强化学习算法系列(六):应用最广泛的算法——PPO算法
强化学习算法
(一)动态规划方法——策略迭代算法(PI)和值迭代算法(VI)
(二)Model-Free类方法——蒙特卡洛算法(MC)和时序差分算法(TD)
(三)基于动作值的算法——Sarsa算法与Q-Learning算法
(四)深度强化学习时代的到来——DQN算法
(五)最主流的算法框架——Actor-Critic算法框架
(六)应用最广泛的算法——PPO算法
(七)更高级的算法——DDPG算法与TD3算法
(八)待续
前言
前面我们已经学习了强化学习中最流行的算法框架——Actor-Critic算法框架,本篇将会介绍该框架下最流行的一种算法——近端策略优化(Proximal Policy Optimization,PPO)算法,我们会结合公式推导其核心思想。我们将从策略梯度方法出发,逐步推导到PPO的关键改进。
一、PPO算法的核心思想
1. 重要性采样
重要性采样是强化学习中的一个重要思想,这种技术利用旧策略的采样数据,估计新策略的期望收益。修正采样分布差异,理论上严格等价。允许用旧策略数据更新新策略(如强化学习中的 Off-Policy 方法)。如果没有使用重要性采样,估计新策略的期望收益得到的结果其实是旧策略的采样与新策略运算得到的结果。我们实际想要的其实是,新策略的采样与新策略的做运算结果。
2. 裁剪机制
为防止 r ( θ ) r(θ) r(θ) 偏离1过多(即策略更新过大),PPO引入裁剪操作:
L C L I P ( θ ) = E [ min ( r ( θ ) A ( s , a ) , c l i p ( r ( θ ) , 1 − ϵ , 1 + ϵ ) A ( s , a ) ) ] L^{CLIP}(θ)=\mathbb E[\min(r(θ)A(s,a), clip(r(θ),1−ϵ,1+ϵ)A(s,a))] LCLIP(θ)=E[min(r(θ)A(s,a),clip(r(θ),1−ϵ,1+ϵ)A(s,a))]其中 ϵ ϵ ϵ是超参数(如0.2),裁剪函数将 r ( θ ) r(θ) r(θ)限制在 [ 1 − ϵ , 1 + ϵ ] [1−ϵ,1+ϵ] [1−ϵ,1+ϵ]之间。
裁剪的直观解释
- 若 A(s,a)>0(动作优于平均),限制 r(θ)≤1+ϵ,避免过度利用;
- 若 A(s,a)<0(动作劣于平均),限制 r(θ)≥1−ϵ,避免过度探索。
3. PPO的完整目标函数
实际中,PPO还增加了值函数误差和熵正则项:
L T o t a l = L C L I P ( θ ) − c 1 L V F ( θ ) + c 2 H ( π θ ) L ^{Total} =L ^{CLIP} (θ)−c_1L^{VF}(θ)+c_2H(π_θ ) LTotal=LCLIP(θ)−c1LVF(θ)+c2H(πθ)其中, L V F L^{VF} LVF是值函数的均方误差; H H H是策略的熵,鼓励探索; c 1 , c 2 c_1,c_2 c1,c2是权重系数。
二、代码实验
import gym
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
import torch.nn.functional as F# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 超参数设置
GAMMA = 0.99
GAE_LAMBDA = 0.95
CLIP_EPSILON = 0.2
PPO_EPOCHS = 4
BATCH_SIZE = 64
LR_ACTOR = 3e-4
LR_CRITIC = 1e-3
MAX_EPISODES = 2000
HIDDEN_SIZE = 128
EPSILON_DECAY = 0.995
reward_list = []# 策略网络(Actor)
class Actor(nn.Module):def __init__(self, state_dim, action_dim):super().__init__()self.net = nn.Sequential(nn.Linear(state_dim, HIDDEN_SIZE),nn.ReLU(),nn.Linear(HIDDEN_SIZE, HIDDEN_SIZE),nn.ReLU(),nn.Linear(HIDDEN_SIZE, action_dim),nn.Softmax(dim=-1))self.to(device)def forward(self, x):return self.net(x)# 价值网络(Critic)
class Critic(nn.Module):def __init__(self, state_dim):super().__init__()self.net = nn.Sequential(nn.Linear(state_dim, HIDDEN_SIZE),nn.ReLU(),nn.Linear(HIDDEN_SIZE, HIDDEN_SIZE),nn.ReLU(),nn.Linear(HIDDEN_SIZE, 1))self.to(device)def forward(self, x):return self.net(x)# PPO智能体
class PPOAgent:def __init__(self, state_dim, action_dim):self.actor = Actor(state_dim, action_dim)self.critic = Critic(state_dim)self.optimizer = optim.Adam([{'params': self.actor.parameters(), 'lr': LR_ACTOR},{'params': self.critic.parameters(), 'lr': LR_CRITIC}])self.data = []def collect_data(self, state, action, reward, next_state, done, log_prob):"""收集单步经验(保持CPU存储)"""self.data.append((torch.FloatTensor(state).to(device),torch.LongTensor([action]).to(device),reward,torch.FloatTensor(next_state).to(device),done,torch.FloatTensor([log_prob]).to(device)))def