【AI模型学习】关于写论文——论文的审美
文章目录
- 一、“补丁法”(Patching)
- 1.1 介绍
- 1.2 方法论
- 1.3 实例
- 二、判断工作的价值
- 2.1 介绍
- 2.2 详细思路
- 2.3 科研性vs工程性
- 三、novelty以及误区
- 3.1 介绍
- 3.2 举例
看了李沐老师的读论文系列后,总结三个老师提到的有关课题研究和论文写作的三个视频。
一、“补丁法”(Patching)
1.1 介绍
定义:
补丁法是指:在现有研究系统或方法中,找到其薄弱点、局限性或不合理的地方,并提出一个“补丁式”的改进。
它不是从零发明一个全新的系统,而是在前人的基础上“打补丁”、“修bug”,以实现更优的效果或更广泛的适应性。
常见应用场景:
- 现有方法无法处理极端情况
- 举例:一个分类器在 imbalanced dataset 上表现不佳,可以设计新的 loss function 或 sampling 方法作为补丁。
- 某个模块性能明显瓶颈
- 举例:Transformer 中 attention 模块计算量大,于是有人提出 Linformer、Performer ——这其实都是对原始方法的补丁。
- 训练不稳定 or 收敛慢
- 举例:GAN 的训练困难,提出 Wasserstein GAN、Spectral Norm 等等,这些就是不断在训练流程上打补丁。
- 功能模块缺失或泛化性差
- 举例:原始模型不具备对抗鲁棒性,于是研究者设计 adversarial training 机制,这也是一种补丁行为。
1.2 方法论
不一定要“从0到1”地创造,只要你能指出已有方法的痛点 + 提出解决方案,这就足够形成一个研究 idea。
很多被顶会接受的论文,本质上就是一个“精致的补丁”:
- 洞察到别人忽略的一个角落;
- 用精巧的方式修补;
- 实验效果显著提升;
- 把过程讲得清楚,这就够了。
如何实践“补丁法”找想法?
| 步骤 | 行动建议 |
|---|---|
| ① 阅读前沿论文 | 特别关注“Limitations”部分、实验失败案例、baseline 不强时作者的解释 |
| ② 尝试复现 | 在复现中你会发现模型不稳定/效果差的地方,这些都是补丁机会 |
| ③ 分析失败场景 | 比如模型在低资源/高噪声场景下性能退化,为何?可以怎么改? |
| ④ 小改进大价值 | 哪怕只是一个改进的激活函数、损失项、新的训练 trick,也可能成为一个论文的主体 |
1.3 实例
Transformer 相关
补丁:自注意力太慢(计算复杂度是 O(n²))
- 问题:原始 Transformer 的 self-attention 在长序列上计算量巨大。
- 补丁例子:
- Performer:提出 kernel-based 近似 attention,把 O(n²) 降到 O(n)。
- Linformer:引入低秩矩阵逼近,用线性复杂度计算 attention。
- Longformer:局部窗口 + 全局 token 机制,提升长文本处理能力。
补丁:缺乏位置感知能力
- 问题:Transformer 自身没有位置信息。
- 补丁例子:
- Sinusoidal Positional Encoding(原始论文);
- Relative Positional Encoding(Transformer-XL);
- Rotary Position Embedding(RoPE in Llama)→ 这就是不断“打补丁”的过程。
自监督学习(如 MoCo、SimCLR)
补丁:contrastive learning 太依赖负样本,且容易过拟合 queue 中的表示
- 问题:Memory Bank/Queue 中的向量更新不同步
- 补丁例子:
- MoCo(Momentum Contrast):引入 momentum encoder 作为补丁,解决队列更新不一致问题。
- BYOL:干脆去掉负样本,构造对比框架的新结构。
- SimSiam:再砍一刀,连 momentum encoder 也砍掉了。都算是对 SimCLR 的“补丁”。
优化器 & 损失函数改进
补丁:Adam 在 batch size 很大时效果变差
- 问题:Adam 在 large batch 上不稳定
- 补丁例子:
- LAMB Optimizer(用于 BERT 预训练):针对 large batch 的适配
- RAdam(Rectified Adam):通过 bias correction 的“补丁”,解决 early step variance 大的问题。
生物信息学 / 结构预测领域
补丁:AlphaFold 需要 MSA,但有些蛋白质找不到同源序列
- 问题:MSA-free 情况下模型退化
- 补丁例子:
- ESMFold(Meta):使用蛋白语言模型 embedding,绕过对 MSA 的依赖。
- OmegaFold:改进结构模块处理长链段缺失情况。
总结思路模板
| 步骤 | 解释 |
|---|---|
| ① 读主流方法 | 阅读经典模型的结构和实验设置 |
| ② 找痛点 | 性能瓶颈?效率低?训练难?泛化差? |
| ③ 局部修改 | 改 loss、加正则、改 attention、改 encoder、改初始化… |
| ④ 做实验 | 补丁有用 → 就能发 paper! |
二、判断工作的价值
2.1 介绍
核心模型:
研究价值 = 新颖性 × 有效性 × 问题规模
具体说明:
- 新颖性(Novelty) 你的研究是否在方法、问题或视角上具有创新性
- 有效性(Effectiveness) 你的方法是否在实验或理论上取得了显著的改进
- 问题规模(Problem Size) 你解决的问题在学术界或工业界的重要性如何
2.2 详细思路
总公式:
研究价值 = 新颖性 × 有效性 × 问题规模
这是一个乘法模型,意味着:
- 三者中任何一项为 0,整体价值都趋近于 0;
- 想做出高价值工作,三者都不能忽视;
- 如果某一项不突出,你需要用其他项来弥补(例如“方法普通但问题超重要”)。
新颖性(Novelty)
