利用大模型实现地理领域文档中英文自动化翻译

一、 背景描述
在跨国性企业日常经营过程中,经常会遇到专业性较强的文档翻译的需求,例如法律文书、商务合同、技术文档等;以往遇到此类场景,企业内部往往需要指派专人投入数小时甚至数天来整理和翻译,效率低下,严重影响了企业日常经营和生产。如何利用自动化工具来自动化批量处理专业文档翻译的工作,使员工更加专注于业务创新,成为摆在企业面前的重要课题。
随着机器学习和大语言模型等技术的飞速发展,专业文档翻译的自动化成为了可能。客户希望构建一个地理领域专业文档的翻译方案,使其通过大语言模型进行翻译,并且提出如下几点要求:
-
自动识别文档的语言种类,自动进行中翻英或者英翻中;
-
翻译后的文档尽可能地保留 Microsoft Office Word 文档中的格式;
-
尽可能地使用地理专业领域的术语,支持客户的术语表并可以用简单的方式扩展;
-
避免中式英语,符合英文的语序和表达习惯。
二、 方案概述
根据客户需求,我们进行了方案的概念模型设计:
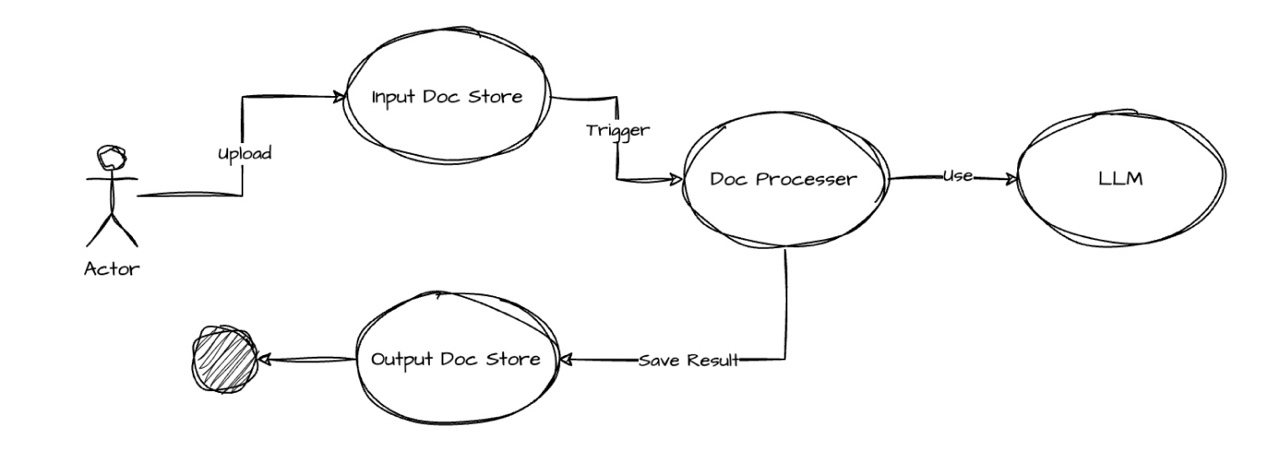
方案执行的流程如下:
-
用户上传中文/英文文档到“输入文档存储”;
-
上传完成的动作,触发文档翻译的处理作业,该作业会调用大语言模型;
-
翻译作业完成后,生成对应的英文/中文文档,结果保存到“输出文档存储”。
基于以上概念模型和流程设计,我们形成了如下的方案组件选型:
-
文档存储,包括原始输入文档存储和翻译后的输出文档存储,我们选用 Amazon S3,因为该服务支持事件通知,可以触发无服务器资源例如 Amazon Lambda 进行处理;
-
文档处理,也就是具体的文档翻译作业,我们选择使用 Lambda,并在代码中调用 Amazon Bedrock 上的大模型来实现;
-
日志记录,开启 Amazon CloudWatch Logs 记录 Lambda 执行过程,方便故障排查和代码调试。
方案部署架构设计如下:
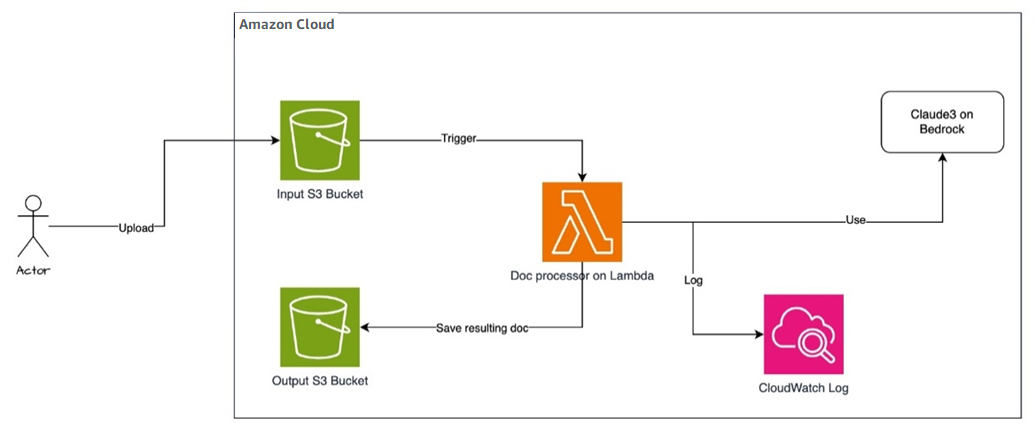
具体执行过程如下:
-
用户通过亚马逊云科技控制台上传原始文档到 Amazon S3 Input 存储桶;
-
S3 对象上传成功的通知,触发 Amazon Lambda 调用 Amazon Bedrock 上的大模型执行文档翻译;
-
Lambda 执行完成后,翻译后的文档自动保存到 S3 Output 存储桶;
用户可以在 Amazon CloudWatch Logs 中查看 Lambda 执行记录。
三、 核心代码实现
-
语种检测
本方案使用 Amazon Bedrock 上的大模型对用户上传的文档,实现了自动化识别其语种是英语还是中文,如果是中文自动翻译成英文,如果是英文则翻译成中文。以下是语种检测部分的代码:
def language_detector(query):print("debug")model_id = '<you-model-id>'print(<you-model-id>')response = bedrock.invoke_model(body=_get_complete_lang_detect_prompt(query), modelId=model_id)print('<< call <you-model-id>')response_body = json.loads(response.get('body').read())print(response_body)match = re.search(r'<lang>([\s\S]*?)</lang>', response_body['content'][0]['text'])print(f"response_body:{ response_body['content'][0]['text']}")if match:final_response = match.group(1)print(f"> in: {query}")print(f"> Language detected: {final_response}")return final_responseelse:# print(f"> in: {query}")print(f"< out: BR ERROR in language detect!!!")
另外,在调用 Amazon Bedrock 上的大模型时,需要按照其格式提供提示词模版,语种检测提示词模板部分的代码如下:def _get_complete_lang_detect_prompt(query, domain='None'):system_prompt = f"""You need to detect the language in the given text. If the text contains characters from different languages, then you should respond the major ONE language that is used. Your output will be processed by a program so no explaintaion is needed.NOTE: You are detecting the language in the given text, not the topic it is telling about.