无约束最优化问题的求解算法--梯度下降法(Gradient Descent)
文章目录
- 梯度下降法
- 梯度下降法原理(通俗版)
- 梯度下降法公式
- 学习率的设置
- **如何选择学习率?**
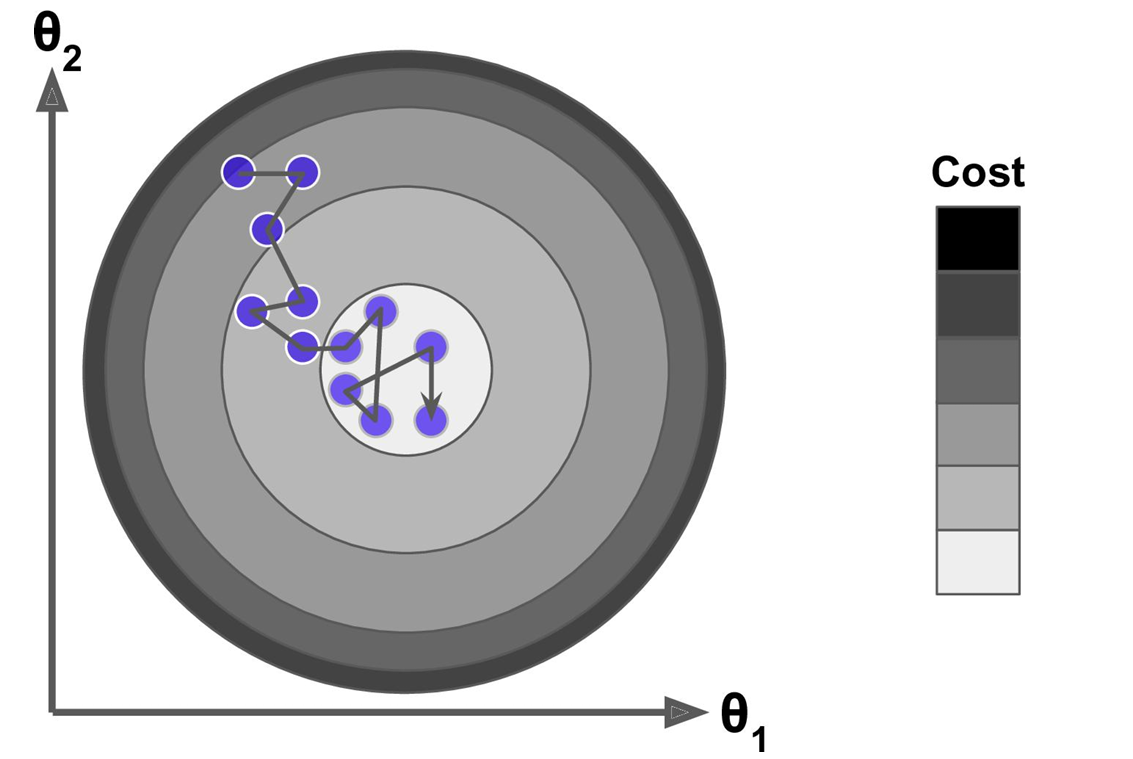
- 全局最优解
- 梯度下降法流程
- 损失函数的导函数
- 三种梯度下降法
- **梯度下降法核心步骤回顾**
- **优缺点详解**
- **1. 全量梯度下降 (Batch Gradient Descent, BGD)**
- **2. 随机梯度下降 (Stochastic Gradient Descent, SGD)**
- **3. 小批量梯度下降 (Mini-Batch Gradient Descent, MBGD)**
- **三种梯度下降的区别与对比**
- 如何选择?
- 梯度下降法的问题与挑战
梯度下降法
- 梯度下降法(Gradient Descent):是一个非常通用的优化算法帮助机器学习求解最优解。所有优化算法的目的都是期待以最快的速度求解模型参数θ,梯度下降就是一种经典常用的优化算法。
- 使用梯度下降法的原因:
- 如果机器学习的损失函数是非凸函数,使用解析解公式求解θ,设置梯度为0会得到很多极值,甚至可能是极大值。
- 解析解计算成本高 :当特征维度N较大时,解析解需要计算矩阵的逆(复杂度O(N³)),计算时间呈指数级增长。例如,特征数量从4增加到16,计算时间会从1秒暴增到64秒。
- 更适合高维和大规模数据:梯度下降法通过迭代逼近最优解,避免了直接求逆的计算瓶颈,尤其适合特征维度高或数据量大的场景(如深度学习)。
- 动态优化的优势:解析解需要一次性求解,而梯度下降可以逐步优化,灵活适应在线学习或超大规模数据的分批训练。
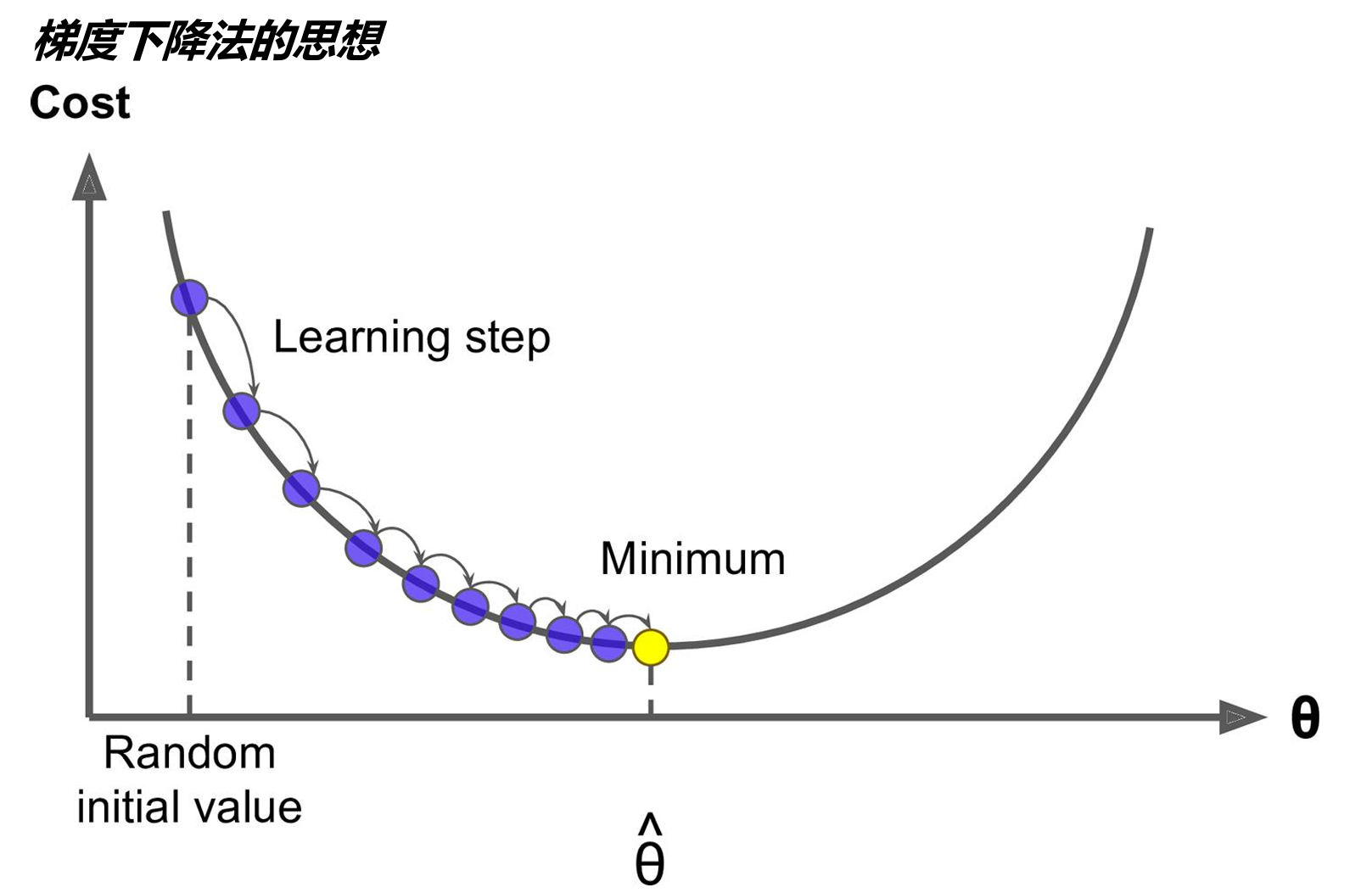
梯度下降法原理(通俗版)
- 初始化:随机猜一个起点:就像猜工资时先随便说个数,计算机一开始也会随机给参数θ(比如W₁, W₂…Wₙ)赋一组初始值。