定义:
研究中是否有原创性的点?是不是别人没有做过的、想过的或者做不到的?
表现形式:
- 提出新的研究问题(问题级别的创新);
- 提出新的方法/模型架构(技术级别的创新);
- 跨领域迁移方法(例如把 NLP 方法用在蛋白质序列上);
- 给出新的解释、机制、视角(理论层面的创新);
- 创建一个新的数据集/评估指标,从而定义新的任务。
正例:
- Vision Transformer(ViT):直接把 transformer 引入 CV,是架构的新颖性;
- DALL·E:文本 → 图像生成任务的定义就是新颖的;
- AlphaFold:结构预测早就有,但它是首次用 end-to-end 深度网络大规模突破。
常见误区(提到的“新颖性误解”):
- 以为“微调一下 loss 就是创新”;
- 用了两个旧模型叠加起来,不是新颖,而是“组合技巧”;
- 语言包装成“XXX++”,实质没变。
提升方法:
- 阅读最新论文,看别人解决什么问题,用什么套路;
- 看论文的“Limitations”部分,很多 idea 都藏在“我们未来会做……”;
- 反问:“如果我是审稿人,哪里是亮点?”
有效性(Effectiveness)
定义:
你的方法/模型是不是真的有效,对比已有方法有显著改进或实证支持。
评估方式:
- 实验性能提升(accuracy, F1, ROC-AUC, perplexity 等);
- 资源效率提升(速度、参数量、内存占用);
- 理论收敛性、可解释性提升;
- 消融实验支持某个组件有效。
正例:
- MoCo 通过 queue+momentum encoder 改进对比学习的稳定性,实验明显优于 SimCLR;
- CLIP 训练时不需要细致标注,但性能甚至超过有监督模型;
- ESMFold 放弃了 MSA,结构预测依然准确,是效率与效果的突破。
常见误区:
- “我们的模型结果比别人好 0.1%,但波动很大”——不稳定、不可重复;
- “我们用新的数据集,效果很好”——但缺乏 baseline 比较;
- “我们在一个领域有效,但没有验证泛化性”。
提升方法:
- 做多个 baseline,对比经典方法;
- 做消融实验,突出自己的模块带来了哪些改变;
- 做不同数据集或真实任务验证,展示通用性。
问题规模(Problem Size)
定义:
你研究的问题是不是重要、常见、痛点明显?有没有人“关心”它?
表现形式:
- 是学术界、工业界都关心的问题(比如“多模态对齐”、“蛋白质结构预测”、“LLM memory”);
- 是很多方法解决不了的问题,或者影响范围大(例如高能耗、训练太慢、可解释性差);
- 是可能带来应用层变革的问题(如人机交互、多语言理解、药物生成等);
正例:
- ChatGPT:解决了通用语言对话问题,影响巨大;
- SAM(Segment Anything):提出通用分割框架,是图像领域的重要任务;
- Graphormer:图结构 → Transformer 表达,是图学习的重要突破。
常见误区:
- “我们做的是一个没人关注的小众问题”——可能被视为价值有限;
- “我们的问题只是已有问题换个壳”;
- “我们只是拿已有模型测了一个冷门 dataset”。
提升方法:
- 多读 survey,看哪些领域是“主战场”;
- 参加会议,看哪些问题是热议话题;
- 跟企业沟通,看哪些是“工业界真实痛点”。
| 问题 | Novelty | Effectiveness | Problem Size | 综合价值 |
|---|---|---|---|---|
| 改进一个 loss 提高 0.3% | 弱(小改) | 较强 | 小问题 | ** |
| 用 ViT 做蛋白质序列分析 | 强(跨领域) | 效果好 | 蛋白是大问题 | ***** |
| 把 GNN 应用于交通流预测 | 有视角 | 待验证 | 现实意义强 | *** |
| 提出一个理论收敛分析方法 | 理论新 | 需实验支持 | 领域是否关心? | *** |
2.3 科研性vs工程性
一个项目的“科研性”和“工程性”怎么理解?
科研性(Scientific value)
- 追求:新发现、新方法、新理论
- 关键词:创新性、理论性、发表论文
- 常问问题:
- 有没有人做过这个问题?
- 我的方法/视角/结果有什么新意?
- 结果表现:
- 发论文、被引用、提出新概念或方法
例子:提出一种全新的GNN结构、构建一个蛋白结构预测的新理论、提出新的对比学习loss
工程性(Engineering value)
- 追求:好用、稳定、效率高
- 关键词:实用性、部署性、解决问题
- 常问问题:
- 能不能跑起来?能不能快?能不能稳定?
- 真实业务中有没有用?
- 结果表现:
- 模型上线、性能指标优秀、用户使用满意
例子:用蒸馏压缩模型上线在边缘设备上;构建一个自动蛋白结构分析平台;让一个原本要跑1小时的任务变成1分钟
| 维度 | 科研性 | 工程性 |
|---|---|---|
| 目标 | 提出新知识 | 解决实际问题 |
| 输出 | 论文、新理论、新算法 | 稳定系统、工具、产品 |
| 常见语境 | “这是一个创新点” | “这个能不能上线?” |
| 评价标准 | 有新意,有影响力 | 有用,好用,跑得动 |
三、novelty以及误区
Michael J. Black在其博客文章《Novelty in Science》中对科学研究中新颖性常见误解进行讨论。这篇文章旨在帮助审稿人和研究者更准确地理解和评估研究的创新性。
3.1 介绍
-
将新颖性等同于技术创新
许多审稿人误以为,只有在技术细节上有所突破的研究才具有新颖性。然而,创新可以体现在多个方面- 数据集创建一个在功能或用途上前所未有的数据集,即使使用的是已知的方法
- 方法应用将现有方法应用于新的领域或问题,产生新的见解
- 简化复杂性用简单的方法替代复杂的算法,提供新的理解
因此,在评估研究的新颖性时,应超越技术细节,关注其在更广泛层面的创新
-
将新颖性等同于惊喜
新颖性常被误认为是带来惊喜的结果。然而,真正的创新往往在事后看起来“显而易见”审稿人应认识到,创新的价值在于首次提出这一想法的过程,而非其在被理解后的直观性 -