compute_gae(self, next_value):"""计算广义优势估计(GAE)"""states = torch.stack([t[0] for t in self.data])rewards = torch.FloatTensor([t[2] for t in self.data]).to(device)dones = torch.FloatTensor([t[4] for t in self.data]).to(device)with torch.no_grad():values = self.critic(states).squeeze()values = torch.cat([values, next_value])advantages = []gae = 0for t in reversed(range(len(rewards))):delta = rewards[t] + GAMMA * values[t + 1] * (1 - dones[t]) - values[t]gae = delta + GAMMA * GAE_LAMBDA * (1 - dones[t]) * gaeadvantages.insert(0, gae)return torch.stack(advantages)def update(self):"""PPO核心更新逻辑"""if not self.data:return# 解压数据并保持GPU张量states = torch.stack([t[0] for t in self.data])actions = torch.stack([t[1] for t in self.data]).squeeze()old_log_probs = torch.stack([t[5] for t in self.data]).squeeze()next_states = torch.stack([t[3] for t in self.data])# 计算最终状态价值with torch.no_grad():next_value = self.critic(next_states[-1])advantages = self.compute_gae(next_value)advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)# 多轮优化for _ in range(PPO_EPOCHS):indices = torch.randperm(len(states)).to(device)for i in range(0, len(states), BATCH_SIZE):idx = indices[i:i + BATCH_SIZE]batch_states = states[idx]batch_actions = actions[idx]batch_old_log_probs = old_log_probs[idx]batch_advantages = advantages[idx]# 计算新策略概率probs = self.actor(batch_states)dist = Categorical(probs)batch_new_log_probs = dist.log_prob(batch_actions)# 计算策略损失ratios = (batch_new_log_probs - batch_old_log_probs).exp()surr1 = ratios * batch_advantagessurr2 = torch.clamp(ratios, 1 - CLIP_EPSILON, 1 + CLIP_EPSILON) * batch_advantagespolicy_loss = -torch.min(surr1, surr2).mean()# 计算价值损失values = self.critic(batch_states).squeeze()value_loss = F.mse_loss(values, values.detach() + batch_advantages)# 计算熵正则项entropy_loss = -dist.entropy().mean()# 总损失total_loss = policy_loss + 0.5 * value_loss + 0.01 * entropy_loss# 反向传播self.optimizer.zero_grad()total_loss.backward()torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.5)torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.5)self.optimizer.step()# 清空数据self.data = []# 训练流程
def train_ppo(env_name, episodes):env = gym.make(env_name)state_dim = env.observation_space.shape[0]action_dim = env.action_space.nagent = PPOAgent(state_dim, action_dim)for episode in range(episodes):state = env.reset()[0]episode_reward = 0done = Falsewhile not done:# 选择动作state_tensor = torch.FloatTensor(state).to(device)with torch.no_grad():action_probs = agent.actor(state_tensor)dist = Categorical(action_probs)action = dist.sample()log_prob = dist.log_prob(action)# 执行动作next_state, reward, terminated, truncated, _ = env.step(action.item())done = terminated or truncated# 