#Linux动态大小裁剪以及包大小变大排查思路
1 动态库裁剪
库分为动态库和静态库,动态库是在程序运行时才加载,静态库是在编译时就加载到程序中。动态库的大小通常比静态库小,因为动态库只包含了程序需要的函数和数据,而静态库则包含了所有的函数和数据。静态库可以理解为引入源码编译,链接器在链接过程中会自动分析需要可不需要的代码进行删除裁剪。因此静态库不存在包大小问题(除了特定平台生成静态库过大导致无法生成库文件的问题)。
动态库裁剪的思路很简单:
- 通过工具或者编译选项删除不必要的数据和代码;
- 只导出需要的函数和数据;
- 关闭不必要的语言特性,如C++的异常处理等;
- 优化代码,比如能用
constexpr实现的尽量用constexpr实现;
1.1 代码层面
首先代码层面,需要尽可能确保不同模块之间的耦合度低,避免出现循环依赖的情况。其次,需要尽可能减少代码的重复,避免出现冗余代码的情况。最后,需要尽可能减少代码的复杂度,避免出现复杂的算法和数据结构的情况。对于一些能够用constexpr实现的功能,尽量用constexpr实现,这样可以减少动态库的大小。
C++中容易导致C++膨胀的代码:
- 模板函数和模板类。模板函数和模板类在实例化时都会有一个对应版本的实例,如果任何函数都通过编译器的默认推导来实例化很容易导致膨胀。因此模板函数和模板类应该尽量避免使用默认推导,尽可能显示推导能减少实例化版本。因此可以使用类型擦除和显示实例化来解决模板膨胀的问题。
- 内联函数。内联函数在编译时会被展开,因此内联函数的代码会被复制到调用处,这样会导致代码膨胀。因此内联函数应该尽量避免使用,除非函数的代码量很小。但是这一条对于现代C++ inline的含义已经发生了变化,inline优化基本完全由C++编译器自动优化。
- 宏。宏在编译时会被替换,因此宏的代码会被复制到调用处,这样会导致代码膨胀。因此宏应该尽量避免使用,除非宏的代码量很小。
- 异常处理。异常处理会导致代码膨胀,因为异常处理需要在运行时进行,因此异常处理会导致代码膨胀。因此异常处理应该尽量避免使用,除非异常处理的代码量很小。异常处理通常需要存储异常栈回溯相关的信息,因此容易导致代码膨胀。
- RTTI。RTTI 允许在运行时获取对象的类型信息。 RTTI 需要在代码中插入额外的类型信息,这会增加二进制文件的大小。
- 虚函数表。虚函数表是一个指针数组,它包含了虚函数的地址。虚函数表需要在运行时进行查找,这会增加二进制文件的大小。但是一般情况下,虚函数表的大小是固定的,因此虚函数表的大小并不是二进制膨胀的主要原因。
1.2 编译选项
通过编译选项可以控制编译器的行为,从而控制编译过程中的优化和裁剪。编译选项通常是通过编译器的命令行参数来设置的。常用的降低二进制大小的编译选项有:
- 优化等级,在编译动态库时,使用 -O2 或 -O3 优化级别。 这些优化级别可以使编译器生成更紧凑的代码,从而减小动态库的大小。或者使用
-Os之类平衡性能和大小的选项。 - 代码裁剪。
-function-sections:将每个函数放入单独的代码段。-gc-sections:在链接时删除未使用的代码段。-Wl,--gc-sections:在链接时删除未使用的代码段。
- LTO。使用链接时优化(Link-Time Optimization, LTO)可以进一步减小动态库的大小。 LTO 允许编译器在链接时进行全局优化,从而消除冗余代码和数据。
-flto:启用 LTO 优化。-fwhole-program:启用 LTO 优化。
1.3 导出符号
导出符号是指动态库中可以被其他模块(例如可执行文件或其他动态库)访问的函数和变量。 换句话说,它们是库的公共接口。默认情况下,在 Linux 系统中,使用 GCC 或 Clang 编译动态库时,所有非 static 的函数和全局变量都会被导出。 这通常会导致导出过多的符号,增加库的大小。导出符号越多,库的大小越大。 通过只导出必要的符号,可以显著减小库的大小。
控制导出符号不同编译器提供的方式不同,但是一般来说,有以下几种方式:
- 通过导出文件指定导出的符号列表;
- 代码中通过标记来标记需要导出的函数。
#ifndef MY_LIBRARY_EXPORT_H
#define MY_LIBRARY_EXPORT_H#ifdef _WIN32#ifdef MY_LIBRARY_BUILD#define MY_EXPORT __declspec(dllexport)#else#define MY_EXPORT __declspec(dllimport)#endif
#elif defined(__GNUC__)#define MY_EXPORT __attribute__((visibility("default")))
#else#define MY_EXPORT
#endif#endif // MY_LIBRARY_EXPORT_H
1.4 strip
通常情况下,二进制产物会包含一些调试信息,比如符号表、调试符号等。这些信息对于调试和分析二进制文件非常有用,但是它们通常不会被用于发布版本。因此,在发布版本中,通常会使用strip工具来去除这些调试信息,从而减小二进制文件的大小。
- 不可逆操作:
strip命令会直接修改文件,并且无法恢复。 因此,在运行strip命令之前,请务必备份文件。 - 影响调试: 移除符号表和调试信息会使调试变得更加困难。 如果需要调试程序,请不要运行
strip命令。 - 发布版本:
strip命令通常用于发布最终版本的程序,以减小文件大小并提高安全性。 - 调试信息分离: 可以使用
--only-keep-debug和--add-gnu-debuglink选项将调试信息分离到单独的文件中。 这样可以在不影响程序运行的情况下进行调试。
2 实验
2.1 测试代码和环境
我们的测试环境是:
Linux DESKTOP-JLHBOB4 4.4.0-19041-Microsoft #4355-Microsoft Thu Apr 12 17:37:00 PST 2024 x86_64 x86_64 x86_64 GNU/Linux
g++ (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
测试代码如下,分别是一个头文件和一个源文件编译成so库:
// my_lib.h
#ifndef MY_LARGE_LIBRARY_H
#define MY_LARGE_LIBRARY_H#include <iostream>
#include <vector>// 用于控制导出符号,可以参考之前的通用 EXPORT 宏
#ifdef _WIN32#ifdef MY_LARGE_LIBRARY_BUILD#define MY_LARGE_LIBRARY_API __declspec(dllexport)#else#define MY_LARGE_LIBRARY_API __declspec(dllimport)#endif