- 计算误差(Loss):用当前的θ预测结果(ŷ),并计算预测值ŷ和真实值y的差距(比如用均方误差MSE)。 目标:让这个误差越小越好。
- 调整参数:根据反馈改进:如果误差变小了:说明调整方向正确,继续按这个方向微调θ;如果误差变大了:说明调反了,换个方向调整(比如增大改减小,或反之)。
- 重复直到最优:像“道士下山”一样,一步步试探,最终找到误差最低的θ(山谷最低点)。
- 核心思想**“猜-反馈-改进”循环**,通过不断试错逼近最优解,而不是直接计算复杂公式。
类比简化
- 猜工资游戏: 朋友说“高了/低了”,你逐步逼近正确答案。
- 梯度下降:计算机用“误差”反馈(如MSE)指导参数调整方向,直到最优。
梯度下降法公式
- 参数更新公式:
W j ( t + 1 ) = W j ( t ) − η ⋅ gradient j W_j^{(t+1)} = W_j^{(t)} - \eta \cdot \text{gradient}_j Wj(t+1)=Wj(t)−η⋅gradientj - 符号说明:
- W j ( t ) W_j^{(t)} Wj(t):第 t t t轮迭代时的参数 W j W_j Wj( θ \theta θ 中的一个分量)。
- η \eta η(或 α \alpha α):学习率(learning rate),控制每次调整的步长(类似“下山时的步幅”)。
- gradient j \text{gradient}_j gradientj:损失函数对 W j W_j Wj的梯度(即当前方向上的“最陡下降方向”)。
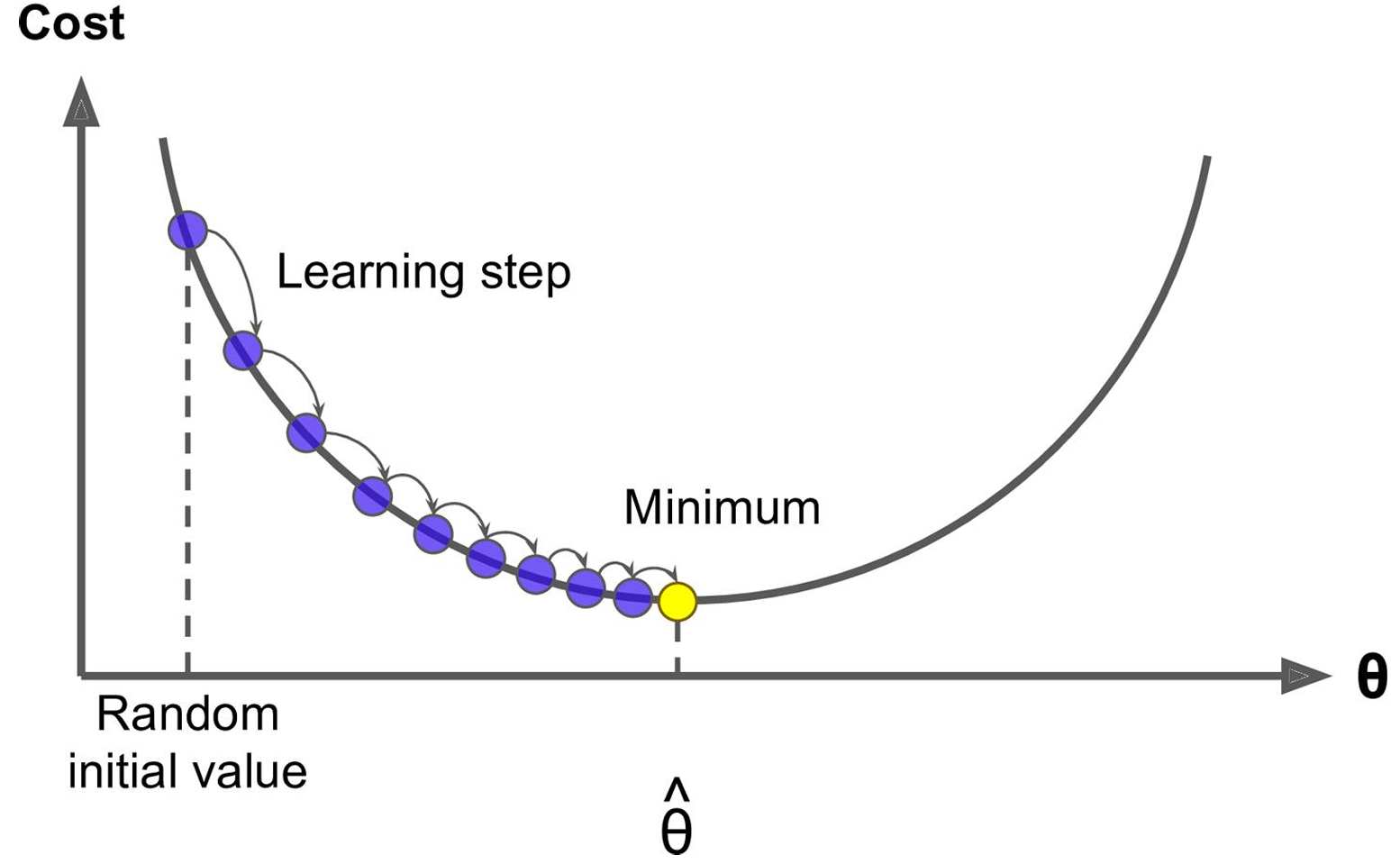
核心作用:
- 梯度(gradient) 告诉参数“往哪个方向调整能最快降低误差”。
- 学习率(η) 决定调整的幅度:
- η太大 → 可能“跨过”最优解(震荡甚至发散)。
- η太小 → 收敛慢(下山速度太慢)。
关键点:
- 梯度决定方向(往哪走),学习率决定步幅(走多远)。
- 所有参数 W j W_j Wj同时按各自梯度调整,直到收敛。