<text> + {query} + </text>The result should be in the tag of <lang></lang>. No explanation is needed. <lang>Respond only within these tags and do not provide any additional text outside the tags.</lang>. E.G. <lang>English</lang> or <lang>Chinese</lang>."""user_message = {"role": "user", "content": query}messages = [user_message]return json.dumps({"anthropic_version": "bedrock-2023-05-31","max_tokens": 80960,"system": system_prompt,"messages": messages})
-
文档翻译
本方案中文档翻译使用了 Amazon Bedrock 上的大模型,核心代码如下:
def agent_bedrock(query, to_language, domain="None"):model_id = <you-model-id>'response = bedrock.invoke_model(body=_get_complete_prompt(query, to_language, domain), modelId=model_id)response_body = json.loads(response.get('body').read())match = re.search(r'<TRANSLATED>([\s\S]*?)</TRANSLATED>', response_body['content'][0]['text'])if match:final_response = match.group(1)# print(f"> in: {query}")# print(f"< out: {final_response}")return final_responseelse:# print(f"> in: {query}")print(f"< out: BR ERROR!!!")return query
文档翻译对应的提示词如下:
def _get_complete_prompt(query, to_language='English', domain='None'):system_prompt = f"""You are a helpful and honest AI assistant, now I want you to help in translation for the give text. you will translate the given text to its {to_language} version. The following are the rules to follow during the translation.* The input will be in <TO_TRANSLATE> tag. they can be words, numbers, or single character, Sometimes they are already in the target language, then only respond the original text into the <TRANSLATED> tag.* it is OK if you don't very confident to translate, in such cases, you can give the best translate you can, because we will have human review later on.* Your output will be put to <TRANSLATED></TRANSLATED> tag. * So, in summary, <TRANSLATED> tag should contain translated or original text, <error> tag should contain the reason why you cannot translate.* The given content is in the {domain} domain, so you should use the professional terms if applicable.* If it is the Chinese-to-English translation, please be aware that the order of terms may very different between the two language. Use the order of Englishto make it flow better. * the following is the terms for you to follow up: {_geo_terms}"""user_message = {"role": "user", "content": "<TO_TRANSLATE>" + query + "</TO_TRANSLATE>"}messages = [user_message]return json.dumps({"anthropic_version": "bedrock-2023-05-31","max_tokens": 80960,"system": system_prompt,"messages": messages})