#elif defined(__GNUC__)#define MY_LARGE_LIBRARY_API __attribute__((visibility("default")))
#else#define MY_LARGE_LIBRARY_API
#endif// 模板类
template <typename T>
class MY_LARGE_LIBRARY_API MyTemplateClass {
public:MyTemplateClass(T value);T getValue() const;
private:T m_value;
};// 内联函数
inline int MY_LARGE_LIBRARY_API inlineFunction(int x) {return x * x * x; // 复杂的计算,增加内联的代价
}// 虚基类
class MY_LARGE_LIBRARY_API BaseClass {
public:BaseClass(int id);virtual ~BaseClass();virtual int calculate() const;int getId() const;
protected:int m_id;
};// 派生类
class MY_LARGE_LIBRARY_API DerivedClass : public BaseClass {
public:DerivedClass(int id, double factor);~DerivedClass() override;int calculate() const override;
private:double m_factor;
};// 一个导出函数,使用了上述的类和函数
MY_LARGE_LIBRARY_API int processData(const std::vector<int>& data);#endif // MY_LARGE_LIBRARY_H
// my_lib.cpp
#include "Mylib.hpp"
#include <numeric> // std::accumulate// 模板类的实现
template <typename T>
MyTemplateClass<T>::MyTemplateClass(T value) : m_value(value) {}template <typename T>
T MyTemplateClass<T>::getValue() const {return m_value;
}// 显式实例化一些常用的模板类型,减少编译单元间的重复实例化
template class MY_LARGE_LIBRARY_API MyTemplateClass<int>;
template class MY_LARGE_LIBRARY_API MyTemplateClass<double>;// 基类的实现
BaseClass::BaseClass(int id) : m_id(id) {}BaseClass::~BaseClass() {}int BaseClass::calculate() const {return m_id * 2;
}int BaseClass::getId() const {return m_id;
}// 派生类的实现
DerivedClass::DerivedClass(int id, double factor) : BaseClass(id), m_factor(factor) {}DerivedClass::~DerivedClass() {}int DerivedClass::calculate() const {return static_cast<int>(m_id * m_factor * 3);
}// processData 函数的实现
int processData(const std::vector<int>& data) {int sum = std::accumulate(data.begin(), data.end(), 0);int inlinedResult = inlineFunction(sum);MyTemplateClass<int> templateObject(inlinedResult);BaseClass* baseObject = new DerivedClass(sum, 2.5);int finalResult = templateObject.getValue() + baseObject->calculate();delete baseObject;return finalResult;
}
2.1.2 不同操作对二进制大小的影响
| 默认 | -O1 | -O2 | -O3 | -Os | 符号 | section | lto | whole | rtti | 异常 | debug | strip | 包大小(Byte) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| √ | 57400 | ||||||||||||
| √ | √ | 53752 | |||||||||||
| √ | √ | 53560 | |||||||||||
| √ | √ | 54784 | |||||||||||
| √ | √ | 53464 | |||||||||||
| √ | √ | √ | 53480 | ||||||||||
| √ | √ | √ | √ | 53936 | |||||||||
| √ | √ | √ | √ | √ | 23120 | ||||||||
| √ | √ | √ | √ | √ | √ | 10408 | |||||||
| √ | √ | √ | √ | √ | √ | √ | 10016 | ||||||
| √ | √ | √ | √ | √ | √ | √ | √ | 10016 | |||||
| √ | √ | √ | √ | √ | √ | √ | √ | √ | 9640 | ||||
| √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | 6008 |
下面是不同配置的详细说明:
- 默认配置:使用默认的编译选项和编译方式,不进行任何裁剪和优化。
g++ -fPIC -shared Mylib.cpp -g -DMY_LARGE_LIBRARY_BUILD -o mylib.so
- 使用不同优化选项对比,具体
-O0、-O1、-O2、-O3。 - 隐藏符号:使用
-fvisibility=hidden选项隐藏所有符号。g++ -fPIC -shared Mylib.cpp -g -DMY_LARGE_LIBRARY_BUILD -o mylibos_hidden.so -fvisibility=hidden -Os
