zset.
zset 有序集合
zset 保留了 set 不能有重复元素的特点
zset 中的每个元素都有一个唯一的浮点类型的分数(score)与之关联,使得 zset 内部的元素是可以维护有序性的。但是这个有序不是用下标作为排序依据的,而是根据分数(score)
| 数据结构 | 是否允许重复元素 | 是否有序 | 有序依据 |
| list | 是 | 是 | 索引下标 |
| set | 否 | 否 | |
| zset | 否 | 是 | 分数 |
常见命令
zadd
添加 \ 更新指定的元素以及关联的分数到 zset 中(分数符合 double 类型,+inf -inf 合法)
zadd key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]
返回本次添加成功的元素个数 O(log(N))
XX 仅用于更新已经存在的元素,不会添加新的元素
NX 仅用于添加新的元素,不会更新已经存在的元素
LT 新的分数小于原分数就更新,反之不更新
GT 新的分数大于原分数就更新,反之不更新
CH zadd 默认返回本次添加的元素个数,指定选项后,将包含本次更新的元素个数
INCR 类似 zincrby,将元素的分数加上指定的分数。只能指定一个元素和分数
分数相同时,按照元素自身的字典序排列
分数不同时,按照分数排列
zset 内部是按照升序排列

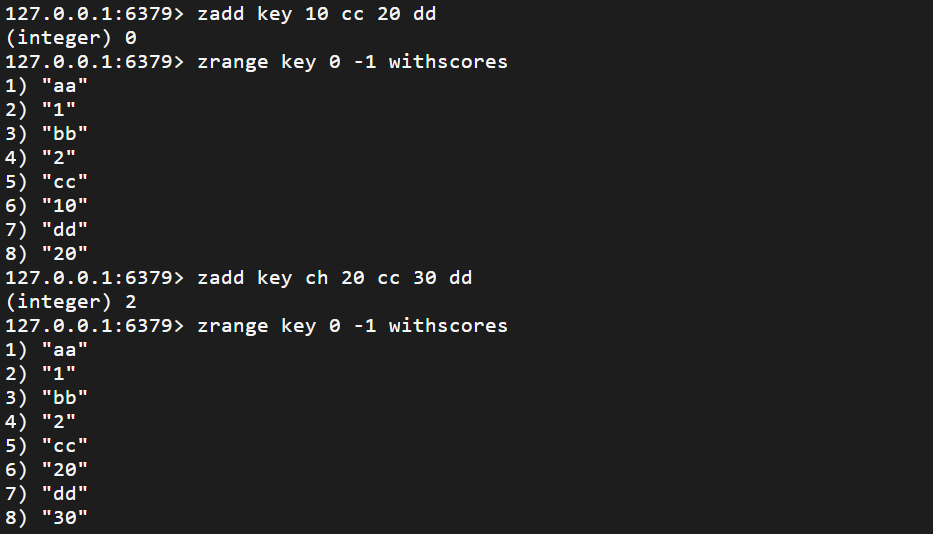

zrange
返回指定区间内的元素,按照分数升序
zrange key start stop [withscores]
返回区间内的元素列表 O(log(N) + M) N 集合中元素的个数 M start 到 stop 的元素个数
加上 withscores 将分数也一起返回
redis 内部存储数据时,是按照二进制的方式来存储的
redis 服务器不负责“字符编码”,把二进制转换成汉字,需要客户端支持 --raw
zcard
获取一个 zset 的基数(cardinality),即 zset 中的元素个数
zcard key
返回 zset 中的元素个数 O(1)
zcount
返回分数在 [min, max] 的元素个数(min max 默认包含,可通过 ( 排除)
zcount key min max
返回满足条件的元素列表个数 O(log(N))