-
文档解析
由于客户提供的输入文档限定为 Microsoft Office Word 格式,因此本方案采用 Python 中的 docx 库进行 Word 文档解析,代码参考如下:
import docx
def parse_doc_and_translate(input_file_name, output_file_name):"""Parse the document and translate the text"""doc = docx.Document(input_file_name)texts = []
-
专业术语翻译
地理领域的专业术语,放在文本文件中(命名为 terms.txt),上传到 Amazon S3 存储桶;在翻译的时候会先行从 S3 上读取专有词汇表,并自动将专有名词注入到提示词中。专有名词的格式如下:
Airy Hypothesis 艾里假说;
alias 假频;
amplitude spectrum 振幅谱;
antiroots 反山根;
Bouguer anomaly 布格异常;
Bouguer correction 布格改正;
continuation 延拓;
density 密度;
如果有新的专有词汇需要加入,只需要更新 S3 上的词汇表即可自动生效。在调用 Amazon Bedrock 上的大模型进行翻译时,提示词要求按照该术语表翻译,这部分核心代码如下:
import os
import boto3s3 = boto3.client('s3')S3_BUCKET = os.environ.get('APP_BUCKET_NAME', 'aaa-demo')
S3_TERMS_FILE = os.environ.get('S3_TERMS_FILE', 'terms.txt')def geo_terms():# Download the object content to a variableresponse = s3.get_object(Bucket=S3_BUCKET, Key=S3_TERMS_FILE)file_content = response['Body'].read().decode('utf-8')return file_contentif __name__ == '__main__':
print(geo_terms())# Amazon Bedrock 上的大模型的提示词中引用该术语表
def _get_complete_prompt(query, to_language='English', domain='None'):
system_prompt = f"""
…
* the following is the terms for you to follow up: {_geo_terms}"""
-
并发配置和异常处理
本方案 Lambda 的并发配置如下:
CONCURRENT_FOR_BEDROCK_INVOCATION = os.environ.get('CONCURRENT_FOR_BEDROCK_INVOCATION', '3')
如果同时上传多个文件,每个 Doc 会相应地启动一个 Lambda 实例来进行翻译工作;在执行翻译的时候,文档会被拆分成段落,并对每个段落进行翻译。一个文档可能会被拆分成 200~400 个片段,为了加快翻译速度,我们加入了并发执行的逻辑,并发数由上面的“CONCURRENT_FOR_BEDROCK_INVOCATION”来控制。设置该参数时需要考虑亚马逊云科技账号中 Bedrock 上的大模型的最大并发数(一般是每分钟 200 次),同时需要考虑并发的文档数量。
四、总结与展望
本次我们采用亚马逊云科技原生服务搭建了一套地理领域专业文档翻译的解决方案,该方案核心处理逻辑采用了亚马逊云科技无服务器化服务 Amazon Lambda,翻译处理完全基于事件触发,对于用户来说大幅降低使用成本,同时运维负担小,用户体验友好。但客户也提出了一些改进意见,例如希望提供独立于亚马逊云科技 Console 的 Web 页面、对用户进行权限划分、专业术语表用户可自行添加、翻译任务状态展示等,后续我们将联合合作伙伴,对这些工程化和定制化功能继续深入合作。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者
本期最新实验《多模一站通 —— Amazon Bedrock 上的基础模型初体验》
✨ 精心设计,旨在引导您深入探索Amazon Bedrock的模型选择与调用、模型自动化评估以及安全围栏(Guardrail)等重要功能。无需管理基础设施,利用亚马逊技术与生态,快速集成与部署生成式AI模型能力。
⏩️[点击进入实验] 即刻开启 AI 开发之旅
构建无限, 探索启程!
相关文章:
利用大模型实现地理领域文档中英文自动化翻译
一、 背景描述 在跨国性企业日常经营过程中,经常会遇到专业性较强的文档翻译的需求,例如法律文书、商务合同、技术文档等;以往遇到此类场景,企业内部往往需要指派专人投入数小时甚至数天来整理和翻译,效率低下&#x…...