- 公式的直观意义:“沿着梯度方向,迈一小步,反复走,直到最低点。”
新参数 = 旧参数 − 步长 × 最陡方向 \text{新参数} = \text{旧参数} - \text{步长} \times \text{最陡方向} 新参数=旧参数−步长×最陡方向
学习率的设置
- 权重更新公式: W j t + 1 = W j t − η ⋅ gradient j W_{j}^{t+1} = W_{j}^{t} - \eta \cdot \text{gradient}_j Wjt+1=Wjt−η⋅gradientj
- W j t W_{j}^{t} Wjt:当前权重
- η \eta η(eta):学习率(控制每次调整的幅度)
- gradient j \text{gradient}_j gradientj:损失函数对权重的梯度
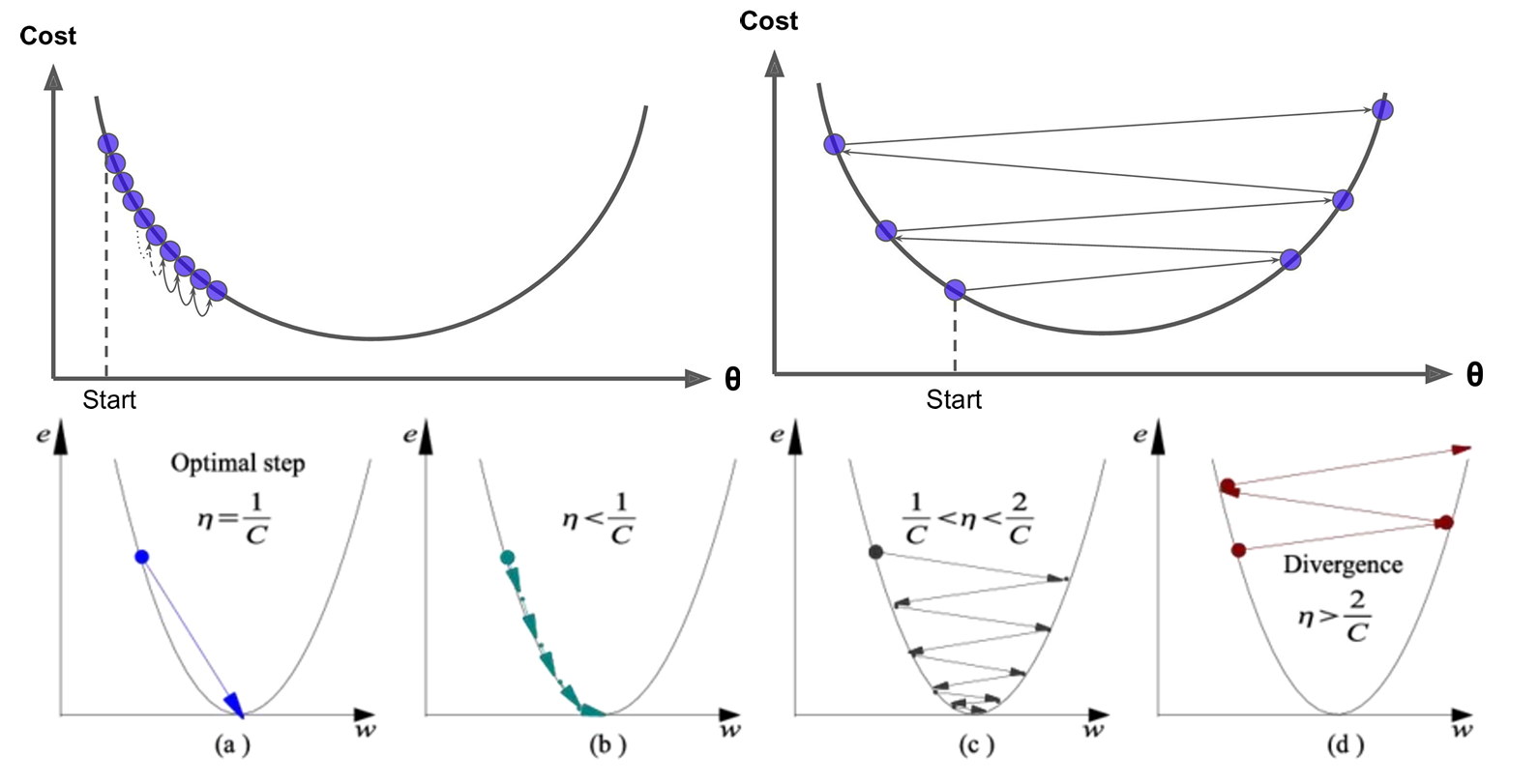
- 学习率的影响
- 学习率太大(如 η=1.0):调整幅度过大,容易“跨过”最优解,导致震荡甚至无法收敛。类似“步子太大,容易走过头,来回摇摆”。
- 学习率太小(如 η=0.0001):每次调整幅度过小,收敛速度极慢,训练时间大幅增加。类似“小碎步前进,要走很久才能到达目标”。
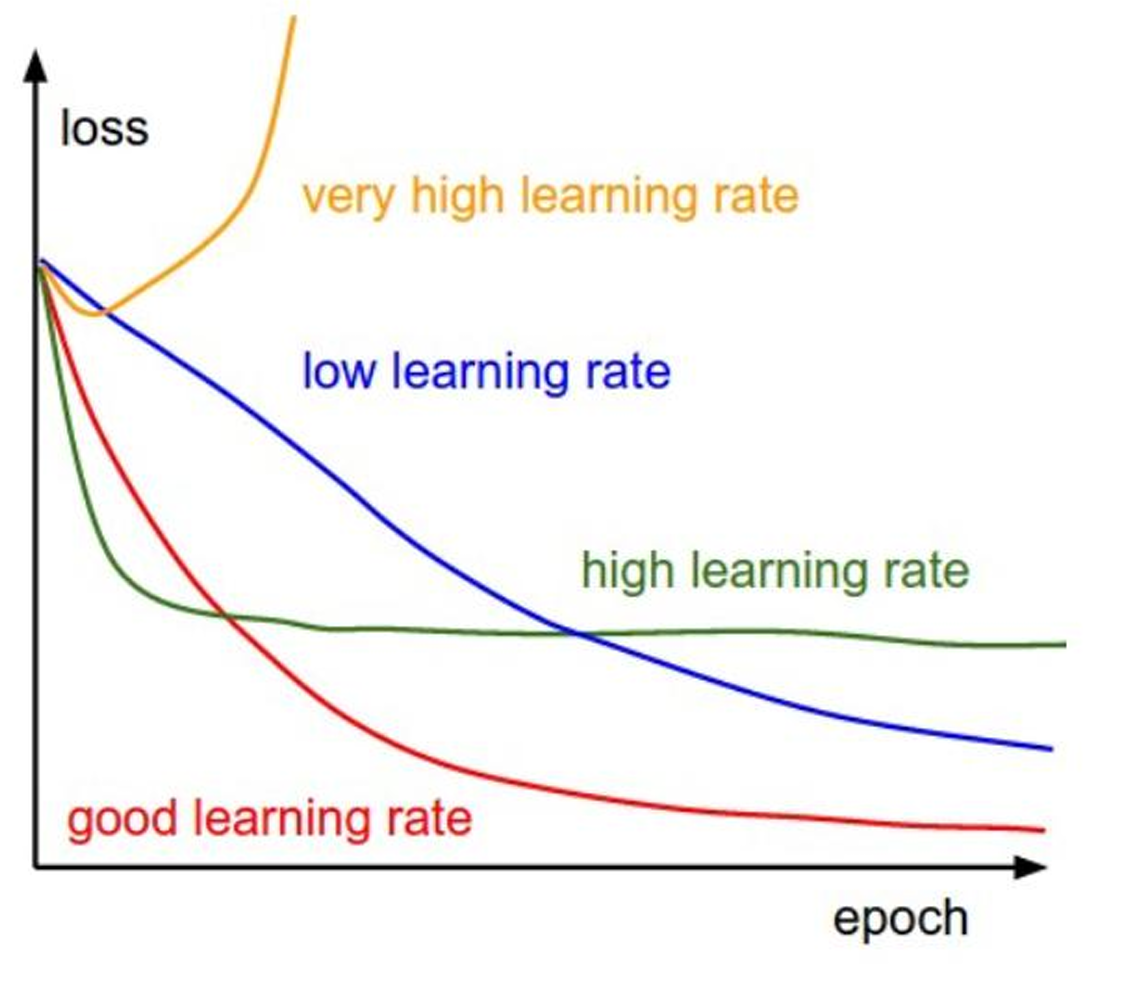
如何选择学习率?
✅ 常用初始值:0.1、0.01、0.001、0.0001(根据问题调整)
✅ 动态调整策略:
- 学习率衰减:随着训练进行,逐步减小 η(越接近最优解,步伐越小)。
- 自适应优化算法:如 Adam、RMSprop 等,自动调整学习率。
全局最优解
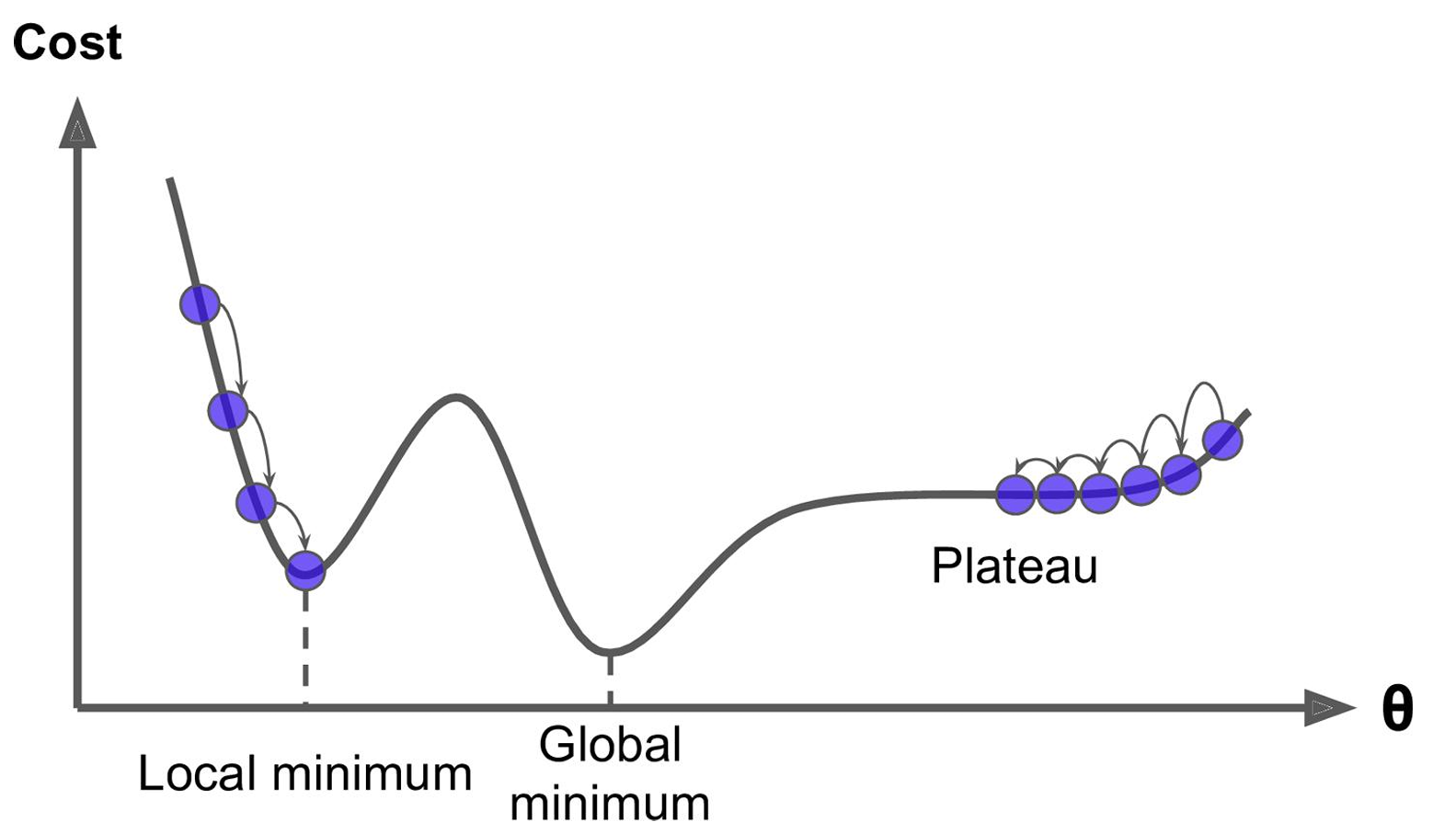
- 如果损失函数是非凸函数,梯度下降法是有可能落到局部最小值的,所以其实步长不能设置的太小太稳健,那样就很容易落入局部最优解,虽说局部最小值也没大问题,因为模型只要是堪用的就好嘛,但是我们肯定还是尽量要奔着全局最优解去。
梯度下降法流程
