场景下都有使用,比如在实现二叉树的层序遍历,floodfill问题(等等未完成)中,都需要借助队列的先进先出特性,下面给出这几个问题的解法 经典的二叉树的层序遍历 算法图示,以下图所示的二叉树为例…...

道可云人工智能每日资讯|首届世界人工智能电影节在法国尼斯举行
道可云元宇宙每日简报(2025年4月15日)讯,今日元宇宙新鲜事有: 杭州《西湖区打造元宇宙产业高地的扶持意见》发布 杭州西湖区人民政府印发《西湖区打造元宇宙产业高地的扶持意见》。该意见已于4月4日正式施行,有效期至…...
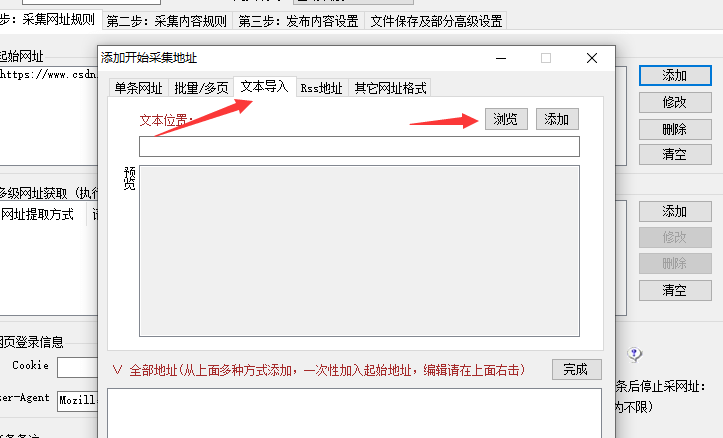
火车头采集动态加载Ajax数据(无分页瀑布流网站)
为了先填充好数据在上线,在本地搭建了一个网站,并用火车头采集数据填充到里面。 开始很上手,因为找的网站的分类中是有分页的。很快捷的找到页面标识。 但是问题来了,如今很多网站都是采用的Ajax加载数据,根本没有分…...

Android Jetpack是什么与原生android 有什么区别
Android Jetpack是什么 Android Jetpack是Google推出的一套开发组件工具集,旨在帮助开发者更高效地构建高质量的Android应用。它包含多个库和工具,被分为架构、用户界面、行为和基础四大类。以下是一些Android Jetpack的示例: 架构组件 ViewModel:用于以生命周期的方式管理…...
)
Android Retrofit 框架适配器模块深入源码分析(五)
Android Retrofit 框架适配器模块深入源码分析 一、引言 在 Android 开发中,网络请求是一个常见且重要的功能。Retrofit 作为一个强大的网络请求框架,以其简洁的 API 和高度的可定制性受到了广泛的欢迎。适配器模块(CallAdapter)…...
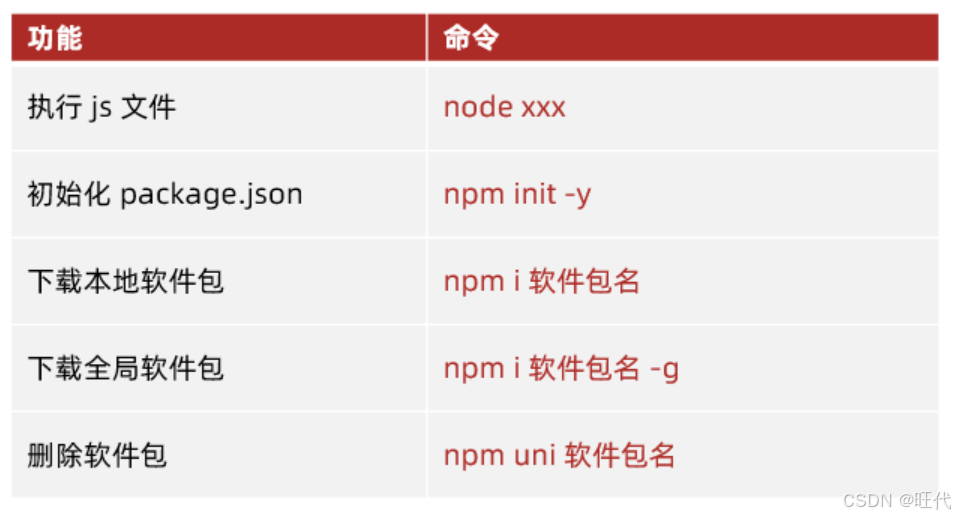
Node.js模块化与npm
目录 一、模块化简介 二、CommonJS 规范 1. 基本语法 2. 导出模块 3. 导入模块 三、ECMAScript 标准(ESM) 1. 启用 ESM 一、默认导出与导入 1. 基本语法 2. 默认导出(每个模块仅一个) 3. 默认导入 二、命名导出与导入…...