SGFormer:卫星-地面融合 3D 语义场景补全
论文介绍 题目:SGFormer: Satellite-Ground Fusion for 3D Semantic Scene Completion 会议:IEEE / CVF Computer Vision and Pattern Recognition Conference 论文:https://www.arxiv.org/abs/2503.16825 代码:https://githu…...
Trinity三位一体开源程序是可解释的 AI 分析工具和 3D 可视化
一、软件介绍 文末提供源码和程序下载学习 Trinity三位一体开源程序是可解释的 AI 分析工具和 3D 可视化。Trinity 提供性能分析和 XAI 工具,非常适合深度学习系统或其他执行复杂分类或解码的模型。 二、软件作用和特征 Trinity 通过结合具有超维感知能力的不同交…...

城市街拍暗色电影胶片风格Lr调色教程,手机滤镜PS+Lightroom预设下载!
调色介绍 城市街拍暗色电影胶片风格 Lr 调色,是借助 Adobe Lightroom 软件,为城市街拍的人像或场景照片赋予独特视觉风格的后期处理方式。旨在模拟电影胶片质感,营造出充满故事感与艺术感的暗色氛围,让照片仿佛截取于某部充满张力…...
】家政平台数据生命线:备份与恢复策略全解析)
【家政平台开发(55)】家政平台数据生命线:备份与恢复策略全解析
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化,测试阶段多维度保障平台质量,…...
加密和解密(大语言模型)
看到很多对matlab的p文件加密方案感兴趣的。网络上技术资料比较少,所以,我让大语言模型提供一些概论性质的东西,转发出来自娱自乐。期望了解p文件加密的复杂度,而不是一定要尝试挑战加密算法。 但根据大语言模型提供的材料&#…...

双轮驱动能源革命:能源互联网与分布式能源赋能工厂能效跃迁
在全球能源结构深度转型与“双碳”目标的双重驱动下,工厂作为能源消耗的主力军,正站在节能变革的关键节点。能源互联网与分布式能源技术的融合发展,为工厂节能开辟了全新路径。塔能科技凭借前沿技术与创新实践,深度探索能源协同优…...

React 更新 state 中的数组
更新 state 中的数组 数组是另外一种可以存储在 state 中的 JavaScript 对象,它虽然是可变的,但是却应该被视为不可变。同对象一样,当你想要更新存储于 state 中的数组时,你需要创建一个新的数组(或者创建一份已有数组…...
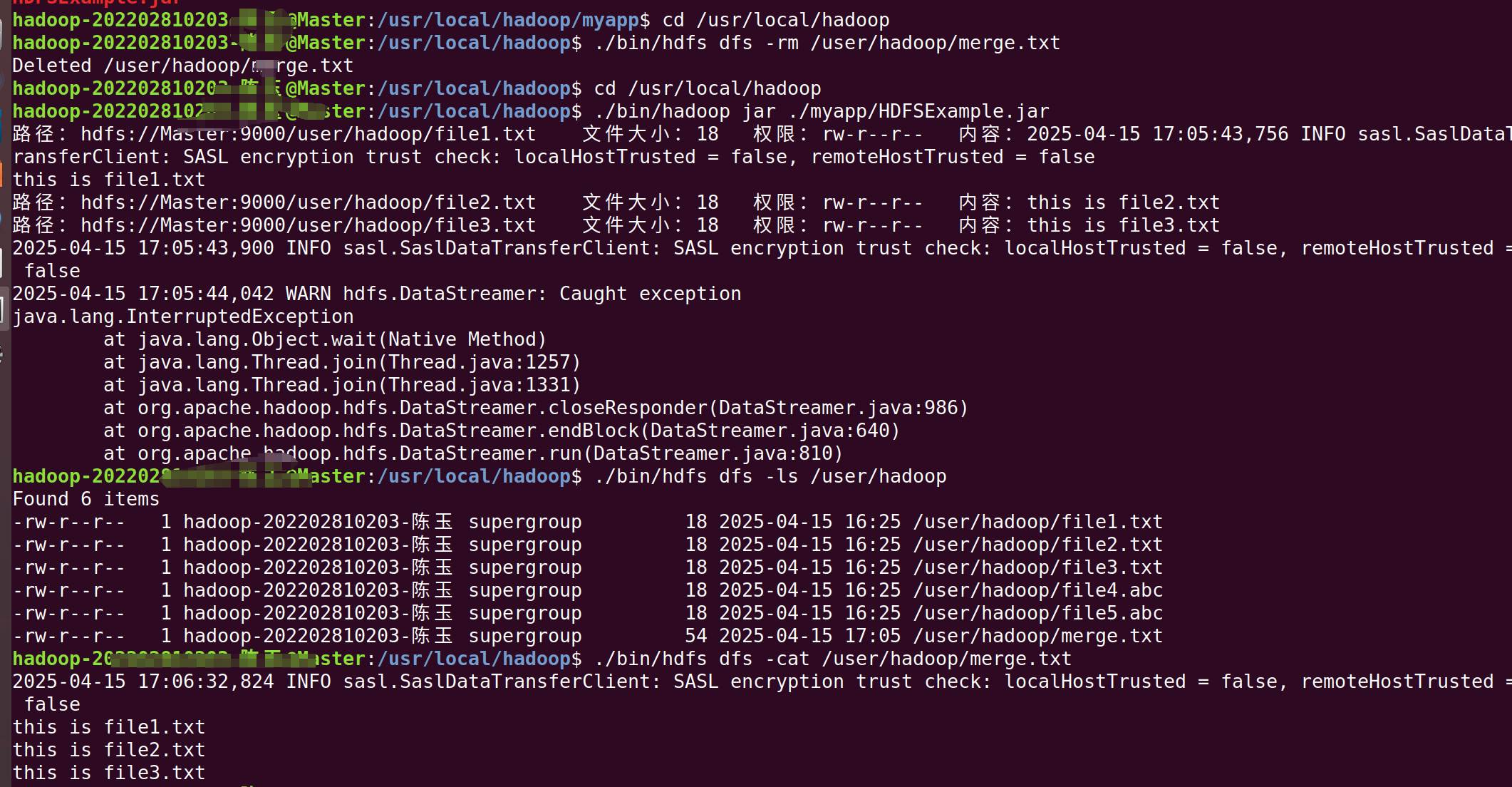
ubantu18.04HDFS编程实践(Hadoop3.1.3)
说明:本文图片较多,耐心等待加载。(建议用电脑) 注意所有打开的文件都要记得保存。 第一步:准备工作 本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之前教程的所有操作。 第二步&am…...