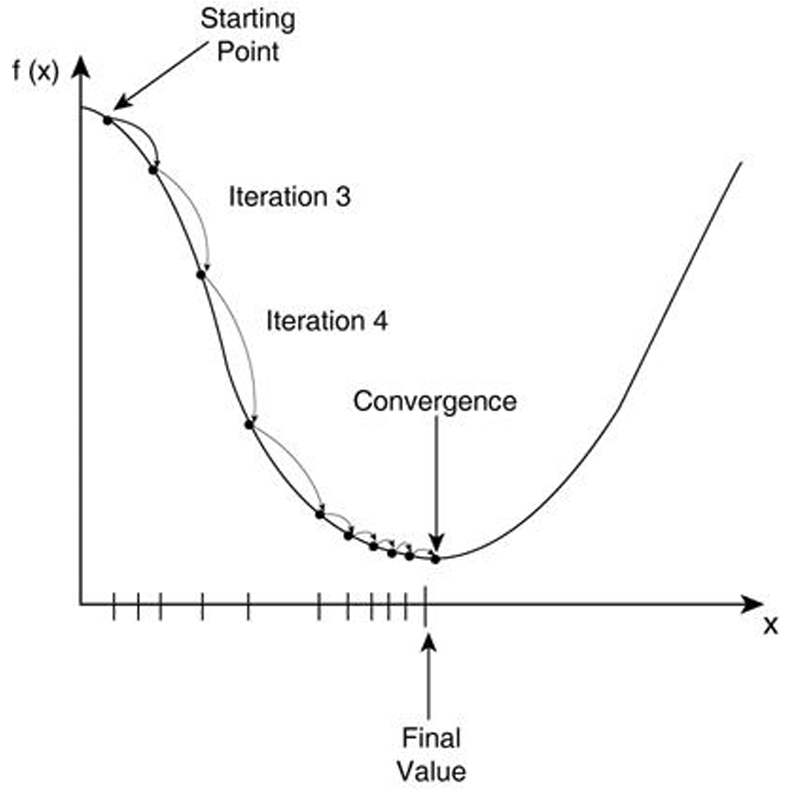
- 梯度下降法就像一个人蒙着眼睛下山的过程,通过不断试探找到最低点。
- 以下是具体步骤:
- 随机初始化:先随便猜一组参数值(θ或W),就像随机站在山上的某个点。
- 实现方法:
np.random.rand()或np.random.randn()
- 实现方法:
- 计算梯度:计算当前位置的"坡度"(梯度)。梯度是损失函数在该点的斜率,指向最陡上升方向。
- 关键点:梯度指向上升方向,所以我们要往反方向走才能下降。
- 参数更新:
- 如果梯度(g)为负 → 需要增大θ
- 如果梯度(g)为正 → 需要减小θ
- 更新公式: θ n e w = θ o l d − η × g r a d i e n t θ_{new} = θ_{old} - η×gradient θnew=θold−η×gradient (η是学习率,控制步长)
- 判断收敛:
- 不能简单判断梯度=0(可能是局部最低或最高点)
- 更好的方法是观察损失值的变化:当损失值基本不再下降时停止
- 实际做法:设置阈值,当损失变化小于阈值时停止
- 关键问题
- 如何随机初始化?:使用随机函数生成初始参数值
- 如何计算梯度?:需要求损失函数对各个参数的偏导数(这是后续要详细讲解的部分)
- 如何调整参数?:按照公式:新参数 = 旧参数 - 学习率×梯度
- 如何判断收敛?:监测损失值的变化幅度,而不是梯度本身
损失函数的导函数
- 推导损失函数的导函数
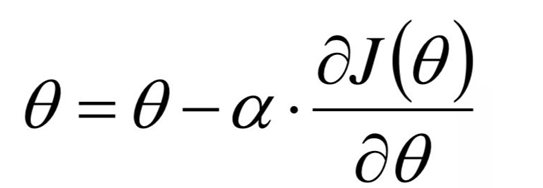
- J ( θ ) J(θ) J(θ)是损失函数
- θ j θ_j θj是某个特征维度 X j X_j Xj对应的权值系数
- 损失函数是MSE,MSE中x、y是已知的,θ是未知的,而θ不是一个变量而是一堆变量。所以我们只能对含有一推变量的函数MSE中的一个变量求导,即偏导,下面就是对 θ j θ_j θj求偏
导。
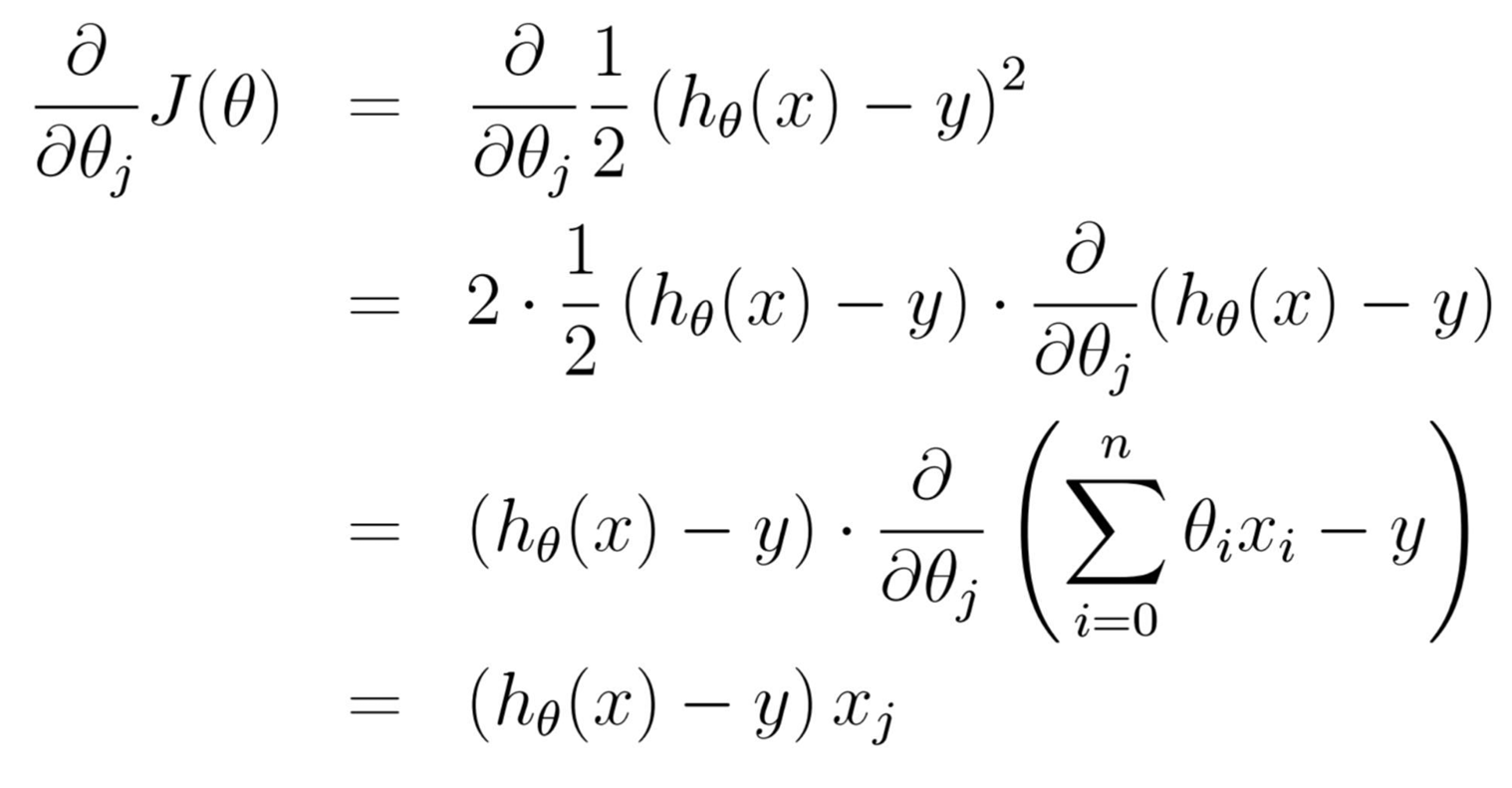