zset 内部会记录每个元素当前的“排行” \ “次序”(下标)
查询到元素,就直接知道了元素所在的“次序”,直接把 min 和 max 对应的元素的次序减法
min 和 max 可以写成浮点数的形式(分数本身就是浮点数)
inf 无穷大 -inf 无穷小
zrevrange
返回指定区间里的元素,按照分数降序排列
zrevrange key start stop [withscores]
返回区间内的元素个数 O(log(N) + M)
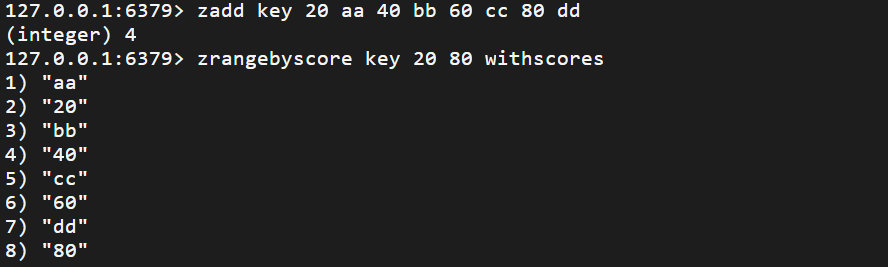
zrangebyscore
返回分数在 [min, max] 的元素
zrangebyscore key min max [withscores]
返回区间内的元素列表 O(log(N) + M)
zpopmax zpopmin
删除并返回分数最高的 count 个元素
zpopmax key [count ...]
zpopmin key [count ...]
返回 分数 和 元素列表 O(log(N) * count)
虽然 Redis 的有序集合记录了开头的元素,但是删除的时候使用的使用的是通用的删除函数,导致出现了重新查找的过程 O(1) ——> O(log(N))

如果存在多个元素,分数相同,同为最大值,zpopmax 删除时只删除其中一个元素
按照元素的字典序进行排列
bzpopmax bzpopmin
阻塞版本的 zpopmax zpopmin
bzpopmax key [key ...] timeout
bzpopmin key [key ...] timeout
返回元素列表 O(log(N))
timeout 超时时间,支持小写形式
zrank zrevrank
返回指定元素的排名(下标从 0 开始)
zrank key member 升序
zrevrank key member 降序
返回排名 O(log(N))

zcount 在计算时,先根据分数找到元素,再根据元素获取排名,把排名一减,得到元素个数
rev >= reverse
zscore
返回指定元素的分数
zscore key member
返回分数 O(1)

zrem
删除指定的元素
zrem key member [member ...]
返回本次删除的元素个数 O(log(N) * count)
zremrangebyrank
按照排序,删除指定范围内的元素(左闭右闭)升序
zremrangebyrank key start stop
返回本次删除的元素个数 O(log(N) + M)
zremrangebyscore
按照分数,删除指定范围内的元素(左闭右闭)升序
zremrangebyscore key min max ( 排除边界值
返回本次删除的元素个数 O(log(N) + M)
zincrby
为指定的元素的关联分数添加指定的分数值
zincrby key increment member
返回增加后的元素的分数 O(log(N))

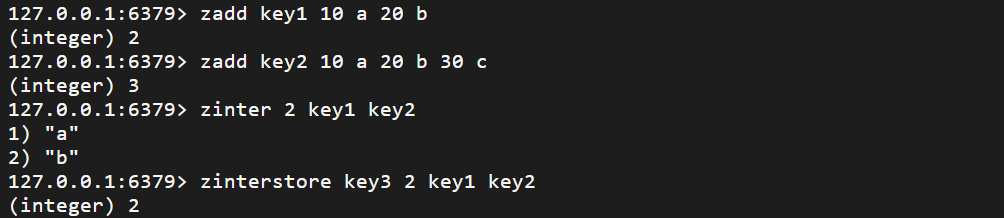
zinter zinterstore
求出给定有序集合中元素的交集,并保存进目标集合中
合并过程中以元素为单位,元素对应的分数按照不同的聚合方式和权重得到新的分数
zinter numkeys key [key ...] [weights weight [weight ...]] [aggreg <sum | min | max >]
zinterstore destination numkeys key [key ...] [weights weight [weight ...]]
[aggreg <sum | min | max >]
返回目标集合的元素列表
返回目标集合中的元素个数 O(N*K) + O(M*log(M))
N 最小集合的元素个数 K 集合的个数 M 目标集合的元素个数
zunion zunionstore
求出给定有序集合中元素的并集,并保存进目标集合中
zuoion numkeys key [key ...] [weights weight [weight ...]] [aggreg <sum | min | max >]
zunionstore destination numkeys key [key ...] [weights weight [weight ...]]
[aggreg <sum | min | max >]
O(N) + O(log(M) * M)
N 集合的个数 M 目标集合的元素个数
内部编码
1)ziplist(压缩列表)元素个数较少或者元素的体积较小
2)skiplist(跳表)
跳表是一个“复杂链表”,查询元素 O(N),相比于树状结构,更适合按照范围获取元素 (B+树)
应用场景
排行榜系统
例如网站上的热搜信息,榜单的维度是多方面的,“分数”是实时变化的
只要把相关信息和对应的分数放到 zset 中就会自动排序
随时可以按照下表进行查询,随着分数变化,使用 zincrby 也更方便,还可以自动排序
对于不同维度,可以将不同维度的数值都放到一个有序集合中,通过 zinterstore 或者 zunionstore 把上述集合按照权重进行集合间运算,得到结果集合
相关文章:
zset.
zset 有序集合 zset 保留了 set 不能有重复元素的特点 zset 中的每个元素都有一个唯一的浮点类型的分数(score)与之关联,使得 zset 内部的元素是可以维护有序性的。但是这个有序不是用下标作为排序依据的,而是根据分数…...