Spring Boot资源耗尽问题排查与优化
Spring Boot服务运行一段时间后新请求无法处理的问题。服务没有挂掉,也没有异常日志。思考可能是一些资源耗尽或阻塞的问题。 思考分析 首先,资源耗尽可能涉及线程池、数据库连接、内存、文件句柄或网络连接等。常见的如线程池配置不当,导致…...

优化WAV音频文件
优化 WAV 音频文件通常涉及 减小文件体积、提升音质 或 适配特定用途(如流媒体、广播等)。以下是分场景的优化方法,涵盖工具和操作步骤: 一、减小文件体积(无损/有损压缩) 1. 无损压缩 转换格式࿱…...

string函数具体事例
输出所有字串出现的位置 输入两个字符串A和B,输出B在A中出现的位置 输入 两行 第一行是一个含有空格的字符串 第二行是要查询的字串 输出 字串的位置 样例输入 I love c c python 样例输出 -1 样例输入 I love c c c 样例输出 8 12 #include<iostream> #inclu…...

8.Rust+Axum 数据库集成实战:从 ORM 选型到用户管理系统开发
摘要 深入探讨 RustAxum 数据库集成,包括 ORM 选型及实践,助力用户管理系统开发。 一、引言 在现代 Web 应用开发中,数据库集成是至关重要的一环。Rust 凭借其高性能、内存安全等特性,与 Axum 这个轻量级且高效的 Web 框架结合…...
)
电脑 BIOS 操作指南(Computer BIOS Operation Guide)
电脑 BIOS 操作指南 电脑的BIOS界面(应为“BIOS”)是一个固件界面,允许用户配置电脑的硬件设置。 进入BIOS后,你可以进行多种设置,具体包括: 1.启动配置 启动顺序:设置从哪个设备启动&#x…...

MySQL快速入门篇---库的操作
目录 一、创建数据库 1.语法 2.示例 二、查看数据库 1.语法 三、字符集编码和校验(排序)规则 1.查看数据库支持的字符集编码 2.查看数据库支持的排序规则 3.查看系统默认字符集和排序规则 3.1.查看系统默认字符集 3.2.查看系统默认排序规则 …...