收集数据(自动记录GPU张量)agent.collect_data(state, action.item(), reward, next_state, done, log_prob.item())state = next_stateepisode_reward += rewardif done:agent.update()reward_list.append(episode_reward)# 打印训练进度if (episode + 1) % 10 == 0:avg_reward = np.mean(reward_list[-10:])print(f"回合: {episode + 1}, 奖励: {episode_reward}, 最近10轮平均: {avg_reward:.1f}")env.close()if __name__ == "__main__":env_name = "CartPole-v1"episodes = MAX_EPISODEStrain_ppo(env_name, episodes)# 保存结果并绘图plt.plot(range(episodes), reward_list)plt.xlabel('训练回合')plt.ylabel('回合总奖励')plt.title('PPO在CartPole-v1中的训练表现')plt.grid(True)plt.show()
绘图代码:
import numpy as np
import matplotlib.pyplot as plt# 加载数据(注意路径与图中一致)
dqn_rewards = np.load("dqn_rewards.npy")
REFINORCE_rewards = np.load("REINFORCE_rewards.npy")
ddqn_rewards = np.load("ddqn_rewards.npy")
ppo_rewards = np.load("ppo_rewards.npy")
AC2_rewards = np.load("AC2_rewards.npy")
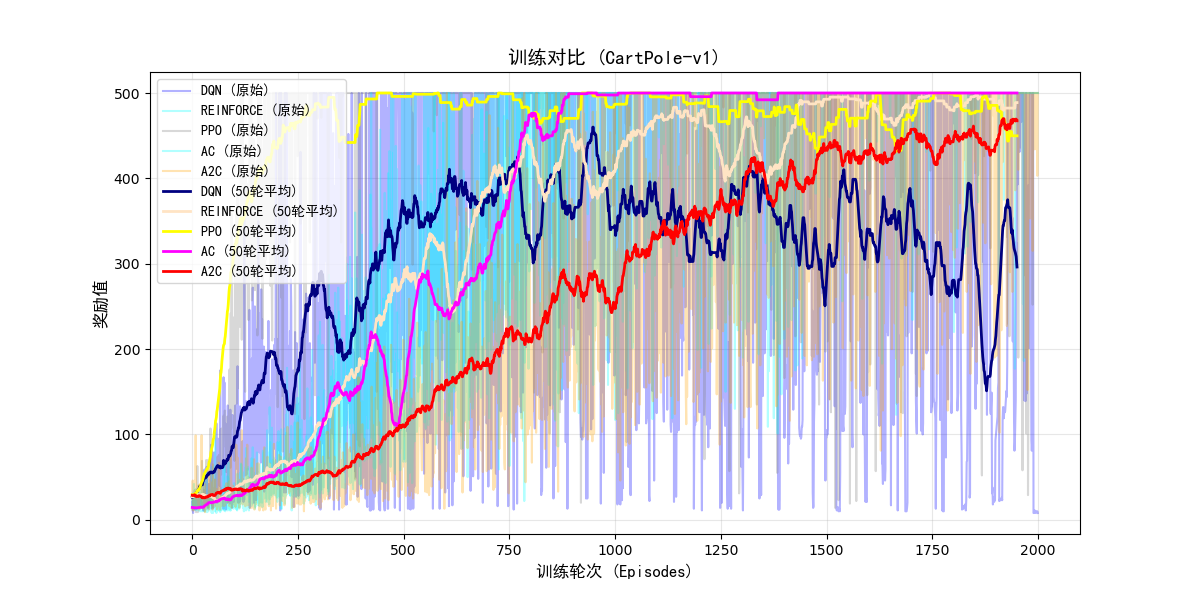
A2C_rewards = np.load("AC_rewards.npy")plt.figure(figsize=(12, 6))# 绘制原始曲线
plt.plot(dqn_rewards, alpha=0.3, color='blue', label='DQN (原始)')
plt.plot(REFINORCE_rewards, alpha=0.3, color='cyan', label='REINFORCE (原始)')
# plt.plot(ddqn_rewards, alpha=0.3, color='orange', label='DDQN (原始)')
plt.plot(ppo_rewards, alpha=0.3, color='gray', label='PPO (原始)')
plt.plot(AC2_rewards, alpha=0.3, color='cyan', label='AC (原始)')
plt.plot(A2C_rewards, alpha=0.3, color='orange', label='A2C (原始)')# 绘制滚动平均曲线(窗口大小=50)
window_size = 50
plt.plot(np.convolve(dqn_rewards, np.ones(window_size)/window_size, mode='valid'),linewidth=2, color='navy', label='DQN (50轮平均)')
plt.plot(np.convolve(REFINORCE_rewards, np.ones(window_size)/window_size, mode='valid'),linewidth=2, color='bisque', label='REINFORCE (50轮平均)')
# plt.plot(np.convolve(ddqn_rewards, np.ones(window_size)/window_size, mode='valid'),
# linewidth=2, color='red', label='DDQN (50轮平均)')
plt.plot(np.convolve(ppo_rewards, np.ones(window_size)/window_size, mode='valid'),linewidth=2, color='yellow', label='PPO (50轮平均)')
plt.plot(np.convolve(AC2_rewards, np.ones(window_size)/window_size, mode='valid'),linewidth=2, color='magenta', label='AC (50轮平均)')
plt.plot(np.convolve(A2C_rewards, np.ones(window_size)/window_size, mode='valid'),linewidth=2, color='red', label='A2C (50轮平均)')# 图表标注
plt.xlabel('训练轮次 (Episodes)', fontsize=12, fontfamily='SimHei')
plt.ylabel('奖励值', fontsize=12, fontfamily='SimHei')
plt.title('训练对比 (CartPole-v1)', fontsize=14, fontfamily='SimHei')
plt.legend(loc='upper left', prop={'family': 'SimHei'})
plt.grid(True, alpha=0.3)# 保存图片(解决原图未保存的问题)
# plt.savefig('comparison.png', dpi=300, bbox_inches='tight')
plt.show()
对比结果图:
相关文章:
强化学习算法系列(六):应用最广泛的算法——PPO算法
强化学习算法 (一)动态规划方法——策略迭代算法(PI)和值迭代算法(VI) (二)Model-Free类方法——蒙特卡洛算法(MC)和时序差分算法(TD) (三)基于动作值的算法——Sarsa算法与Q-Learning算法 (四…...