将新颖性等同于实用性或价值
并非所有的新想法都是立即有用的有时,新的方法或理论在短期内难以评估其价值,但这并不意味着它们缺乏新颖性审稿人应谨慎评估新想法的潜在影响,而不是仅根据其当前的实用性做出判断 -
将新颖性等同于难度
有些人认为,只有在研究过程中经历了极大困难的工作才算创新然而,提出一个简单而有效的想法,同样需要深厚的理解和洞察力审稿人应重视那些通过简化复杂问题而带来新见解的研究 -
忽视新颖性的多样性
新颖性不仅限于上述几个方面它还可以体现在- 跨学科的连接将不同领域的概念结合,产生新的理论框架
- 理论的新解释对现有现象提供新的解释或视角
- 方法论的革新引入新的研究方法或实验设计
因此,评估新颖性时,应全面考虑研究在多个维度上的创新
3.2 举例
1.将新颖性误解为复杂性(Complexity)
误解解释:
许多人以为研究越复杂、数学越多、细节越难,就越新颖。
正确认知:
一个简单、优雅的想法,如果别人没提出过,它就具备真正的新颖性,哪怕实现细节非常简单。
正面例子:
-
ReLU 激活函数(2011)
- ReLU (
max(0,x)) 是非常简单的激活函数,早期被认为“太傻”,但其简洁性大幅提升训练效率,迅速取代 sigmoid / tanh。 - ➜ 这不是复杂的数学推导,但却是极具影响力的创新。
- ReLU (
-
BatchNorm(2015)
- 想法非常简单:normalize 中间层的分布,有效缓解梯度消失。
- 当时很多人觉得“不过是加了一行代码”,结果成为基础组件。
反例:
- 过度设计网络结构,写几十页数学公式,但最终改进效果微小,仅提升 0.1%。
- ➜ 这种论文看似“高深”,但实际缺乏真正新意。
- 将新颖性误解为技术难度(Difficulty)
误解解释:
有些人觉得:必须技术上很难做、要调几个月才能跑起来的项目,才算有贡献。
正确认知:
真正的新颖性在于发现新的切入点或机制,而不是工程难度有多大。
正面例子:
-
MoCo(2019)
- 用一个动量 encoder + queue 的结构解决对比学习中的负样本一致性问题。
- 技术难度不大,实现也很“清爽”,但 idea 很聪明,是认知上的突破。
-
SimSiam(2020)
- 用一小段 encoder + predictor,完全去掉负样本,比 MoCo 还精简。
- 没有任何 fancy trick,但模型工作得很好。
反面例子:
- 在工业界实现一个部署 pipeline、写了很多脚本和系统组件,这属于“工程难度高”,但如果没有新方法或原理创新,学术价值有限。
- 将新颖性误解为惊喜感(Surprise)
误解解释:
看到一个 idea,“啊,这我也能想到!”就以为它不新颖了。
正确认知:
新颖性不是“听起来惊艳”,而是别人没先想到。事后看起来显而易见,是好想法的标志。
正面例子:
-
Transformer(2017)
- “Self-attention 替代 RNN”听起来好像理所当然,但之前没人这样做过。
- 一旦提出,全世界都觉得“早该这样了”——这正说明它的合理性。
-
ViT(2020)
- “把图像切 patch 扔给 Transformer”听起来不复杂,但一开始没人敢做。
- 真正做出来并跑出好结果后,才变成主流。
反面例子:
- 审稿人看到你用简单方法解决了老问题,觉得“这太 obvious,不够 novel”。
- ➜ 如果之前没人这样做过,这种质疑本身就错了。
- 将新颖性误解为技术创新(Technical novelty)
误解解释:
只有提出新算法、架构才算创新。
正确认知:
创新可以来自问题定义、应用转化、数据设计、评估标准等多个维度。
正面例子:
-
AlphaFold2(2021)
- 真正的创新不完全在模型结构,而在整个 pipeline:引入 Evoformer、三角注意力模块、大数据集训练、结构模块等。
- 是一整套集成创新,不只是某个技术点。
-
CLIP(2021)
- 核心 idea 是“用对比学习把图片和文字拉在一起”,方法上并不复杂。
- 但它定义了一个“文本指导图像表示学习”的新范式,是任务定义上的突破。
-
SAM(Segment Anything Model, 2023)
- 本质上是一个大规模提示驱动的图像分割器。方法不是全新,任务设计和 scale 的贡献是新颖的点。
反例:
- “我们提出了 LayerNorm++、Transformer++、ResNet-xxx”:
- ➜ 如果只是小改进而没有明确的问题背景或创新动机,就不一定有意义。
- 将新颖性误解为实用性(Usefulness)
误解解释:
有些人认为:这个研究“暂时没啥用”,所以不值得做或不能发表。
正确认知:
科学中的新颖性不必立即有用,它的价值可能体现在未来或基础理论发展中。
正面例子:
-
GAN(2014)
- 最初只是一个对抗训练框架,没人知道能生成什么。
- 几年后变成图像生成的基石。
-
Transformer(2017)
- 一开始只是做机器翻译,后来才成为 NLP、CV、多模态的核心。
-
GPT(2018)
- 早期版本没什么实际应用,被嘲讽为“过拟合 Wikipedia 的模型”;
- 今天变成通用大模型,重塑 AI 工业。
反面例子:
- 审稿人说“这个 idea 没有明显应用场景”,就直接否决论文,这种是对科研评价的不准确。
总结表格
| 误解类型 | 正确认知 | 代表正例 | 错误案例或评价方式 |
|---|---|---|---|
| 复杂性 | 简单也能新颖 | ReLU、BatchNorm | “你这个太简单” |
| 技术难度 | 不难也有贡献 | MoCo、SimSiam | “你调代码调得不够久” |
| 惊喜感 | 显然≠不新 | Transformer、ViT | “这不是很 obvious 吗?” |
| 技术创新 | 不限于算法 | CLIP、SAM | “你方法没变,不 novel” |
| 实用性 | 不一定立马实用 | GAN、GPT | “现在没用,不给你 accept” |
相关文章:

【AI模型学习】关于写论文——论文的审美
文章目录 一、“补丁法”(Patching)1.1 介绍1.2 方法论1.3 实例 二、判断工作的价值2.1 介绍2.2 详细思路2.3 科研性vs工程性 三、novelty以及误区3.1 介绍3.2 举例 看了李沐老师的读论文系列后,总结三个老师提到的有关课题研究和论文写作的三…...

OpenCV day6
函数内容接上文:OpenCV day4-CSDN博客 , OpenCV day5-CSDN博客 目录 平滑(模糊) 25.cv2.blur(): 26.cv2.boxFilter(): 27.cv2.GaussianBlur(): 28.cv2.medianBlur(): 29.cv2.bilateralFilter(): 锐…...

AI的出现,是否能替代IT从业者?
一、技术能力的边界:AI 能做什么? 自动化基础任务 代码生成:GitHub Copilot、天工 AI 等工具可自动生成 80% 以上的重复性代码,例如根据自然语言描述生成完整的网站前端代码。测试与运维:AI 驱动的测试工具能自动生成测…...
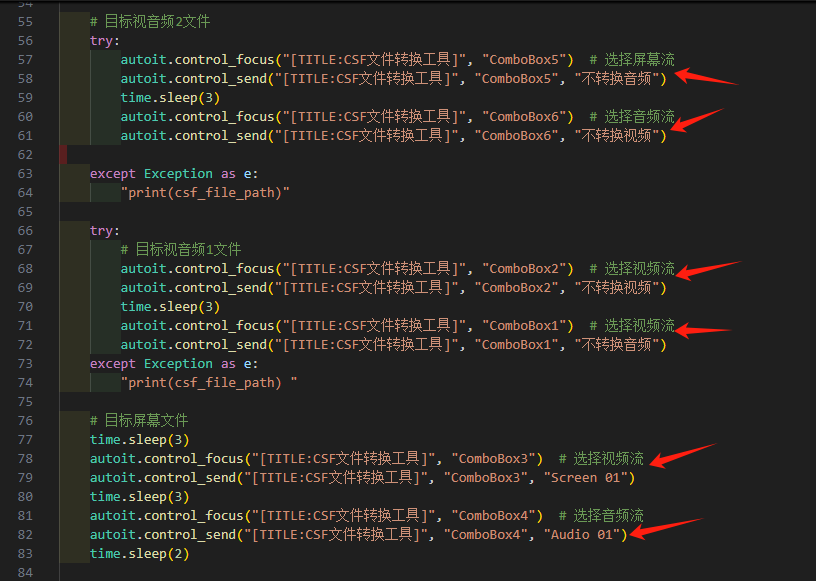
【AI飞】AutoIT入门七(实战):python操控autoit解决csf视频批量转换(有点难,AI都不会)
背景: 终极目标:通过python调用大模型,获得结果,然后根据返回信息,控制AutoIT操作电脑软件,执行具体工作。让AI更具有执行力。 已完成部分: 关于python调用大模型的,可以参考之前的…...