前端:uniapp中uni.pageScrollTo方法与元素的overflow-y:auto之间的关联
在uniapp中,uni.pageScrollTo方法与元素的overflow-y:auto属性之间存在以下关联和差异: 一、功能定位差异 uni.pageScrollTo 属于页面级滚动控制,作用于整个页面容器34。要求页面内容高度必须超过屏幕高度,且由根元素下…...
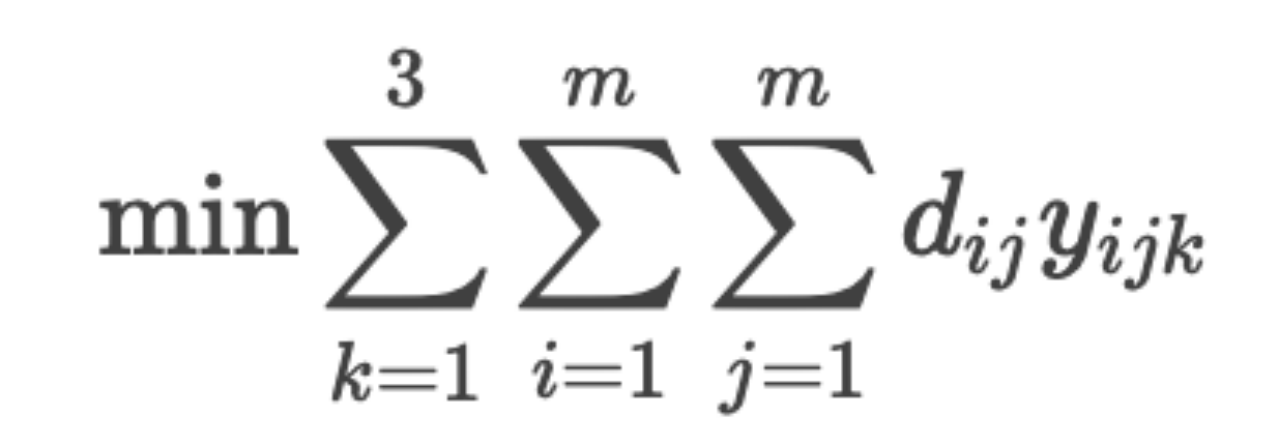
【已更新完毕】2025华中杯B题数学建模网络挑战赛思路代码文章教学:校园共享单车的调度与维护问题
完整内容请看文末最后的推广群 构建校园共享单车的调度与维护问题 摘要 共享单车作为一种便捷、环保的短途出行工具,近年来在高校校园内得到了广泛应用。然而,共享单车的运营也面临一些挑战。某高校引入共享单车后,委托学生对运营情况进行调…...
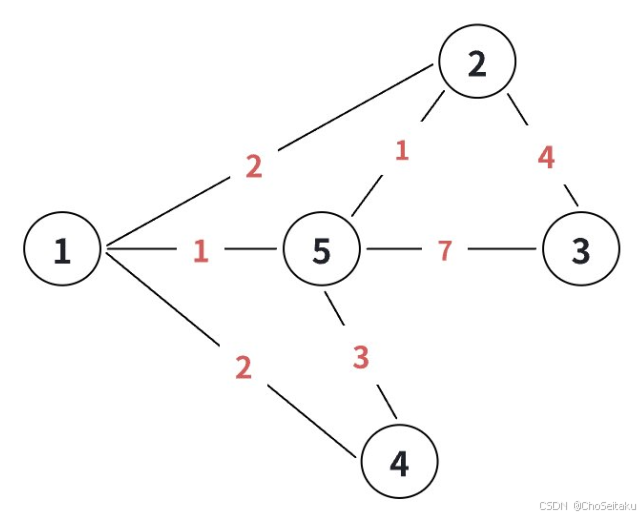
NO.92十六届蓝桥杯备战|图论基础-最小生成树-Prim算法-Kruskal算法|买礼物|繁忙的都市|滑雪(C++)
一个具有n个顶点的连通图,其⽣成树为包含n-1条边和所有顶点的极⼩连通⼦图。对于⽣成树来说,若砍去⼀条边就会使图不连通图;若增加⼀条边就会形成回路。 ⼀个图的⽣成树可能有多个,将所有⽣成树中权值之和最⼩的树称为最⼩⽣成树…...
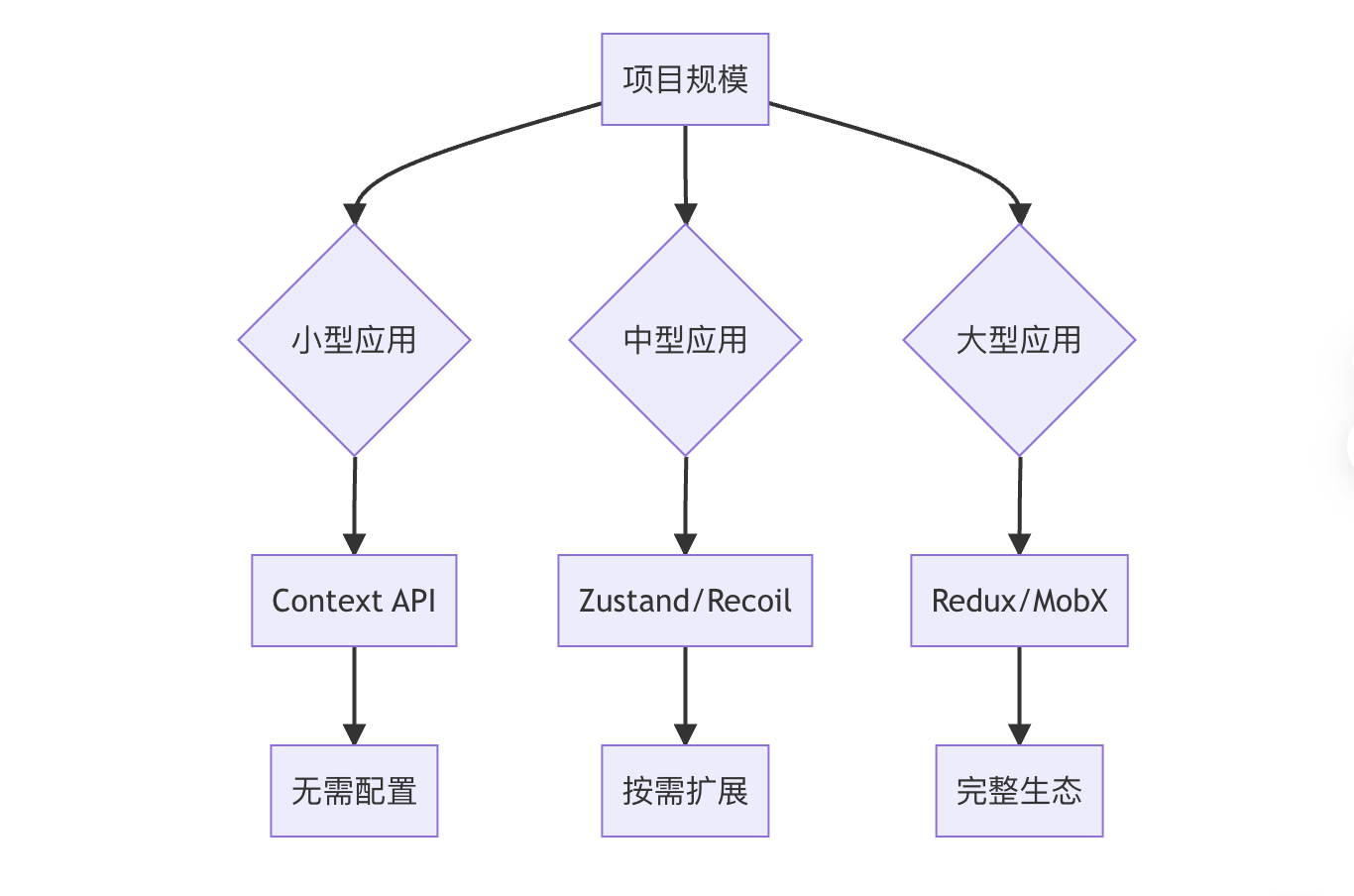
第十四节:实战场景-何实现全局状态管理?
React.createElement调用示例 Babel插件对JSX的转换逻辑 React 全局状态管理实战与 JSX 转换原理深度解析 一、React 全局状态管理实现方案 1. Context API useReducer 方案(轻量级首选) // 创建全局 Context 对象 const GlobalContext createConte…...