Windows 部署 DeepSeek 详细教程
一、准备工作 系统要求: 建议Windows 10 22H2 或更高版本,家庭版或专业版上网环境: 建议科学上网,国内访问部分网站会很慢设备要求: 内存8G以上、关闭防火墙 二、安装Ollama 官网链接: https://ollama.com/downloadg…...
过去十年前端框架演变与技术驱动因素剖析
一、技术演进脉络(2013-2023) 2013-2015:结构化需求催生框架雏形 早期的jQuery虽然解决了跨浏览器兼容性问题(如IE8兼容性处理),但其松散的代码组织方式难以支撑复杂应用开发。Backbone.js的出现首次引入M…...

从零开始学A2A一:A2A 协议的高级应用与优化
A2A 协议的高级应用与优化 学习目标 掌握 A2A 高级功能 理解多用户支持机制掌握长期任务管理方法学习服务性能优化技巧 理解与 MCP 的差异 分析多智能体场景下的优势掌握不同场景的选择策略 第一部分:多用户支持机制 1. 用户隔离架构 #mermaid-svg-Awx5UVYtqOF…...

#Linux动态大小裁剪以及包大小变大排查思路
1 动态库裁剪 库分为动态库和静态库,动态库是在程序运行时才加载,静态库是在编译时就加载到程序中。动态库的大小通常比静态库小,因为动态库只包含了程序需要的函数和数据,而静态库则包含了所有的函数和数据。静态库可以理解为引入…...

基于微信小程序的中医小妙招系统的设计与实现
hello hello~ ,这里是 code袁~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 🦁作者简介:一名喜欢分享和记录学习的在校大学生…...

sqlite3的API以及命令行
sqlite是目前最流行的嵌入式数据库。 所谓嵌入式,就是足够简单,可以嵌入到我们自己开发的应用程序之中。 在Linux系统中,sqlite的使用只需要使用它的API,连接它的动态连接库,甚至都不用连接,sqlite的实现…...
css button 点击效果
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><title>button点击效果</title><style>#container {display: flex;align-items: center;justify-content: center;}.pushable {position: relat…...

表征流体作用力的参数及其特性
在圆柱绕流研究中,这些参数分别表征流体作用力的关键特性,以下是详细解析: 📊 参数物理意义及工程应用 符号名称物理意义典型值范围(参考)工程意义 C d m a x C_{dmax} Cdmax最大阻力系数瞬时阻力系数&a…...