MARA/MARC表 PSTAT字段
最近要开发一个维护物料视图的功能。其中PSTAT字段是来记录已经维护的视图的。这里记录一下视图和其对应的字母。 MARA还有个VPSTA(完整状态)字段,不过在我试的时候每次PSTAT出现一个它就增加一个,不知道具体是为什么。 最近一直…...

《探秘鸿蒙分布式软总线:开启无感发现与零等待传输新时代》
在数字化浪潮中,设备之间的互联互通成为构建智能生态的关键。鸿蒙系统中的分布式软总线技术,宛如一座桥梁,让各种智能设备紧密相连。尤其是其实现的设备间无感发现和零等待传输功能,更是为用户带来了前所未有的便捷体验࿰…...

学习型组织与系统思考
真正的学习型组织不是只关注个人的学习,而是关注整个系统的学习。—彼得圣吉 在这两年里,越来越多的企业开始询问是否可以将系统思考的内容内化给自己的内训师,进而在公司内部进行教学。我非常理解企业这样做的动机,毕竟内部讲师…...
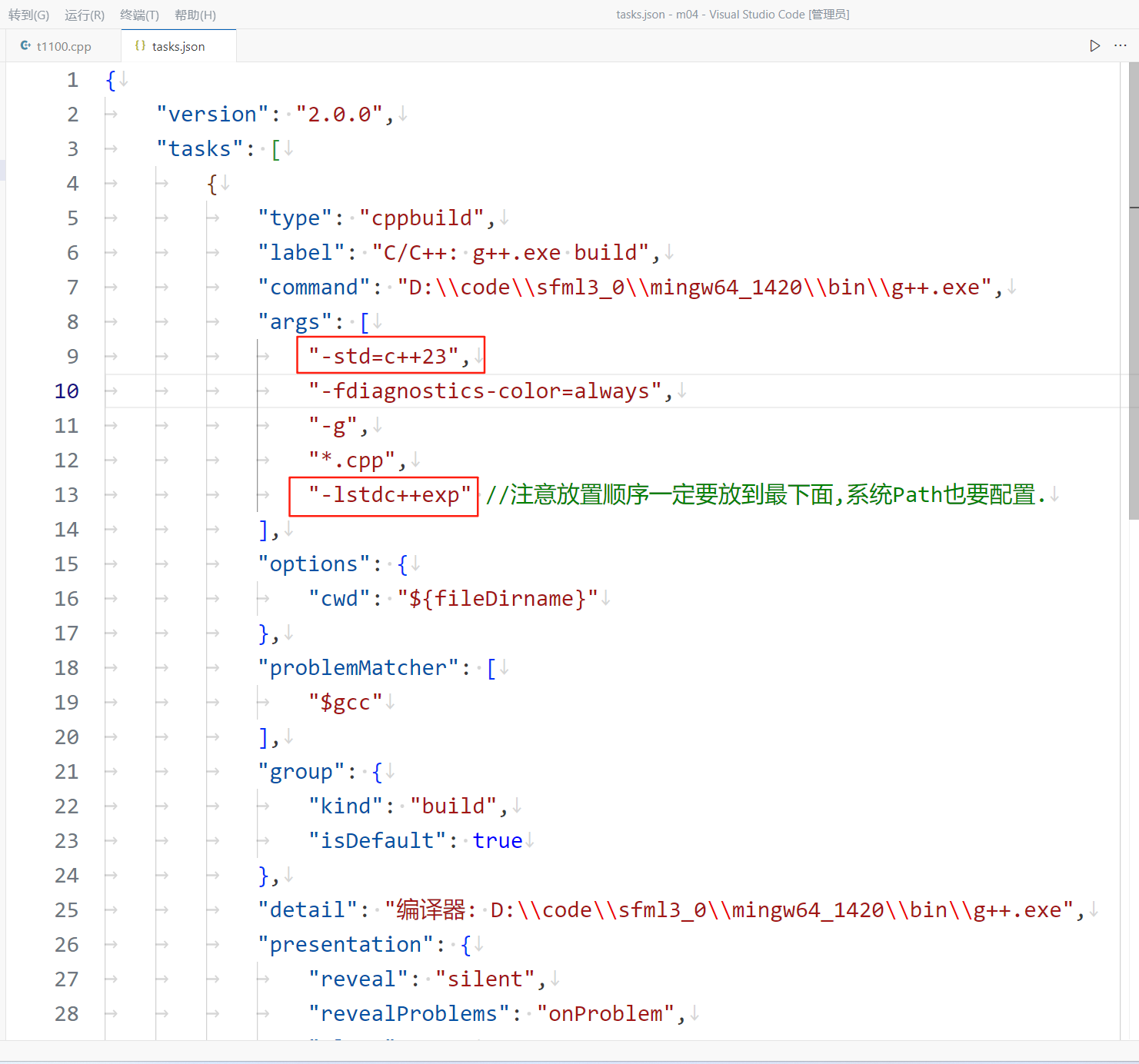
支持mingw g++14.2 的c++23 功能print的vscode tasks.json生成调试
在mingw14.2版本中, print库的功能默认没有开启, 生成可执行文件的tasks.json里要显式加-lstdcexp, 注意放置顺序. tasks.json (支持mingw g14.2 c23的print ) {"version": "2.0.0","tasks": [{"type": "cppbuild","…...
守护者进程小练习
守护者进程含义 定义:守护进程(Daemon)是运行在后台的特殊进程,独立于控制终端,周期性执行任务或等待事件触发。它通常以 root 权限运行,名称常以 d 结尾(如 sshd, crond)。 特性&a…...
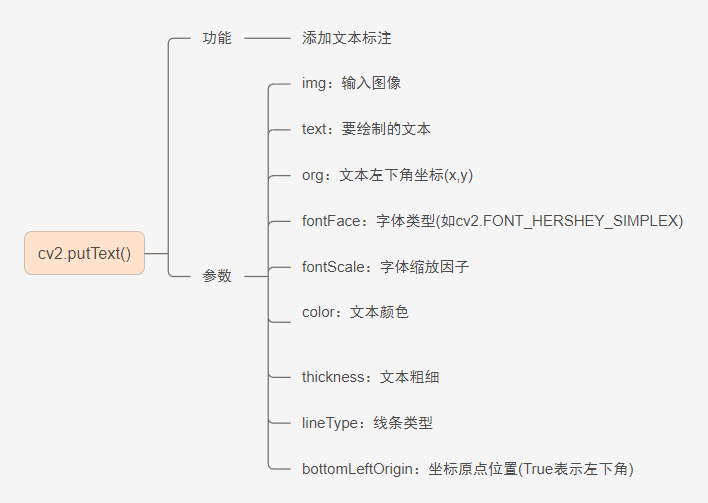
opencv函数展示3
一、图像平滑(模糊) 线性滤波(速度快): 1.cv2.blur() 2.cv2.boxFilter() 3.cv2.GaussianBlur() 非线性滤波(速度慢但效果好): 4.cv2.medianBlur() 5.cv2.bilateralFilter() 二、锐…...