nginx中的代理缓存
1.缓存存放路径 对key取哈希值之后,设置cache内容,然后得到的哈希值的倒数第一位作为第一个子目录,倒数第三位和倒数第二位组成的字符串作为第二个子目录,如图。 proxy_cache_path /xxxx/ levels1:2 2.文件名哈希值...

【前端vue生成二维码和条形码——MQ】
前端vue生成二维码和条形码——MQ 前端vue生成二维码和条形码——MQ一、安装所需要的库1、安装qrcode2、安装jsbarcode 二、使用步骤1、二维码生成2、条形码生成 至此,大功告成! 前端vue生成二维码和条形码——MQ 一、安装所需要的库 1、安装qrcode 1…...
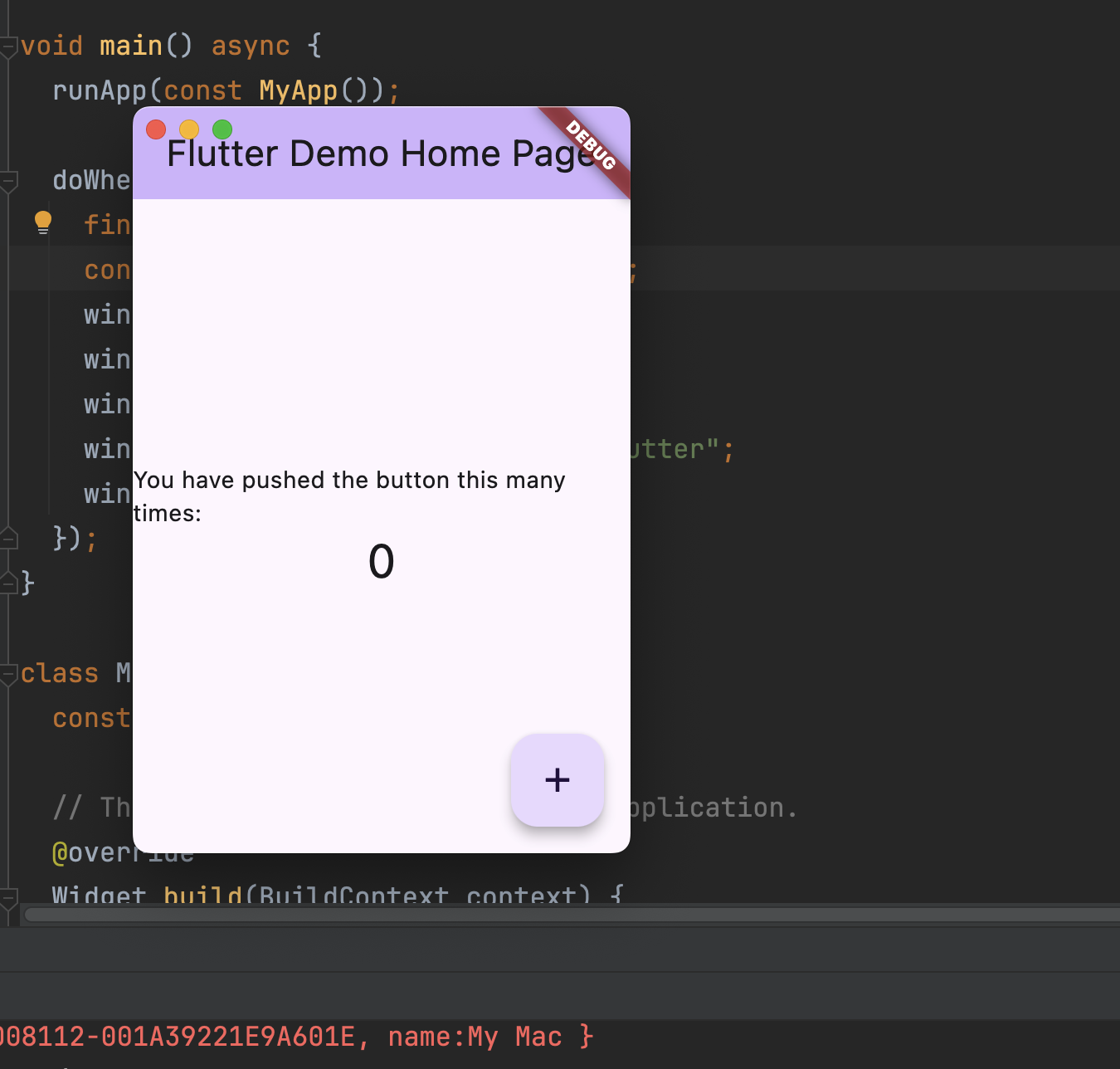
flutter 桌面应用之窗口自定义
在开发桌面软件的时候我们经常需要配置软件的窗口的大小以及位置 我们有两个框架选择:window_manager和bitsdojo_window 对比bitsdojo_window 特性bitsdojo_windowwindow_manager自定义标题栏✅ 支持❌ 不支持控制窗口行为(大小/位置)✅(基本…...