Foundation Agent:深度赋能AI4DATA
2025年5月17日,第76期DataFunSummit:AI Agent技术与应用峰会将在DataFun线上社区举办。Manus的爆火并非偶然,随着基础模型效果不断的提升,Agent作为大模型的超级应用备受全世界的关注。为了推动其技术和应用,本次峰会计…...
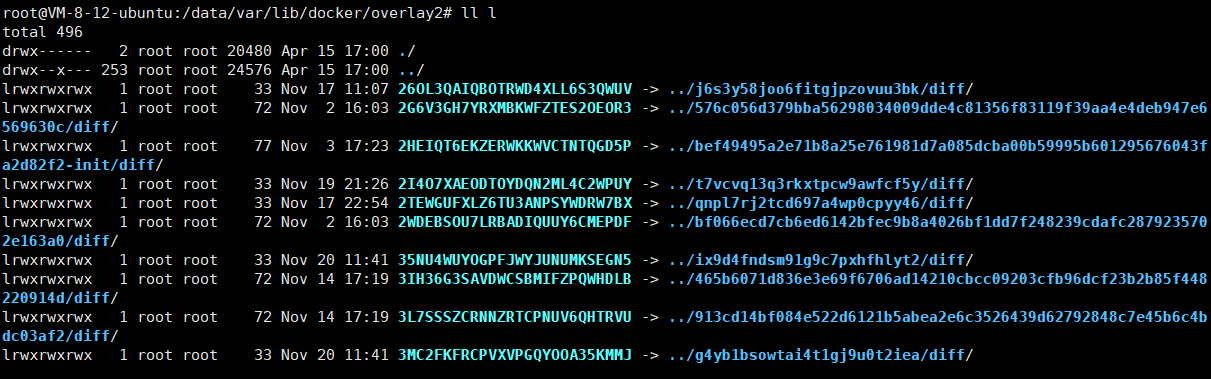
Docker--Docker镜像原理
docker 是操作系统层的虚拟化,所以 docker 镜像的本质是在模拟操作系统。 联合文件系统(UnionFS) 联合文件系统(UnionFS) 是Docker镜像实现分层存储的核心技术,它通过将多个只读层(Image Laye…...
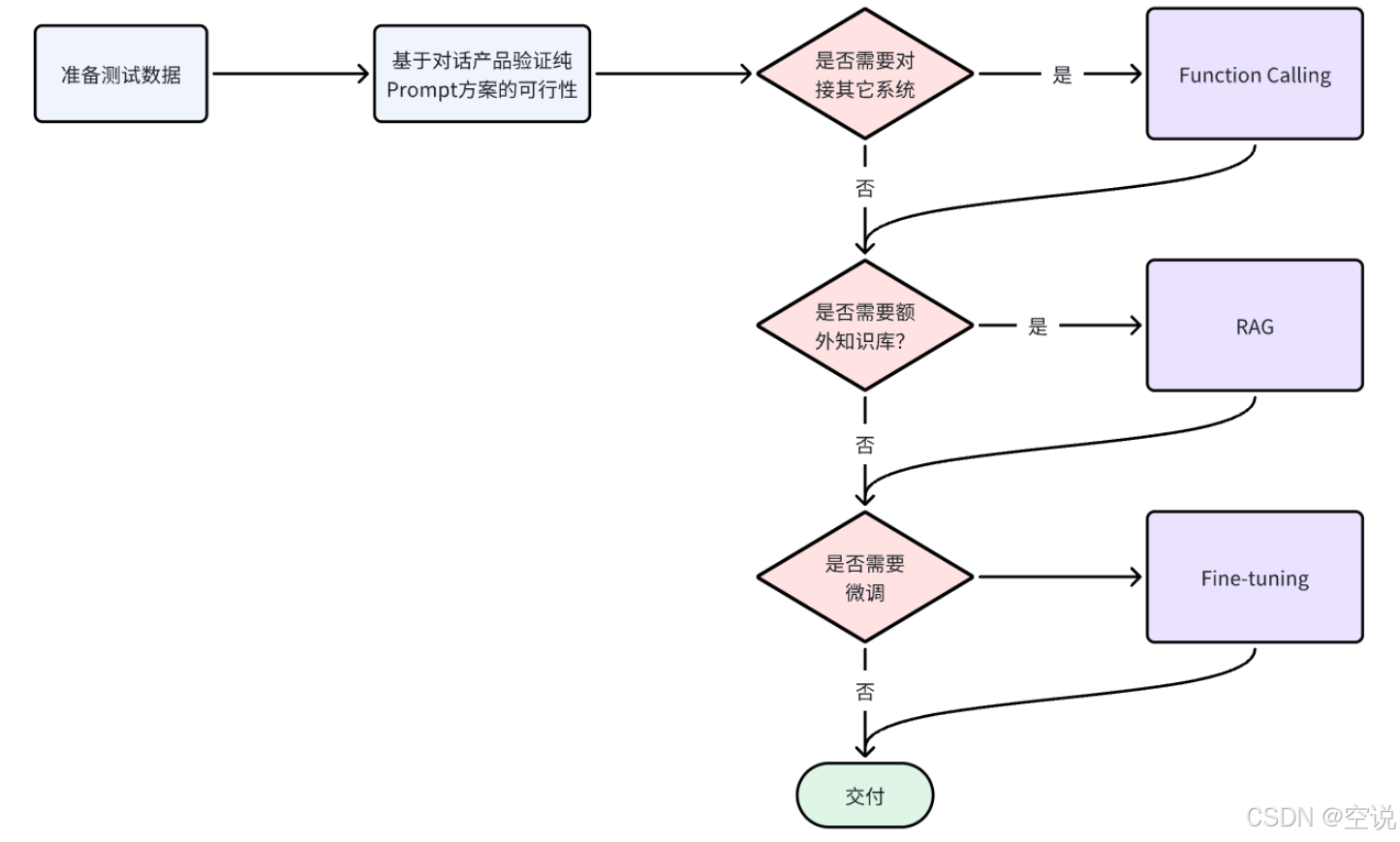
SpringAI+DeepSeek大模型应用开发——2 大模型应用开发架构
目录 2.大模型开发 2.1 模型部署 2.1.1 云服务-开放大模型API 2.1.2 本地部署 搜索模型 运行大模型 2.2 调用大模型 接口说明 提示词角色 编辑 会话记忆问题 2.3 大模型应用开发架构 2.3.1 技术架构 纯Prompt模式 FunctionCalling RAG检索增强 Fine-tuning …...
Transformer 架构 - 编码器 (Transformer Architecture - Encoder)
1.Transformer 编码器整体结构 Transformer 编码器的结构相对直观:它由 N 个完全相同的编码器层 (Encoder Layer) 堆叠而成。 图1: Transformer 编码器整体结构示意图 (简化) 输入序列(例如,通过 embedding 层转换后的词向量)首先会加上位置编码,然后传入第一个编码器层…...
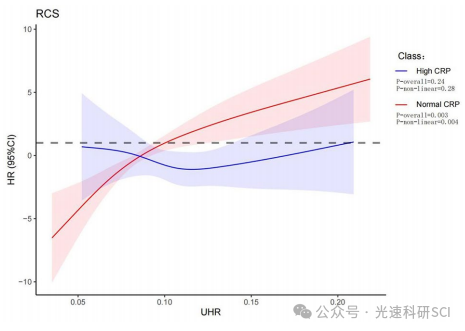
2.2/Q2,Charls最新文章解读
文章题目:Association of uric acid to high-density lipoprotein cholesterol ratio with the presence or absence of hypertensive kidney function: results from the China Health and Retirement Longitudinal Study (CHARLS) DOI:10.1186/s12882-…...