Vue3 + TypeScript中provide和inject的用法示例
基础写法(类型安全) typescript // parent.component.vue import { provide, ref } from vue import type { InjectionKey } from vue// 1. 定义类型化的 InjectionKey const COUNTER_KEY Symbol() as InjectionKey<number> const USER_KEY Sy…...
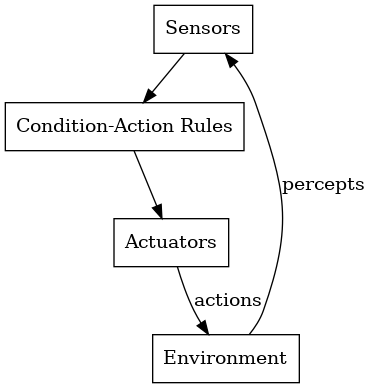
AI Agents系列之AI代理架构体系
1. 引言 智能体架构是定义智能体组件如何组织和交互的蓝图,使智能体能够感知其环境、推理并采取行动。本质上,它就像是智能体的数字大脑——集成了“眼睛”(传感器)、“大脑”(决策逻辑)和“手”(执行器),用于处理信息并采取行动。 选择正确的架构对于构建有效的智能…...

3个实用的脚本
1. Linux 系统清理临时文件脚本 该脚本用于清理系统中 /tmp 目录下超过 7 天的临时文件。 #!/bin/bash# 清理 /tmp 目录下超过 7 天的文件 find /tmp -type f -atime 7 -exec rm -f {} \;# 清理 /var/tmp 目录下超过 7 天的文件 find /var/tmp -type f -atime 7 -exec rm -f {…...
2025海外代理IP测评:Bright Data,ipfoxy,smartproxy,ipipgo,kookeey,ipidea哪个值得推荐?
近年来,随着全球化和跨境业务需求的不断扩大“海外代理IP”逐渐成为企业和个人在多样化场景中的重要工具。无论是进行数据采集、广告验证、社交媒体管理,还是跨境电商平台运营,选择合适的代理IP服务商都显得尤为重要。然而,市场上…...