- 独立section裁剪:使用
-ffunction-sections和-fdata-sections选项将每个函数和数据放入单独的代码段和数据段。g++ -fPIC -shared Mylib.cpp -g -DMY_LARGE_LIBRARY_BUILD -o mylibos_sections.so -ffunction-sections -fdata-sections -Os
ltog++ -fPIC -shared Mylib.cpp -g -DMY_LARGE_LIBRARY_BUILD -o mylibos_sections_lto.so -ffunction-sections -fdata-sections -Os -Wl,--gc-sections -flto
- 更激进的优化:
-fwhole-programg++ -fPIC -shared Mylib.cpp -g -DMY_LARGE_LIBRARY_BUILD -o mylibos_sections_lto_whole.so -ffunction-sections -fdata-sections -Os -Wl,--gc-sections -flto -fwhole-program
- 禁用RTTI:
-fno-rttig++ -fPIC -shared Mylib.cpp -g -DMY_LARGE_LIBRARY_BUILD -o mylibos_sections_lto_whole_nortti.so -ffunction-sections -fdata-sections -Os -Wl,--gc-sections -flto -fwhole-program -fno-rtti
- 禁用异常
-fno-exceptionsg++ -fPIC -shared Mylib.cpp -g -DMY_LARGE_LIBRARY_BUILD -o mylibos_sections_lto_whole_nortti_noex.so -ffunction-sections -fdata-sections -Os -Wl,--gc-sections -flto -fwhole-program -fno-rtti -fno-exceptions
- 分离调试信息:
-gsplit-dwarfg++ -fPIC -shared Mylib.cpp -g -DMY_LARGE_LIBRARY_BUILD -o mylibos_sections_lto_whole_nortti_noex_debuginfo.so -ffunction-sections -fdata-sections -Os -Wl,--gc-sections -flto -fwhole-program -fno-rtti -fno-exceptions -gsplit-dwarf
- 删除无用的信息:
stripstrip -g -x -s mylib.so
从上面的结果来看我们上面大部分操作都可以减少二进制,而且效果明显,我们的库从最开始的57400Byte减少到了6008Byte。能够看到成效是非常明显的。但是本来预期能够降低包大小的操作没有降低包大小的同时,反而增加了包大小这是为什么。
实际工程中往往限制导出符号比较能够降低包大小,上面的实验没有降低包大小的原因是因为我们的测试代码非常简单函数太少,因此包大小的优化效果不是很明显。以及一些其他参数没有降低包大小的原因也是因为我们的测试代码比较简单。
2.1 包大小排查思路
下面我们就简单排查下。
根据上面的数据我们能够看到有两个选项导致了包大小变大,分别是-O3和gc-sections,前者是因为该选项更倾向于优化性能而牺牲存储空间,因此已经有明确的结论不需要我们去排查。但是我们期望gc-sections等选项带来的是包大小优化,但是事实却不是如此。
首先,对于一个二进制动态库,其有不同的section组成,为了确认包大小变大的原因我们首先要做的是确认是哪个section变大了。因此我们使用objdump -h工具拆分二进制包来确认哪个部分增大了。下面是拆分得到的结果:
27 .debug_aranges 00000080 0000000000000000 DEBUG
30 .debug_line 000005f1 0000000000000000 DEBUG
31 .debug_str 00003bbe 0000000000000000 DEBUG
33 .debug_ranges 00000180 0000000000000000 DEBUG27 .debug_aranges 00000110 0000000000000000 DEBUG
30 .debug_line 0000055f 0000000000000000 DEBUG
31 .debug_str 00003bae 0000000000000000 DEBUG
33 .debug_ranges 000000f0 0000000000000000 DEBUG
从上面的拆包能够看到增加的主要是调试信息。而这部分调试信息在后续的strip中已经被删除了,因此影响我们最终产物大小的额外因素已经被排除了。如果希望知道具体增大了什么可以通过相关的提取对应section的信息来确认哪一部分增大了。
上面的排查路径其实不是很典型,因为一般情况下包大小都是因为代码引起的
下面简单描述下如何排查包大小问题:
- 首先,对比的产物一定是相同编译参数下的最终产物,使用两个带调试信息的不同编译参数的包对比没有意义(因此排查的前提是代码相同编译参数不同或者编译参数相同代码更改);
- 准备好后,使用
objdump -h分析不同section的大小,来确认方向:- 不同section对应不同的数据,一般情况下比较容易出现增大的是data和text段
.text: 代码段,包含可执行指令。 如果包大小增加主要是 .text section 变大,则需要关注代码优化。.rodata: 只读数据段,包含字符串常量、只读变量等。 大量的字符串常量或嵌入式资源会增加此 section 的大小。.data: 已初始化数据段,包含已初始化的全局变量和静态变量。 大的静态数组或全局变量会增加此 section 的大小。
- 明确具体包大小变化比较大的section后,可以尝试对比代码变动来初步确定变大的根本原因,如果无法确定则继续;
- 使用命令
nm -CS <your_binary> | sort -rnk1对代码段和数据段进行排序,然后对比不同版本之间的差异。 - 找到差异的具体部分之后再使用
objdump -d反汇编并对比源码来确认最终原因。
emsp; 需要注意的是,有些博客会推荐使用
bloaty,个人建议如果能够通过该工具排查发现数据异常,推荐直接使用linux native的工具链。(在实际项目中发现bloaty似乎统计的不是很准确。)
相关文章:

#Linux动态大小裁剪以及包大小变大排查思路
1 动态库裁剪 库分为动态库和静态库,动态库是在程序运行时才加载,静态库是在编译时就加载到程序中。动态库的大小通常比静态库小,因为动态库只包含了程序需要的函数和数据,而静态库则包含了所有的函数和数据。静态库可以理解为引入…...

基于微信小程序的中医小妙招系统的设计与实现
hello hello~ ,这里是 code袁~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 🦁作者简介:一名喜欢分享和记录学习的在校大学生…...

sqlite3的API以及命令行
sqlite是目前最流行的嵌入式数据库。 所谓嵌入式,就是足够简单,可以嵌入到我们自己开发的应用程序之中。 在Linux系统中,sqlite的使用只需要使用它的API,连接它的动态连接库,甚至都不用连接,sqlite的实现…...
css button 点击效果
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><title>button点击效果</title><style>#container {display: flex;align-items: center;justify-content: center;}.pushable {position: relat…...

表征流体作用力的参数及其特性
在圆柱绕流研究中,这些参数分别表征流体作用力的关键特性,以下是详细解析: 📊 参数物理意义及工程应用 符号名称物理意义典型值范围(参考)工程意义 C d m a x C_{dmax} Cdmax最大阻力系数瞬时阻力系数&a…...