环境搭建与入门:Flutter SDK安装与配置
环境搭建与入门:Flutter SDK安装与配置 一、Flutter开发环境概述 1.1 Flutter开发环境组成 Flutter开发环境主要包含以下几个关键组件: Flutter SDK:Flutter的核心开发工具包Dart SDK:Flutter使用的编程语言环境IDE/编辑器&am…...

linux驱动之poll
驱动中 poll 实现 在用户空间实现事件操作的一个主要实现是调用 select/poll/epoll 函数。那么在驱动中怎么来实现 poll 的底层呢? 其实在内核的 struct file_operations 结构体中有一个 poll 成员,其就是底层实现的接口函数。 驱动中 poll 函数实现原…...
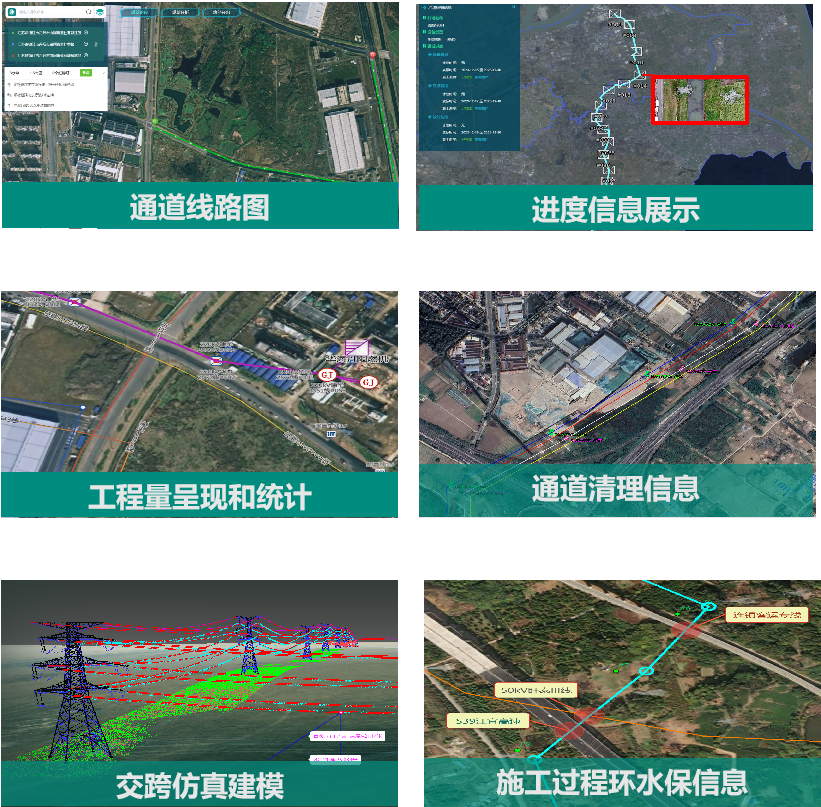
遥感技术赋能电力设施监控:应用案例篇
目前主流的电力巡检手段利用无人机能够通过设定灵活航线进行低空飞行、搭载不同的采集设备,能够从不同角度对输电线进行贴近拍摄,但缺陷是偏远山区无人机飞行技术要求高,成本高,且飞行的无人机也可能会对输电线产生破坏。 星图云开…...
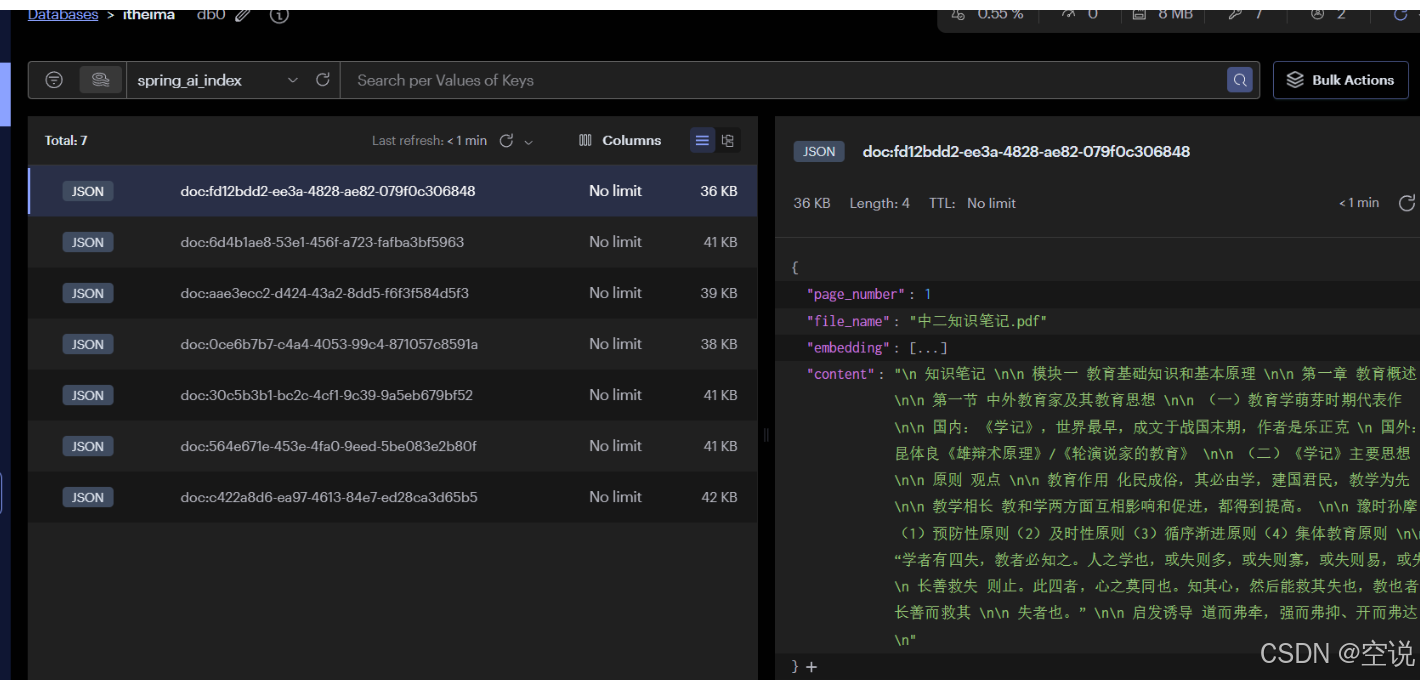
SpringAI+DeepSeek大模型应用开发——5 ChatPDF
ChatPDF 知识库 RAG检索增强 由于训练大模型非常耗时,再加上训练语料本身比较滞后,所以大模型存在知识限制问题: 知识数据比较落后,往往是几个月之前的;不包含太过专业领域或者企业私有的数据; 为了解决…...

yolov8 框架自带模型体验功能
简介 YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务。 YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,…...