下拉框select标签类型
在我们很多页面里有下拉框的选择,这种元素怎么定位呢?下拉框分为两种类型:我们分别针对这两种元素进行定位和操作 select标签 : 通过select类处理。 非select标签 1、针对下拉框元素,如果是Select标签类型,…...

CentOS 7 linux系统从无到有部署项目
环境部署操作手册 一、Maven安装与配置 1. 下载与解压 下载地址:https://maven.apache.org/download.cgi?spm5238cd80.38b417da.0.0.d54c32cbnOpQh2&filedownload.cgi上传并解压解压命令: tar -zxvf apache-maven-3.9.9-bin.tar.gz -C /usr/loc…...
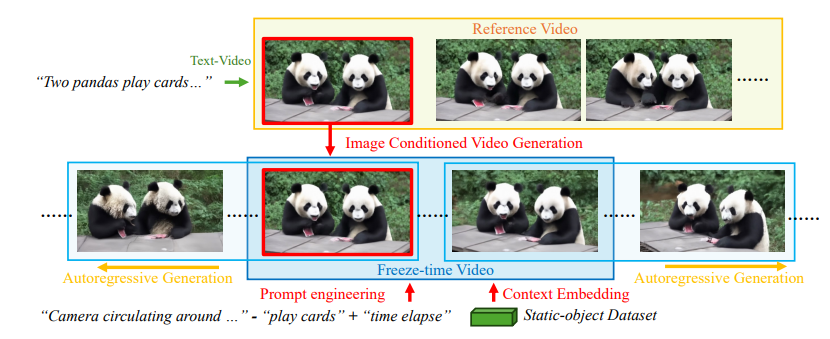
李飞飞团队新作WorldScore:“世界生成”能力迎来统一评测,3D/4D/视频模型同台PK
从古老神话中对世界起源的幻想,到如今科学家们在实验室里对虚拟世界的构建,人类探索世界生成奥秘的脚步从未停歇。如今,随着人工智能和计算机图形学的深度融合,我们已站在一个全新的起点,能够以前所未有的精度和效率去…...
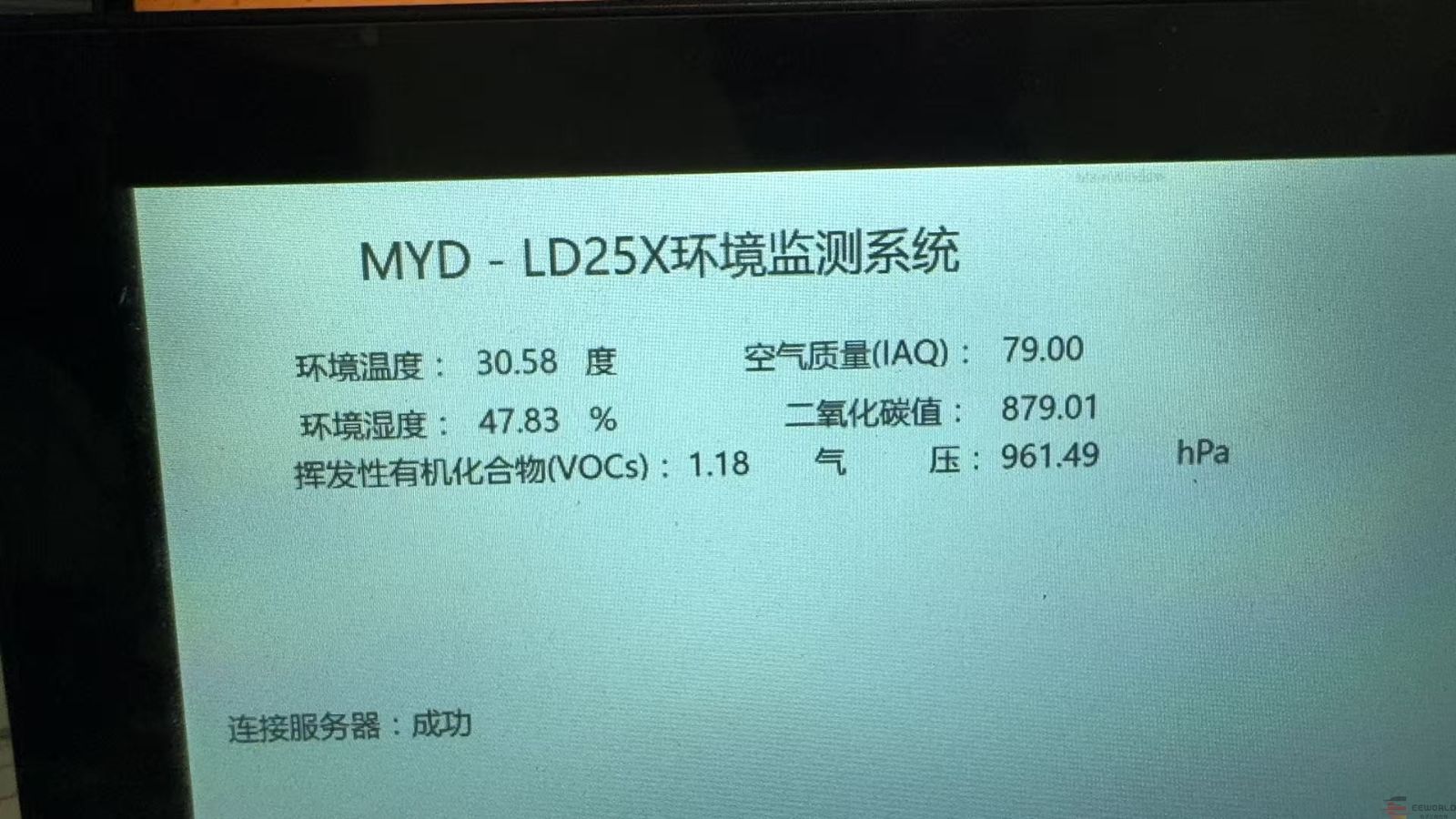
如何在米尔-STM32MP257开发板上部署环境监测系统
本文将介绍基于米尔电子MYD-LD25X开发板(米尔基于STM35MP257开发板)的环境监测系统方案测试。 摘自优秀创作者-lugl4313820 一、前言 环境监测是当前很多场景需要的项目,刚好我正在论坛参与的一个项目:Thingy:91X 蜂窝物联网原型…...
MySQL之SQL优化
目录 1.插入数据 2.大批量插入数据 3.order by优化 4.group by优化 5.limit优化 6.count优化 count用法 7.update优化 1.插入数据 如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化 第一个:批量插入数据 Insert into tb_test va…...
python_level1.2
目录 一、变量 例如:小正方形——>大正方形 【1】第一次使用这个变量,所以说:定义一个变量length; 【2】:是赋值符号,不是等于符号。(只有赋值,该变量才会被创建)…...