条款13:以对象管理资源
什么是资源?内存?没错但是内存只是我们需要管理众多资源的一种,资源还包括数据的连接,文件描述符,互斥锁,网络套接字,不管哪种资源他都是从系统中获取的,当你不在需要他的时候是要还…...
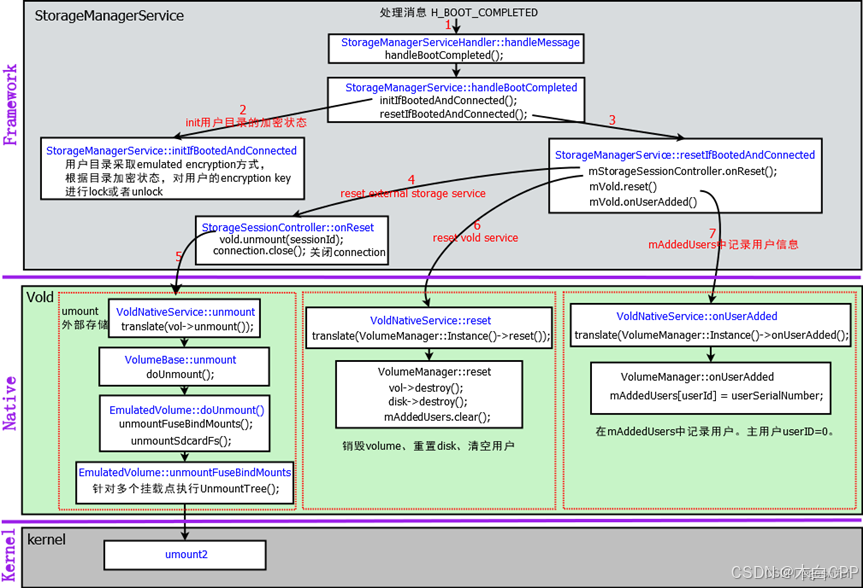
Android守护进程——Vold (Volume Daemon)
简介 介绍:Vold 是用来管理 android 系统的存储设备,如U盘、SD卡、磁盘等移动设备的热插拔、挂载、卸载、格式化 框架结构:Vold 在系统中以守护进程存在,是一个单独的进程。处于Kernel和Framework之间,是两个层级连接…...
vue3+vite 实现.env全局配置
首先创建.env文件 VUE_APP_BASE_APIhttp://127.0.0.1/dev-api 然后引入依赖: pnpm install dotenv --save-dev 引入完成后,在vite.config.js配置文件内加入以下内容: const env dotenv.config({ path: ./.env }).parsed define: { // 将…...
AI 组件库是什么?如何影响UI的开发?
AI组件库是基于人工智能技术构建的、面向用户界面(UI)开发的预制模块集合。它们结合了传统UI组件(如按钮、表单、图表)与AI能力(如机器学习、自然语言处理、计算机视觉),旨在简化开发流程并增强…...