Foundation Agent:深度赋能AI4DATA
2025年5月17日,第76期DataFunSummit:AI Agent技术与应用峰会将在DataFun线上社区举办。Manus的爆火并非偶然,随着基础模型效果不断的提升,Agent作为大模型的超级应用备受全世界的关注。为了推动其技术和应用,本次峰会计…...
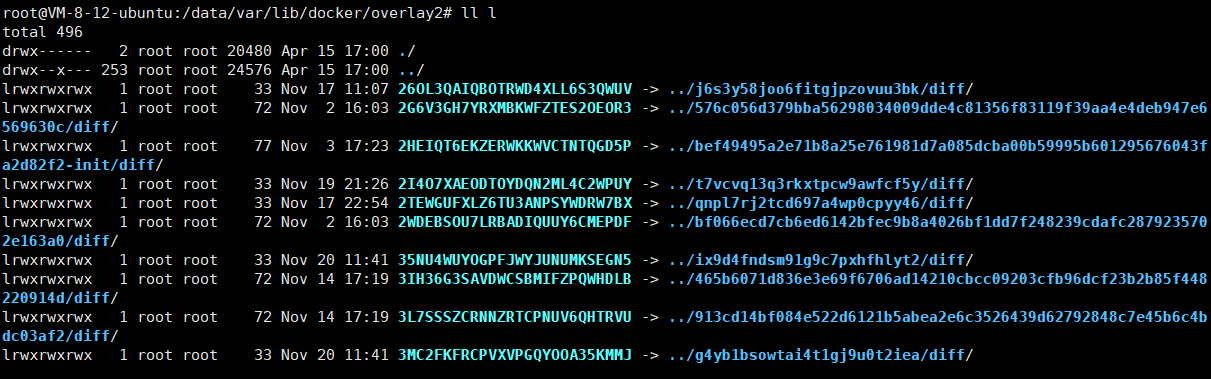
Docker--Docker镜像原理
docker 是操作系统层的虚拟化,所以 docker 镜像的本质是在模拟操作系统。 联合文件系统(UnionFS) 联合文件系统(UnionFS) 是Docker镜像实现分层存储的核心技术,它通过将多个只读层(Image Laye…...
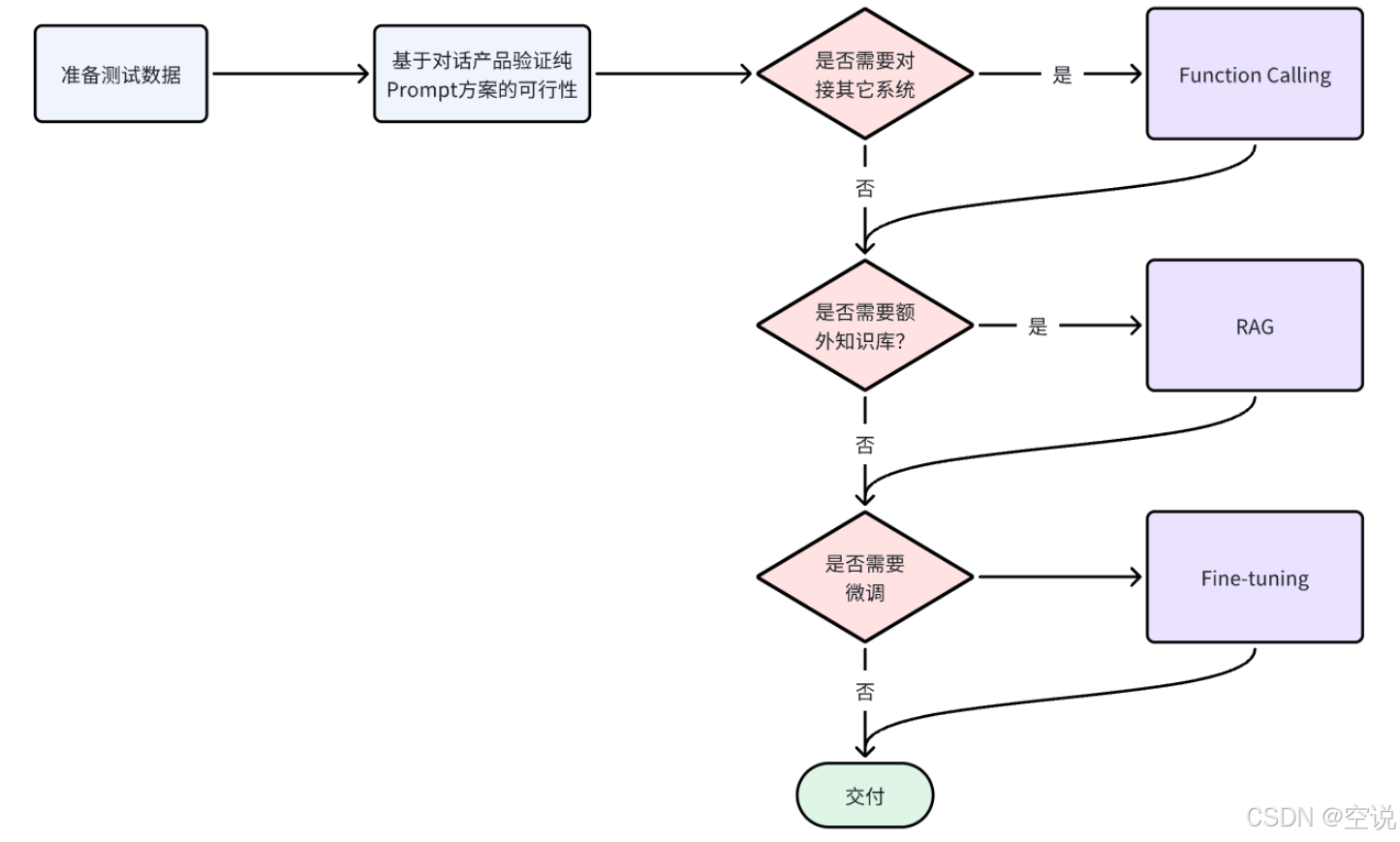
SpringAI+DeepSeek大模型应用开发——2 大模型应用开发架构
目录 2.大模型开发 2.1 模型部署 2.1.1 云服务-开放大模型API 2.1.2 本地部署 搜索模型 运行大模型 2.2 调用大模型 接口说明 提示词角色 编辑 会话记忆问题 2.3 大模型应用开发架构 2.3.1 技术架构 纯Prompt模式 FunctionCalling RAG检索增强 Fine-tuning …...
Transformer 架构 - 编码器 (Transformer Architecture - Encoder)
1.Transformer 编码器整体结构 Transformer 编码器的结构相对直观:它由 N 个完全相同的编码器层 (Encoder Layer) 堆叠而成。 图1: Transformer 编码器整体结构示意图 (简化) 输入序列(例如,通过 embedding 层转换后的词向量)首先会加上位置编码,然后传入第一个编码器层…...
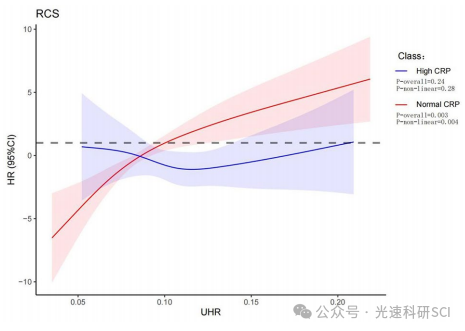
2.2/Q2,Charls最新文章解读
文章题目:Association of uric acid to high-density lipoprotein cholesterol ratio with the presence or absence of hypertensive kidney function: results from the China Health and Retirement Longitudinal Study (CHARLS) DOI:10.1186/s12882-…...

下拉框select标签类型
在我们很多页面里有下拉框的选择,这种元素怎么定位呢?下拉框分为两种类型:我们分别针对这两种元素进行定位和操作 select标签 : 通过select类处理。 非select标签 1、针对下拉框元素,如果是Select标签类型,…...