三种梯度下降法
梯度下降法核心步骤回顾
- 初始化参数:随机生成初始参数(θ/W)。
- 计算梯度:求损失函数对参数的偏导(梯度),确定下降方向。
- 更新参数:沿梯度反方向调整参数(学习率η控制步长)。
- 判断收敛:通过损失变化或梯度接近零终止迭代。
优缺点详解
1. 全量梯度下降 (Batch Gradient Descent, BGD)

- 公式:
θ j t + 1 = θ j t − η ⋅ 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_{j}^{t+1} = \theta_{j}^{t} - \eta \cdot \frac{1}{m} \sum_{i=1}^{m} \left( h_{\theta}(x^{(i)}) - y^{(i)} \right) x_{j}^{(i)} θjt+1=θjt−η⋅m1i=1∑m(hθ(x(i))−y(i))xj(i)
说明: - θ j t \theta_{j}^{t} θjt: 第 t t t 次迭代的参数 θ j \theta_j θj(第 j j j 维)。
- η \eta η: 学习率(步长)。
- m m m: 训练集总样本数。
- h θ ( x ( i ) ) h_{\theta}(x^{(i)}) hθ(x(i)): 模型对样本 x ( i ) x^{(i)} x(i)的预测值。
- 特点:每次迭代使用全部样本计算梯度,更新稳定但计算成本高。
- 优点:
- 梯度方向准确,收敛稳定(数学上保证凸函数的全局最优)。
- 易于并行化(因梯度计算依赖全数据集)。
- 缺点:
- 计算成本高(每次迭代需遍历全部数据)。
- 内存占用大,无法处理超出内存的数据集。
- 对非凸函数可能陷入局部最优。
2. 随机梯度下降 (Stochastic Gradient Descent, SGD)
公式:
θ j t + 1 = θ j t − η ⋅ ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_{j}^{t+1} = \theta_{j}^{t} - \eta \cdot \left( h_{\theta}(x^{(i)}) - y^{(i)} \right) x_{j}^{(i)} θjt+1=θjt−η⋅(hθ(x(i))−y(i))xj(i)
说明:
- i i i: 随机选取的单个样本索引( i ∼ Uniform ( 1 , m ) i \sim \text{Uniform}(1, m) i∼Uniform(1,m))。
- 特点:每次迭代仅用一个样本更新参数,计算快但噪声大。
- 优点:
- 计算速度快,适合大规模或流式数据。
- 随机性可能逃离局部最优(非凸优化中表现更好)。
- 缺点:
- 梯度估计噪声大,收敛不稳定(需精细调节学习率)。
- 难以并行化(因更新依赖单个样本)。
3. 小批量梯度下降 (Mini-Batch Gradient Descent, MBGD)
公式:
θ j t + 1 = θ j t − η ⋅ 1 b ∑ i = k k + b − 1 ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta_{j}^{t+1} = \theta_{j}^{t} - \eta \cdot \frac{1}{b} \sum_{i=k}^{k+b-1} \left( h_{\theta}(x^{(i)}) - y^{(i)} \right) x_{j}^{(i)} θjt+1=θjt−η⋅b1i=k∑k+b−1(hθ(x(i))−y(i))xj(i)
说明:
- b b b: 小批量大小(通常 b ∈ [ 32 , 256 ] b \in [32, 256] b∈[32,256])。
- k k k: 当前批次的起始样本索引。
- 特点:折中方案,平衡计算效率和稳定性。
- 优点:
- 平衡BGD的稳定性和SGD的速度(主流深度学习选择)。
- 可利用GPU并行计算小批量数据。
- 缺点:
- 需手动调节批量大小(k)和学习率。
- 仍存在一定噪声(但比SGD小)。
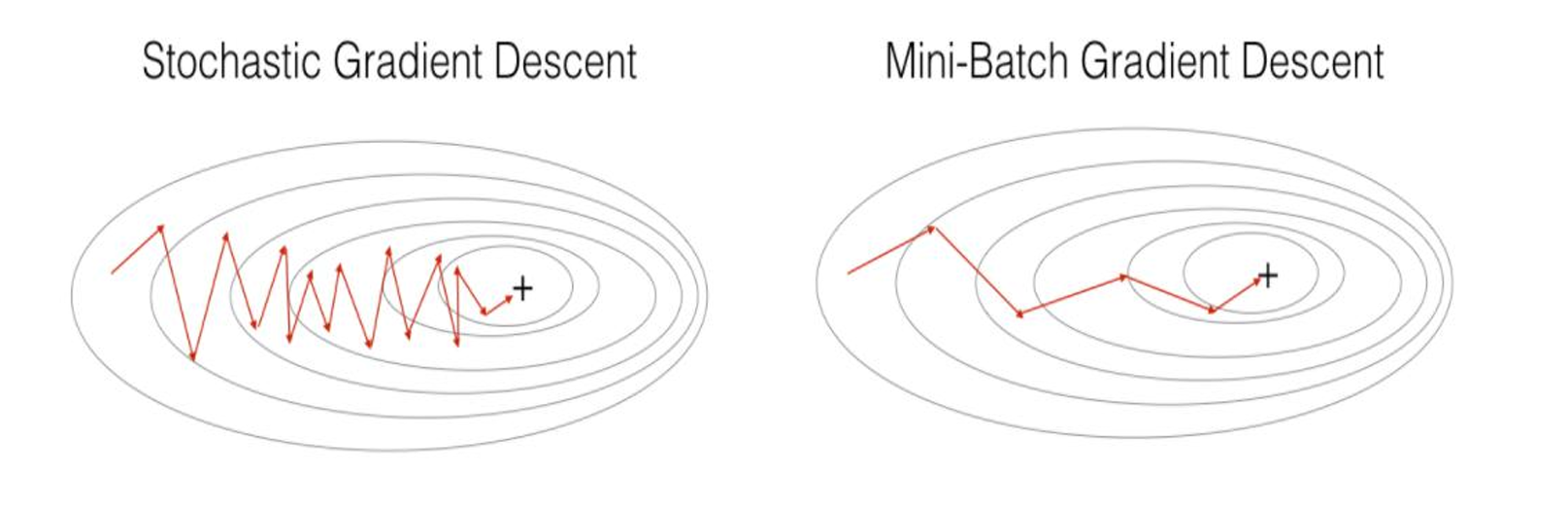
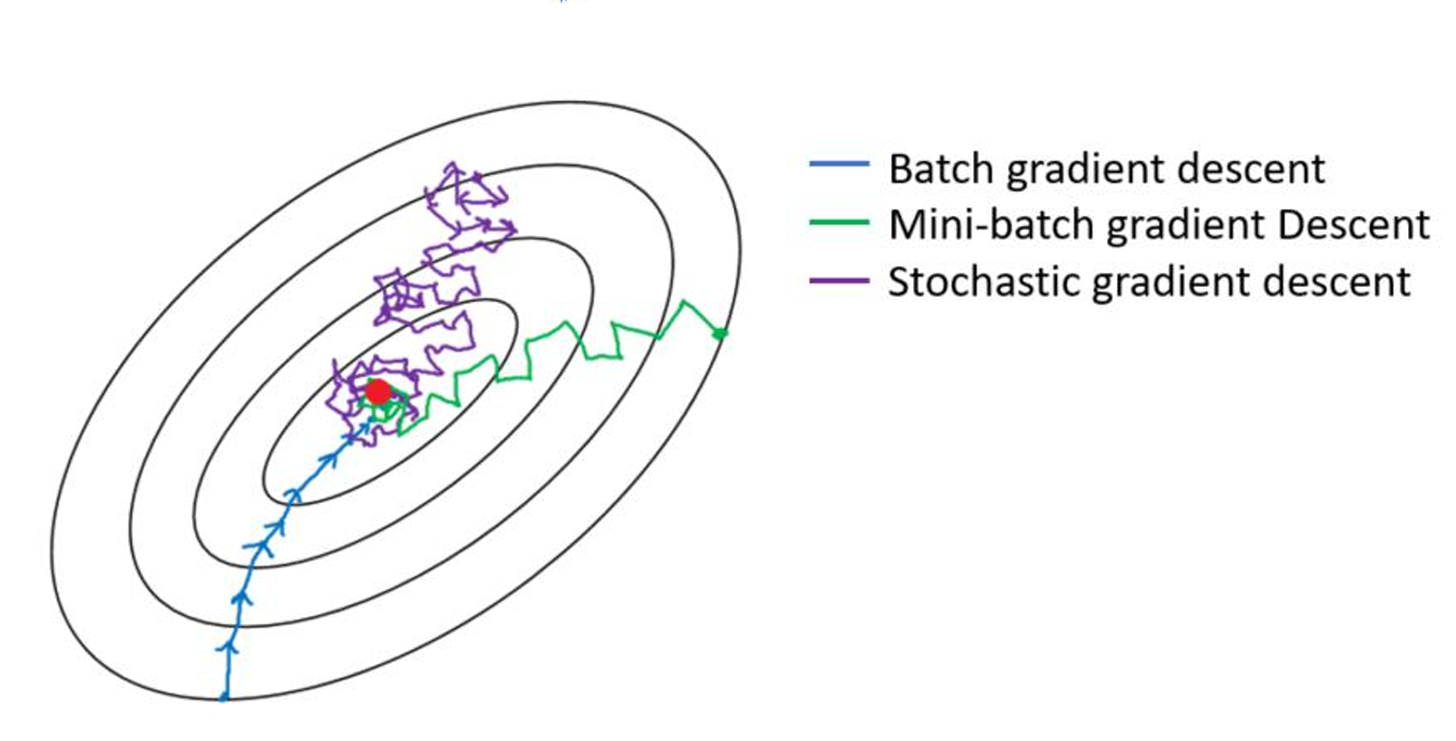
收敛路径:
BGD → 平滑但慢
SGD → 快速但震荡
MBGD → 折中方案
三种梯度下降的区别与对比
| 类型 | 全量(批量)梯度下降 (BGD) | 随机梯度下降 (SGD) | 小批量梯度下降 (MBGD) |
|---|---|---|---|
| 每次迭代的样本量 | 全部样本(N) | 单个样本(1) | 小批量样本(k,通常32-256) |
| 梯度计算方式 | 真实梯度(全局平均) | 噪声梯度(单个样本的估计) | 近似梯度(局部平均) |
| 参数更新频率 | 每轮迭代1次更新 | 每样本1次更新 | 每k个样本1次更新 |
| 收敛性 | 稳定,但可能陷入局部最优 | 不稳定,震荡大 | 平衡稳定性和随机性 |
| 计算效率 | 慢(尤其大数据集) | 快(适合在线学习) | 适中(GPU并行优化友好) |
| 内存需求 | 高(需加载全部数据) | 低 | 中 |
| 适用场景 | 凸函数、小数据集 | 非凸优化、大规模数据 | 深度学习等大多数场景 |
如何选择?
- 数据量小 → BGD(确保精度)。
- 数据量大/在线学习 → SGD(牺牲稳定性换速度)。
- 深度学习/默认推荐 → MBGD(批量大小常选32/64/128)。
梯度下降法的问题与挑战
相关文章:
无约束最优化问题的求解算法--梯度下降法(Gradient Descent)
文章目录 梯度下降法梯度下降法原理(通俗版)梯度下降法公式学习率的设置**如何选择学习率?** 全局最优解梯度下降法流程损失函数的导函数三种梯度下降法**梯度下降法核心步骤回顾****优缺点详解****1. 全量梯度下降 (Batch Gradient Descent,…...
Python全功能PDF工具箱GUI:支持转换、加密、旋转、图片提取、日志记录等多功能操作
使用Python打造一款集成 PDF转换、编辑、加密、解密、图片提取、日志追踪 等多个功能于一体的桌面工具应用(Tkinter ttkbootstrap PyPDF2 等库)。 ✨项目背景与开发动机 在日常办公或学习中,我们经常会遇到各种关于PDF文件的操作需求&#…...