【AI模型学习】关于写论文——论文的审美
文章目录 一、“补丁法”(Patching)1.1 介绍1.2 方法论1.3 实例 二、判断工作的价值2.1 介绍2.2 详细思路2.3 科研性vs工程性 三、novelty以及误区3.1 介绍3.2 举例 看了李沐老师的读论文系列后,总结三个老师提到的有关课题研究和论文写作的三…...

OpenCV day6
函数内容接上文:OpenCV day4-CSDN博客 , OpenCV day5-CSDN博客 目录 平滑(模糊) 25.cv2.blur(): 26.cv2.boxFilter(): 27.cv2.GaussianBlur(): 28.cv2.medianBlur(): 29.cv2.bilateralFilter(): 锐…...

AI的出现,是否能替代IT从业者?
一、技术能力的边界:AI 能做什么? 自动化基础任务 代码生成:GitHub Copilot、天工 AI 等工具可自动生成 80% 以上的重复性代码,例如根据自然语言描述生成完整的网站前端代码。测试与运维:AI 驱动的测试工具能自动生成测…...
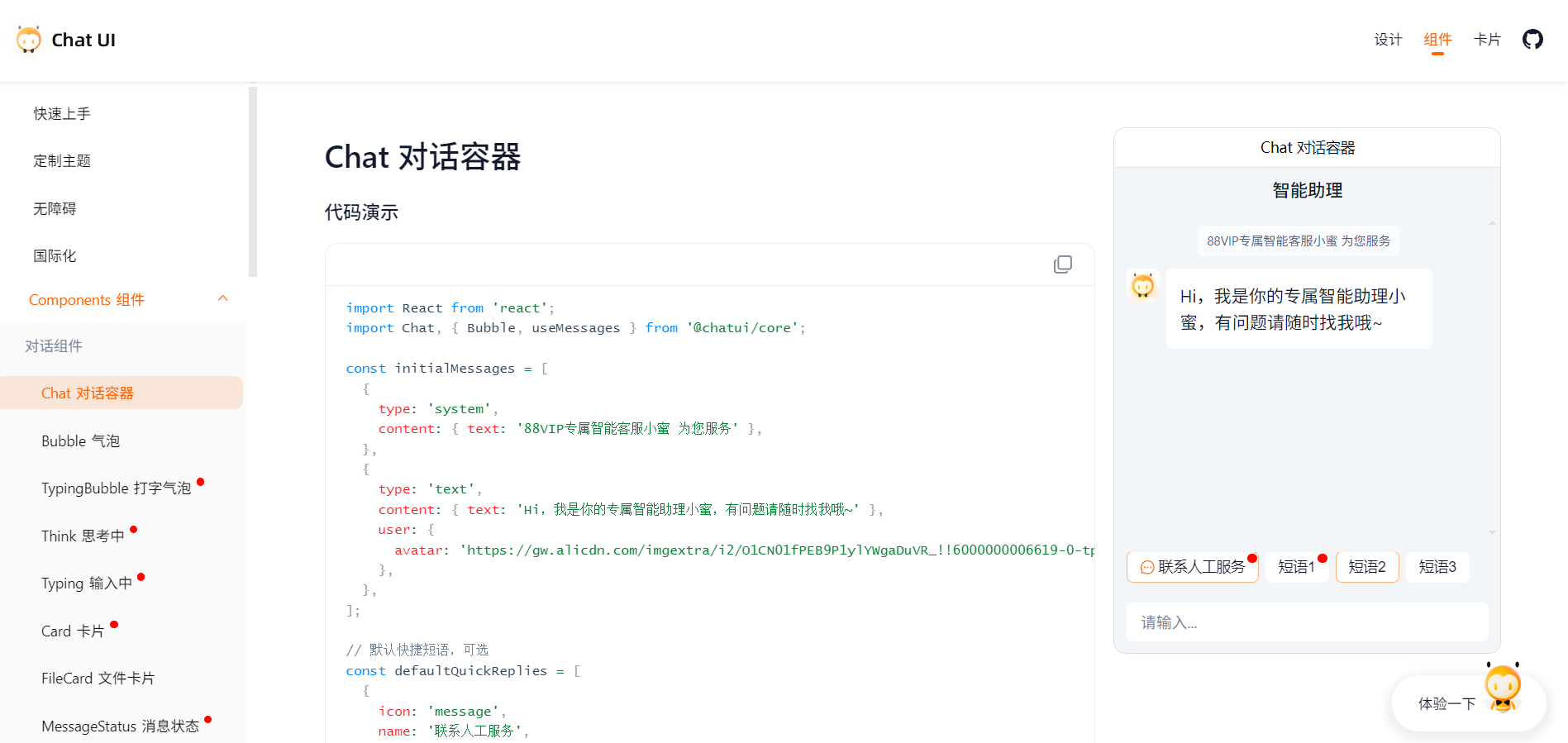
【AI飞】AutoIT入门七(实战):python操控autoit解决csf视频批量转换(有点难,AI都不会)
背景: 终极目标:通过python调用大模型,获得结果,然后根据返回信息,控制AutoIT操作电脑软件,执行具体工作。让AI更具有执行力。 已完成部分: 关于python调用大模型的,可以参考之前的…...

MARA/MARC表 PSTAT字段
最近要开发一个维护物料视图的功能。其中PSTAT字段是来记录已经维护的视图的。这里记录一下视图和其对应的字母。 MARA还有个VPSTA(完整状态)字段,不过在我试的时候每次PSTAT出现一个它就增加一个,不知道具体是为什么。 最近一直…...

《探秘鸿蒙分布式软总线:开启无感发现与零等待传输新时代》
在数字化浪潮中,设备之间的互联互通成为构建智能生态的关键。鸿蒙系统中的分布式软总线技术,宛如一座桥梁,让各种智能设备紧密相连。尤其是其实现的设备间无感发现和零等待传输功能,更是为用户带来了前所未有的便捷体验࿰…...