CentOS 7 linux系统从无到有部署项目
环境部署操作手册 一、Maven安装与配置 1. 下载与解压 下载地址:https://maven.apache.org/download.cgi?spm5238cd80.38b417da.0.0.d54c32cbnOpQh2&filedownload.cgi上传并解压解压命令: tar -zxvf apache-maven-3.9.9-bin.tar.gz -C /usr/loc…...
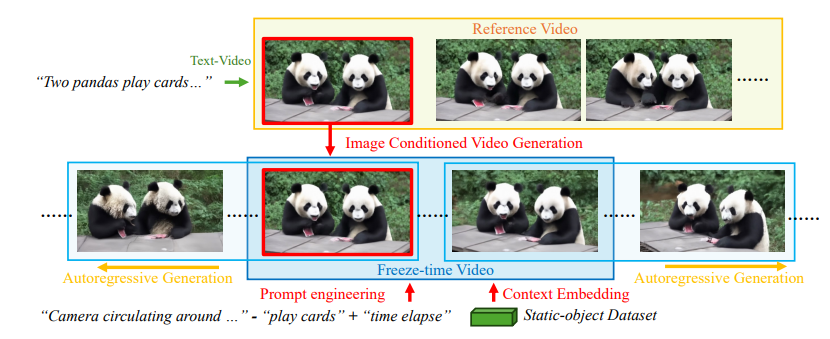
李飞飞团队新作WorldScore:“世界生成”能力迎来统一评测,3D/4D/视频模型同台PK
从古老神话中对世界起源的幻想,到如今科学家们在实验室里对虚拟世界的构建,人类探索世界生成奥秘的脚步从未停歇。如今,随着人工智能和计算机图形学的深度融合,我们已站在一个全新的起点,能够以前所未有的精度和效率去…...
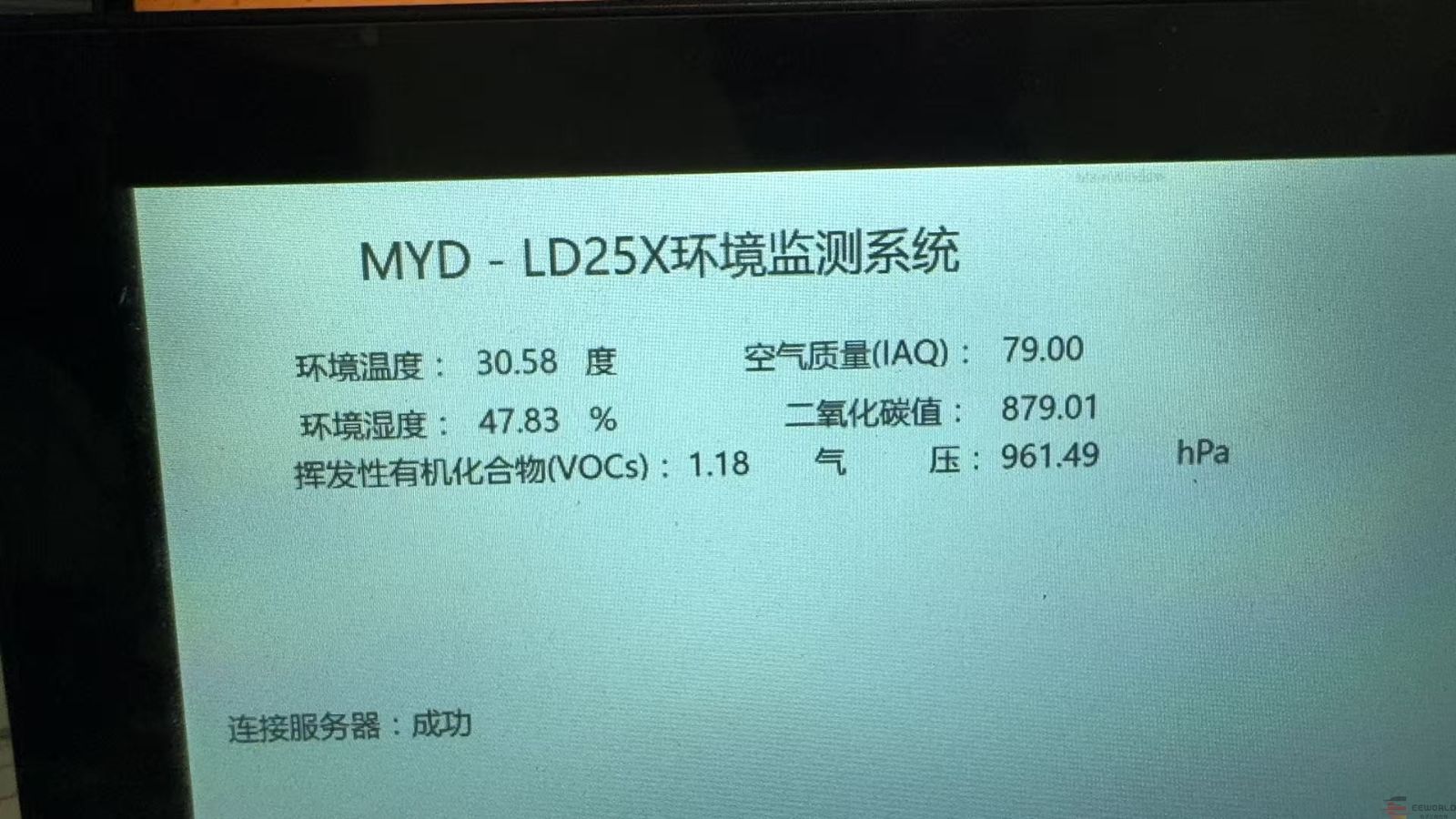
如何在米尔-STM32MP257开发板上部署环境监测系统
本文将介绍基于米尔电子MYD-LD25X开发板(米尔基于STM35MP257开发板)的环境监测系统方案测试。 摘自优秀创作者-lugl4313820 一、前言 环境监测是当前很多场景需要的项目,刚好我正在论坛参与的一个项目:Thingy:91X 蜂窝物联网原型…...
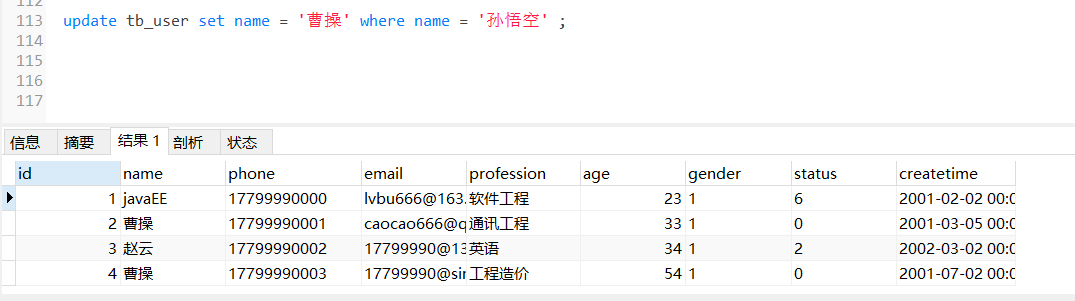
MySQL之SQL优化
目录 1.插入数据 2.大批量插入数据 3.order by优化 4.group by优化 5.limit优化 6.count优化 count用法 7.update优化 1.插入数据 如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化 第一个:批量插入数据 Insert into tb_test va…...
python_level1.2
目录 一、变量 例如:小正方形——>大正方形 【1】第一次使用这个变量,所以说:定义一个变量length; 【2】:是赋值符号,不是等于符号。(只有赋值,该变量才会被创建)…...