[密码学实战]国密算法面试题解析及应用
以下是密码学领域常见的面试题及其详细解析,涵盖基础理论、算法实现与应用场景,帮助系统化备战技术面试 一、基础概念类 1. 密码学的主要目标是什么? 答案: 确保数据的机密性(加密防止窃听)、完整性(哈希校验防篡改)、认证性(数字签名验证身份)和不可否认性(签名防…...

React 受控表单绑定基础
React 中最常见的几个需求是: 渲染一组列表绑定点击事件表单数据与组件状态之间的绑定 受控表单绑定是理解表单交互的关键之一。 📍什么是受控组件? 在 React 中,所谓“受控组件”,指的是表单元素(如 &l…...
计算机视觉---相机标定
相机标定在机器人系统中的作用 1.确定相机的内部参数 相机的内部参数包括焦距、主点坐标、像素尺寸等。这些参数决定了相机成像的几何关系。通过标定,可以精确获取这些参数,从而将图像中的像素坐标与实际的物理坐标建立联系。例如,已知相机…...

LeetCode 443 压缩字符串
字符数组压缩算法详解:实现与分析 一、引言 在处理字符数组时,我们常常遇到需要对连续重复字符进行压缩的场景。这不仅可以节省存储空间,还能提升数据传输效率。本文将深入解析一个经典的字符数组压缩算法,通过详细的实现步骤和…...

datasheet数据手册-阅读方法
DataSheet Datasheet(数据手册):电子元器件或者芯片的数据手册,一般由厂家编写,格式一般为PDF,内容为电子分立元器件或者芯片的各项参数,电性参数,物理参数,甚至制造材料…...

AI绘制流程图,方法概述
1 deepseek 生成图片的mermaid格式代码,在kimi中进行绘图或在jupter notebook中绘制: 或在draw.io中进行绘制(mermaid代码) 2 svg是矢量图,可以插入到word """mermaid graph TDA[基线解算] --> B[北…...

ObjectOutputStream 深度解析
ObjectOutputStream 深度解析 ObjectOutputStream 是 Java IO 体系中的一个关键类,用于序列化(将对象转换为字节流),通常与 ObjectInputStream 配合使用,实现对象的持久化存储或网络传输。 1.作用:完成对象的序列化过程 2.它可以将JVM当中的Java对象序列化到文件中/网…...

git回滚指定版本并操作
你可以通过以下步骤切换到第三个版本。根据你的需求,有两种主要方法: 方法 1:临时查看第三个版本(不修改当前分支) 适用于仅查看或测试旧版本,不保留后续修改: 找到第三个版本的提交哈希&#…...

【AI插件开发】Notepad++ AI插件开发实践:支持配置界面
一、引用 此前的系列文章已基本完成了Notepad的AI插件的功能开发,但是此前使用的配置为JSON配置文件,不支持界面配置。 本章在此基础上集成支持配置界面,这样不需要手工修改配置文件,直接在界面上操作,方便快捷。 注…...

polkitd服务无法启动导致docker无法启动问题解决
问题docker服务无法启动,溯源发现是polkit服务没有正确运行 systemctl status polkit可以看到类似提示 Sep 18 02:58:24 server1 dbus[897]: [system] Failed to activate service org.freedesktop.PolicyKit1: timed out Sep 18 02:59:29 server1 systemd[1]: po…...