柴油机气缸体顶底面粗铣组合机床总体及夹具设计
一、引言 柴油机气缸体是柴油机的关键部件,其顶底面的加工精度直接影响气缸体的装配质量和柴油机的性能。粗铣是气缸体顶底面加工的重要工序,设计一款高效、精确的粗铣组合机床及配套夹具,对于提高气缸体加工效率和质量具有重要意义。 二、…...

SpringBoot - Minio
1、简介 MinIO 是一个开源的对象存储服务器,用于存储和管理大规模的非结构化数据,例如图像、视频、日志文件、备份和容器镜像。MinIO 旨在提供高性能、高可用性、可扩展性和易用性的对象存储解决方案,适用于私有云、公共云和混合云环境。2、…...

Android --- SystemUI启动流程
1.main 函数入口,调用SystemServer().run()方法 代码路径:frameworks/base/services/java/com/android/server/SystemServer.java 2.run 方法中有3种服务的启动,我们主要看StartOtherService 代码路径:frameworks/base/services/java/com/android/se…...

docker镜像被覆盖了怎么办?通过sha256重新上传镜像
如果一个镜像通过相同的标签被重新推送(覆盖),那么旧的镜像内容虽然在 Docker 的存储中可能仍然存在,但通过原来的标签将无法直接访问到它。Docker 和 Harbor 默认情况下不会自动删除旧的镜像层,除非进行了垃圾回收&am…...
Java观察者模式在Android开发中的应用详解)
(二十六)Java观察者模式在Android开发中的应用详解
Java观察者模式在Android开发中的应用 观察者模式(Observer Pattern)是一种行为型设计模式,它定义了一种一对多的依赖关系,使得多个观察者对象可以同时监听一个主题对象。当主题对象的状态发生变化时,所有注册的观察者…...