Linux、Kylin OS挂载磁盘,开机自动加载
0.实验环境: 1.确定挂载目录,如果没有使用mkdir 进行创建: mkdir /data 2.查看磁盘 lsblk #列出所有可用的块设备df -T #查看磁盘文件系统类型 3.格式化成xfs文件系统 (这里以xfs为例,ext4类似) mkfs.xfs /dev/vdb 4.挂载到…...

FPGA-VGA
目录 前言 一、VGA是什么? 二、物理接口 三、VGA显示原理 四、VGA时序标准 五、VGA显示参数 六、模块设计 七、波形图设计 八、彩条波形数据 前言 VGA的FPGA驱动 一、VGA是什么? VGA(Video Graphics Array)是IBM于1987年推出的…...

java的lambda和stream流操作
Lambda 表达式 ≈ 匿名函数 (Lambda接口)函数式接口:传入Lambda表达作为函数式接口的参数 函数式接口 只能有一个抽象方法的接口 Lambda 表达式必须赋值给一个函数式接口,比如 Java 8 自带的: 接口名 作用 Functio…...
【嵌入式】【阿里云服务器】【树莓派】学习守护进程编程、gdb调试原理和内网穿透信息
目录 一. 守护进程的含义及编程实现的主要过程 1.1守护进程 1.2编程实现的主要过程 二、在树莓派中通过三种方式创建守护进程 2.1nohup命令创建 2.2fork()函数创建 2.3daemon()函数创建 三、在阿里云中通过三种方式创建守护进程 3.1nohup命令创建 3.2fork()函数创建 …...

数据结构学习笔记 :树与二叉树详解
目录 树的基本概念二叉树的定义与特性二叉树的存储结构 3.1 顺序存储 3.2 链式存储二叉树遍历特殊二叉树类型总结与应用场景 一、树的基本概念 核心定义 树:由根节点和若干子树构成的层次结构。叶子节点(终端节点):没有子节点的…...
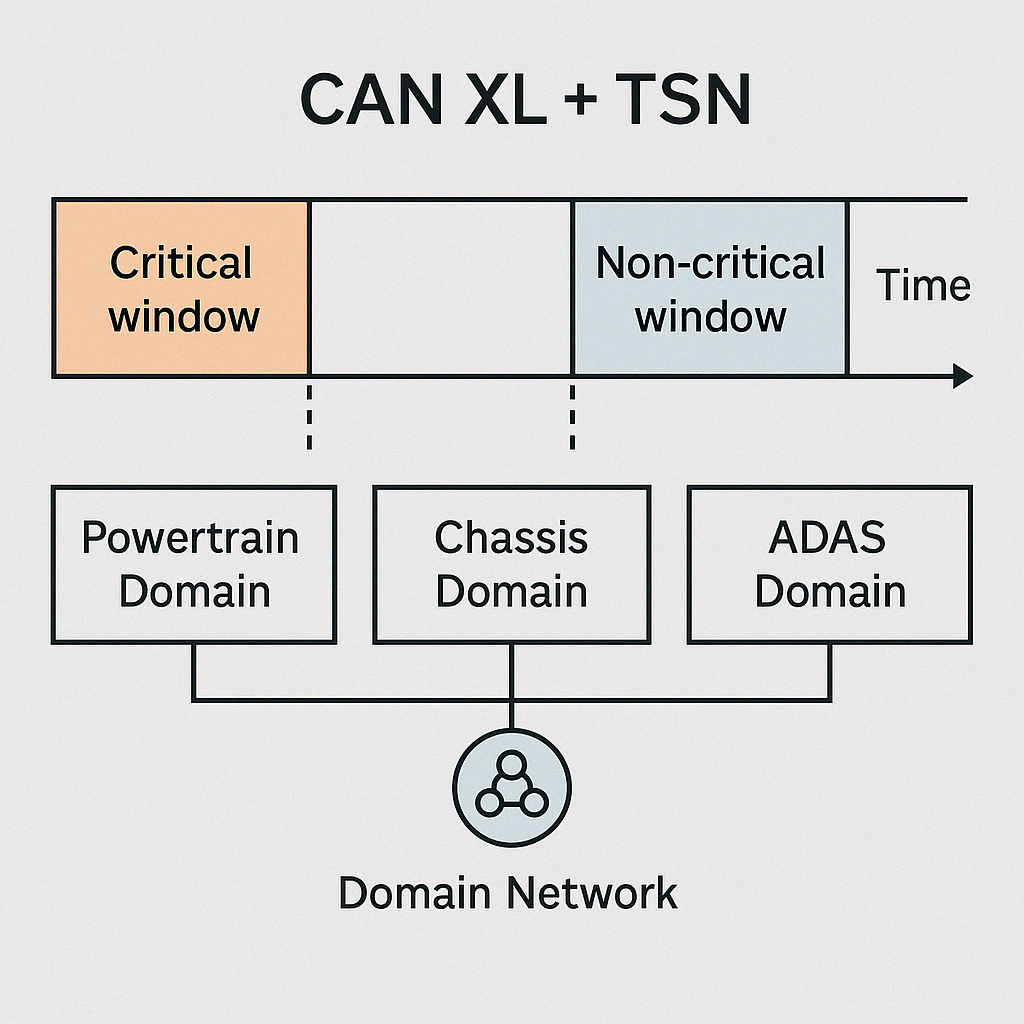
前沿篇|CAN XL 与 TSN 深度解读
引言 1. CAN XL 标准演进与设计目标 2. CAN XL 物理层与帧格式详解 3. 时间敏感网络 (TSN) 关键技术解析 4. CAN XL + TSN 在自动驾驶领域的典型应用...