Linux、Kylin OS挂载磁盘,开机自动加载
0.实验环境: 1.确定挂载目录,如果没有使用mkdir 进行创建: mkdir /data 2.查看磁盘 lsblk #列出所有可用的块设备df -T #查看磁盘文件系统类型 3.格式化成xfs文件系统 (这里以xfs为例,ext4类似) mkfs.xfs /dev/vdb 4.挂载到…...

FPGA-VGA
目录 前言 一、VGA是什么? 二、物理接口 三、VGA显示原理 四、VGA时序标准 五、VGA显示参数 六、模块设计 七、波形图设计 八、彩条波形数据 前言 VGA的FPGA驱动 一、VGA是什么? VGA(Video Graphics Array)是IBM于1987年推出的…...

java的lambda和stream流操作
Lambda 表达式 ≈ 匿名函数 (Lambda接口)函数式接口:传入Lambda表达作为函数式接口的参数 函数式接口 只能有一个抽象方法的接口 Lambda 表达式必须赋值给一个函数式接口,比如 Java 8 自带的: 接口名 作用 Functio…...
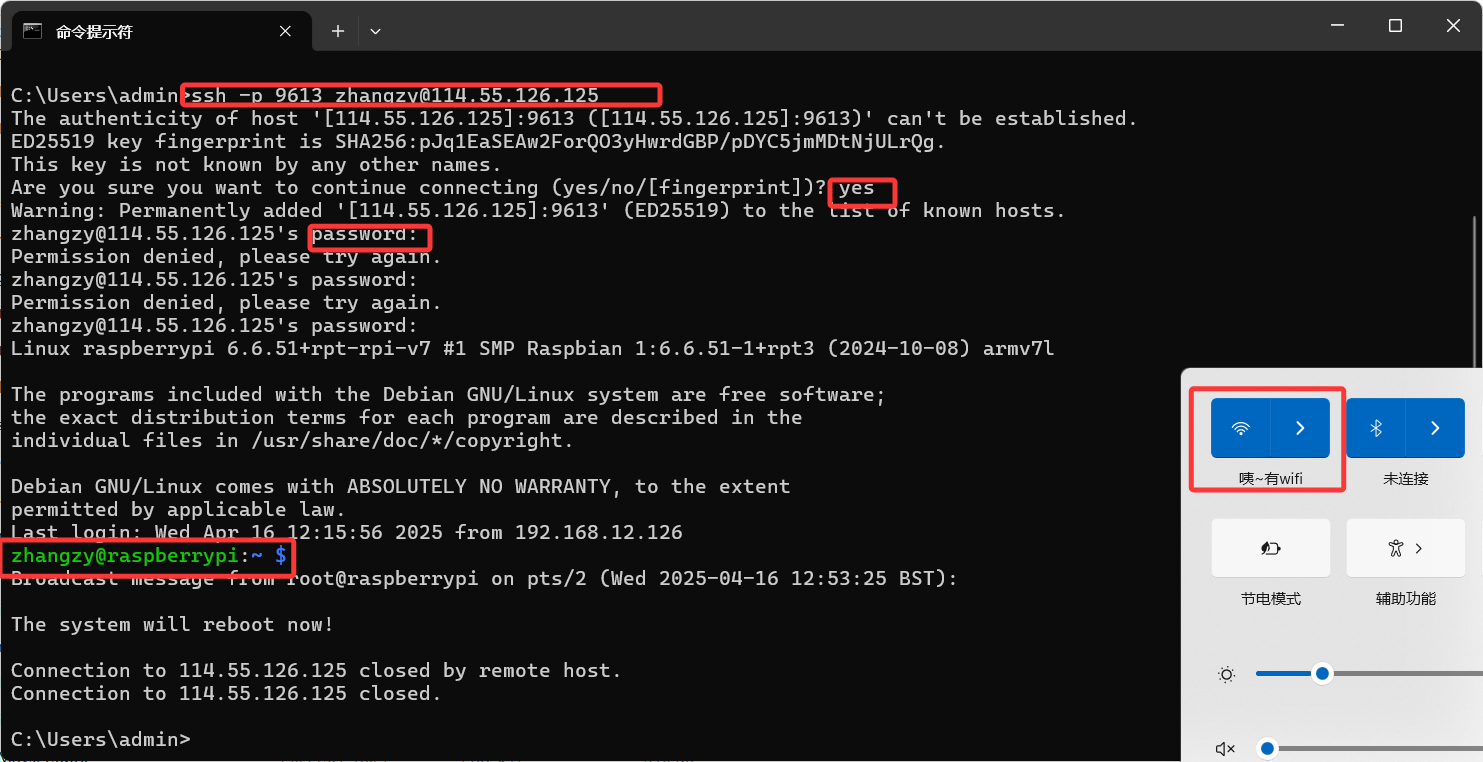
【嵌入式】【阿里云服务器】【树莓派】学习守护进程编程、gdb调试原理和内网穿透信息
目录 一. 守护进程的含义及编程实现的主要过程 1.1守护进程 1.2编程实现的主要过程 二、在树莓派中通过三种方式创建守护进程 2.1nohup命令创建 2.2fork()函数创建 2.3daemon()函数创建 三、在阿里云中通过三种方式创建守护进程 3.1nohup命令创建 3.2fork()函数创建 …...