数据驱动、精准协同:高端装备制造业三位一体生产管控体系构建
开篇引入 鉴于集团全面推行生产运营体建设以及对二级单位生产过程管控力度逐步加强,某高端装备制造企业生产部长王总正在开展新的一年企业生产管控规划工作,为了能够更好地进行体系规划与建设应用,特邀请智能制造专家小智来进行讨论交流。 王…...

航电系统之通信技术篇
航电系统(航空电子系统)的通信技术是现代航空器的核心技术之一,其核心目标是实现飞行器内部各系统之间以及飞行器与外部设备(如地面控制中心、其他飞行器等)之间高效、可靠的信息交互。随着航空技术的不断发展…...

Linux 日常运维命令大全
Linux 作为一种开源操作系统,在服务器运维中扮演着重要角色。掌握常用的 Linux 命令对于运维人员而言至关重要。本文将整理一份 Linux 服务器运维常用命令大全,帮助你在日常工作中提高效率和准确性。 1. 基础命令 基础命令是Linux操作的起点࿰…...

HTTP 3.0 协议的特点
HTTP/3 是互联网传输协议的一次重要升级,相较于 HTTP/2,它引入了多项显著改进和新特性。 基于 QUIC 协议: HTTP/3 采用了 QUIC(Quick UDP Internet Connections)作为底层传输协议,QUIC 基于 UDP࿰…...

[工具]Java xml 转 Json
[工具]Java xml 转 Json 依赖 <!-- https://mvnrepository.com/artifact/cn.hutool/hutool-all --> <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.37</version> </dependen…...

「仓颉编程语言」Demo
仓颉编程语言」Demo python 1)# 仓颉语言写字楼管理系统示例(虚构语法)# 语法规则:中文关键词 类Python逻辑定义 写字楼管理系统属性:租户库 列表.新建()报修队列 列表.新建()费用单价 5 # 元/平方米方法 添加租户(名称, 楼层, 面积):…...