华为OD机试真题——MELON的难题(2025A卷:200分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 200分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C、C语言、GO六种语言的最佳实现方式! 2025华为OD真题目录全流程解析/备考攻略/经验分享 华为OD机试真题《MELON的…...

【C++】深入浅出之继承
目录 继承的概念及定义继承的定义继承方式和访问限定符protected与private的区别 默认继承方式继承类模板基类和派生类对象赋值兼容转换继承中的作⽤域(隐藏关系)相关面试题⭐ 派生类的默认成员函数⭐构造函数拷贝构造赋值重载析构函数 继承与友元继承与静态成员继承的方式菱形…...
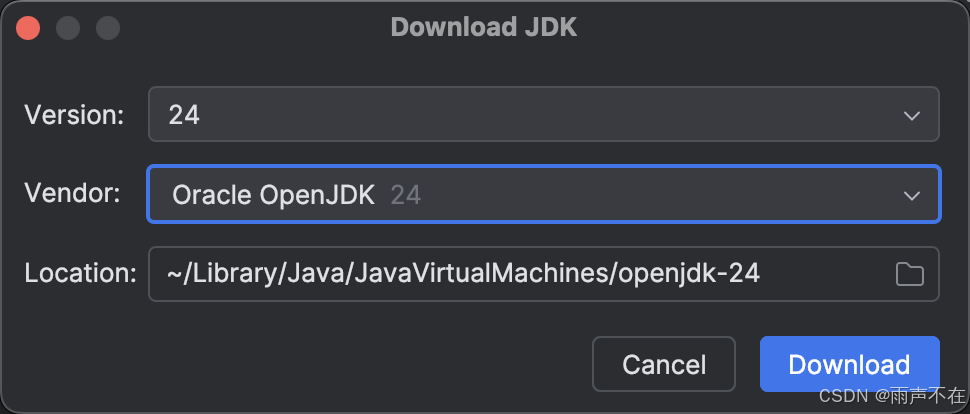
在 macOS 上切换默认 Java 版本
下载javasdk 打开android studio -> setting -> build.execution,dep -> build tools -> gradle -> Gradle JDK -> download JDK… 点击下载,就下载到了 ~/Library/Java/JavaVirtualMachines/ 安装 jenv brew install jenv将 jenv 集成到 Shell …...
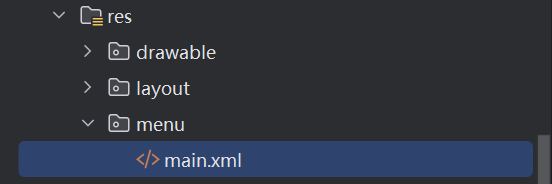
【安卓开发】【Android Studio】Menu(菜单栏)的使用及常见问题
一、菜单栏选项 在项目中添加顶部菜单栏的方法: 在res目录下新建menu文件夹,在该文件夹下新建用于菜单栏的xml文件: 举例说明菜单栏的写法,只添加一个选项元素: <?xml version"1.0" encoding"ut…...

2025.04.17【Stacked area】| 生信数据可视化:堆叠区域图深度解析
文章目录 生信数据可视化:堆叠区域图深度解析堆叠面积图简介为什么使用堆叠面积图如何使用R语言创建堆叠面积图安装和加载ggplot2包创建堆叠面积图的基本步骤示例代码 解读堆叠面积图堆叠面积图的局限性实际应用案例示例:基因表达量随时间变化 结论 生信…...