【SpringMVC】深入解析自定义拦截器、注册配置拦截器、拦截路径方法及常见拦截路径、排除拦截路径、拦截器的执行流程
拦截器 上个章节我们完成了强制登录的功能, 后端程序根据Session来判断用户是否登录, 但是实现方法是比较麻烦的: 需要修改每个接口的处理逻辑需要修改每个接口的返回结果接口定义修改, 前端代码也需要跟着修改 有没有更简单的办法, 统一拦截所有的请求, 并进行Se…...

基于VS Code 为核心平台的python语言智能体开发平台搭建
以下是基于 VS Code 为核心平台,整合 Node-RED、Gradio、Docker Desktop 的智能体可视化开发平台优化方案,聚焦工具链深度集成与开发效率提升: 一、核心架构设计 #mermaid-svg-f8l9kYPAlJ2TlpGF {font-family:"trebuchet ms",verd…...

使用最新threejs复刻经典贪吃蛇游戏的3D版,附完整源码
基类Entity 建立基类Entity,实现投影能力、动画入场效果(从小变大的弹性动画)、计算自己在地图格位置的方法。 // 导入gsap动画库(用于创建补间动画) import gsap from gsap// 定义Entity基类 export default class …...
论坛测试报告
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

IPMI 与 Redfish API简介
--- ### **IPMI 与 Redfish API 详解** #### **1. IPMI(智能平台管理接口)** **简介** IPMI(Intelligent Platform Management Interface)是一种硬件级别的带外管理标准,允许管理员通过独立于操作系统的网络通道(BMC)监控和管理服务器硬件,即使主机已关机或操作系…...
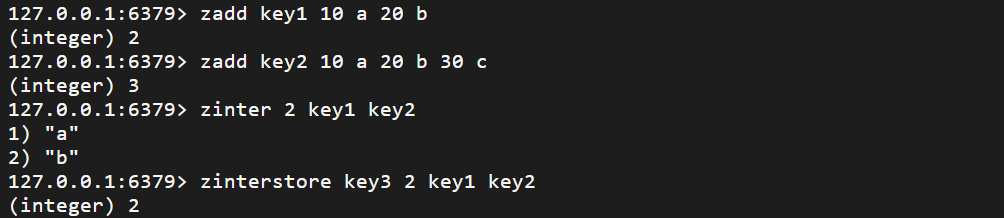
zset.
zset 有序集合 zset 保留了 set 不能有重复元素的特点 zset 中的每个元素都有一个唯一的浮点类型的分数(score)与之关联,使得 zset 内部的元素是可以维护有序性的。但是这个有序不是用下标作为排序依据的,而是根据分数…...

Windows 部署 DeepSeek 详细教程
一、准备工作 系统要求: 建议Windows 10 22H2 或更高版本,家庭版或专业版上网环境: 建议科学上网,国内访问部分网站会很慢设备要求: 内存8G以上、关闭防火墙 二、安装Ollama 官网链接: https://ollama.com/downloadg…...
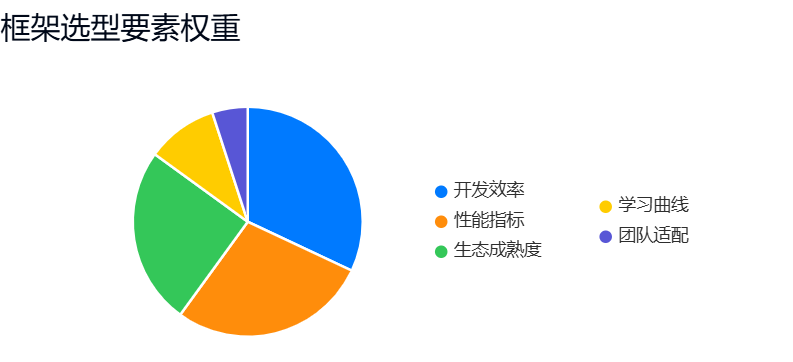
过去十年前端框架演变与技术驱动因素剖析
一、技术演进脉络(2013-2023) 2013-2015:结构化需求催生框架雏形 早期的jQuery虽然解决了跨浏览器兼容性问题(如IE8兼容性处理),但其松散的代码组织方式难以支撑复杂应用开发。Backbone.js的出现首次引入M…...

从零开始学A2A一:A2A 协议的高级应用与优化
A2A 协议的高级应用与优化 学习目标 掌握 A2A 高级功能 理解多用户支持机制掌握长期任务管理方法学习服务性能优化技巧 理解与 MCP 的差异 分析多智能体场景下的优势掌握不同场景的选择策略 第一部分:多用户支持机制 1. 用户隔离架构 #mermaid-svg-Awx5UVYtqOF…...

#Linux动态大小裁剪以及包大小变大排查思路
1 动态库裁剪 库分为动态库和静态库,动态库是在程序运行时才加载,静态库是在编译时就加载到程序中。动态库的大小通常比静态库小,因为动态库只包含了程序需要的函数和数据,而静态库则包含了所有的函数和数据。静态库可以理解为引入…...