发现“横”字手写有难度,对比两个“横”字
我发现手写体“横”字“好看”程度,难以比得上印刷体: 两个从方正简体启体来的“横”字: 哪个更好看?我是倾向于左边一点。 <div style"transform: rotate(180deg); display: inline-block;"> 左边是我从方正简…...
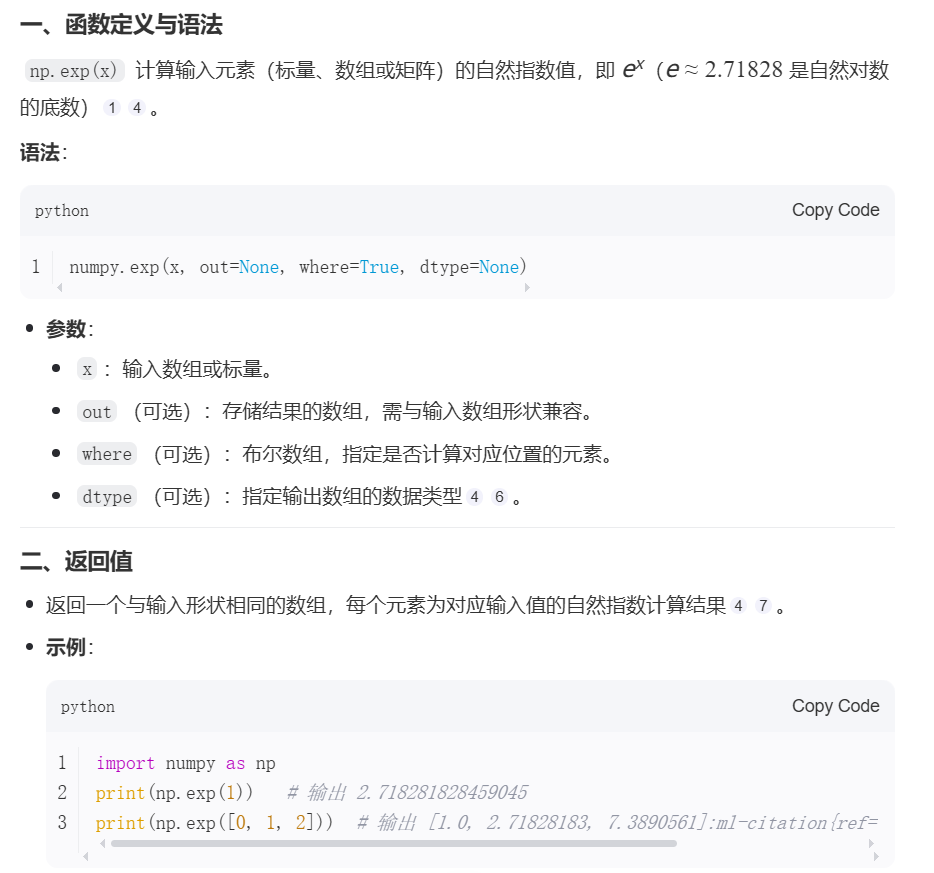
深度学习3.1 线性回归
3.1.1 线性回归的基本概念 损失函数 梯度下降 3.1.2 向量化加速 %matplotlib inline import math import time import numpy as np import torch from d2l import torch as d2ln 1000000 #本机为了差距明显,选择数据较大,运行时间较长,可选…...

番外篇 | SEAM-YOLO:引入SEAM系列注意力机制,提升遮挡小目标的检测性能
前言:Hello大家好,我是小哥谈。SEAM(Squeeze-and-Excitation Attention Module)系列注意力机制是一种高效的特征增强方法,特别适合处理遮挡和小目标检测问题。该机制通过建模通道间关系来自适应地重新校准通道特征响应。在遮挡小目标检测中的应用优势包括:1)通道注意力增强…...

SpringBoot ApplicationEvent:事件发布与监听机制
文章目录 引言一、事件机制的基本概念二、创建自定义事件2.1 定义事件类2.2 发布事件2.3 简化的事件发布 三、创建事件监听器3.1 使用EventListener注解3.2 实现ApplicationListener接口3.3 监听非ApplicationEvent类型的事件 四、事件监听的高级特性4.1 条件事件监听4.2 异步事…...

[250415] OpenAI 推出 GPT-4.1 系列,支持 1M token
目录 OpenAI 推出 GPT-4.1 系列 OpenAI 推出 GPT-4.1 系列 OpenAI 宣布,新一代 GPT-4.1 模型系列正式发布,包括 GPT-4.1, GPT-4.1 mini 和 GPT-4.1 nano 三款模型,该系列模型在各项性能指标上全面超越 GPT-4o 和 GPT-4o mini,尤其…...