学习型组织与系统思考
真正的学习型组织不是只关注个人的学习,而是关注整个系统的学习。—彼得圣吉 在这两年里,越来越多的企业开始询问是否可以将系统思考的内容内化给自己的内训师,进而在公司内部进行教学。我非常理解企业这样做的动机,毕竟内部讲师…...
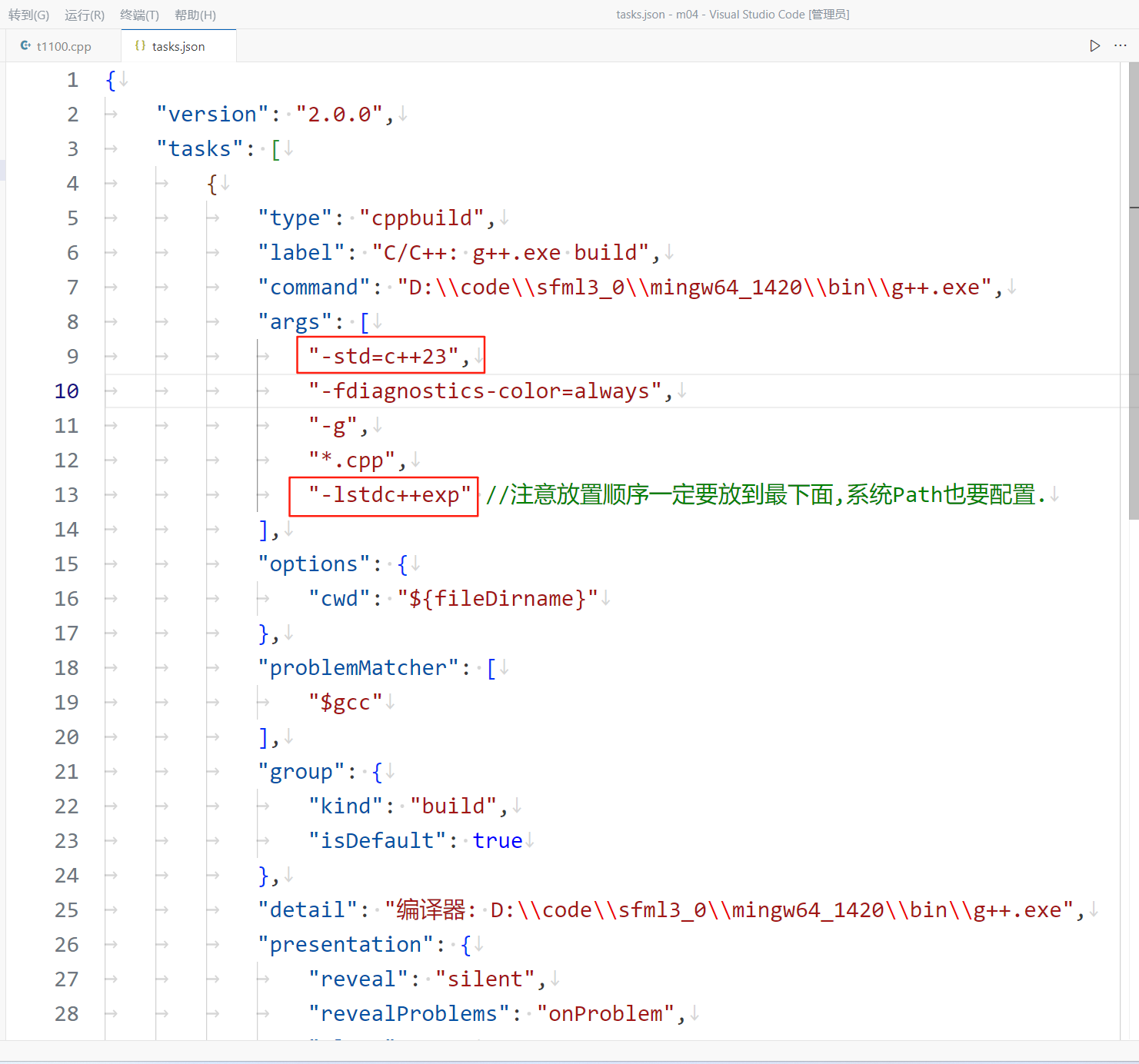
支持mingw g++14.2 的c++23 功能print的vscode tasks.json生成调试
在mingw14.2版本中, print库的功能默认没有开启, 生成可执行文件的tasks.json里要显式加-lstdcexp, 注意放置顺序. tasks.json (支持mingw g14.2 c23的print ) {"version": "2.0.0","tasks": [{"type": "cppbuild","…...
守护者进程小练习
守护者进程含义 定义:守护进程(Daemon)是运行在后台的特殊进程,独立于控制终端,周期性执行任务或等待事件触发。它通常以 root 权限运行,名称常以 d 结尾(如 sshd, crond)。 特性&a…...
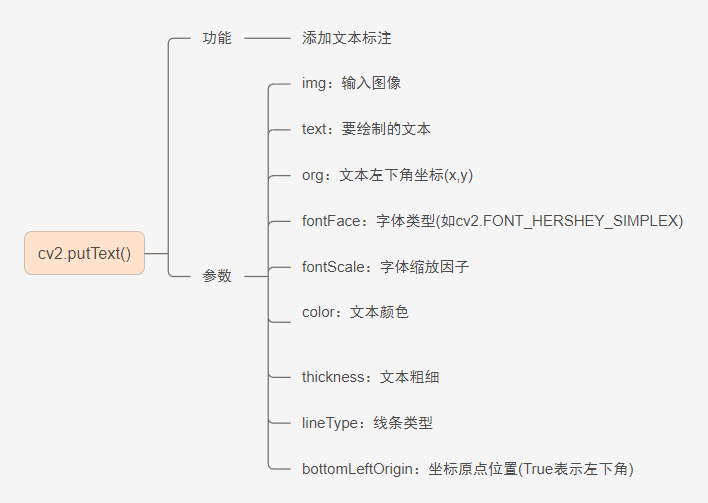
opencv函数展示3
一、图像平滑(模糊) 线性滤波(速度快): 1.cv2.blur() 2.cv2.boxFilter() 3.cv2.GaussianBlur() 非线性滤波(速度慢但效果好): 4.cv2.medianBlur() 5.cv2.bilateralFilter() 二、锐…...