数据结构学习笔记 :树与二叉树详解
目录 树的基本概念二叉树的定义与特性二叉树的存储结构 3.1 顺序存储 3.2 链式存储二叉树遍历特殊二叉树类型总结与应用场景 一、树的基本概念 核心定义 树:由根节点和若干子树构成的层次结构。叶子节点(终端节点):没有子节点的…...
前沿篇|CAN XL 与 TSN 深度解读
引言 1. CAN XL 标准演进与设计目标 2. CAN XL 物理层与帧格式详解 3. 时间敏感网络 (TSN) 关键技术解析 4. CAN XL + TSN 在自动驾驶领域的典型应用...

七、LangChain Tool类参数对接机制解析:基于Pydantic的类型安全与流程实现
LangChain 的 Tool 类(包括 BaseTool 和 StructuredTool)通过 参数校验、输入解析、函数调用 的流程,将外部函数与 Agent 的逻辑对接。以下是其内部逻辑的详细解析: 1. 工具与函数对接的核心机制 (1) 工具的定义方式 LangChain 提供了两种主要方式定义工具: 继承 BaseTo…...

Spring-AI-alibaba 结构化输出
1、将模型响应转换为 ActorsFilms 对象实例: ActorsFilms package com.alibaba.cloud.ai.example.chat.openai.entity;import java.util.List;public record ActorsFilms(String actor, List<String> movies) { } GetMapping("/toBean")public Ac…...
AI大模型科普:从零开始理解AI的“超级大脑“,以及如何用好提示词?
大家好,小机又来分享AI了。 今天分享一些新奇的东西, 你有没有试过和ChatGPT聊天时,心里偷偷犯嘀咕:"这AI怎么跟真人一样对答如流?它真的会思考吗?" 或者刷到技术文章里满屏的"Token"…...
STM32单片机入门学习——第40节: [11-5] 硬件SPI读写W25Q64
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.18 STM32开发板学习——第一节: [1-1]课程简介第40节: [11-5] 硬件SPI读…...

【Java学习笔记】关键字汇总
Java 关键字汇总 用于定义数据类型的关键字: classinterfaceenumbyteshortintlongfloatdoublecharbooleanvoid 用于定义数据值的关键字: truefalsenull 用于定义流程控制的关键字: ifelseswitchcasedefaultwhiledoforbreakcontinueretu…...

langgraph框架之初识
1.什么是langgraph? LangGraph 是一个用于构建可控代理的底层编排框架。在AI中,代理也就是执行动作的智能体,也就是agent。使用这个框架可以构建一个可以自由控制的智能执行体,它可以帮我们做许多事情,如下࿱…...
如何将 .txt 文件转换成 .md 文件
一、因为有些软件上传文件的时候需要 .md 文件,首先在文件所在的目录中,点击“查看”,然后勾选上“文件扩展名”,这个时候该目录下的所有文件都会显示其文件类型了。 二、这时直接对目标的 .txt 文件进行重命名,把后缀…...

pdfjs库使用记录1
import React, { useEffect, useState, useRef } from react; import * as pdfjsLib from pdfjs-dist; // 设置 worker 路径 pdfjsLib.GlobalWorkerOptions.workerSrc /pdf.worker.min.js; const PDFViewer ({ url }) > { const [pdf, setPdf] useState(null); const […...