七、LangChain Tool类参数对接机制解析:基于Pydantic的类型安全与流程实现
LangChain 的 Tool 类(包括 BaseTool 和 StructuredTool)通过 参数校验、输入解析、函数调用 的流程,将外部函数与 Agent 的逻辑对接。以下是其内部逻辑的详细解析: 1. 工具与函数对接的核心机制 (1) 工具的定义方式 LangChain 提供了两种主要方式定义工具: 继承 BaseTo…...

Spring-AI-alibaba 结构化输出
1、将模型响应转换为 ActorsFilms 对象实例: ActorsFilms package com.alibaba.cloud.ai.example.chat.openai.entity;import java.util.List;public record ActorsFilms(String actor, List<String> movies) { } GetMapping("/toBean")public Ac…...
AI大模型科普:从零开始理解AI的“超级大脑“,以及如何用好提示词?
大家好,小机又来分享AI了。 今天分享一些新奇的东西, 你有没有试过和ChatGPT聊天时,心里偷偷犯嘀咕:"这AI怎么跟真人一样对答如流?它真的会思考吗?" 或者刷到技术文章里满屏的"Token"…...
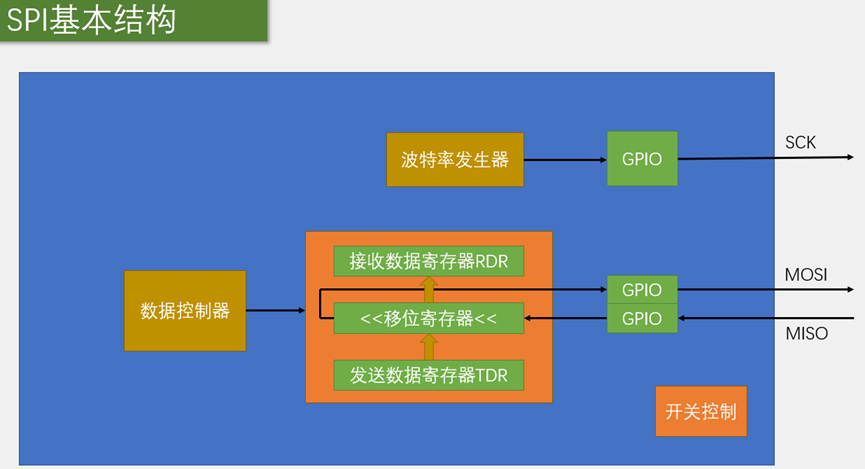
STM32单片机入门学习——第40节: [11-5] 硬件SPI读写W25Q64
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.18 STM32开发板学习——第一节: [1-1]课程简介第40节: [11-5] 硬件SPI读…...