软件工程中数据一致性的探讨
软件工程中数据一致性的探讨 引言数据一致性:软件工程中的业务正确性与性能的权衡数据一致性为何重要业务正确性:事务的原子性与一致性ACID原则的基石分布式事务的挑战一致性级别:从强一致到最终一致 实践中的一致性权衡金融系统:…...
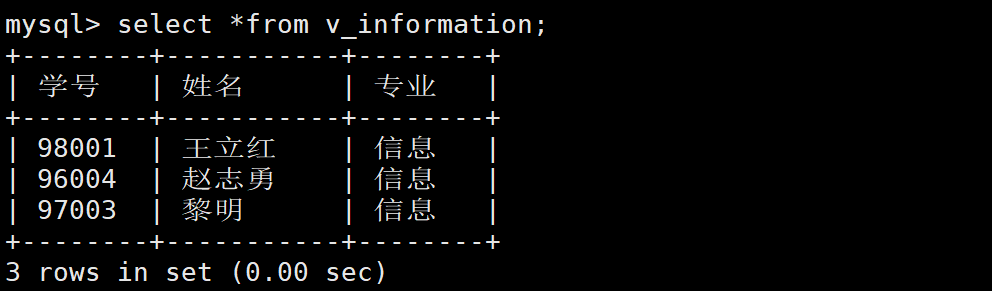
数据库原理及应用mysql版陈业斌实验四
🏝️专栏:Mysql_猫咪-9527的博客-CSDN博客 🌅主页:猫咪-9527-CSDN博客 “欲穷千里目,更上一层楼。会当凌绝顶,一览众山小。” 目录 实验四索引与视图 1.实验数据如下 student 表(学生表&…...

华为OD机试真题——最长的顺子(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C、C语言、GO六种语言的最佳实现方式! 本文收录于专栏:《2025华为OD真题目录全流程解析/备考攻略/经验…...

【HTML】html文件
HTML文件全解析:搭建网页的基石 在互联网的广袤世界里,每一个绚丽多彩、功能各异的网页背后,都离不开HTML文件的默默支撑。HTML,即超文本标记语言(HyperText Markup Language),作为网页创建的基…...

使用 XWPFDocument 生成表格时固定列宽度
一、XWPFDocument XWPFTable个性化属性 1.初始默认写法 XWPFTable table document.createTable(n, m); //在文档中创建一个n行m列的表格 table.setWidth("100%"); // 表格占页面100%宽度// 通过getRow获取行进行自定义设置 XWPFTableRow row table.getRow(0); XW…...
足球AI模型:一款用数据分析赛事的模型
2023 年欧冠决赛前,某体育数据平台的 AI 模型以 78% 的概率预测曼城夺冠 —— 最终瓜迪奥拉的球队首次捧起大耳朵杯。当足球遇上 AI,那些看似玄学的 "足球是圆的",正在被数据与算法拆解成可计算的概率命题。今天我们就来聊聊&#…...
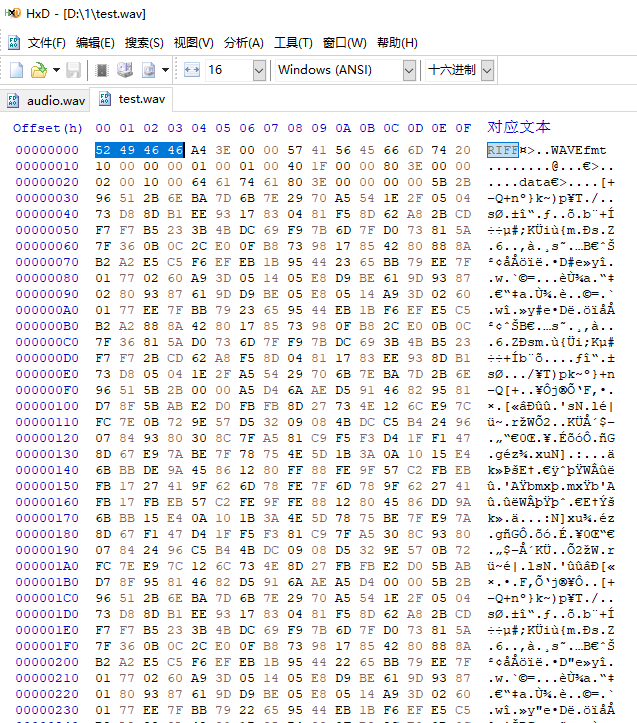
【ESP32|音频】一文读懂WAV音频文件格式【详解】
简介 最近在学习I2S音频相关内容,无可避免会涉及到关于音频格式的内容,所以刚开始接触的时候有点一头雾水,后面了解了下WAV相关内容,大致能够看懂wav音频格式是怎么样的了。本文主要为后面ESP32 I2S音频系列文章做铺垫࿰…...

万向死锁的发生
我是标题 1.欧拉角2.万向死锁 参考:小豆8593 1.欧拉角 欧拉角在Unity中描述的是一种变换(Transform)共有3个轴体,默认顺序为x->y->z. 2.万向死锁 可以把万向死锁的情况理解成:由于轴体旋转的顺序是固定的&am…...
 详解(18))
JavaScript学习教程,从入门到精通,JavaScript BOM (Browser Object Model) 详解(18)
JavaScript BOM (Browser Object Model) 详解 1. BOM 介绍 BOM (Browser Object Model) 是浏览器对象模型,它提供了独立于内容而与浏览器窗口进行交互的对象。BOM的核心对象是window,它表示浏览器的一个实例。 BOM包含的主要对象: window…...

人工智能与云计算:技术融合与实践
1. 引言 人工智能(AI)和云计算是当今科技领域最具变革性的两项技术。AI通过模拟人类智能解决问题,而云计算则提供了弹性可扩展的计算资源。两者的结合创造了前所未有的可能性,使企业能够以更低的成本部署复杂的AI解决方案。 本文将探讨AI与云计算的技术融合,包括核心概念、…...
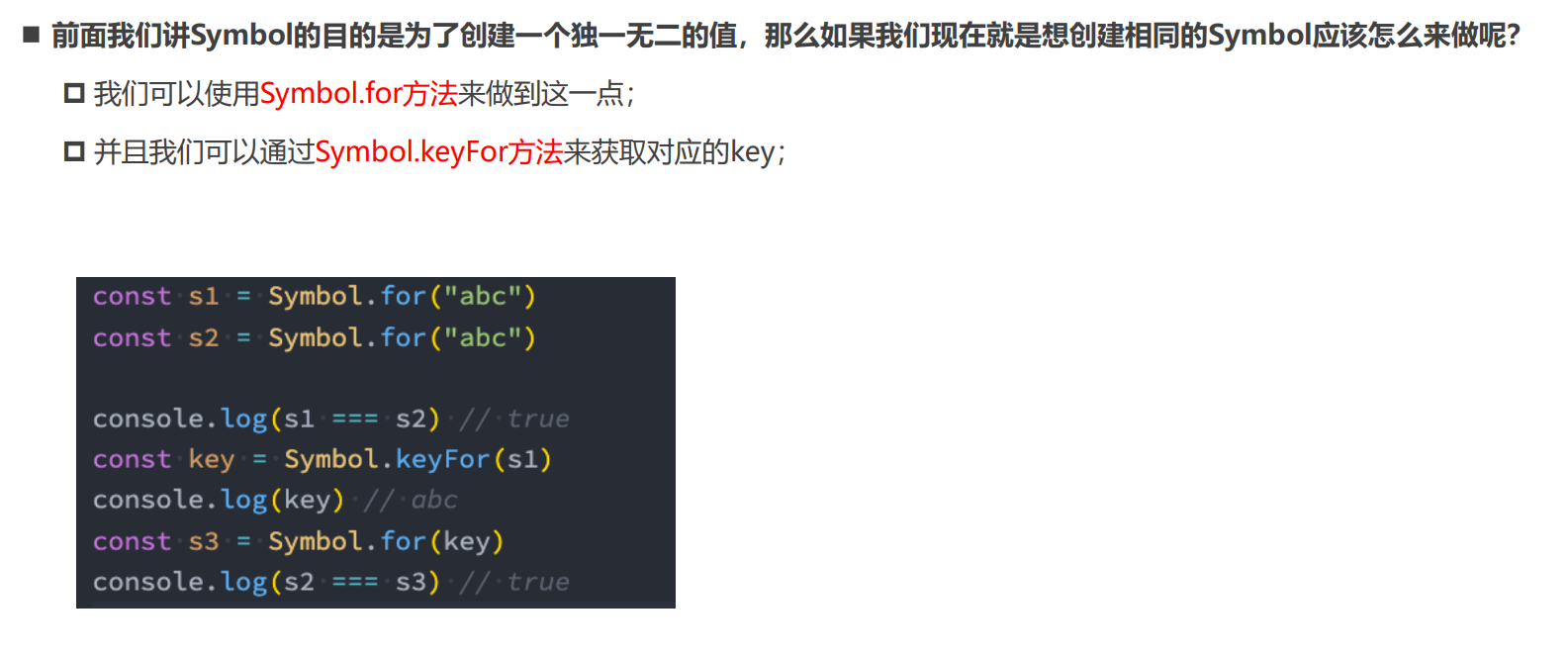
42.[前端开发-JavaScript高级]Day07-手写apply-call-bind-块级作用域
手写apply-call-bind <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"widthdevi…...