环境搭建与入门:Flutter SDK安装与配置
环境搭建与入门:Flutter SDK安装与配置 一、Flutter开发环境概述 1.1 Flutter开发环境组成 Flutter开发环境主要包含以下几个关键组件: Flutter SDK:Flutter的核心开发工具包Dart SDK:Flutter使用的编程语言环境IDE/编辑器&am…...

linux驱动之poll
驱动中 poll 实现 在用户空间实现事件操作的一个主要实现是调用 select/poll/epoll 函数。那么在驱动中怎么来实现 poll 的底层呢? 其实在内核的 struct file_operations 结构体中有一个 poll 成员,其就是底层实现的接口函数。 驱动中 poll 函数实现原…...
遥感技术赋能电力设施监控:应用案例篇
目前主流的电力巡检手段利用无人机能够通过设定灵活航线进行低空飞行、搭载不同的采集设备,能够从不同角度对输电线进行贴近拍摄,但缺陷是偏远山区无人机飞行技术要求高,成本高,且飞行的无人机也可能会对输电线产生破坏。 星图云开…...
SpringAI+DeepSeek大模型应用开发——5 ChatPDF
ChatPDF 知识库 RAG检索增强 由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题: 知识数据比较落后,往往是几个月之前的;不包含太过专业领域或者企业私有的数据; 为了解决…...

yolov8 框架自带模型体验功能
简介 YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务。 YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,…...

柴油机气缸体顶底面粗铣组合机床总体及夹具设计
一、引言 柴油机气缸体是柴油机的关键部件,其顶底面的加工精度直接影响气缸体的装配质量和柴油机的性能。粗铣是气缸体顶底面加工的重要工序,设计一款高效、精确的粗铣组合机床及配套夹具,对于提高气缸体加工效率和质量具有重要意义。 二、…...

SpringBoot - Minio
1、简介 MinIO 是一个开源的对象存储服务器,用于存储和管理大规模的非结构化数据,例如图像、视频、日志文件、备份和容器镜像。MinIO 旨在提供高性能、高可用性、可扩展性和易用性的对象存储解决方案,适用于私有云、公共云和混合云环境。2、…...

Android --- SystemUI启动流程
1.main 函数入口,调用SystemServer().run()方法 代码路径:frameworks/base/services/java/com/android/server/SystemServer.java 2.run 方法中有3种服务的启动,我们主要看StartOtherService 代码路径:frameworks/base/services/java/com/android/se…...

docker镜像被覆盖了怎么办?通过sha256重新上传镜像
如果一个镜像通过相同的标签被重新推送(覆盖),那么旧的镜像内容虽然在 Docker 的存储中可能仍然存在,但通过原来的标签将无法直接访问到它。Docker 和 Harbor 默认情况下不会自动删除旧的镜像层,除非进行了垃圾回收&am…...
Java观察者模式在Android开发中的应用详解)
(二十六)Java观察者模式在Android开发中的应用详解
Java观察者模式在Android开发中的应用 观察者模式(Observer Pattern)是一种行为型设计模式,它定义了一种一对多的依赖关系,使得多个观察者对象可以同时监听一个主题对象。当主题对象的状态发生变化时,所有注册的观察者…...

【SpringMVC】深入解析自定义拦截器、注册配置拦截器、拦截路径方法及常见拦截路径、排除拦截路径、拦截器的执行流程
拦截器 上个章节我们完成了强制登录的功能, 后端程序根据Session来判断用户是否登录, 但是实现方法是比较麻烦的: 需要修改每个接口的处理逻辑需要修改每个接口的返回结果接口定义修改, 前端代码也需要跟着修改 有没有更简单的办法, 统一拦截所有的请求, 并进行Se…...