ObjectInputStream 终极解析与记忆指南
ObjectInputStream 终极解析与记忆指南 一、核心本质 ObjectInputStream 是 Java 提供的对象反序列化流,继承自 InputStream,用于读取由ObjectOutputStream序列化的Java对象。 核心特性速查表 特性说明继承链InputStream → ObjectInputStream核心功能实现Java对象反序列化…...
)
数据结构有哪些类型(对于数据结构的简述)
在学习计算机时,数据结构是不可忽视的一点,从考研时的408课程,再到工作中编写软件,网站,要想在计算机领域站住脚跟,数据结构是必备的 在这里,我对于数据结构进行了汇总,并简要描述&…...
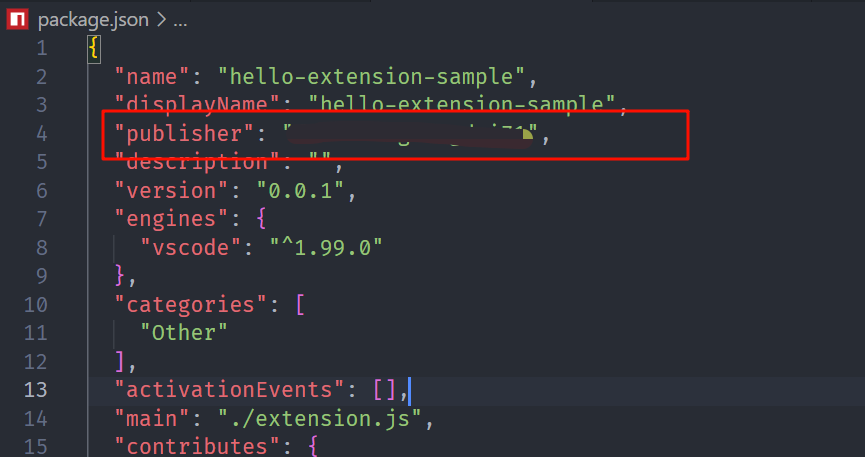
Vscode 插件开发
文章目录 1、使用vscode官方插件生成框架,下载脚手架2、使用脚手架初始化项目,这里我选择的是js3、生成的文件结构如下,重要的就是以下两个文件4、代码5、打包使用6、发布官网地址7、publisher ID undefined provided in the extension manif…...

C# string和其他引用类型的区别
在C#中,字符串(String)和其他引用类型(Reference Types)之间有几个关键的区别,这些区别主要体现在它们的内存管理、赋值行为以及使用方式上。 1. 内存管理 字符串(String)࿱…...
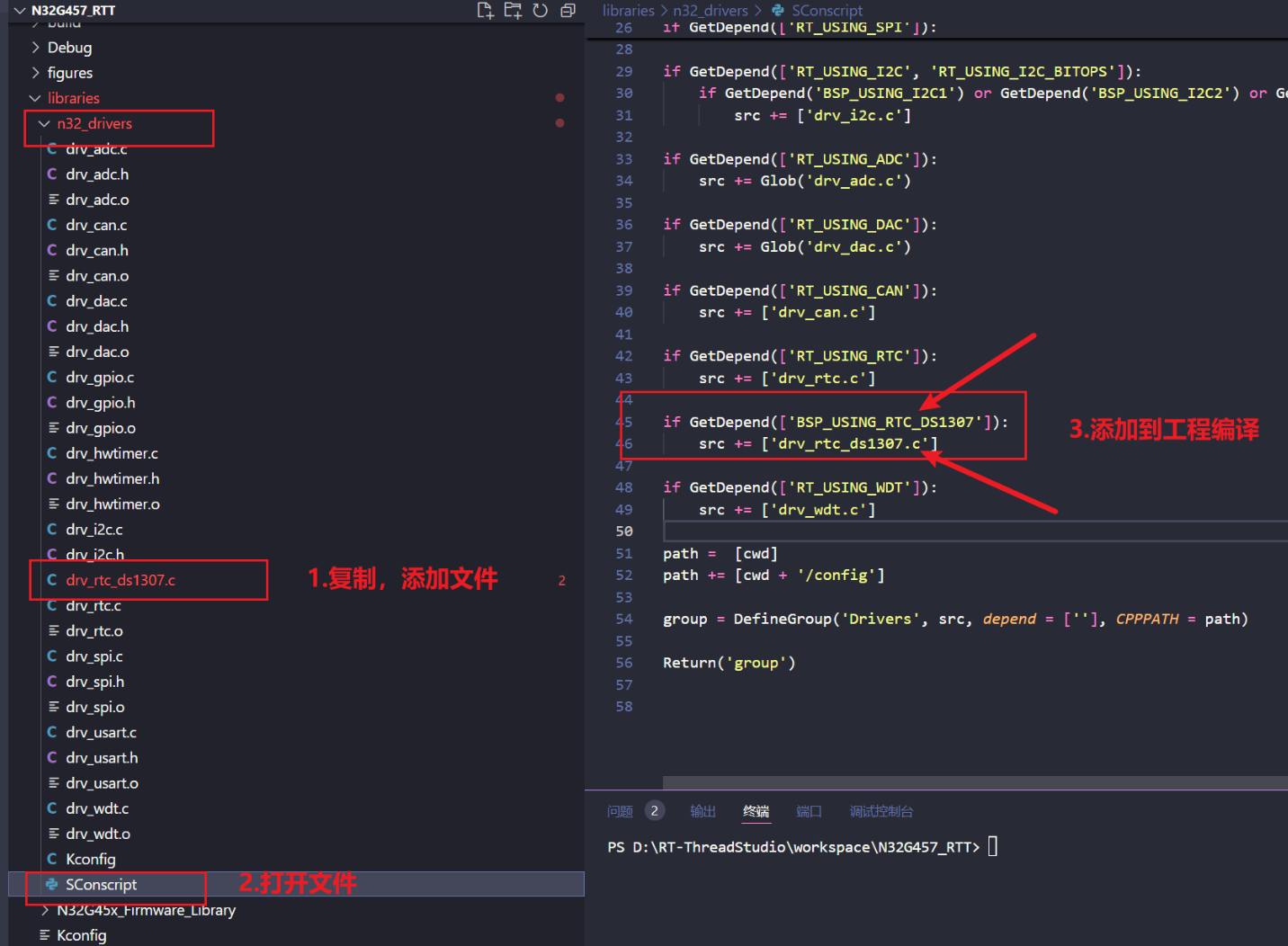
RTT添加一个RTC时钟驱动,以DS1307为例
添加一个外部时钟芯片 这里多了一个选项 复制drv_rtc.c,重命名为drv_rtc_ds1307.c 添加到工程中 /*** @file drv_rtc_ds1307.c* @brief * @author jiache (wanghuan3037@fiberhome.com)* @version 1.0* @date 2025-01-08* * @copyright Copyright (c) 2025 58* */ #...
常见的低代码策略整理
低代码策略通过简化开发流程、降低技术门槛、提升效率,帮助用户快速构建灵活可靠的应用。这些策略的核心优势体现在以下方面: 快速交付与降本增效 减少编码需求:通过可视化配置(如变量替换、表达式函数)替代传统编码…...

从彩色打印单行标准九九表学习〖代码情书〗的书写范式(Python/DeepSeek)
写给python终端的情书,学习代码设计/书写秘笈。 笔记模板由python脚本于2025-04-17 12:49:08创建,本篇笔记适合有python编程基础的coder翻阅。 【学习的细节是欢悦的历程】 博客的核心价值:在于输出思考与经验,而不仅仅是知识的简…...